Tableau Data Management
このコンテンツは、Tableau Blueprint の一部です。Tableau Blueprint は、組織がデータの活用方法を拡大および改善して、影響力を強化できるよう支援する成熟したフレームワークです。使用を開始する前に、まず評価(新しいウィンドウでリンクが開く)を受けてください。
Tableau Data Management を使用すると、分析環境内のデータをより適切に管理できるようになり、常に信頼できる最新のデータを基にして意思決定を行えるようになります。データの準備から、カタログ化、検索、ガバナンスに至るまで、Tableau Data Management はデータへの信頼性を高め、セルフサービス分析の利用を促進します。このサービスは、Tableau Prep Conductor と Tableau Catalog を含むさまざまな機能の集まりであり、個別にライセンスが必要です。これにより、Tableau Server や Tableau Cloud にある Tableau コンテンツとデータ アセットを管理することができます。
Tableau Data Management とは
全体的に見ると、組織は、「データ ガバナンス」と「データ ソース管理」のアプローチによってメリットが得られるでしょう。これらのアプローチについては、Tableau Blueprint の他の場所で説明されています。それらの方法論にとどまらず、データベース、データ分析、ビジュアライゼーションのコミュニティでは「データ マネジメント」という一般的な用語をよく耳にします。しかし、この用語は、Tableau Server と Tableau Cloud で使用する一連の機能である Tableau Data Management では、より具体的な意味になります。Tableau Data Management の機能は、Tableau Server を Windows または Linux で使用しているか、Tableau Cloud を使用しているかに関わらずほとんど同じです (Tableau Cloud または Tableau Server でのみ利用できる機能も一部にあります)。
Tableau Data Management には、組織でデータ管理やデータ分析を行う人たちがデータ関連のコンテンツとアセットを Tableau 環境で管理するのに役立つ一連のツールが含まれています。具体的には、Tableau Data Management を購入すると、次の 3 つの機能セットが追加されます。
Tableau Catalog
Tableau Prep Conductor
仮想接続とデータ ポリシー
Tableau Catalog
Tableau Data Management の本来の機能である Tableau Catalog には、Tableau データ ソースへのアクセスのしやすさ、理解のしやすさ、信頼度のわかりやすさを実現するための機能が備わっています。Tableau Catalog は、系列、データ品質、検索、影響分析などの領域に焦点を当てており、データ管理、データ可視化、データ分析を行う人たちにとって Tableau Server や Tableau Cloud のデータ ソースを理解し、信頼するのが容易になります。Tableau Catalog には、Tableau REST API のメタデータ メソッドを介した、Tableau 開発者向けの追加機能も含まれています。
Tableau Catalog を初めて有効にすると、Tableau Server や Tableau Cloud サイト内のすべての関連コンテンツ アイテムがスキャンされ、すべての関連オブジェクトの接続ビューが構築されます (Tableau Catalog ではこれをコンテンツ メタデータと呼びます)。これにより、単なるデータ接続を超えて検索機能が拡張されます。データ管理者やビジュアル作成者は、列、データベース、テーブルに基づいて検索することができます。
あるオブジェクトが依存する別のオブジェクトを不注意に変更または削除してしまう可能性を減らすために (たとえば、実稼働ワークブックのキーとなるデータベース列の名前を変更または削除するなど)、Tableau Catalog の系列機能で、メトリクス、フロー、仮想接続を含む Tableau サイト上のすべてのコンテンツ間の相互関係を明らかにします。オブジェクト間の関係を簡単に確認し、保留中の変更を実行する前にその影響を分析できるようになりました。

