データ セットの構成
注: バージョン 2020.4.1 以降では、Tableau Server および Tableau Cloud でフローの作成と編集を行えるようになりました。このトピックの内容は、特に記載がない限り、すべてのプラットフォームに適用されます。Web 上でのフローの作成の詳細については、Tableau Server(新しいウィンドウでリンクが開く) および Tableau Cloud(新しいウィンドウでリンクが開く) ヘルプの「Web 上の Tableau Prep」を参照してください。
データ セットを設定して、フローで扱うデータ セットの量を決定することができます。データに接続するか、テーブルを [フロー] ペインにドラッグすると、インプット ステップがフローに自動的に追加されます。
インプット ステップでは、フローに含めるデータの内容と量を決定できます。これは常にフローの最初のステップになります。
入力ステップからデータを更新することもできます。詳細については、「インプット ステップでのデータの追加(新しいウィンドウでリンクが開く)」を参照してください。
インプット ステップでは、次のことができます。
- フロー ペインのインプット ステップを右クリック (MacOS では Cmd を押しながらクリック) して、名前を変更したり、削除したりすることができます。
- 同じ親ディレクトリまたは子ディレクトリにある複数のファイルをユニオンします。詳細については、「インプット ステップでのファイルおよびデータベース テーブルのユニオン作成」を参照してください。
- (バージョン 2023.1 以降) データ セットの元の並べ替え順序に基づいて自動的に生成された行番号が含まれるようになりました。「データ セットの行番号を含める」を参照してください。
- フィールドを検索します。
- フィールド値のプレビューを参照してください。
- また、フィールド名を変更したりテキスト ファイルにテキスト設定を構成したりすることで、フィールドのプロパティを構成できます。
注: 角かっこが含まれるフィールド値は自動的に丸かっこに変換されます。
- フローに取り込まれるデータ サンプルを設定します。「データ サンプルのサイズの設定」を参照してください。
- 不要なフィールドを削除します。インプット ステップにはいつでも戻ることができ、後でフィールドを含めることができます。
- クリー二ングする必要はないが、フロー出力には含めたいフィールドを非表示にします。必要に応じて、いつでも再表示できます。
- 選択したフィールドにフィルターを適用します。
- データ接続がサポートするフィールドのデータ型を変更します。
- (バージョン 2023.3 以降) CSV ファイルのヘッダーと開始行を設定できます。
- (バージョン 2024.1 以降) Excel ファイルのヘッダーと開始行を設定できます。
データ セットの行番号を含める
Tableau Prep Builder バージョン 2023.1 以降と Web 上の Microsoft Excel およびテキスト (.csv) ファイルでサポートされています。
注: このオプションは、現在、インプット ユニオンに含まれるファイルではサポートされていません。
バージョン 2023.1 以降、Tableau Prep はデータの元の並べ替え順序に基づいて行番号を自動的に生成し、フローに新しいフィールドとして含めることができるようになりました。これは、Microsoft Excel またはテキスト (.csv) のファイル タイプでのみ使用できます。
以前のリリースでは、これらの行番号を含めたい場合は、データ セットをフローに追加する前に、手動でソースに追加する必要がありました。
このフィールドは、データに接続するときにインプット ステップで生成されます。デフォルトではフローから除外されていますが、ワンクリックでフローに含めることができます。含めることを選択した場合、他のフィールドと同様に動作し、フロー操作および計算フィールドで使用できます。
Tableau Prep は、計算フィールドの ROW_NUMBER 関数もサポートします。この関数は、行 ID やタイムスタンプなど、並べ替えを定義できるフィールドがデータ セットにある場合に役立ちます。この関数の使用方法については、「詳細レベル、ランク、タイル計算の作成」を参照してください。
ソース行番号フィールドのフローへの追加
-
フィールドを右クリックまたは Cmd キーを押しながらクリック (MacOS) するか、[その他のオプション]
![3 つのドットで表される [その他のオプション] メニュー。](Img/prep_moreoptions_icon.png) メニューをクリックして、[Include Field (フィールドを含める)] を選択します。
メニューをクリックして、[Include Field (フィールドを含める)] を選択します。データのプレビュー:

フィールドのリスト:

