Funções do Tableau (por categoria)
A funções do Tableau nesta referência são organizadas por categoria. Clique em uma categoria para navegar pelas funções. Ou pressione Ctrl+F (Command-F em um Mac) para abrir a caixa de pesquisa que pode ser usada para buscar uma função específica na página.
ABS
| Sintaxe | ABS(number) |
| Saída | Número (positivo) |
| Definição | Retorna o valor absoluto do <number> especificado. |
| Exemplo | ABS(-7) = 7 O segundo exemplo retorna o valor absoluto para todos os números contidos no campo Variação de orçamento. |
| Observações | Consulte também SIGN. |
ACOS
| Sintaxe | ACOS(number) |
| Saída | Número (ângulo em radianos) |
| Definição | Retorna o arco cosseno (ângulo) do <number> fornecido. |
| Exemplo | ACOS(-1) = 3.14159265358979 |
| Observações | A função inversa, COS, toma o ângulo em radianos como argumento e retorna o cosseno. |
ASIN
| Sintaxe | ASIN(number) |
| Saída | Número (ângulo em radianos) |
| Definição | Retorna o arco seno (ângulo) de um determinado <number>. |
| Exemplo | ASIN(1) = 1.5707963267949 |
| Observações | A função inversa, SIN, toma o ângulo em radianos como argumento e retorna o seno. |
ATAN
| Sintaxe | ATAN(number) |
| Saída | Número (ângulo em radianos) |
| Definição | Retorna o arco tangente (ângulo) de um determinado <number>. |
| Exemplo | ATAN(180) = 1.5652408283942 |
| Observações | A função inversa, |
ATAN2
| Sintaxe | ATAN2(y number, x number) |
| Saída | Número (ângulo em radianos) |
| Definição | Retorna o ângulo entre dois números especificados (x e y). O resultado é em radianos. |
| Exemplo | ATAN2(2, 1) = 1.10714871779409 |
| Observações | Consulte também ATAN, TAN e COT. |
CEILING
| Sintaxe | CEILING(number) |
| Saída | Inteiro |
| Definição | Arredonda um para o <number> inteiro mais próximo de valor maior ou igual. |
| Exemplo | CEILING(2.1) = 3 |
| Observações | Consulte também FLOOR e ROUND. |
| Limitações do banco de dados |
|
COS
| Sintaxe | COS(number)O argumento numérico é o ângulo em radianos. |
| Saída | Número |
| Definição | Retorna o cosseno de um ângulo. |
| Exemplo | COS(PI( ) /4) = 0.707106781186548 |
| Observações | A função inversa, Consulte também |
COT
| Sintaxe | COT(number)O argumento numérico é o ângulo em radianos. |
| Saída | Número |
| Definição | Retorna a cotangente de um ângulo. |
| Exemplo | COT(PI( ) /4) = 1 |
| Observações | Consulte também ATAN, TAN e PI. Para converter um ângulo de graus em radianos, use RADIANS. |
DEGREES
| Sintaxe | DEGREES(number)O argumento numérico é o ângulo em radianos. |
| Saída | Número (graus) |
| Definição | Converte um ângulo em radianos em graus. |
| Exemplo | DEGREES(PI( )/4) = 45.0 |
| Observações | A função inversa, Consulte também |
DIV
| Sintaxe | DIV(integer1, integer2) |
| Saída | Inteiro |
| Definição | Retorna a parte inteira de uma operação de divisão, na qual o <integer1> é dividido pelo <integer2>. |
| Exemplo | DIV(11,2) = 5 |
EXP
| Sintaxe | EXP(number) |
| Saída | Número |
| Definição | Retorna e elevado à potência do especificado <number>. |
| Exemplo | EXP(2) = 7.389 |
| Observações | Consulte também LN. |
FLOOR
| Sintaxe | FLOOR(number) |
| Saída | Inteiro |
| Definição | Arredonda um número para o <number> mais próximo de valor menor ou igual. |
| Exemplo | FLOOR(7.9) = 7 |
| Observações | Consulte também CEILING e ROUND. |
| Limitações do banco de dados |
|
HEXBINX
| Sintaxe | HEXBINX(number, number) |
| Saída | Número |
| Definição | Mapeia as coordenadas x, y com a coordenada x do compartimento hexagonal mais próximo. Os compartimentos têm extensão 1, então as entradas podem precisar ser escalonadas corretamente. |
| Exemplo | HEXBINX([Longitude]*2.5, [Latitude]*2.5) |
| Observações | HEXBINX e HEXBINY são funções de armazenamento e plotagem dos compartimentos hexagonais. Compartimentos hexagonais são uma opção eficiente e elegante para a visualização de dados em um plano x/y como um mapa. Como os compartimentos são hexagonais, cada um se aproxima de um círculo e minimiza a variação da distância entre o ponto de dados e o centro do compartimento. Isso torna o agrupamento mais preciso e informativo. |
HEXBINY
| Sintaxe | HEXBINY(number, number) |
| Saída | Número |
| Definição | Mapeia as coordenadas x, y com a coordenada y do compartimento hexagonal mais próximo. Os compartimentos têm extensão 1, então as entradas podem precisar ser escalonadas corretamente. |
| Exemplo | HEXBINY([Longitude]*2.5, [Latitude]*2.5) |
| Observações | Consulte também HEXBINX. |
LN
| Sintaxe | LN(number) |
| Saída | Número A saída é |
| Definição | Retorna o algoritmo natural de um <number>. |
| Exemplo | LN(50) = 3.912023005 |
| Observações | Consulte também EXP e LOG. |
LOG
| Sintaxe | LOG(number, [base])Se o argumento base opcional não estiver presente, a base 10 será usada. |
| Saída | Número |
| Definição | Retorna o algoritmo de um número para a base especificada. |
| Exemplo | LOG(16,4) = 2 |
| Observações | Consulte também POWER LN. |
MAX
| Sintaxe | MAX(expression) ou MAX(expr1, expr2) |
| Saída | Mesmo tipo de dados do argumento ou NULL se alguma parte do argumento for nula. |
| Definição | Retorna o máximo de dois argumentos, que devem ser do mesmo tipo de dados.
|
| Exemplo | MAX(4,7) = 7 |
| Observações | Para cadeia de caracteres
Para fontes de dados de bancos de dados, o valor de cadeia de caracteres Para datas Para datas, Como uma agregação
Como comparação
Consulte também |
MIN
| Sintaxe | MIN(expression) ou MIN(expr1, expr2) |
| Saída | Mesmo tipo de dados do argumento ou NULL se alguma parte do argumento for nula. |
| Definição | Retorna, no mínimo, dois argumentos, que devem ser do mesmo tipo de dados.
|
| Exemplo | MIN(4,7) = 4 |
| Observações | Para cadeia de caracteres
Para fontes de dados de bancos de dados, o valor de cadeia de caracteres Para datas Para datas, o Como uma agregação
Como comparação
Consulte também |
PI
| Sintaxe | PI() |
| Saída | Número |
| Definição | Retorna o pi da constante numérica: 3,14159... |
| Exemplo | PI() = 3.14159 |
| Observações | Útil para funções trigonométricas que recebem informações em radianos. Consulte também RADIANS. |
POWER
| Sintaxe | POWER(number, power) |
| Saída | Número |
| Definição | Eleva o <number> à <power> especificada. |
| Exemplo | POWER(5,3) = 125 |
| Observações | Você também pode usar o símbolo ^, como 5^3 = POWER(5,3) = 125 |
RADIANS
| Sintaxe | RADIANS(number) |
| Saída | Número (ângulo em radianos) |
| Definição | Converte o <number> determinado de graus para radianos. |
| Exemplo | RADIANS(180) = 3.14159 |
| Observações | A função inversa, DEGREES, obtém um ângulo em radianos e retorna o ângulo em graus. |
ROUND
| Sintaxe | ROUND(number, [decimals]) |
| Saída | Número |
| Definição | Arredonda o O argumento de |
| Exemplo | ROUND(1/3, 2) = 0.33 |
| Observações | Alguns bancos de dados, como o SQL Server, permitem a especificação de um comprimento negativo, em que -1 arredonda o número para múltiplos de 10, -2 arredonda para múltiplos de 100, etc. Isso não é válido para todos os bancos de dados. Por exemplo, isso não é verdadeiro para o Excel ou o Access. Dica: como |
SIGN
| Sintaxe | SIGN(number) |
| Saída | -1, 0 ou 1 |
| Definição | Retorna o sinal de um <number>: os valores de retorno possíveis são: -1 se o número for negativo, 0 se o número for zero ou 1 se o número for positivo. |
| Exemplo | SIGN(AVG(Profit)) = -1 |
| Observações | Consulte também ABS. |
SIN
| Sintaxe | SIN(number)O argumento numérico é o ângulo em radianos. |
| Saída | Número |
| Definição | Retorna o seno de um ângulo. |
| Exemplo | SIN(0) = 1.0 |
| Observações | A função inversa, Consulte também |
SQRT
| Sintaxe | SQRT(number) |
| Saída | Número |
| Definição | Retorna a raiz quadrada de um <number>. |
| Exemplo | SQRT(25) = 5 |
| Observações | Consulte também SQUARE. |
SQUARE
| Sintaxe | SQUARE(number) |
| Saída | Número |
| Definição | Retorna o quadrado de um <number>. |
| Exemplo | SQUARE(5) = 25 |
| Observações | Consulte também SQRT e POWER. |
TAN
| Sintaxe | TAN(number)O argumento numérico é o ângulo em radianos. |
| Saída | Número |
| Definição | Retorna a tangente de um ângulo. |
| Exemplo | TAN(PI ( )/4) = 1.0 |
| Observações | Consulte também ATAN, ATAN2,COT e PI. Para converter um ângulo de graus em radianos, use RADIANS. |
ZN
| Sintaxe | ZN(expression) |
| Saída | Qualquer, ou o |
| Definição | Retorna a Use esta função para substituir valores nulos por zeros. |
| Exemplo | ZN(Grade) = 0 |
| Observações | Esta é uma função muito útil ao usar campos que podem conter valores nulos em um cálculo. Envolvendo o campo com ZN pode evitar erros causados pelo cálculo com nulos. |
ASCII
| Sintaxe | ASCII(string) |
| Saída | Número |
| Definição | Retorna o código ASCII do primeiro caractere de <string>. |
| Exemplo | ASCII('A') = 65 |
| Observações | Esse é o inverso da função CHAR. |
CHAR
| Sintaxe | CHAR(number) |
| Saída | Cadeia de caracteres |
| Definição | Retorna o caractere codificado pelo código ASCII <number>. |
| Exemplo | CHAR(65) = 'A' |
| Observações | Esse é o inverso da função ASCII. |
CONTAINS
| Sintaxe | CONTAINS(string, substring) |
| Saída | Booleano |
| Definição | Retornará true se a cadeia de caracteres determinada contiver a subcadeia de caracteres especificada. |
| Exemplo | CONTAINS("Calculation", "alcu") = true |
| Observações | Veja também a função lógica(O link abre em nova janela) Dependendo da fonte de dados, CONTAINS pode diferenciar maiúsculas de minúsculas. Isto é, para algumas fontes de dados, |
ENDSWITH
| Sintaxe | ENDSWITH(string, substring) |
| Saída | Booleano |
| Definição | Retornará true se a cadeia de caracteres determinada terminar com a subcadeia de caracteres especificada. Espaços em branco à direita são ignorados. |
| Exemplo | ENDSWITH("Tableau", "leau") = true |
| Observações | Veja também o RegEx aceito na documentação de funções adicionais(O link abre em nova janela). |
FIND
| Sintaxe | FIND(string, substring, [start]) |
| Saída | Número |
| Definição | Retorna a posição de índice de uma subcadeia de caracteres em uma cadeia de caracteres, ou 0 se a subcadeia de caracteres não for encontrada. O primeiro caractere na cadeia de caracteres está na posição 1. Se o argumento opcional |
| Exemplo | FIND("Calculation", "alcu") = 2FIND("Calculation", "Computer") = 0FIND("Calculation", "a", 3) = 7FIND("Calculation", "a", 2) = 2FIND("Calculation", "a", 8) = 0 |
| Observações | Veja também o RegEx aceito na documentação de funções adicionais(O link abre em nova janela). |
FINDNTH
| Sintaxe | FINDNTH(string, substring, occurrence) |
| Saída | Número |
| Definição | Retorna a posição da nª ocorrência de substring dentro da string especificada, onde n é definido pelo argumento de ocorrência |
| Exemplo | FINDNTH("Calculation", "a", 2) = 7 |
| Observações |
Veja também o RegEx aceito na documentação de funções adicionais(O link abre em nova janela). |
LEFT
| Sintaxe | LEFT(string, number) |
| Saída | Cadeia de caracteres |
| Definição | Retorna o <number> mais à esquerda de caracteres na cadeia de caracteres. |
| Exemplo | LEFT("Matador", 4) = "Mata" |
| Observações | Veja também MID e RIGHT. |
LEN
| Sintaxe | LEN(string) |
| Saída | Número |
| Definição | Retorna o comprimento da cadeia de caracteres. |
| Exemplo | LEN("Matador") = 7 |
| Observações | Não confundir com a função espacial(O link abre em nova janela) LENGTH. |
LOWER
| Sintaxe | LOWER(string) |
| Saída | Cadeia de caracteres |
| Definição | Retorna a <string> fornecida em todos os caracteres minúsculos. |
| Exemplo | LOWER("ProductVersion") = "productversion" |
| Observações | Veja também UPPER e PROPER. |
LTRIM
| Sintaxe | LTRIM(string) |
| Saída | Cadeia de caracteres |
| Definição | Retorna a <string> fornecida com os espaços à esquerda removidos. |
| Exemplo | LTRIM(" Matador ") = "Matador " |
| Observações | Consulte também RTRIM. |
MAX
| Sintaxe | MAX(expression) ou MAX(expr1, expr2) |
| Saída | Mesmo tipo de dados do argumento ou NULL se alguma parte do argumento for nula. |
| Definição | Retorna o máximo de dois argumentos, que devem ser do mesmo tipo de dados.
|
| Exemplo | MAX(4,7) = 7 |
| Observações | Para cadeia de caracteres
Para fontes de dados de bancos de dados, o valor de cadeia de caracteres Para datas Para datas, Como uma agregação
Como comparação
