Trouver des ensembles de données efficaces
Un moyen efficace d’apprendre à utiliser Tableau pour analyser des données (ou créer un échantillon ou un contenu de faisabilité) consiste à trouver un ensemble de données que vous jugez intéressant. Lorsque vous avez de véritables questions auxquelles vous voulez répondre avec des données, les étapes de l’analyse deviennent plus faciles et plus significatives.
La réalité des ensembles de données
Si vous cherchez un ensemble de données qui ne se compose pas de données officielles sanctionnées par les entreprises, tenez compte de deux faits incompressibles.
Vous ne trouverez pas ce que vous cherchez.
- Essayez d’éviter les attentes strictes de ce dont vous avez besoin.
- Restez flexible et ouvert d’esprit quant au contenu utilisable pour un projet donné.
- Parfois, les données que vous voulez se trouvent derrière un paywall - décidez si cela en vaut la peine ou non.
Vous devrez nettoyer les données.
- Préparez-vous à devoir nettoyer et organiser(Le lien s’ouvre dans une nouvelle fenêtre) un minimum les données afin qu’elles soient bien structurées pour l’analyse.
- Vous devrez peut-être intégrer des ensembles de données supplémentaires(Le lien s’ouvre dans une nouvelle fenêtre).
- Il peut être vital de disposer d’un dictionnaire de données ou de métadonnées.
- Des calculs peuvent être nécessaires.
Composants d’un ensemble de données efficace
Un ensemble de données efficace est celui qui convient à votre objectif. Tant que ce besoin est satisfait, votre ensemble de données remplit sa fonction. Toutefois, certaines considérations peuvent vous aider à éliminer les ensembles de données qui ne sont pas susceptibles de convenir à votre objectif. En règle générale, recherchez les ensembles de données qui remplissent les conditions suivantes :
- Contiennent les éléments dont vous avez besoin
- Contiennent des données désagrégées
- Contiennent au moins quelques dimensions et quelques mesures
- Disposent de métadonnées solides ou d’un dictionnaire de données
- Sont utilisables (les données ne sont pas dans un format propriétaire, trop compliqué ou trop lourd)
Superstore est l’un des exemples de source de données livrés avec Tableau Desktop. (Vous pouvez également le télécharger à partir de la Page d’échantillons de données de Tableau Public(Le lien s’ouvre dans une nouvelle fenêtre).) Pourquoi cet ensemble de données est-il si performant ?
- Éléments nécessaires : Superstore contient des dates, des données géographiques, des champs avec une relation hiérarchique (Catégorie, Sous-catégorie, Produit), des mesures qui sont positives et négatives (Profit), etc. Il existe très peu de types de graphiques que vous ne pouvez pas réaliser avec le seul Superstore, et très peu de fonctionnalités qu’il ne peut pas aider à démontrer.
- Données désagrégées : les données au niveau de la ligne correspondent à chaque élément d’une transaction. Ces éléments peuvent être regroupés au niveau de la commande (via l’ID de commande) ou selon l’une des dimensions (comme la date, le client, la région, etc.)
- Dimensions et mesures : Superstore inclut plusieurs dimensions, ce qui nous permet de « découper en tranches » selon des critères tels que la catégorie ou la ville. Il inclut également de nombreuses mesures et dates, ce qui ouvre des possibilités de types de graphiques et de calculs.
- Métadonnées : Superstore contient des champs et des valeurs au nom explicite. Vous n’avez pas besoin de chercher ce que signifient les valeurs.
- Petit et propre : Superstore ne pèse que quelques mégaoctets et prend donc très peu de place dans l’installateur du Tableau. Il s’agit également de données très ordonnées, ne comportant que des valeurs correctes dans chaque champ et une structure de données efficaces.
