Salvar e compartilhar seu trabalho
A partir de 14 de outubro de 2025, o Data Cloud foi renomeado como Data 360. Durante essa transição, você pode ver referências a Data Cloud em nosso aplicativo e documentação. Embora o nome seja novo, a funcionalidade e o conteúdo permanecem inalterados.
Em qualquer ponto do fluxo, você pode salvar o trabalho manualmente ou deixar que o Tableau o faça automaticamente ao criar ou editar fluxos na Web. Existem algumas diferenças quando você trabalha com fluxos na Web.
Para obter mais informações sobre os fluxos de criação na Web, consulte Tableau Prep na Web na ajuda do Tableau Server(O link abre em nova janela) e Tableau Cloud(O link abre em nova janela).
| Tableau Prep Builder | Tableau Prep na Web |
|---|---|
|
|
Para manter os dados atualizados, você pode executar os fluxos manualmente no Tableau Prep Builder ou na linha de comando. Você também pode executar os fluxos publicados no Tableau Server ou no Tableau Cloud manualmente ou de acordo com a agenda. Para obter mais informações sobre a execução de fluxos, consulte Publicar um fluxo no Tableau Server ou Tableau Cloud.
Salvar um fluxo
No Tableau Prep Builder, você pode salvar o fluxo manualmente para fazer um backup de seu trabalho antes de executar qualquer operação adicional. Seu fluxo está salvo no formato de arquivo de fluxo (.tfl) do Tableau Prep.
Além disso, é possível empacotar os arquivos locais (Excel, arquivos de texto e extrações do Tableau) junto com o fluxo para compartilhar com terceiros, da mesma forma que se empacota uma pasta de trabalho para compartilhamento no Tableau Desktop. Apenas arquivos locais podem ser empacotados com um fluxo. Os dados de conexões de banco de dados, por exemplo, não são incluídos.
Na criação na Web, os arquivos locais são empacotados automaticamente com o nosso fluxo. As conexões diretas de arquivos ainda não são compatíveis.
Ao salvar o fluxo empacotado, ele é salvo como um Arquivo de fluxo empacotado do Tableau (.tflx).
- Para salvar seu fluxo manualmente, no menu superior, selecione Arquivo > Salvar.
- No Tableau Prep Builder, para empacotar os arquivos de dados com o fluxo, no menu superior, execute uma das ações a seguir:
- Selecione Arquivo > Exportar fluxo empacotado
- Selecione Arquivo > Salvar como. Em seguida, na caixa de diálogo Salvar como, selecione Arquivos de fluxo empacotados do Tableau no menu suspenso Salvar como tipo.
Salvar os fluxos automaticamente na Web
Se você criar ou editar fluxos na Web, quando você fizer uma alteração no fluxo (conecte-se a uma fonte de dados, adicione uma etapa e assim por diante), o trabalho será salvo automaticamente em um intervalo de poucos segundos como rascunho para que você não o perca.
Você só pode salvar os fluxos no servidor em que está conectado no momento. Você não pode criar um fluxo de rascunho em um servidor e tentar salvá-lo ou publicá-lo em outro. Se você quiser publicar o fluxo para um projeto diferente no servidor, use a opção do menu Arquivo > Publicar como e selecione o projeto na caixa de diálogo.
Você só pode ver os fluxos de rascunho até publicá-los e disponibilizá-los para qualquer usuário que tenha permissões para acessar o projeto no servidor. Os fluxos no status de rascunho são marcados com o selo Rascunho para que você possa encontrar facilmente os fluxos em andamento. Se o fluxo nunca foi publicado, o selo Nunca publicado será mostrado ao lado do selo Rascunho.

Após a publicação do fluxo, quando você o edita e publica fluxo novamente, outra versão é criada. Você pode ver uma lista das versões de fluxo na caixa de diálogo Histórico de revisões. Na página Explorar, clique no menu ![]() Ações e selecione Histórico de revisões.
Ações e selecione Histórico de revisões.
Para obter mais informações sobre o gerenciamento do histórico de revisões, consulte Trabalhar com revisões de conteúdo(O link abre em nova janela) na Ajuda do Desktop do Tableau.
Observação: o salvamento automático é ativado por padrão. Os administradores podem desativar o salvamento automático em um site, mas não é recomendado. Desative o salvamento automático, use o método de "Atualizar site" da API REST do Tableau Server e defina o atributo flowAutoSaveEnabled como false. Para obter mais informações, consulte Métodos de site da API REST do Tableau Server: site de atualização(O link abre em nova janela).
Recuperação automática de arquivos
Por padrão, o Tableau Prep Builder salvará automaticamente um rascunho dos fluxos abertos se o aplicativo travar ou falhar. Os fluxos de rascunho são salvos na pasta Fluxos recuperados em Meu repositório do Tableau Prep. Da próxima vez que você abrir o aplicativo, uma caixa de diálogo será mostrada com uma lista dos fluxos recuperados para você selecionar. Você poderá abrir um fluxo recuperado e continuar de onde parou ou excluir o arquivo de fluxo recuperado se não precisar dele.
Observação: se você recuperou fluxos na pasta Fluxos recuperados, esta caixa de diálogo será exibida sempre que você abrir o aplicativo até que a pasta esteja vazia.

