作業の保存と共有
2025 年 10 月 14 日以降、「Data Cloud」は「Data 360」というブランド名に変わりました。この変更の途上では、アプリケーションやドキュメントに「Data Cloud」と表示されることがあります。名前は新しいですが、機能と内容は変更されていません。
作業内容はフローのどの時点でも手動で保存することができます。または、Web 上でフローを作成または編集する際に Tableau で自動的に保存されるようにすることもできます。Web 上でフローを操作する場合、いくつかの相違点があります。
Web 上でのフローの作成の詳細については、Tableau Server(新しいウィンドウでリンクが開く) および Tableau Cloud(新しいウィンドウでリンクが開く) ヘルプの「Web 上の Tableau Prep」を参照してください。
| Tableau Prep Builder | Web 上の Tableau Prep |
|---|---|
|
|
データを最新の状態に保つために、フローを Tableau Prep Builder やコマンド ラインから手動で実行することができます。また、Tableau Server または Tableau Cloud でパブリッシュされたフローを手動で実行するか、スケジュールに従って実行することもできます。フローの実行について詳しくは、「Tableau Server または Tableau Cloud へのフローのパブリッシュ」を参照してください。
フローの保存
Tableau Prep Builder では、追加の操作を実行する前に、フローを保存して作業内容をバックアップできます。フローは Tableau Prep フロー (.tfl) ファイル形式で保存されます。
Tableau Desktop でワークブックをパッケージして共有するのと同様に、ローカル ファイル (Excel、テキスト ファイル、Tableau 抽出) をフローと一緒にパッケージして他のユーザーに共有することもできます。ローカル ファイルのみをフローと一緒にパッケージできます。データベース接続のデータなどは含まれません。
Web オーサリングでは、ローカルファイルは自動的にフローと一緒にパッケージ化されます。ファイルへの直接接続はまだサポートされていません。
パッケージド フローを保存すると、フローはパッケージド Tableau Flow ファイル (.tflx) として保存されます。
- フローを保存するには、トップ メニューから [ファイル] > [保存] を選択します。
- Tableau Prep Builder では、データ ファイルをフローと一緒にパッケージ化するには、トップ メニューから次のいずれかを実行します。
- [ファイル] > [パッケージド フローのエクスポート] を選択します。
- [ファイル] > [名前を付けて保存] を選択します。その後、[名前を付けて保存] ダイアログで、[種類を指定して保存] ドロップダウン メニューより [パッケージド Tableau Flow ファイル] を選択します。
Web 上でフローを自動的に保存する
Web 上でフローを作成または編集する場合、フローに変更を加えると (データ ソースに接続してステップを追加するなど)、その作業は数秒ごとに下書きとして保存されるため、作業が失われることはありません。
フローは現在サインインしているサーバーにのみ保存できます。1 つのサーバーでフローの下書きを作成して、別のサーバーに保存またはパブリッシュすることはできません。フローをサーバー上の別のプロジェクトにパブリッシュする場合は、[ファイル] > [Publish As (名前を付けてパブリッシュ)] オプションを使用して、ダイアログからプロジェクトを選択します。
フローの下書きは、パブリッシュしてサーバー上のプロジェクトにアクセスするパーミッションを持つすべてのユーザーが使用できるようになるまで、自分以外のユーザーには表示できません。ステータスが下書きになっているフローには、下書きのバッジが付けられているため、進行中のフローは簡単に見つけることができます。フローがパブリッシュされていない場合は、下書きのバッジの横の [Never Published (パブリッシュされていない)] バッジが表示されます。

フローをパブリッシュした後にフローを編集してもう一度パブリッシュすると、新しいバージョンが作成されます。[リビジョン履歴] ダイアログでフローのバージョンのリストを確認できます。[検索] ページで、![]() [アクション] メニューをクリックし、[リビジョン履歴] を選択します。
[アクション] メニューをクリックし、[リビジョン履歴] を選択します。
リビジョン履歴の管理の詳細については、Tableau Desktop ヘルプの「コンテンツのリビジョンの操作」(新しいウィンドウでリンクが開く)を参照してください。
注: 自動保存は既定で有効化されています。管理者がサイトで自動保存を無効にすることは可能ですが、推奨されてません。自動保存をオフにするには、Tableau Server REST API メソッドの「サイトの更新」を使用して、flowAutoSaveEnabled 属性を false に設定します。詳細については、「Tableau Server REST API サイトのメソッド: サイトの更新(新しいウィンドウでリンクが開く)」を参照してください。
ファイルの自動復元
既定では、Tableau Prep Builder でアプリケーションがフリーズまたはクラッシュした場合、開いているフローの下書きが自動的に保存されます。フローの下書きは マイ Tableau Prep リポジトリの [Recovered Flow (復元されたフロー)] フォルダーに保存されます。次回アプリケーションを開くと、ダイアログに復元されたフローの選択可能なリストが表示されます。復元されたフローを開いて中断した場所から続行するか、必要がない場合は復元されたフロー ファイルを削除することができます。
注: [Recovered Flow (復元されたフロー)] フォルダーの中にフローを復元した場合、このダイアログは、そのフォルダーが空になるまでアプリケーションを開くたびに表示されます。

この機能を有効にしたくない場合、管理者としてインストール中またはインストール後にオフにすることができます。この機能をオフにする方法については、Tableau Desktop および Tableau Prep の導入ガイドにある「ファイルの復元をオフにする(新しいウィンドウでリンクが開く)」を参照してください。
削除されたフローの復元
Tableau Cloud および Tableau Server バージョン 2025.3 以降の Tableau Prep Web 作成でサポートされています。
Web 作成では、以前に削除したフローをごみ箱から復元できます。ごみ箱がオンになっている場合、フローは完全に削除されたのではなく、一時的にごみ箱に移動しただけであるため、そこで復元するか、完全に削除できます。下書き状態のフローは、引き続き完全に削除されます。ごみ箱の詳細については「ごみ箱(新しいウィンドウでリンクが開く)」を参照してください。
注: この機能は、Tableau Prep Builder では利用できません。
この機能を使用するには、以下が必要です。
-
パーミッション: サイト管理者、サーバー管理者、Creator、または Explorer (パブリッシュ可能) のロールが割り当てられている必要があります。
-
サイト設定: サイトのごみ箱をオンにします
-
フローのステータス: フローをパブリッシュする必要があります。
ごみ箱の中のフローを保存する期間は、管理者によって設定されます。
フローの復元
-
ホーム ページからサイド ペインを展開し、[ごみ箱] を選択します。
-
[ごみ箱] ページで、[コンテンツ タイプ] ドロップダウン メニューから [フロー] を選択します。