変更リストがクリアされ、フィールドがフロー データの一部になると、後続のフロー ステップに生成された行番号が表示されます。
ソース行番号の詳細
ソース行番号をデータ セット含める場合、次のオプションと考慮事項が適用されます。
- データ ソースの行番号は、データのサンプリングまたはフィルター処理の前に適用されます。
- これにより、ソース行番号と呼ばれる新しいフィールドが作成され、フロー全体で維持されます。このフィールド名はローカライズされていませんが、いつでも名前を変更できます。
- この名前のフィールドが既に存在する場合、新しいフィールド名の数字が 1 ずつ増加します。たとえば、ソース行番号-1、ソース行番号-2 のようになります。
- フィールドのデータ型は以降のステップで変更できます。
- このフィールドは、フロー操作と計算で使用できます。
- この値は、インプット データが更新されるか、フローが実行されるたびに、データ セット全体に対して再生成されます。
- このフィールドは、インプット ユニオンでは使用できません。
ヘッダーとデータ開始行の設定
テキストファイル (.csv) は バージョン 2023.3 以降および Web 上の Tableau Prep Builder でサポートされ、Excel ファイル (.xls) はバージョン 2024.1 以降でサポートされています。
特定の行をフィールド ヘッダー行として設定したり、Excel およびテキスト (.csv) ファイルのデータの開始行を設定したりすることができます。
Excel ファイルまたはテキスト ファイルに接続する場合、一般的なシナリオでは、人間が判読できるように、ファイルの最初の数行にメタ情報が入力され、フォーマットされています。既定では、Tableau Prep は CSV ファイルの最初の行をフィールド ヘッダー行として解釈します。Excel ファイルは、フィールド タイプと空の行に基づいて解釈されます。Tableau Prep はヘッダーとして行を選択するか、ヘッダー行を含めないようにすることができます。
たとえば、次のファイルでは、STORE DETAILS がヘッダー行として解釈されます。
メタデータ情報 (1) を除外して、行 3 をヘッダー (2) として設定し、行 4 をデータの開始行として設定することで、データの正しいスキーマ構成を提示できます。
CSV ファイル:

Excel ファイル:

たとえば、以下は行のヘッダーと開始行の既定の設定を示しています。

以下は、メタデータが除外されたデータを示しています。

注: データのプレビューには、データ サンプル設定への変更は反映されません。
ヘッダーと開始行の設定
[データのプレビュー] の入力ビューを使用して、データのスキーマ構造を視覚的に検査し、ヘッダー行と開始行を設定して入力ソース データからメタデータを除外できます。
データの開始行は、ヘッダー行の値よりも大きい任意の値に設定できます。デフォルトでは、Tableau Prep はデータ開始行をヘッダー行の次の番号に設定します。ヘッダー行とデータ開始行の間の行は無視されます。
注: データ プレビューとデータ インタープリターは相互に排他的です。データ インタープリターは Excel スプレッドシートのサブ テーブルのみを検出します。テキスト ファイルとスプレッドシートの開始行の指定はサポートされていません。
- インプット ステップを選択します。
- ツールバーから、[データのプレビュー] の入力ビューをクリックします。
- ヘッダーとして設定する行で、[その他のオプション] メニューをクリックし、[ヘッダーとして設定] を選択します。
- データ開始行として設定する行で、[その他のオプション] メニューをクリックし、[データ開始として設定] を選択します。既定では、データ開始行は次の連続した行番号に設定されます。

[ヘッダー オプション] メニューには、ヘッダー行とデータ開始行の行番号が表示されます。必要に応じて、[ヘッダー オプション] ダイアログでヘッダーと開始行を直接設定できます。

単一ファイル内の複数のスキーマ
1 つのファイルに複数のデータ ソースが含まれている場合は、同じデータ ソースに接続して追加の入力ステップを作成し、2 つ目のデータ ソースのヘッダー行とデータ開始行を設定することができます。たとえば、以下のファイルには行番号 3 で始まるデータ ソース (1) と、行番号 28 で始まる別の 2 つ目のスキーマ (2) が含まれています。