Consulte também |
MID
| Sintaxe | (MID(string, start, [length]) |
| Saída | Cadeia de caracteres |
| Definição | Retorna uma cadeia de caracteres começando na posição Se o argumento numérico opcional |
| Exemplo | MID("Calculation", 2) = "alculation"MID("Calculation", 2, 5) ="alcul" |
| Observações | Veja também o RegEx aceito na documentação de funções adicionais(O link abre em nova janela). |
MIN
| Sintaxe | MIN(expression) ou MIN(expr1, expr2) |
| Saída | Mesmo tipo de dados do argumento ou NULL se alguma parte do argumento for nula. |
| Definição | Retorna, no mínimo, dois argumentos, que devem ser do mesmo tipo de dados.
|
| Exemplo | MIN(4,7) = 4 |
| Observações | Para cadeia de caracteres
Para fontes de dados de bancos de dados, o valor de cadeia de caracteres Para datas Para datas, o Como uma agregação
Como comparação
Consulte também |
PROPER
| Sintaxe | PROPER(string) |
| Saída | Cadeia de caracteres |
| Definição | Retorna a |
| Exemplo | PROPER("PRODUCT name") = "Product Name"PROPER("darcy-mae") = "Darcy-Mae" |
| Observações | Espaços e caracteres não alfanuméricos, como pontuação, são tratados como separadores. |
| Limitações do banco de dados | PROPER está disponível apenas para alguns arquivos simples e em extrações. Se você precisar usar PROPER em uma fonte de dados que de outra forma não oferece suporte, considere usar uma extração. |
REPLACE
| Sintaxe | REPLACE(string, substring, replacement |
| Saída | Cadeia de caracteres |
| Definição | Procura em <string> por <substring> e substitui por <replacement>. Se a <substring> não for encontrada, a string não será alterada. |
| Exemplo | REPLACE("Version 3.8", "3.8", "4x") = "Version 4x" |
| Observações | Veja também REGEXP_REPLACE no documentação de funções adicionais(O link abre em nova janela). |
RIGHT
| Sintaxe | RIGHT(string, number) |
| Saída | Cadeia de caracteres |
| Definição | Retorna o <number> mais à direita dos caracteres na cadeia de caracteres. |
| Exemplo | RIGHT("Calculation", 4) = "tion" |
| Observações | Veja também LEFT e MID. |
RTRIM
| Sintaxe | RTRIM(string) |
| Saída | Cadeia de caracteres |
| Definição | Retorna a <string> fornecida com os espaços à direita removidos. |
| Exemplo | RTRIM(" Calculation ") = " Calculation" |
| Observações | Veja também LTRIM e TRIM. |
SPACE
| Sintaxe | SPACE(number) |
| Saída | Cadeia de caracteres (especificamente, apenas espaços) |
| Definição | Retorna uma cadeia de caracteres composta por um número especificado de espaços repetidos. |
| Exemplo | SPACE(2) = " " |
SPLIT
| Sintaxe | SPLIT(string, delimiter, token number) |
| Saída | Cadeia de caracteres |
| Definição | Retorna uma subcadeia de uma cadeia de caracteres, usando um caractere delimitador para dividir a cadeia de caracteres em uma sequência de tokens. |
| Exemplo | SPLIT ("a-b-c-d", "-", 2) = "b"SPLIT ("a|b|c|d", "|", -2) = "c" |
| Observações | A cadeia de caracteres é interpretada como uma sequência alternada de delimitadores e tokens. Então, para a cadeia de caracteres
Consulte também o REGEX compatível na documentação de funções adicionais(O link abre em nova janela). |
| Limitações do banco de dados | Os comandos de divisão e divisão personalizada estão disponíveis para os tipos de fontes de dados a seguir: extrações de dados do Tableau, Microsoft Excel, arquivo de texto, arquivo PDF, Salesforce, OData, Microsoft Azure Market Place, Google Analytics, Vertica, Oracle, MySQL, PostgreSQL, Teradata, Amazon Redshift, Aster Data, Google Big Query, Cloudera Hadoop Hive, Hortonworks Hive e Microsoft SQL Server. Algumas fontes de dados impõe limites às cadeias de caracteres de divisão. Consulte Limitações da função SPLIT posteriormente neste tópico. |
STARTSWITH
| Sintaxe | STARTSWITH(string, substring) |
| Saída | Booleano |
| Definição | Retornará true se string começar com substring. Espaços em branco à esquerda são ignorados. |
| Exemplo | STARTSWITH("Matador, "Ma") = TRUE |
| Observações | Consulte também CONTAINS, bem como REGEX compatível na documentação de funções adicionais(O link abre em nova janela). |
TRIM
| Sintaxe | TRIM(string) |
| Saída | Cadeia de caracteres |
| Definição | Retorna a <string> com os espaços à esquerda e à direita removidos. |
| Exemplo | TRIM(" Calculation ") = "Calculation" |
| Observações | Veja também LTRIM e RTRIM. |
UPPER
| Sintaxe | UPPER(string) |
| Saída | Cadeia de caracteres |
| Definição | Retorna a <string> fornecida com todos os caracteres maiúsculos. |
| Exemplo | UPPER("Calculation") = "CALCULATION" |
| Observações | Veja também PROPER e LOWER. |
Observação: As funções de data não consideram o início do ano fiscal configurado. Consulte Datas fiscais.
DATE
Função de conversão de tipo que altera as expressões de cadia de caracteres e número em datas, desde que estejam em um formato reconhecível.
| Sintaxe | DATE(expression) |
| Saída | Data |
| Definição | Retorna uma data de acordo com um número, cadeia de caracteres ou de data <expression>. |
| Exemplo | DATE([Employee Start Date]) DATE("September 22, 2018") DATE("9/22/2018")DATE(#2018-09-22 14:52#) |
| Observações | Ao contrário de
|
DATEADD
Adiciona um número especificado de partes de data (meses, dias etc) à data de início.
| Sintaxe | DATEADD(date_part, interval, date) |
| Saída | Data |
| Definição | Retorna a <date> com o <interval> do número especificado, adicionado a <date_part> especificada dessa data. Por exemplo, adicionar três meses ou 12 dias a uma data de início. |
| Exemplo | Adie todas as datas de vencimento em uma semana DATEADD('week', 1, [due date])Adicione 280 dias à data 20 de fevereiro de 2021 DATEADD('day', 280, #2/20/21#) = #November 27, 2021# |
| Observações | Oferece suporte às datas de ISO 8601. |
DATEDIFF
Retorna o número de partes da data (semanas, anos etc.) entre duas datas.
| Sintaxe | DATEDIFF(date_part, date1, date2, [start_of_week]) |
| Saída | Inteiro |
| Definição | Retorna a diferença entre <date1> e <date2> expressa em unidades de <date_part>. Por exemplo, subtraindo as datas que alguém entrou e saiu de uma banda para ver quanto tempo eles estavam na banda. |
| Exemplo | Número de dias entre 25 de março de 1986 e 20 de fevereiro de 2021 DATEDIFF('day', #3/25/1986#, #2/20/2021#) = 12,751Quantos meses alguém estava em uma banda DATEDIFF('month', [date joined band], [date left band]) |
| Observações | Oferece suporte às datas de ISO 8601. |
DATENAME
Retorna o nome da parte de data especificada como uma cadeia de caracteres discreta.
| Sintaxe | DATENAME(date_part, date, [start_of_week]) |
| Saída | Cadeia de caracteres |
| Definição | Retorna <date_part> de <date> como uma cadeia de caracteres. |
| Exemplo | DATENAME('year', #3/25/1986#) = "1986"DATENAME('month', #1986-03-25#) = "March" |
| Observações | Oferece suporte às datas de ISO 8601. Um cálculo muito semelhante é DATEPART, que retorna o valor da parte da data especificada como um inteiro contínuo. Alterando os atributos do resultado do cálculo (dimensão ou medida, contínua ou discreta) e a formatação da data, os resultados de Uma função inversa é DATEPARSE, que recebe um valor de cadeia de caracteres e o formata como uma data. |
DATEPARSE
Retorna cadeias de caracteres especificamente formatadas como datas.
| Sintaxe | DATEPARSE(date_format, date_string) |
| Saída | Data |
| Definição | O argumento <date_format> como o campo <date_string> é organizado. Devido à variedade de maneiras que o campo de cadeia de caracteres pode ser ordenado, o <date_format> precisa ter correspondência exata. Para obter uma explicação completa e os detalhes de formatação, consulte Converter um campo em um campo de data(O link abre em nova janela). |
| Exemplo | DATEPARSE('yyyy-MM-dd', "1986-03-25") = #March 25, 1986# |
| Observações |
As funções inversas, que separam datas e retornam o valor de suas partes, são |
| Limitações do banco de dados |
|
DATEPART
Retorna o nome da parte de data especificada como um inteiro.
| Sintaxe | DATEPART(date_part, date, [start_of_week]) |
| Saída | Inteiro |
| Definição | Retorna <date_part> de <date> como um inteiro. |
| Exemplo | DATEPART('year', #1986-03-25#) = 1986DATEPART('month', #1986-03-25#) = 3 |
| Observações | Oferece suporte às datas de ISO 8601. Um cálculo muito semelhante é Uma função inversa é |
DATETRUNC
Esta função pode ser considerada como arredondamento de data. Leva uma data específica e retorna uma versão dessa data na especificidade desejada. Como cada data deve ter um valor para dia, mês, trimestre e ano, DATETRUNC define os valores como o valor mais baixo para cada parte da data até a parte da data especificada. Consulte o exemplo para obter mais informações.
| Sintaxe | DATETRUNC(date_part, date, [start_of_week]) |
| Saída | Data |
| Definição | Trunca a <date> na precisão definida por <date_part>. Esta função retorna uma nova data. Por exemplo, quando você trunca uma data no meio do mês no nível do mês, essa função retorna o primeiro dia do mês. |
| Exemplo | DATETRUNC('day', #9/22/2018#) = #9/22/2018#DATETRUNC('iso-week', #9/22/2018#) = #9/17/2018#(a segunda-feira da semana contendo 9/22/2018) DATETRUNC(quarter, #9/22/2018#) = #7/1/2018# (primeiro dia do trimestre contendo 9/22/2018) Observação: para semana e iso-semana, o |
| Observações | Oferece suporte às datas de ISO 8601. Você não deveria usar Por exemplo, |
DAY
Retorna o dia do mês (1 a 31) especificada como um inteiro.
| Sintaxe | DAY(date) |
| Saída | Inteiro |
| Definição | Retorna o dia da <date> especificada como um inteiro. |
| Exemplo | Day(#September 22, 2018#) = 22 |
| Observações | Consulte também WEEK, MONTH, TRIMESTRE, YEAR e os equivalentes ISO. |
ISDATE
Verifica se a cadeia de caracteres é um formato de data válido.
| Sintaxe | ISDATE(string) |
| Saída | Booliano |
| Definição | Retornará true se uma determinada <string> for uma data válida. |
| Exemplo | ISDATE(09/22/2018) = true ISDATE(22SEP18) = false |
| Observações | O argumento necessário deve ser uma cadeia de caracteres. ISDATE não pode ser usado para um campo com um tipo de dados de data – o cálculo retornará um erro. |
ISOQUARTER
| Sintaxe | ISOQUARTER(date) |
| Saída | Inteiro |
| Definição | Retorna o trimestre baseado em semana ISO8601 de uma <date> especificada como um inteiro. |
| Exemplo | ISOQUARTER(#1986-03-25#) = 1 |
| Observações | Consulte também ISOWEEK, ISOWEEKDAY, ISOYEAR, e não equivalentes ao ISO. |
ISOWEEK
| Sintaxe | ISOWEEK(date) |
| Saída | Inteiro |
| Definição | Retorna a semana baseada em semana ISO8601 especificada de <date> como um inteiro. |
| Exemplo | ISOWEEK(#1986-03-25#) = 13 |
| Observações | Consulte também ISOWEEKDAY, ISOQUARTER, ISOYEAR, e não equivalentes ao ISO. |
ISOWEEKDAY
| Sintaxe | ISOWEEKDAY(date) |
| Saída | Inteiro |
| Definição | Retorna dia da semana baseado em semana ISO8601 de uma <date> especificada como um inteiro. |
| Exemplo | ISOWEEKDAY(#1986-03-25#) = 2 |
| Observações | Consulte também ISOWEEK, ISOQUARTER, ISOYEAR, e não equivalentes ao ISO. |
ISOYEAR
| Sintaxe | ISOYEAR(date) |
| Saída | Inteiro |
| Definição | Retorna ano baseado em semana ISO8601 de uma <date> especificada como um inteiro. |
| Exemplo | ISOYEAR(#1986-03-25#) = 1,986 |
| Observações | Consulte também ISOWEEK, ISOWEEKDAY, ISOQUARTER, e não equivalentes ao ISO. |
MAKEDATE
| Sintaxe | MAKEDATE(year, month, day) |
| Saída | Data |
| Definição | Retorna um valor de data composto por <year>, <month> e <day> especificados. |
| Exemplo | MAKEDATE(1986,3,25) = #1986-03-25# |
| Observações | Observação: os valores inseridos incorretamente serão ajustados em uma data, como Disponível para as Extrações de dados do Tableau. Verifique a disponibilidade em outras fontes de dados.
|
MAKEDATETIME
| Sintaxe | MAKEDATETIME(date, time) |
| Saída | Datetime |
| Definição | Retorna um datetime que combina <date> e <time>. A data pode ser um tipo date, datetime ou string. A hora deve ser um datetime. |
| Exemplo | MAKEDATETIME("1899-12-30", #07:59:00#) = #12/30/1899 7:59:00 AM#MAKEDATETIME([Date], [Time]) = #1/1/2001 6:00:00 AM# |
| Observações | Esta função está disponível somente para conexões compatíveis com o MySQL (que, para o Tableau, são o MySQL e o Amazon Aurora).
|
MAKETIME
| Sintaxe | MAKETIME(hour, minute, second) |
| Saída | Datetime |
| Definição | Retorna um valor de data composto por <hour>, <minute> e <second> especificados. |
