Tableau Data Management
Ce contenu fait partie de Tableau Blueprint, un cadre de maturité vous permettant d’approfondir et d’améliorer la façon dont votre organisation utilise les données pour générer de l’impact. Pour commencer votre voyage, faites notre évaluation(Le lien s’ouvre dans une nouvelle fenêtre).
Tableau Data Management facilite la gestion des données dans votre environnement analytique, de sorte que la prise de décision s’appuie toujours sur des données à jour et fiables. Tout est fait dans ce module d’extension pour renforcer la confiance dans les données et accélérer l’adoption de l’analytique en libre-service : préparation des données, catalogage, recherche, gouvernance. Il s’agit d’un ensemble de fonctionnalités sous licence distincte, incluant Tableau Prep Conductor et Tableau Catalog, pour gérer le contenu et les actifs de données dans Tableau Server et Tableau Cloud.
Qu’est-ce que Tableau Data Management?
Dans l’ensemble, votre organisation tirera parti des approches de gouvernance des données et de gestion des sources de données abordées ailleurs dans Tableau Blueprint. Au-delà de ces méthodologies, on utilise aussi de façon générique le terme Gestion des données dans les communautés de bases de données, de l’analyse de données et de la visualisation. Toutefois, ce terme devient plus précis quand on parle de Tableau avec Tableau Data Management, un ensemble de fonctionnalités à utiliser avec Tableau Server et Tableau Cloud. Peu importe si vous utilisez Tableau Server pour Windows ou Linux ou Tableau Cloud, les fonctionnalités de Tableau Data Management sont pour la plupart identiques (un petit sous-ensemble de fonctionnalités peut n’être disponible que dans Tableau Cloud ou Tableau Server).
Tableau Data Management comprend un ensemble d’outils permettant aux gestionnaires de données et aux analystes de votre organisation de gérer le contenu et les actifs liés aux données dans votre environnement Tableau. Trois ensembles de fonctionnalités supplémentaires sont notamment ajoutés lors de votre achat de Tableau Data Management :
Tableau Catalog
Tableau Prep Conductor
Connexions virtuelles et stratégies de données
Tableau Catalog
Caractéristique originale de Tableau Data Management, les fonctionnalités de Tableau Catalog permettent de rationaliser l’accès, la compréhension et la confiance dans les sources de données Tableau. Avec des domaines d’intérêt tels que le lignage, la qualité des données, la recherche et l’analyse d’impact, Tableau Catalog permet aux gestionnaires de données et aux visualiseurs ou analystes de données de mieux comprendre les sources de données dans Tableau Server et Tableau Cloud et s’y fier. Tableau Catalog intègre des fonctionnalités supplémentaires pour les développeurs Tableau avec des méthodes de métadonnées accessibles dans l’API REST de Tableau.
Lorsque Tableau Catalog est activé pour la première fois, il analyse tous les éléments de contenu liés dans votre site Tableau Server ou Tableau Cloud pour créer une vue connectée de tous les objets liés (Tableau Catalog s’y réfère sous le terme de métadonnées de contenu). Cela permet d’étendre les capacités de recherche au-delà des seules connexions de données. Les gestionnaires de données et les auteurs visuels peuvent également effectuer des recherches sur la base de colonnes, de bases de données et de tables.
Pour réduire le risque de modifier ou de supprimer involontairement un objet dont un autre objet dépend (par exemple, renommer ou supprimer une colonne de base de données qui est essentielle pour un classeur de production), la fonctionnalité Lignage de Tableau Catalog met en évidence l’interdépendance de tout le contenu d’un site Tableau, y compris les métriques, les flux et les connexions virtuelles. Désormais, vous avez plus de visibilité dans les relations entre les objets et êtes en mesure d’analyser aisément l’impact d’une modification attendue avant de l’effectuer.

Pour renforcer la fiabilité de vos sources de données Tableau, Tableau Catalog apporte un complément d’information, tel que des descriptions étendues d’objets liés aux données, la vue Détails des données et des étiquettes de mots-clés pour vous donner plus de flexibilité dans la recherche. La certification des sources de données place une icône bien visible à côté des sources de données pour indiquer que le propriétaire ou l’administrateur de la source de données lui fait confiance. Les éléments de données (sources de données, colonnes, etc.) pouvant être une source de préoccupation pour les consommateurs, tels que les données périmées ou obsolètes, peuvent être signalés par des avertissements sur la qualité des données. Outre l’option d’avertissement sur la qualité des données, les données sensibles peuvent être spécifiquement signalées par des étiquettes de sensibilité.
