Spara och dela ditt arbete
Data Cloud har bytt namn till Data 360 från och med den 14 oktober 2025. Under övergångstiden kan du se hänvisningar till Data Cloud i vårt program och i vår dokumentation. Även om namnet är nytt är funktionaliteten och innehållet oförändrat.
När som helst i ditt flöde kan du spara ditt arbete manuellt, eller automatiskt låta Tableau göra det åt dig när du skapar eller redigerar flöden på webben. När man arbetar med flöden på webben finns det några skillnader.
Mer information om hur du redigerar flöden på webben finns i Tableau Prep på webben i hjälpen för Tableau Server(Länken öppnas i ett nytt fönster) och Tableau Cloud(Länken öppnas i ett nytt fönster).
| Tableau Prep Builder | Tableau Prep på webben |
|---|---|
|
|
För att hålla data uppdaterade kan du köra dina flöden manuellt från Tableau Prep Builder eller från kommandoraden. Du kan också köra flöden som publiceras på Tableau Server eller Tableau Cloud manuellt eller enligt ett schema. Mer information om hur man kör flöden finns i Publicera ett flöde i Tableau Server eller Tableau Cloud.
Spara ett flöde
I Tableau Prep Builderkan du spara ditt flöde manuellt för att säkerhetskopiera ditt arbete innan du utför några ytterligare åtgärder. Ditt flöde sparas i Tableau Prep flow-format (.tfl).
Du kan också paketera dina lokala filer (Excel, Textfiler och Tableau extrakt) med ditt flöde för att dela med andra, precis som förpackning av en arbetsbok för att dela i Tableau Desktop. Endast lokala filer kan paketeras med ett flöde. Data från databasanslutningar ingår till exempel inte.
I webbredigering packas lokala filer automatiskt med vårt flöde. Direkta filanslutningar stöds ännu inte.
När du sparar ett förpackat flöde sparas flödet som en packeterad Tableau Flow File (.tflx).
- Om du vill spara flödet manuellt väljer du Fil > Spara från den övre menyn.
- För att paketera dina datafiler från toppmenyn i Tableau Prep Builder med ditt flöde, gör du något av följande:
- Välj Fil > Exportera paketerat flöde
- Välj Arkiv > Spara som. Sedan i dialogrutan Spara som välj Packeterade Tableau Flow File från Spara som typ rullgardinsmeny.
Spara dina flöden på webben automatiskt
Om du skapar eller redigerar flöden på webben sparas arbetet automatiskt som ett utkast med några sekunders mellanrum så fort du gör en ändring i flödet (ansluter till en datakälla, lägger till ett steg och så vidare) så att du inte riskerar att förlora något.
Du kan bara spara flöden till den server som du för närvarande är inloggad på. Du kan inte skapa ett utkastflöde på en server och försöka spara eller publicera det på en annan server. Om du vill publicera flödet till ett annat projekt på servern använder du menyalternativet Fil > Publicera som och väljer sedan ditt projekt i dialogrutan.
Utkastflöden kan endast ses av dig tills du publicerar dem och gör dem tillgängliga för alla som har behörighet att komma åt projektet på din server. Flöden i ett utkaststatus taggas med ett Utkast-märke så att du enkelt kan hitta dina flöden under utveckling. Om flödet aldrig har publicerats visas ett Aldrig Publicerat-märke bredvid Utkast-märket.

När ett flöde har publicerats och du redigerar och publicerar flödet på nytt skapas en ny version. Du kan se en lista över flödesversioner i dialogrutan Granskningshistorik . På sidan Utforska klickar du på menyn ![]() Åtgärder och väljer Granskningshistorik.
Åtgärder och väljer Granskningshistorik.
För mer information om hantering av granskningshistorik, se Arbete med innehållsrevisioner(Länken öppnas i ett nytt fönster) i hjälp för Tableau Desktop.
Obs! Autospara är aktiverat som standard. Administratörer kan inaktivera Spara automatiskt för en plats, men det rekommenderas inte. För att stänga av autospara, använd Tableau Server REST API-metoden ”Update Site” och ställ in flowAutoSaveEnabled attributet till falskt. Mer information finns i Tableau Server REST API Site Methods: Update Site(Länken öppnas i ett nytt fönster) (Tableau Server REST API-platsmetoder: Uppdatera plats).
Automatisk filåterställning
Som standard sparar Tableau Prep Builder automatiskt ett utkast av alla öppna flöden om programmet fryser eller kraschar. Utkastflöden sparas i mappen Återställda flöden i Min Tableau Prep-lagringsplats. Nästa gång du öppnar programmet visas en dialogruta med en lista över de återställda flöden du kan välja bland. Du kan öppna ett återställt flöde och fortsätta där du slutade, eller ta bort filen för det återställda flödet om du inte behöver den.
Obs! Om du har återställt flöden i mappen Återställda flöden visas den här dialogrutan varje gång du öppnar programmet tills mappen är tom.

Om du inte vill att den här funktionen ska aktiveras kan du som administratör stänga av den under installationen eller efter installationen. För mer information om hur du stänger av denna funktion, se Stäng av filåterställning(Länken öppnas i ett nytt fönster) i distributionsguiden för Tableau Desktop och Tableau Prep.
Återställ borttagna flöden
Stöds i Tableau Prep-webbredigering i Tableau Cloud och Tableau Server version 2025.3 och senare.
I webbredigering kan du återställa borttagna flöden från papperskorgen. Om papperskorgen är aktiverad flyttas flöden tillfälligt till papperskorgen istället för att tas bort permanent, och medan de är i papperskorgen kan du återställa dem eller välja att ta bort dem permanent. Flöden i utkastläge tas dock fortfarande bort permanent. Mer information om papperskorgen finns i Papperskorgen(Länken öppnas i ett nytt fönster).
Obs! Den här funktionen finns inte i Tableau Prep Builder än.
Följande krävs för att använda den funktionen:
Behörighet: Du måste ha någon av rollerna Platsadministratör, Serveradministratör, Creator eller Explorer (kan publicera).
Platsinställning: Papperskorgen är aktiverad för din plats
Flödesstatus: Flödet måste vara publicerat.
Administratören ställer in hur länge flöden ska lagras i papperskorgen.
Återställa ett flöde
Utöka sidorutan från startsidan och välj sedan Papperskorg.
På sidan Papperskorg väljer du Flöden i listrutemenyn Innehållstyp.

Öppna menyn Fler åtgärder för flödet du vill återställa och välj sedan Återställ.

Välj ett projekt som återställningsplats.