| Exemplo | MAKETIME(14, 52, 40) = #1/1/1899 14:52:40# |
| Observações | Como o Tableau não oferece suporte a um tipo de dados de hora, apenas DATETIME e hora, a saída é uma datetime. A parte de data do campo será 1/1/1899. Função semelhante a |
MAX
| Sintaxe | MAX(expression) ou MAX(expr1, expr2) |
| Saída | Mesmo tipo de dados do argumento ou NULL se alguma parte do argumento for nula. |
| Definição | Retorna o máximo de dois argumentos, que devem ser do mesmo tipo de dados.
|
| Exemplo | MAX(4,7) = 7 |
| Observações | Para cadeia de caracteres
Para fontes de dados de bancos de dados, o valor de cadeia de caracteres Para datas Para datas, Como uma agregação
Como comparação
Consulte também |
MIN
| Sintaxe | MIN(expression) ou MIN(expr1, expr2) |
| Saída | Mesmo tipo de dados do argumento ou NULL se alguma parte do argumento for nula. |
| Definição | Retorna, no mínimo, dois argumentos, que devem ser do mesmo tipo de dados.
|
| Exemplo | MIN(4,7) = 4 |
| Observações | Para cadeia de caracteres
Para fontes de dados de bancos de dados, o valor de cadeia de caracteres Para datas Para datas, o Como uma agregação
Como comparação
Consulte também |
MONTH
| Sintaxe | MONTH(date) |
| Saída | Inteiro |
| Definição | Retorna o mês da <date> especificada como um inteiro. |
| Exemplo | MONTH(#1986-03-25#) = 3 |
| Observações | Consulte também DAY, WEEK, TRIMESTRE, YEAR e os equivalentes ISO |
NOW
| Sintaxe | NOW() |
| Saída | Datetime |
| Definição | Retorna a data e a hora atuais do sistema local. |
| Exemplo | NOW() = 1986-03-25 1:08:21 PM |
| Observações |
Consulte também Se a fonte de dados for uma conexão ativa, a data e a hora do sistema podem estar em outro fuso horário. Para obter mais informações sobre como abordar isso, consulte Base de dados de conhecimento. |
TRIMESTRE
| Sintaxe | QUARTER(date) |
| Saída | Inteiro |
| Definição | Retorna o trimestre da <date> especificada como um inteiro. |
| Exemplo | QUARTER(#1986-03-25#) = 1 |
| Observações | Consulte também DAY, WEEK, MONTH, YEAR e os equivalentes ISO |
TODAY
| Sintaxe | TODAY() |
| Saída | Data |
| Definição | Retorna a data atual do sistema local. |
| Exemplo | TODAY() = 1986-03-25 |
| Observações |
Consulte também NOW, um cálculo semelhante que retorna uma data e hora em vez de uma data. Se a fonte de dados for uma conexão em tempo real, a data do sistema pode estar em outro fuso horário. Para obter mais informações sobre como abordar isso, consulte Base de dados de conhecimento. |
WEEK
| Sintaxe | WEEK(date) |
| Saída | Inteiro |
| Definição | Retorna a semana da <date> especificada como um inteiro. |
| Exemplo | WEEK(#1986-03-25#) = 13 |
| Observações | Consulte também DAY, MONTH, TRIMESTRE, YEAR e os equivalentes ISO |
YEAR
| Sintaxe | YEAR(date) |
| Saída | Inteiro |
| Definição | Retorna o ano da <date> especificada como um inteiro. |
| Exemplo | YEAR(#1986-03-25#) = 1,986 |
| Observações | Consulte também DAY, WEEK, MONTH, TRIMESTRE e os equivalentes ISO |
date_part
Muitas funções de data no Tableau aceitam o argumento date_part, que é uma constante de cadeia de caracteres que informa à função qual parte de uma data deve ser considerada, como dia, semana, trimestre, etc. O valores válidos de date_part que você pode usar são:
| date_part | Valores |
|---|---|
'year' | Ano de quatro dígitos |
'quarter' | 1-4 |
'month' | 1-12 ou "January", "February" e assim por diante |
'dayofyear' | Dia do ano; 1 de janeiro é 1, 1 de fevereiro é 32 etc. |
'day' | 1-31 |
'weekday' | 1-7 ou "Sunday", "Monday" e assim por diante |
'week' | 1-52 |
'hour' | 0-23 |
'minute' | 0-59 |
'second' | 0-60 |
'iso-year' | Ano de ISO 8601 com quatro dígitos |
'iso-quarter' | 1-4 |
'iso-week' | 1-52, o início da semana é sempre segunda-feira |
'iso-weekday' | 1-7, o início da semana é sempre segunda-feira |
AND
| Sintaxe | <expr1> AND <expr2> |
| Definição | Realiza uma conjunção lógica em duas expressões. (Se ambos os lados forem true, o teste lógico retornará true.) |
| Saída | Booleano (true ou false) |
| Exemplo | IF [Season] = "Spring" AND "[Season] = "Fall" "Se ambos (Season = Spring) e (Season = Fall) forem true simultaneamente, então retorna It's the apocalypse and footwear doesn't matter." |
| Observações | Frequentemente usado com IF e IIF. Veja também NOT e OU. Se ambas as expressões forem Se você criar um cálculo no qual o resultado de uma comparação Observação: o operador |
CASE
| Sintaxe | CASE <expression>
|
| Saída | Depende do tipo de dados dos valores <then>. |
| Definição | Avalia |
| Exemplo | "Olhe para o campo Season. Se o valor for Summer, retorna Sandals. Se o valor for Winter, retorna Boots. Se nenhuma das opções do cálculo corresponder ao que está no campo Season, retorna um Sneakers." |
| Observações | Usado com WHEN, THEN, ELSE e END. Dica: muitas vezes você pode usar um grupo para obter os mesmos resultados de uma função CASE complicada ou usar CASE para substituir a funcionalidade de agrupamento nativo, como no exemplo anterior. Você pode querer testar qual é o melhor desempenho para o seu cenário. |
ELSE
| Sintaxe | CASE <expression>
|
| Definição | Uma parte opcional da expressão IF ou CASE usada para especificar um valor padrão a ser retornado se nenhuma das expressões testadas for true. |
| Exemplo | IF [Season] = "Summer" THEN 'Sandals' CASE [Season] |
| Observações | Usado com CASE, WHEN, IF, ELSEIF, THEN e END
|
ELSEIF
| Sintaxe | [ELSEIF <test2> THEN <then2>] |
| Definição | Uma parte opcional de uma expressão IF usada para especificar condições adicionais além do IF inicial. |
| Exemplo | IF [Season] = "Summer" THEN 'Sandals' |
| Observações | Usado com IF, THEN, ELSE e END
Diferente de |
END
| Definição | Usado para fechar uma expressão IF ou CASE. |
| Exemplo | IF [Season] = "Summer" THEN 'Sandals' "Se Season = Summer, então retorna Sandals. Caso contrário, observe a próxima expressão. Se Season = Winter, então retorna Boots. Se nenhuma das expressões for true, retorna Sneakers." CASE [Season] "Olhe para o campo Season. Se o valor for Summer, retorna Sandals. Se o valor for Winter, retorna Boots. Se nenhuma das opções do cálculo corresponder ao que está no campo Season, retorna um Sneakers." |
| Observações |
IF
| Sintaxe | IF <test1> THEN <then1> |
| Saída | Depende do tipo de dados dos valores <then>. |
| Definição | Testa uma série de expressões e retorna o valor |
| Exemplo | IF [Season] = "Summer" THEN 'Sandals' "Se Season = Summer, então retorna Sandals. Caso contrário, observe a próxima expressão. Se Season = Winter, então retorna Boots. Se nenhuma das expressões for true, retorna Sneakers." |
| Observações |
IFNULL
| Sintaxe | IFNULL(expr1, expr2) |
| Saída | Depende do tipo de dados dos valores <expr>. |
| Definição | Retorna |
| Exemplo | IFNULL([Assigned Room], "TBD") "Se o campo Assigned Room não for nulo, retorna seu valor. Se o campo Assigned Room for nulo, retorna TBD." |
| Observações | Compare com ISNULL. Consulte também ZN. |
IIF
| Sintaxe | IIF(<test>, <then>, <else>, [<unknown>]) |
| Saída | Depende do tipo de dados dos valores na expressão. |
| Definição | Verifica se uma condição foi atendida (<test>) e retorna <then> se o teste for true, <else> se o teste for false e um valor opcional para <unknown>, se o teste for nulo. Se o desconhecido opcional não for especificado, IIF retorna nulo. |
| Exemplo | IIF([Season] = 'Summer', 'Sandals', 'Other footwear') "Se Season = Summer, então retorna Sandals. Caso contrário, retorna Other footwear" IIF([Season] = 'Summer', 'Sandals', "Se Season = Summer, então retorna Sandals. Caso contrário, observe a próxima expressão. Se Season = Winter, então retorna Boots. Se nenhuma for true, retrona Sneakers." IIF('Season' = 'Summer', 'Sandals', "Se Season = Summer, então retorna Sandals. Caso contrário, observe a próxima expressão. Se Season = Winter, então retorna Boots. Se nenhuma das expressões for true, retorna Sneakers.” |
| Observações |
Ou seja, no cálculo abaixo o resultado será Red e não Orange, pois a expressão deixa de ser avaliada assim que A=A for avaliada como true:
|
IN
| Sintaxe | <expr1> IN <expr2> |
| Saída | Booleano (true ou false) |
| Definição | Retorna TRUE se qualquer valor em <expr1> corresponde a qualquer valor em <expr2>. |
| Exemplo | SUM([Cost]) IN (1000, 15, 200) "O valor do campo Custo é 1000, 15 ou 200?" [Field] IN [Set] "O valor do campo está presente no conjunto?" |
| Observações | Os valores Consulte também WHEN. |
ISDATE
| Sintaxe | ISDATE(string) |
| Saída | Booleano (true ou false) |
| Definição | Retornará true se uma <string> for uma data válida. A expressão de entrada precisa ser um campo de cadeia de caracteres (texto). |
| Exemplo | ISDATE("2018-09-22")"A cadeia de caracteres 2018-09-22 é uma data formatada corretamente?" |
| Observações | O que é considerado uma data válida depende da localidade(O link abre em nova janela) do sistema que avalia o cálculo. Por exemplo: Nos Estados Unidos:
No Reino Unido:
|
ISNULL
| Sintaxe | ISNULL(expression) |
| Saída | Booleano (true ou false) |
| Definição | Retorna true se |
| Exemplo | ISNULL([Assigned Room]) "O campo Sala Atribuída é nulo?" |
| Observações | Compare com IFNULL. Consulte também ZN. |
MAX
| Sintaxe | MAX(expression) ou MAX(expr1, expr2) |
| Saída | Mesmo tipo de dados do argumento ou NULL se alguma parte do argumento for nula. |
| Definição | Retorna o máximo de dois argumentos, que devem ser do mesmo tipo de dados.
|
| Exemplo | MAX(4,7) = 7 |
| Observações | Para cadeia de caracteres
Para fontes de dados de bancos de dados, o valor de cadeia de caracteres Para datas Para datas, Como uma agregação
Como comparação
Consulte também |
MIN
| Sintaxe | MIN(expression) ou MIN(expr1, expr2) |
| Saída | Mesmo tipo de dados do argumento ou NULL se alguma parte do argumento for nula. |
| Definição | Retorna, no mínimo, dois argumentos, que devem ser do mesmo tipo de dados.
|
| Exemplo | MIN(4,7) = 4 |
| Observações | Para cadeia de caracteres
Para fontes de dados de bancos de dados, o valor de cadeia de caracteres Para datas Para datas, o Como uma agregação
Como comparação
Consulte também |
NOT
| Sintaxe | NOT <expression> |
| Saída | Booleano (true ou false) |
| Definição | Realiza uma negação lógica em uma expressão. |
| Exemplo | IF NOT [Season] = "Summer" "Se Season não é igual a Summer, então retorna Don't wear sandals. Caso contrário, retorna Wear sandals" |
| Observações |
OU
| Sintaxe | <expr1> OR <expr2> |
| Saída | Booleano (true ou false) |
| Definição | Realiza uma disjunção lógica em duas expressões. |
| Exemplo | IF [Season] = "Spring" OR [Season] = "Fall" "Se (Season = Spring) ou (Season = Fall) for true, retorna Sneakers." |
| Observações | Frequentemente usado com IF e IIF. Veja também DATE e NOT. Se uma das expressões for Se você criar um cálculo que exibe o resultado de uma comparação Observação: o operador |
THEN
| Sintaxe | IF <test1> THEN <then1>
|
| Definição | Uma parte obrigatória de uma expressaõ IF, ELSEIF ou CASE, usada para definir qual resultado retornar se um valor ou teste específico for true. |
| Exemplo | IF [Season] = "Summer" THEN 'Sandals' "Se Season = Summer, então retorna Sandals. Caso contrário, observe a próxima expressão. Se Season = Winter, então retorna Boots. Se nenhuma das expressões for true, retorna Sneakers." CASE [Season] "Olhe para o campo Season. Se o valor for Summer, retorna Sandals. Se o valor for Winter, retorna Boots. Se nenhuma das opções do cálculo corresponder ao que está no campo Season, retorna um Sneakers." |
| Observações |
WHEN
| Sintaxe | CASE <expression>
|
| Definição | Uma parte obrigatória de uma expressão CASE. Encontra o primeiro <<value>> que corresponde <expression>> e retorna ao <then> correspondente. |
| Exemplo | CASE [Season] "Olhe para o campo Season. Se o valor for Summer, retorna Sandals. Se o valor for Winter, retorna Boots. Se nenhuma das opções do cálculo corresponder ao que está no campo Season, retorna um Sneakers." |
| Observações | Usado com CASE, THEN, ELSE e END.
CASE <expression> Os valores aos quais |
ZN
| Sintaxe | ZN(expression) |
| Saída | Depende do tipo de dados de <expression>ou 0. |
| Definição | Retorna <expression> se não for nulo, caso contrário, retorna zero. |
| Exemplo | ZN([Test Grade]) "Se Test Grade não for nulo, retorne o valor. Se Test Grade for nulo, retorne 0." |