-
復元するフローの [その他のアクション] メニューを選択し、[復元] を選択します。
![削除したフローを復元する際に、ごみ箱ページに表示されるフローの [その他のアクション] メニュー。](Img/prep_recycle_bin_restore_menu.png)
-
復元場所としてプロジェクトを選択します。

-
[復元] を選択します。
Tableau Desktop でフロー出力を表示する
注: このオプションは Web 上では使用できません。
データのクリーニングを行う際に、進捗を Tableau Desktop で表示して確認したいと思うことがあるかもしれません。Tableau Desktop でフローを開くと、Tableau Prep Builder が永続的な Tableau .hyper ファイルと Tableau データ ソース (.tds) ファイルを作成します。ファイルは Tableau リポジトリのデータ ソース ファイルに保存されるので、いつでもデータを試すことができます。
Tableau Desktop でフローを開くと、選択したステップまで、操作が適用された状態のフローの作業中のデータ サンプルが表示されます。
注: データを試すことはできますが、Tableau ではデータのサンプルのみが表示されるため、ワークブックをパッケージ化されたワークブック (.twbx) として保存することはできません。Tableau でデータを操作する準備ができたら、フローの出力ステップを作成して出力をファイルに保存するか、パブリッシュされたデータ ソースとして保存してから、Tableau の完全なデータ ソースに接続します。
Tableau Desktop でデータ サンプルを表示するには、次の手順を実行します。
- データを表示するステップを右クリックし、コンテキスト メニュ-から [Tableau Desktop でプレビュー] を選択します。

- Tableau Desktop が [シート] タブで開きます。
データ抽出ファイルとパブリッシュされたデータ ソースを作成する
フロー出力を生成するには、フローを実行します。フローを実行すると、変更内容がデータ セット全体に適用されます。フローを実行すると、Tableau データ ソース (.tds) および Tableau データ抽出 (.hyper) ファイルが作成されます。
注: 空間データを含むフローは、.hyper ファイルのみに、またはパブリッシュされたデータ ソースとしてのみ出力できます。その他の出力タイプは現在、サポートされていません。空間データの操作の詳細については、「空間計算と結合の作成(新しいウィンドウでリンクが開く)」を参照してください。
Tableau Prep Builder
フロー出力から抽出ファイルを作成して、Tableau Desktop で使用したり、データをサード パーティに共有したりできます。抽出ファイルは以下の形式で作成できます。
- ハイパー抽出 (.hyper): これは Tableau 抽出ファイルの最新のタイプです。
- コンマ区切り値 (.csv): データをサード パーティと共有するには、抽出を .csv ファイルに保存します。エクスポートされた CSV ファイルは、BOM 付きの UTF-8 でエンコードされます。
- Microsoft Excel (.xlsx): Microsoft Excel スプレッドシートです。
Web 上での Tableau Prep Builder
フロー出力を、パブリッシュされたデータ ソースまたはデータベースへの出力としてパブリッシュします。
- フロー出力をデータ ソースとして Tableau Server または Tableau Cloud に保存して、データを共有し、クリーニング、加工、および結合したデータへの一元的なアクセスを提供します。
- フロー出力をデータベースに保存して、クリーニングおよび準備されたフロー データを含むテーブル データを作成、置換、または追加します。詳細については、「フロー出力データを外部データベースに保存する」を参照してください。
フローを実行するときに増分更新を使用して、フル データ セットではなく新しいデータのみを更新することによって、時間とリソースを節約します。増分更新を使用して、フローを構成して実行する方法について詳しくは、「増分更新を使用したフロー データの更新」を参照してください。
注: Tableau Prep Builder の出力を Tableau Server にパブリッシュするには、Tableau Server REST API を有効にする必要があります。詳しくは、Tableau Rest API ヘルプの「REST API の要件 (英語)(新しいウィンドウでリンクが開く)」を参照してください。セキュア ソケット レイヤー (SSL) 暗号化証明書を使用するサーバーにパブリッシュするには、Tableau Prep Builder を実行しているマシンで追加構成ステップが必要です。詳しくは、Tableau Desktop および Tableau Prep Builder 導入ガイドの「インストールの前に(新しいウィンドウでリンクが開く)」を参照してください。
フロー出力にパラメーターを含める
バージョン 2021.4 以降の Tableau Prep Builder および Web 上でサポートされています
フロー出力ファイル名、パス、テーブル名、またはカスタム SQL スクリプト (バージョン 2022.1.1 以降) にパラメーター値を含めて、さまざまなデータ セットのフローを簡単に実行できるようにします。詳細については、「フローでパラメーターを作成して使用する」を参照してください。
抽出ファイルを作成する
注: この出力オプションは、Web 上でフローを作成または編集する場合は使用できません。
- ステップでプラス アイコン
 をクリックし、[出力の追加] を選択します。
をクリックし、[出力の追加] を選択します。以前にフローを実行したことがある場合は、出力ステップでフローの実行
![右向き矢印として表示される [フローの実行] ボタン。](Img/prep_run_flow.png) ボタンをクリックします。そうすると、フローが実行され、出力が更新されます。
ボタンをクリックします。そうすると、フローが実行され、出力が更新されます。[出力] ペインが開き、データのスナップショットが表示されます。

- 左側のペインで、[Save output to (出力の保存先)] ドロップダウン リストから [ファイル] を選択します。以前のバージョンで [ファイルに保存] を選択します。
- [参照] ボタンをクリックし、[名前を付けて抽出を保存] ダイアログでファイル名を入力して [許可] をクリックします。
- [Output type (出力タイプ)] フィールドで、次の出力タイプから選択します。
- Tableau データ抽出 (.hyper)
- コンマ区切り値 (.csv)
-
(Tableau Prep Builder) [書き込みオプション] セクションで、既定の書き込みオプションを表示して、新しいデータをファイルに書き込み、必要に応じて変更します。詳細については、書き込みオプションの構成を参照してください。
- [テーブルの作成]: このオプションでは、新しいテーブルが作成されるか、既存のテーブルが新しい出力に置き換えられます。
- [テーブルに追加]: このオプションでは、既存のテーブルに新しいデータが追加されます。テーブルが存在しない場合は、新しいテーブルが作成され、以降の実行でこのテーブルに新しい行が追加されます。
注: [テーブルに追加] では、.csv の出力タイプには対応していません。対応している更新の組み合わせの詳細については、フロー更新オプションを参照してください。
- [フローの実行] をクリックしてフローを実行し、抽出ファイルを生成します。
Microsoft Excel ワークシートへの抽出を作成する
Tableau Prep Builder バージョン 2021.1.2 以降でサポートされています。この出力オプションは、Web 上でフローを作成または編集する場合、または空間データを含むフローの出力を作成する場合は使用できません。
フロー データを Microsoft Excel ワークシートに出力するには、新しいワークシートを作成するか、既存のワークシートにデータを追加・置換できます。以下の条件が適用されます。
- 対応しているファイル形式は Microsoft Excel .xlsx のみです。
- ワークシートの行はセル A1 から始まります。
- データを追加したり置換する場合、最初の行はヘッダーと見なされます。
- ヘッダー名は、新しいワークシートを作成するときに追加されますが、既存のワークシートにデータを追加する場合は追加されません。
- 既存のワークシートの書式や式は、フロー出力に適用されません。
- 名前付きのテーブルや範囲への書き込みは、現在対応していません。
- 増分更新は現在サポートされていません。
Microsoft Excel ワークシート ファイルにフロー データを出力する
- ステップでプラス アイコン をクリックし、[出力の追加] を選択します。
以前にフローを実行したことがある場合は、出力ステップでフローの実行
ボタンをクリックします。そうすると、フローが実行され、出力が更新されます。[出力] ペインが開き、データのスナップショットが表示されます。