Se não quiser que esse recurso seja habilitado, como Administrador, você poderá desativá-lo durante ou após a instalação. Para obter mais informações sobre como desativar este recurso, consulte Desativar recuperação de arquivos(O link abre em nova janela) no guia de implantação do Tableau Desktop e do Tableau Prep.
Recuperar fluxos excluídos
Com suporte na criação na Web do Tableau Prep no Tableau Cloud e no Tableau Server versão 2025.3 e posterior.
Na criação na Web, você pode recuperar fluxos excluídos anteriormente da Lixeira. Se a Lixeira estiver ativada, em vez de serem excluídos permanentemente, os fluxos serão movidos temporariamente para a lixeira, onde você poderá recuperá-los ou excluí-los de forma permanente. Os fluxos em estado de rascunho ainda são excluídos permanentemente. Para obter mais informações a Lixeira, consulte Lixeira(O link abre em nova janela).
Observação: este recurso não está disponível no Tableau Prep Builder.
Para utilizar esta funcionalidade, é necessário o seguinte:
Permissões: você deve receber a função de Administrador de site, Administrador de servidor, Creator ou Explorer (pode publicar).
Configuração do site: a lixeira está ativada para seu site
Status do fluxo: o fluxo deve ser publicado.
O período de tempo em que os fluxos são armazenados na Lixeira é definido pelo administrador.
Recuperar um fluxo
Na página inicial, expanda o painel lateral e selecione Lixeira.
Na página Lixeira, selecione Fluxos na lista suspensa Tipo de conteúdo.
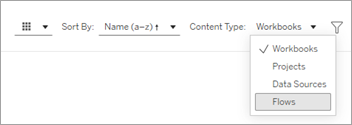
Selecione o menu Mais ações para o fluxo que você deseja restaurar e, em seguida, selecione Restaurar.
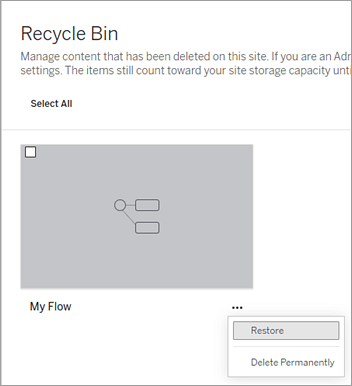
Selecione um projeto como local de restauração.
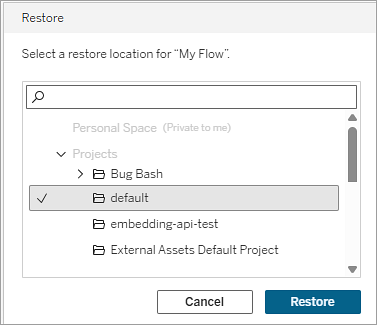
Selecione Restaurar.
Exibir saída de fluxo no Tableau Desktop
Observação: esta opção não está disponível na Web.
Às vezes, ao limpar seus dados, você pode querer verificar o andamento olhando no Tableau Desktop. Quando o fluxo é aberto no Tableau Desktop, o Tableau Prep Builder cria um arquivo .hyper permanente do Tableau ou um arquivo (.tds) de fonte de dados do Tableau. Esses arquivos são salvos no repositório do Tableau, no arquivo Fontes de dados, para que você possa usar os dados a qualquer momento.
Ao abrir o fluxo no Tableau Desktop, você pode ver a amostra de dados com a estiver trabalhando no fluxo com as operações aplicadas a ela, até a etapa selecionada.
Observação: embora você possa experimentar seus dados, o Tableau mostra apenas uma amostra dos dados e você não poderá salvar a pasta de trabalho como uma pasta de trabalho em pacote (.twbx). Quando estiver pronto para trabalhar com seus dados no Tableau, crie uma etapa de saída para seu fluxo e salve a saída em um arquivo ou como uma fonte de dados publicada, então conecte a fonte de dados completa no Tableau.
Para exibir a amostra de dados no Tableau Desktop, faça o seguinte:
- Clique com o botão direito do mouse na etapa que deseja exibir os dados e selecione Visualizar no Tableau Desktop no menu de contexto.

- O Tableau Desktop é aberto na guia Planilha.
Criar arquivos de extração de dados e fontes de dados publicadas
Para criar a saída de fluxo, execute o fluxo. Ao executar o fluxo, suas alterações são aplicadas a todo o conjunto de dados. Executar o fluxo resulta em um arquivo de fonte de dados do Tableau (.tds) e extração de dados do Tableau (.hyper).
Observação: fluxos que incluem dados espaciais só podem ser gerados para arquivos .hyper ou como uma fonte de dados publicada. Outros tipos de saída não são compatíveis no momento. Para obter mais informações sobre como trabalhar com dados espaciais, consulte Criar cálculos espaciais e uniões de colunas.(O link abre em nova janela)
Tableau Prep Builder
É possível criar um arquivo de extração da saída do fluxo para usar no Tableau Desktop ou para compartilhar os dados com terceiros. Criar um arquivo de extração nos formatos a seguir:
- Extração Hyper (.hyper): este é o tipo de arquivo de extração mais recente do Tableau.
- Valor separado por vírgula (.csv): salve a extração em um arquivo .csv para compartilhar os dados com terceiros. A codificação do arquivo CSV o exportado será UTF-8 com o BOM.
- Microsoft Excel (.xlsx): Uma planilha do Microsoft Excel.
Tableau Prep Builder e na Web
Publique sua saída de fluxo como uma fonte de dados publicada ou saída para um banco de dados.
- Salve sua saída de fluxo como uma fonte de dados no Tableau Server ou Tableau Cloud para compartilhar seus dados e fornecer acesso centralizado aos dados que você limpou, formatou e combinou.
- Salve sua saída de fluxo em um banco de dados para criar, substituir ou anexar os dados da tabela com seus dados de fluxo limpos e preparados. Para obter mais informações, consulte Salvar dados de saída de fluxo em bancos de dados externos.
Use a atualização incremental ao executar seu fluxo para economizar tempo e recursos atualizando apenas novos dados em vez de seu conjunto de dados completo. Para obter informações sobre como configurar e executar o fluxo usando a atualização incremental, consulte Atualizar dados de fluxo usando a atualização incremental.
Observação: para publicar a saída do Tableau Prep Builder no Tableau Server, a API REST do Tableau Server deve estar habilitada. Para obter mais informações consulte Requisitos da REST API(O link abre em nova janela) na Ajuda da REST API do Tableau . Para publicar em um servidor que usa certificados de criptografia Secure Socket Layer (SSL), são necessárias etapas de configuração adicionais no computador que executa o Tableau Prep Builder. Para obter mais informações, consulte Antes da instalação(O link abre em nova janela) no Guia de implantação do Tableau Desktop e Tableau Prep Builder.
Incluir parâmetros em sua saída de fluxo
Com suporte no Tableau Prep Builder e na Web a partir da versão 2021.4
Inclua valores de parâmetro em seus nomes de arquivo de saída de fluxo, caminhos, nomes de tabela ou scripts SQL personalizados (versão 2022.1.1 e posterior) para executar facilmente seus fluxos para diferentes conjuntos de dados. Para obter mais informações, consulte Criar e usar parâmetros em fluxos.
Criar uma extração para um arquivo
Observação: esta opção de saída não está disponível ao criar ou editar fluxos na Web.
- Clique no ícone de adição
 em uma etapa e selecione Adicionar saída.
em uma etapa e selecione Adicionar saída.Se já tiver executado o fluxo anteriormente, clique no botão de executar fluxo
 na etapa de saída. Isso executa o fluxo e atualiza a saída.
na etapa de saída. Isso executa o fluxo e atualiza a saída.O painel de Saída é aberto e mostra um instantâneo de seus dados.