Välj Återställ.
Visa flödesutdata i Tableau Desktop
Obs! Det här alternativet är inte tillgängligt på webben.
Ibland när du rensar dina data kanske du vill kontrollera dina framsteg genom att titta på dem i Tableau Desktop. När ditt flöde öppnas i Tableau Desktop, skapar Tableau Prep Builder en permanent Tableau .hyper-fil och en fil för Tableau datakälla (.tds). Dessa filer sparas i din Tableau-lagringsplats i Datakällfilen så att du kan experimentera med dina data när som helst.
När du öppnar flödet i Tableau Desktop visas det dataurval som du arbetar med i flödet med de åtgärder som tillämpas på det, upp till det steg som du har valt.
Obs! Även om du kan experimentera med dina data, visar Tableau bara ett exempel på dina data och du kommer inte att kunna spara arbetsboken som en paketerad arbetsbok (.twbx). När du är redo att arbeta med data i Tableau skapar du ett utdatasteg i flödet och sparar utdata i en fil eller som en publicerad datakälla och ansluter sedan till den fullständiga datakällan i Tableau.
Gör följande för att visa ditt dataprov i Tableau Desktop:
- Högerklicka på steget där du vill visa dina data och välj Förhandsgranska i Tableau Desktop på kontextmenyn.

- Tableau Desktop öppnas på fliken Ark.
Skapa dataextraktfiler och publicerade datakällor
Du skapar flödesutdata genom att köra flödet. När du kör ditt flöde tillämpas dina ändringar på hela datauppsättningen. Att köra flöden resulterar i en Tableau Data Source (.tds) och en Tableau Data Extract (.hyper) -fil.
Obs! Utdata från flöden som innehåller spatiala data är begränsade till .hyper-filer och publicerade datakällor. För närvarande stöds inga andra utdatatyper. Mer information om hur du arbetar med spatiala data finns i Skapa spatiala beräkningar och kopplingar.(Länken öppnas i ett nytt fönster)
Tableau Prep Builder
Du kan skapa en extraktfil från flödesutdata för att använda i Tableau Desktop eller för att dela data med tredje part. Skapa en extraktfil i följande format:
- Hyperextrakt (.hyper): Detta är den senaste Tableau-extraktfiltypen.
- Kommaseparerat värde (.csv): Spara exktraktet i en .csv-fil för att dela dina data med tredje part. Kodningen av den exporterade CSV-filen är UTF-8 med BOM.
- Microsoft Excel (.xlsx): Ett Microsoft Excel-kalkylblad.
Tableau Prep Builder och på webben
Publicera ditt flöde till en publicerad datakälla eller utdata till en databas.
- Spara flödesutdata som en datakälla till Tableau Server eller Tableau Cloud för att dela data och ge central tillgång till de data du har rensat, format och kombinerat.
- Spara flödesutdata i en databas för att skapa, ersätta eller lägga till tabelldata med dina rena, förberedda flödesdata. Mer information finns i Spara flödesutdata till externa databaser.
Använd inkrementell uppdatering när du kör ditt flöde för att spara tid och resurser genom att bara uppdatera nya data istället för din fullständiga datauppsättning. För information om hur du konfigurerar och kör ditt flöde med inkrementell uppdatering, se Uppdatera flödesdata med inkrementell uppdatering.
Obs! För att publicera Tableau Prep Builder-utdata till Tableau Server måste Tableau Server REST API vara aktiverat. Mer information finns i Rest API krav(Länken öppnas i ett nytt fönster) i hjälpavsnittet för Tableau Rest API. För att publicera till en server som använder SSL-krypteringscertifikat (Secure Socket Layer) krävs ytterligare konfigurationssteg på datorn som kör Tableau Prep Builder. Mer information finns i Innan installation(Länken öppnas i ett nytt fönster) i distributionsguiden för Tableau Desktop och Tableau Prep Builder.
Inkludera parametrar i ditt flödesutdata
Stöds i Tableau Prep Builder och på webben med start i version 2021.4
Inkludera parametervärden i dina utdatafilnamn, sökvägar, tabellnamn eller anpassade SQL-skript (version 2022.1.1 och senare) för att enkelt köra dina flöden för olika datauppsättningar. Mer information finns i Skapa och använd parametrar i flöden.
Skapa ett extrakt till en fil
Obs! Det här utmatningsalternativet är inte tillgängligt när du skapar eller redigerar flöden på webben.
- Klicka på plusikonen
 i ett steg och välj Lägg till utdata.
i ett steg och välj Lägg till utdata.Om du har kört flödet tidigare så klicka på knappen Kör flöde
 i utmatningssteget. Därmed körs flödet och dina utdata uppdateras.
i utmatningssteget. Därmed körs flödet och dina utdata uppdateras.Rutan Utdata öppnas och visar dig en ögonblicksbild av dina data.

- Välj Fil i listrutan Spara utdata till i den vänstra rutan. I tidigare versioner väljer du Spara till fil.
- Klicka på knappen Bläddra, sedan i dialogrutan Spara extrakt som, ange ett namn för filen och klicka på Acceptera.
- I fältet Utdatatyp väljer du bland följande utdatatyper:
- Tableau-dataextrakt (.hyper)
- Kommaseparerade värden (.csv)
(Tableau Prep Builder) Visa standardskrivalternativet för att skriva nya data till dina filer i avsnittet Skrivalternativ och gör eventuella ändringar om så behövs. Mer information finns i Anpassa skrivalternativ.
- Skapa tabell: Det här alternativet skapar en ny tabell eller ersätter den befintliga tabellen med nya utdata.
- Lägg till i tabell: Det här alternativet lägger till nya data i din befintliga tabell. Om tabellen inte redan finns så skapas en ny tabell och efterföljande körningar lägger till nya rader i den här tabellen.
Obs!Lägg till i tabell är inte tillgängligt för .csv-utdatatyper. Mer information om stödda uppdateringskombinationer finns i Alternativ för uppdatering av flöde.
- Klicka på Kör flöde för att köra flödet och generera extrakfilen.
Skapa ett extrakt till ett Microsoft Excel-arbetsblad
Stöds i Tableau Prep Builder version 2021.1.2 och senare. Det här utdataalternativet är inte tillgängligt när du skapar eller redigerar flöden på webben eller när du skapar utdata för flöden som innehåller spatiala data.
När du matar ut flödesdata till ett Microsoft Excel-arbetslad kan du skapa ett nytt arbetsblad eller lägga till eller ersätta data i ett befintligt arbetsblad. Följande villkor gäller:
- Endast Microsoft Excel .xlsx-filformat stöds.
- Arbetsbladets rader börjar i cell A1.
- När du lägger till eller ersätter data antas den första raden vara rubrik.
- Rubriknamn läggs till när du skapar ett nytt arbetsblad, men inte när du lägger till data i ett befintligt arbetsblad.
- Formatering eller formler i befintliga arbetsblad tillämpas inte på flödesutdata.
- Skrivning till namngivna tabeller eller områden stöds för närvarande inte.
- Inkrementell uppdatering stöds för närvarande inte.
Mata ut flödesdata till en Microsoft Excel-arbetsbladfil
- Klicka på plusikonen i ett steg och välj Lägg till utdata.
Om du har kört flödet tidigare så klicka på knappen Kör flöde
i utmatningssteget. Därmed körs flödet och dina utdata uppdateras.Rutan Utdata öppnas och visar dig en ögonblicksbild av dina data.