![]()
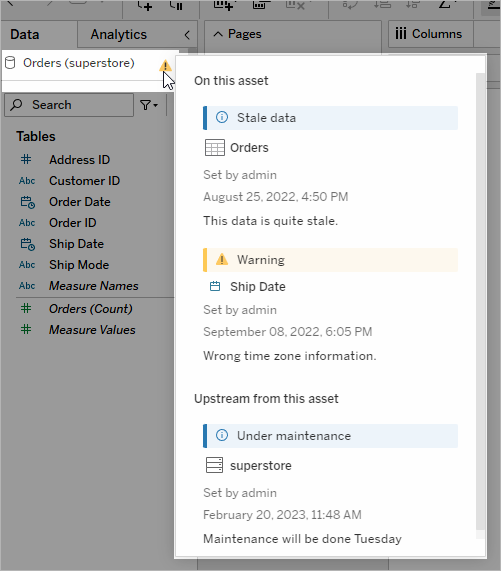
Tableau Prep Conductor
Si vous êtes comme de nombreux clients de Tableau, vous avez découvert les avantages qu’offre Tableau Prep Builder pour créer des « flux » sophistiqués de préparation de données qui combinent plusieurs sources de données, mettent en forme les données, personnalisent les colonnes et produisent un ou plusieurs formats de données souhaités. Mais une fois que vous avez créé le flux Tableau Prep parfait, comment l’automatiser pour qu’il s’exécute et effectue une mise à jour complète et incrémentielle des sources de données selon une programmation?
C’est ici que Tableau Prep Conductor, une autre fonctionnalité de la gestion des données, entre en scène. Tableau Prep Conductor permet une programmation flexible des flux Tableau Prep, qu’ils soient publiés dans votre environnement Tableau Server ou Tableau Cloud à partir de Tableau Prep Builder ou créés directement dans un navigateur avec la fonctionnalité de création Web de flux Tableau Prep. Commencez par tester votre flux Web (vous pouvez exécuter des flux manuellement sur demande sans Data Management, mais vous devrez acheter Data Management pour programmer l’exécution automatique des flux avec Prep Conductor). Le flux doit être exécuté jusqu’à ce qu’il soit terminé et qu’il crée la source de données de sortie souhaitée sans aucune erreur avant votre programmation.
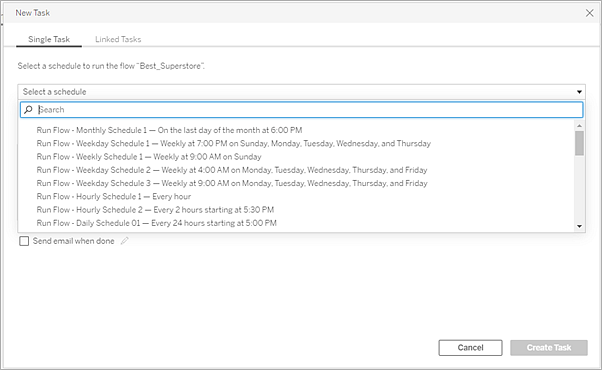
Si vous utilisez Tableau Server, votre administrateur (ou vous-même, si vous disposez des privilèges appropriés) peut créer des programmations personnalisées (par exemple, « Tous les jours à minuit », « Dimanche à midi », etc.) afin que les flux Prep soient exécutés de la même manière que le sont les actualisations d’extraits.
Si vous utilisez Tableau Cloud, un ensemble de programmations de flux Tableau Prep prédéfinies est installé par défaut. Vous ne pouvez pas les personnaliser ni créer vos propres programmations de flux Tableau Prep.
Programmez l’exécution des flux à partir du menu Actions. En programmant une tâche simple, seul le flux Tableau Prep sélectionné selon votre programmation sera exécuté. En programmant une tâche liée, vous pourrez sélectionner un ou plusieurs flux supplémentaires qui seront exécutés en séquence avec le flux sélectionné, si vous souhaitez « enchaîner » l’exécution de plusieurs flux dans un ordre spécifique (par exemple pour créer une sortie de source de données qui servira de source de données d’entrée pour un flux ultérieur). Les flux s’exécuteront désormais en fonction de la programmation, mettant automatiquement à jour ou créant des sources de données sur lesquelles pourront s’appuyer les classeurs Tableau.