| Observações |
Consulte também ISNULL. |
ATTR
| Sintaxe | ATTR(expression) |
| Definição | Retorna o valor da expressão caso tenha um único valor para todas as linhas. Do contrário, retorna um asterisco. Os valores nulos são ignorados. |
AVG
| Sintaxe | AVG(expression) |
| Definição | Retorna a média de todos os valores na expressão. Os valores nulos são ignorados. |
| Observações | AVG pode ser usado apenas com campos numéricos. |
COLLECT
| Sintaxe | COLLECT(spatial) |
| Definição | Um cálculo agregado que combina os valores no campo do argumento. Os valores nulos são ignorados. |
| Observações | COLLECT pode ser usado apenas com campos espaciais. |
CORR
| Sintaxe | CORR(expression1, expression2) |
| Saída | Número de -1 a 1 |
| Definição | Retorna o coeficiente de correlação Pearson de duas expressões. |
| Exemplo | example |
| Observações | A correlação Pearson mede a relação linear entre duas variáveis. Os resultados variam de -1 a +1 inclusive, em que 1 denota uma relação linear positiva e exata, 0 denota nenhuma relação linear entre a variância e −1 é uma relação negativa exata. O quadrado de um resultado CORR é equivalente ao valor quadrado de R para um modelo de linha de tendência linear. Consulte Termos do modelo de linha de tendência(O link abre em nova janela). Use com expressões LOD no escopo da tabela: Você pode usar CORR para visualizar a correlação em uma dispersão desagregada usando uma Expressão de nível de detalhe com escopo de tabela(O link abre em nova janela). Por exemplo: {CORR(Sales, Profit)}Com uma expressão de nível de detalhe, a correlação é executada em todas as linhas. Se usou uma fórmula como |
| Limitações do banco de dados |
Para outras fontes de dados, considere extrair os dados ou usar |
COUNT
| Sintaxe | COUNT(expression) |
| Definição | Retorna o número de itens. Os valores Null não são contados. |
COUNTD
| Sintaxe | COUNTD(expression) |
| Definição | Retorna o número de itens distintos em um grupo. Os valores Null não são contados. |
COVAR
| Sintaxe | COVAR(expression1, expression2) |
| Definição | Retorna a covariância de amostra de duas expressões |
| Observações | A covariância quantifica como duas variáveis mudam ao mesmo tempo. Uma covariância positiva indica que as variáveis tendem a se mover na mesma direção, como quando valores maiores de uma variável tendem a corresponder aos valores maiores da outra variável, em média. A covariância de amostra usa o número de pontos de dados não nulos, n - 1, para normalizar o cálculo da covariância, em vez de n, que é usado pela covariância populacional (disponível com a função Se O valor de |
| Limitações do banco de dados |
Para outras fontes de dados, considere extrair os dados ou usar |
COVARP
| Sintaxe | COVARP(expression 1, expression2) |
| Definição | Retorna a covariância populacional de duas expressões. |
| Observações | A covariância quantifica como duas variáveis mudam ao mesmo tempo. Uma covariância positiva indica que as variáveis tendem a se mover na mesma direção, como quando valores maiores de uma variável tendem a corresponder aos valores maiores da outra variável, em média. A covariância populacional é a covariância de amostra multiplicada por (n-1)/n, em que n é o número total de pontos de dados não nulos. A covariância populacional é a escolha apropriada quando há dados disponíveis para todos os itens de interesse, ao invés de somente um subconjunto aleatório de itens, em que a covariância de amostra (com a função Se |
| Limitações do banco de dados |
Para outras fontes de dados, considere extrair os dados ou usar |
MAX
| Sintaxe | MAX(expression) ou MAX(expr1, expr2) |
| Saída | Mesmo tipo de dados do argumento ou NULL se alguma parte do argumento for nula. |
| Definição | Retorna o máximo de dois argumentos, que devem ser do mesmo tipo de dados.
|
| Exemplo | MAX(4,7) = 7 |
| Observações | Para cadeia de caracteres
Para fontes de dados de bancos de dados, o valor de cadeia de caracteres Para datas Para datas, Como uma agregação
Como comparação
Consulte também |
MEDIAN
| Sintaxe | MEDIAN(expression) |
| Definição | Retorna o mediano de uma expressão em todos os registros. Os valores nulos são ignorados. |
| Observações | MEDIAN pode ser usado apenas com campos numéricos. |
| Limitações do banco de dados |
Para outros tipos de fonte de dados, é possível extrair os dados para um arquivo de extração para usar essa função. Consulte Extrair seus dados(O link abre em nova janela). |
MIN
| Sintaxe | MIN(expression) ou MIN(expr1, expr2) |
| Saída | Mesmo tipo de dados do argumento ou NULL se alguma parte do argumento for nula. |
| Definição | Retorna, no mínimo, dois argumentos, que devem ser do mesmo tipo de dados.
|
| Exemplo | MIN(4,7) = 4 |
| Observações | Para cadeia de caracteres
Para fontes de dados de bancos de dados, o valor de cadeia de caracteres Para datas Para datas, o Como uma agregação
Como comparação
Consulte também |
PERCENTILE
| Sintaxe | PERCENTILE(expression, number) |
| Definição | Retorna o valor percentil da expressão indicada correspondente ao <number> especificado. O <number> deve estar entre 0 e 1 (inclusive) e deve ser uma constante numérica. |
| Exemplo | PERCENTILE([Score], 0.9) |
| Limitações do banco de dados | Esta função está disponível para as seguintes fontes de dados: conexões não legadas do Microsoft Excel e de arquivo de texto, extrações e tipos de fontes de dados somente de extração (por exemplo, Google Analytics, OData ou Salesforce), fontes de dados Sybase IQ 15.1 e posteriores, fontes de dados Oracle 10 e posteriores, fontes de dados Cloudera Hive e Hortonworks Hadoop Hive, fontes de dados EXASolution 4.2 e posteriores. Para outros tipos de fonte de dados, é possível extrair os dados para um arquivo de extração para usar essa função. Consulte Extrair seus dados(O link abre em nova janela). |
STDEV
| Sintaxe | STDEV(expression) |
| Definição | Retorna o desvio padrão estatístico de todos os valores na expressão atribuída com base em uma amostra da população. |
STDEVP
| Sintaxe | STDEVP(expression) |
| Definição | Retorna o desvio padrão estatístico de todos os valores na expressão atribuída com base em uma tendência de população. |
SUM
| Sintaxe | SUM(expression) |
| Definição | Retorna a soma de todos os valores na expressão. Os valores nulos são ignorados. |
| Observações | SUM pode ser usado apenas com campos numéricos. |
VAR
| Sintaxe | VAR(expression) |
| Definição | Retorna a variação estatística de todos os valores na expressão atribuída com base em uma amostra da população. |
VARP
| Sintaxe | VARP(expression) |
| Definição | Retorna a variação estatística de todos os valores na expressão atribuída com base na população inteira. |
FULLNAME( )
| Sintaxe | FULLNAME( ) |
| Saída | Cadeia de caracteres |
| Definição | Retorna o nome completo do usuário atual. |
| Exemplo | FULLNAME( ) Isso retorna o nome completo do usuário conectado, como "Hamlin Myrer". [Manager] = FULLNAME( ) Se o gerente "Hamlin Myrer" estiver conectado, este exemplo retornará TRUE se o campo Gerente da exibição contiver "Hamlin Myrer". |
| Observações | Esta função verifica:
Filtros de usuário Quando usado como um filtro, esse campo calculado, como |
ISFULLNAME
| Sintaxe | ISFULLNAME("User Full Name") |
| Saída | Booleano |
| Definição | Retorna |
| Exemplo | ISFULLNAME("Hamlin Myrer") |
| Observações | O argumento Esta função verifica:
|
ISMEMBEROF
| Sintaxe | ISMEMBEROF("Group Name") |
| Saída | Booleano ou nulo |
| Definição | Retorna |
| Exemplo | ISMEMBEROF('Superstars')ISMEMBEROF('domain.lan\Sales') |
| Observações | O argumento Se o usuário estiver conectado ao Tableau Cloud ou Tableau Server, a associação ao grupo é determinada pelos grupos do Tableau. A função retornará TRUE se a cadeia de caracteres fornecida for "Todos os usuários" A função Se for feita uma alteração na associação ao grupo de um usuário, a alteração nos dados baseados na associação ao grupo será refletida em uma pasta de trabalho ou exibição com uma nova sessão. A sessão existente refletirá dados obsoletos. |
ISUSERNAME
| Sintaxe | ISUSERNAME("username") |
| Saída | Booleano |
| Definição | Retorna TRUE se o nome de usuário do usuário atual coincide com o nome de usuário especificado ou FALSE se não coincide. |
| Exemplo | ISUSERNAME("hmyrer") |
| Observações | O argumento Esta função verifica:
|
USERDOMAIN( )
| Sintaxe | USERDOMAIN( ) |
| Saída | Cadeia de caracteres |
| Definição | Retorna o domínio de usuário do usuário atual. |
| Observações | Esta função verifica:
|
USERNAME( )
| Sintaxe | USERNAME( ) |
| Saída | Cadeia de caracteres |
| Definição | Retorna o nome de usuário do usuário atual. |
| Exemplo | USERNAME( ) Isso retorna o nome do usuário do usuário conectado, como "hmyrer". [Manager] = USERNAME( ) Se o gerente "hmyrer" estiver conectado, este exemplo retornará TRUE se o campo Gerente da exibição contiver "hmyrer". |
| Observações | Esta função verifica:
Filtros de usuário Quando usado como um filtro, esse campo calculado, como |
USERATRIBUTE
Observação: antes usar esta função, consulte Funções de atributo do usuário para controlar e personalizar o acesso a dados. Para obter mais informações, dependendo do seu fluxo de trabalho, consulte os tópicos Autenticação e Exibições inseridas(O link abre em nova janela) na Ajuda de Embedding API v3, os tópicos OIDC(O link abre em nova janela) ou SAML(O link abre em nova janela) no Tableau Cloud ou os tópicos OIDC(O link abre em nova janela) ou SAML(O link abre em nova janela) no Tableau Server.
| Sintaxe | USERATTRIBUTE('attribute_name') |
| Saída | Cadeia de caracteres ou nulo |
| Definição | Se Retorna nulo se |
| Exemplo | Suponha que “Region” seja o atributo de usuário incluído no JWT ou na resposta SAML e passado para o Tableau. Como autor da pasta de trabalho, você pode configurar sua visualização para filtrar dados com base em uma região especificada. Nesse filtro, você pode fazer referência ao seguinte cálculo. [Region] = USERATTRIBUTE("Region")Quando User2, da região oeste, exibe a visualização incorporada, o Tableau mostra os dados apropriados apenas para a região oeste. |
| Observações | Você pode usar a função USERATTRIBUTEINCLUDES se espera que <'attribute_name'> retorne vários valores. |
USERATTRIBUTEINCLUDES
Observação: antes usar esta função, consulte Funções de atributo do usuário para controlar e personalizar o acesso a dados. Para obter mais informações, dependendo do seu fluxo de trabalho, consulte os tópicos Autenticação e Exibições inseridas(O link abre em nova janela) na Ajuda de Embedding API v3, os tópicos OIDC(O link abre em nova janela) ou SAML(O link abre em nova janela) no Tableau Cloud ou os tópicos OIDC(O link abre em nova janela) ou SAML(O link abre em nova janela) no Tableau Server.
| Sintaxe | USERATTRIBUTEINCLUDES('attribute_name', 'expected_value') |
| Saída | Booleano |
| Definição | Retorna
Caso contrário, retorna |
| Exemplo | Suponha que “Region” seja o atributo de usuário incluído no JWT ou na resposta SAML e passado para o Tableau. Como autor da pasta de trabalho, você pode configurar sua visualização para filtrar dados com base em uma região especificada. Nesse filtro, você pode fazer referência ao seguinte cálculo. USERATTRIBUTEINCLUDES('Region', [Region])Se User2 da região Oeste acessar a visualização inserida, o Tableau verificará se o atributo de usuário Region corresponde a um dos valores do campo [Region]. Quando true, a visualização mostra os dados apropriados. Quando User3 da região Norte acessa a mesma visualização, ela não consegue ver nenhum dado porque não há correspondência com os valores do campo [Região]. |
FIRST( )
Retorna o número de linhas da linha atual até a primeira linha na partição. Por exemplo, a exibição a seguir mostra as vendas trimestrais. Quando FIRST() é calculado na partição Date, a compensação da primeira linha em relação à segunda linha é -1.
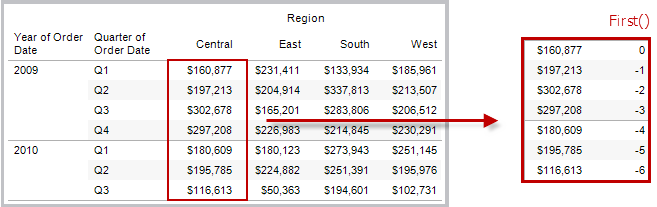
Exemplo
Quando o índice de linha atual for 3, FIRST()
= -2.
INDEX( )
Retorna o índice da linha atual na partição, sem qualquer classificação em relação ao valor. O índice da primeira linha começa em 1. Por exemplo, a tabela a seguir mostra as vendas trimestrais. Quando INDEX() é calculada na partição Date, o índice de cada linha é 1, 2, 3, 4..., etc.

