Funzioni di calcolo tabella
Questo articolo illustra le funzioni di calcolo tabella e i relativi utilizzi in Tableau. Mostra anche come creare un calcolo tabella utilizzando l’editor di calcolo.
Perché utilizzare le funzioni di calcolo tabella
Le funzioni di calcolo tabella ti consentono di eseguire calcoli sui valori di una tabella.
Ad esempio, puoi calcolare la percentuale del totale di una singola vendita per l’anno oppure per diversi anni.
Funzioni di calcolo tabella disponibili in Tableau:
Queste sono le funzioni di calcolo tabella native utilizzabili in Tableau senza un’estensione di analisi esterna.
FIRST( )
Restituisce il numero di righe dalla riga corrente alla prima riga della partizione. Ad esempio, la seguente vista mostra le vendite trimestrali. Quando FIRST() è calcolato all’interno della partizione Data, l’offset della prima riga dalla seconda riga è -1.

Esempio
Quando l’indice di riga corrente è 3, FIRST()
= -2.
INDEX( )
Restituisce l’indice della riga corrente nella partizione, senza alcun ordinamento in base al valore. L’indice della prima riga inizia da 1. Ad esempio, la seguente tabella mostra le vendite trimestrali. Quando INDEX() è calcolato all’interno della partizione Data, l’indice di ogni riga è 1, 2, 3, 4....., ecc.

Esempio
Per la terza riga della partizione, INDEX() = 3.
LAST( )
Restituisce il numero di righe dalla riga corrente all’ultima riga della partizione. Ad esempio, la seguente tabella mostra le vendite trimestrali. Quando LAST() è calcolato all’interno della partizione Data, l’offset dell’ultima riga dalla seconda riga è 5.

Esempio
Quando l’indice di riga corrente è 3 di 7, LAST() = 4.
LOOKUP(espressione, [offset])
Restituisce il valore dell’espressione in una riga di destinazione, specificato come offset relativo rispetto alla riga corrente. Utilizza FIRST() + n e LAST() - n come parte della definizione dell’offset per una destinazione relativa alla prima/ultima riga della partizione. Se offset viene omesso, la riga da confrontare può essere impostata nel menu del campo. Se la riga di destinazione non è determinabile, questa funzione restituisce NULL.
La seguente vista mostra le vendite trimestrali. Quando LOOKUP (SUM(Sales), 2) viene calcolato all’interno della partizione Data, ogni riga mostra il valore delle vendite da 2 trimestri nel futuro.

