データへの接続
2025 年 10 月 14 日以降、「Data Cloud」は「Data 360」というブランド名に変わりました。この変更の途上では、アプリケーションやドキュメントに「Data Cloud」と表示されることがあります。名前は新しいですが、機能と内容は変更されていません。
Tableau Prepは、分析のためにデータをクリーニングおよび形成する作業に役立てることができます。このプロセスの最初のステップは、使用するデータを特定することです。
特に記載がない限り、このトピックの情報はすべてのプラットフォームに適用されます。Web 上でのフローの作成の詳細については、Tableau Server ヘルプの「Web 上の Tableau Prep」(新しいウィンドウでリンクが開く)を参照してください。
次のいずれかを使用してデータに接続できます。
一般的なデータ型用の組み込みコネクタを介した接続
データ接続の最も一般的な方法は、Tableau Prep Builder で組み込みコネクタを使用することです。これらは最も一般的なデータ型で使用可能です。また、Tableau Prep Builder では新しいバージョンで新しいコネクタが頻繁に追加されています。使用可能なコネクタのリストを確認するには、Tableau Prep Builder を開くか、Web 上のフローを開始して [接続の追加] ボタンをクリックし、左側のペインの [接続] でデータに対応するコネクタが記載されているかどうかを確認します。
ボタンをクリックし、左側のペインの [接続] でデータに対応するコネクタが記載されているかどうかを確認します。
ほとんどの組み込みコネクタは、すべてのプラットフォームで同じように機能します。詳細は、Tableau Desktop ヘルプの「サポートされるコネクタ」(新しいウィンドウでリンクが開く)トピックで説明されています。
注意: データ ソースに接続するときは、フィールド名または計算フィールドに「レコード数」という予約名を使用しないでください。この予約名を使用すると、パーミッションに関連するエラーが発生します。
ネイティブ コネクタを使用する際の考慮事項
-
コネクタがサポートされていないバージョンでフローを開くと、フローは開きますが、エラーが発生する可能性があり、データ接続を削除しない限りフローを実行することができません。
- MySQL ベースのコネクタを使用する場合、既定の動作では、SSL が有効になっていると接続がセキュリティで保護されます。ただし、Tableau Prep Builder は、MySQL ベースのコネクタに対するカスタム証明書ベースの SSL 接続をサポートしていません。
-
バージョン 2025.1 以降では、オンプレミスのデータ ソースに接続し、フローを Tableau Cloud にパブリッシュして、スケジュールに従って実行できます。そうするには、Bridge クライアント プールに Tableau Bridge クライアントが構成されていて、ドメインがプライベート ネットワーク許可リストに追加されている必要があります。Tableau Prep Builder および Web 上でデータ ソースに接続するときは、サーバー URL が Bridge プール内のドメインと一致していることを確認してください。詳細については、「Tableau Server または Tableau Cloud へのフローのパブリッシュ」トピックの「データベース」セクションを参照してください。
-
Tableau Prep Conductor を実行して、Bridge を介してフラット ファイルに接続する Tableau Prep フローを更新することはできません。Prep Conductor のフロー更新が正常に行われるようにするには、フラット ファイルを Tableau Cloud が直接アクセスできる場所 (Google ドライブ、Box、Dropbox など) に移動します
-
Bridge 経由での Snowflake への接続はサポートされていません。
-
以下のセクションで詳しく説明されていますが、コネクタによっては Tableau Prep Builder で使用する場合の要件が異なることがあります。
-
バージョン 2025.3 以降、Tableau Prep Builder から Tableau Server または Tableau Cloud に接続するときに、Tableau Prep にパッケージ化された埋め込みブラウザーを使用して認証するか、マシンの既定のブラウザーを使用するかを選択できるようになりました。詳細については、「Tableau Server または Tableau Cloud へのフローのパブリッシュ(新しいウィンドウでリンクが開く)」を参照してください。
Tableau Desktop の場合と同じように、Tableau Prep でもクラウド データ ソースに接続できます。ただし、クラウド データ ソースに接続するフローをパブリッシュし、サーバーのスケジュールに従ってフローを実行する場合は、Tableau Server または Tableau Cloud で認証資格情報を設定する必要があります。
[マイ アカウントの設定] ページの [設定] タブで認証資格情報を設定し、同じ認証資格情報を使用してクラウド コネクタ入力に接続します。
Tableau Prep Builder
フローをパブリッシュする場合は、[パブリッシュ] ダイアログで [編集] をクリックして接続を編集し、[認証] ドロップダウンで <認証資格情報> の [埋め込み] を選択します。
フローをパブリッシュするときに、パブリッシュ ダイアログ (Tableau Prep Builder バージョン 2020.1.1 移行) から認証資格情報を追加し、自動的にフローに埋め込むこともできます。詳細については、「Tableau Prep Builder からフローをパブリッシュする」を参照してください。
認証資格情報を保存しておらず、[認証] ドロップダウンで [ユーザーの確認] を選択した場合は、フローをパブリッシュした後で接続を編集し、Tableau Server または Tableau Cloud の [接続] タブに認証資格情報を入力する必要があります。情報を入力しないと、実行時にフローが失敗します。
Web 上の Tableau Prep
Web オーサリングでは、上部のメニューの [ファイル] > [接続資格情報] で認証資格情報を埋め込むことができます。詳細については、Tableau Server ヘルプの「フローのパブリッシュ」(新しいウィンドウでリンクが開く)を参照してください。
![[ファイル] メニューには、[接続の認証資格情報] サブメニューが表示され、フローがパブリッシュされたときにデータ接続の認証資格情報をフロー内に埋め込むための [パブリッシュされたフローに埋め込む] が表示されています。](Img/prep_embed_credentials.png)