Tableau データ ソースの信頼性を向上させるために、Tableau Catalog には拡張されたデータ関連オブジェクトの説明、データの詳細ビュー、検索の柔軟性を高めるためのキーワード タグなどの補足情報が用意されています。データソースを認定すると、データ ソースの横に目立つアイコンが配置され、データ ソースの所有者または管理者がデータ ソースを信頼していることが示されます。非推奨のデータや古いデータなど、利用者にとって懸念材料となる可能性のあるデータ項目 (データ ソース、列など) には、データ品質に関する警告を指定することもできます。データ品質に関する警告のオプションに加えて、機密データには機密ラベルのフラグを特別に付けることもできます。
![]()
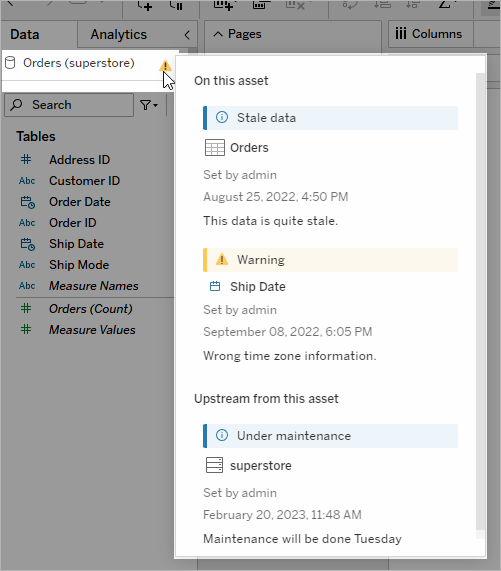
Tableau Prep Conductor
Tableau Prep Builder の利点については、多くの Tableau ユーザーと同じように、すでにお気づきのことでしょう。複数のデータ ソースを組み合わせ、データを成形し、列をカスタマイズし、1 つまたは複数の希望のデータ形式に出力できる、データ準備の高度な「フロー」を作成することができます。しかし、完璧な準備フローを作成しても、それを自動化して、スケジュールに従ってデータ ソースを完全または段階的に更新するにはどうすればよいでしょうか?
そこで、Data Management のもう 1 つの機能である Tableau Prep Conductor が活躍します。Tableau Prep Conductor を使用すると、Tableau Prep フローを柔軟にスケジューリングできます。それは、Tableau Prep Builder から Tableau Server または Tableau Cloud 環境にパブリッシュするか、Prep フロー Web 作成を使用してブラウザーで直接作成するかに関わらず実行できます。まず、Web ベースのフローをテストします (Data Management を使用せずにオンデマンドで手動によりフローを実行することもできますが、Prep Conductor でフローが自動的に実行されるようにスケジュールするには、Data Management を購入する必要があります)。スケジューリングする前に、フローが最後まで実行され、エラーなく目的のデータ ソースが出力される必要があります。
Tableau Server を使用している場合、管理者 (または適切な権限がある人) は、抽出更新のために行っていたのと同じように、カスタム スケジュール (「毎日午前 0 時」、「日曜日の正午」など) を作成して準備フローを実行できます。
Tableau Cloud を使用している場合、事前定義された一連の準備フロー スケジュールが既定でインストールされています。これらをカスタマイズしたり、独自の準備フロー スケジュールを作成したりすることはできません。
[アクション] メニューからフローの実行をスケジュールします。単一タスクのスケジュールは、選択したスケジュールで選択した準備フローのみを実行します。リンクされたタスクのスケジュールは、複数のフローを特定の順序で実行するように「チェーン」することができます。選択したフローと、順番に実行する 1 つまたは複数の追加フローを選択することができ、あるデータ ソースを出力して後続のフローの入力として使用することなどが可能になります。フローはスケジュールどおりに実行され、Tableau ワークブックのベースとなるデータ ソースが自動的に更新または作成されます。
フローをスケジュールする機能に加えて、Data Management と Tableau Prep Conductor にはいくつかのオプションが追加されています。スケジュールされたフローの成功または失敗の監視、フロー スケジュールが成功または失敗したときのメール通知の送信、Tableau Server または Tableau Cloud の REST API を使用したプログラムでのフローの実行、フローのパフォーマンス履歴を監視する追加の管理ビュー機能から得られる利点などのオプションです。
