Tableau Data Management
Det här innehållet är en del av Tableau Blueprint – ett ramverk med vilket ni kan zooma in och förbättra hur organisationen använder data för att få större genomslag. Sätt igång genom att göra vår utvärdering(Länken öppnas i ett nytt fönster).
Tableau Data Management hjälper dig att bättre hantera data i din analysmiljö och se till att pålitlig och aktuell data alltid används som underlag för beslut. Tableau Data Management kommer att öka förtroendet för din data – från dataförberedelse till katalogisering, sökning och kontroll – och accelerera användningen av självbetjäningsanalys. Erbjudandet är en separat licensierad samling funktioner som innefattar Tableau Prep Conductor och Tableau Catalog, som hanterar Tableau-innehåll och dataresurser i Tableau Server och Tableau Cloud.
Vad är Tableau Data Management?
Sammantaget kommer din organisation att dra nytta av tillvägagångssätt för datastyrning och hantering av datakällor som diskuteras på andra ställen i Tableau Blueprint. Utöver de här metoderna kommer du ofta att höra allmänna referenser till termen ”datahantering” i databasen, dataanalyser och visualiseringscommunities. Den här termen blir dock mer specifik när det kommer till Tableau med Tableau Data Management, en uppsättning funktioner för användning med Tableau Server och Tableau Cloud. Oavsett om du använder Tableau Server för Windows, Linux eller Tableau Cloud är funktionerna i Tableau Data Management till stor del identiska (en liten underuppsättning funktioner kanske bara är tillgängliga i Tableau Cloud eller Tableau Server).
Tableau Data Management omfattar en uppsättning verktyg som hjälper din organisations datastewards och -analytiker att hantera datarelaterat innehåll och resurser i din Tableau-miljö. Närmare bestämt läggs tre extra funktionsuppsättningar till när du köper Tableau Data Management:
Tableau Catalog
Tableau Prep Conductor
Virtuella anslutningar med datapolicyer
Tableau Catalog
Den ursprungliga Tableau Data Management-funktionen Tableau Catalog tillhandahåller funktioner för att effektivisera åtkomst, förståelse och förtroende för Tableau-datakällor. Med fokus på områden som ursprung, datakvalitet, sökning och konsekvensanalys kan Tableau Catalog göra det lättare för datastewards och datavisualiserare/-analytiker att förstå och lita på datakällor i Tableau Server och Cloud. Tableau Catalog har ytterligare funktioner för Tableau-utvecklare via metadatametoder i Tableau REST API.
När Tableau Catalog aktiveras för första gången skannar funktionen alla relaterade innehållsobjekt på din Tableau Server- eller Cloud-webbplats för att skapa en ansluten vy av alla relaterade objekt (Tableau Catalog refererar till detta som innehållsmetadata). Detta utökar sökmöjligheterna utöver bara dataanslutningar. Datastewards och visuella författare kan också söka baserat på kolumner, databaser och tabeller.
Tableau Catalogs ursprungsfunktion visar inbördes samband mellan allt innehåll på en Tableau-webbplats, inklusive mätvärden, flöden och virtuella anslutningar, för att minska risken att oavsiktligt ändra eller ta bort ett objekt som ett annat objekt är beroende av (till exempel byta namn på eller ta bort en databaskolumn som är avgörande för en produktionsarbetsbok). Du kan nu enkelt se relationerna mellan objekt och analysera effekten av en eventuell ändring innan du gör den.

Tableau Catalog tillhandahåller kompletterande information för att förbättra förtroendet för dina Tableau-datakällor, som utförligare datarelaterade objektbeskrivningar, vyn Datainformation och nyckelordstaggar för bättre sökflexibilitet. Certifiering av datakällor placerar en framträdande ikon bredvid datakällor för att markera en datakällas ägares eller administratörs förtroende för datakällan. Dataobjekt (datakällor, kolumner osv.) som kan vara oroande för konsumenterna, som föråldrade eller inaktuella data, kan betecknas med datakvalitetsvarningar. Utöver ett alternativ med datakvalitetsvarningar kan känsliga data flaggas specifikt med känslighetsetiketter.