Exemplo
Para a terceira linha na partição, INDEX() = 3.
LAST( )
Retorna o número de linhas da linha atual até a última linha na partição. Por exemplo, a tabela a seguir mostra as vendas trimestrais. Quando LAST() é calculado na partição Date, a compensação da última linha em relação à segunda linha é 5.

Exemplo
Quando o índice de linha atual for 3 de 7, LAST() = 4.
LOOKUP(expression, [offset])
Retorna o valor da expressão em uma linha de destino, especificada como uma compensação relativa da linha atual. Use FIRST() + n e LAST() - n como parte de sua definição de deslocamento para um destino relativo à primeira/última linha da partição. Se offset for omitido, a linha para comparação poderá ser definida no menu de campo. Esta função retornará NULL se a linha de destino não puder ser determinada.
A exibição a seguir mostra as vendas trimestrais. Quando LOOKUP (SUM(Sales), 2) é calculado na partição Date, cada linha mostra o valor de vendas de 2 trimestres no futuro.

Exemplo
LOOKUP(SUM([Profit]),
FIRST()+2) calcula SUM(Profit) na terceira linha da partição.
Funções MODEL_EXTENSION
As funções de extensão do modelo:
MODEL_EXTENSION_BOOL
MODEL_EXTENSION_INT
MODEL_EXTENSION_REAL
MODEL_EXTENSION_STRING
são usadas para passar dados para um modelo implantado em um serviço externo, como R, TabPy ou Matlab. Consulte Extensões do Analytics(O link abre em nova janela).
MODEL_PERCENTILE(target_expression, predictor_expression(s))
Retorna a probabilidade (entre 0 e 1) do valor esperado ser menor ou igual à marca observada, definida pela expressão-alvo e outros preditores. Esta é a Função de Distribuição Preditiva Posterior, também conhecida como Função de Distribuição Cumulativa (CDF).
Esta função é o inverso de MODEL_QUANTILE. Para obter informações sobre funções de modelagem preditiva, consulte Como funcionam as funções de modelagem preditiva no Tableau.
Exemplo
A fórmula a seguir devolve o quantil da marca para a soma das vendas, ajustada para contagem de pedidos.
MODEL_PERCENTILE(SUM([Sales]), COUNT([Orders]))
MODEL_QUANTILE(quantile, target_expression, predictor_expression(s))
Retorna um valor numérico de destino dentro do intervalo provável definido pela expressão de destino e outros preditores, em um quantil especificado. Este é o Quantil Preditivo Posterior.
Esta função é o inverso de MODEL_PERCENTILE. Para obter informações sobre funções de modelagem preditiva, consulte Como funcionam as funções de modelagem preditiva no Tableau.
Exemplo
A fórmula a seguir retorna a mediana (0,5) da soma prevista de vendas, ajustada para contagem de pedidos.
MODEL_QUANTILE(0.5, SUM([Sales]), COUNT([Orders]))
PREVIOUS_VALUE(expression)
Retorna o valor desse cálculo na linha anterior. Retornará a expressão especificada se a linha atual for a primeira linha da partição.
Exemplo
SUM([Profit]) * PREVIOUS_VALUE(1) calcula o produto em execução de SUM(Profit).
RANK(expression, ['asc' | 'desc'])
Retorna a posição na classificação da concorrência padrão para a linha atual da partição. Valores idênticos são colocados em uma posição na classificação idêntica. Use o argumento opcional 'asc' | 'desc' para especificar a ordem crescente ou decrescente. O padrão é decrescente.
Com esta função, o conjunto de valores (6, 9, 9, 14) seria classificado (4, 2, 2, 1).
Os nulos são ignorados em funções de classificação. Eles não são numerados e não são contabilizados para o número total de registros em cálculos de posição na classificação percentil.
Para obter informações sobre opções de classificação diferentes, consulte Cálculo da posição na classificação.
Exemplo
A imagem a seguir mostra o efeito das várias funções de classificação (RANK, RANK_DENSE, RANK_MODIFIED, RANK_PERCENTILE e RANK_UNIQUE) sobre um conjunto de valores. O conjunto de dados contém informações sobre 14 alunos (do Aluno A até Aluno N); a coluna Idade mostra a idade atual de cada aluno (todos os alunos são entre 17 e 20 anos). As colunas restantes mostram o efeito de cada função do ranking no conjunto de valores de idade, sempre assumindo a ordem padrão (ascendente ou descendente) para a função.
![]()
RANK_DENSE(expression, ['asc' | 'desc'])
Retorna a posição na classificação densa para a linha atual na partição. Para valores idênticos, são atribuídos uma mesma posição na classificação, mas nenhuma lacuna é inserida na sequência numérica. Use o argumento opcional 'asc' | 'desc' para especificar a ordem crescente ou decrescente. O padrão é decrescente.
Com esta função, o conjunto de valores (6, 9, 9, 14) seria classificado (3, 2, 2, 1).
Os nulos são ignorados em funções de classificação. Eles não são numerados e não são contabilizados para o número total de registros em cálculos de posição na classificação percentil.
Para obter informações sobre opções de classificação diferentes, consulte Cálculo da posição na classificação.
RANK_MODIFIED(expression, ['asc' | 'desc'])
Retorna a posição na classificação da concorrência modificada para a linha atual na partição. Valores idênticos são colocados em uma posição na classificação idêntica. Use o argumento opcional 'asc' | 'desc' para especificar a ordem crescente ou decrescente. O padrão é decrescente.
Com esta função, o conjunto de valores (6, 9, 9, 14) seria classificado (4, 3, 3, 1).
Os nulos são ignorados em funções de classificação. Eles não são numerados e não são contabilizados para o número total de registros em cálculos de posição na classificação percentil.
Para obter informações sobre opções de classificação diferentes, consulte Cálculo da posição na classificação.
RANK_PERCENTILE(expression, ['asc' | 'desc'])
Retorna a posição na classificação percentil para a linha atual na partição. Use o argumento opcional 'asc' | 'desc' para especificar a ordem crescente ou decrescente. O padrão é crescente.
Com esta função, o conjunto de valores (6, 9, 9, 14) seria classificado (0,00, 0,67, 0,67, 1,00).
Os nulos são ignorados em funções de classificação. Eles não são numerados e não são contabilizados para o número total de registros em cálculos de posição na classificação percentil.
Para obter informações sobre opções de classificação diferentes, consulte Cálculo da posição na classificação.
RANK_UNIQUE(expression, ['asc' | 'desc'])
Retorna a posição na classificação exclusiva para a linha atual na partição. Para valores idênticos, são atribuídas diferentes posições na classificação. Use o argumento opcional 'asc' | 'desc' para especificar a ordem crescente ou decrescente. O padrão é decrescente.
Com esta função, o conjunto de valores (6, 9, 9, 14) seria classificado (4, 2, 3, 1).
Os nulos são ignorados em funções de classificação. Eles não são numerados e não são contabilizados para o número total de registros em cálculos de posição na classificação percentil.
Para obter informações sobre opções de classificação diferentes, consulte Cálculo da posição na classificação.
RUNNING_AVG(expression)
Retorna a média em execução da expressão especificada a partir da primeira linha na partição para a linha atual.
A exibição a seguir mostra as vendas trimestrais. Quando RUNNING_AVG(SUM([Sales]) é calculado na partição Date, o resultado é uma média em execução dos valores de vendas de cada trimestre.