- No painel esquerdo, selecione Arquivo na lista suspensa Salvar saída no. Nas versões anteriores, selecione Salvar no arquivo.
- Clique no botão Procurar, depois, na caixa de diálogo Salvar extração como, insira um nome para o arquivo e clique em Aceitar.
- No campo Tipo de saída, selecione um destes tipos de saída:
- Extração de dados do Tableau (.hyper)
- Valores separados por vírgula (.csv)
(Tableau Prep Builder) Na seção Opções de gravação, veja a opção de gravação padrão para gravar os novos dados nos arquivos e faça alterações conforme necessário. Para obter mais informações, consulte Configurar opções de gravação.
- Criar tabela: esta opção cria uma nova tabela ou substitui a tabela existente pela nova saída.
- Anexar à tabela: esta opção adiciona os novos dados à tabela existente. Se a tabela ainda não existir, uma nova tabela será criada e as execuções subsequentes adicionarão novas linhas a ela.
Observação: a opção Anexar à tabela não é compatível com os tipos de saída .csv. Para obter mais informações sobre as combinações de atualização compatíveis, consulte Opções de atualização de fluxo.
- Clique em Executar fluxo para executar o fluxo e gerar o arquivo de extração.
Criar uma extração para uma planilha do Microsoft Excel
Com suporte no Tableau Prep Builder versão 2021.1.2 e posteriores. Essa opção de saída não está disponível ao criar ou editar fluxos na Web ou ao criar saídas para fluxos que incluem dados espaciais.
Quando você produz dados de fluxo para uma planilha do Microsoft Excel, pode criar uma nova planilha ou anexar ou substituir dados em uma planilha existente. Aplicam-se as seguintes condições:
- Apenas os formatos de arquivos .xlsx do Microsoft Excel são aceitos.
- As linhas da planilha começam na célula A1.
- Ao anexar ou substituir dados, pressupõe-se que a primeira linha seja cabeçalhos.
- Os nomes do cabeçalho são adicionados ao criar uma nova planilha, mas não ao adicionar dados a uma planilha existente.
- Qualquer formatação ou fórmulas nas planilhas existentes não são aplicadas à saída de fluxo.
- Gravar para tabelas ou intervalos nomeados não é aceito no momento.
- A atualização incremental não é aceita atualmente.
Dados de fluxo de saída para um arquivo de planilha do Microsoft Excel
- Clique no ícone de adição em uma etapa e selecione Adicionar saída.
Se já tiver executado o fluxo anteriormente, clique no botão de executar fluxo
na etapa de saída. Isso executa o fluxo e atualiza a saída.O painel de Saída é aberto e mostra um instantâneo de seus dados.

- No painel esquerdo, selecione Arquivo na lista suspensa Salvar saída no.
- Clique no botão Procurar, depois, na caixa de diálogo Salvar extração como, insira ou selecione o nome de arquivo e clique em Aceitar.
- No campo Tipo de saída, selecione Microsoft Excel (.xlsx).

- No campo Planilha, selecione a planilha para a qual deseja gravar seus resultados ou digite um novo nome no campo e clique em Criar nova tabela.
- Na configuração Opções de gravação, selecione uma das seguintes opções:
- Criar tabela: cria ou recria (se o arquivo já existir) a planilha com os dados de fluxo.
- Anexar à tabela: adiciona novas linhas a uma planilha existente. Se a planilha não existir, uma é criada e as execuções de fluxo subsequentes adicionam linhas a essa planilha.
- Substituir os dados: substitui todos os dados, exceto a primeira linha em uma planilha existente pelos dados de fluxo.
Uma comparação de campo mostra os campos no fluxo que correspondem aos campos na planilha, caso a planilha já exista. Se a planilha for nova, será exibida uma correspondência de campo de um para um. Todos os campos que não correspondem são ignorados.

- Clique em Executar fluxo para executar o fluxo e gerar o arquivo de extração do Microsoft Excel.
Criar uma fonte de dados publicada
- Clique no ícone de adição em uma etapa e selecione Adicionar saída.
Observação: o Tableau Prep Builder atualiza fontes de dados publicadas anteriormente e mantém, a modelagem de dados (por exemplo, campos calculados, formatação de números e assim por diante) que possam ser incluídos na fonte de dados. Se a fonte de dados não puder ser atualizada, a fonte de dados, incluindo a modelagem de dados, será substituída.
- O painel de saída é aberto e mostra um instantâneo de seus dados.