Tableau Prep Builderバージョン 2019.4.1 では、次のクラウド コネクタが追加され、Web 上でフローを作成または編集するときにも使用できます。
- Box
- DropBox
- Google ドライブ
- OneDrive
上記のコネクタを使用してデータへ接続する方法の詳細については、Tableau Desktop ヘルプでコネクタ固有の(新しいウィンドウでリンクが開く)ヘルプ トピックを参照してください。
Tableau Prep Builder バージョン 2020.2.1 以降でサポートされています。Web 上でフローを作成する場合は、Tableau Server および Tableau Cloud バージョン 2020.4 でサポートされています。
Tableau Prep Builder は、Tableau Desktop と同様に Salesforce コネクタを使用したデータへの接続に対応しますが、いくつかの違いがあります。
- Tableau Prep Builder は、どの結合タイプにも対応しています。
- カスタム SQL は、Tableau Prep Builder 2022.1.1 以降で作成できます。カスタム SQL を使用するフローを実行でき、2020.2.1 以降では既存のステップを編集できます。
- 標準接続を使用した独自のカスタム接続の作成は、現在対応していません。
- 既定のデータ ソース名を一意の名前にしたりカスタム名に変更したりすることはできません。
- 保存した認証資格情報を使用して Tableau Server にフローをパブリッシュする場合、サーバー管理者は、コネクタの OAuth クライアント ID とシークレットを使用して Tableau Server を構成する必要があります。詳細については、Tableau Server ヘルプの「Salesforce.com の OAuth を保存済みの認証資格情報に変更する(新しいウィンドウでリンクが開く)」を参照してください。
- Salesforce コネクタを使用するフロー入力で増分更新を実行するには、Tableau Prep Builder バージョン 2021.1.2 以降を使用している必要があります。増分更新の使用の詳細については、増分更新を使用したフロー データの更新を参照してください。
Tableau Prep では、抽出を作成してデータをインポートします。現在、Salesforce では、抽出のみ対応しています。含まれているデータ量によっては、最初の抽出に時間がかかる場合があります。データの読み込み中は、インプット ステップにタイマーが表示されます。
Salesforce コネクタの使用に関する一般的な情報については、「Tableau Desktop と Web 作成のヘルプ」の「Salesforce(新しいウィンドウでリンクが開く)」を参照してください。
Salesforce Data Cloud コネクタ (2023 年 10 月の Tableau Cloud でリリース) を使用すると、Salesforce Data Cloud を使用するデータに接続できます。詳細については、「Tableau Cloud の Web 作成を Salesforce Data Cloud に接続する」(新しいウィンドウでリンクが開く)を参照してください。
Salesforce Data Cloud のデータに接続するには、Salesforce Data Cloud コネクタを使用します。Salesforce Data Cloud コネクタは、データ スペースを認識し、より明確なオブジェクト ラベルを提示し、高速化されたクエリを活用します。
- [接続] ペインで、サーバー コネクタ リストから [Salesforce Data Cloud] を選択します。
- [Salesforce Data Cloud] ダイアログで、[サインイン] をクリックします。
- ユーザー名とパスワードを入力して Salesforce にサインインします。
- [許可] を選択します。
- ブラウザー ペインを閉じます。
- Tableau Prep で、データ スペースを選択してテーブルを表示します。
- テーブルを選択します。
Tableau Prep Builder は、Tableau Desktop と同様に、Google BigQuery を使用したデータへの接続をサポートします。
認証資格情報を設定して、Tableau Prep が Google BigQuery と通信できるようにする必要があります。フローを Tableau Server または Tableau Cloud にパブリッシュする計画がある場合は、それらのアプリケーションに対しても OAuth 接続を構成する必要があります。
注: Tableau Prep では、Google BigQuery のカスタマイズ属性の使用は現在サポートされていません。
- Google での OAuth の設定(新しいウィンドウでリンクが開く) - Tableau Server 用の OAuth 接続の構成。
- OAuth 接続(新しいウィンドウでリンクが開く) - Tableau Cloud 用の OAuth 接続の構成。
SSL を設定して Google BigQuery に接続 (MacOS のみ)
Mac で Tableau Prep Builder を使用し、プロキシで Big Query に接続している場合は、SSL 構成を変更して Google BigQuery に接続する必要が生じる可能性があります。
注: Windows ユーザーは、追加の手順は必要ありません。
Google BigQuery への OAuth 接続用に SSL を設定するには、次の手順を実行します。
- プロキシの SSL 証明書をファイル (proxy.cer など) にエクスポートします。証明書は
Applications > Utilities > Keychain Access >System > Certificates (under Category)にあります。 -
Tableau Prep Builder の実行に使用している Java のバージョンを特定します。例:
/Applications/Tableau Prep Builder 2020.4.app/Plugins/jre/lib/security/cacerts -
ターミナル コマンド プロンプトを開き、お使いの Tableau Prep Builder バージョンに合わせて次のコマンドを実行します。
注: keytool コマンドは、Tableau Prep Builder の実行に使用している Java のバージョンが含まれるディレクトリから実行する必要があります。このコマンドを実行する前に、ディレクトリの変更が必要な場合があります。例:
cd /Users/tableau_user/Desktop/SSL.cer -keystore Tableau Prep Builder 2020.1.1/Plugins/jre/bin。次に、keytool コマンドを実行します。keytool –import –trustcacerts –file /Users/tableau_user/Desktop/SSL.cer -keystore Tableau Prep Builder <version>/Plugins/jre/lib/security/cacerts -storepass changeit例:
keytool –import –trustcacerts –file /Users/tableau_user/Desktop/SSL.cer -keystore Tableau Prep Builder 2020.4.1/Plugins/jre/lib/security/cacerts -storepass changeit
keytool コマンドの実行時に FileNotFoundException (アクセスが拒否されました) と表示された場合は、引き上げられたアクセス許可でコマンドを実行してみてください。例: sudo keytool –import –trustcacerts –file /Users/tableau_user/Desktop/SSL.cer -keystore Tableau Prep Builder 2020.4.1/Plugins/jre/lib/security/cacerts -storepass changeit。
Google BigQuery 認証資格情報を設定および管理する
インプット ステップで Google BigQuery への接続に使用する認証資格情報は、Tableau Server または Tableau Cloud で Google BigQuery の [マイ アカウントの設定] ページにある [設定] タブで設定される認証資格情報と一致する必要があります。
フローをパブリッシュする際、認証の設定で異なる認証資格情報を選択したり、何も選択しなかったりすると、フローは認証エラーで失敗し、Tableau Server または Tableau Cloud でフローの接続の編集が必要になります。
認証資格情報を編集するには、次の手順を実行します。
- Tableau Server または Tableau Cloud で、Google BigQuery 接続の [接続] タブにある [その他のアクション]
![3 つのドットで表される [その他のオプション] メニュー。](Img/prep_moreoptions_icon.png) をクリックします。
をクリックします。 - [接続の編集] を選択します。
- [マイ アカウントの設定] ページの [設定] タブで設定した保存済みの認証資格情報を選択します。
サービス アカウント (JSON) ファイルを使用してサインイン
Tableau Prep Builder バージョン 2021.3.1 以降でサポートされています。Web 上でフローを作成する場合、サービス アカウントへのアクセスは利用できません。
- サービス アカウントを保存済み認証資格情報として追加します。詳細については、「Google OAuth を保存済み認証資格情報に変更する(新しいウィンドウでリンクが開く)」を参照してください。
- メール アドレスまたは電話番号を使用して Google BigQuery にサインインし、[次へ] を選択します。
- [認証] で、[Sign In using Service Account (JSON) file (サービス アカウント (JSON) ファイルを使用してサインイン)] を選択します。
- ファイル パスを入力するか、[参照] ボタンを使用してファイル パスを検索します。
- [サインイン] をクリックします。
- パスワードを入力して続行します。
- [同意する] を選択して、Tableau が Google BigQuery データにアクセスできるようにします。ブラウザーを閉じるように求めるプロンプトが表示されます。
OAuth を使用したサインイン
Tableau Prep Builder バージョン 2020.2.1 以降でサポートされています。Web 上でフローを作成する場合は、Tableau Server および Tableau Cloud バージョン 2020.4 でサポートされています。
- メール アドレスまたは電話番号を使用して Google BigQuery にサインインし、[次へ] を選択します。
- [認証] で、[Sign In using OAuth (OAuth を使用してサインイン)] を選択します。
- [サインイン] をクリックします。
- パスワードを入力して続行します。
- [同意する] を選択して、Tableau が Google BigQuery データにアクセスできるようにします。ブラウザーを閉じるように求めるプロンプトが表示されます。
認証資格情報の設定と管理に関する詳細については、次のトピックを参照してください。
「Tableau Desktop と Web 作成のヘルプ」の「アカウント設定の管理」(新しいウィンドウでリンクが開く)。
フローをパブリッシュするときに認証オプションを設定する方法については、「Tableau Prep Builder からフローをパブリッシュする(新しいウィンドウでリンクが開く)」を参照してください。
Tableau Server または Tableau Cloud で接続エラーを解決する方法については、「エラーの表示と解決(新しいウィンドウでリンクが開く)」を参照してください。
Tableau Prep Builder バージョン 2019.2.1 以降でサポートされています。Web 上でフローを作成する場合は、Tableau Server および Tableau Cloud バージョン 2020.4 でサポートされています。
Tableau Prep Builder、Tableau Server、Tableau Cloud は、Tableau Desktop と同様に SAP HANA を使用したデータへの接続に対応しますが、いくつかの違いがあります。
Tableau Desktop と同じ手順を使用してデータベースに接続します。詳細については、「SAP HANA(新しいウィンドウでリンクが開く)」を参照してください。接続してテーブルを検索した後で、テーブルをキャンバスにドラッグし、フローの構築を開始します。
注: フローをスケジュールに従って実行するには、このコネクタを Tableau Server バージョン 2019.2 以降で使用する必要があります。以前のバージョンのサーバーを使用している場合は、コマンド ライン インターフェイスを使用してフロー データを更新できます。コマンド ラインからのフロー実行の詳細については、「コマンド ラインからフロー出力ファイルを更新(新しいウィンドウでリンクが開く)」を参照してください。
-