Exemplo
RUNNING_AVG(SUM([Profit])) calcula a média em execução de SUM(Profit).
RUNNING_COUNT(expression)
Retorna a contagem em execução da expressão especificada a partir da primeira linha na partição para a linha atual.
Exemplo
RUNNING_COUNT(SUM([Profit])) calcula a contagem em execução de SUM(Profit).
RUNNING_MAX(expression)
Retorna o máximo em execução da expressão especificada a partir da primeira linha na partição para a linha atual.

Exemplo
RUNNING_MAX(SUM([Profit])) calcula o máximo em execução de SUM(Profit).
RUNNING_MIN(expression)
Retorna o mínimo em execução da expressão especificada a partir da primeira linha na partição para a linha atual.

Exemplo
RUNNING_MIN(SUM([Profit])) calcula o mínimo em execução de SUM(Profit).
RUNNING_SUM(expression)
Retorna a soma em execução da expressão especificada a partir da primeira linha na partição para a linha atual.

Exemplo
RUNNING_SUM(SUM([Profit])) calcula a soma em execução de SUM(Profit)
SIZE()
Retorna o número de linhas na partição. Por exemplo, a exibição a seguir mostra as vendas trimestrais. Na partição Date, há sete linhas, portanto, o Size() da partição Date é 7.

Exemplo
SIZE() = 5 quando a partição atual contém cinco linhas.
Funções SCRIPT_
As funções script:
SCRIPT_BOOL
SCRIPT_INT
SCRIPT_REAL
SCRIPT_STRING
são usadas para passar dados para um serviço externo, como R, TabPy ou Matlab. Consulte Extensões do Analytics(O link abre em nova janela).
TOTAL(expression)
Retorna o número total da expressão fornecida em uma divisão do cálculo de tabela.
Exemplo
Suponha que você está começando com esta exibição:

Você abre o editor de cálculo e cria um novo campo nomeado de Totalidade:

Em seguida, solte o campo Totalidade em Texto para substituir SUM(Sales). Suas exibições são alteradas de tal forma, que ela soma os valores com base no valor padrão de Calcular usando:

Isso levanta a questão, qual é o valor padrão de Calcular usando? Se você clicar com o botão direito do mouse (clique pressionando a tecla Control, no Mac) na Totalidade, no painel de Dados, e escolher Editar, haverá um pouco de informação adicional disponível:

O valor padrão de Calcular usando é uma Tabela (horizontal). O resultado é que a Totalidade é soma dos valores em cada linha da tabela. Assim, o valor visualizado em cada linha é a soma dos valores da versão original da tabela.
Os valores na linha 2011/Q1 na tabela original foram de US$ 8.601,00; US$ 6.579,00; US$ 44.262,00; e US$ 15.006,00. Os valores na tabela após a Totalidade substituem a SUM(Sales) com um total de US $74.448,00; que é a soma dos quatro valores originais.
Observe o triângulo ao lado de Totalidade depois de soltá-lo em Texto:

Isso indica que este campo está usando um cálculo de tabela. Você pode clicar com o botão direito do mouse no campo e escolher Editar o cálculo de tabela para redirecionar a sua função para um valor de Calcular usando diferente. Por exemplo, você pode defini-lo para Tabela (vertical). Nesse caso, a tabela ficaria assim:

TOTAL(expression)
Retorna o número total da expressão fornecida em uma divisão do cálculo de tabela.
Exemplo
Suponha que você está começando com esta exibição:
Você abre o editor de cálculo e cria um novo campo nomeado de Totalidade:
Em seguida, solte o campo Totalidade em Texto para substituir SUM(Sales). Suas exibições são alteradas de tal forma, que ela soma os valores com base no valor padrão de Calcular usando:
Isso levanta a questão, qual é o valor padrão de Calcular usando? Se você clicar com o botão direito do mouse (clique pressionando a tecla Control, no Mac) na Totalidade, no painel de Dados, e escolher Editar, haverá um pouco de informação adicional disponível:
O valor padrão de Calcular usando é uma Tabela (horizontal). O resultado é que a Totalidade é soma dos valores em cada linha da tabela. Assim, o valor visualizado em cada linha é a soma dos valores da versão original da tabela.
Os valores na linha 2011/Q1 na tabela original foram de US$ 8.601,00; US$ 6.579,00; US$ 44.262,00; e US$ 15.006,00. Os valores na tabela após a Totalidade substituem a SUM(Sales) com um total de US $74.448,00; que é a soma dos quatro valores originais.
Observe o triângulo ao lado de Totalidade depois de soltá-lo em Texto:
Isso indica que este campo está usando um cálculo de tabela. Você pode clicar com o botão direito do mouse no campo e escolher Editar o cálculo de tabela para redirecionar a sua função para um valor de Calcular usando diferente. Por exemplo, você pode defini-lo para Tabela (vertical). Nesse caso, a tabela ficaria assim:
WINDOW_AVG(expression, [start, end])
Retorna a média da expressão na janela. A janela é definida como desvios em relação à linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Há uma função de agregação equivalente: AVG. Consulte Funções do Tableau (em ordem alfabética)(O link abre em nova janela).
Exemplo
A fórmula a seguir retorna a média de janela de SUM(Profit) das duas linhas anteriores à linha atual.
WINDOW_AVG(SUM[Profit]), -2, 0)
WINDOW_CORR(expression1, expression2, [start, end])
Retorna o coeficiente de correlação Pearson de duas expressões dentro da janela. A janela é definida como desvios em relação à linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
A correlação Pearson mede a relação linear entre duas variáveis. Os resultados variam de -1 a +1 inclusive, em que 1 denota uma relação linear positiva e exata, quando uma alteração positiva em uma variável implica na alteração positiva da magnitude correspondente da outra variável, 0 denota nenhuma relação linear entre a variância e −1 é uma relação negativa exata.
Há uma função de agregação equivalente: CORR. Consulte Funções do Tableau (em ordem alfabética)(O link abre em nova janela).
Exemplo
A fórmula a seguir retorna a correlação Pearson de SUM(Profit) e SUM(Sales) das cinco linhas anteriores à linha atual.
WINDOW_CORR(SUM[Profit]), SUM([Sales]), -5, 0)
WINDOW_COUNT(expression, [start, end])
Retorna a contagem da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Exemplo
WINDOW_COUNT(SUM([Profit]), FIRST()+1, 0) calcula a contagem de SUM(Profit) a partir da segunda linha até a linha atual
WINDOW_COVAR(expression1, expression2, [start, end])
Retorna a covariância de amostra de duas expressões dentro da janela. A janela é definida como desvios em relação à linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se os argumentos iniciais e finais forem omitidos, a janela será toda a partição.
A covariância de amostra usa o número de pontos de dados não nulos, n - 1, para normalizar o cálculo da covariância, em vez de n, que é usado pela covariância populacional (disponível com a função WINDOWS_COVARP). A covariância de amostra é a escolha apropriada quando os dados são uma amostra aleatória sendo usada para estimar a covariância de uma população maior.
Há uma função de agregação equivalente: COVAR. Consulte Funções do Tableau (em ordem alfabética)(O link abre em nova janela).
Exemplo
A fórmula a seguir retorna a covariância de amostra de SUM(Profit) e SUM(Sales) das duas linhas anteriores à linha atual.
WINDOW_COVAR(SUM([Profit]), SUM([Sales]), -2, 0)
WINDOW_COVARP(expression1, expression2, [start, end])
Retorna a covariância populacional de duas expressões dentro da janela. A janela é definida como desvios em relação à linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
A covariância populacional é a covariância de amostra multiplicada por (n-1)/n, em que n é o número total de pontos de dados não nulos. A covariância populacional é a escolha apropriada quando há dados disponíveis para todos os itens de interesse, ao invés de somente um subconjunto aleatório de itens, em que a covariância de amostra (com a função WINDOWS_COVAR) é apropriada.
Há uma função de agregação equivalente: COVARP. Funções do Tableau (em ordem alfabética)(O link abre em nova janela)
Exemplo
A fórmula a seguir retorna a covariância populacional de SUM(Profit) e SUM(Sales) das duas linhas anteriores à linha atual.
WINDOW_COVARP(SUM([Profit]), SUM([Sales]), -2, 0)
WINDOW_MEDIAN(expression, [start, end])
Retorna o mediano da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Por exemplo, a exibição a seguir mostra o lucro trimestral. Um mediano de janela na partição Date retorna o lucro médio em todas as datas.

Exemplo
WINDOW_MEDIAN(SUM([Profit]), FIRST()+1, 0) calcula o mediano de SUM(Profit) a partir da segunda linha até a linha atual.
WINDOW_MAX(expression, [start, end])
Retorna o máximo da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Por exemplo, a exibição a seguir mostra as vendas trimestrais. Uma máxima de janela na partição Date retorna o máximo de vendas em todas as datas.

Exemplo
WINDOW_MAX(SUM([Profit]), FIRST()+1, 0) calcula o máximo de SUM(Profit) a partir da segunda linha até a linha atual.
WINDOW_MIN(expression, [start, end])
Retorna o mínimo da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Por exemplo, a exibição a seguir mostra as vendas trimestrais. Um mínimo de janela na partição Date retorna o mínimo de vendas em todas as datas.