Esempio
LOOKUP(SUM([Profit]),
FIRST()+2) calcola SUM(Profitto) nella terza riga della partizione.
Funzioni MODEL_EXTENSION
Le funzioni di estensione del modello:
MODEL_EXTENSION_BOOL
MODEL_EXTENSION_INT
MODEL_EXTENSION_REAL
MODEL_EXTENSION_STRING
vengono utilizzate per passare dati a un modello distribuito su un servizio esterno come R, TabPy o Matlab. Consulta Passare espressioni con le estensioni di analisi(Il collegamento viene aperto in una nuova finestra).
MODEL_PERCENTILE(espressione_destinazione, espressione/i_predittore)
Restituisce la probabilità (compresa tra 0 e 1) che il valore previsto sia minore o uguale all’indicatore osservato, definito dall’espressione di destinazione e da altri predittori. Questa è la funzione di distribuzione predittiva posteriore, anche nota come funzione di distribuzione cumulativa (CDF).
Questa funzione è l’inversa di MODEL_QUANTILE. Per informazioni sulle funzioni di modellazione predittiva, consulta Funzionamento delle funzioni di modellazione predittiva in Tableau.
Esempio
La formula seguente restituisce il quantile dell’indicatore per la somma delle vendite, rettificato in base al conteggio degli ordini.
MODEL_PERCENTILE(SUM([Sales]), COUNT([Orders]))
MODEL_QUANTILE(quantile, espressione_destinazione, espressione/i_predittore)
Restituisce un valore numerico di destinazione all’interno dell’intervallo probabile definito dall’espressione di destinazione e da altri predittori, in corrispondenza di un quantile specificato. Questo è il quantile predittivo posteriore.
Questa funzione è l’inversa di MODEL_PERCENTILE. Per informazioni sulle funzioni di modellazione predittiva, consulta Funzionamento delle funzioni di modellazione predittiva in Tableau.
Esempio
La formula seguente restituisce la somma prevista mediana (0,5) delle vendite, rettificata in base al conteggio degli ordini.
MODEL_QUANTILE(0.5, SUM([Sales]), COUNT([Orders]))
PREVIOUS_VALUE(espressione)
Restituisce il valore di questo calcolo nella riga precedente. Restituisce l’espressione data se la riga corrente è la prima riga della partizione.
Esempio
SUM([Profit]) * PREVIOUS_VALUE(1) calcola il prodotto corrente di SUM(Profitto).
RANK(espressione, ['asc' | 'desc'])
Restituisce la classificazione standard della concorrenza per la riga corrente della partizione. A valori identici viene assegnata una classificazione identica. Utilizza l’argomento facoltativo 'asc' | 'desc' per specificare l’ordine crescente o decrescente. L’impostazione predefinita è decrescente.
Con questa funzione, l’insieme dei valori (6, 9, 9, 14) sarebbe classificato (4, 2, 2, 1).
I valori NULL vengono ignorati nelle funzioni di classificazione. Non sono numerati e non vengono conteggiati rispetto al numero totale di record nel calcolo della classificazione percentile.
Per informazioni sulle diverse opzioni di classificazione, consulta Calcolo Classificazione.
Esempio
L’immagine seguente mostra l’effetto delle varie funzioni di classificazione (RANK, RANK_DENSE, RANK_MODIFIED, RANK_PERCENTILE e RANK_UNIQUE) su un insieme di valori. L’insieme di dati contiene informazioni su 14 studenti (da Student A a Student N); la colonna Age (Età) mostra l’età attuale di ogni Student (studente) (tutti gli studenti hanno un’età compresa tra i 17 e i 20 anni). Le colonne rimanenti mostrano l’effetto di ogni funzione di classificazione sull’insieme dei valori di età, presumendo che la funzione conservi l’ordine predefinito (crescente o decrescente).
![]()
RANK_DENSE(espressione, ['asc' | 'desc'])
Restituisce la classificazione densa per la riga corrente della partizione. A valori identici è assegnata una classificazione identica, ma nella sequenza numerica non vengono inseriti intervalli. Utilizza l’argomento facoltativo 'asc' | 'desc' per specificare l’ordine crescente o decrescente. L’impostazione predefinita è decrescente.
Con questa funzione, l’insieme dei valori (6, 9, 9, 14) sarebbe classificato (3, 2, 2, 1).
I valori NULL vengono ignorati nelle funzioni di classificazione. Non sono numerati e non vengono conteggiati rispetto al numero totale di record nel calcolo della classificazione percentile.
Per informazioni sulle diverse opzioni di classificazione, consulta Calcolo Classificazione.
RANK_MODIFIED(espressione, ['asc' | 'desc'])
Restituisce la classificazione modificata della concorrenza per la riga corrente della partizione. A valori identici viene assegnata una classificazione identica. Utilizza l’argomento facoltativo 'asc' | 'desc' per specificare l’ordine crescente o decrescente. L’impostazione predefinita è decrescente.
Con questa funzione, l’insieme dei valori (6, 9, 9, 14) sarebbe classificato (4, 3, 3, 1).
I valori NULL vengono ignorati nelle funzioni di classificazione. Non sono numerati e non vengono conteggiati rispetto al numero totale di record nel calcolo della classificazione percentile.
Per informazioni sulle diverse opzioni di classificazione, consulta Calcolo Classificazione.
RANK_PERCENTILE(espressione, ['asc' | 'desc'])
Restituisce la classificazione percentile per la riga corrente della partizione. Utilizza l’argomento facoltativo 'asc' | 'desc' per specificare l’ordine crescente o decrescente. Quello predefinito è ascendente.
Con questa funzione, l’insieme dei valori (6, 9, 9, 14) sarebbe classificato (0,00, 0,67, 0,67, 1,00).
I valori NULL vengono ignorati nelle funzioni di classificazione. Non sono numerati e non vengono conteggiati rispetto al numero totale di record nel calcolo della classificazione percentile.
Per informazioni sulle diverse opzioni di classificazione, consulta Calcolo Classificazione.
RANK_UNIQUE(espressione, ['asc' | 'desc'])
Restituisce la classificazione univoca per la riga corrente della partizione. A valori identici sono assegnate classificazioni differenti. Utilizza l’argomento facoltativo 'asc' | 'desc' per specificare l’ordine crescente o decrescente. L’impostazione predefinita è decrescente.
Con questa funzione, l’insieme dei valori (6, 9, 9, 14) sarebbe classificato (4, 2, 3, 1).
I valori NULL vengono ignorati nelle funzioni di classificazione. Non sono numerati e non vengono conteggiati rispetto al numero totale di record nel calcolo della classificazione percentile.
Per informazioni sulle diverse opzioni di classificazione, consulta Calcolo Classificazione.
RUNNING_AVG(espressione)
Restituisce la media mobile dell’espressione data, dalla prima riga della partizione alla riga corrente.
La seguente vista mostra le vendite trimestrali. Quando all’interno della partizione Data viene calcolato RUNNING_AVG(SUM([Sales]), il risultato è una media mobile dei valori di vendita per ogni trimestre.

Esempio
RUNNING_AVG(SUM([Profit])) calcola la media mobile di SUM(Profitto).
RUNNING_COUNT(espressione)
Restituisce il conteggio corrente dell’espressione data, dalla prima riga della partizione alla riga corrente.
Esempio
RUNNING_COUNT(SUM([Profit])) calcola il conteggio corrente di SUM(Profitto).
RUNNING_MAX(espressione)
Restituisce il valore massimo corrente dell’espressione data, dalla prima riga nella partizione alla riga corrente.