- 左側のペインで、[Save output to (出力の保存先)] ドロップダウン リストから [ファイル] を選択します。
- [参照] ボタンをクリックし、[名前を付けて抽出を保存] ダイアログでファイル名を入力するか選択して、[許可] をクリックします。
- [Output type (出力タイプ)] フィールドで [Microsoft Excel (.xlsx)] を選択します。

- [ワークシート] フィールドで、結果を書き込むワークシートを選択するか、フィールドに新しい名前を入力して、[新しいテーブルの作成] をクリックします。
- [書き込みオプション] セクションで、次のいずれかのオプションを選択します。
- テーブルの作成: フロー データが含まれるワークシートを作成するか、ファイルが既に存在する場合は再作成します。
- テーブルに追加: 既存のワークシートに新しい行を追加します。ワークシートが存在しない場合は、ワークシートが作成され、フローの実行時にそのワークシートに行が追加されます。
- データの置換: 既存のワークシートの最初の行を除く既存のデータをすべてフローのデータに置き換えます。
ワークシートが既に存在する場合、フィールドの比較には、ワークシート内のフィールドと一致するフローのフィールドが表示されます。新規のワークシートの場合は、1 対 1 のフィールド一致が表示されます。一致しないフィールドは無視されます。

- [フローの実行] をクリックしてフローを実行し、Microsoft Excel 抽出ファイルを生成します。
パブリッシュされたデータ ソースを作成する
- ステップでプラス アイコン をクリックし、[出力の追加] を選択します。
注: Tableau Prep Builder では、以前パブリッシュされたデータ ソースが更新され、データ ソースに含まれている可能性のあるデータ モデリング (計算フィールドや番号書式など) が維持されます。データ ソースを更新できない場合は、代わりにデータ モデリングを含むデータ ソースが置き換えられます。
- [出力] ペインが開き、データのスナップショットが表示されます。
![[出力の保存先] フィールドは [パブリッシュ済みのデータ ソース] に設定されています。データの表が表示されています。](Img/prep_publishasdatasource2.png)
- [Save output to (出力の保存先)] ドロップダウン リストから [パブリッシュされたデータ ソース] (以前のバージョンの [データ ソースとしてパブリッシュ]) を選択します。次のフィールドを完了します。
- サーバー(Tableau Prep Builder のみ): データ ソースとデータ抽出のパブリッシュを行うサーバーを選択します。サーバーにサインインしていない場合は、サインインするよう求められます。
注: Tableau Prep Builder バージョン 2020.1.4 以降では、ユーザーがサーバーにサインインした後、アプリケーションを閉じるときに、Tableau Prep Builder によりサーバー名と認証資格情報が記憶されます。次回アプリケーションを開くと、既にサーバーにサインインしています。
Mac では、Tableau Prep Builder が SSL 証明書を安全に使用して Tableau Server や Tableau Cloud 環境に接続できるよう、Mac キーチェーンへのアクセスを提供するよう求められることがあります。
Tableau Cloud に出力している場合は、サイトがホストされているポッドを「serverUrl」に含める必要があります。たとえば、「https://online.tableau.com」ではなく「https://eu-west-1a.online.tableau.com」となります。
- プロジェクト: データ ソースと抽出を読み込むプロジェクトを選択します。
- 名前: ファイル名を入力します。
- 説明: データ ソースの説明を入力します。
- サーバー(Tableau Prep Builder のみ): データ ソースとデータ抽出のパブリッシュを行うサーバーを選択します。サーバーにサインインしていない場合は、サインインするよう求められます。
- (Tableau Prep Builder) [書き込みオプション] セクションで、既定の書き込みオプションを表示して、新しいデータをファイルに書き込み、必要に応じて変更します。詳しくは、「書き込みオプションの構成」を参照してください。
- [テーブルの作成]: このオプションでは、新しいテーブルが作成されるか、既存のテーブルが新しい出力に置き換えられます。
- [テーブルに追加]: このオプションでは、既存のテーブルに新しいデータが追加されます。テーブルが存在しない場合は、新しいテーブルが作成され、以降の実行でこのテーブルに新しい行が追加されます。
- [フローの実行] をクリックしてフローを実行し、データ ソースをパブリッシュします。
フロー出力データを外部データベースに保存する
この出力オプションは、空間データを含むフローの出力を作成する場合は使用できません。
重要: この機能を使用すると、外部データベースのデータを完全に削除したり、置き換えたりできます。データベースに書き込むためのパーミッションがあることを確認してください。
データの損失を防ぐために、[カスタム SQL] オプションを使用してテーブル データのコピーを作成し、フロー データをテーブルに書き込む前にコピーを実行できます。
Tableau Prep Builder または Web でサポートされているコネクタからデータに接続して、外部データベースにデータを出力できます。これにより、フローが実行されるたびに、フローのクリーニングされた準備済みのデータを使用して、データベース内のデータを追加または更新できます。この機能は、特に明記されていない限り、増分更新と完全更新の両方のオプションで使用できます。増分更新を構成する方法について詳しくは、増分更新を使用したフロー データの更新を参照してください。
フロー出力を外部データベースに保存すると、Tableau Prep は次の処理を実行します。
- 行を生成し、データベースに対して SQL コマンドを実行します。
- 出力データベースの一時テーブル (または Snowflake に出力する場合はステージング領域) にデータを書き込みます。
- 操作が成功すると、データは一時テーブル (または Snowflake のステージング領域) から宛先テーブルに移動されます。
- ユーザーがデータをデータベースに書き込んだ後に実行する必要のある SQL コマンドを実行します。
SQL スクリプトが失敗すると、フローは失敗します。ただし、データはデータベース テーブルに引き続き読み込まれます。フローの実行をもう一度やり直すか、データベースで SQL スクリプトを手動で実行して適用することができます。
出力オプション
データベースにデータを書き込むときに、次のオプションを選択できます。テーブルがまだ存在しない場合は、フローが最初に実行されるときにテーブルが作成されます。
- [テーブルに追加]: このオプションでは、既存のテーブルにデータが追加されます。テーブルが存在しない場合、フローが最初に実行されるときにテーブルが作成され、後続のフローが実行されるたびにそのテーブルにデータが追加されます。
