Funções de cálculo de tabela
Este artigo apresenta funções de cálculo de tabela e seus usos no Tableau. Ele também demonstra como criar um cálculo de tabela usando o editor de cálculo.
Porque usar funções de cálculo de tabela
Funções de cálculo de tabela permitem realizar cálculos com os valores de uma tabela.
Por exemplo, é possível calcular o percentual do total de uma venda individual com relação ao ano todo ou a vários anos.
Funções de cálculo de tabela disponíveis no Tableau
Essas são as funções nativas de cálculo de tabela que podem ser usadas no Tableau sem uma extensão externa do Analytics.
FIRST( )
Retorna o número de linhas da linha atual até a primeira linha na partição. Por exemplo, a exibição a seguir mostra as vendas trimestrais. Quando FIRST() é calculado na partição Date, a compensação da primeira linha em relação à segunda linha é -1.
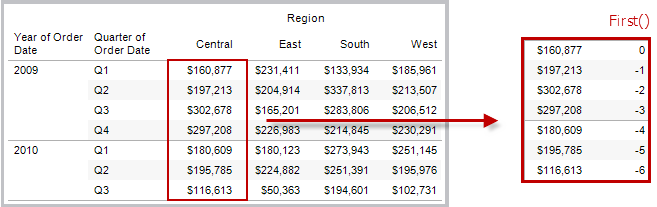
Exemplo
Quando o índice de linha atual for 3, FIRST()
= -2.
INDEX( )
Retorna o índice da linha atual na partição, sem qualquer classificação em relação ao valor. O índice da primeira linha começa em 1. Por exemplo, a tabela a seguir mostra as vendas trimestrais. Quando INDEX() é calculada na partição Date, o índice de cada linha é 1, 2, 3, 4..., etc.

Exemplo
Para a terceira linha na partição, INDEX() = 3.
LAST( )
Retorna o número de linhas da linha atual até a última linha na partição. Por exemplo, a tabela a seguir mostra as vendas trimestrais. Quando LAST() é calculado na partição Date, a compensação da última linha em relação à segunda linha é 5.

Exemplo
Quando o índice de linha atual for 3 de 7, LAST() = 4.
LOOKUP(expression, [offset])
Retorna o valor da expressão em uma linha de destino, especificada como uma compensação relativa da linha atual. Use FIRST() + n e LAST() - n como parte de sua definição de deslocamento para um destino relativo à primeira/última linha da partição. Se offset for omitido, a linha para comparação poderá ser definida no menu de campo. Esta função retornará NULL se a linha de destino não puder ser determinada.
A exibição a seguir mostra as vendas trimestrais. Quando LOOKUP (SUM(Sales), 2) é calculado na partição Date, cada linha mostra o valor de vendas de 2 trimestres no futuro.