Outre la possibilité de programmer des flux, Tableau Data Management et Tableau Prep Conductor intègrent des options permettant de surveiller les réussites ou les échecs des flux programmés, d’envoyer des notifications par courriel en cas de réussite ou d’échec de la programmation des flux, d’exécuter des flux par programmation avec l’API REST de Tableau Server ou Tableau Cloud, et de bénéficier de fonctionnalités supplémentaires des vues administratives pour surveiller l’historique des performances du flux.
RECOMMANDATION DE MEILLEURES PRATIQUES : Si vous prévoyez d’exécuter un grand nombre de flux Tableau Prep Conductor sur Tableau Server, vous devrez peut-être adapter l’échelle de votre environnement serveur. Si nécessaire, réglez les performances de votre système Tableau Server en ajoutant d’autres nœuds ou processus du gestionnaire de processus en arrière-plan pour tenir compte de la charge des flux Tableau Prep requise.
Qu’en est-il de Tableau Cloud? Même si rien ne vous oblige à envisager des changements dans l’architecture de Tableau Cloud pour la capacité des flux Tableau Prep, vous devez acquérir un bloc de ressources (unité de capacité de calcul de Tableau Cloud) pour chaque flux Tableau Prep Conductor simultané que vous souhaitez programmer. Déterminez le nombre de programmations de flux simultanés dont vous avez besoin et achetez des blocs de ressources Tableau Cloud en conséquence.
Connexions virtuelles
Passons maintenant à notre prochaine fonctionnalité de gestion des données : les connexions virtuelles. Une connexion virtuelle fournit un point d’accès central aux données. Elle peut accéder à plusieurs tables sur plusieurs bases de données. Les connexions virtuelles vous permettent de gérer l’extraction des données et la sécurité en un seul endroit, au niveau de la connexion.
Quand les connexions virtuelles sont-elles utiles?
Si vous envisagez une manière traditionnelle de partager une connexion de base de données avec plusieurs classeurs dans Tableau, il vous viendra sans doute à l’esprit de vous connecter directement à un serveur de base de données comme SQL Server ou Snowflake, de fournir des identifiants de connexion à la base de données, d’ajouter et de joindre une ou plusieurs tables, puis de publier la source de données sur Tableau Server ou Tableau Cloud. Même si vous choisissez de l’utiliser comme une connexion en direct aux données, il est tout à fait possible que vous souhaitiez extraire des données de la source de données afin d’accélérer les classeurs connectés.
Pour simplifier notre discours, considérons que vous pouvez effectuer cette opération un certain nombre de fois pour tenir compte, par exemple, d’un ensemble différent de tables ou de jointures, entraînant l’utilisation de plusieurs sources de données publiées (et peut-être extraites) pour une série de classeurs dont les critères diffèrent pour les tables et les jointures, mais qui utilisent tous la même base de données initiale.
Voyons maintenant ce qui se passe si un élément de la base de données SQL Server ou Snowflake initiale référencée dans cette série de sources de données change, par exemple si les tables sont renommées, si des champs supplémentaires sont ajoutés ou si des identifiants de la base de données sont modifiés. Vous devez maintenant ouvrir chacune des sources de données créées précédemment, apporter les modifications nécessaires pour tenir compte du changement de base de données et republier (et, éventuellement, reprogrammer les actualisations d’extraits).
Vous trouverez sans doute qu’il est plus simple de créer une seule « définition » initiale de la connexion de données, avec le nom du serveur de la base de données, les identifiants et les références des tables. Vous préférerez peut-être extraire les données de cette « définition » plus large. Ensuite, lorsque vous devrez créer différentes sources de données pour plusieurs combinaisons de tables, de jointures, etc., vous pourrez vous référer à cette « définition » initiale plutôt que de vous connecter directement à un ou plusieurs serveurs de base de données. Si un élément de la structure centrale de la base de données change (par exemple, les noms des tables changent ou les identifiants sont modifiés), il vous suffit de modifier l’objet de la « définition » initiale et toutes les sources de données dépendantes héritent alors automatiquement des modifications.