![]()
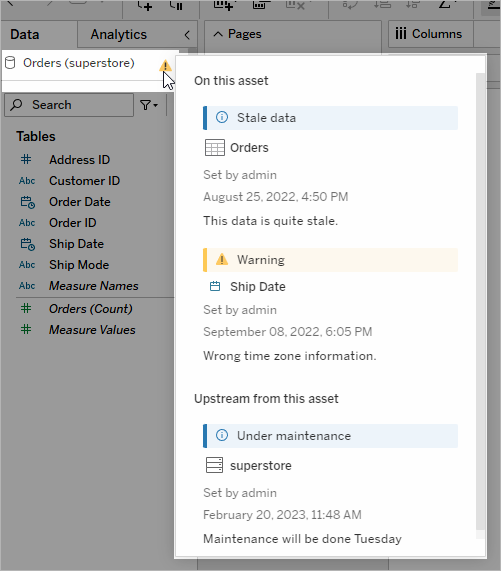
Tableau Prep Conductor
Många Tableau-kunder har redan upptäckt fördelarna med Tableau Prep Builder vid skapande av komplexa dataförberedande ”flöden” som kombinerar flera datakällor, formar data, anpassar kolumner och skapar utdata i ett eller flera önskade dataformat. Men när du väl har skapat det perfekta Prep-flödet, hur automatiserar du det för att köra och helt eller stegvis uppdatera datakällor enligt ett schema?
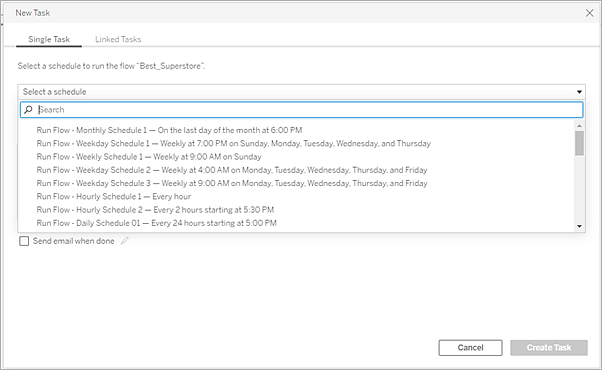
Det är här Tableau Prep Conductor, en annan Data Management-funktion, kommer in i bilden. Tableau Prep Conductor möjliggör flexibel schemaläggning av Tableau Prep-flöden, oavsett om de publiceras till din Tableau Server eller Tableau Cloud-miljö från Tableau Prep Builder eller skapas direkt i en webbläsare med Prep-flödet för webbredigering. Börja med att testa ditt webbaserade flöde (du kan köra flöden manuellt on demand utan Data Management, men du måste köpa Data Management för att schemalägga flöden att köras automatiskt med Prep Conductor). Låt flödet köra klart och säkerställ att din önskade utdatakälla skapas utan fel innan du schemalägger.
Om du använder Tableau Server kan din administratör (eller du själv, om du har rätt behörighet) skapa anpassade scheman (som ”Varje dag vid midnatt”, ”Söndag kl. 12.00” osv.) för att köra Prep-flöden, ungefär som du kan ha gjort för extraktuppdateringar.
Om du använder Tableau Cloud installeras en uppsättning fördefinierade Prep-flödesscheman som standard. Du kan inte anpassa dessa eller skapa dina egna Prep-flödesscheman.
Schemalägg flöden som ska köras via menyn Åtgärder. Ett schema för en enkel uppgift kör endast det valda Prep-flödet med det schema som du väljer. Med ett schema för en länkad uppgift kan du välja ytterligare ett eller flera flöden som ska köras i följd med det valda flödet om du skulle vilja ”kedja” flera flöden för att köras i en specifik ordning (kanske för att skapa en datakälla som ska användas som indatakälla för ett efterföljande flöde). Flödena kommer nu att köras när de är schemalagda och automatiskt uppdatera eller skapa datakällor som Tableau-arbetsböcker kan baseras på.
Utöver möjligheten att schemalägga flöden medför Data Management och Tableau Prep Conductor alternativ för att övervaka lyckade/misslyckade schemalagda flöden, skicka e-postmeddelanden när flödesscheman lyckas eller misslyckas, köra flöden genom programmering med Tableau Server/Cloud REST API och dra nytta av ytterligare administrationsvyfunktioner för att övervaka flödesprestandahistorik.