このようなタイプのデータ ソースの場合は、次の手順に従います。
- 最初の入力ステップを選択します。
- ツールバーから、[データのプレビュー] の入力ビューをクリックします。
- ヘッダーとして設定する行で、[その他のオプション] メニューをクリックし、[ヘッダーとして設定] を選択します。
- データ開始行として設定する行で、[その他のオプション] メニューをクリックし、[データ開始として設定] を選択します。既定では、データ開始行は次の連続した行番号に設定されます。
- 次の入力ステップを選択します。
- 追加のデータ ソースのヘッダーと開始行を設定するには、上記のステップを繰り返します。
ヘッダー行とデータ開始行の間の行は無視されます。
複数のテーブルのユニオン
バージョン 2024.1 以降と Web 上の Tableau Prep Builder のテキスト (.csv) ファイルでサポートされています。
同じスキーマ構造とメタデータ行を持つデータ ソースから複数のテーブルをユニオンできます。
- ファイルに接続し、最初の入力ステップを選択します。
- ツールバーから、[データのプレビュー] の入力ビューをクリックします。
- ヘッダーとして設定する行で、[その他のオプション] メニューをクリックし、[ヘッダーとして設定] を選択します。
- データ開始行として設定する行で、[その他のオプション] メニューをクリックし、[データ開始として設定] を選択します。
- [テーブル] タブをクリックし、[複数のテーブルをユニオン] を選択します。
- [適用] をクリックしてファイルをユニオンし、入力ユニオン内のすべてのファイルのヘッダーと行の選択を維持します。これは、ユニオンされた入力ファイル全体のファイル構造とスキーマが同じであることを前提としています。

カスタム SQL クエリへの接続
データベースがカスタム SQL の使用をサポートしている場合、[接続] ペインの下あたりに [カスタム SQL] が表示されます。[カスタム SQL] をダブルクリックして [カスタム SQL] タブを開き、ここでクエリを入力してデータを事前選択したり、ソース固有の操作を使用することができます。クエリによりデータ セットを取得した後、データをフローに追加する前に、含めるフィールドの選択、フィルターの適用、データ型の変更を行うことができます。
![Tableau Prep フロー入力ステップの [カスタム SQL] タブ。データに接続するための SQL クエリを入力できます。](Img/prep_customSQL.png)
カスタム SQL の詳細については、カスタム SQL を使用したデータへの接続を参照してください。
インプット ステップでクリーニング操作を適用
一部のクリーニング操作のみインプット ステップで利用できます。以下の変更はいずれもインプット フィールド リストで行えます。変更内容は [変更内容] ペインで追跡され、注釈は [フロー] ペインのインプット ステップの左側とインプット フィールド リストに追加されます。
- フィールドを非表示: フィールドを削除するのではなく非表示にして、フローが混雑しないようにします。フィールドは、必要に応じていつでも再表示できます。非表示のフィールドは、フローを実行したときに出力に含まれたままとなります。
- フィルター: 計算エディターを使用して値をフィルタリングするか、バージョン 2023.1 以降では、[相対日付フィルター] ダイアログを使用して、日付フィールドや日付と時刻のフィールドの日付範囲をすばやく指定することもできます。
- フィールド名の変更:[フィールド名] フィールドで、フィールド名をダブルクリック (MacOS では Ctrl を押しながらクリック) し、新しいフィールド名を入力します。
- データ型の変更: フィールドのデータ型をクリックし、メニューから新しいデータ型を選択します。このオプションは現在、Microsoft Excel、テキスト、PDF ファイル、Box、Dropbox、Google ドライブ、および OneDrive のデータ ソースでサポートされています。他のすべてのデータ ソースは、クリーニング ステップで変更できます。
フローに含めるフィールドの選択
注: バージョン 2023.1 以降では、複数のフィールドを選択して非表示、再表示、削除、または含めることができます。以前のリリースでは、一度に 1 つのフィールドを操作して、チェック ボックスをオンまたはオフにして、フィールドを含めたり削除したりすることができました。
[入力] ペインにはデータ セットに含まれるフィールドのリストが表示されます。既定では、自動生成されたフィールドであるソース行番号を除くすべてのフィールドが含まれます。データのプレビューまたはリスト ビューを使用してフィールドを管理します。
- 検索: フィールドを検索します。
- フィールドを非表示にする: フロー出力に含めるが、クリーニングする必要がないフィールドを非表示にします。
- [フィールドのリスト] で、目のアイコン
 をクリックするか、[その他のオプション] メニューから [フィールドを非表示にする] を選択します。
をクリックするか、[その他のオプション] メニューから [フィールドを非表示にする] を選択します。 - データのプレビューで、[その他のオプション] メニューから [フィールドを非表示にする] を選択します。
フィールドは実行時にフローによって処理されます。必要なときはいつでも、フィールドを再表示することができます。詳細については、「フィールドの非表示(新しいウィンドウでリンクが開く)」を参照してください。
- [フィールドのリスト] で、目のアイコン
- フィールドを含める: 削除済みとしてマークされているフィールドをフローに追加します。
- [フィールドのリスト] で 1 つまたは複数の行を選択し、右クリック (MacOS では Cmd を押しながらクリック) するか、[その他のオプション] メニューから [フィールドを含める] を選択すると、削除済みとマークされたフィールドを再び追加することができます。
- [データのプレビュー] で、フローに含めるフィールドの [その他のオプション] メニューをクリックし、[フィールドを含める] を選択します。
- [フィールドのリスト] で 1 つまたは複数の行を選択し、右クリック (MacOS では Cmd を押しながらクリック) するか、[その他のオプション]
- フィールドを削除:
- [フィールドのリスト] で、1 つまたは複数の行を選択し、右クリック (MacOS では Cmd を押しながらクリック) して [X] をクリックするか、[その他のオプション] メニューから [フィールドを削除] を選択すると、フローに含めたくないフィールドを削除することができます。
- [データのプレビュー] で、削除するフィールドの [その他のオプション] メニューをクリックし、[フィールドを削除] を選択します。
- [フィールドのリスト] で、1 つまたは複数の行を選択し、右クリック (MacOS では Cmd を押しながらクリック) して [X] をクリックするか、[その他のオプション]
インプット ステップでのフィールドへのフィルターの適用
インプット ステップでフィルターを適用して、データ ソースから取り込むデータの量を減らします。フローを実行するときに処理したくないデータを除外することで、インタラクティブなパフォーマンス効率とより有用なデータ サンプルを得ることができます。
インプット ステップでは、計算エディターを使用してフィルターを適用できます。バージョン 2023.1 以降では、[相対日付フィルター] ダイアログを使用して、日付フィールド タイプと日付と時刻のフィールド タイプに含める値の正確な日付範囲を指定することもできます。詳細については、「データのフィルタリング(新しいウィンドウでリンクが開く)」の「相対日付フィルター」を参照してください。
クリーン二ング ステップやその他のタイプのステップでは、他のフィルター オプションを使用できます。詳細については、データのフィルタリング(新しいウィンドウでリンクが開く)を参照してください。
計算フィルターの適用
- ツールバーの [値のフィルター] をクリックします。以下のいずれかの方法を使用して、データをフィルターします。
[フィールドのリスト] で、フィールド名から [その他のオプション]
メニューをクリックし、[フィルター] > [計算...] の順に選択します。[データのプレビュー] で、[その他のオプション]
メニューをクリックし、[フィルター] > [計算...] の順に選択します。