Esempio
RUNNING_MAX(SUM([Profit])) calcola il valore massimo corrente di SUM(Profitto).
RUNNING_MIN(espressione)
Restituisce il valore minimo corrente dell’espressione data, dalla prima riga della partizione alla riga corrente.

Esempio
RUNNING_MIN(SUM([Profit])) calcola il valore minimo corrente di SUM(Profitto).
RUNNING_SUM(espressione)
Restituisce la somma corrente dell’espressione data, dalla prima riga della partizione alla riga corrente.

Esempio
RUNNING_SUM(SUM([Profit])) calcola la somma corrente di SUM(Profitto)
SIZE()
Restituisce il numero di righe della partizione. Ad esempio, la seguente vista mostra le vendite trimestrali. All’interno della partizione Data, ci sono sette righe, quindi SIZE() per la partizione Data sarà 7.

Esempio
SIZE() = 5 quando la partizione corrente contiene cinque righe.
Funzioni SCRIPT_
Le funzioni SCRIPT:
SCRIPT_BOOL
SCRIPT_INT
SCRIPT_REAL
SCRIPT_STRING
vengono utilizzate per passare dati a un servizio esterno come R, TabPy o Matlab. Consulta Passare espressioni con le estensioni di analisi(Il collegamento viene aperto in una nuova finestra).
TOTAL(espressione)
Restituisce il totale per l’espressione data in una partizione di calcolo tabella.
Esempio
Supponi di iniziare con questa vista:

Apri l’editor di calcolo e crea un nuovo campo denominato Totale:

Trascina Totale su Testo per sostituire SUM(Vendite). La vista cambia in modo tale da sommare i valori in base al valore predefinito Calcola utilizzando:

A questo punto la domanda è: qual è il valore predefinito di Calcola utilizzando? Se nel riquadro Dati fai clic con il pulsante destro del mouse (Control-clic su un Mac) su Totale e selezioni Modifica, avrai a disposizione un’ulteriore informazione:

Il valore predefinito di Calcola utilizzando è Tabella (orizzontale). Il risultato è che Totale sta sommando i valori in orizzontale su ogni riga della tabella. Quindi, il valore che vedi in ogni riga è la somma dei valori della versione originale della tabella.
I valori della riga 2011/T1 nella tabella originale erano 8601 $, 6579 $, 44262 $ e 15006 $. I valori nella tabella dopo che Totale ha sostituito SUM(Vendite) corrispondono tutti a 74.448 $, ovvero la somma dei quattro valori originali.
Nota il triangolo accanto a Totale dopo averlo trascinato su Testo:

Indica che questo campo utilizza un calcolo tabella. Puoi fare clic con il pulsante destro del mouse sul campo e selezionare Modifica calcolo tabella per reindirizzare la funzione a un valore di Calcola utilizzando differente. Ad esempio, puoi impostarlo su Tabella (verticale). In questo caso, la tabella apparirebbe così:

TOTAL(espressione)
Restituisce il totale per l’espressione data in una partizione di calcolo tabella.
Esempio
Supponi di iniziare con questa vista:
Apri l’editor di calcolo e crea un nuovo campo denominato Totale:
Trascina Totale su Testo per sostituire SUM(Vendite). La vista cambia in modo tale da sommare i valori in base al valore predefinito Calcola utilizzando:
A questo punto la domanda è: qual è il valore predefinito di Calcola utilizzando? Se nel riquadro Dati fai clic con il pulsante destro del mouse (Control-clic su un Mac) su Totale e selezioni Modifica, avrai a disposizione un’ulteriore informazione:
Il valore predefinito di Calcola utilizzando è Tabella (orizzontale). Il risultato è che Totale sta sommando i valori in orizzontale su ogni riga della tabella. Quindi, il valore che vedi in ogni riga è la somma dei valori della versione originale della tabella.
I valori della riga 2011/T1 nella tabella originale erano 8601 $, 6579 $, 44262 $ e 15006 $. I valori nella tabella dopo che Totale ha sostituito SUM(Vendite) corrispondono tutti a 74.448 $, ovvero la somma dei quattro valori originali.
Nota il triangolo accanto a Totale dopo averlo trascinato su Testo:
Indica che questo campo utilizza un calcolo tabella. Puoi fare clic con il pulsante destro del mouse sul campo e selezionare Modifica calcolo tabella per reindirizzare la funzione a un valore di Calcola utilizzando differente. Ad esempio, puoi impostarlo su Tabella (verticale). In questo caso, la tabella apparirebbe così:
WINDOW_AVG(espressione, [inizio, fine])
Restituisce la media dell’espressione all’interno della finestra. La finestra viene definita come offset dalla riga corrente. Utilizza FIRST()+n e LAST()-n per gli offset dalla prima o dall’ultima riga della partizione. Se l’inizio e la fine sono omessi, viene utilizzata l’intera partizione.
Esiste una funzione di aggregazione equivalente: AVG. Consulta Funzioni di Tableau (in ordine alfabetico)(Il collegamento viene aperto in una nuova finestra).
Esempio
La seguente formula restituisce la media della finestra di SUM(Profit) dalle due righe precedenti alla riga corrente.
WINDOW_AVG(SUM[Profit]), -2, 0)
WINDOW_CORR(espressione1, espressione2, [inizio, fine])
Restituisce il coefficiente di correlazione di Pearson di due espressioni all’interno della finestra. La finestra viene definita come offset dalla riga corrente. Utilizza FIRST()+n e LAST()-n per gli offset dalla prima o dall’ultima riga della partizione. Se l’inizio e la fine sono omessi, viene utilizzata l’intera partizione.
La correlazione di Pearson misura la relazione lineare tra due variabili. I risultati variano da -1 a +1 inclusi, dove 1 denota un’esatta relazione lineare positiva, come quando un cambiamento positivo in una variabile implica un cambiamento positivo di grandezza corrispondente nell’altra; 0 denota l’assenza di relazioni lineari tra la varianza, e -1 è un’esatta relazione negativa.
Esiste una funzione di aggregazione equivalente: CORR. Consulta Funzioni di Tableau (in ordine alfabetico)(Il collegamento viene aperto in una nuova finestra).
Esempio
La seguente formula restituisce la correlazione di Pearson di SUM(Profitto) e SUM(Vendite) dalle cinque righe precedenti alla riga corrente.
WINDOW_CORR(SUM[Profit]), SUM([Sales]), -5, 0)
WINDOW_COUNT(espressione, [inizio, fine])
Restituisce il conteggio dell’espressione all’interno della finestra. La finestra viene definita mediante offset dalla riga corrente. Utilizza FIRST()+n e LAST()-n per gli offset dalla prima o dall’ultima riga della partizione. Se l’inizio e la fine sono omessi, viene utilizzata l’intera partizione.
Esempio
WINDOW_COUNT(SUM([Profit]), FIRST()+1, 0) calcola il conteggio di SUM(Profitto) dalla seconda riga a quella corrente
WINDOW_COVAR(espressione1, espressione2, [inizio, fine])
Restituisce la covarianza del campione di due espressioni all’interno della finestra. La finestra viene definita come offset dalla riga corrente. Utilizza FIRST()+n e LAST()-n per gli offset dalla prima o dall’ultima riga della partizione. Se gli argomenti di inizio e fine vengono omessi, la finestra è l’intera partizione.
Per normalizzare il calcolo della covarianza, la covarianza del campione utilizza il numero di punti dati non NULL n - 1 al posto di n, che viene invece utilizzato dalla covarianza della popolazione (con la funzione WINDOW_COVARP). La covarianza del campione è la scelta appropriata quando i dati sono un campione casuale che viene utilizzato per stimare la covarianza per una popolazione più numerosa.
Esiste una funzione di aggregazione equivalente: COVAR. Consulta Funzioni di Tableau (in ordine alfabetico)(Il collegamento viene aperto in una nuova finestra).
Esempio
La seguente formula restituisce la covarianza del campione di SUM(Profitto) e SUM(Vendite) dalle due righe precedenti alla riga corrente.
WINDOW_COVAR(SUM([Profit]), SUM([Sales]), -2, 0)
WINDOW_COVARP(espressione1, espressione2, [inizio, fine])
Restituisce la covarianza della popolazione di due espressioni all’interno della finestra. La finestra viene definita come offset dalla riga corrente. Utilizza FIRST()+n e LAST()-n per gli offset dalla prima o dall’ultima riga della partizione. Se l’inizio e la fine sono omessi, viene utilizzata l’intera partizione.
La covarianza della popolazione è la covarianza del campione moltiplicata per (n-1)/n, dove n è il numero totale di punti dati non NULL. La covarianza della popolazione è la scelta appropriata quando sono disponibili dati per tutti gli elementi di interesse. Al contrario, quando è presente solo un sottoinsieme casuale di elementi, è preferibile utilizzare la covarianza del campione (con la funzione WINDOW_COVAR).
Esiste una funzione di aggregazione equivalente: COVARP. Funzioni di Tableau (in ordine alfabetico)(Il collegamento viene aperto in una nuova finestra).
Esempio
La seguente formula restituisce la covarianza della popolazione di SUM(Profitto) e SUM(Vendite) dalle due righe precedenti alla riga corrente.
WINDOW_COVARP(SUM([Profit]), SUM([Sales]), -2, 0)
WINDOW_MEDIAN(espressione, [inizio, fine])
Restituisce il valore mediano dell’espressione all’interno della finestra. La finestra viene definita mediante offset dalla riga corrente. Utilizza FIRST()+n e LAST()-n per gli offset dalla prima o dall’ultima riga della partizione. Se l’inizio e la fine sono omessi, viene utilizzata l’intera partizione.
Ad esempio, la seguente vista mostra i profitti trimestrali. Un valore mediano della finestra all’interno della partizione Data restituisce il profitto mediano in tutte le date.