SAP HANA データベースに変数やパラメーターが含まれている場合、それらの値を設定するため、[入力] ステップの [設定] タブにある [変数とパラメーター] セクションで必要な情報を入力する必要があります。古い Tableau Prep バージョン (2026.1 以前) の場合は、[入力] ステップの [変数とパラメーター] タブに移動します。
-
変数およびパラメーター値を使用する SAP HANA データソースへの接続は、ライブ データソースでのみサポートされます。このオプションは、SAP HANA のパブリッシュされたデータ ソースではサポートされていません。
-
Tableau Cloud バージョン 2026.2 以降では、Tableau Bridge を利用して、変数とパラメーターを含むオンプレミスの SAP HANA データ ソースに接続できます。
-
Tableau Prep Builder バージョン 2019.2.2 以降および Web 上ではバージョン 2020.4.1 以降、初期 SQL を使用して接続のクエリを実行できます。変数に複数の値がある場合は、ドロップダウン リストから必要な値を選択できます。
変数とパラメーターを入力します。
-
SAP HANA データ ソースに接続します。
-
[入力] ペインの [設定] タブで、使用する変数とオペランドを選択します。
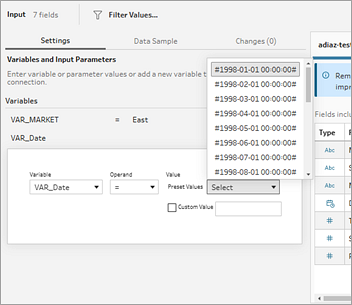
以前のバージョン (2026.1 以前) では、[変数とパラメーター] タブを選択してから、使用する変数とオペランドを選択します。

-
プリセット値のリストから選択するか、カスタム値を入力してデータベースにクエリを実行し、必要な値を返すか、変数を追加します。変数を追加するには、[変数] セクションでプラス ボタン
 をクリックし、変数とオペランドを選択してからカスタム値を入力します。
をクリックし、変数とオペランドを選択してからカスタム値を入力します。![[変数] セクションでプラス ボタンをクリックし、変数とオペランドを選択してからカスタム値を入力することで、その他の値を追加します。](Img/prep_SAPHANA2.png)
Tableau Prep Builder バージョン 2020.4.1 以降でサポートされています。Web 上でフローを作成する場合は、Tableau Server および Tableau Cloud バージョン 2020.4 でサポートされています。
Tableau Prep Builder の場合、またはWeb 上でフローを作成または編集する場合、空間ファイルおよび空間データ ソースに接続できます。
注: 現時点では、.shp ファイル タイプは Web ではサポートされていません。このファイル タイプに接続する必要がある場合は、Tableau Prep Builder でこのファイル タイプに接続してから、フローをサーバーにパブリッシュします。
Tableau Prep は以下の接続タイプをサポートしています。
- 空間ファイル形式
- Tableau Prep Builder: Esri シェープファイル、Esri File Geodatabases、KML、TopoJSON、GeoJSON、抽出、MapInfo MID/MIF、TAB ファイル、圧縮されたシェープファイル。
- Tableau Server および Tableau Cloud: 圧縮されたシェープファイル、KML、TopoJSON、GeoJSON、Esri File Geodatabases、抽出。
- 空間データベース (Amazon Redshift、Microsoft SQL Server、Oracle、PostgreSQL)。
バージョン 2026.1 以降では、空間関数を使用して計算フィールドを作成し、結合ステップで 交差演算子を使用して空間データを結合できます。詳細については、「空間計算と結合の作成(新しいウィンドウでリンクが開く)」を参照してください。
標準の結合を使用して空間テーブルと非空間テーブルを組み合わせ、抽出 (.hyper) ファイルに空間データを出力することもできます。Tableau Prep では、マップ ビュー上での空間データの視覚化は、現在サポートされていません。
サポート済みクリーニング操作
空間ファイル データを操作する場合、一部のクリーニング操作はサポートされません。Tableau Prep では、シェイプ ファイル データに次のクリーニング操作のみ使用できます。
- フィルター: Null 値または不明な値のみの削除
- フィールド名の変更
- フィールドの複製
- 保持するフィールド
- フィールドの削除
- 計算フィールドの作成
接続する前に
空間ファイルに接続する前に、以下のファイルが同じディレクトリに存在することを確認します。
- Esri シェープファイル: フォルダーには Esri シェープファイルの .zip ファイルおよび .shp、.shx、.dbf、.prj などのファイルが含まれている必要があります。
- Esri File Geodatabases: フォルダーには File Geodatabase の .gdb ファイル、または File Geodatabases の .gdb の .zip ファイルが含まれている必要があります。
- KML ファイル: フォルダーには .kml file ファイルが含まれている必要があります(他のファイルは不要です)。
- GeoJSON ファイル: フォルダーには .geojson ファイルが含まれている必要があります (他のファイルは不要です)。
- TopoJSON ファイル: フォルダー .json ファイルまたは .topojson ファイルが含まれている必要があります(他のファイルは不要です)。
空間ファイルへの接続
-
次のいずれかを実行します。
- Tableau Prep Builder を開き、[接続の追加] ボタンをクリックします。
- Tableau Server または Tableau Cloud を開きます。[エクスプローラ] メニューの [新規作成] > [フロー] をクリックします。
- Tableau Prep Builder を開き、[接続の追加]
-
コネクタのリストから [空間ファイル] を選択します。
空間フィールドには空間データ タイプが割り当てられており、変更はできません。フィールドを空間ファイルから取得する場合、フィールドにはデフォルトのフィールド名 "Geometry" が割り当てられます。フィールドを空間データベースから取得する場合、データベースのフィールド名が表示されます。Tableau がデータのタイプを判断できない場合、フィールドは "Null" と表示されます。

Tableau Prep Builder バージョン 2019.2.2 以降でサポートされています。このコネクタのタイプは、Web 上でのフローの作成ではまだサポートされていません。