Exemplo
LOOKUP(SUM([Profit]),
FIRST()+2) calcula SUM(Profit) na terceira linha da partição.
Funções MODEL_EXTENSION
As funções de extensão do modelo:
MODEL_EXTENSION_BOOL
MODEL_EXTENSION_INT
MODEL_EXTENSION_REAL
MODEL_EXTENSION_STRING
são usadas para passar dados para um modelo implantado em um serviço externo, como R, TabPy ou Matlab. Consulte Extensões do Analytics(O link abre em nova janela).
MODEL_PERCENTILE(target_expression, predictor_expression(s))
Retorna a probabilidade (entre 0 e 1) do valor esperado ser menor ou igual à marca observada, definida pela expressão-alvo e outros preditores. Esta é a Função de Distribuição Preditiva Posterior, também conhecida como Função de Distribuição Cumulativa (CDF).
Esta função é o inverso de MODEL_QUANTILE. Para obter informações sobre funções de modelagem preditiva, consulte Como funcionam as funções de modelagem preditiva no Tableau.
Exemplo
A fórmula a seguir devolve o quantil da marca para a soma das vendas, ajustada para contagem de pedidos.
MODEL_PERCENTILE(SUM([Sales]), COUNT([Orders]))
MODEL_QUANTILE(quantile, target_expression, predictor_expression(s))
Retorna um valor numérico de destino dentro do intervalo provável definido pela expressão de destino e outros preditores, em um quantil especificado. Este é o Quantil Preditivo Posterior.
Esta função é o inverso de MODEL_PERCENTILE. Para obter informações sobre funções de modelagem preditiva, consulte Como funcionam as funções de modelagem preditiva no Tableau.
Exemplo
A fórmula a seguir retorna a mediana (0,5) da soma prevista de vendas, ajustada para contagem de pedidos.
MODEL_QUANTILE(0.5, SUM([Sales]), COUNT([Orders]))
PREVIOUS_VALUE(expression)
Retorna o valor desse cálculo na linha anterior. Retornará a expressão especificada se a linha atual for a primeira linha da partição.
Exemplo
SUM([Profit]) * PREVIOUS_VALUE(1) calcula o produto em execução de SUM(Profit).
RANK(expression, ['asc' | 'desc'])
Retorna a posição na classificação da concorrência padrão para a linha atual da partição. Valores idênticos são colocados em uma posição na classificação idêntica. Use o argumento opcional 'asc' | 'desc' para especificar a ordem crescente ou decrescente. O padrão é decrescente.
Com esta função, o conjunto de valores (6, 9, 9, 14) seria classificado (4, 2, 2, 1).
Os nulos são ignorados em funções de classificação. Eles não são numerados e não são contabilizados para o número total de registros em cálculos de posição na classificação percentil.
Para obter informações sobre opções de classificação diferentes, consulte Cálculo da posição na classificação.
Exemplo
A imagem a seguir mostra o efeito das várias funções de classificação (RANK, RANK_DENSE, RANK_MODIFIED, RANK_PERCENTILE e RANK_UNIQUE) sobre um conjunto de valores. O conjunto de dados contém informações sobre 14 alunos (do Aluno A até Aluno N); a coluna Idade mostra a idade atual de cada aluno (todos os alunos são entre 17 e 20 anos). As colunas restantes mostram o efeito de cada função do ranking no conjunto de valores de idade, sempre assumindo a ordem padrão (ascendente ou descendente) para a função.
![]()
RANK_DENSE(expression, ['asc' | 'desc'])
Retorna a posição na classificação densa para a linha atual na partição. Para valores idênticos, são atribuídos uma mesma posição na classificação, mas nenhuma lacuna é inserida na sequência numérica. Use o argumento opcional 'asc' | 'desc' para especificar a ordem crescente ou decrescente. O padrão é decrescente.
Com esta função, o conjunto de valores (6, 9, 9, 14) seria classificado (3, 2, 2, 1).
Os nulos são ignorados em funções de classificação. Eles não são numerados e não são contabilizados para o número total de registros em cálculos de posição na classificação percentil.
Para obter informações sobre opções de classificação diferentes, consulte Cálculo da posição na classificação.
RANK_MODIFIED(expression, ['asc' | 'desc'])
Retorna a posição na classificação da concorrência modificada para a linha atual na partição. Valores idênticos são colocados em uma posição na classificação idêntica. Use o argumento opcional 'asc' | 'desc' para especificar a ordem crescente ou decrescente. O padrão é decrescente.
Com esta função, o conjunto de valores (6, 9, 9, 14) seria classificado (4, 3, 3, 1).
Os nulos são ignorados em funções de classificação. Eles não são numerados e não são contabilizados para o número total de registros em cálculos de posição na classificação percentil.
Para obter informações sobre opções de classificação diferentes, consulte Cálculo da posição na classificação.
RANK_PERCENTILE(expression, ['asc' | 'desc'])
Retorna a posição na classificação percentil para a linha atual na partição. Use o argumento opcional 'asc' | 'desc' para especificar a ordem crescente ou decrescente. O padrão é crescente.
Com esta função, o conjunto de valores (6, 9, 9, 14) seria classificado (0,00, 0,67, 0,67, 1,00).
Os nulos são ignorados em funções de classificação. Eles não são numerados e não são contabilizados para o número total de registros em cálculos de posição na classificação percentil.
Para obter informações sobre opções de classificação diferentes, consulte Cálculo da posição na classificação.
RANK_UNIQUE(expression, ['asc' | 'desc'])
Retorna a posição na classificação exclusiva para a linha atual na partição. Para valores idênticos, são atribuídas diferentes posições na classificação. Use o argumento opcional 'asc' | 'desc' para especificar a ordem crescente ou decrescente. O padrão é decrescente.
Com esta função, o conjunto de valores (6, 9, 9, 14) seria classificado (4, 2, 3, 1).
Os nulos são ignorados em funções de classificação. Eles não são numerados e não são contabilizados para o número total de registros em cálculos de posição na classificação percentil.
Para obter informações sobre opções de classificação diferentes, consulte Cálculo da posição na classificação.
RUNNING_AVG(expression)
Retorna a média em execução da expressão especificada a partir da primeira linha na partição para a linha atual.
A exibição a seguir mostra as vendas trimestrais. Quando RUNNING_AVG(SUM([Sales]) é calculado na partição Date, o resultado é uma média em execução dos valores de vendas de cada trimestre.