REKOMMENDATIONER FÖR BÄSTA PRAXIS: Om du planerar att köra ett stort antal Tableau Prep Conductor-flöden på Tableau Server kan du behöva justera skalningen av din servermiljö. Vid behov kan du finjustera prestanda för ditt Tableau Server-system genom att lägga till ytterligare noder eller bakgrundsprocesser för att tillgodose den Prep-flödesbelastning som krävs.
Hur är det med Tableau Cloud? Även om du inte kommer att behöva överväga arkitektoniska förändringar av Tableau Cloud för Prep-flödeskapacitet behöver du skaffa ett resursblock (en enhet med bearbetningskapacitet i Tableau Cloud) för alla Tableau Prep Conductor-flöden som du vill schemalägga samtidigt. Fastställ hur många samtidiga flödesscheman som du behöver och köp motsvarande antal Tableau Cloud-resursblock.
Virtuella anslutningar
Nästa Data Management-funktion är virtuella anslutningar. En virtuell anslutning skapar en central åtkomstpunkt till data. Den kan komma åt flera tabeller i flera olika databaser. Virtuella anslutningar låter dig hantera dataextrakt och säkerhet på ett ställe, på anslutningsnivån.
När är virtuella anslutningar användbara?
Om du är på jakt efter ett traditionellt sätt att dela en databasanslutning med flera arbetsböcker i Tableau kommer du förmodligen att överväga att ansluta direkt till en databasserver som SQL Server eller Snowflake, tillhandahålla inloggningsuppgifter för databasen, lägga till och ansluta en eller flera tabeller och därefter publicera datakällan till Tableau Server eller Tableau Cloud. Även om du kan välja att använda en sådan lösning som en liveanslutning till data är det mycket möjligt att du även vill extrahera data från datakällan för att påskynda anslutna arbetsböcker.
Rent hypotetiskt föreställer vi oss att du kan göra detta hur många gånger som helst för att till exempel rymma en annan uppsättning tabeller eller kopplingar, vilket resulterar i flera publicerade (och kanske även extraherade) datakällor som används för en serie arbetsböcker som har olika tabell-/kopplingskrav, men som alla använder samma initiala databas.
Vi överväger vad som skulle hända om något med den initiala SQL Server- eller Snowflake-databasen som används av datakällorna ändras – några tabeller kanske får nya namn, ytterligare fält läggs till eller inloggningsuppgifterna för databasen ändras. Du står nu inför uppgiften att öppna var och en av de tidigare skapade datakällorna, göra nödvändiga ändringar för att anpassa dem efter förändringen i databasen och därefter återpublicera (och kanske även schemalägga extraktuppdateringar på nytt).
Du kanske tycker att det är mycket enklare att bara skapa en initial ”dataanslutningsdefinition” som lagrar databasens servernamn, inloggningsuppgifter och tabellreferenser? Och du kanske föredrar att extrahera data från den större ”definitionen”? När du senare behöver skapa olika datakällor för olika kombinationer av tabeller, kopplingar och så vidare kan du referera till den initiala ”definitionen” i stället för att ansluta direkt till en eller flera databasservrar. Om något i den grundläggande databasstrukturen ändras (till exempel tabellnamn eller inloggningsuppgifter) behöver du bara ändra det initiala ”definitionsobjektet” så ärver alla beroende datakällor ändringarna automatiskt.
Data Management-funktionen introducerar den här delade ”definitionskapaciteten” via en virtuell anslutning. En virtuell anslutning liknar en datakällas standardanslutning då den lagrar databasservern, inloggningsuppgifterna och utvalda tabeller. Och precis som en traditionell Tableau-datakälla kan en virtuell anslutning innehålla anslutningar till fler än en databas/datakälla (var och en med sin egen uppsättning inloggningsuppgifter och tabeller). Även om vissa metadataändringar tillåts i en virtuell anslutning (som att dölja eller byta namn på fält) kopplas inte tabeller inom den virtuella anslutningen. Om du använder den virtuella anslutningen som en direkt källa för en arbetsbok eller som en anslutningstyp för ytterligare en publicerad datakälla kan du koppla tabeller och göra ytterligare anpassningar av datakällan.