- Na lista suspensa Salvar saída em, selecione Fonte de dados publicada (Publicar como fonte de dados em versões anteriores). Preencha os campos a seguir:
- Servidor (somente para o Tableau Prep Builder): selecione o servidor onde deseja publicar a fonte de dados e a extração de dados. Se não estiver logado a um servidor você será solicitado a entrar.
Observação: a partir do Tableau Prep Builder versão 2020.1.4, depois de entrar no servidor, Tableau Prep Builderlembra o nome do servidor e as credenciais quando você fecha o aplicativo. Na próxima vez que você abrir o aplicativo, já estará conectado ao seu servidor.
No Mac, você pode ser solicitado a fornecer acesso às chaves do Mac para que o Tableau Prep Builder possa usar certificados SSL com segurança para se conectar ao ambiente do Tableau Server ou do Tableau Cloud.
Se você estiver enviando para o Tableau Cloud, inclua o pod onde seu site está hospedado no "serverUrl". Por exemplo, "https://eu-west-1a.online.tableau.com”, não "https://online.tableau.com".
- Projeto: selecione o projeto onde deseja carregar a fonte de dados e a extração.
- Nome: insira um nome de arquivo.
- Descrição: insira uma descrição para a fonte de dados.
- Servidor (somente para o Tableau Prep Builder): selecione o servidor onde deseja publicar a fonte de dados e a extração de dados. Se não estiver logado a um servidor você será solicitado a entrar.
- (Tableau Prep Builder) Na seção Opções de gravação, veja a opção de gravação padrão para gravar os novos dados nos arquivos e faça alterações conforme necessário. Para obter mais informações, consulte Configurar opções de gravação
- Criar tabela: esta opção cria uma nova tabela ou substitui a tabela existente pela nova saída.
- Anexar à tabela: esta opção adiciona os novos dados à tabela existente. Se a tabela ainda não existir, uma nova tabela será criada e as execuções subsequentes adicionarão novas linhas a ela.
- Clique em Executar fluxo para executar o fluxo e publicar a fonte de dados.
Salvar dados de saída de fluxo em bancos de dados externos
Esta opção de saída não está disponível ao criar saída para fluxos que incluem dados espaciais.
Importante: este recurso permite excluir permanentemente e substituir os dados em um banco de dados externo. Verifique se você tem permissões para gravar no banco de dados.
Para evitar a perda de dados, você pode usar a opção SQL personalizado para fazer uma cópia dos dados da sua tabela e executá-los antes de gravar os dados de fluxo na tabela.
Você pode se conectar a dados de qualquer um dos conectores que o Tableau Prep Builder ou a Web permite e enviar dados para um banco de dados externo. Isso permite adicionar ou atualizar dados em seu banco de dados com dados limpos e preparados do seu fluxo toda vez que o fluxo é executado. Este recurso está disponível para opções de atualização incremental e completa, salvo indicação em contrário. Para obter mais informações sobre como configurar a atualização incremental, consulte Atualizar dados de fluxo usando a atualização incremental.
Quando você salva sua saída de fluxo em um banco de dados externo, o Tableau Prep faz o seguinte:
- Gera as linhas e executa os comandos SQL no banco de dados.
- Grava os dados em uma tabela temporária (ou área de preparação se for para Snowflake) no banco de dados de saída.
- Se a operação for bem-sucedida, os dados serão movidos da tabela temporária (ou da área de preparação para Snowflake) para a tabela de destino.
- Executa todos os comandos SQL que você deseja executar depois de gravar os dados no banco de dados.
Se o script SQL falhar, o fluxo também terá erros. No entanto, seus dados ainda serão carregados em suas tabelas de banco de dados. Você pode tentar executar o fluxo mais uma vez ou executar manualmente seu script SQL em seu banco de dados para aplicá-lo.
Opções de saída
Você pode selecionar as seguintes opções ao gravar dados em um banco de dados. Se a tabela ainda não existir, ela será criada quando o fluxo for executado pela primeira vez.
- Anexar à tabela: esta opção adiciona dados a uma tabela existente. Se a tabela não existir, será criada quando o fluxo for executado pela primeira vez e os dados serão adicionados a essa tabela a cada fluxo subsequente executado.
- Criar tabela: esta opção cria uma nova tabela com os dados do seu fluxo. Se a tabela já existir, a tabela e qualquer estrutura de dados existente ou propriedades existentes definidas para a tabela serão excluídas e substituídas por uma nova tabela que usa a estrutura de dados de fluxo. Todos os campos existentes no fluxo são adicionados à nova tabela de banco de dados.
- Substituir dados: esta opção exclui os dados da tabela existente e os substitui pelos dados do seu fluxo, mas preserva a estrutura e as propriedades da tabela do banco de dados. Se a tabela não existir, a tabela será criada quando o fluxo for executado pela primeira vez e os dados da tabela forem substituídos por cada fluxo subsequente executado.