Exemplo
RUNNING_AVG(SUM([Profit])) calcula a média em execução de SUM(Profit).
RUNNING_COUNT(expression)
Retorna a contagem em execução da expressão especificada a partir da primeira linha na partição para a linha atual.
Exemplo
RUNNING_COUNT(SUM([Profit])) calcula a contagem em execução de SUM(Profit).
RUNNING_MAX(expression)
Retorna o máximo em execução da expressão especificada a partir da primeira linha na partição para a linha atual.

Exemplo
RUNNING_MAX(SUM([Profit])) calcula o máximo em execução de SUM(Profit).
RUNNING_MIN(expression)
Retorna o mínimo em execução da expressão especificada a partir da primeira linha na partição para a linha atual.

Exemplo
RUNNING_MIN(SUM([Profit])) calcula o mínimo em execução de SUM(Profit).
RUNNING_SUM(expression)
Retorna a soma em execução da expressão especificada a partir da primeira linha na partição para a linha atual.

Exemplo
RUNNING_SUM(SUM([Profit])) calcula a soma em execução de SUM(Profit)
SIZE()
Retorna o número de linhas na partição. Por exemplo, a exibição a seguir mostra as vendas trimestrais. Na partição Date, há sete linhas, portanto, o Size() da partição Date é 7.

Exemplo
SIZE() = 5 quando a partição atual contém cinco linhas.
Funções SCRIPT_
As funções script:
SCRIPT_BOOL
SCRIPT_INT
SCRIPT_REAL
SCRIPT_STRING
são usadas para passar dados para um serviço externo, como R, TabPy ou Matlab. Consulte Extensões do Analytics(O link abre em nova janela).
TOTAL(expression)
Retorna o número total da expressão fornecida em uma divisão do cálculo de tabela.
Exemplo
Suponha que você está começando com esta exibição:

Você abre o editor de cálculo e cria um novo campo nomeado de Totalidade:

Em seguida, solte o campo Totalidade em Texto para substituir SUM(Sales). Suas exibições são alteradas de tal forma, que ela soma os valores com base no valor padrão de Calcular usando:

Isso levanta a questão, qual é o valor padrão de Calcular usando? Se você clicar com o botão direito do mouse (clique pressionando a tecla Control, no Mac) na Totalidade, no painel de Dados, e escolher Editar, haverá um pouco de informação adicional disponível:

O valor padrão de Calcular usando é uma Tabela (horizontal). O resultado é que a Totalidade é soma dos valores em cada linha da tabela. Assim, o valor visualizado em cada linha é a soma dos valores da versão original da tabela.
Os valores na linha 2011/Q1 na tabela original foram de US$ 8.601,00; US$ 6.579,00; US$ 44.262,00; e US$ 15.006,00. Os valores na tabela após a Totalidade substituem a SUM(Sales) com um total de US $74.448,00; que é a soma dos quatro valores originais.
Observe o triângulo ao lado de Totalidade depois de soltá-lo em Texto:

Isso indica que este campo está usando um cálculo de tabela. Você pode clicar com o botão direito do mouse no campo e escolher Editar o cálculo de tabela para redirecionar a sua função para um valor de Calcular usando diferente. Por exemplo, você pode defini-lo para Tabela (vertical). Nesse caso, a tabela ficaria assim:

TOTAL(expression)
Retorna o número total da expressão fornecida em uma divisão do cálculo de tabela.
Exemplo
Suponha que você está começando com esta exibição:
Você abre o editor de cálculo e cria um novo campo nomeado de Totalidade:
Em seguida, solte o campo Totalidade em Texto para substituir SUM(Sales). Suas exibições são alteradas de tal forma, que ela soma os valores com base no valor padrão de Calcular usando:
Isso levanta a questão, qual é o valor padrão de Calcular usando? Se você clicar com o botão direito do mouse (clique pressionando a tecla Control, no Mac) na Totalidade, no painel de Dados, e escolher Editar, haverá um pouco de informação adicional disponível:
O valor padrão de Calcular usando é uma Tabela (horizontal). O resultado é que a Totalidade é soma dos valores em cada linha da tabela. Assim, o valor visualizado em cada linha é a soma dos valores da versão original da tabela.
Os valores na linha 2011/Q1 na tabela original foram de US$ 8.601,00; US$ 6.579,00; US$ 44.262,00; e US$ 15.006,00. Os valores na tabela após a Totalidade substituem a SUM(Sales) com um total de US $74.448,00; que é a soma dos quatro valores originais.
Observe o triângulo ao lado de Totalidade depois de soltá-lo em Texto:
Isso indica que este campo está usando um cálculo de tabela. Você pode clicar com o botão direito do mouse no campo e escolher Editar o cálculo de tabela para redirecionar a sua função para um valor de Calcular usando diferente. Por exemplo, você pode defini-lo para Tabela (vertical). Nesse caso, a tabela ficaria assim:
WINDOW_AVG(expression, [start, end])
Retorna a média da expressão na janela. A janela é definida como desvios em relação à linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Há uma função de agregação equivalente: AVG. Consulte Funções do Tableau (em ordem alfabética)(O link abre em nova janela).
Exemplo
A fórmula a seguir retorna a média de janela de SUM(Profit) das duas linhas anteriores à linha atual.
WINDOW_AVG(SUM[Profit]), -2, 0)
WINDOW_CORR(expression1, expression2, [start, end])
Retorna o coeficiente de correlação Pearson de duas expressões dentro da janela. A janela é definida como desvios em relação à linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
A correlação Pearson mede a relação linear entre duas variáveis. Os resultados variam de -1 a +1 inclusive, em que 1 denota uma relação linear positiva e exata, quando uma alteração positiva em uma variável implica na alteração positiva da magnitude correspondente da outra variável, 0 denota nenhuma relação linear entre a variância e −1 é uma relação negativa exata.
Há uma função de agregação equivalente: CORR. Consulte Funções do Tableau (em ordem alfabética)(O link abre em nova janela).
Exemplo
A fórmula a seguir retorna a correlação Pearson de SUM(Profit) e SUM(Sales) das cinco linhas anteriores à linha atual.
WINDOW_CORR(SUM[Profit]), SUM([Sales]), -5, 0)
WINDOW_COUNT(expression, [start, end])
Retorna a contagem da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Exemplo
WINDOW_COUNT(SUM([Profit]), FIRST()+1, 0) calcula a contagem de SUM(Profit) a partir da segunda linha até a linha atual
WINDOW_COVAR(expression1, expression2, [start, end])
Retorna a covariância de amostra de duas expressões dentro da janela. A janela é definida como desvios em relação à linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se os argumentos iniciais e finais forem omitidos, a janela será toda a partição.
A covariância de amostra usa o número de pontos de dados não nulos, n - 1, para normalizar o cálculo da covariância, em vez de n, que é usado pela covariância populacional (disponível com a função WINDOWS_COVARP). A covariância de amostra é a escolha apropriada quando os dados são uma amostra aleatória sendo usada para estimar a covariância de uma população maior.
Há uma função de agregação equivalente: COVAR. Consulte Funções do Tableau (em ordem alfabética)(O link abre em nova janela).
Exemplo
A fórmula a seguir retorna a covariância de amostra de SUM(Profit) e SUM(Sales) das duas linhas anteriores à linha atual.
WINDOW_COVAR(SUM([Profit]), SUM([Sales]), -2, 0)
WINDOW_COVARP(expression1, expression2, [start, end])
Retorna a covariância populacional de duas expressões dentro da janela. A janela é definida como desvios em relação à linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
A covariância populacional é a covariância de amostra multiplicada por (n-1)/n, em que n é o número total de pontos de dados não nulos. A covariância populacional é a escolha apropriada quando há dados disponíveis para todos os itens de interesse, ao invés de somente um subconjunto aleatório de itens, em que a covariância de amostra (com a função WINDOWS_COVAR) é apropriada.
Há uma função de agregação equivalente: COVARP. Funções do Tableau (em ordem alfabética)(O link abre em nova janela)
Exemplo
A fórmula a seguir retorna a covariância populacional de SUM(Profit) e SUM(Sales) das duas linhas anteriores à linha atual.
WINDOW_COVARP(SUM([Profit]), SUM([Sales]), -2, 0)
WINDOW_MEDIAN(expression, [start, end])
Retorna o mediano da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Por exemplo, a exibição a seguir mostra o lucro trimestral. Um mediano de janela na partição Date retorna o lucro médio em todas as datas.