1. Un ensemble de données performant comporte les éléments dont vous avez besoin pour vos objectifs
Si vous recherchez un ensemble de données pour créer une visualisation spécifique ou pour mettre en valeur des fonctionnalités particulières, assurez-vous que l’ensemble de données comporte les types de champs dont vous avez besoin. Par exemple, les cartes sont un excellent support visuel mais nécessitent des données géographiques. Les démonstrations de base impliquent souvent une exploration en cascade des dates. Les données nécessitent donc au moins un champ de date (et il faudrait qu’il soit d’une granularité supérieure à une seule année pour permettre une exploration en cascade). Tous les ensembles de données n’ont pas besoin de tous ces éléments. Vous devez déterminer ce dont vous avez besoin pour votre objectif et ne pas perdre de temps avec des ensembles de données auxquels il manque des éléments clés.
Éléments courants d’analyse :
- Dates
- Données géographiques
- Données hiérarchiques
- Mesures « intéressantes » : soit une variation de grande ampleur, soit des valeurs positives et négatives
Certaines fonctionnalités ou certains types de données peuvent nécessiter des caractéristiques spécifiques des données, telles que :
- Clusters(Le lien s’ouvre dans une nouvelle fenêtre)
- Prévisions(Le lien s’ouvre dans une nouvelle fenêtre)
- Courbes de tendances(Le lien s’ouvre dans une nouvelle fenêtre)
- Filtres utilisateur(Le lien s’ouvre dans une nouvelle fenêtre)
- Calculs spatiaux(Le lien s’ouvre dans une nouvelle fenêtre)
- Calculs(Le lien s’ouvre dans une nouvelle fenêtre) spécifiques
- Graphiques à puces(Le lien s’ouvre dans une nouvelle fenêtre)
2. Un ensemble de données performant est constitué de données désagrégées (brutes)
Des données trop agrégées(Le lien s’ouvre dans une nouvelle fenêtre) ne sont guère utiles pour l’analyse. Par exemple, si vous souhaitez examiner les tendances des personnes qui consultent « Pumpkin Spice » sur Google mais que vous disposez de données annuelles, vous ne pouvez qu’obtenir un aperçu de très haut niveau. L’idéal serait de mettre la main sur des données quotidiennes, afin de pouvoir constater le pic spectaculaire atteint à la date à laquelle Starbucks a lancé #PSL.
Ce qui est considéré comme des données désagrégées peut varier selon l’analyse. Notez que pour des raisons de confidentialité ou de commodité, la granularité de certains ensembles de données ne sera jamais entière. Par exemple, il est peu probable que vous trouviez un ensemble de données avec une déclaration au cas par cas des cas de paludisme, de sorte que les totaux mensuels par région pourraient être suffisamment granulaires.
Comprendre l’agrégation et la granularité est un concept essentiel pour de nombreuses raisons. Il a des répercussions sur des opérations telles que la recherche d’ensembles de données utiles, la création de la visualisation de votre choix, la combinaison correcte des données et l’utilisation des expressions LOD. L’agrégation et la granularité sont les extrémités opposées d’un spectre.
L’agrégation fait référence à la manière dont les données sont combinées entre elles, par exemple en additionnant toutes les recherches de Pumpkin Spice ou en prenant la moyenne de toutes les températures relevées autour de Seattle un jour donné.
- Par défaut, les mesures sont agrégées dans Tableau. L’agrégation par défaut est SUM. Vous pouvez modifier l’agrégation sur des éléments tels que la moyenne, la médiane, le total distinct, le minimum, etc.
La granularité fait référence au degré de détail des données. Que représente une ligne (ou un enregistrement) dans l’ensemble de données ? Une personne atteinte de malaria ? Le nombre total de cas de paludisme d’une province pour le mois ? C’est ce qu’on appelle la granularité. Connaître la granularité des données est crucial.
Pour en savoir plus, consultez Agrégation de données dans Tableau.
3. Un ensemble de données performant comporte des dimensions et des mesures
De nombreux types de visualisation requièrent des dimensions et des mesures
- Si vous n’avez que des dimensions, vous êtes largement limité aux opérations de totalisation, calcul de pourcentages ou utilisation du champ Total de tables.
- Si vous n’avez que des mesures, vous ne pouvez pas diviser les valeurs par quoi que ce soit. Vous pouvez désagréger les données entièrement ou travailler avec l’agrégation globale SUM ou AVG, etc.