- [テーブルの作成]: このオプションでは、フローのデータで新しいテーブルが作成されます。テーブルが既に存在する場合、テーブルと、テーブルに定義されている既存のデータ構造またはプロパティは削除され、フロー データ構造を使用する新しいテーブルに置き換えられます。フローに存在するフィールドは、新しいデータベース テーブルに追加されます。
- [データの置換]: このオプションでは、既存のテーブルのデータが削除され、フローのデータに置き換えられますが、データベース テーブルの構造とプロパティは保持されます。テーブルが存在しない場合、フローが最初に実行されるときにテーブルが作成され、後続のフローが実行されるたびにテーブル データが置き換えられます。
その他のオプション
書き込みオプションに加えて、カスタム SQL スクリプトを含めるか、データベースに新しいテーブルを追加できます。
- カスタム SQL スクリプト: カスタム SQL を入力し、データがデータベース テーブルに書き込まれる前、後、または前後にスクリプトを実行するかどうかを選択します。これらのスクリプトを使用して、フロー データがテーブルに書き込まれる前にデータベース テーブルのコピーを作成したり、インデックスを追加したり、他のテーブル プロパティを追加したりできます。
注: バージョン 2022.1.1 以降では、SQL スクリプトにパラメーターを挿入することもできます。詳細については、「出力ステップへのユーザー パラメーターの適用」を参照してください。
- [新しいテーブルの追加]: 既存のテーブル リストからテーブルを選択するのではなく、一意の名前を持つ新しいテーブルをデータベースに追加します。既定のスキーマ (Microsoft SQL Server と PostgreSQL) 以外のスキーマを適用する場合は、構文
[schema name].[table name]を使用してスキーマを指定できます。
サポートされるデータベースとデータベース要件
Tableau Prepでは、選択した数のデータベースのテーブルへのフロー データの書き込みをサポートしています。Tableau Cloud のスケジュールに従って実行されるフローは、クラウドでホストされている場合にのみ、これらのデータベースに書き込むことができます。
バージョン 2025.1 以降では、オンプレミスのデータ ソースに接続する場合、Tableau Bridge クライアントを使用して Tableau Cloud のデータに接続し、データを更新できます。そうするには、Bridge クライアント プールに Tableau Bridge クライアントが構成されていて、ドメインがプライベート ネットワーク許可リストに追加されている必要があります。Tableau Prep Builder および Web 上でデータ ソースに接続するときは、サーバー URL が Bridge プール内のドメインと一致していることを確認してください。詳細については、「Tableau Prep Builder からフローをパブリッシュする(新しいウィンドウでリンクが開く)」の Tableu Cloud セクションの「データベース」を参照してください。
一部のデータベースには、データの制限や要件があります。Tableau Prep では、ピーク パフォーマンスを維持するため、サポートされているデータベースにデータを書き込む際に、いくつかの制限が設けられる場合があります。次の表に、フロー データを保存できるデータベースと、データベースの制限または要件を示します。これらの要件を満たさないデータを使用すると、フローの実行時にエラーが発生する可能性があります。
注: フィールドの文字数制限の設定はまだサポートされていません。ただし、文字制限の制約を含むテーブルをデータベースに作成し、[データの置換] オプションを使用して、データベース内のテーブル構造を維持したまま、データを置き換えることができます。
| データベース | 要件または制限 |
|---|---|
| Amazon Redshift |
|
| Amazon S3 (出力のみ) | 「フロー出力データを Amazon S3 に保存する」を参照してください |
| Databricks |
|
| Google BigQuery |
|
| Microsoft SQL Server |
|
| MySQL |
|
| Oracle |
|
| Pivotal Greenplum Database |
|
| PostgreSQL |
|
| SAP HANA |
|
| Snowflake |
|
| Teradata |
|
| Vertica |
|
フロー データをデータベースに保存する
注: データベースの認証資格情報は、フローをパブリッシュするときに埋め込むことができます。認証資格情報の埋め込みの詳細については、Tableau Prep Builder からフローをパブリッシュするの「データベース」セクションを参照してください。
- ステップでプラス アイコン をクリックし、[出力の追加] を選択します。
- [出力の保存先] ドロップダウン リストから、[データベースとクラウド ストレージ] を選択します。
- [設定]タブで、次の情報を入力します。
- [接続] ドロップダウン リストで、フロー出力の書き込みに使用するデータベース コネクタを選択します。サポートされているコネクタのみが表示されます。これらのコネクタは、フロー入力に使用したコネクタと同じコネクタか、別のコネクタです。別のコネクタを選択すると、サインインを求めるメッセージが表示されます。
重要: 選択したデータベースへの書き込みパーミッションがあることを確認してください。パーミッションがないと、フローでデータが部分的にしか処理されない可能性があります。
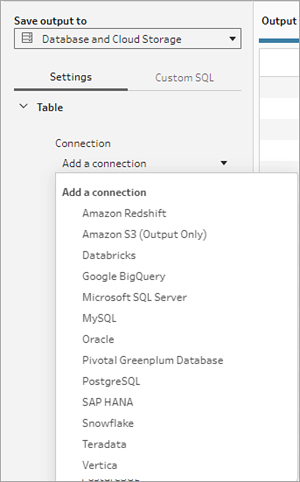
- [データベース] ドロップダウン リストで、フローの出力データを保存するデータベースを選択します。スキーマまたはデータベースには、ドロップダウン リストに表示されるテーブルが少なくとも 1 つ含まれている必要があります。
- [テーブル] ドロップダウン リストで、フローの出力データを保存するテーブルを選択します。選択した書き込みオプションに応じて、新しいテーブルが作成されたり、フロー データによってテーブル内の既存のデータが置き換えられたり、フロー データが既存のテーブルに追加されたりします。
データベースに新しいテーブルを作成するには、フィールドに一意のテーブル名を入力し、[新しいテーブルの作成] をクリックします。選択した書き込みオプションに関係なく、フローを初めて実行すると、フローと同じスキーマを使用してデータベースにテーブルが作成されます。
![[出力先の保存] ダイアログ。](Img/prep_wtdb3.png)
- [接続] ドロップダウン リストで、フロー出力の書き込みに使用するデータベース コネクタを選択します。サポートされているコネクタのみが表示されます。これらのコネクタは、フロー入力に使用したコネクタと同じコネクタか、別のコネクタです。別のコネクタを選択すると、サインインを求めるメッセージが表示されます。
- [出力] ペインには、データのスナップショットが表示されます。フィールドの比較には、テーブル内のフィールドと一致する、フローのフィールドが表示されます (テーブルが既に存在する場合)。テーブルが新規の場合は、1 対 1 のフィールド一致が表示されます。