Esempio
WINDOW_MEDIAN(SUM([Profit]), FIRST()+1, 0) calcola la mediana di SUM(Profitto) dalla seconda riga a quella corrente.
WINDOW_MAX(espressione, [inizio, fine])
Restituisce il valore massimo dell’espressione all’interno della finestra. La finestra viene definita mediante offset dalla riga corrente. Utilizza FIRST()+n e LAST()-n per gli offset dalla prima o dall’ultima riga della partizione. Se l’inizio e la fine sono omessi, viene utilizzata l’intera partizione.
Ad esempio, la seguente vista mostra le vendite trimestrali. Un valore massimo della finestra all’interno della partizione Data restituisce il valore massimo delle vendite in tutte le date.

Esempio
WINDOW_MAX(SUM([Profit]), FIRST()+1, 0) calcola il massimo di SUM(Profitto) dalla seconda riga a quella corrente.
WINDOW_MIN(espressione, [inizio, fine])
Restituisce il valore minimo dell’espressione all’interno della finestra. La finestra viene definita mediante offset dalla riga corrente. Utilizza FIRST()+n e LAST()-n per gli offset dalla prima o dall’ultima riga della partizione. Se l’inizio e la fine sono omessi, viene utilizzata l’intera partizione.
Ad esempio, la seguente vista mostra le vendite trimestrali. Un valore minimo della finestra all’interno della partizione Data restituisce il valore minimo delle vendite in tutte le date.

Esempio
WINDOW_MIN(SUM([Profit]), FIRST()+1, 0) calcola il minimo di SUM(Profitto) dalla seconda riga a quella corrente.
WINDOW_PERCENTILE(espressione, numero, [inizio, fine])
Restituisce il valore corrispondente al percentile specificato all’interno della finestra. La finestra viene definita mediante offset dalla riga corrente. Utilizza FIRST()+n e LAST()-n per gli offset dalla prima o dall’ultima riga della partizione. Se l’inizio e la fine sono omessi, viene utilizzata l’intera partizione.
Esempio
WINDOW_PERCENTILE(SUM([Profit]), 0.75, -2, 0) calcola il 75° percentile di SUM(Profitto) dalle due righe precedenti a quella corrente.
WINDOW_STDEV(espressione, [inizio, fine])
Restituisce la deviazione standard del campione dell’espressione all’interno della finestra. La finestra viene definita mediante offset dalla riga corrente. Utilizza FIRST()+n e LAST()-n per gli offset dalla prima o dall’ultima riga della partizione. Se l’inizio e la fine sono omessi, viene utilizzata l’intera partizione.
Esempio
WINDOW_STDEV(SUM([Profit]), FIRST()+1, 0) calcola la deviazione standard di SUM(Profitto) dalla seconda riga a quella corrente.
WINDOW_STDEVP(espressione, [inizio, fine])
Restituisce la deviazione standard distorta dell’espressione all’interno della finestra. La finestra viene definita mediante offset dalla riga corrente. Utilizza FIRST()+n e LAST()-n per gli offset dalla prima o dall’ultima riga della partizione. Se l’inizio e la fine sono omessi, viene utilizzata l’intera partizione.
Esempio
WINDOW_STDEVP(SUM([Profit]), FIRST()+1, 0) calcola la deviazione standard di SUM(Profitto) dalla seconda riga a quella corrente.
WINDOW_SUM(espressione, [inizio, fine])
Restituisce la somma dell’espressione all’interno della finestra. La finestra viene definita mediante offset dalla riga corrente. Utilizza FIRST()+n e LAST()-n per gli offset dalla prima o dall’ultima riga della partizione. Se l’inizio e la fine sono omessi, viene utilizzata l’intera partizione.
Ad esempio, la seguente vista mostra le vendite trimestrali. Una somma della finestra calcolata all’interno della partizione Data restituisce la somma delle vendite in tutti i trimestri.