Cela ne signifie pas qu’un ensemble de données comportant seulement des dimensions est inutile. Les données démographiques sont un exemple de données comportant beaucoup de dimensions, et une grande partie de l’analyse relative à la démographie est basée sur les totaux ou les pourcentages. Mais pour obtenir un ensemble de données plus riche sur le plan analytique, il faut au moins quelques dimensions et mesures.
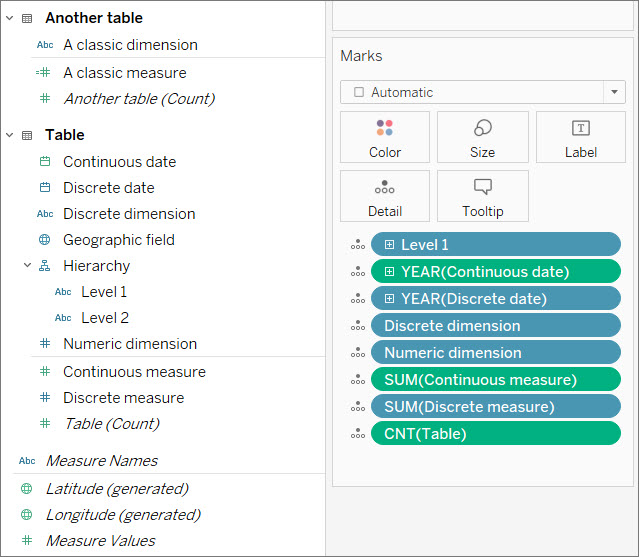
Dans l’image ci-dessus, notez que la Dimension numérique n’a pas d’agrégation sur la fiche Repères, à la différence de Mesure continue et Mesure discrète.
Dimensions et mesures
Les champs sont divisés en dimensions et en mesures avec une ligne horizontale dans le volet Données. Dans Tableau, les dimensions apparaissent en tant que telles dans la vue, alors que les mesures sont automatiquement agrégées. L’agrégation par défaut pour une mesure est SUM.
- Les dimensions sont qualitatives, c’est-à-dire qu’elles sont décrites et non mesurées.
- Les dimensions sont souvent par exemple une ville ou un pays, la couleur des yeux, une catégorie, un nom d’équipe, etc.
- Les dimensions sont généralement discrètes.
- Les mesures sont quantitatives, c’est-à-dire qu’elles peuvent être mesurées et enregistrées (numériques).
- Les mesures sont souvent par exemple des ventes, une hauteur, un nombre de clics, etc.
- Les mesures sont généralement continues.
Si vous pouviez faire des calculs avec un champ, ce champ est probablement une mesure. Si jamais vous n’êtes pas sûr qu’un champ doive être une mesure ou une dimension, pensez à la possibilité de faire des calculs significatifs avec les valeurs. La fonction AVG(RowID), la somme de deux numéros de sécurité sociale ou la division d’un code postal par 10 a-t-elle une signification ? Non. Ce sont des dimensions qui s’écrivent sous la forme de nombres. Pensez au nombre de pays qui ont des codes postaux alphanumériques - ce sont simplement des étiquettes, même si aux États-Unis, ils ne sont que numériques. Tableau peut reconnaître de nombreux noms de champs indiquant qu’un champ numérique est en fait une identification ou un code postal, et essaie d’en faire des dimensions, mais le processus n’est pas parfait. Utilisez le test « Pourrais-je faire des calculs avec ça ? » pour décider si un champ numérique doit être une mesure ou une dimension et réorganisez le volet Données comme nécessaire.
Remarque : même si vous pouvez faire des calculs avec des dates (comme le calcul DATEDIFF), la convention standard consiste à classer les dates en tant que dimensions.
Discret et continu
Les champs discrets ou continus sont assez proches des concepts de dimension et de mesure, mais ils ne sont pas identiques.
- Les champs discrets contiennent des valeurs distinctes. Ils forment des en-têtes ou des étiquettes dans la vue et les piliers sont bleus
- Les champs continus forment un tout ininterrompu. Ils forment un axe dans la vue et les piliers sont vertes
Pour bien appréhender le discret et le continu, vous pouvez examiner un champ de date. Les dates peuvent être discrètes OU continues.