フィールドの不一致がある場合は、ステータス メモにエラーが表示されます。
- [一致なし: フィールドは無視されます]: フィールドはフロー内に存在しますが、データベースには存在しません。[テーブルの作成] 書き込みオプションを選択して完全更新を実行しない限り、フィールドはデータベース テーブルに追加されません。完全更新を実行すると、フローのフィールドがデータベース テーブルに追加され、フロー出力スキーマが使用されます。
- [一致なし: フィールドに Null 値が含まれます]: フィールドはデータベースに存在しますが、フローには存在しません。フローは、フィールドがあるデータベース テーブルに Null 値を渡します。フローにフィールドが存在するが、フィールド名が異なるため、フィールドが一致しない場合は、クリーニング ステップに移動し、データベースのフィールド名と一致するようにフィールド名を編集できます。フィールド名を編集する方法について詳しくは、「クリーニング操作の適用」を参照してください。
- [エラー: フィールドのデータ型が一致しません]: フローのフィールドと、出力の書き込み先のデータベース テーブルのフィールドに割り当てられるデータ型が一致する必要があります。一致しない場合、フローの実行に失敗します。クリーニング ステップに移動し、フィールドのデータ型を編集すると、この不一致を修正できます。データ型の変更について詳しくは、「データに割り当てられたデータ型の確認」を参照してください。
- 書き込みオプションを選択します。完全更新用と増分更新用に別のオプションを選択できます。フロー実行方法を選択するとオプションが適用されます。増分更新を使用したフローの実行について詳しくは、「増分更新を使用したフロー データの更新」を参照してください。
- [テーブルに追加]: このオプションでは、既存のテーブルにデータが追加されます。テーブルが存在しない場合、フローが最初に実行されるときにテーブルが作成され、後続のフローが実行されるたびにそのテーブルにデータが追加されます。
- [テーブルの作成]: このオプションでは、新しいテーブルが作成されます。同じ名前のテーブルが既に存在する場合は、既存のテーブルが削除され、新しいテーブルに置き換えられます。テーブルに定義されている既存のデータ構造やプロパティも削除され、フロー データ構造に置き換えられます。フローに存在するフィールドは、新しいデータベース テーブルに追加されます。
- [データの置換]: このオプションでは、既存のテーブルのデータが削除され、フローのデータに置き換えられますが、データベース テーブルの構造とプロパティは保持されます。
- (オプション) [カスタム SQL] タブをクリックし、SQL スクリプトを入力します。データがテーブルに書き込まれる [Before (前)]と [After (後)] に、実行するスクリプトを入力できます。

- [フローの実行] をクリックしてフローを実行し、選択したデータベースにデータを書き込みます。
フロー出力データを CRM Analytics のデータセットに保存する
バージョン 2022.3 以降の Tableau Prep Builder および Web 上でサポートされています。
注: CRM Analytics には、外部ソースからのデータを統合する際にいくつかの要件と制限があります。フロー出力を CRM Analytics に正常に書き込めるようにするには、Salesforce ヘルプの「データをデータセットに統合する前の考慮事項」(新しいウィンドウでリンクが開く)を参照してください。
Tableau Prep を使用してデータをクリーニングし、CRM Analytics で取得する予測結果を向上させます。まず、Web で Tableau Prep Builder または Tableau Prep がサポートしているコネクタからデータに接続します。次に、変換を適用してデータをクリーニングし、フロー データをアクセス権がある CRM Analytics のデータセットに直接出力します。
CRM Analytics にデータを出力するフローは、コマンド ライン インターフェイスを使用して実行できません。Tableau Prep Builder を使用するか、Tableau Prep Conductor で Web 上のスケジュールを使用すると、フローを手動で実行することができます。
前提条件
フロー データを CRM Analytics に出力するには、Salesforce と Tableau の次のライセンス、アクセス権、パーミッションがある必要があります。
Salesforce の要件
| 要件 | 説明 |
|---|---|
| Salesforce 権限 |
CRM Analytics Plus または CRM Analytics Growth ライセンスのいずれかに割り当てられている必要があります。 CRM Analytics Plus ライセンスには、次の権限セットが含まれています。
CRM Analytics Growth ライセンスには、次の権限セットが含まれています。
詳細については、Salesforce ヘルプの「CRM Analytics ライセンスと権限セットの詳細(新しいウィンドウでリンクが開く)」、および「ユーザー権限セットの選択および割り当て(新しいウィンドウでリンクが開く)」を参照してください。 |
|
管理者設定 |
Salesforce 管理者は、次の構成を行う必要があります。
|
Tableau Prep の要件
| 要件 | 説明 |
|---|---|
|
Tableau Prep のライセンスとパーミッション |
Creator のライセンス アプリとデータセットを選択してフロー データを出力する前に、Salesforce 組織アカウントに Creator としてサインインして認証を受ける必要があります。 |
|
OAuth データ接続 |
サーバー管理者として、コネクタの OAuth クライアント ID とシークレットを使用して Tableau Server を構成する必要があります。この操作は、Tableau Server でフローを実行するために必要です。 詳細については、Tableau Server ヘルプの「Salesforce.com OAuth 用に Tableau Server を構成する(新しいウィンドウでリンクが開く)」を参照してください。 |
フロー データを CRM Analytics に保存する
Tableau Prep Builder から CRM Analytics へ保存する場合、次の CRM Analytics 入力制限が適用されます。
- アップロードする外部データの最大ファイル サイズ: 40 GB
- 24 時間のローリング期間内にアップロードする全外部データの最大ファイル サイズ: 50 GB
- ステップでプラス アイコン をクリックし、[出力の追加] を選択します。
- [Save output to (出力の保存先)] ドロップダウン リストから [CRM Analytics] を選択します。
![[接続] のドロップダウンが展開されたデータセット保存オプション。](Img/prep_output_crma_signin.png)
- [データセット] セクションで、Salesforce に接続します。
Salesforce にサインインし、[Allow (許可)] をクリックして、CRM Analytics アプリとデータセットに Tableau アクセスを付与するか、既存の Salesforce 接続を選択します。
- [名前] フィールドで、既存のデータ セット名を選択します。これにより、データ セットが上書きされて、フロー出力に置き換えられます。そうしない場合は、新しい名前を入力し、[Create new dataset (新しいデータセットの作成)] をクリックして、選択した CRM Analytics アプリのデータセットを作成します。
注: データ セット名は 80 文字以内にする必要があります。