ベスト プラクティスの推奨事項: Tableau Server 上で多数の Tableau Prep Conductor フローを実行する予定がある場合は、サーバー環境のスケーリングを調整する必要があるかもしれません。求められる準備フローの負荷に対応するには、必要に応じてノードやバックグラウンダー プロセスを追加し、Tableau Server システムのパフォーマンスを調整します。
Tableau Cloud の場合はどうでしょうか? 準備フローの処理容量を確保するために Tableau Cloud のアーキテクチャを変更する必要はありませんが、Tableau Prep Conductor で同時フローをスケジューリングする場合は、各フローに 1 つのリソース ブロック (Tableau Cloud 処理容量の単位) を取得する必要があります。必要とする同時フローのスケジュール数を定めて、それに応じて Tableau Cloud のリソース ブロックを購入します。
仮想接続
Data Management の次の機能は、仮想接続です。仮想接続は、データへのアクセス ポイントを一元化するものです。複数のデータベースにまたがって複数のテーブルにアクセスすることが可能になります。仮想接続では、データの抽出とセキュリティを接続レベルで一元管理できます。
仮想接続が役に立つ場面
データベース接続を Tableau の複数のワークブックから従来の方法で共有するには、SQL Server や Snowflake などのデータベース サーバーに直接接続し、データベースへ認証資格情報を提示してログインし、1 つまたは複数のテーブルを追加して結合し、データ ソースを Tableau Server や Tableau Cloud にパブリッシュする、といったことを思い浮かべるでしょう。これをデータへのライブ接続で使用することもできますが、データ ソースからデータを抽出して、接続されたワークブックを高速化したいとおそらく思うでしょう。
理解を深めるために、たとえば、さまざまなテーブルや結合の集まりを収容する目的で、この操作を何度も実行することを考えてみます。データソースを使用する一連のワークブックはテーブルや結合の要件が異なるので、その結果、パブリッシュされた (そしておそらくは抽出された) データ ソースがいくつもできることでしょう。ところが、それらが使用している元のデータベースはすべて同じものです。
ここで、一連のデータ ソースが参照する元の SQL Server や Snowflake のデータベースで何らかの変更があると、何が起こるでしょうか? たとえば、テーブル名が変更されたり、フィールドが追加されたり、データベースの認証資格情報が変更されたりした場合です。前に作成したデータ ソースを一つずつ開き、データベースの変更に伴う必要な変更を加え、もう一度パブリッシュする (そしておそらくは抽出更新をスケジュールし直す) というタスクに直面することになるでしょう。
そのため、元のデータ接続の「定義」を 1 つだけ作成して、そこにデータベース サーバー名、認証資格情報、テーブル参照を保存する方が簡単だと思うでしょう。そして、そのより大きな「定義」からデータを抽出することを望むでしょう。これにより、テーブルや結合などの組み合わせが異なるさまざまなデータ ソースを作成する必要があっても、いくつかのデータベース サーバーに直接接続するのではなく、その元の「定義」を参照ことが可能になります。コアとなるデータベース構造で何らかの変更 (テーブル名や認証資格情報の変更など) があった場合、元の「定義」オブジェクトを変更するだけで済み、その変更は依存するすべてのデータ ソースに自動的に継承されます。
Data Management には、この仮想接続を介した「定義」の共有機能が導入されています。仮想接続は、データベース サーバー、ログイン認証資格情報、選択したテーブルを保存するという点で標準のデータ ソース接続に似ています。また、従来の Tableau データ ソースと同様に、仮想接続には複数のデータベースやデータ ソースへの接続を含めることができます。各接続には、それぞれ個別の認証資格情報とテーブルが含まれています。仮想接続では一部のメタデータの変更 (フィールドの非表示や名前変更など) が許可されていますが、テーブルは仮想接続内で結合されません。最終的に仮想接続をワークブックの直接ソースとして使用する場合、またはパブリッシュされた追加のデータ ソースの接続タイプとして使用する場合、テーブルを結合して、データ ソースに対するカスタマイズをさらに行うこともできます。