[接続] ペインにリストされていないデータ ソースへ接続する必要がある場合は、SQL 標準をサポートするその他のデータベース (ODBC) コネクタを使用して任意のデータ ソースに接続し、ODBC API を実装できます。その他のデータベース (ODBC) コネクタを使用したデータへの接続は、そのコネクタを Tableau Desktop で使用する場合と似ていますが、いくつかの相違点があります。
-
接続できるのは、DSN (データ ソース名) オプションを使用する場合のみです。
-
Tableau Server でフローをパブリッシュして実行するには、サーバーが一致する DSN を使用して構成されている必要があります。
注: その他のデータベース (ODBC) コネクタを含むフローのコマンド ラインからの実行は、現在サポートされていません。
-
Windows と MacOS の両方に単一の接続エクスペリエンスがあります。ODBC ドライバー (Windows) の接続属性の確認を求める機能はサポートされていません。
-
Tableau Prep Builder で対応しているのは 64 ビット ドライバーのみです。
接続する前に
その他のデータベース (ODBC) コネクタを使用してデータに接続するには、データベース ドライバーをインストールして、DSN (データ ソース名) の設定と構成を行う必要があります。Tableau Server にフローをパブリッシュして実行するには、サーバーが一致する DSN を使用して構成されている必要があります。
重要: Tableau Prep Builder でサポートされているのは、64 ビットドライバーのみです。32 ビット ドライバーの設定と構成を既に行っており、ドライバーで 32 ビット版と 64 ビット版の同時インストールが許可されていない場合は、32 ビット版をアンインストールしてから 64 ビット版をインストールする必要があります。
-
ODBC データ ソース アドミニストレーター (64 ビット) (Windows) または ODBC Manager ユーティリティ (MacOS) のいずれかを使用して DSN を作成します。
お使いの Mac にユーティリティがインストールされていない場合は、www.odbcmanager.net(新しいウィンドウでリンクが開く) などからダウンロードするか、odbc.ini ファイルを手動で編集できます。
-
ODBC データ ソース アドミニストレーター (64 ビット) (Windows) または ODBC Manager ユーティリティ (MacOS) で、新しいデータ ソースを追加してからデータ ソースのドライバーを選択し、[完了] をクリックします。

-
[ODBC Driver Setup (ODBC ドライバーのセットアップ)] ダイアログで、サーバー名、ポート、ユーザー名、パスワードなどの構成情報を入力します。[テスト] (ダイアログにこのオプションがある場合) をクリックして接続が正しく設定されていることを確認してから、構成を保存します。
注: Tableau Prep Builder では、接続属性の確認を求める機能はサポートされていません。DNS の構成時にこの情報を設定する必要があります。
次の例では、MySQL Connector の構成ダイアログを示します。

その他のデータベース (ODBC) を使用した接続
-
Tableau Prep Builder を開き、[接続の追加]
ボタンをクリックします。 -
コネクタのリストから、[その他のデータベース (ODBC)] を選択します。
-
[その他のデータベース (ODBC)] ダイアログで、ドロップダウン リストから DSN を選択し、ユーザー名とパスワードを入力します。次に、[サインイン] をクリックします。

-
[接続] ペインで、ドロップダウン リストからデータベースを選択します。

Microsoft Excel の直接接続にのみ対応しています。Data Interpreter は、現在、クラウド ドライブに保存された Excel ファイルでは利用できません。
注: Tableau Prep Conductor を実行して、Bridge を介してフラット ファイルに接続する Tableau Prep フローを更新することはできません。Prep Conductor のフロー更新が正常に行われるようにするには、フラット ファイルを Tableau Cloud が直接アクセスできる場所 (Google ドライブ、Box、Dropbox など) に移動します
Microsoft Excel ファイルを操作する場合、Data Interpreter を使用してデータのサブテーブルを検出したり、関係のない情報を削除して分析用データの準備を行うことができます。Data Interpreter をオンにすると、これらのサブテーブルを検出し、[接続] ペインの [テーブル] セクションで新しいテーブルとしてリストに記載します。その後、[フロー] ペインにドラッグできます。
Data Interpreter をオフにすると、これらのテーブルは [接続] ペインから削除されます。これらのテーブルがフローで既に使用されている場合は、データの欠落のためフローでエラーが発生します。
注: 現在、Data Interpreter は Excel スプレッドシートのサブテーブルのみを検出します。テキスト ファイルとスプレッドシートの開始行の指定はサポートされていません。また、データ インタープリターが検出したテーブルは、ワイルドカード ユニオンの検索結果に含まれません。
以下の例は、[接続] ペインで Excel スプレッドシートに Data Interpreter を使用した結果を示しています。Data Interpreter が 2 つの追加サブテーブルを検出しました。
| Data Interpreter 使用前 | Data Interpreter 使用後 |
|---|---|
![Tableau Prep の [接続] ペインにある [Data Interpreter の使用] チェック ボックス。](Img/prep_DIbefore.png)
|
![Tableau Prep の [接続] ペインの [テーブル] セクションに表示される Data Interpreter の結果。見つかったサブテーブルのリストが表示されています。](Img/prep_DIafter.png)
|
Data Interpreter を使用するには、以下の手順を完了します。
-
[データへの接続]、[Microsoft Excel] の順に選択します。
-
ファイルを選択し、[開く] をクリックします。
-
[Data Interpreter の使用] チェック ボックスを選択します。
-
新しいテーブルを [フロー] ペインにドラッグし、フローに含めます。古いテーブルを削除するには、古いテーブルのインプット ステップを右クリックし、[削除] を選択します。
カスタム コネクタを使用した接続