- Välj Fil i listrutan Spara utdata till i den vänstra rutan.
- Klicka på knappen Bläddra, sedan i dialogrutan Spara extrakt som, ange ett namn för filen och klicka på Acceptera.
- I fältet Utdatatypg väljer du Microsoft Excel (.xlsx).

- I fältet Arbetsblad väljer du det arbetsblad som du vill skriva dina resultat till, eller anger ett nytt namn i fältet istället och klickar sedan på Skapa ny tabell.
- I avsnittet Skrivalternativ väljer du ett av följande skrivalternativ:
- Skapa tabell: Skapar eller återskapar arbetsbladet med flödesdata (om filen redan finns).
- Lägg till i tabell: Lägger till nya rader i ett befintligt arbetsblad. Om arbetsbladet inte finns skapas ett och efterföljande flödeskörningar lägger till rader i det arbetsbladet.
- Ersätt data: Ersätter alla befintliga data utom den första raden i ett befintligt arbetsblad med flödesdata.
En fältjämförelse visar de fält i flödet som matchar fälten i arbetsbladet, om det redan finns. Om arbetsbladet är nytt visas en en-mot-en-fältmatchning. Alla fält som inte matchar ignoreras.

- Klicka på Kör flöde för att köra flödet och generera Microsoft Excel-extrakfilen.
Skapa en publicerad datakälla
- Klicka på plusikonen i ett steg och välj Lägg till utdata.
Obs! Tableau Prep Builder uppdaterar tidigare publicerade datakällor och upprätthåller alla datamodeller (till exempel beräknade fält, nummerformatering och så vidare) som kan inkluderas i datakällan. Om datakällan inte kan uppdateras ersätts datakällan, inklusive datamodellering, i stället.
- Rutan Utdata öppnas och visar dig en ögonblicksbild av dina data.