- [名前] フィールドの下で、表示されたアプリが、書き込みパーミッションがあるアプリであることを確認します。
アプリを変更するには、[Browse Datasets (データセットの参照)] をクリックして、リストからアプリを選択し、[名前] フィールドにデータセット名を入力して、[Accept (許可)] をクリックします。
![データ セットのリストを表示する [データセットの選択] ダイアログ ボックス。](Img/prep_output_crma_dataset_app.png)
- [書き込みオプション] セクションでは、サポートされているオプションは [完全更新] と [テーブルの作成] だけです。
- [フローの実行] をクリックしてフローを実行し、CRM Analytics データセットにデータを書き込みます。
フローの実行に成功したら、データ マネージャーの [Monitor (監視)] タブにある CRM Analytics の出力結果を確認できます。この機能の詳細については、Salesforce ヘルプの「外部データアップロードの監視(新しいウィンドウでリンクが開く)」を参照してください。
フロー出力データを Data Cloud に保存する
バージョン 2023.3 以降の Tableau Prep Builder および Web 上でサポートされています。
Tableau Prep でデータを準備してから、Data Cloud でデータと既存のデータ セットを関連付けます。Web 上で Tableau Prep Builder または Tableau Prep がサポートしているコネクタを使用して、データをインポートし、データのクリーニングと準備を行ってから、取り込み API を使用して、フロー データを Data Cloud に直接出力します。
権限の前提条件
|
Salesforce のライセンス |
Data Cloud エディションとアドオン ライセンスの詳細については、Salesforce ヘルプの「Data Cloud Standard Editions and Licenses」を参照してください。 また、「Data Cloud の制限とガイドライン」も参照してください。 |
| データ スペースの権限 |
ユーザーはデータ スペースに割り当てられていることに加えて、Data Cloud で次のいずれかの権限セットに割り当てられている必要があります。
詳細については、「データ スペースの管理(新しいウィンドウでリンクが開く)」と「従来の権限セットを使用したデータ スペースの管理(新しいウィンドウでリンクが開く)」を参照してください。 |
|
Data Cloud への取り込み権限 |
Data Cloud への取り込みの項目アクセスのために、次のコネクタに割り当てられている必要があります。
詳細は、「Enable Object and Field Permissions」を参照してください。 |
| Salesforce プロファイル |
以下のために、プロファイルのアクセス権を有効にします。
|
| Tableau Prep のライセンスとパーミッション | Creator のライセンスアプリとデータ セットを選択してフロー データを出力する前に、Salesforce 組織アカウントに Creator としてサインインして認証を受ける必要があります。 |
フロー データを Data Cloud に保存する
取り込み API をすでに使用していて、この API を手動で呼び出してデータ セットを Data Cloud に保存している場合は、Tableau Prep を使用してワークフローを簡素化することができます。前提条件となる構成は、Tableau Prep の場合と同じです。
Data Cloud にデータを初めて保存する場合は、「Data Cloud の設定前提条件」の設定要件に従ってください。
- ステップでプラス アイコン をクリックし、[出力の追加] を選択します。
- [Save output to (出力の保存先)] ドロップダウン リストから [Salesforce Data Cloud] を選択します。
- [オブジェクト] セクションから、サインインする [Salesforce Data Cloud 組織] を選択します。

- [Salesforce Data Cloud] メニューで、[サインイン] をクリックします。
- 自分のユーザー名とパスワードを使用して、Data Cloud 組織にサインインします。
- [アクセスを許可] フォームで、[許可] をクリックします。
- [Save output to (出力の保存先)] セクションで、取り込み API コネクタとオブジェクト名を入力します。
- 取り込み API コネクタ名とオブジェクト名を見つけるには、次の手順を実行します。
Salesforce Data Cloud にログインし、[Data Cloud の設定] に移動します。
![Salesforce 組織の設定メニューに表示されている [Data Cloud の設定] メニュー オプション。](Img/prep_wtdb_DC_setup.png)
クイック検索ボックスに「取り込み API」と入力し、結果から [取り込み API] を選択します。
![Salesforce 組織の [Data Cloud の設定] のクイック検索メニューに表示されている [取り込み API] メニュー オプション。](Img/prep_wtdb_DC_Ingestion_API_menu.png)
[取り込み API] ページでは、[コネクタ名] の下に利用可能なコネクタのリストが表示されます。
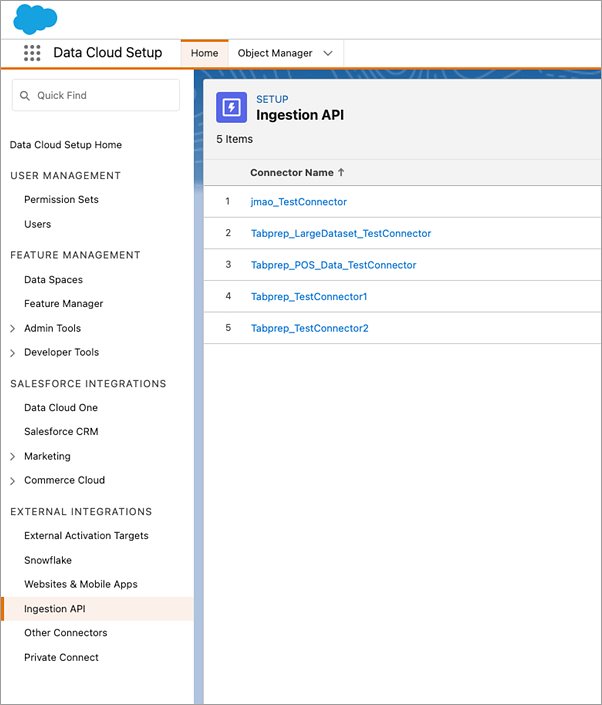
使用するコネクタの対応するオブジェクト名を見つけるには、リストにあるコネクタを選択します。[Connector Details (コネクタの詳細)] ページの [スキーマ] セクションで、[オブジェクト名] の下に対応するオブジェクトのリストが表示されます。
![Salesforce Data Cloud 取り込み API の [Connector Details (コネクタの詳細)] ページに表示されている、コネクタの対応するオブジェクト。](Img/prep_wtdb_DC_Ingestion_API_Connectors_Object.png)
- [書き込みオプション] セクションでは、指定された値がテーブルにすでに存在する場合は既存の行が更新され、指定された値が存在しない場合は新しい行が挿入されることが示されます。
- [フローの実行] をクリックしてフローを実行し、Data Cloud にデータを書き込みます。
- データス トリームの実行ステータスとデータ エクスプローラのオブジェクトを表示して、Data Cloud のデータを検証します。