När en virtuell anslutning har skapats och publicerats till Tableau Server eller Tableau Cloud och korrekta behörigheter har ställts in kan du ansluta till den virtuella anslutningen i Tableau Desktop eller Tableau Server/Cloud precis som du skulle göra med vilken annan datakälla som helst. Du behöver dock inte ange databasens serverplats eller inloggningsuppgifter och du kommer omedelbart att kunna koppla tabeller och fortsätta med att visualisera data eller publicera datakällan.
Datapolicyer
Utöver de centraliserade databasanslutningsfunktionerna som har beskrivits tidigare har Tableau Data Managements virtuella anslutningar även ett effektivare centraliserat alternativ för säkerhet på radnivå med datapolicyer. Använd en datapolicy för att tillämpa säkerhet på radnivå på en eller flera tabeller i en virtuell anslutning. En datapolicy filtrerar data, vilket säkerställer att användarna bara ser de data de ska se. Datapolicyer tillämpas på både live- och extraktanslutningar.
När är datapolicyer användbara?
I många organisationer är det vanligt att automatiskt begränsa data som är synliga i en visualisering till bara det som är tillämpligt för den aktuella användaren. Vi tar en delad instrumentpanel som innehåller beställningsinformation i ett korstabellobjekt som exempel.
Om du är försäljningschef för ett stort område visar korstabellen beställningar för varje kontoansvarig inom ditt område.
Om du däremot är en enskild kontoansvarig visar korstabellen endast beställningar för dina konton.
Det här scenariot kräver att säkerhet på radnivå implementeras i din Tableau-miljö, vilket kan åstadkommas med en av flera metoder, inklusive följande:
Säkerhet på radnivå i databasen. Varje gång en visualisering visas uppmanas användaren att logga in i den underliggande databasen med sina egna inloggningsuppgifter eller så ärvs användarens inloggningsuppgifter från hans eller hennes Tableau-användarkonto. Den resulterande datauppsättningen begränsas till de data som användaren tillåts att visa baserat på de angivna inloggningsuppgifterna. Detta kan inte bara snabbt bli tröttsamt eftersom varje användare måste använda sina egna inloggningsuppgifter, men livedataanslutningen kan påverka prestandan genom en kraftig belastning av den underliggande databasen. Dessutom kan vissa alternativ för att överföra inloggningsuppgifter till liveanslutningar vara begränsade med Tableau Cloud.
Tableau-användarfilter. Användarfilter tillämpas när du skapar enskilda arbetsblad i en arbetsbok. Genom att ange kombinationer av antingen individuella Tableau-användares inloggningsuppgifter eller medlemskap i en eller flera Tableau-användargrupper kan individuella arbetsblad filtreras till att endast visa data som är relevanta för den aktuella användaren. Detta kan bli tröttsamt, eftersom varje enskilt arbetsblad i en arbetsbok kräver att användarfilter tillhandahålls – det finns inget sätt att ange ett användarfilter för en stor grupp av arbetsböcker genom en enda process. Om en användare dessutom oavsiktligt får redigeringsbehörighet till arbetsboken kan han eller hon enkelt dra användarfiltret från hyllan Filter och se alla underliggande data som han eller hon kanske inte har behörighet att visa.
Genom att använda en underuppsättning av Tableau-beräkningsspråket kan datapolicyer specificera komplexa regler (kanske genom att använda en relaterad ”berättigandetabell” i en databas) för att anpassa och begränsa data som den virtuella anslutningen returnerar baserat på användar-ID eller gruppmedlemskap. Det upprätthåller inte bara säkerheten på radnivå på datakällans nivå (alla arbetsböcker som är anslutna till datakällan kommer automatiskt att ärva säkerheten och tillämpa alla ändringar som görs inom den virtuella anslutningen) – det medför även ett extra lager av säkerhet genom att begränsa alla ändringar av datapolicyer till endast de med redigeringsbehörighet för den ursprungliga virtuella anslutningen.