- Si l’on considère les températures moyennes en août sur une décennie ou un siècle, cela signifie que « Août » est utilisé comme une partie de date qualitative et discrète.
- L’examen de la tendance générale des cas de paludisme signalés depuis 1960 prendrait un axe unique et ininterrompu, ce qui signifie que la date est utilisée comme une valeur quantitative continue.
Pour plus d’informations, consultez Dimensions et mesures, Bleu et vert.
Tableau crée au moins trois champs, quel que soit l’ensemble de données :
- Noms de mesures (une dimension)
- Valeurs de mesures (une mesure)
- TableName(Count) (une mesure)
Et si l’ensemble de données comporte des champs géographiques, Tableau créera également des champs de Latitude (généré) et de Longitude (généré).
Les noms de mesures et les valeurs de mesures sont deux champs utiles. Pour plus d’informations, reportez-vous à Valeurs de mesures et noms de mesures.
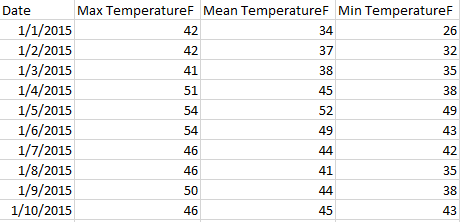
Total de tables fournit le nombre d’enregistrements pour la table en comptant les lignes. Cela vous permet d’avoir au moins une mesure dans votre ensemble de données et peut vous aider dans certaines analyses. Vous devez comprendre la granularité de vos données (ce que représente une ligne) pour pouvoir définir ce que signifie le nombre d’enregistrements.
Ici, chaque ligne correspond à un jour, donc le total de tables serait le nombre de jours :
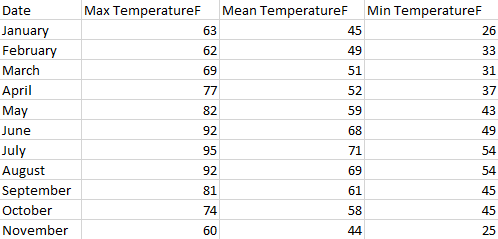
Ici, chaque ligne correspond à un mois, donc le nombre de tables serait le nombre de mois :
4. Un ensemble de données efficace comporte des métadonnées ou un dictionnaire de données
Un ensemble de données ne peut être utile que si vous savez à quoi correspondent ces données. Il est particulièrement frustrant, dans la quête de données performantes, d’ouvrir un fichier qui se présente ainsi :
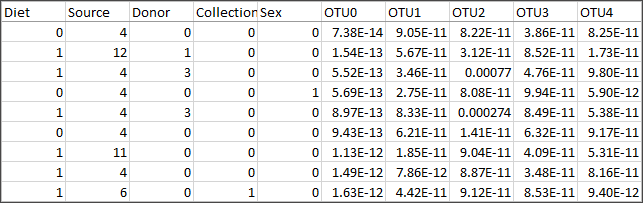
Que signifie une source de 4 ou de 12 ? Et quelles sont les informations contenues dans les champs OTU0-OTU4 ?
Un ensemble de données efficace est celui qui comporte soit des champs et des membres bien étiquetés, soit un dictionnaire de données qui vous permet de réétiqueter les données vous-même. Pensez à Superstore : les champs et leurs valeurs sont immédiatement évidents, tels que la catégorie et ses membres (technologie, mobilier et fournitures de bureau). Ou, pour l’ensemble des données sur les microbiomes dans l’image ci-dessus, il existe un dictionnaire de données(Le lien s’ouvre dans une nouvelle fenêtre) qui explique chaque source (4 est la matière fécale et 12 l’estomac) et la taxonomie de chaque OTU (OTU3 est une bactérie du genre Parabacteroides).
Les dictionnaires de données peuvent également être appelés métadonnées, indicateurs, définitions de variables, glossaires, ou bien d’autres termes. Au bout du compte, un dictionnaire de données fournit des informations sur les noms des colonnes et les membres d’une colonne. Ces informations peuvent être introduites dans la source de données ou la visualisation de plusieurs façons, notamment :
- Renommer les colonnes pour qu’elles soient plus faciles à comprendre (vous pouvez le faire dans l’ensemble de données lui-même ou dans Tableau).