-
計算エディターにフィルター条件を入力します。

相対日付フィルターの適用
- データ型が [日付] または [日付と時刻] であるフィールドを選択し、次のいずれかの方法を使用して、相対日付フィルターを適用します。
- [フィールドのリスト] で、右クリック (MacOS では Cmd を押しながらクリック) するか、フィールド名の列から [その他のオプション] メニューをクリックし、[フィルター] > [相対日付] の順にを選択します。
- [データのプレビュー] で、フィールドから [その他のオプション] メニューをクリックし、[フィルター] > [相対日付] の順に選択します。

- [フィールドのリスト] で、右クリック (MacOS では Cmd を押しながらクリック) するか、フィールド名の列から [その他のオプション]
-
[相対日付フィルター] ダイアログで、フローに含める年、四半期、月、週、または日の正確な範囲を指定します。また、特定の日付を基準とするアンカーを構成し、NULL 値を含めることもできます。
注: デフォルトでは、フィルターは、オーサリング エクスペリエンス内でフローが実行またはプレビューされた日付に関連して動作します。

フィールド名の変更
次のいずれかの方法を使用して、フィールドの名前を変更します。
フィールド グリッドとフロー ペインで、インプット ステップの左に注釈が追加されます。変更した内容は、[変更内容] ペインでも追跡されます。
- [フィールドのリスト] で、[フィールド名] 列からフィールドを選択し、[フィールド名を変更] をクリックします。フィールドに新しい名前を入力します。
- [データのプレビュー] でフィールドを選択し、[フィールド名を変更] をクリックします。フィールドに新しい名前を入力します。