Esempio
WINDOW_SUM(SUM([Profit]), FIRST()+1, 0) calcola la somma di SUM(Profitto) dalla seconda riga a quella corrente.
WINDOW_VAR(espressione, [inizio, fine])
Restituisce la varianza del campione dell’espressione all’interno della finestra. La finestra viene definita mediante offset dalla riga corrente. Utilizza FIRST()+n e LAST()-n per gli offset dalla prima o dall’ultima riga della partizione. Se l’inizio e la fine sono omessi, viene utilizzata l’intera partizione.
Esempio
WINDOW_VAR((SUM([Profit])), FIRST()+1, 0) calcola la varianza di SUM(Profitto) dalla seconda riga a quella corrente.
WINDOW_VARP(espressione, [inizio, fine])
Restituisce la varianza distorta dell’espressione all’interno della finestra. La finestra viene definita mediante offset dalla riga corrente. Utilizza FIRST()+n e LAST()-n per gli offset dalla prima o dall’ultima riga della partizione. Se l’inizio e la fine sono omessi, viene utilizzata l’intera partizione.
Esempio
WINDOW_VARP(SUM([Profit]), FIRST()+1, 0) calcola la varianza di SUM(Profitto) dalla seconda riga a quella corrente.
Funzioni di calcolo tabella di estensione di analisi disponibili in Tableau
Le estensioni di analisi sono connessioni tra Tableau e un servizio esterno come TabPy per Python, Matlab e R. Per utilizzare le estensioni di analisi nella tua analisi, devi prima configurare una connessione(Il collegamento viene aperto in una nuova finestra) tra Tableau e il servizio esterno, ad esempio il server TabPy. Potrai quindi utilizzare script all’interno di calcoli tabella specifici (MODEL_EXTENSION_ per utilizzare modelli denominati pubblicati o SCRIPT_ per passare un’espressione al servizio esterno). I dati nella visualizzazione (la "tabella" del calcolo tabella) vengono trasmessi in modo sicuro al server esterno, lo script viene eseguito e i risultati vengono ritrasmessi come output del calcolo.
Funzioni di estensione del modello
Da utilizzare con modelli denominati distribuiti su un servizio TabPy esterno.
MODEL_EXTENSION_BOOL (nome_modello, argomenti, espressione)
Restituisce il risultato booleano di un’espressione calcolata da un modello con nome distribuito su un servizio esterno TabPy.
nome_modello è il nome del modello di analisi distribuito che si desidera utilizzare.
Ogni argomento è una singola stringa che imposta i valori di input accettati dal modello distribuito ed è definita dal modello di analisi.
Utilizza le espressioni per definire i valori inviati da Tableau al modello di analisi. Assicurati di utilizzare le funzioni di aggregazione (SUM, AVG e così via) per aggregare i risultati.
Quando si utilizza la funzione, i tipi di dati e l’ordine delle espressioni devono corrispondere a quelli degli argomenti di input.
Esempio
MODEL_EXTENSION_BOOL ("isProfitable","inputSales", "inputCosts", SUM([Sales]), SUM([Costs]))
MODEL_EXTENSION_INT (nome_modello, argomenti, espressione)
Restituisce il risultato booleano di un’espressione calcolata da un modello con nome distribuito su un servizio esterno TabPy.
nome_modello è il nome del modello di analisi distribuito che si desidera utilizzare.
Ogni argomento è una singola stringa che imposta i valori di input accettati dal modello distribuito ed è definita dal modello di analisi.
Utilizza le espressioni per definire i valori inviati da Tableau al modello di analisi. Assicurati di utilizzare le funzioni di aggregazione (SUM, AVG e così via) per aggregare i risultati.
Quando si utilizza la funzione, i tipi di dati e l’ordine delle espressioni devono corrispondere a quelli degli argomenti di input.
Esempio
MODEL_EXTENSION_INT ("getPopulation", "inputCity", "inputState", MAX([City]), MAX ([State]))
MODEL_EXTENSION_REAL (nome_modello, argomenti, espressione)
Restituisce un risultato reale di un’espressione calcolata da un modello con nome distribuito su un servizio esterno TabPy.