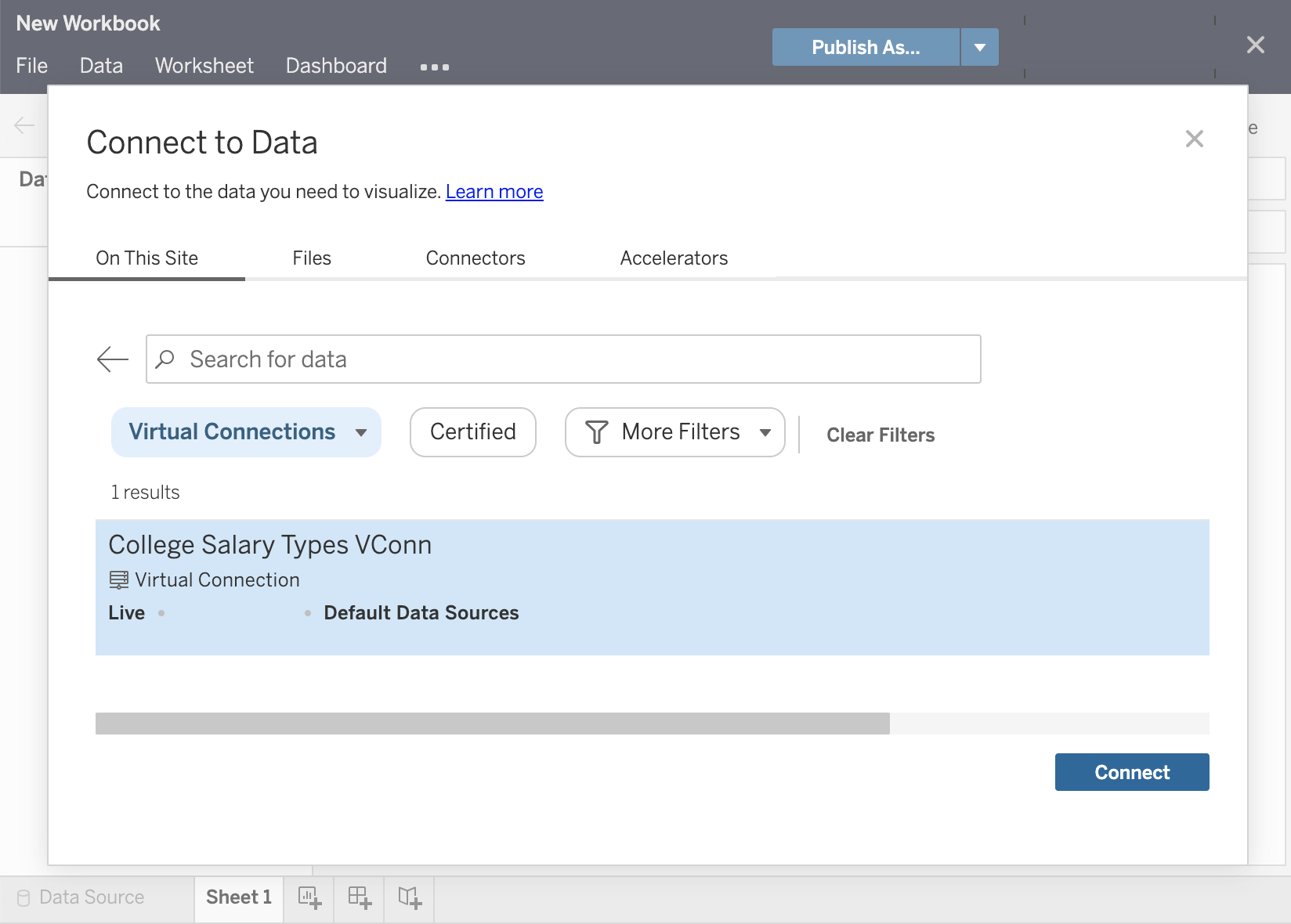
La fonctionnalité de gestion des données introduit cette capacité de « définition » partagée par le biais d’une connexion virtuelle. Une connexion virtuelle est similaire à une connexion de source de données standard en ce sens qu’elle contient le serveur de base de données, les identifiants de connexion et les tables sélectionnées. À l’instar d’une source de données Tableau classique, une connexion virtuelle peut intégrer des connexions à plusieurs bases de données ou sources de données (chacune ayant son propre ensemble d’identifiants et de tables). Si certaines modifications de métadonnées sont autorisées dans une connexion virtuelle (par exemple, masquer ou renommer des champs), les tables ne sont pas jointes à la connexion virtuelle. Par la suite, quand vous utilisez la connexion virtuelle comme source directe pour un classeur ou comme type de connexion pour une autre source de données publiée, vous pouvez joindre des tables et effectuer d’autres personnalisations de la source de données.