- Ré-aliaser les membres du champ (vous pouvez le faire dans l’ensemble de données lui-même ou dans Tableau).
- Créer des calculs pour ajouter les informations du dictionnaire de données.
- Commenter le champ dans Tableau (les commentaires n’apparaissent pas sur les visualisations publiées, mais seulement dans l’environnement de création).
- Utiliser le dictionnaire de données comme autre source de données et combiner les deux sources de données.
La perte d’un dictionnaire de données peut rendre un ensemble de données inutilisable. Si vous ajoutez un ensemble de données à vos favoris, ajoutez-y également le dictionnaire de données. En cas de téléchargement, téléchargez les deux et conservez-les au même endroit.
5. Un ensemble de données efficace est celui que vous pouvez utiliser
Tant que vous pouvez comprendre l’ensemble de données et qu’il contient les informations dont vous avez besoin, même un petit ensemble de données peut être très utile pour l’analyse. Les petits ensembles de données sont également faciles à stocker, à partager et à publier, et peuvent être performants.
De même, il se peut que vous trouviez l’ensemble de données « parfait » pour vos besoins, mais s’il nécessite un effort irréaliste de nettoyage, c’est qu’il n’est pas si parfait après tout. Il est important de savoir renoncer à un ensemble de données trop désorganisé.
Par exemple, cet ensemble de données provient d’un article de Wikipédia sur les fréquences relatives des lettres. Au départ, il comportait 84 lignes et 16 colonnes (permutées pour former 1245 lignes et 3 colonnes). Le fichier Excel est de 16KB. Mais avec certains groupes, ensembles, calculs et autres manipulations, il permet une analyse robuste et des visuels intéressants.
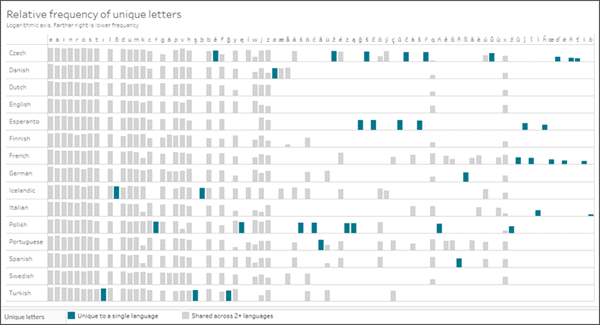
Cliquez sur l’image pour télécharger le classeur.
Réétiqueter vos données
Une fois que vous avez trouvé un ensemble de données efficace, il vous faudra souvent le réétiqueter. Le réétiquetage des données peut être utile pour créer des données factices pour des échantillons ou des démonstrations, ou pour rendre les données plus lisibles.
Le fait de renommer un champ modifie la manière dont il s’affiche dans Tableau, par exemple si vous renommez « Ventes » en « Ventes de pipeline » ou « État » en « Province ».
Le ré-aliasing modifie la façon dont les membres d’un champ sont affichés, par exemple en ré-aliasant les valeurs d’un champ Pays de manière à ce que CHN devienne la Chine et RUS la Russie.
- Les valeurs dans un champ de dimension discrète sont appelées membres. Seuls les membres peuvent être ré-aliasés. Envisagez un champ de mesure pour la température. Une valeur de 54°F ne peut pas être modifiée sans changer les données elles-mêmes. Mais lorsque vous ré-aliasez le membre « CHN » en « Chine » dans un champ Pays, il s’agit de la même information, qui est simplement étiquetée d’une autre manière.
Renommer et ré-aliaser signifie quasiment la même chose. Selon la convention de Tableau, les champs sont nommés et les membres sont aliasés. Pour plus d’informations, voir Organiser et personnaliser des champs dans le volet Données et Créer des alias pour renommer des membres de la vue.
Remarque : le renommage ou le ré-aliasing modifie seulement l’apparence dans Tableau Desktop. Aucune modification n’est répercutée sur les données sous-jacentes.