ブラウザ ウィンドウで https://login.salesforce.com/ が開きます。

![Data Cloud にサインインするときに表示される [アクセス許可] フォーム。](Img/prep_saveDC_allow.png)

考慮事項
- 一度に 1 つのフローを実行できます。別の出力保存を実行する前に、Data Cloud でフローの実行を完了する必要があります。
- Data Cloud にフローを保存するには、しばらく時間がかかる場合があります。Data Cloud でステータスをチェックしてください。
- データは、Upsert 関数を使用して Data Cloud に保存されます。ファイル内のレコードが既存のレコードに一致する場合、既存のレコードは、データ内の値で更新されます。一致するレコードが見つからない場合、レコードは、新しいエンティティとして作成されます。
- Prep Conductor では、同じフローを自動的に実行するようにスケジュールしている場合、データは更新されません。これは、Upsert のみがサポートされているからです。
- Data Cloud への保存プロセス中にジョブを中止することはできません。
- Data Cloud に保存される項目は検証されません。Data Cloud でデータを検証してください。
Data Cloud の設定前提条件
これらのステップは、Tableau Prep フローを Data Cloud に保存するための前提条件です。Data Cloud のコンセプトの詳細と、Tableau データ ソースと Data Cloud 間のデータ マッピングについては、「Salesforce Data Cloud について」を参照してください。
取り込み API コネクタを設定する
スキーマ ファイルを .yaml ファイル拡張子が付いた OpenAPI (OAS) 形式でアップロードして、ソース オブジェクトから取り込み API データ ストリームを作成します。スキーマ ファイルには、Web サイトのデータがどのように構造化されているかが記述されています。詳細については、YAML ファイルの例と「取り込み API」を参照してください。
- [設定] 歯車アイコンをクリックしてから、[Data Cloud Setup (Data Cloud の設定)] をクリックします。
- [取り込み API] をクリックします。
- [New (新規作成)] をクリックして、コネクタ名を入力します。
- 新しいコネクタの詳細ページで、スキーマ ファイルを
.yamlファイル拡張子が付いた OpenAPI (OAS) 形式でアップロードします。スキーマ ファイルには、API を介して転送されるデータがどのように構造化されているかが記述されています。 - [Preview Schema (スキーマのプレビュー)] フォームで [保存] をクリックします。
注: 取り込み API スキーマには一連の要件があります。取り込む前に、「スキーマの要件」を参照してください。
データ ストリームを作成する
データ ストリームは、Data Cloud に取り込まれるデータ ソースであり、接続と、Data Cloud に取り込まれる関連付けられたデータで構成されます。
- アプリ ランチャーに移動し、[Data Cloud] を選択します。
- [データ ストリーム] タブをクリックします。
- [New (新規作成)] をクリックし、[取り込み API] を選択してから、[次へ] をクリックします。
- 取り込み API とオブジェクトを選択します。
- データ スペース、カテゴリ、プライマリ キーを選択してから、[次へ] をクリックします。
- [Deploy (展開)] をクリックします。
Data Cloud には、真のプライマリ キーを使用する必要があります。プライマリ キーが存在しない場合、プライマリ キーの数式項目を作成する必要があります。
カテゴリには、プロファイル、エンゲージメント、またはその他を選択します。エンゲージメント カテゴリ向けのオブジェクトには、日付/時刻項目が存在する必要があります。profile または other タイプのオブジェクトは、この同じ要件を強制しません。詳細については、「カテゴリ」と「プライマリキー」を参照してください。
これで、データ ストリームとデータ レイク オブジェクトが用意できました。データ ストリームをデータ スペースに追加できるようになりました。

データ ストリームをデータ スペースに追加する
任意のソースからデータを Data Cloud に取り込むときは、フィルターを使用して、または使用せずに、データ レイク オブジェクト (DLO) を関連データ スペースに関連付けます。
- [データ スペース] タブをクリックします。
- 既定のデータ スペースか、割り当てられてたデータ スペースの名前を選択します。
- [Add Data (データの追加)] をクリックします。
- 作成したデータ レイク オブジェクトを選択し、[次へ] をクリックします。
- (オプション) オブジェクトのフィルターを選択します。
- [保存] をクリックします。