Une fois qu’une connexion virtuelle a été créée et publiée sur Tableau Server ou Tableau Cloud et que les autorisations appropriées ont été définies, vous pouvez vous connecter à la connexion virtuelle dans Tableau Desktop ou Tableau Server/Cloud comme vous le feriez avec n’importe quelle autre source de données. Toutefois, vous n’aurez pas besoin de spécifier l’emplacement d’un serveur de base de données ni de fournir des identifiants. Par ailleurs, vous pourrez immédiatement joindre des tables et visualiser des données ou publier la source de données.
Stratégies de données
Outre les fonctionnalités de connexion de base de données centralisée décrites plus tôt, les connexions virtuelles de Tableau Data Management offrent également une option de sécurité au niveau des lignes centralisée et plus simplifiée grâce aux stratégies de données. Utilisez une stratégie de données pour appliquer la sécurité au niveau des lignes à une ou plusieurs tables dans une connexion virtuelle. Une stratégie de données filtre les données, garantissant ainsi que les utilisateurs ne voient que les données qu’ils sont censés voir. Les stratégies de données s’appliquent aux connexions en direct et aux extraits.
Quand les stratégies de données sont-elles utiles?
Il est fréquent que plusieurs organisations restreignent automatiquement les données visibles dans une visualisation à celles qui concernent l’utilisateur actuel. Prenons l’exemple d’un tableau de bord partagé qui contient les détails d’une commande dans un objet de tableau croisé.
Si vous êtes directeur commercial d’un grand territoire, le tableau croisé des détails affichera les commandes de tous les chargés de compte de votre territoire.
Toutefois, si vous êtes chargé d’un compte individuel, le tableau croisé des détails affichera uniquement les commandes relatives à vos comptes.
Ce scénario nécessite que vous appliquez la sécurité au niveau des lignes dans votre environnement Tableau, en procédant comme suit :
Sécurité au niveau des lignes dans la base de données. Chaque fois qu’il consulte une visualisation, le Viewer est invité à se connecter à la base de données sous-jacente avec ses propres identifiants, sinon ses identifiants sont récupérés à partir de son compte utilisateur Tableau. L’ensemble de données qui en résulte est limité aux seules données qu’il est autorisé à consulter sur la base des identifiants fournis. Non seulement cela peut très vite devenir un travail fastidieux, chaque Viewer étant tenu de conserver ses propres identifiants, mais la connexion de données en direct risque d’affecter les performances en perturbant fortement la base de données sous-jacente. En outre, il est possible que Tableau Cloud limite certaines options de transmission des identifiants aux connexions en direct.
Filtres utilisateur Tableau. Les filtres utilisateur sont appliqués lors de la création de feuilles de calcul individuelles dans un classeur. En indiquant des combinaisons d’identifiants de l’utilisateur Tableau individuels ou l’appartenance à un ou plusieurs groupes d’utilisateurs Tableau, les feuilles de calcul individuelles peuvent être filtrées pour que seules les données pertinentes pour l’utilisateur concerné soient visibles. Cette opération peut devenir lassante, car chaque feuille de calcul d’un classeur nécessite qu’on applique des filtres utilisateur. Il sera alors impossible de spécifier un filtre utilisateur pour un grand groupe de classeurs utilisant un seul processus. En outre, si un utilisateur reçoit involontairement des autorisations d’édition sur le classeur, il peut aisément faire glisser le filtre utilisateur de l’étagère Filtres et visualiser toutes les données sous-jacentes qu’il n’est peut-être pas autorisé à consulter.
En ayant recours à un sous-ensemble du langage de calcul Tableau, les stratégies de données peuvent spécifier des règles sophistiquées (éventuellement en utilisant une « table des droits » connexe dans une base de données) afin de personnaliser et de limiter les données renvoyées par la connexion virtuelle, en fonction de l’identité de l’utilisateur ou de son appartenance au groupe. Cette mesure permet de sécuriser la source de données au niveau des lignes (tous les classeurs connectés à la source de données hériteront automatiquement de la sécurité et adopteront toute modification effectuée dans la connexion virtuelle). Elle permet également d’ajouter une couche de sécurité supplémentaire en limitant la modification des stratégies de données aux seules personnes disposant d’une autorisation d’édition pour la connexion virtuelle d’origine.