Tableau Prep で ODBC ベースおよび JDBC ベースのデータ用の組み込みコネクタが提供されていない場合は、カスタム コネクタを使用できます。実行できること:
- パートナーが作成したコネクタを使用する。Exchange のコネクタの詳細については、「パートナーが作成したコネクタを使用する」を参照してください。
- Tableau コネクタ SDK を使用して構築されたカスタム コネクタを使用します。コネクタ SDKは、ODBC ベースまたは JDBC ベースのデータ用にカスタマイズされたコネクタを構築するためのツールを提供します。詳細については、Tableau Desktop ヘルプの「Tableau コネクタ SDK を使用して構築されたコネクタ」(新しいウィンドウでリンクが開く)を参照してください。
ODBC ベースおよび JDBC ベースのデータ用のカスタム コネクタは、Tableau Prep Builder バージョン2 020.4.1 以降でサポートされています。
コネクタ開発者の方は、「コネクタの実行」を参照し、詳細を確認してください。
コネクタによっては、追加のドライバーをインストールする必要があります。接続プロセス中にメッセージが表示された場合は、そのメッセージに従って必要なドライバーをダウンロードしてインストールします。カスタム コネクタは現在 Tableau Cloud では使用できません。
パートナーが作成したコネクタを使用する
パートナーが作成したコネクタ、またはその他のカスタム コネクタは、[接続] ペインから利用できます。これらのコネクタは [追加の接続] に表示され、Tableau Exchange コネクタページからも利用できます。
- 左側のペインで、[接続] をクリックします。
- [接続] ペインの [追加の接続] セクションから、使用するコネクタをクリックします。
- [Tableau をインストールして再起動する] をクリックします。
コネクタがインストールされると、[接続] ペインの [サーバーへ] セクションにコネクタが表示されます。
注: コネクタを読み込めないという警告が表示された場合は、Tableau Exchange コネクタ ページから必要な .taco ファイルをインストールします。ドライバーをインストールするよう求められたら、Tableau Exchange にアクセスしてドライバーのダウンロード手順とダウンロードする場所を確認してください。
パブリッシュされたデータ ソースへの接続
パブリッシュされたデータソースは、他のユーザーと共有できるデータ ソースです。他のユーザーがデータ ソースを利用できるようする場合は、Tableau Prep Builder (バージョン 2019.3.1 以降) から Tableau Server または Tableau Cloud にパブリッシュするか、フローからの出力としてパブリッシュできます。
Tableau Prep Builder で作業している場合でも、Web 上で作業している場合でも、パブリッシュされたデータ ソースをフローの入力データ ソースとして使用できます。
注: パブリッシュされたデータ ソースがインプットとして含まれるフローをパブリッシュすると、パブリッシャーが既定のフロー所有者として割り当てられます。フローを実行するときは、フロー所有者を実行アカウントに使用します。実行アカウントの詳細については、「実行サービス アカウント(新しいウィンドウでリンクが開く)」を参照してください。Tableau Server または Tableau Cloud でフロー所有者を変更できるのはサイト管理者またはサーバー管理者のみで、自分自身のみに変更できます。
Tableau Prep Builder サポート:
- ユーザー フィルターまたは関数を含むパブリッシュされたデータ ソースは、Tableau Prep Builder (バージョン 2021.1.3 以降) でサポートされます。
- 単一サーバーおよびサイトへの接続。異なるサーバーへのログインや、同じサーバーで異なるサイトへのログインはサポートされていません。次の操作を実行するには、同じサーバーまたはサイトへの接続を使用する必要があります。
- パブリッシュされたデータ ソースに接続する。
- フロー出力を Tableau Server または Tableau Cloud へパブリッシュする。
- Tableau Server または Tableau Cloud でのフローの実行をスケジュールする。
フローでパブリッシュされたデータ ソースを使用している場合、サーバーからサインアウトすると、フロー接続が切断されます。フローはエラー状態になり、パブリッシュされたデータ ソースからのデータをプロファイル ペインまたはデータ グリッドに表示することができなくなります。
注: Tableau Prep Builder では、多次元 (キューブ) データやマルチサーバー接続を含むパブリッシュされたデータ ソース、または関連するテーブルを含むパブリッシュされたデータ ソースはサポートされません。
Tableau Server および Tableau Cloud では以下がサポートされます。
- Tableau Server および Tableau Cloud バージョン 2021.2 以降のユーザー フィルターまたは関数を含むパブリッシュされたデータ ソース
- パブリッシュされたデータ ソース (Tableau Server または Tableau Cloud バージョン 2020.4 以降) を使用した Web 上でのフローの作成と編集
- パブリッシュされたデータ ソース (Tableau Server および Tableau Cloud バージョン 2019.3 以降) への接続
注: 以前のバージョンの Tableau Server では、パブリッシュされたデータ ソースの一部の機能がサポートされない場合があります。
認証資格情報とパーミッションについて:
- パブリッシュされたデータ ソースに接続するには、サインインしているサーバー サイトで Explorer 以上のロールが割り当てられている必要があります。Web 上でフローを作成または編集できるのは作成者だけです。サイト ロールの詳細については、Tableau Server ヘルプの「ユーザーのサイト ロールの設定(新しいウィンドウでリンクが開く)」を参照してください。
- Tableau Prep Builder では、サーバーにサインインしたユーザー ID に基づいてデータ ソース アクセスが承認されます。アクセスできるデータのみが表示されます。
-
Prep の Web 作成 (Tableau Server および Tableau Cloud) でも、サーバーにサインインしたユーザー ID に基づいてデータ ソース アクセスが承認されます。アクセスできるデータのみが表示されます。
ただし、フローを手動で実行するか、スケジュールを使用して実行する場合、データ ソース アクセスはフロー所有者の ID に基づいて承認されます。フローを最後にパブリッシュしたユーザーが新しいフロー所有者になります。