Exemplo
WINDOW_MEDIAN(SUM([Profit]), FIRST()+1, 0) calcula o mediano de SUM(Profit) a partir da segunda linha até a linha atual.
WINDOW_MAX(expression, [start, end])
Retorna o máximo da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Por exemplo, a exibição a seguir mostra as vendas trimestrais. Uma máxima de janela na partição Date retorna o máximo de vendas em todas as datas.

Exemplo
WINDOW_MAX(SUM([Profit]), FIRST()+1, 0) calcula o máximo de SUM(Profit) a partir da segunda linha até a linha atual.
WINDOW_MIN(expression, [start, end])
Retorna o mínimo da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Por exemplo, a exibição a seguir mostra as vendas trimestrais. Um mínimo de janela na partição Date retorna o mínimo de vendas em todas as datas.

Exemplo
WINDOW_MIN(SUM([Profit]), FIRST()+1, 0) calcula o mínimo de SUM(Profit) a partir da segunda linha até a linha atual.
WINDOW_PERCENTILE(expression, number, [start, end])
Retorna o valor correspondente ao percentil especificado dentro da janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Exemplo
WINDOW_PERCENTILE(SUM([Profit]), 0.75, -2, 0) retorna o 75º percentil para SUM(Profit) das duas linhas anteriores para a linha atual.
WINDOW_STDEV(expression, [start, end])
Retorna o desvio padrão de exemplo da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Exemplo
WINDOW_STDEV(SUM([Profit]), FIRST()+1, 0) calcula o desvio padrão de SUM(Profit) a partir da segunda linha até a linha atual.
WINDOW_STDEVP(expression, [start, end])
Retorna o desvio padrão tendencioso da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Exemplo
WINDOW_STDEVP(SUM([Profit]), FIRST()+1, 0) calcula o desvio padrão de SUM(Profit) a partir da segunda linha até a linha atual.
WINDOW_SUM(expression, [start, end])
Retorna a soma da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Por exemplo, a exibição a seguir mostra as vendas trimestrais. Uma soma de janela na partição Date retorna a soma de vendas em todos os trimestres.