nome_modello è il nome del modello di analisi distribuito che si desidera utilizzare.
Ogni argomento è una singola stringa che imposta i valori di input accettati dal modello distribuito ed è definita dal modello di analisi.
Utilizza le espressioni per definire i valori inviati da Tableau al modello di analisi. Assicurati di utilizzare le funzioni di aggregazione (SUM, AVG e così via) per aggregare i risultati.
Quando si utilizza la funzione, i tipi di dati e l’ordine delle espressioni devono corrispondere a quelli degli argomenti di input.
Esempio
MODEL_EXTENSION_REAL ("profitRatio", "inputSales", "inputCosts", SUM([Sales]), SUM([Costs]))
MODEL_EXTENSION_STRING (nome_modello, argomenti, espressione)
Restituisce il risultato stringa di un’espressione calcolata da un modello con nome distribuito su un servizio esterno TabPy.
nome_modello è il nome del modello di analisi distribuito che si desidera utilizzare.
Ogni argomento è una singola stringa che imposta i valori di input accettati dal modello distribuito ed è definita dal modello di analisi.
Utilizza le espressioni per definire i valori inviati da Tableau al modello di analisi. Assicurati di utilizzare le funzioni di aggregazione (SUM, AVG e così via) per aggregare i risultati.
Quando si utilizza la funzione, i tipi di dati e l’ordine delle espressioni devono corrispondere a quelli degli argomenti di input.
Esempio
MODEL_EXTENSION_STR ("mostPopulatedCity", "inputCountry", "inputYear", MAX ([Country]), MAX([Year]))
Funzioni SCRIPT
Invece di utilizzare un modello esterno definito come le funzioni MODEL_EXPRESSION, le funzioni SCRIPT vengono utilizzate per specificare l'espressione direttamente nel calcolo della tabella.
Nota: in seguito alle chiamate è prevista la restituzione di una singola colonna contenente lo stesso numero di righe inviate alla funzione.
SCRIPT_BOOL
Restituisce come risultato un valore booleano dall’espressione specificata. L’espressione viene passata direttamente a un’istanza di servizio di estensione di analisi in esecuzione.
Nelle espressioni R, utilizza .argn (con un punto iniziale) per fare riferimento ai parametri (.arg1, .arg2, ecc.).
Nelle espressioni Python, utilizza _argn (con un carattere di sottolineatura iniziale).
Esempi
Nell’esempio R, .arg1 è uguale a SUM([Profitto]):
SCRIPT_BOOL("is.finite(.arg1)", SUM([Profit]))
Nell’esempio successivo, la funzione restituisce True per gli ID dei negozi nello stato di Washington e False negli altri casi. Questo esempio potrebbe essere la definizione di un campo calcolato intitolato IsStoreInWA.
SCRIPT_BOOL('grepl(".*_WA", .arg1, perl=TRUE)',ATTR([Store ID]))
Un comando per Python assumerebbe questa forma:
SCRIPT_BOOL("return map(lambda x : x > 0, _arg1)", SUM([Profit]))
SCRIPT_INT
Restituisce come risultato un numero intero dall’espressione specificata. L’espressione viene passata direttamente a un’istanza di servizio di estensione di analisi in esecuzione.
Nelle espressioni R, utilizza .argn (con un punto iniziale) per fare riferimento ai parametri (.arg1, .arg2, ecc.)
Nelle espressioni Python, utilizza _argn (con un carattere di sottolineatura iniziale).
Esempi
Nell’esempio R, .arg1 è uguale a SUM([Profitto]):
SCRIPT_INT("is.finite(.arg1)", SUM([Profit]))
Nell’esempio seguente, il clustering k-viene utilizzato per creare tre cluster:
SCRIPT_INT('result <- kmeans(data.frame(.arg1,.arg2,.arg3,.arg4), 3);result$cluster;', SUM([Petal length]), SUM([Petal width]),SUM([Sepal length]),SUM([Sepal width]))
Un comando per Python assumerebbe questa forma:
SCRIPT_INT("return map(lambda x : int(x * 5), _arg1)", SUM([Profit]))
SCRIPT_REAL
Restituisce come risultato un numero reale dall’espressione specificata. L’espressione viene passata direttamente a un’istanza di servizio di estensione di analisi in esecuzione. Nelle