- I rullgardinsmenyn Spara utdata till väljer du Publicerad datakälla (Publicera som datakälla i tidigare versioner) . Fyll i följande fält:
- Server (endast Tableau Prep Builder): Välj servern där du vill publicera datakällan och dataextraktet. Om du inte är inloggad på en server blir du ombedd att logga in.
Obs! Från och med Tableau Prep Builder version 2020.1.4, efter att du loggat in på din server, kommer Tableau Prep Builder ihåg ditt servernamn och dina inloggningsuppgifter när du stänger programmet. Nästa gång du öppnar programmet är du redan inloggad på din server.
På Mac kan du bli ombedd att ge tillgång till din Mac-nyckelring så att Tableau Prep Builder säkert kan använda SSL-certifikat för att ansluta till din Tableau Server eller Tableau Cloud-miljö.
Om du matar ut till Tableau Cloud inkluderar du det datacenter som är värd för din plats i ”serverUrl”. Till exempel ”https://eu-west-1a.online.tableau.com” inte ”https://online.tableau.com”.
- Projekt: Välj det projekt där du vill ladda datakällan och extrahera.
- Namn: Ange ett filnamn.
- Beskrivning: Ange en beskrivning för datakällan.
- Server (endast Tableau Prep Builder): Välj servern där du vill publicera datakällan och dataextraktet. Om du inte är inloggad på en server blir du ombedd att logga in.
- (Tableau Prep Builder) Visa standardskrivalternativet för att skriva nya data till dina filer i avsnittet Skrivalternativ och gör eventuella ändringar om så behövs. Mer information finns i Anpassa skrivalternativ
- Skapa tabell: Det här alternativet skapar en ny tabell eller ersätter den befintliga tabellen med nya utdata.
- Lägg till i tabell: Det här alternativet lägger till nya data i din befintliga tabell. Om tabellen inte finns redan så skapas en ny tabell och efterföljande körningar lägger till nya rader i den här tabellen.
- Klicka på Kör flöde för att köra flödet och publicera datakällan.
Spara flödesutdata till externa databaser
Det här utdataalternativet är inte tillgängligt när du skapar utdata för flöden som innehåller spatiala data.
Viktigt: Med den här funktionen kan du permanent radera och ersätta data i en extern databas. Kontrollera att du har behörighet att skriva till databasen.
För att förhindra förlust av data kan du använda alternativet Anpassad SQL för att göra en kopia av dina tabelldata och köra den innan du skriver flödesdata till tabellen.
Du kan ansluta till data från någon av de anslutningar som Tableau Prep Builder eller webben stöder och mata ut data till en extern databas. Du kan lägga till eller uppdatera data i din databas med rena, förberedda data från ditt flöde varje gång flödet körs. Den här funktionen är tillgänglig för både inkrementella och fullständiga uppdateringsalternativ, såvida inget annat anges. För information om hur du konfigurerar inkrementell uppdatering, se Uppdatera flödesdata med inkrementell uppdatering.
När du sparar din flödesutmatning i en extern databas, gör Tableau Prep följande:
- Genererar raderna och kör alla SQL-kommandon mot databasen.
- Skriver data till en tillfällig tabell (eller plattform om utmatning sker till Snowflake) i utdatadatabasen.
- Om åtgärden lyckas flyttas data från den tillfälliga tabellen (eller din plattform för Snowflake) till måltabellen.
- Kör alla SQL-kommandon som du vill köra efter att ha skrivit data till databasen.
Om SQL-skriptet misslyckas kommer flödet att misslyckas. Dina data kommer dock fortfarande att laddas i dina databastabeller. Du kan försöka köra flödet igen eller manuellt köra ditt SQL-skript i databasen för att tillämpa det.
Utdataalternativ
Du kan välja följande alternativ när du skriver data till en databas. Om tabellen inte existerar skapas den när flödet körs för första gången.
- Lägg till i tabell: Det här alternativet lägger till nya data i en befintlig tabell. Om tabellen inte finns skapas den när flödet körs första gången och data läggs till i tabellen vid varje efterföljande flödeskörning.
- Skapa tabell: Detta alternativ skapar en ny tabell med data från ditt flöde. Om tabellen redan finns tas tabellen, och eventuella befintliga datastrukturer eller egenskaper som definierats för tabellen, bort och ersätts med en ny tabell som använder flödesdatastrukturen. Alla fält som finns i flödet läggs till i den nya databastabellen.
- Ersätt data: Det här alternativet tar bort data i den befintliga tabellen och ersätter dem med data från flödet, men bevarar databastabellens struktur och egenskaper. Om tabellen inte finns skapas den när flödet körs första gången och tabelldata ersätts vid varje efterföljande flödeskörning.
Ytterligare alternativ
Förutom skrivalternativen kan du också inkludera anpassade SQL-skript eller lägga till nya tabeller i din databas.
- Anpassade SQL-skript: Ange din anpassade SQL och välj om du vill köra ditt skript före, efter eller både före och efter att data skrivs till databastabellerna. Du kan använda dessa skript för att skapa en kopia av databastabellen innan flödesdata skrivs till tabellen, lägga till ett index, lägga till andra tabellegenskaper och så vidare.
Obs! Från och med version 2022.1.1 kan du också infoga parametrar i dina SQL-skript. Mer information finns i Tillämpa användarparametrar på utmatningssteg.
- Lägg till en ny tabell: Lägg till en ny tabell med ett unikt namn i databasen istället för att välja en från den befintliga tabellistan. Om du vill använda ett annat schema än standardschemat (Microsoft SQL Server och PostgreSQL) kan du ange det med syntaxen
[schema name].[table name].
Databaser som stöds och databaskrav
Tableau Prep stöder att skriva flödesdata till tabeller i ett utvalt antal databaser. Flöden som körs på ett schema i Tableau Cloud kan bara skriva till dessa databaser om de är molnbaserade.
Om du ansluter till lokala datakällor kan du, från och med version 2025.1, använda en Tableau Bridge-klient för att ansluta till och uppdatera dina data i Tableau Cloud. Det kräver en Tableau Bridge-klient som är konfigurerad i en Bridge-klientpool, med domänen tillagd i godkännandelistan över privata nätverk. Se till att serverns URL matchar domänen i Bridge-poolen när du ansluter till din datakälla i Tableau Prep Builder och på webben. Mer information finns under ”Databaser” i avsnittet Tableau Cloud i Publicera ett flöde från Tableau Prep Builder(Länken öppnas i ett nytt fönster).
Vissa databaser har datarestriktioner eller datakrav. Tableau Prep kan också införa vissa gränser för att upprätthålla maximal prestanda när du skriver data till de databaser som stöds. I följande tabell listas de databaser där du kan spara dina flödesdata och eventuella databasrestriktioner eller krav. Data som inte uppfyller dessa krav kan leda till fel när flödet körs.
Obs! Det går inte att ange teckengränser för fält än. Du kan dock skapa tabeller i databasen som innehåller teckenbegränsningar och sedan använda alternativet Ersätt data för att ersätta dina data men behålla tabellens struktur i databasen.
| Databas | Krav eller begränsningar |
|---|---|
| Amazon Redshift |
|
| Amazon S3 (endast utdata) | Se Spara flödesutdata till Amazon S3 |
| Databricks |
|
| Google BigQuery |
|
| Microsoft SQL Server |
|
| MySQL |
|
| Oracle |
|
| Pivotal Greenplum-databas |
|
| PostgreSQL |
|
| SAP HANA |
|
| Snowflake |
|
| Teradata |
|
| Vertica |
|
Spara flödesdata till en databas.
Obs! Du kan bädda in dina inloggningsuppgifter för databasen när du publicerar flödet. För mer information om inbäddning av referenser, se avsnittet Databaser i Publicera ett flöde från Tableau Prep Builder
- Klicka på plusikonen i ett steg och välj Lägg till utdata.
- Välj Databas och molnlagring i listrutan Spara utdata till.
- På fliken Inställningar anger du följande information:
- I rullgardinsmenyn Anslutning väljer du databasanslutningen där du vill skriva flödesutmatningen. Endast kopplingar som stöds visas. Det kan vara samma kontakt som du använde för din flödesindata eller en annan kontakt. Om du väljer en annan anslutning blir du ombedd att logga in.
Viktigt: Se till att du har skrivbehörighet till den databas du väljer. Annars kan flödet endast delvis bearbeta data.
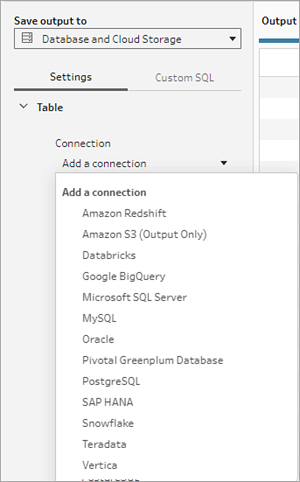
- I rullgardinsmenyn Databas väljer du databas där du vill spara flödesutdata. Scheman eller databaser måste innehålla minst en tabell för att visas i listrutan.
- I rullgardinsmenyn Tabell väljer du tabellen där du vill spara flödesutdata. Beroende på det skrivalternativ du väljer kommer en ny tabell att skapas, flödesdata kommer att ersätta alla befintliga data i tabellen, eller så kommer flödesdata att läggas till i den befintliga tabellen.
Om du vill skapa en ny tabell i databasen anger du istället ett unikt tabellnamn i fältet och klickar sedan på Skapa ny tabell. När du kör flödet för första gången, oavsett vilket skrivalternativ du väljer, skapas tabellen i databasen med samma schema som flödet.

- I rullgardinsmenyn Anslutning väljer du databasanslutningen där du vill skriva flödesutmatningen. Endast kopplingar som stöds visas. Det kan vara samma kontakt som du använde för din flödesindata eller en annan kontakt. Om du väljer en annan anslutning blir du ombedd att logga in.
- Rutan Utdata öppnas och visar dig en ögonblicksbild av dina data. En fältjämförelse visar de fält i flödet som matchar fälten i tabellen, om tabellen redan finns. Om tabellen är ny visas en en-mot-en-fältmatchning.