Exemplo
WINDOW_MIN(SUM([Profit]), FIRST()+1, 0) calcula o mínimo de SUM(Profit) a partir da segunda linha até a linha atual.
WINDOW_PERCENTILE(expression, number, [start, end])
Retorna o valor correspondente ao percentil especificado dentro da janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Exemplo
WINDOW_PERCENTILE(SUM([Profit]), 0.75, -2, 0) retorna o 75º percentil para SUM(Profit) das duas linhas anteriores para a linha atual.
WINDOW_STDEV(expression, [start, end])
Retorna o desvio padrão de exemplo da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Exemplo
WINDOW_STDEV(SUM([Profit]), FIRST()+1, 0) calcula o desvio padrão de SUM(Profit) a partir da segunda linha até a linha atual.
WINDOW_STDEVP(expression, [start, end])
Retorna o desvio padrão tendencioso da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Exemplo
WINDOW_STDEVP(SUM([Profit]), FIRST()+1, 0) calcula o desvio padrão de SUM(Profit) a partir da segunda linha até a linha atual.
WINDOW_SUM(expression, [start, end])
Retorna a soma da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Por exemplo, a exibição a seguir mostra as vendas trimestrais. Uma soma de janela na partição Date retorna a soma de vendas em todos os trimestres.

Exemplo
WINDOW_SUM(SUM([Profit]), FIRST()+1, 0) calcula a soma de SUM(Profit) a partir da segunda linha até a linha atual.
WINDOW_VAR(expression, [start, end])
Retorna a variação da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Exemplo
WINDOW_VAR((SUM([Profit])), FIRST()+1, 0) calcula a variância de SUM(Profit) a partir da segunda linha até a linha atual.
WINDOW_VARP(expression, [start, end])
Retorna a variação tendenciosa da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Exemplo
WINDOW_VARP(SUM([Profit]), FIRST()+1, 0) calcula a variância de SUM(Profit) a partir da segunda linha até a linha atual.
As funções de passagem RAWSQL enviam expressões SQL diretamente ao banco de dados, sem serem interpretadas pelo Tableau. Se houver funções de banco de dados personalizadas que o Tableau não conheça, você poderá usar as funções de passagem para chamar essas funções personalizadas.
Como o Tableau não interpreta a expressão, você deve definir a agregação quando necessário. Você poderá usar a versão RAWSQLAGG de uma função quando precisar passar uma expressão agregada.
As funções de passagem RAWSQL podem não funcionar com fontes de dados federadas (combinadas em diferentes bancos de dados) ou publicadas.
Sintaxe RAWSQL
As funções RAWSQL têm dois tipos: desagregada e agregada. Isso é especificado na primeira parte do nome da função, RAWSQL ou RAWSQLAGG. A parte final do nome da função é o tipo de saída, como BOOL, STR ou INT. Em todas as funções RAWSQL, o argumento é "sql_expr", [arg1], ...[arg2]. Ao escrever a função, você pode usar uma sintaxe de substituição %n para inserir o nome do campo ou a expressão correta.
Sintaxe de substituição %n
Normalmente, seu banco de dados não entenderá os nomes de campo mostrados no Tableau. Como o Tableau não interpreta as expressões SQL nas funções de passagem, o uso de nomes de campo do Tableau na sua expressão pode causar erros. Use %n para inserir o nome do campo ou a expressão correta para um cálculo do Tableau no SQL de passagem.
Por exemplo, se você tivesse uma função que calculasse o mediano de um conjunto de valores, você poderia chamar essa função na coluna [Sales] do Tableau, desta forma:
RAWSQLAGG_REAL("MEDIAN(%1)", [Sales])REALSQLAGGporque você deseja especificar a agregação.REALporque a saída é numérica e não necessariamente um inteiro.MEDIANé a agregação.%1é o espaço reservado para[Sales].
Funções RAWSQL
A expressão SQL é passada diretamente ao banco de dados subjacente. Use %n na expressão SQL como uma sintaxe substituta para os valores de banco de dados.
As seguintes funções RAWSQL estão disponíveis no Tableau:
RAWSQL_BOOL
| Sintaxe | RAWSQL_BOOL("sql_expr", [arg1], …[argN]) |
| Saída | Booleano |
| Definição | Retorna um resultado booliano de uma determinada expressão SQL. |
| Exemplo | RAWSQL_BOOL("%1 > %2", [Sales], [Profit])No exemplo, %1 é igual a [Sales] e %2 é igual a [Profit]. |
RAWSQLAGG_BOOL
| Sintaxe | RAWSQLAGG_BOOL("sql_expr", [arg1], …[argN]) |
| Saída | Booleano |
| Definição | Retorna um resultado booliano de uma determinada expressão SQL de agregação. |
| Exemplo | RAWSQLAGG_BOOL("SUM( %1) >SUM( %2)", [Sales], [Profit]) No exemplo, %1 é igual a [Sales] e %2 é igual a [Profit]. |
RAWSQL_DATE
| Sintaxe | RAWSQL_DATE("sql_expr", [arg1], …[argN]) |
| Saída | Data |
| Definição | Retorna um resultado de data de uma determinada expressão SQL. |
| Exemplo | RAWSQL_DATE("%1", [Order Date])Neste exemplo, %1 é igual a [Order Date]. |
RAWSQLAGG_DATE
| Sintaxe | RAWSQLAGG_DATE("sql_expr", [arg1], …[argN]) |
| Saída | Data |
| Definição | Retorna um resultado de data de uma determinada expressão SQL de agregação |
| Exemplo | RAWSQLAGG_DATE("MAX(%1)", [Order Date])Neste exemplo, %1 é igual a [Order Date]. |
RAWSQL_DATETIME
| Sintaxe | RAWSQL_DATETIME("sql_expr", [arg1], …[argN]) |
| Saída | Datetime |
| Definição | Retorna um resultado de data e hora de uma determinada expressão SQL. |
| Exemplo | RAWSQL_DATETIME("%1", [Order Date])Neste exemplo, %1 é igual a [Order Date]. |
RAWSQLAGG_DATETIME
| Sintaxe | RAWSQLAGG_DATETIME("sql_expr", [arg1], …[argN]) |
| Saída | Datetime |
| Definição | Retorna um resultado de data e hora de uma determinada expressão SQL de agregação. |
| Exemplo | RAWSQLAGG_DATETIME("MIN(%1)", [Order Date])Neste exemplo, %1 é igual a [Order Date]. |
RAWSQL_INT
| Sintaxe | RAWSQL_INT("sql_expr", [arg1], …[argN]) |
| Saída | Inteiro |
| Definição | Retorna um resultado de inteiro de uma determinada expressão SQL. |
| Exemplo | RAWSQL_INT("500 + %1", [Sales])Neste exemplo, %1 é igual a [Sales]. |
RAWSQLAGG_INT
| Sintaxe | RAWSQLAGG_INT("sql_expr", [arg1,] …[argN]) |
| Saída | Inteiro |
| Definição | Retorna um resultado de inteiro de uma determinada expressão SQL de agregação. |
| Exemplo | RAWSQLAGG_INT("500 + SUM(%1)", [Sales])Neste exemplo, %1 é igual a [Sales]. |
RAWSQL_REAL
| Sintaxe | RAWSQL_REAL("sql_expr", [arg1], …[argN]) |
| Saída | Numérico |
| Definição | Retorna um resultado numérico de uma determinada expressão SQL. |
| Exemplo | RAWSQL_REAL("-123.98 * %1", [Sales])Neste exemplo, %1 é igual a [Sales] |
RAWSQLAGG_REAL
| Sintaxe | RAWSQLAGG_REAL("sql_expr", [arg1,] …[argN]) |
| Saída | Numérico |
| Definição | Retorna um resultado numérico de uma determinada expressão SQL de agregação. |
| Exemplo | RAWSQLAGG_REAL("SUM( %1)", [Sales])Neste exemplo, %1 é igual a [Sales]. |
RAWSQL_SPATIAL
| Sintaxe | RAWSQL_SPATIAL("sql_expr", [arg1], …[argN]) |
| Saída | Espacial |
| Definição | Retorna um resultado espacial de uma determinada expressão SQL. |
| Exemplo | RAWSQL_SPATIAL("%1", [Geometry])Neste exemplo, %1 é igual a [Geometry]. |
| Observação | Não há a versão RAWSQLAGG desta função. |
RAWSQL_STR
| Sintaxe | RAWSQL_STR("sql_expr", [arg1], …[argN]) |
| Saída | Cadeia de caracteres |
| Definição | Retorna uma cadeia de caracteres de uma determinada expressão SQL. |
| Exemplo | RAWSQL_STR("%1", [Customer Name])Neste exemplo, %1 é igual a [Customer Name]. |
RAWSQLAGG_STR
| Sintaxe | RAWSQLAGG_STR("sql_expr", [arg1,] …[argN]) |
| Saída | Cadeia de caracteres |
| Definição | Retorna uma cadeia de caracteres de uma determinada expressão SQL de agregação. |
| Exemplo | RAWSQLAGG_STR("AVG(%1)", [Discount])Neste exemplo, %1 é igual a [Discount]. |
As funções espaciais permitem executar a análise espacial avançada e combinar arquivos espaciais com dados em outros formatos, como arquivos de texto ou planilhas.
ÁREA
| Sintaxe | AREA(Spatial Polygon, 'units') |
| Saída | Número |
| Definição | Retorna a área total da superfície de um <spatial polygon>. |
| Exemplo | AREA([Geometry], 'feet') |
| Observações | Nomes de unidades aceitas (devem estar entre aspas no cálculo, como
|
BUFFER
| Sintaxe | BUFFER(Spatial point, distance, 'units')
|
| Saída | Geometria |
| Definição | Para pontos espaciais, retorna uma forma poligonal centrada sobre um Para cadeias de caracteres de linhas, calcula os polígonos formados incluindo todos os pontos dentro da distância do raio da cadeia de caracteres de linhas. Para polígonos, calcula um polígono que é um recuo (distância negativa) ou um avanço (distância positiva) de cada polígono fornecido. |
| Exemplo | BUFFER([Spatial Point Geometry], 25, 'mi') BUFFER(MAKEPOINT(47.59, -122.32), 3, 'km') BUFFER(MAKELINE(MAKEPOINT(0, 20),MAKEPOINT (30, 30)),20,'km')) |
| Observações | Nomes de unidades aceitas (devem estar entre aspas no cálculo, como
|
DIFFERENCE
| Sintaxe | DIFFERENCE(Spatial, Spatial) |
| Saída | Polígono espacial |
| Definição | Calcula as porções de regiões restantes quando todas as regiões no segundo argumento são extraídas do primeiro argumento em áreas que se sobrepõem. Descarta regiões do segundo argumento em áreas que não se sobrepõem. |
| Exemplo | DIFFERENCE(Spatial Polygon1, Spatial Polygon2) |
| Observações | Aceita polígonos e multipolígonos espaciais, pontos ou linhas não espaciais. |
DISTÂNCIA
| Sintaxe | DISTANCE(SpatialPoint1, SpatialPoint2, 'units') |
| Saída | Número |
| Definição | Retorna a medida da distância entre dois pontos na <unit> especificada. |
| Exemplo | DISTANCE([Origin Point],[Destination Point], 'km') |
| Observações | Nomes de unidades aceitas (devem estar entre aspas no cálculo, como
|
| Limitações do banco de dados | Essa função só pode ser criada com uma conexão em tempo real, mas continuará a funcionar se uma fonte de dados for convertida em uma extração. |
INTERSECTION
| Sintaxe | INTERSECTION (spatial, spatial) |
| Saída | Polígono |
| Definição | Calcula e retorna as partes de regiões no segundo argumento que se sobrepõem às regiões no primeiro argumento. |
| Exemplo | INTERSECTION (Spatial Polygon1, Spatial Polygon2) |
| Observações | Aceita polígonos e multipolígonos espaciais, pontos ou linhas não espaciais. |
INTERSECTS
| Sintaxe | INTERSECTS (geometry1, geometry2) |
| Saída | Booliano |
| Definição | Retorna true ou false indicando se duas geometrias se sobrepõem no espaço. |
| Observações | Combinações suportadas: ponto/polígono, linha/polígono e polígono/polígono. |
MAKELINE
| Sintaxe | MAKELINE(SpatialPoint1, SpatialPoint2) |