Opções adicionais
Além das opções de gravação, você também pode incluir scripts de SQL personalizado ou adicionar uma nova tabela ao seu banco de dados.
- Scripts de SQL personalizados: insira seu SQL personalizado e selecione se deseja executar seu script antes, depois ou antes e depois que os dados forem gravados nas tabelas do banco de dados. Você pode usar esses scripts para criar uma cópia de sua tabela de banco de dados antes que os dados de fluxo sejam gravados na tabela, adicionar um índice, adicionar outras propriedades de tabela e assim por diante.
Observação: a partir da versão 2022.1.1, você também pode inserir parâmetros em seus scripts SQL. Para obter mais informações, consulte Aplicar parâmetros de usuário às etapas de saída.
- Adicionar uma nova tabela: adicione uma nova tabela com um nome exclusivo ao banco de dados em vez de selecionar uma na lista de tabelas existente. Se você quiser aplicar um esquema diferente do esquema padrão (Microsoft SQL Server e PostgreSQL), poderá especificá-lo usando a sintaxe
[schema name].[table name].
Bancos de dados compatíveis e requisitos de bancos de dados
O Tableau Prep permite a gravação de dados de fluxo em tabelas em um número específico de bancos de dados. Os fluxos executados em uma agenda no Tableau Cloud só poderão ser gravados nesses bancos de dados se estiverem hospedados na nuvem.
Se você se conectar a fontes de dados locais, a partir da versão 2025.1, poderá usar um cliente do Tableau Bridge para se conectar e atualizar seus dados no Tableau Cloud. Isso requer um cliente Tableau Bridge configurado em um pool de clientes Bridge, com o domínio adicionado ao Lista de permissões de rede privada. No Tableau Prep Builder e na Web, ao se conectar à sua fonte de dados, certifique-se de que a URL do servidor corresponda ao domínio no pool de ponte. Para obter mais informações, consulte "Bancos de dados" na seção Tableau Cloud em Publicar um fluxo do Tableau Prep Builder(O link abre em nova janela).
Alguns bancos de dados têm restrições de dados ou requisitos. O Tableau Prep também pode impor alguns limites para manter o alto desempenho ao gravar dados nos bancos de dados compatíveis. A tabela a seguir lista os bancos de dados onde você pode salvar seus dados de fluxo e quaisquer restrições ou requisitos de banco de dados. Os dados que não atendem a esses requisitos podem resultar em erros na execução do fluxo.
Observação: ainda não há suporte para definir limites de caracteres para os campos. No entanto, você pode criar as tabelas em seu banco de dados que incluem restrições de limite de caracteres e, em seguida, usar a opção Substituir dados para substituir seus dados, mas manter a estrutura da tabela no banco de dados.
| Banco de dados | Requisitos ou restrições |
|---|---|
| Amazon Redshift |
|
| Amazon S3 (somente saída) | Salvar dados de saída de fluxo no Amazon S3 |
| Databricks |
|
| Google BigQuery |
|
| Microsoft SQL Server |
|
| MySQL |
|
| Oracle |
|
| Pivotal Greenplum Database |
|
| PostgreSQL |
|
| SAP HANA |
|
| Snowflake |
|
| Teradata |
|
| Vertica |
|
Salvar dados de fluxo em um banco de dados
Observação: você pode inserir suas credenciais no banco de dados ao publicar o fluxo. Para obter mais informações sobre como inserir credenciais, consulte a seção Bancos de dados em Publicar um fluxo no Tableau Prep Builder.
- Clique no ícone de adição em uma etapa e selecione Adicionar saída.
- Na lista suspensa Salvar saída, selecione Banco de dados e Armazenamento na nuvem.
- Na guia Configurações, insira estas informações:
- Na lista suspensa Conexão, selecione o conector de banco de dados onde deseja gravar a saída de fluxo. São exibidos apenas os conectores compatíveis. Este pode ser o mesmo conector que você usou para sua entrada de fluxo ou um conector diferente. Se você selecionar um conector diferente, será solicitado a fazer logon.
Importante: certifique-se de ter permissão de gravação para o banco de dados selecionado. Caso contrário, o fluxo só poderá processar parcialmente os dados.
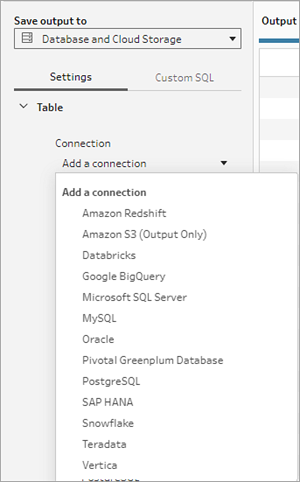
- Na lista suspensa Banco de dados, selecione o banco de dados onde você deseja salvar os dados de saída de fluxo. Os esquemas ou bancos de dados devem ter pelo menos uma tabela para ficarem visíveis na lista suspensa.
- Na lista suspensa Tabela, selecione a tabela onde você deseja salvar os dados de saída de fluxo. Dependendo da opção de gravação selecionada, uma nova tabela será criada, os dados de fluxo substituirão os dados existentes na tabela ou os dados de fluxo serão adicionados à tabela existente.
Para criar uma nova tabela no banco de dados, digite um nome de tabela exclusivo no campo e clique em Criar nova tabela. Quando você executa o fluxo pela primeira vez, independentemente da opção de gravação selecionada, a tabela é criada no banco de dados usando o mesmo esquema que o fluxo.