Om det finns några missmatchningar i fält visar en statusanteckning eventuella fel.
- Ingen träff: Fält ignoreras: Fält finns i flödet men inte i databasen. Fältet kommer inte att läggas till i databastabellen om du inte väljer skrivalternativet Skapa tabell och utför en fullständig uppdatering. Därefter läggs flödesfälten till i databastabellen och använder schemat för flödesutdata.
- Ingen träff: Fält kommer innehålla null-värden: Fält finns i databasen men inte i flödet. Flödet skickar ett null-värde till databastabellen för fältet. Om fältet finns i flödet, men inte matchar eftersom fältnamnet är annorlunda, kan du navigera till ett rensningssteg och redigera fältnamnet så att det matchar databasfältnamnet. Mer information om hur du kan redigera fältnamn finns i Tillämpa rensningsåtgärder.
- Fel: Fältdatatyper matchar inte: Datatypen som tilldelats ett fält i både flödet och databastabellen som du skriver utdata till måste matcha, annars kommer flödet att misslyckas. Du kan navigera till ett rengöringssteg och redigera fältdatatypen för att åtgärda detta. Mer information om hur man ändrar datatyper finns i Granska de datatyper som tilldelats dina data.
- Välj ett skrivalternativ. Du kan välja ett annat alternativ för fullständig och inkrementell uppdatering och alternativet tillämpas när du väljer din metod för flödeskörning. Mer information om hur du kör vårt flöde med inkrementell uppdatering finns i Uppdatera flödesdata med inkrementell uppdatering.
- Lägg till i tabell: Det här alternativet lägger till nya data i en befintlig tabell. Om tabellen inte finns skapas den när flödet körs första gången och data läggs till i tabellen vid varje efterföljande flödeskörning.
- Skapa tabell: Detta alternativ skapar en ny tabell. Om tabellen med samma namn redan finns tas den befintliga tabellen bort och ersätts med den nya tabellen. Alla befintliga datastrukturer eller egenskaper som definierats för tabellen tas också bort och ersätts med flödesdatastrukturen. Alla fält som finns i flödet läggs till i den nya databastabellen.
- Ersätt data: Det här alternativet tar bort data i den befintliga tabellen och ersätter dem med data från flödet, men bevarar databastabellens struktur och egenskaper.
- (valfritt) Klicka på fliken Anpassa SQL och ange ditt SQL-skript. Du kan ange ett skript för att köra Före och Efter data skrivs till tabellen.

- Klicka på Kör flöde för att köra flödet och skriva dina data till din valda databas.
Spara flödesutdata till datauppsättningar i CRM Analytics
Stöds i Tableau Prep Builder och på webben från och med version 2022.3.
Obs! CRM Analytics har flera krav och vissa begränsningar när man integrerar data från externa källor. För att säkerställa att du kan skriva ditt flödesutdata till CRM Analytics, se Överväganden innan du integrerar data i datauppsättningar(Länken öppnas i ett nytt fönster) i Salesforce-hjälpen.
Rensa din data med Tableau Prep och få bättre förutsägelseresultat i CRM Analytics. Anslut helt enkelt till data från någon av kopplingarna som Tableau Prep Builder eller Tableau Prep på webben har stöd för. Tillämpa sedan omvandlingar för att rensa dina data och mata ut dina flödesdata direkt till datauppsättningar i CRM Analytics som du har åtkomst till.
Flöden som matar ut data till CRM Analytics kan inte köras med kommandoradsgränssnittet. Du kan köra flöden manuellt med Tableau Prep Builder eller med hjälp av ett schema på webben med Tableau Prep Conductor.
Förutsättningar
För att mata ut flödesdata till CRM Analytics behöver du kontrollera att du har följande licenser, åtkomst och behörigheter i Salesforce och Tableau.
Salesforce-krav
| krav | beskrivning |
|---|---|
| Salesforce-behörigheter | Du måste tilldelas någon av licenserna CRM Analytics Plus eller CRM Analytics Growth. CRM Analytics Plus-licensen inkluderar följande behörighetsuppsättningar:
CRM Analytics Growth-licensen inkluderar följande behörighetsuppsättningar:
Mer information finns i Läs om CRM Analytics-licenser och behörighetsuppsättningar(Länken öppnas i ett nytt fönster) och Välj och tilldela behörighetsuppsättningar för användare(Länken öppnas i ett nytt fönster) i Salesforce-hjälpen. |
Administratörsinställningar | Salesforce-administratörer måste konfigurera:
|
Förutsättningar för Tableau Prep
| krav | beskrivning |
|---|---|
Licens och behörigheter för Tableau Prep | Creator-licens Som Creator måste du logga in på ditt Salesforce-organisationskonto och autentisera dig innan du kan välja appar och datauppsättningar för att mata ut dina flödesdata. |
OAuth-dataanslutningar | Som serveradministratör konfigurerar du Tableau Server med ett OAuth-klient-ID och en hemlighet på kopplingen. Detta krävs för att köra flöden på Tableau Server. Mer information finns i Konfigurera Tableau Server för Salesforce.com OAuth(Länken öppnas i ett nytt fönster) i Tableau Server-hjälpen. |
Spara flödesdata till CRM Analytics
Följande CRM Analytics-indatagränser gäller när du sparar från Tableau Prep Builder till CRM Analytics.
- Maximal filstorlek för extern datauppladdning: 40 GB
- Maximal filstorlek för alla externa datauppladdningar under en 24-timmarsperiod: 50 GB
- Klicka på plusikonen i ett steg och välj Lägg till utdata.
- Välj CRM Analytics i listrutan Spara utdata till.

- Anslut till Salesforce i avsnittet Datauppsättning.
Logga in på Salesforce och klicka på Tillåt för att ge Tableau åtkomst till CRM Analytics-appar och -datauppsättningar eller välj en befintlig Salesforce-anslutning
- Välj ett befintligt datauppsättningsnamn i fältet Namn. Detta skriver över och ersätter datauppsättningen med dina flödesutdata. Annars skriver du ett nytt namn och klickar på Skapa ny datauppsättning för att skapa en ny datauppsättning i den valda CRM Analytics-appen.
Obs! Datauppsättningsnamn får inte överstiga 80 tecken.

- Under fältet Namn verifierar du att appen som visas är den som du har behörighet att skriva till.
För att ändra appen klickar du på Bläddra bland datauppsättningar och väljer sedan appen i listan, anger datauppsättningens namn i fältet Namn och klickar på Acceptera.