Exemplo
WINDOW_SUM(SUM([Profit]), FIRST()+1, 0) calcula a soma de SUM(Profit) a partir da segunda linha até a linha atual.
WINDOW_VAR(expression, [start, end])
Retorna a variação da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Exemplo
WINDOW_VAR((SUM([Profit])), FIRST()+1, 0) calcula a variância de SUM(Profit) a partir da segunda linha até a linha atual.
WINDOW_VARP(expression, [start, end])
Retorna a variação tendenciosa da expressão na janela. A janela é definida por meio de compensações da linha atual. Use FIRST()+n e LAST()-n como compensações da primeira ou última linha na partição. Se o início e o fim forem omitidos, toda a partição será usada.
Exemplo
WINDOW_VARP(SUM([Profit]), FIRST()+1, 0) calcula a variância de SUM(Profit) a partir da segunda linha até a linha atual.
Funções de cálculo de tabela da Extensão do Analytics disponíveis no Tableau
Extensões do Analytic são conexões entre o Tableau e um serviço externo, como TabPy para Python, Matlab e R. Para usar extensões de Analytics Extensions em sua análise, você deve primeiro configurar uma conexão(O link abre em nova janela) entre o Tableau e um serviço externo, como um servidor TabPy. Em seguida, você pode usar scripts dentro de cálculos de tabela específicos (MODEL_EXTENSION_ para usar modelos nomeados publicados ou SCRIPT_ para passar uma expressão para o serviço externo). Os dados na visualização (a “tabela” da tabela calc) são passados com segurança para o servidor externo, o script é executado e os resultados são transmitidos de volta como a saída do cálculo.
Funções de extensão do modelo
Para uso com modelos nomeados implantados em um serviço externo TabPy.
MODEL_EXTENSION_BOOL (model_name, argumentos, expressão)
Retorna o resultado booliano de uma expressão calculada por um modelo nomeado implantado em um serviço externo TabPy.
Model_name é o nome do modelo de análise implementado que você deseja usar.
Cada argumento é uma única cadeia de caracteres que define os valores de entrada que o modelo implementado aceita e é definido pelo modelo analítico.
Use expressões para definir os valores que são enviados do Tableau para o modelo de análise. Certifique-se de usar funções de agregação (SUM, AVG, etc.) para agregar os resultados.
Ao usar a função, os tipos de dados e a ordem das expressões devem corresponder aos dos argumentos de entrada.
Exemplo
MODEL_EXTENSION_BOOL ("isProfitable","inputSales", "inputCosts", SUM([Sales]), SUM([Costs]))
MODEL_EXTENSION_INT (nome_modelo, argumentos, expressão)
Retorna um resultado inteiro de uma expressão calculada por um modelo nomeado implantado em um serviço externo TabPy.
Model_name é o nome do modelo de análise implementado que você deseja usar.
Cada argumento é uma única cadeia de caracteres que define os valores de entrada que o modelo implementado aceita e é definido pelo modelo analítico.
Use expressões para definir os valores que são enviados do Tableau para o modelo de análise. Certifique-se de usar funções de agregação (SUM, AVG, etc.) para agregar os resultados.
Ao usar a função, os tipos de dados e a ordem das expressões devem corresponder aos dos argumentos de entrada.
Exemplo
MODEL_EXTENSION_INT ("getPopulation", "inputCity", "inputState", MAX([City]), MAX ([State]))
MODEL_EXTENSION_REAL (nome_modelo, argumentos, expressão)
Retorna um resultado real de uma expressão calculada por um modelo nomeado implantado em um serviço externo TabPy.