Réétiqueter pour fabriquer des données factices
Le réétiquetage des ensembles de données existants est un excellent moyen de rendre les échantillons ou le contenu de la démonstration plus convaincants.
- Utilisez un ensemble de données facile (comme Superstore) pour créer ce que vous souhaitez (type de graphique spécifique, présentation de certaines fonctionnalités, etc.)
- Renommez les champs pertinents, modifiez les infobulles et modifiez à votre convenance les aspects textuels pour masquer ce que les données représentent réellement.
Important : ne le faites que si les informations sont clairement factices. Évitez que les gens pensent qu’il s’agit de données réelles et soient tentés de les utiliser pour l’analyse. Par exemple, utilisez des noms farfelus ou des noms de champs sans signification comme des couleurs ou des animaux.
Ré-aliaser pour rendre les données plus faciles à utiliser
Il est plus efficace de stocker les données sous forme de valeurs numériques plutôt que de chaînes de caractères, bien que le codage numérique puisse rendre les données plus difficiles à comprendre. Pour les petits ensembles de données, cela n’aura probablement pas d’impact sur les performances. Il faut dans ce cas privilégier la possibilité de comprendre facilement les données.
Un inconvénient du ré-aliasing est que vous n’avez plus accès à ces valeurs numériques (ce qui rend plus difficile le tri, l’attribution de dégradés de couleurs, etc.). Envisagez de dupliquer le champ et de ré-aliaser la copie. Sinon, un calcul dans Tableau peut être un bon moyen de préserver les informations d’origine tout en les rendant plus facilement compréhensibles.
Ré-aliaser avec la fonction CASE
Les calculs peuvent être très puissants pour le ré-aliasing. Ainsi, les fonctions CASE(Le lien s’ouvre dans une nouvelle fenêtre) vous permettent de dire, par exemple, « lorsque ce champ a une valeur de A, donnez-moi X. Lorsque la valeur est B, donnez-moi Y ».
Ici, la fonction CASE examine l’échelle F dans un ensemble de données sur les tornades et fournit la description écrite associée à chaque valeur numérique :
CASE [F-scale]
WHEN "0" THEN "Some damage to chimneys; branches broken off trees; shallow-rooted trees pushed over; sign boards damaged."
WHEN "1" THEN "The lower limit is the beginning of hurricane wind speed; peels surface off roofs; mobile homes pushed off foundations or overturned; moving autos pushed off the roads..."
WHEN "2" THEN "Roofs torn off frame houses; mobile homes demolished; boxcars overturned; large trees snapped or uprooted; highrise windows broken and blown in; light-object missiles generated."
WHEN "3" THEN "Roofs and some walls torn off well-constructed houses; trains overturned; most trees in forest uprooted; heavy cars lifted off the ground and thrown."
WHEN "4" THEN "Well-constructed houses leveled; structures with weak foundations blown away some distance; cars thrown and large missiles generated."
WHEN "5" THEN "Strong frame houses lifted off foundations and carried considerable distances to disintegrate; ... trees debarked; steel reinforced concrete structures badly damaged."
END
Nous pouvons maintenant choisir d’utiliser soit le champ original « F-scale » (0-5), soit le champ « F-scale damage description » dans la visualisation.
Conseils pour la recherche d’ensembles de données
Remarque : assurez-vous que vous pouvez répondre à la question « Que représente une ligne (alias un enregistrement) dans l’ensemble de données ? » Si vous n’arrivez pas à l’articuler, vous risquez de ne pas comprendre suffisamment bien les données pour pouvoir les utiliser ou elles peuvent être mal structurées pour l’analyse.
- Gardez une trace de la provenance des données.
- Conservez les informations du dictionnaire de données avec les données elles-mêmes.
- Évitez les données obsolètes si vous avez besoin que le contenu reste à jour. Recherchez :
- des données actualisables (stocks, météo, rapports publiés régulièrement, etc.)
- des données intemporelles (la masse moyenne des différents animaux ne va pas changer d’une année à l’autre)
- des données que vous pouvez pérenniser en les remplaçant artificiellement par des dates historiques ou futures
- Essayez simplement de Googler ce que vous recherchez, vous pourriez avoir des surprises.