- I avsnittet Skrivalternativ är Fullständig uppdatering och Skapa tabell de enda alternativen som stöds.
- Klicka på Kör flöde för att köra flödet och skriva dina data till CRM Analytics-datauppsättningen.
Om flödet körs framgångsrikt kan du verifiera utdataresultaten i CRM Analytics på fliken Övervaka i datahanteraren. Mer information om den här funktionen finns i Övervaka en extern databelastning(Länken öppnas i ett nytt fönster) i Salesforce-hjälpen.
Spara flödesutdata till Data Cloud
Stöds i Tableau Prep Builder och på webben från och med version 2023.3.
Förbered data med Tableau Prep och associera dem sedan med befintliga datauppsättningar i Data Cloud. Använd någon av de kopplingar som Tableau Prep Builder eller Tableau Prep på webben har stöd för för att importera data, rensa och förbereda dem och sedan mata ut flödesdata direkt till Data Cloud med hjälp av inhämtnings-API:et.
Behörighetskrav
Salesforce-licens | Information om Data Cloud-utgåvor och tilläggslicenser finns i Standardutgåvor och licenser för Data Cloud (på engelska) i Salesforce-hjälpen. Läs även Begränsningar och riktlinjer för Data Cloud (på engelska). |
| Behörigheter för datautrymmen | Du måste vara tilldelad till ett datautrymme och även till en av följande behörighetsuppsättningar i Data Cloud:
Mer information finns i Hantera datautrymmen(Länken öppnas i ett nytt fönster) (på engelska) och Hantera datautrymmen med äldre behörighetsuppsättningar(Länken öppnas i ett nytt fönster) (på engelska). |
Behörighet för inhämtning till Data Cloud | Du måste tilldelas följande för fältåtkomst för inhämtning till Data Cloud:
Mer information finns i Aktivera behörigheter för objekt och fält (på engelska). |
| Salesforce-profiler | Aktivera profilåtkomst för:
|
| Licens och behörigheter för Tableau Prep | Creator-licens Som Creator-användare måste du logga in på ditt Salesforce-organisationskonto och autentisera dig innan du kan välja appar och datauppsättningar för utmatning av flödesdata. |
Spara flödesdata till Data Cloud
Om du redan använder inhämtnings-API:et och anropar API:erna manuellt för att spara datauppsättningar till Data Cloud, kan du förenkla det arbetsflödet med Tableau Prep. Den konfiguration som krävs är samma som för Tableau Prep.
Om det här är första gången du sparar data till Data Cloud följer du konfigurationskraven i Konfigurationskrav för Data Cloud.
- Klicka på plusikonen i ett steg och välj Lägg till utdata.
- Välj Salesforce Data Cloud i listrutan Save output to (Spara utdata till).
- I avsnittet Object (Objekt) väljer du Salesforce Data Cloud-organisation att logga in på.

- Klicka på Sign In (Logga in) på Salesforce Data Cloud-menyn.
- Logga in på Data Cloud-organisationen med ditt användarnamn och lösenord.
- Klicka på Allow (Tillåt) i formuläret Allow Access (Tillåt åtkomst).
- I avsnittet Save output to (Spara utdata till) anger du kopplingen för inhämtnings-API:et och objektnamnet.
- Gör följande för att hitta namnet på kopplingen för inhämtnings-API:et och motsvarande objektnamn:
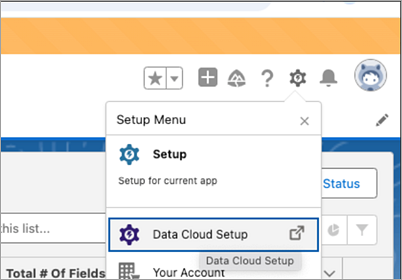
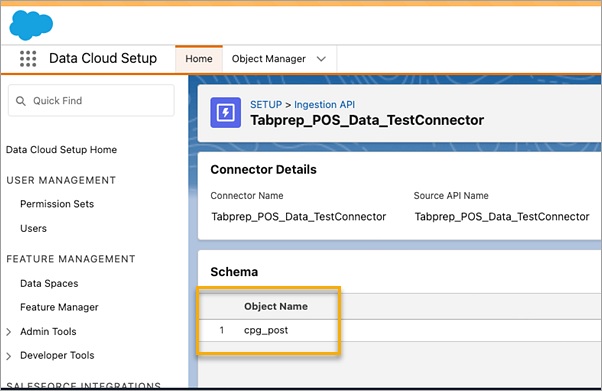
Logga in på Salesforce Data Cloud och gå till Data Cloud Setup (Data Cloud-konfiguration).
I rutan för snabbsökning skriver du Users (Användare) och väljer sedan Ingestion API (Inhämtnings-API) i resultatet.
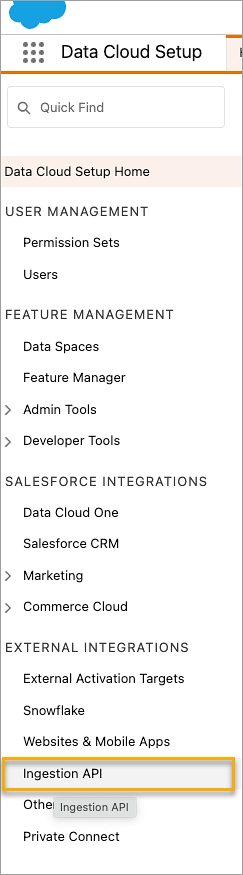
På sidan Ingestion API (Inhämtnings-API) visas tillgängliga kopplingar under Connector Name (Kopplingsnamn).
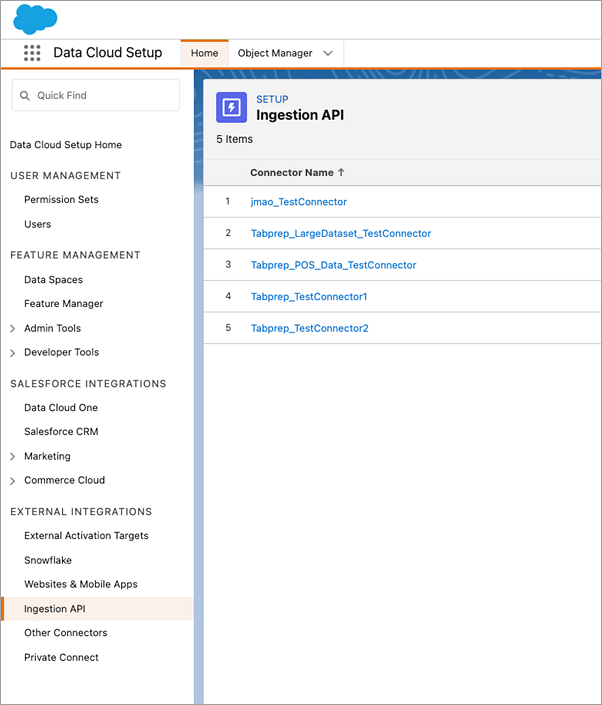
Välj en koppling i listan för att hitta motsvarande Object Name (Objektnamn) för den koppling som du vill använda. I avsnittet Schema på sidan Connector Details (Kopplingsinformation) visas motsvarande objekt under Object Name (Objektnamn).
- Avsnittet Write Options (Skrivalternativ) talar om att befintliga rader uppdateras om det angivna värdet redan finns i en tabell eller att en ny rad infogas om det angivna värdet inte finns.
- Klicka på Run Flow (Kör flöde) för att köra flödet och skriva data till Data Cloud.
- Kontrollera data i Data Cloud genom att visa körstatusen i dataströmmen och objekten i datautforskaren.