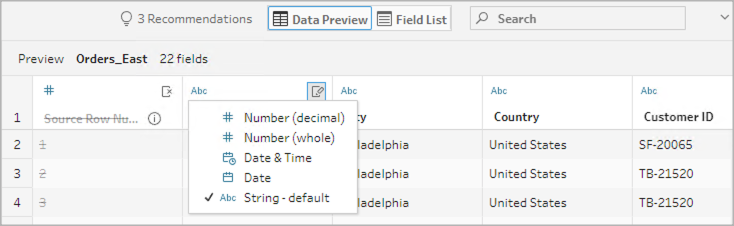
データ型の変更
現在、Microsoft Excel、テキスト、PDF ファイル、Box、Dropbox、Google ドライブ、および OneDrive のデータ ソースでサポートされています。他のすべてのデータ ソースは、クリーニング ステップで変更できます。
注: ソース行番号 (バージョン 2023.1 以降) のデータ型は、クリーニング ステップまたはその他のステップ タイプでのみ変更できます。
フィールドのデータ型を変更するには、次を実行します。
- フィールドのデータ型をクリックします。
- メニューから新しいデータ型を選択します。
- データのプレビュー:
- フィールドのビュー:

また、フローの他のステップ タイプでフィールドのデータ型を変更したり、データの役割を割り当ててフィールド値を検証できるようにしたりすることもできます。データ型を変更する方法やデータの役割を使用する方法の詳細については、データに割り当てられたデータ型の確認(新しいウィンドウでリンクが開く)およびデータの役割を使用したデータの検証(新しいウィンドウでリンクが開く)を参照してください。
フィールド プロパティの構成
テキスト ファイルを操作する際、[設定] タブが表示されます。ここでは、テキスト ファイルのフィールド区切りなど、テキストのプロパティを構成したり、接続を編集したりできます。[接続] ペインでファイル接続を編集したり、増分更新の設定を構成したりすることもできます。フローの増分更新を設定する方法については、増分更新を使用したフロー データの更新を参照してください。
テキスト ファイルまたは Excel ファイルを操作する際、フローを開始する前に誤って推測したデータ型を修正することもできます。データ型の変更は、フローの開始後に [プロファイル] ペインのその後のステップでいつでも行なえます。
テキスト ファイルのテキスト設定の構成
テキスト ファイルの解析に使用する設定を変更するには、以下のオプションから選択します。
-
最初の行にヘッダーが含まれます (既定): 最初の行をフィールド ラベルとして使用するには、このオプションを選択します。
-
フィールド名を自動に生成: Tableau Prep Builder でフィールド ヘッダーの自動生成を行う場合は、このオプションを選択します。フィールドの命名規則は、Tableau Desktop と同じモデルに従っています。F1、F2 などです。
-
フィールド区切り: 列の区切りに使用するリストから文字を選択します。カスタム文字を入力するには、[その他] を選択します。
-
テキスト修飾子: ファイルで値を囲む文字を選択します。
-
文字セット: テキスト ファイルのエンコードを記述する文字セットを選択します。
-
ロケール: ファイルの解析に使用するロケールを選択します。この設定は、使用する小数点および桁区切りを示します。
データ サンプルのサイズの設定
階層化された行選択は、Tableau Prep Builder バージョン 2023.3 以降でサポートされています。
Tableau Prep は、既定で、データ セットの代表的なサンプルのデータを効果的に探索して準備するために、必要となる最大行数を決定します。Tableau Prep のサンプル アルゴリズムに基づくと、入力データ内のフィールド数が増えるほど、許容される行数は少なくなります。
データがサンプリングされると、サンプルがどのように計算されて返されたかに応じて、結果のサンプルには必要な行がすべて含まれる場合もあれば、含まれない場合もあります。たとえば、デフォルトでは、Tableau Prep はクイック選択方式を使用してデータをサンプリングします。
この方式を使用して先頭の行がロードされると、データ セットが大きく、データが時系列に構成されている場合は、最も古いデータがサンプリングされて表示され、すべてのデータを代表したサンプルにはならない可能性があります。期待したデータが表示されない場合は、データ サンプル設定を変更し、再度クエリを実行できます。
Web 作成を使用してフローの作成や編集を行う場合、大きなデータ セットを使用するときにユーザーが選択できる最大行数は、Tableau Server 管理者によって設定されます。Tableau Cloud では、この制限は固定されており、管理者が変更することはできません。詳細については、Tableau Server(新しいウィンドウでリンクが開く) または Tableau Cloud(新しいウィンドウでリンクが開く) ヘルプの「サンプル データと処理の制限」を参照してください。
サンプリング用のデータの準備
分析に特定の値が必要ないことがわかっている場合は、入力ステップでそのフィールドを削除し、フローの作成時または実行時にそのデータが含まれないようにします。
サンプリングを行う大きなデータ セットの場合、入力ステップでフィールドを削除すると、Tableau Prep で読み込む行数が増加します。サンプリングを行わない場合、入力ステップでフィールドを削除すると、Tableau Prep で読み込むデータ量が減少します。
データセットから不要なフィールドと値を削除した後、サンプリングのために読み込むデータ量またはサンプル方式を変更できます。
データ サンプル設定の変更
サンプル データはインタラクティブなエクスペリエンスに役立ちます。すべてのデータをプロファイリングし、作業中に大きなデータ セットに変更を加えるのに比べ、フローの編集がより効率的になります。すべてのデータを使用するのは、フローを実行する時になります。サンプル セクションで加えた変更は、現在のフローに適用されます。
クリーニングとシェーピング後のデータを検証するには、フローを実行し、Tableau Desktop で出力を表示します。
注: 「Tableau Desktop でサンプルを表示」するのではなく、完全なフローを実行することにより、データ全体を確認できます。サンプルに含まれていない予期しない値や間違った値が表示された場合は、Tableau Prep に戻ってこれに対処できます。
- データセットから不要なフィールドと値を削除します。
- 入力ステップを選択し、「データ サンプル」タブをクリックします。