- サイト管理者およびサーバー管理者はフロー所有者を変更できますが、自分自身にのみ変更できます。
- パブリッシュされたデータ ソースに接続するには、認証資格情報を埋め込む必要があります。
ヒント: データ ソースの認証資格情報が埋め込まれていない場合は、データ ソースを更新して埋め込みの認証資格情報を追加する必要があります。
フローでパブリッシュされたデータ ソースを使用する
パブリッシュされたデータ ソースに接続してそれをフローで使用するには、Tableau Prep の次のバージョンの手順に従います。
[接続] ペインから、Tableau Server や Tableau Cloud に保存されているパブリッシュされたデータ ソースなどに直接接続できます。Tableau Catalog が有効になっている データ管理(新しいウィンドウでリンクが開く) を使用している場合は、データベースやテーブルを検索して接続し、説明、データ品質警告、証明書などのデータ ソースに関するメタ データを表示したりフィルター処理したりすることもできます。
Tableau Catalog の詳細については、Tableau Server(新しいウィンドウでリンクが開く) または Tableau Cloud(新しいウィンドウでリンクが開く) のヘルプの「Tableau Catalog について」を参照してください。
-
Tableau Prep Builder を開き、[接続の追加]
ボタンをクリックします。Web オーサリングでは、ホーム ページで [作成] > [フロー] をクリックするか、[探索] ページで [新規作成] > [フロー] をクリックします。次に [データへの接続] をクリックします。
-
[接続] ペインの [データの検索] から [Tableau Server] を選択します。

-
サインインしてサーバーまたはサイトに接続します。
Web 作成では、サインインしているサーバーの [データの検索] ダイアログが開きます。バージョン 2025.3 以降では、サーバーの認証方法 (埋め込みブラウザーまたは既定のブラウザー) を選択することもできます。詳細については、「Tableau Server または Tableau Cloud へのフローのパブリッシュ(新しいウィンドウでリンクが開く)」を参照してください。
-
[データの検索] ダイアログで、使用可能なパブリッシュされたデータ ソースのリストから検索します。フィルター オプションを使用して、接続のタイプと認定されたデータ ソースでフィルター処理します。
-
使用するデータ ソースを選択し、[接続] をクリックします。
データ ソースに接続するパーミッションがない場合は、行と [接続] ボタンは灰色で表示されます。
注: Tableau Catalog が有効になっている データ管理 を使用していない場合は、[コンテンツ タイプ] ドロップダウンは表示されません。パブリッシュされたデータ ソースのみがリストに表示されます。
![[データ ソース] コンテンツ タイプが選択された状態で [データ] ペインを検索します。](Img/prep_SearchDataCatalog2.png)
-
データ ソースが [フロー] ペインに追加されます。[接続] ペインで、追加のデータ ソースを選択するか、検索オプションを使用してデータ ソースを検索し、フロー ペインにドラッグしてフローを作成します。[入力] ペインの [Tableau Server] タブに、パブリッシュされたデータ ソースの詳細が表示されます。
![[接続] ペインに検索可能なデータ ソースのリストを表示する Tableau Prep フロー。](Img/prep_dai_metadata.png)
-
(オプション) Tableau Catalog が有効になっている データ管理 を使用している場合は、[コンテンツ タイプ] ドロップダウンを使用してデータベースとテーブルを検索できます。
![[データ ソース] コンテンツ タイプが選択された状態で [データ] ペインを検索します。](Img/prep_SearchDataCatalog3.png)
右上隅のフィルター オプションを使用して、接続タイプ、データ品質の警告、認定などで結果をフィルター処理することができます。

-
Tableau Prep Builder を開き、[接続の追加]
ボタンをクリックします。 -
コネクタのリストから、[Tableau Server] を選択します。
![[Tableau Server 接続] が強調表示された Tableau Prep の [接続] ペイン。](Img/prep_connect_dai.png)
-
サインインしてサーバーまたはサイトに接続します。
-
データ ソースを選択するか、検索オプションを使用してデータ ソースを検索し、フロー ペインにドラッグしてフローを開始します。[入力] ペインの [Tableau Server] タブに、パブリッシュされたデータ ソースの詳細が表示されます。
仮想接続に接続する
Tableau Prep Builder バージョン 2021.4.1 以降、Tableau Server および Tableau Cloud バージョン 2021.4 以降でサポートされています。この機能を使用するには データ管理 が必要です。
フローで仮想接続を使用してデータに接続できます。仮想接続は、データへの中央アクセス ポイントを提供する共有可能なリソースです。
仮想接続に接続する際の考慮事項:
- データベースの認証資格情報は仮想接続に埋め込まれています。サーバーにサインインするだけで、仮想接続のテーブルにアクセスできます。
- 行レベルのセキュリティを適用するデータ ポリシーを仮想接続に含めることができます。フローを操作および実行するときに、アクセスできるテーブル、フィールド、値のみが表示されます。
- 仮想接続の行レベルのセキュリティは、フロー出力には適用されません。フロー出力にアクセスできるすべてのユーザーに、同じデータが表示されます。
- カスタム SQL と初期 SQL はサポートされていません。
- パラメーターはサポートされていません。フローでパラメーターを使用する方法の詳細については、フローでパラメーターを作成して使用するを参照してください。
仮想接続とデータ ポリシーの詳細については、Tableau Server(新しいウィンドウでリンクが開く) または Tableau Cloud(新しいウィンドウでリンクが開く) のヘルプを参照してください。
-
Tableau Prep Builder を開き、[接続の追加]
ボタンをクリックします。Web オーサリングでは、ホーム ページで [作成] > [フロー] をクリックするか、[探索] ページで [新規作成] > [フロー] をクリックします。次に [データへの接続] をクリックします。
-
[接続] ペインの [データの検索] から [Tableau Server] を選択します。