- Na lista suspensa Conexão, selecione o conector de banco de dados onde deseja gravar a saída de fluxo. São exibidos apenas os conectores compatíveis. Este pode ser o mesmo conector que você usou para sua entrada de fluxo ou um conector diferente. Se você selecionar um conector diferente, será solicitado a fazer logon.
- O painel de saída mostra um instantâneo de seus dados. Uma comparação de campo mostra os campos no fluxo que correspondem aos campos na tabela, caso a tabela já exista. Se a tabela for nova, será exibida uma correspondência de campo de um para um.

Caso existam incompatibilidades de campo, uma nota de status mostra os erros.
- Sem correspondência: campo ignorado: os campos existem no fluxo, mas não no banco de dados. O campo não será adicionado à tabela de banco de dados, a menos que você selecione a opção de gravação Criar tabela e execute uma atualização completa. Em seguida, os campos de fluxo são adicionados à tabela de banco de dados e usam o esquema de saída de fluxo.
- Sem correspondência: o campo conterá valores nulos: os campos existem no banco de dados, mas não no fluxo. O fluxo passa um valor nulo para a tabela de banco de dados no campo. Se o campo existir no fluxo, mas for incompatível porque o nome de campo é diferente, você poderá navegar até uma etapa de limpeza e editar o nome de campo para corresponder ao nome de campo do banco de dados. Para obter informações sobre como editar o nome de campo, consulte Aplicar operações de limpeza.
- Erro: os tipos de dados de campo não correspondem: os tipos de dados atribuídos a um campo, tanto no fluxo quanto na tabela do banco de dados em que você está gravando sua saída, devem corresponder; caso contrário, o fluxo falhará. Você pode navegar até uma etapa de limpeza e editar o tipo de dados de campo para corrigir isso. Para obter mais informações sobre a mudança de tipos de dados, consulte Consultar os tipos de dados atribuídos aos seus dados.
- Selecione uma opção de gravação. Você pode selecionar uma opção diferente para atualização completa e incremental, e a opção é aplicada quando você seleciona seu método de execução de fluxo. Para obter mais informações sobre a execução do nosso fluxo usando a atualização incremental, consulte Atualizar dados de fluxo usando a atualização incremental.
- Anexar à tabela: esta opção adiciona dados a uma tabela existente. Se a tabela não existir, será criada quando o fluxo for executado pela primeira vez e os dados serão adicionados a essa tabela a cada fluxo subsequente executado.
- Criar tabela: esta opção cria uma nova tabela. Se a tabela com o mesmo nome já existir, a tabela existente será excluída e substituída pela nova tabela. Qualquer estrutura de dados existente ou propriedades definidas para a tabela também são excluídas e substituídas pela estrutura de dados de fluxo. Todos os campos existentes no fluxo são adicionados à nova tabela de banco de dados.
- Substituir dados: esta opção exclui os dados da tabela existente e os substitui pelos dados do seu fluxo, mas preserva a estrutura e as propriedades da tabela do banco de dados.
- (opcional) Clique na guia SQL personalizado e insira seu script de SQL. Você pode inserir um script para executar Antes e Depois de os dados serem gravados na tabela.

- Clique em Executar fluxo para executar o fluxo e gravar seus dados no banco de dados selecionado.
Salvar dados de saída de fluxo em conjuntos de dados no CRM Analytics
Com suporte no Tableau Prep Builder e na Web a partir da versão 2022.3
Observação: o CRM Analytics tem vários requisitos e algumas limitações ao integrar dados de fontes externas. Para garantir que você possa gravar com êxito sua saída de fluxo no CRM Analytics, consulte Considerações antes de integrar dados em conjuntos de dados(O link abre em nova janela) na ajuda do Salesforce.
Limpe seus dados usando o Tableau Prep e obtenha melhores resultados de previsão no CRM Analytics. Basta conectar aos dados de qualquer um dos conectores que o Tableau Prep Builder ou Tableau Prep na Web oferece suporte. Em seguida, aplique transformações para limpar seus dados e enviar seus dados de fluxo diretamente para conjuntos de dados no CRM Analytics aos quais você tem acesso.
Os fluxos que geram dados para o CRM Analytics não podem ser executados usando a interface de linha de comando. Você pode executar fluxos manualmente usando o Tableau Prep Builder ou um agendamento na Web com o Tableau Prep Conductor.
Pré-requisitos
Para enviar dados de fluxo para o CRM Analytics, verifique se você tem as seguintes licenças, acesso e permissões no Salesforce e no Tableau.
Requisitos do Salesforce
| requisito | description |
|---|---|
| Permissões do Salesforce | Você deve estar designado para a licença CRM Analytics Plus ou CRM Analytics Growth. A licença CRM Analytics Plus inclui os conjuntos de permissões:
A licença CRM Analytics Plus inclui os conjuntos de permissões:
Para obter mais informações, consulte Saiba mais sobre licenças e conjuntos de atribuir usuários permissões do CRM Analytics(O link abre em nova janela) e Selecionar e atribuir conjuntos de permissões do usuário(O link abre em nova janela) na ajuda do Salesforce. |
Configurações do administrador | Os administradores da Salesforce precisarão configurar:
|
Requisitos do Tableau Prep
| requisito | description |
|---|---|
Licença e permissões do Tableau Prep | Licença Creator. Como criador, você precisa fazer login em sua conta organizacional do Salesforce e autenticar antes de selecionar Aplicativos e conjuntos de dados para gerar seus dados de fluxo. |
Conexões de dados OAuth | Como administrador do servidor, configure o Tableau Server com uma ID de cliente OAuth e um segredo no conector. Isso é necessário para executar fluxos no Tableau Server. Para obter mais informações, consulte Configurar Tableau Server para Oauth do Salesforce.com Oauth(O link abre em nova janela) na ajuda do Tableau Server. |
Salvar dados de fluxo em um CRM Analytics
Os seguintes limites de entrada do CRM Analytics se aplicam ao salvar de Tableau Prep Builder para CRM Analytics.
- Tamanho máximo de arquivo para uploads de dados externos: 40 GB
- Tamanho máximo de arquivo para todos os uploads de dados externos em um período contínuo de 24 horas: 50 GB
- Clique no ícone de adição em uma etapa e selecione Adicionar saída.
- Na lista suspensa Salvar saída em, selecione CRM Analytics.

- Na seção Conjunto de dados de dados, conecte-se ao Salesforce.
Faça login no Salesforce e clique em Permitir para conceder ao Tableau acesso aos aplicativos e conjuntos de dados do CRM Analytics ou selecione uma conexão existente do Salesforce
- No campo Nome, selecione um nome de conjunto de dados existente. Isso substituirá o conjunto de dados pela saída do fluxo. Caso contrário, digite um novo nome e clique em Criar novo conjunto de dados para criar um novo conjunto de dados no aplicativo CRM Analytics selecionado.
Observação: os nomes dos conjuntos de dados não podem exceder 80 caracteres.

- Abaixo do campo Nome, verifique se o aplicativo mostrado é o aplicativo para o qual você tem permissão para gravar.
Para alterar o aplicativo, clique em Procurar conjuntos de dados, selecione o aplicativo na lista, insira o nome do conjunto de dados no campo Nome e clique em Aceitar.