-
データ サンプリングのために読み込む行数を選択します。選択した行数はパフォーマンスに影響します。
- 自動: (デフォルト) データを迅速に読み込み、サンプルに十分なデータが得られるように行数を自動的に計算します。読み込まれる行数は、393,216 行以下です。
-
指定: 通常、データ構造の理解と、読み込み時間の短縮のために、少数の行を読み込むために使用します。百万行未満の行数を指定します。
注: Web 作成の場合、大きなデータ セットを使用するときにユーザーが選択できる最大行数は、Tableau Server 管理者によって設定されます。Tableau Cloud では、この制限は固定されており、管理者が変更することはできません。ユーザーは、その制限までの行数を選択できます。
- 最大: 可能な限り多くのデータが読み込まれるように、1,048,576 行以下の行数が選択されます。大きなデータ セットに対するハイパフォーマンス要件を満たしていることを確認してください。
-
サンプリングで返される行数に使用する方式を選択します。[ランダム] または [階層化] を選択すると、パフォーマンスに影響が出る可能性があります。
注: 行の選択は、入力データ ソースがランダム サンプリングをサポートしている場合にのみサポートされます。データ ソースがランダム サンプリングをサポートしていない場合は、既定の方法であるクイック選択が使用されます。
-
クイック選択: (デフォルト) 可能な限り迅速に行を返すため、パフォーマンスに基づいてデータをサンプリングします。一部の行はサンプルに含まれない場合があります。サンプリングに使用される行は、最初の N 行であるか、データベースが以前のクエリのメモリでキャッシュした行である可能性があります。この方式では、ほとんどの場合、ランダム サンプリングよりも速い結果が得られますが、偏ったサンプルが返される可能性があります (レコードが時系列に並べられている場合、データ内に存在するすべての年ではなく 1 年のみのデータなど)。
-
ランダム: 大きなデータ セットをサンプリングし、選択した行全体を一般的に代表するサンプルを返すことができます。Tableau Prep は、読み込んだすべての選択行に基づいてランダムな行を返します。このオプションは、データの初回取得時にパフォーマンスに影響する可能性があります。
- 階層化: 指定したフィールドでグループ化し、各サブグループ内のデータをサンプリングできます。Tableau Prep は、可能な限り均等にグループ化するために、選択したフィールド全体に分散して、要求された行数を返します。データ ソースによっては、フィールドのある値が他の値より多くの行を含む可能性があります。
-
例
これらの例は、Tableau Prep に含まれているグローバル世界指標のデータ セットに基づいています。最初の例では、行数として [自動] を使用し、サンプリング方式またはサンプリングで返す行数として [ランダム] を使用しています。

これらの値を設定して、ランダムに選択された 3 千行でデータ セット全体を表しています。

2 番目の例では、行数として [指定] を使用し、サンプリング方式として [階層化] を使用しています。行数の指定は値 7 に設定され、[出生率] フィールドがグループ化に使用されています。

新しいサンプル値は、すべてのフィールドにわたって統一された 7 行のユニークな値の分布を示しています。
![行数の指定は値 7 に設定され、[出生率] フィールドがグループ化に使用されています。](Img/prep_sample_stratified_example.png)