Det öppnas ett webbläsarfönster för https://login.salesforce.com/.



Överväganden
- Du kan bara köra ett flöde åt gången. Körningen måste slutföras i Data Cloud innan du kan spara utdata igen.
- Det kan ta lite tid att spara ett flöde till Data Cloud. Kontrollera statusen i Data Cloud.
- Data sparas i Data Cloud med hjälp av Upsert-funktionen. Om en post i en fil matchar en befintlig post uppdateras den befintliga posten med värdena i dina data. Om ingen matchning hittas skapas posten som en ny enhet.
- För Prep Conductor uppdateras data inte om du schemalägger samma flöde att köras automatiskt. Det beror på att endast Upsert stöds.
- Du kan inte avbryta jobbet under tiden det sparas till Data Cloud.
- Det sker ingen kontroll av fält som sparas till Data Cloud. Kontrollera data i Data Cloud.
Konfigurationskrav för Data Cloud
De här stegen krävs för att spara Tableau Prep-flöden till Data Cloud. Du hittar detaljerad information om Data Cloud-koncept och datamappning mellan Tableau-datakällor och Data Cloud i Om Salesforce Data Cloud (på engelska).
Konfigurera en koppling för inhämtnings-API
Skapa en dataström för inhämtnings-API:et från källobjekten genom att ladda upp en schemafil i OpenAPI-format (OAS) med filtillägget .yaml. Schemafilen beskriver hur data från webbplatsen är strukturerade. Mer information finns i Exempel på YAML-fil och Ingestion API.
- Klicka på kugghjulsikonen för Setup (Konfiguration) och sedan på Data Cloud Setup (Konfiguration av Data Cloud).
- Klicka på Ingestion API (Inhämtnings-API).
- Klicka på New (Ny) och ange ett kopplingsnamn.
- På informationssidan för den nya kopplingen laddar du upp en schemafil i OpenAPI-format (OAS) med filtillägget
.yaml. Schemafilen beskriver hur data som överförs via API:t är strukturerade. - Klicka på Save (Spara) i formuläret Preview Schema (Förhandsgranska schema).
Obs! Scheman för inhämtnings-API:et har fastställda krav. Läs avsnittet Schemakrav innan inhämtning.
Skapa en dataström
Dataströmmar är en datakälla som hämtas till Data Cloud. De består av anslutningar och tillhörande data som hämtas till Data Cloud.
- Gå till App Launcher (Appstartaren) och välj Data Cloud.
- Klicka på fliken Data Streams (Dataströmmar).
- Klicka på New (Ny), välj Ingestion API (Inhämtnings-API) och klicka sedan Next (Nästa).
- Välj inhämtnings-API:et och objekten.
- Välj Data Space (Datautrymme), Category (Kategori) och Primary Key (Primärnyckel) och klicka sedan på Next (Nästa).
- Klicka på Deploy (Distribuera).
En äkta primärnyckel måste användas för Data Cloud. Om det inte finns någon måste du skapa ett formelfält för primärnyckeln.
För Category (Kategori) kan du välja mellan Profile (Profil), Engagement (Engagemang) eller Other (Annat). Ett datumtidsfält måste finnas för objekt som är avsedda för kategorin Engagement (Engagemang). Objekt av typen Profile (Profil) eller Other (Annat) har inte samma krav. Mer information finns i Kategori (på engelska) och Primärnyckel (på engelska).
Nu har du en dataström och ett datasjöobjekt. Du kan nu lägga till dataströmmen i ett datautrymme.

Lägga till en dataström i ett datautrymme
När du tar in data från en källa till Data Cloud kopplar du datasjöobjekten till det relevanta datautrymmet med eller utan filter.
- Klicka på fliken Data Spaces (Datautrymmen).
- Välj standarddatautrymmet eller namnet på det datautrymme som du tilldelats.
- Klicka på Add Data (Lägg till data).
- Välj det datasjöobjekt du skapade och klicka på Next (Nästa).
- (Valfritt)Välj filter för objektet.
- Klicka på Save (Spara).

Mappa datasjöobjektet till Salesforce-objekt
Datamappning relaterar fält för datasjöobjekt till fält för datamodellobjekt.
- Gå till fliken Data Stream (Dataström) och välj den dataström du skapade.