- Na seção Opções de gravação, Atualização completa e Criar tabela são as únicas opções com suporte.
- Clique em Executar fluxo para executar o fluxo e gravar seus dados no conjunto de dados CRM Analytics.
Se a execução do fluxo for bem-sucedida, você poderá verificar os resultados de saída no CRM Analytics na guia Monitor do gerenciador de dados. Para obter mais informações sobre esse recurso, consulte Monitorar um carregamento de dados externos(O link abre em nova janela) na ajuda do Salesforce.
Salvar dados de saída de fluxo em Data Cloud
Com suporte no Tableau Prep Builder e na Web a partir da versão 2023.3
Prepare seus dados com o Tableau Prep e associe-os aos conjuntos de dados existentes no Data Cloud. Use qualquer um dos conectores compatíveis com o Tableau Prep Builder ou o Tableau Prep na Web para importar seus dados, limpar e preparar seus dados e, em seguida, enviar seus dados de fluxo diretamente para o Data Cloud usando a API de ingestão.
Pré-requisitos de permissão
Licença do Salesforce | Para obter informações sobre edições do Data Cloud e licenças complementares, consulte Edições e licenças padrão do Data Cloud na ajuda do Salesforce. Veja também Limites e diretrizes do Data Cloud. |
| Permissões de espaço de dados | Você deve estar atribuído a um espaço de dados e a um dos seguintes conjuntos de permissões no Data Cloud:
Para obter mais informações, veja Gerenciar espaços de dados(O link abre em nova janela) e Gerenciar espaços de dados com conjuntos de permissões herdados(O link abre em nova janela). |
Permissão de ingestão para Data Cloud | Você deve ser atribuído ao seguinte para acesso de campo para ingestão no Data Cloud:
Para obter mais informações, veja Habilitar permissões de objetos e campos. |
| Perfis do Salesforce | Habilite o acesso ao perfil para:
|
| Licença e permissões do Tableau Prep | Licença Creator. Como criador, você precisa fazer login em sua conta organizacional do Salesforce e autenticar antes de selecionar Aplicativos e conjuntos de dados para gerar seus dados de fluxo. |
Salvar dados de fluxo em Data Cloud
Se você já usa a API de ingestão e chama manualmente as APIs para salvar conjuntos de dados no Data Cloud, você pode simplificar esse fluxo de trabalho usando o Tableau Prep. As configurações de pré-requisito são as mesmas do Tableau Prep.
Se esta for a primeira vez que você salva dados no Data Cloud, siga os requisitos de configuração em Pré-requisitos de configuração do Data Cloud.
- Clique no ícone de adição em uma etapa e selecione Adicionar saída.
- Na lista suspensa Salvar saída, selecione Salesforce Data Cloud.
- Na seção Objeto, selecione a organização do Salesforce Data Cloud para fazer login.

- No menu Salesforce Data Cloud, clique em Entrar.
- Faça login na organização Data Cloud usando seu nome de usuário e senha.
- Na formulário Permitir acesso, clique em Permitir.
- Na seção Salvar saída para, insira o conector da API de ingestão e o Nome do objeto.
- Para encontrar o nome do Conector de API de ingestão e Nome do objeto correspondente, faça o seguinte:
Faça login no Salesforce Data Cloud e navegue até Configuração do Data Cloud.
Na caixa Localização rápida, digite API de ingestão, então selecione API de ingestão nos resultados.
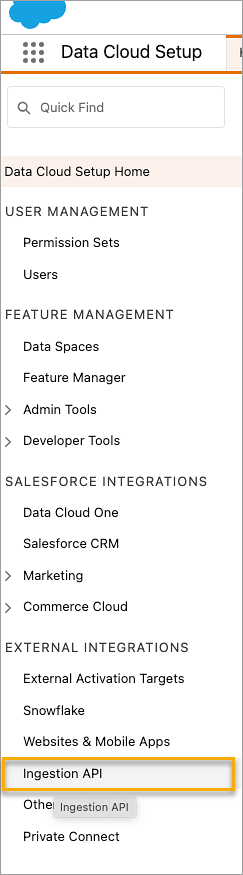
Na página API de ingestão, você verá os conectores disponíveis listados em Nome do conector.
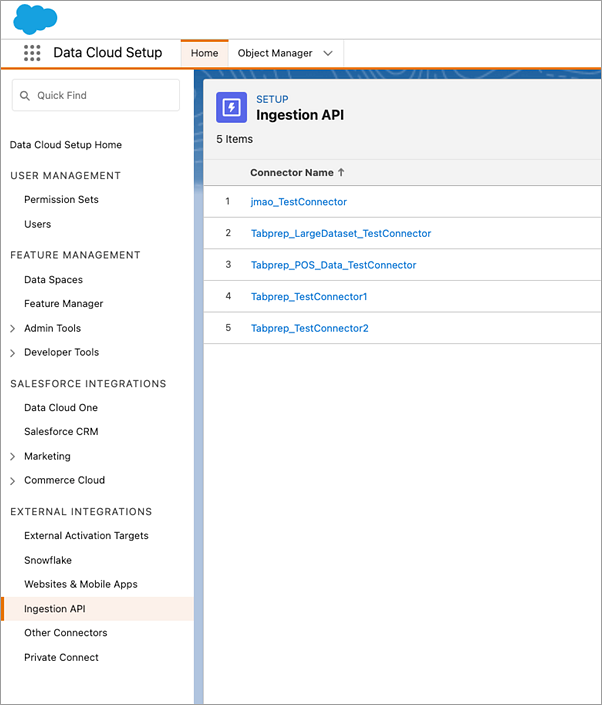
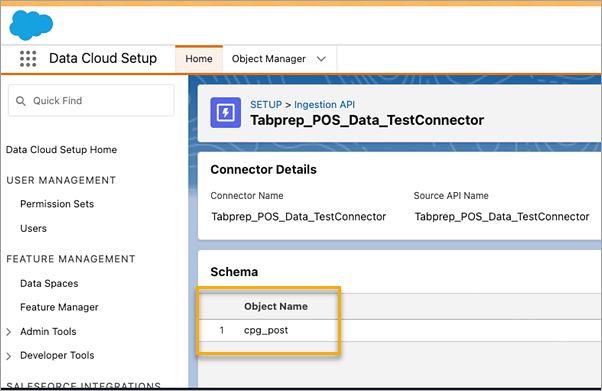
Para encontrar o correspondente Nome do objeto para o conector que você deseja usar, selecione um conector na lista. Na página Detalhes do conector na seção Esquema, você verá os objetos correspondentes listados em Nome do objeto.
- A seção Opções de Gravação indica que as linhas existentes serão atualizadas se o valor especificado já existir em uma tabela, ou uma nova linha será inserida se o valor especificado ainda não existir.
- Clique em Executar fluxo para executar o fluxo e gravar seus dados no Data Cloud.
- Valide os dados no Data Cloud visualizando o status de execução no Data Stream e os objetos no Data Explorer.