仮想接続を作成して Tableau Server または Tableau Cloud にパブリッシュし、適切な権限を設定したら、他のデータ ソースに接続するのと同じように、Tableau Desktop または Tableau Server や Tableau Cloud で仮想接続に接続できます。データベース サーバーの場所を指定したり、認証資格情報を入力したりする必要はなく、テーブルを結合して、データの視覚化やデータ ソースのパブリッシュにすぐに進むことができます。
データ ポリシー
前に説明した一元化されたデータベース接続機能に加えて、Tableau Data Management の仮想接続では、より合理化され、一元化された行レベルのセキュリティ オプションもデータ ポリシーにより提供しています。データ ポリシーを使用すると、仮想接続内の 1 つまたは複数のテーブルに行レベルのセキュリティを適用できます。データ ポリシーは、データをフィルタリングし、ユーザーに表示されるべきデータのみが表示されるようにします。データ ポリシーは、ライブ接続と抽出接続の両方に適用されます。
データ ポリシーが役に立つ場面
一般に多くの組織では、現在のユーザーに当てはまるデータのみがビジュアライゼーションに表示されるように自動的に制限を行います。たとえば、クロス集計オブジェクトに注文の詳細が含まれる共有ダッシュボードを考えます。
広い地域の営業マネージャーであれば、詳細のクロス集計には地域内のすべての営業担当者の注文が表示されます。
一方、個々の営業担当者であれば、詳細のクロス集計には担当する注文のみが表示されます。
このシナリオでは、Tableau 環境に行レベルのセキュリティを実装する必要があります。これは、次のようないくつかの方法で実現できます。
データベースの行レベルのセキュリティ。ビジュアライゼーションが表示されるたびに、閲覧者は自分の認証資格情報を使用して参照元のデータベースにログインするか、Tableau ユーザー アカウントから認証資格情報を継承するように求められます。結果として得られるデータ セットは、提供された認証資格情報に基づいて、閲覧が許されたデータのみに制限されます。各閲覧者は自分の認証資格情報を持っている必要があるため、この作業はすぐに面倒になるだけでなく、ライブ データ接続は参照元のデータベースに大きな負荷をかけるため、パフォーマンスに影響を与える可能性があります。さらに、Tableau Cloud では、ライブ接続に認証資格情報を渡すことを選択できない場合があります。
Tableau のユーザー フィルター。ユーザー フィルターは、ワークブック内に個別のワークシートを作成するときに適用されます。個々の Tableau ユーザーの認証資格情報、あるいは 1 つまたは複数の Tableau ユーザー グループのメンバーシップの組み合わせを指定することで、個々のワークシートをフィルタリングして、そのユーザーに関連するデータのみを表示できます。ワークブック内の個々のワークシートでユーザー フィルターを指定する必要があるため、この作業は面倒になる可能性があります。多くのワークブックの集まりに対して 1 つのプロセスでユーザー フィルターを指定する方法はありません。さらに、ユーザーがワークブックに対する編集権限を誤って与えられた場合、ユーザー フィルターをフィルター シェルフからドラッグして簡単に外すことができ、表示権限のない参照元のデータがすべて表示されてしまう可能性があります。
Tableau 計算言語の一部を利用すると、ユーザー ID やグループ メンバーシップに基づいた高度なルールをデータ ポリシーで指定し (おそらくデータベース内の関連する「資格テーブル」を使用して)、仮想接続が返すデータをカスタマイズして制限することができます。これにより、データ ソース レベルでの行レベルのセキュリティが維持されるだけでなく (データ ソースに接続されたすべてのワークブックにセキュリティが自動的に継承され、仮想接続内で行われた変更が適用されます)、データ ポリシーの変更を元の仮想接続の編集権限を持つ人だけに制限することで、セキュリティの層が追加されます。