Model_name é o nome do modelo de análise implementado que você deseja usar.
Cada argumento é uma única cadeia de caracteres que define os valores de entrada que o modelo implementado aceita e é definido pelo modelo analítico.
Use expressões para definir os valores que são enviados do Tableau para o modelo de análise. Certifique-se de usar funções de agregação (SUM, AVG, etc.) para agregar os resultados.
Ao usar a função, os tipos de dados e a ordem das expressões devem corresponder aos dos argumentos de entrada.
Exemplo
MODEL_EXTENSION_REAL ("profitRatio", "inputSales", "inputCosts", SUM([Sales]), SUM([Costs]))
MODEL_EXTENSION_STRING (nome_modelo, argumentos, expressão)
Retorna o resultado da string de uma expressão calculada por um modelo nomeado implantado em um serviço externo TabPy.
Model_name é o nome do modelo de análise implementado que você deseja usar.
Cada argumento é uma única cadeia de caracteres que define os valores de entrada que o modelo implementado aceita e é definido pelo modelo analítico.
Use expressões para definir os valores que são enviados do Tableau para o modelo de análise. Certifique-se de usar funções de agregação (SUM, AVG, etc.) para agregar os resultados.
Ao usar a função, os tipos de dados e a ordem das expressões devem corresponder aos dos argumentos de entrada.
Exemplo
MODEL_EXTENSION_STR ("mostPopulatedCity", "inputCountry", "inputYear", MAX ([Country]), MAX([Year]))
Funções de script
Em vez de usar um modelo externo definido como funções MODEL_EXPRESSION, funções SCRIPT são usadas para especificar a expressão diretamente no cálculo da tabela.
Observação: as chamadas esperam que seja retornada uma única coluna que contenha o mesmo número de linhas que foi enviado para a função.
SCRIPT_BOOL
Retorna um resultado Booliano da expressão especificada. A expressão é transmitida diretamente para uma extensão de análise em execução.
Nas expressões R, use .argn (com um ponto à frente) para fazer referência a parâmetros (.arg1, .arg2 etc.).
Nas expressões de Python, use _argn (com um sublinhado à frente).
Exemplos
Neste exemplo R, .arg1 é igual a SUM([Profit]):
SCRIPT_BOOL("is.finite(.arg1)", SUM([Profit]))
O próximo exemplo retorna True para IDs de loja no estado de Washington e False para os demais. Este exemplo poderia ser a definição de um campo calculado intitulado IsStoreInWA.
SCRIPT_BOOL('grepl(".*_WA", .arg1, perl=TRUE)',ATTR([Store ID]))
Um comando do Python seria dessa forma:
SCRIPT_BOOL("return map(lambda x : x > 0, _arg1)", SUM([Profit]))
SCRIPT_INT
Retorna um resultado do inteiro da expressão especificada. A expressão é transmitida diretamente para uma extensão de análise em execução.
Nas expressões R, use .argn (com um ponto à frente) para fazer referência a parâmetros (.arg1, .arg2 etc.).
Nas expressões de Python, use _argn (com um sublinhado à frente).
Exemplos
Neste exemplo R, .arg1 é igual a SUM([Profit]):
SCRIPT_INT("is.finite(.arg1)", SUM([Profit]))
No próximo exemplo, o agrupamento k-means é usado para criar três clusters:
SCRIPT_INT('result <- kmeans(data.frame(.arg1,.arg2,.arg3,.arg4), 3);result$cluster;', SUM([Petal length]), SUM([Petal width]),SUM([Sepal length]),SUM([Sepal width]))
Um comando do Python seria dessa forma:
SCRIPT_INT("return map(lambda x : int(x * 5), _arg1)", SUM([Profit]))
SCRIPT_REAL
Retorna um resultado real da expressão especificada. A expressão é transmitida diretamente para uma extensão de análise em execução. Nas