espressioni R, utilizza .argn (con un punto iniziale) per fare riferimento ai parametri (.arg1, .arg2, ecc.)
Nelle espressioni Python, utilizza _argn (con un carattere di sottolineatura iniziale).
Esempi
Nell’esempio R, .arg1 è uguale a SUM([Profitto]):
SCRIPT_REAL("is.finite(.arg1)", SUM([Profit]))
L’esempio seguente converte i valori di temperatura da Celsius a Fahrenheit.
SCRIPT_REAL('library(udunits2);ud.convert(.arg1, "celsius", "degree_fahrenheit")',AVG([Temperature]))
Un comando per Python assumerebbe questa forma:
SCRIPT_REAL("return map(lambda x : x * 0.5, _arg1)", SUM([Profit]))
SCRIPT_STR
Restituisce come risultato una stringa dall’espressione specificata. L’espressione viene passata direttamente a un’istanza di servizio di estensione di analisi in esecuzione.
Nelle espressioni R, utilizza .argn (con un punto iniziale) per fare riferimento ai parametri (.arg1, .arg2, ecc.)
Nelle espressioni Python, utilizza _argn (con un carattere di sottolineatura iniziale).
Esempi
Nell’esempio R, .arg1 è uguale a SUM([Profitto]):
SCRIPT_STR("is.finite(.arg1)", SUM([Profit]))
L’esempio seguente estrae un’abbreviazione di stato da una stringa più complicata (nella forma originale 13XSL_CA, A13_WA):
SCRIPT_STR('gsub(".*_", "", .arg1)',ATTR([Store ID]))
Un comando per Python assumerebbe questa forma:
SCRIPT_STR("return map(lambda x : x[:2], _arg1)", ATTR([Region]))
Creare un calcolo tabella utilizzando l’editor di calcolo
Per informazioni su come creare un calcolo tabella utilizzando l’editor di calcolo, segui i passaggi seguenti.
Nota: è possibile creare calcoli tabella in Tableau in diversi modi. In questo esempio, viene mostrato solo uno di questi modi. Per maggiori informazioni, consulta Trasformare i valori con i calcoli tabella(Il collegamento viene aperto in una nuova finestra).
Fase 1: creare la visualizzazione
In Tableau Desktop, connettiti all’origine dati salvata Sample - Superstore, fornita con Tableau.
Passa a un foglio di lavoro.
Dal riquadro Dati, sotto Dimensioni, trascina Data ordine sullo spazio Colonne.
Dal riquadro Dati, sotto Dimensioni, trascina Sottocategoria sullo spazio Righe.
Dal riquadro Dati, in Misure, trascina Vendite su Testo nella scheda Indicatori.
La visualizzazione viene aggiornata in una tabella di testo.
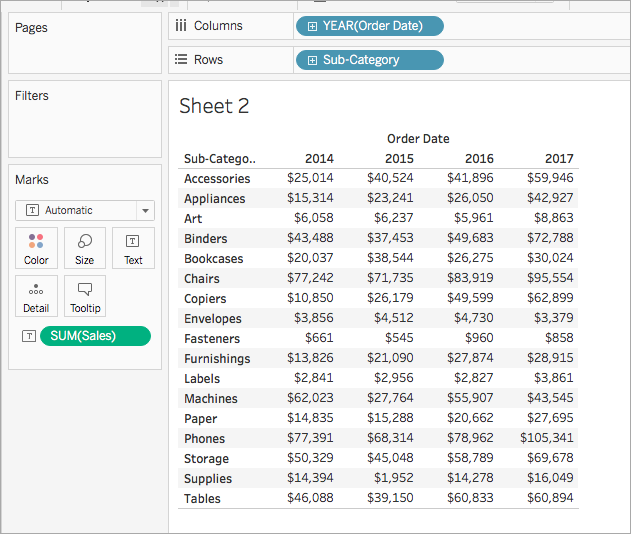
Fase 2: creare il calcolo tabella
Seleziona Analisi > Crea campo calcolato.
Nell’editor di calcolo che si apre, esegui le seguenti operazioni:
- Denomina il campo calcolato Somma corrente del profitto.
Immetti la seguente formula:
RUNNING_SUM(SUM([Profit]))Questa formula calcola la somma corrente delle vendite del profitto. Il calcolo si riferisce a tutta la tabella.
Al termine, fai clic su OK.
Visualizzerai il nuovo campo calcolo tabella in Misure nel riquadro Dati. Proprio come gli altri campi, puoi utilizzarlo in una o più visualizzazioni.
Fase 3: utilizzare il calcolo tabella nella visualizzazione
Dal riquadro Dati, in Misure, trascina Somma corrente del profitto su Colore nella scheda Indicatori.
Sulla scheda Indicatori, fai clic sul menu a discesa Tipo di indicatore e seleziona Quadrato.
La visualizzazione viene aggiornata in una tabella evidenziata:
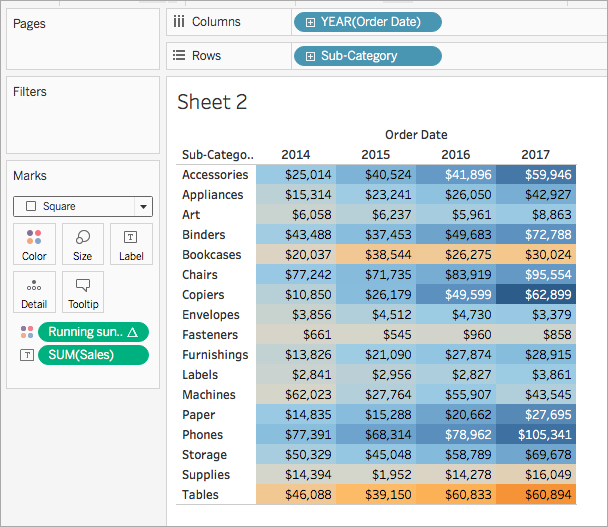
Fase 4: modificare il calcolo tabella
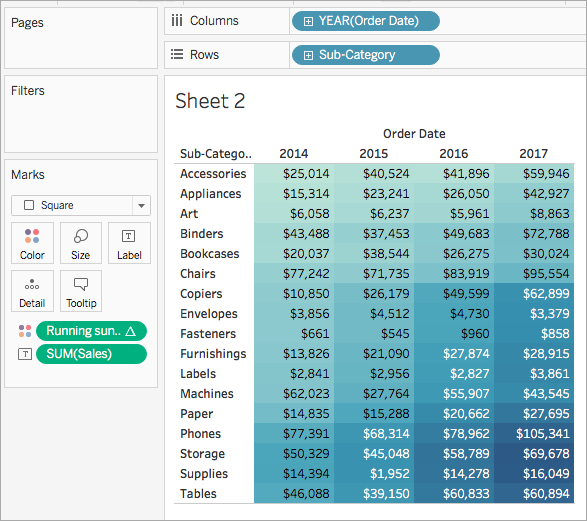
- Sulla scheda Indicatori, fai clic con il pulsante destro del mouse su Somma corrente del profitto e seleziona Modifica calcolo della tabella.
Nella finestra di dialogo Calcolo tabella che si apre, sotto Calcola usando, seleziona Tabella (giù).
La visualizzazione si aggiorna come segue:
Vedi anche
Creare un calcolo tabella(Il collegamento viene aperto in una nuova finestra)
Personalizzare i calcoli tabella(Il collegamento viene aperto in una nuova finestra)