- N’ayez pas peur de renoncer à un ensemble de données s’il nécessite trop de préparation.
Où rechercher des données
Où pouvez-vous rechercher des données ? Il existe un nombre colossal de sources possibles pour les ensembles de données. Voici quelques options pour démarrer. Notez que la réalité des ensembles de données s’applique à ces sites. Vous ne trouverez sans doute pas ce que vous avez en tête à de moment précis et vous devrez très probablement faire un peu de nettoyage pour que les données soient prêtes à être analysées.
Décharge de responsabilité : bien que nous fassions tout notre possible pour que ces liens vers des sites externes soient précis, à jour et pertinents, Tableau ne peut pas garantir la précision ou l’actualité des pages gérées par des fournisseurs externes. Le fait d’inscrire un site ici ne constitue pas une approbation de son contenu ou de l’entreprise. Contactez le site externe pour des réponses aux questions concernant son contenu.
Tableau Public(Le lien s’ouvre dans une nouvelle fenêtre) : Tableau Public est une ressource remarquable pour les ensembles de données compatibles avec Tableau. Recherchez les classeurs qui traitent d’un sujet qui vous intéresse, parcourez-les pour trouver de l’inspiration, puis téléchargez le classeur pour accéder aux données. Vous pouvez aussi consulter des Échantillons de données(Le lien s’ouvre dans une nouvelle fenêtre).
Tables Wikipédia(Le lien s’ouvre dans une nouvelle fenêtre) : obtenez des données à partir des tables Wikipédia en : copiant et collant dans une feuille de calcul, en copiant et collant directement dans Tableau, ou en utilisant Google Sheets et la fonction IMPORTHTML(Le lien s’ouvre dans une nouvelle fenêtre) pour créer une feuille de calcul Google des données.
Recherche d’ensembles de données sur Google(Le lien s’ouvre dans une nouvelle fenêtre) : « Un moteur de recherche pour unifier le monde fragmenté des ensembles de données en ligne »
Les données sont plurielles(Le lien s’ouvre dans une nouvelle fenêtre) : abonnez-vous à une lettre d’information hebdomadaire contenant des ensembles de données, ou parcourez les archives(Le lien s’ouvre dans une nouvelle fenêtre).
Lundi du relooking(Le lien s’ouvre dans une nouvelle fenêtre) : participez chaque lundi à un travail sur un ensemble de données donné et à la création de visualisations plus performantes et plus efficaces pour nous aider à rendre l’information plus accessible. Vous pouvez voir ce que d’autres personnes ont fait avec le même ensemble de données, pour stimuler votre analyse ou trouver une source d’inspiration. Utilisez #makeovermonday(Le lien s’ouvre dans une nouvelle fenêtre) sur Twitter pour participer.
Autres sites
- Connecteurs de données Web Tableau(Le lien s’ouvre dans une nouvelle fenêtre)
- Data.world(Le lien s’ouvre dans une nouvelle fenêtre) et son WDC pour Tableau(Le lien s’ouvre dans une nouvelle fenêtre)
- Données ouvertes Github(Le lien s’ouvre dans une nouvelle fenêtre)
- Kaggle(Le lien s’ouvre dans une nouvelle fenêtre)
- datahub.io(Le lien s’ouvre dans une nouvelle fenêtre)
- r/datasets(Le lien s’ouvre dans une nouvelle fenêtre)
- OMS(Le lien s’ouvre dans une nouvelle fenêtre)
- Data.UN.org(Le lien s’ouvre dans une nouvelle fenêtre)
- Banque mondiale(Le lien s’ouvre dans une nouvelle fenêtre)
- data.gov(Le lien s’ouvre dans une nouvelle fenêtre), data.gov.au(Le lien s’ouvre dans une nouvelle fenêtre), data.gov.uk(Le lien s’ouvre dans une nouvelle fenêtre), etc.
- Airbnb(Le lien s’ouvre dans une nouvelle fenêtre)
- Yelp(Le lien s’ouvre dans une nouvelle fenêtre)
- Zillow(Le lien s’ouvre dans une nouvelle fenêtre)