expressões R, use .argn (com um ponto à frente) para fazer referência a parâmetros (.arg1, .arg2 etc.).
Nas expressões de Python, use _argn (com um sublinhado à frente).
Exemplos
Neste exemplo R, .arg1 é igual a SUM([Profit]):
SCRIPT_REAL("is.finite(.arg1)", SUM([Profit]))
O próximo exemplo converte valores de temperatura de Celsius em Fahrenheit.
SCRIPT_REAL('library(udunits2);ud.convert(.arg1, "celsius", "degree_fahrenheit")',AVG([Temperature]))
Um comando do Python seria dessa forma:
SCRIPT_REAL("return map(lambda x : x * 0.5, _arg1)", SUM([Profit]))
SCRIPT_STR
Retorna um resultado da cadeia de caracteres da expressão especificada. A expressão é transmitida diretamente para uma extensão de análise em execução.
Nas expressões R, use .argn (com um ponto à frente) para fazer referência a parâmetros (.arg1, .arg2 etc.).
Nas expressões de Python, use _argn (com um sublinhado à frente).
Exemplos
Neste exemplo R, .arg1 é igual a SUM([Profit]):
SCRIPT_STR("is.finite(.arg1)", SUM([Profit]))
O próximo exemplo extrai uma abreviação de estado de uma cadeia de caracteres mais complicada (na forma original 13XSL_CA, A13_WA):
SCRIPT_STR('gsub(".*_", "", .arg1)',ATTR([Store ID]))
Um comando do Python seria dessa forma:
SCRIPT_STR("return map(lambda x : x[:2], _arg1)", ATTR([Region]))
Criar um cálculo de tabela usando o editor de cálculo
Siga as etapas abaixo para saber como criar um cálculo de tabela usando o editor de cálculo.
Observação: há várias maneiras de criar cálculos de tabela no Tableau. Este exemplo demonstra apenas uma destas maneiras. Para obter mais informações, consulte Transformar valores com cálculos de tabela(O link abre em nova janela).
Etapa 1: criar a visualização
No Tableau Desktop, conecte-se à fonte de dados salva Sample-Superstore, incluída no Tableau.
Navegue até uma planilha.
No painel Dados, em Dimensões, arraste Data do pedido até a divisória Colunas.
No painel Dados, em Dimensões, arraste Subcategoria até a divisória Linhas.
No painel Dados, em Medidas, arraste Vendas até Texto no cartão Marcas.
Sua visualização se atualiza em uma tabela de texto.
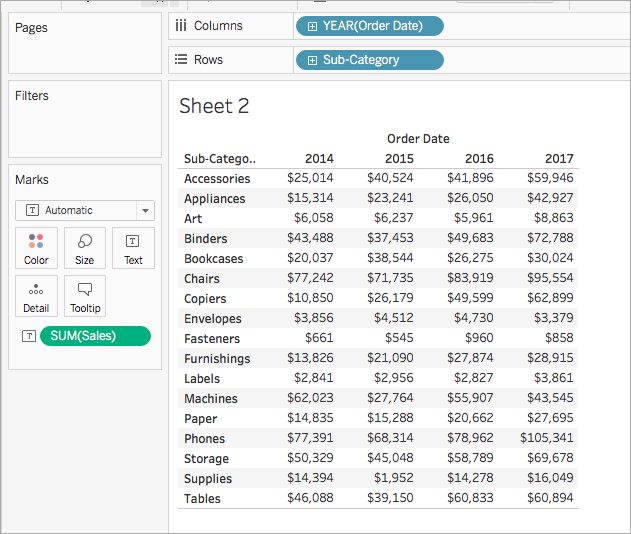
Etapa 2: criar o cálculo de tabela
Selecione Análise > Criar campo calculado.
No editor de cálculo aberto, faça o seguinte:
- Nomeie o campo calculado, soma parcial dos lucros.
Insira a fórmula a seguir:
RUNNING_SUM(SUM([Profit]))Esta fórmula calcula a soma parcial dos lucros das vendas. Ela é calculada em toda a tabela.
Ao terminar, clique em OK.
O novo campo de cálculo de tabela aparece em Medidas no painel Dados. Assim como os outros campos, é possível usá-lo em uma ou mais visualizações.
Etapa 3: usar o cálculo de tabela na visualização
No painel Dados, em Medidas, arraste Soma parcial dos lucros até Cor no cartão Marcas.
No cartão Marcas, clique no menu suspenso Tipo de marcas e selecione Quadrado.
A visualização se atualiza em uma tabela de destaque:
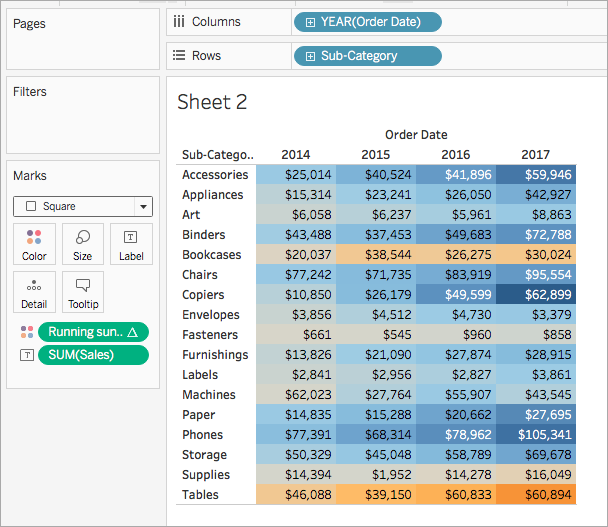
Etapa 4: editar o cálculo de tabela
- No cartão Marcas, clique com o botão direito do mouse em Soma parcial dos lucros e selecione Editar cálculo de tabela.
Na caixa de diálogo Cálculo de tabela que abre, em Calcular usando, selecione Tabela (para baixo).
A visualização se atualiza no seguinte:
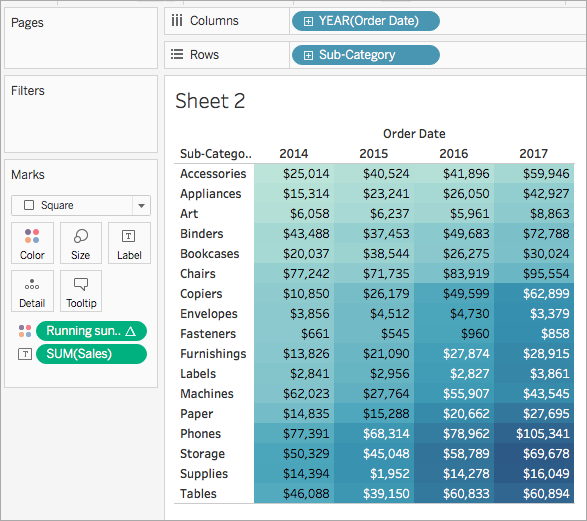
Consulte também
Criar um cálculo de tabela(O link abre em nova janela)
Personalizar cálculos de tabela(O link abre em nova janela)