データ レイク オブジェクトを Salesforce オブジェクトにマッピングする
データ マッピングは、データ レイク オブジェクト項目をデータ モデル オブジェクト (DMO) 項目に関連付けます。
- [データ ストリーム] タブに移動し、作成したデータ ストリームを選択します。
![[開始] ボタンのあるデータ マッピング ステータスのフォーム。](Img/prep_saveDC_map.png)
- [データ マッピング] セクションで、[Start (開始)] をクリックします。
項目マッピングキャンバスには、ソース DLO が左側に表示され、対象 DMO が右側に表示されます。詳細については、「データモデルオブジェクトのマッピング」を参照してください。
Data Cloud 取り込み API 用の外部クライアントアプリまたは接続アプリケーションを作成する
取り込み API を使用して、データを Data Cloud に送信する前に、外部クライアント アプリ (推奨) または接続済みアプリ (非推奨) を使用するように Salesforce を構成する必要があります。詳細については、Salesforce ヘルプの次のトピックを参照してください。
-
外部クライアント アプリの場合: 「外部クライアント アプリの OAuth 設定の構成(新しいウィンドウでリンクが開く)」および「外部クライアント アプリの作成(新しいウィンドウでリンクが開く)」
-
接続済みアプリの場合: 「API インテグレーション用の OAuth 設定の有効化」および「Data Cloud 取り込み API 用の接続済みアプリの作成」を参照してください。
取り込み API 用の外部クライアント アプリまたは接続済みアプリの設定の一環として、次の OAuth スコープを選択する必要があります。
- Data Cloud 取り込み API データにアクセスして管理する (cdp_ingest_api)
- Data Cloud のプロファイル データを管理する (cdp_profile_api)
- Data Cloud データに対して ANSI SQL クエリを実行する (cdp_query_api)
- API を介してユーザー データを管理する (api)
- ユーザーに代わっていつでも要求を実行する (refresh_token、offline_access)
スキーマの要件
Data Cloud で 取り込み API ソースを作成するには、アップロードするスキーマ ファイルが特定の要件を満たしている必要があります。「取り込み API スキーマファイルの要件」を参照してください。
- アップロードするスキーマは、.yml または .yaml ファイル拡張子が付いた有効な OpenAPI 形式である必要があります。OpenAPI バージョン 3.0.x がサポートされています。
- オブジェクトには、ネストされたオブジェクトを含めることができません。
- 各スキーマには、少なくとも 1 つのオブジェクトが必要です。各オブジェクトには、少なくとも 1 つの項目が必要です。
- オブジェクトには、1000 個を超える項目を含めることができません。
- オブジェクトは、80 文字以下にする必要があります。
- オブジェクト名には、a ~ z、A ~ Z、0 ~ 9、_、- のみが使用できます。ユニコード文字は使用できません。
- 項目名には、a ~ z、A ~ Z、0 ~ 9、_、- のみが使用できます。ユニコード文字は使用できません。
- 予約語 (date_id、location_id、dat_account_currency、dat_exchange_rate、pacing_period、pacing_end_date、row_count、version) を項目名として使用することはできません。項目名に文字列 __.を含めることはできません。
- 項目名は 80 文字以内にする必要があります。
- 項目は、次の型と形式を満たす必要があります。
- テキスト型またはブール型の場合: 文字列
- 数値型の場合: 数値
- データ型の場合: 文字列、形式: 日付/時刻
- 重複したオブジェクト名 (大文字と小文字が区別される) を使用することはできません。
- オブジェクトに重複した項目名 (大文字と小文字が区別される) を含めることはできません。
- ペイロードの日付/時刻データ型項目は、yyyy-MM-dd’T’HH:mm:ss.SSS’Z' 形式の ISO 8601 UTC Zulu である必要があります。
スキーマを更新するときは、以下に注意する必要があります。
- 既存の項目データ型を変更することはできません。
- オブジェクトの更新時には、オブジェクトのすべての既存項目が存在する必要があります。
- 更新したスキーマ ファイルには変更されたオブジェクトのみが含まれるため、オブジェクトの包括的なリストを毎回提供する必要はありません。
- エンゲージメント カテゴリ向けのオブジェクトには、日付/時刻項目が存在する必要があります。
profileまたはotherタイプのオブジェクトは、この同じ要件を強制しません。
YAML ファイルの例
openapi: 3.0.3
components:
schemas:
owner:
type: object
required:
- id
- name
- region
- createddate
properties:
id:
type: integer
format: int64
name:
type: string
maxLength: 50
region:
type: string
maxLength: 50
createddate:
type: string
format: date-time
car:
type: object
required:
- car_id
- color
- createddate
properties:
car_id:
type: integer
format: int64
color:
type: string
maxLength: 50
createddate:
type: string
format: date-time
フロー出力データを Amazon S3 に保存する
Tableau Prep Builder 2024.2 以降、および Web Authoring と Tableau Cloud で使用できます。この機能は、Tableau Server ではまだ使用できません。
Tableau Prep Builder または Web がサポートする任意のコネクタからデータに接続し、フロー出力を .parquet ファイルまたは .csv ファイルとして Amazon S3 に保存できます。出力は新しいデータとして保存することも、既存の S3 データを上書きすることもできます。データの損失を防ぐために、[カスタム SQL] オプションを使用してテーブル データのコピーを作成し、フロー データを S3 に保存する前にコピーを実行できます。
フロー出力の保存と S3 コネクタへの接続は互いに独立しています。Tableau Prep 入力接続として使用した既存の S3 接続を再利用することはできません。
Amazon S3 に保存できるデータの総量とオブジェクトの数には制限がありません。個々の Amazon S3 オブジェクトのサイズは、最小 0 バイトから最大 5 TB までの範囲になります。1 回の PUT でアップロードできる最大のオブジェクトは 5 GB です。100 MB を超えるオブジェクトの場合、マルチパートアップロード機能の使用を検討する必要があります。「マルチパート アップロードを使用したオブジェクトのアップロードとコピー」を参照してください。
パーミッション
Amazon S3 バケットに書き込むには、バケットのリージョン、バケット名、アクセス キー ID、シークレット アクセス キーが必要です。これらのキーを取得するには、AWS 内に Identity and Access Management (IAM) ユーザーを作成する必要があります。「IAM ユーザーのアクセスキーの管理」を参照してください。
フロー データを Amazon S3 に保存する
- ステップでプラス アイコン をクリックし、[出力の追加] を選択します。
- [出力の保存先] ドロップダウン リストから、[データベースとクラウド ストレージ] を選択します。
- [テーブル] の [接続] セクションから、[Amazon S3 (出力のみ)] を選択します。
- [Amazon S3 (出力のみ)] のフォームに次の情報を追加します。
- アクセス キー ID: Amazon S3 に送信するリクエストの署名に使用したキー ID。
- シークレット アクセス キー: AWS リソースにアクセスする権限があることを確認するために使用される、セキュリティ認証情報 (パスワード、アクセス キー)。
- バケット リージョン: Amazon S3 バケットの場所 (AWS リージョン エンドポイント)。例: us-east-2。
- バケット名: フロー出力を書き込む S3 バケットの名前。同じリージョン内で 2 つの AWS アカウントのバケット名を同じにすることはできません。
注: S3 リージョンとバケット名を確認するには、AWS S3 アカウントにログインし、AWS S3 コンソールに移動します。
- [サインイン] をクリックします。
- S3 URIフィールドに、
.csvファイルまたは.parquetファイルの名前を入力します。既定では、フィールドにs3://<your_bucket_name>が入力されています。ファイル名には拡張子.csvまたは.parquet.を含める必要があります。フロー出力を新しい S3 オブジェクトとして保存することも、既存の S3 オブジェクトを上書きすることもできます。
- 新しい S3 オブジェクトとする場合は、
.parquetファイルまたは.csvファイルの名前を入力します。URI はプレビュー テキストに表示されています。例:s3://<bucket_name><name_file.csv>。 - 既存の S3 オブジェクトを上書きする場合は、
.parquetファイルまたは.csvファイルの名前を入力するか、[参照] をクリックして S3 の既存の.parquetファイルまたは.csvファイルを検索します。注: [オブジェクトの参照] ウィンドウには、以前に Amazon S3 にサインインして保存したファイルのみが表示されます。
- 新しい S3 オブジェクトとする場合は、
- 書き込みオプションの場合、フローからのデータを使用して新しい S3 オブジェクトが作成されます。データが既に存在する場合、オブジェクトに定義されている既存のデータ構造またはプロパティは削除され、フロー データに置き換えられます。フローに存在するフィールドが、新しい S3 オブジェクトに追加されます。
- [フローの実行] をクリックしてフローを実行し、データを S3 に書き込みます。
AWS S3 アカウントにログインし、AWS S3 コンソールに移動すると、データが S3 に保存されたことを確認できます。