| Saída | Geometria (linha) |
| Definição | Gera uma marca de linha entre dois pontos |
| Exemplo | MAKELINE(MAKEPOINT(47.59, -122.32), MAKEPOINT(48.5, -123.1)) |
| Observações | Útil para construir mapas de origem-destino. |
MAKEPOINT
| Sintaxe | MAKEPOINT(latitude, longitude, [SRID]) |
| Saída | Geometria (ponto) |
| Definição | Converte dados das colunas Se o argumento opcional |
| Exemplo | MAKEPOINT(48.5, -123.1) MAKEPOINT([AirportLatitude], [AirportLongitude]) MAKEPOINT([Xcoord],[Ycoord], 3493) |
| Observações |
Você pode usar o |
LENGTH
| Sintaxe | LENGTH(geometry, 'units') |
| Saída | Número |
| Definição | Retorna o comprimento do caminho geodésico da sequência de linhas ou sequências no <geometry> usando <units> fornecido. |
| Exemplo | LENGTH([Spatial], 'metres') |
| Observações | O resultado será <NaN> se o argumento de geometria não tiver cadeias de linha, embora outros elementos sejam permitidos. |
OUTLINE
| Sintaxe | OUTLINE(spatial polygon) |
| Saída | Geometria |
| Definição | Converte uma geometria poligonal em cadeias de linhas. |
| Observações | Útil para criar uma camada separada para um contorno que pode ter um estilo diferente do preenchimento. Aceita polígonos dentro de multipolígonos. |
SHAPETYPE
| Sintaxe | SHAPETYPE(geometry) |
| Saída | Cadeia de caracteres |
| Definição | Retorna uma cadeia de caracteres descrevendo a estrutura do espaço <geometry>, como Empty, Point, MultiPoint, LineString, MultiLinestring, Polygon, MultiPolygon, Mixed e unsupported (Vazio, Ponto, Multiponto, Cadeia de caracteres de linha, Cadeia de caracteres de várias linhas, Polígono, VáriosPolígonos, Combinado e sem suporte). |
| Exemplo | SHAPETYPE(MAKEPOINT(48.5, -123.1)) = "Point" |
SYMDIFFERENCE
| Sintaxe | SYMDIFFERENCE(spatial, spatial) |
| Saída | Geometria |
| Definição | Calcula quaisquer porções de regiões do segundo argumento que se sobrepõem às regiões do primeiro argumento e descarta ambas. Retorna as porções restantes das regiões de ambos os argumentos. |
| Exemplo |
|
VALIDATE
| Sintaxe | VALIDATE(spatial geometry) |
| Saída | Geometria |
| Definição | Confirma a correção topológica da geometria no seu valor espacial. Se o valor não puder ser usado para análise devido a problemas como o perímetro de um polígono se cruzando, o resultado será nulo. Se a geometria estiver correta, o resultado será a geometria original. |
| Exemplo |
|
Expressões regulares
Para obter mais informações sobre sintaxe de expressão regular, consulte a documentação da sua fonte de dados. Para extrações do Tableau, a sintaxe da expressão regular atende aos padrões de ICU (International Components for Unicode), um projeto de fonte aberta de bibliotecas de C/C++ e Java antigas para suporte de Unicode, internacionalização de software e globalização de software. Consulte a página Regular Expressions(O link abre em nova janela) (Expressões regulares) no ICU User Guide, disponível on-line.
REGEXP_REPLACE
| Sintaxe | REGEXP_REPLACE(string, pattern, replacement) |
| Saída | Cadeia de caracteres |
| Definição | Retorna uma cópia de uma cadeia de caracteres determinada, onde o padrão de expressão regular é substituído pela cadeia de caracteres de substituição. |
| Exemplo | REGEXP_REPLACE('abc 123', '\s', '-') = 'abc-123' |
| Observações | Esta função está disponível para fontes de dados de arquivo de texto, Hadoop Hive, Google BigQuery, PostgreSQL, Extração de dados do Tableau, Microsoft Excel, Salesforce, Vertica, Pivotal Greenplum, Teradata (versão 14.1 e posterior), Snowflake e Oracle. Para extrações de dados do Tableau, o padrão e a reposição devem ser constantes. |
REGEXP_MATCH
| Sintaxe | REGEXP_MATCH(string, pattern) |
| Saída | Booleano |
| Definição | Retorna true se uma subcadeia de caracteres de uma cadeia de caracteres específica corresponder ao padrão de expressão regular. |
| Exemplo | REGEXP_MATCH('-([1234].[The.Market])-','\[\s*(\w*\.)(\w*\s*\])')=true |
| Observações | Esta função está disponível para fontes de dados de arquivo de texto, Google BigQuery, PostgreSQL, Extração de dados do Tableau, Microsoft Excel, Salesforce, Vertica, Pivotal Greenplum, Teradata (versão 14.1 e posterior), Impala 2.3.0 (por meio de fontes de dados do Cloudera Hadoop), Snowflake e Oracle. Para extrações de dados do Tableau, o padrão deve ser uma constante. |
REGEXP_EXTRACT
| Sintaxe | REGEXP_EXTRACT(string, pattern) |
| Saída | Cadeia de caracteres |
| Definição | Retorna a parte de uma cadeia de caracteres que corresponda ao padrão de expressão regular. |
| Exemplo | REGEXP_EXTRACT('abc 123', '[a-z]+\s+(\d+)') = '123' |
| Observações | Esta função está disponível para fontes de dados de arquivo de texto, Hadoop Hive, Google BigQuery, PostgreSQL, Extração de dados do Tableau, Microsoft Excel, Salesforce, Vertica, Pivotal Greenplum, Teradata (versão 14.1 e posterior), Snowflake e Oracle. Para extrações de dados do Tableau, o padrão deve ser uma constante. |
REGEXP_EXTRACT_NTH
| Sintaxe | REGEXP_EXTRACT_NTH(string, pattern, index) |
| Saída | Cadeia de caracteres |
| Definição | Retorna a parte de uma cadeia de caracteres que corresponda ao padrão de expressão regular. A subcadeia é comparada com o grupo de captura nth, onde n é o índice dado. Se o índice for 0, toda a cadeia de caracteres é retornada. |
| Exemplo | REGEXP_EXTRACT_NTH('abc 123', '([a-z]+)\s+(\d+)', 2) = '123' |
| Observações | Esta função está disponível para fontes de dados de arquivo de texto, PostgreSQL, Extração de dados do Tableau, Microsoft Excel, Salesforce, HP Vertica, Pivotal Greenplum, Teradata (versão 14.1 e posterior) e Oracle. Para extrações de dados do Tableau, o padrão deve ser uma constante. |
Funções específicas do Hadoop Hive
Observação: somente as funções PARSE_URL e PARSE_URL_QUERY estão disponíveis para as fontes de dados do Cloudera Impala.
GET_JSON_OBJECT(cadeia de caracteres JSON, caminho JSON)
Retorna o objeto JSON dentro da cadeia de caracteres JSON baseando-se no caminho JSON.
PARSE_URL(string, parte_url)
Retorna um componente da cadeia de caractere de URL dada quando o componente é definido por parte_url. Valores url_part válidos incluem: 'HOST', 'PATH', 'QUERY', 'REF', 'PROTOCOL', 'AUTHORITY', 'FILE' e 'USERINFO'.
Exemplo
PARSE_URL('http://www.tableau.com', 'HOST') = 'www.tableau.com'
PARSE_URL_QUERY(string, chave)
Retorna o valor do parâmetro de consulta especificado na cadeia de caracteres de URL dada. O parâmetro de consulta é definido pela chave.
Exemplo
PARSE_URL_QUERY('http://www.tableau.com?page=1&cat=4', 'page') = '1'
XPATH_BOOLEAN(cadeia de caracteres XML, cadeia de caracteres de expressão XPath)
Retorna verdadeiro se a expressão XPath corresponde a um nó ou é avaliada como verdadeira.
Exemplo
XPATH_BOOLEAN('<values> <value id="0">1</value><value id="1">5</value>', 'values/value[@id="1"] = 5') = true
XPATH_DOUBLE(cadeia de caracteres XML, cadeia de caracteres da expressão XPath)
Retorna o valor de ponto flutuante da expressão XPath.
Exemplo
XPATH_DOUBLE('<values><value>1.0</value><value>5.5</value> </values>', 'sum(value/*)') = 6.5
XPATH_FLOAT(cadeia de caracteres XML, cadeia de caracteres da expressão XPath)
Retorna o valor de ponto flutuante da expressão XPath.
Exemplo
XPATH_FLOAT('<values><value>1.0</value><value>5.5</value> </values>','sum(value/*)') = 6.5
XPATH_INT(cadeia de caracteres XML, cadeia de caracteres da expressão XPath)
Retorna o valor numérico da expressão XPath, ou zero, se a expressão XPath não pode ser avaliada como número.
Exemplo
XPATH_INT('<values><value>1</value><value>5</value> </values>','sum(value/*)') = 6
XPATH_LONG(cadeia de caracteres XML, cadeia de caracteres da expressão XPath)
Retorna o valor numérico da expressão XPath, ou zero, se a expressão XPath não pode ser avaliada como número.
Exemplo
XPATH_LONG('<values><value>1</value><value>5</value> </values>','sum(value/*)') = 6
XPATH_SHORT(cadeia de caracteres XML, cadeia de caracteres da expressão XPath)
Retorna o valor numérico da expressão XPath, ou zero, se a expressão XPath não pode ser avaliada como número.
Exemplo
XPATH_SHORT('<values><value>1</value><value>5</value> </values>','sum(value/*)') = 6
XPATH_STRING(cadeia de caracteres XML, cadeia de caracteres da expressão XPath)
Retorna o texto do primeiro nó correspondente.
Exemplo
XPATH_STRING('<sites ><url domain="org">http://www.w3.org</url> <url domain="com">http://www.tableau.com</url></sites>', 'sites/url[@domain="com"]') = 'http://www.tableau.com'
Funções específicas do Google BigQuery
DOMAIN(string_url)
Dada uma cadeia de caracteres de URL, retorna o domínio como uma cadeia de caractere.
Exemplo
DOMAIN('http://www.google.com:80/index.html') = 'google.com'
GROUP_CONCAT(expressão)
Concatena os valores de cada registro em uma única string delimitada por vírgula. Esta função atua como uma SUM() para strings.
Exemplo
GROUP_CONCAT(Region) = "Central,East,West"
HOST(string_url)
Dada uma cadeia de caracteres de URL, retorna o nome do host como uma cadeia de caracteres.
Exemplo
HOST('http://www.google.com:80/index.html') = 'www.google.com:80'
LOG2(número)
Retorna o logaritmo de um número na base 2.
Exemplo
LOG2(16) = '4.00'
LTRIM_THIS(string, string)
Retorna a primeira cadeia de caracteres com qualquer ocorrência da segunda cadeia de caracteres à esquerda removida.
Exemplo
LTRIM_THIS('[-Sales-]','[-') = 'Sales-]'
RTRIM_THIS(cadeia de caracteres, cadeia de caracteres)
Retorna a primeira cadeia de caracteres com qualquer ocorrência da segunda cadeia de caracteres à direita removida.
Exemplo
RTRIM_THIS('[-Market-]','-]') = '[-Market'
TIMESTAMP_TO_USEC(expressão)
Converte um tipo de dado TIMESTAMP em um carimbo de data/hora UNIX em microssegundos.
Exemplo
TIMESTAMP_TO_USEC(#2012-10-01 01:02:03#)=1349053323000000
USEC_TO_TIMESTAMP(expressão)
Converte um carimbo de data/hora UNIX em microssegundos em um tipo de dados TIMESTAMP.
Exemplo
USEC_TO_TIMESTAMP(1349053323000000) = #2012-10-01 01:02:03#
TLD(string_url)
Dada uma cadeia de caracteres de URL, retorna o domínio de nível superior mais qualquer domínio de país na URL.
Exemplo
TLD('http://www.google.com:80/index.html') = '.com'
TLD('http://www.google.co.uk:80/index.html') = '.co.uk'
Deseja saber mais sobre as funções?
Leia os tópicos sobre funções(O link abre em nova janela).
Consulte também
Funções do Tableau (em ordem alfabética)(O link abre em nova janela)