- Klicka på Start (Starta) i avsnittet Data Mapping (Datamappning).
På arbetsytan för fältmappning ser du källdatasjöobjekten till vänster och måldatamodellobjekten till höger. Mer information finns i Mappa datamodellobjekt (på engelska).
Skapa ett externt klientprogram eller anslutet program för Data Cloud Ingestion API
Innan du kan skicka data till Data Cloud med inhämtnings-API:et måste du konfigurera Salesforce för användning av ett externt klientprogram eller ett anslutet program. Mer information finns i följande avsnitt i Salesforce-hjälpen:
För externa klientprogram: Configure the External Client App OAuth Settings(Länken öppnas i ett nytt fönster) och Create an External Client App(Länken öppnas i ett nytt fönster)
För anslutna program: Enable OAuth Settings for API Integration och Create a connected App for Data Cloud Ingestion API
Som en del av konfigurationen av ditt externa klientprogram eller anslutna program för inhämtnings-API:et måste du välja följande OAuth-omfattningar:
- Komma åt och hantera data för inhämtnings-API:et för Data Cloud (cdp_ingest_api)
- Hantera Data Cloud-profildata (cdp_profile_api)
- Köra ANSI SQL-frågor på Data Cloud-data (cdp_query_api)
- Hantera användardata via API:er (api)
- Utföra förfrågningar å dina vägnar när som helst (refresh_token, offline_access)
Schemakrav
För att kunna skapa en källa för inhämtnings-API:et i Data Cloud måste den schemafil du laddar upp uppfylla vissa krav. Mer information finns i Krav för scheman för inhämtnings-API (på engelska).
- Uppladdade scheman måste ha ett giltigt OpenAPI-format med tillägget .yml eller .yaml. OpenAPI version 3.0.x stöds.
- Objekt får inte ha kapslade objekt.
- Varje schema måste ha minst ett objekt. Varje objekt måste ha minst ett fält.
- Objekt får inte ha fler än 1 000 fält.
- Objektnamn får inte vara längre än 80 tecken.
- Objektnamn får bara innehålla a-ö, A-Ö, 0–9, _, -. Inga Unicode-tecken.
- Fältnamn får bara innehålla a-ö, A-Ö, 0–9, _, -. Inga Unicode-tecken.
- Fältnamn får inte vara något av dessa reserverade ord: date_id, location_id, dat_account_currency, dat_exchange_rate, pacing_period, pacing_end_date, row_count, version. Fältnamn får inte innehålla strängen __.
- Fältnamn får inte överstiga 80 tecken.
- Fält måste uppfylla följande krav på typ och format:
- För text eller boolesk typ: sträng
- För nummertyp: nummer
- För datumtyp: sträng; format: datum-tid
- Objektnamn får inte dupliceras och de är inte skiftlägeskänsliga.
- Objekt får inte ha duplicerade fältnamn och de är inte skiftlägeskänsliga.
- DateTime-datatypfält i nyttolaster måste vara ISO 8601 UTC Zulu med formatet yyyy-MM-dd’T’HH:mm:ss.SSS’Z'.
När du uppdaterar schemat ska du vara medveten om följande:
- Befintliga fältdatatyper kan inte ändras.
- När ett objekt uppdateras måste alla befintliga fält för det objektet finnas.
- Den uppdaterade schemafilen innehåller bara ändrade objekt, så du behöver inte ha en heltäckande lista över alla objekt varje gång.
- Ett datumtidsfält måste finnas för objekt som är avsedda för kategorin Engagement (Engagemang). Objekt av typen
profileellerotherhar inte samma krav.
Exempel på YAML-fil
openapi: 3.0.3
components:
schemas:
owner:
type: object
required:
- id
- name
- region
- createddate
properties:
id:
type: integer
format: int64
name:
type: string
maxLength: 50
region:
type: string
maxLength: 50
createddate:
type: string
format: date-time
car:
type: object
required:
- car_id
- color
- createddate
properties:
car_id:
type: integer
format: int64
color:
type: string
maxLength: 50
createddate:
type: string
format: date-time Spara flödesutdata till Amazon S3
Finns i Tableau Prep Builder 2024.2 och senare samt i Webbredigering och Tableau Cloud. Den här funktionen finns inte i Tableau Server än.
Du kan ansluta till data från alla kopplingar som Tableau Prep Builder eller webben har stöd för och spara flödesutdata som en .parquet- eller .csv-fil till Amazon S3. Utdata kan sparas som nya data eller så kan du skriva över befintliga S3-data. För att förhindra dataförlust kan du använda alternativet Anpassad SQL för att göra en kopia av tabelldata och köra den innan du sparar flödesdata till S3.
Att spara flödesutdata och ansluta till S3-kopplingen är två skilda saker. Du kan inte återanvända en befintlig S3-anslutning som du använt som en Tableau Prep-indataanslutning.
Det finns ingen gräns för den totala datavolymen och antalet objekt du kan lagra i Amazon S3. Enskilda Amazon S3-objekt kan variera i storlek från som minst 0 byte till högst 5 TB. Det största objekt som kan laddas upp i en enda PUT-åtgärd är 5 GB. För objekt som är större än 100 MB bör kunder överväga att använda uppdelad uppladdning. Läs mer i Ladda upp och kopiera objekt med uppdelad uppladdning (på engelska).
Behörigheter
Om du vill skriva till Amazon S3-bucketen behöver du känna till bucketregionen, bucketnamnet, ID:t för åtkomstnyckeln och den hemliga åtkomstnyckeln. För att få de här nycklarna måste du skapa en IAM-användare (Identity and Access Management) inom AWS. Läs mer i Hantera åtkomstnycklar för IAM-användare (på engelska).
Spara flödesdata till Amazon S3
- Klicka på plusikonen i ett steg och välj Lägg till utdata.
- Välj Databas och molnlagring i listrutan Spara utdata till.
- I avsnittet Tabell > Anslutning väljer du Amazon S3 (endast utdata).
- I formuläret Amazon S3 (endast utdata) lägger du till följande information:
- ID för åtkomstnyckel: Det nyckel-ID som du använde för att signera förfrågningarna till Amazon S3.
- Hemlig åtkomstnyckel: Säkerhetsuppgifter (lösenord, åtkomstnycklar) som används för att verifiera att du har behörighet att komma åt AWS-resursen.
- Bucketregion: Amazon S3-bucketplatsen (regional AWS-slutpunkt). Till exempel: us-east-2.
- Bucketnamn: Namnet på den S3-bucket du vill skriva flödesutdata till. Två AWS-konton i samma region kan inte ha samma bucketnamn.
Obs! Om du vill ta reda på din S3-region och ditt bucketnamn loggar du in på ditt AWS S3-konto och går till AWS S3-konsolen.
- Klicka på Logga in.
- I URI-fältet i S3 anger du namnet på
.csv- eller.parquet-filen. Som standard är fältet ifyllt meds3://<your_bucket_name>. Filnamnet måste ha filtillägget.csveller.parquet.Du kan spara flödesutdata som ett nytt S3-objekt eller skriva över ett befintligt S3-objekt.
- För ett nytt S3-objekt skriver du namnet på
.parquet- eller.csv-filen. URI:n visas i förhandsgranskningstexten. Exempel:s3://<bucket_name><name_file.csv>. - Om du vill skriva över ett befintligt S3-objekt skriver du namnet på
.parquet- eller.csv-filen eller klickar på Bläddra för att hitta befintliga.parquet- eller.csv-filer i S3.Obs! Fönstret Bläddra bland objekt visar bara filer som har sparats vid tidigare inloggningar till Amazon S3.
- För ett nytt S3-objekt skriver du namnet på
- För Skrivalternativ skapas ett nytt S3-objekt med data från ditt flöde. Om data redan finns tas alla befintliga datastrukturer eller egenskaper som definierats för objektet bort och ersätts med nya flödesdata. Alla fält som finns i flödet läggs till i det nya S3-objektet.
- Klicka på Kör flöde för att köra flödet och skriva data till S3.
Du kan verifiera att data sparades till S3 genom att logga in på ditt AWS S3-konto och gå till AWS S3-konsolen.