-
サインインしてサーバーまたはサイトに接続します。
Web オーサリングでは、サインインしているサーバーの [データの検索] ダイアログが開きます。
-
[すべて入力] をクリックします。

-
[仮想接続] を選択します。

-
使用するデータ ソースを選択し、[接続] をクリックします。
-
データ ソースが [フロー] ペインに追加されます。[接続] ペインで、仮想接続に含まれているテーブルのリストから選択し、それらを [フロー] ペインにドラッグして、フローを開始できます。

注: 仮想接続に接続するときに、[変更内容] ペインに [名前の変更] 操作が表示された場合は、それらを削除しないでください。Tableau Prep は、これらの操作を自動生成して、フィールドのユーザー フレンドリーな名前にマップして表示します。
Tableau データ抽出への接続
データ フローへの入力としてデータ抽出に接続できます。抽出は、フィルターを使用して他の制限を構成することによって作成できるデータの保存済みサブセットです。抽出は.hyper ファイルとして保存されます。
Tableau Prep Builder での抽出の使用ついては、作業の保存と共有を参照してください。
Tableau Catalog を介したデータへの接続
データ管理(新しいウィンドウでリンクが開く) が Tableau Catalog で有効になっている場合は、Tableau Server や Tableau Cloud に保存されているデータベースやテーブル、ファイルなどを検索して接続できるようになりました。
Tableau Catalog の詳細については、Tableau Server(新しいウィンドウでリンクが開く) や Tableau Cloud(新しいウィンドウでリンクが開く) のヘルプの「Tableau Catalog について」を参照してください。
その他の接続オプション
接続すると、選択した接続に応じて、次のオプションが表示される場合があります。
カスタム SQL を使用したデータへの接続
データベースから必要な情報を把握し、SQL クエリの記述方法を理解している場合は、Tableau Desktop の場合と同じように、カスタム SQL クエリを使用してデータに接続できます。カスタム SQL を使用すると、テーブル間でデータのユニオンを作成したり、フィールドを再キャストしてクロスデータベース結合を実行したり、分析のためにデータを再構築またはデータのサイズを圧縮したりすることができます。
-
データ ソースに接続し、[接続] ペインの [データベース] フィールドでデータベースを選択します。
-
[カスタム SQL] リンクをクリックして [カスタム SQL] タブを開きます。
![Tableau Prep フロー入力ステップの [カスタム SQL] タブ。データに接続するための SQL クエリを入力できます。](Img/prep_custom_sql.png)
-
テキスト ボックスにクエリを入力するか貼り付け、[実行] をクリックしてクエリを実行します。
![Tableau Prep フロー入力ステップの [カスタム SQL] タブ。データに接続するための SQL クエリを入力できます。](Img/prep_custom_SQL2.png)
- フロー ペインにクリーニング ステップを追加して、カスタム SQL クエリの関連フィールドだけがフローに追加されることを確認します。
初期 SQL を使用した接続のクエリ
Tableau Prep Builder バージョン 2019.2.2 以降でサポートされています。Web 上でフローを作成する場合は、バージョン 2020.4.1 でサポートされています。
対応するデータベースへの接続時に実行する初期 SQL コマンドを指定できます。たとえば、Amazon Redshift に接続する場合、データベースへの接続時に、インプット ステップでフィルターを追加するときのように、SQL ステートメントを入力してフィルターを適用できます。SQL コマンドは、データがサンプリングされ Tableau Prep に読み込まれる前に適用されます。
Tableau Prep Builder (バージョン 2020.1.3 以降) および Web 上では、アプリケーション名、バージョン、およびフロー名などのデータを渡すパラメーターを含めることにより、データ ソースをクエリするときに追跡データを含めることもできます。
初期 SQL の実行
データを更新して初期 SQL コマンドを実行するには、次のいずれかの操作を行います。
- 初期 SQL コマンドを変更し、接続を再確立してインプット ステップを更新します。
- フローを実行します。初期 SQL コマンドは、すべてのデータを処理する前に実行されます。
- Tableau Server または Tableau Cloud 上でフローを実行します。初期 SQL は、フローが実行されるたびにデータの読み込み操作の一部として実行されます
注: Tableau Server または Tableau Cloud でスケジュールを設定してフローを実行するには、データ管理(新しいウィンドウでリンクが開く) が必要です。データ管理 の詳細については「データ管理 について(新しいウィンドウでリンクが開く)」を参照してください。

- [接続] ペインで、リストから初期 SQL をサポートするコネクタを選択します。
- [初期 SQL の表示] リンクをクリックしてダイアログを展開し、SQL ステートメントを入力します。
初期 SQL ステートメントへのパラメーターのインクルード
Tableau Prep Builder バージョン 2020.1.3 以降でサポートされています。Web 上でフローを作成する場合は、バージョン 2020.4.1 以降でサポートされています。
次のパラメーターをデータ ソースに渡すと、Tableau Prep アプリケーション、バージョン、およびフロー名に関する詳細情報を追加できます。TableauServerUser および TableauServerUserFull パラメーターは現在サポートされていません。
| パラメーター | 説明 | 戻り値 |
|---|---|---|
| TableauApp | データ ソースへのアクセスに使用されるアプリケーション。 |
Prep Builder Prep Conductor |
| TableauVersion | アプリケーションのバージョン番号。 |
Tableau Prep Builder: 正確なバージョンを返します。例: 2020.4.1 Tableau Prep Conductor: Tableau Prep Conductor が有効になっているメジャー サーバー バージョンを返します。例: 2020.4 |
| FlowName | Tableau Prep Builder での .tfl ファイルの名前。 | 例: Entertainment Data_Cleaned |