Uma janela do navegador será aberta para https://login.salesforce.com/.



Considerações
- É possível executar um fluxo por vez. A execução deve ser concluída no Data Cloud antes que outra saída Salvar possa ser executada.
- Os tempos de espera para salvar um fluxo no Data Cloud podem levar algum tempo para serem concluídos. Verifique o status no Data Cloud.
- Os dados são salvos no Data Cloud usando a função Upsert. Se um registro em um arquivo corresponder a um registro existente, o registro existente será atualizado com os valores dos seus dados. Se nenhuma correspondência for encontrada, o registro será criado como uma nova entidade.
- Para o Prep Conductor, se você agendar o mesmo fluxo para execução automática, os dados não serão atualizados. Isso ocorre porque apenas o Upsert é compatível.
- Você não pode cancelar o trabalho durante o processo de salvar no Data Cloud.
- Não há validação de campos salvos no Data Cloud. Valide os dados no Data Cloud.
Pré-requisitos de configuração do Data Cloud
Estas etapas são um pré-requisito para salvar fluxos do Tableau Prep no Data Cloud. Para obter informações detalhadas sobre conceitos do Data Cloud e mapeamento de dados entre fontes de dados do Tableau e Data Cloud, consulte Sobre a nuvem de dados do Salesforce.
Configurar o conector Salesforce API
Crie um fluxo de dados da API de ingestão a partir de seus objetos de origem fazendo upload de um arquivo de esquema no formato OpenAPI (OAS) com uma extensão de arquivo .yaml. O arquivo de esquema descreve como os dados do seu site são estruturados. Para obter mais informações, consulte o Exemplos de arquivo YAML e API de ingestão.
- Clique no ícone de engrenagem Configurar e depois Configuração da nuvem de dados.
- Clique em API de ingestão.
- Clique em Novo e forneça um nome de conector.
- Na página de detalhes do novo conector, carregue um arquivo de esquema no formato OpenAPI (OAS) com uma extensão de arquivo
.yaml. O arquivo de esquema descreve como os dados transferidos por meio da API são estruturados. - Clique Salvar no formulário Esquema de visualização.
Observação: os esquemas da API de ingestão definiram requisitos. Veja Requisitos de esquema antes da ingestão.
Criar um fluxo de dados
Os fluxos de dados são uma fonte de dados trazida para o Data Cloud. Consiste nas conexões e nos dados associados ingeridos no Data Cloud.
- Vá para o Iniciador de aplicativos e selecione Data Cloud.
- Clique na guia Fluxo de dados.
- Clique em Novo e selecione API de ingestão, então clique em Próximo.
- Selecione a API de ingestão e os objetos.
- Selecione o espaço de dados, a categoria e a chave primária e clique em Próximo.
- Clique em Implantar.
Uma chave primária verdadeira deve ser usada para Data Cloud. Se não existir, você precisará criar um campo de fórmula para a chave primária.
Para Categoria, escolha entre Perfil, Engajamento ou Outro. Um campo de data e hora deve estar presente para objetos destinados à categoria de trabalho. Objetos do tipo perfil ou outros não impõem esse mesmo requisito. Para obter mais informações, veja Categoria e Chave primária.
Agora você tem um fluxo de dados e um objeto de lago de dados. Seu fluxo de dados agora pode ser adicionado a um espaço de dados.

Adicione seu fluxo de dados a um espaço de dados
Ao trazer dados de qualquer fonte para o Data Cloud, você associa os Objetos de lago de dados (DLOs) ao espaço de dados relevante com ou sem filtros.
- Clique na guia Espaços de dados.
- Escolha o Espaço de dados padrão ou o nome do espaço de dados ao qual você está atribuído.
- Clique em Adicionar dados.
- Selecione o objeto de Lago de dados que você criou e clique em Próximo.
- (Opcional) selecione filtros para o objeto.
- Clique em Salvar.

Mapeie o objeto de Lago de dados para objetos do Salesforce
O mapeamento de dados relaciona os campos do Objeto de lago de dados aos campos do Objeto de modelo de dados (DMO).
- Vá para a guia Fluxo de dados e selecione o fluxo de dados que você criou.

- Na seção Mapeamento de dados, clique em Começar.
A tela de mapeamento de campo mostra seus DLOs de origem à esquerda e DMOs de destino à direita. Para obter mais informações, consulte Mapear objetos do modelo de dados.
Criar um aplicativo cliente externo ou aplicativo conectado para a API de ingestão do Data Cloud
Para enviar dados para o Data Cloud usando a API de ingestão, configure o Salesforce para usar um aplicativo cliente externo (recomendado) ou um aplicativo conectado (obsoleto). Para obter mais detalhes, consulte o seguinte na Ajuda do Salesforce:
Para aplicativo cliente externo: Definir as configurações de OAuth do aplicativo cliente externo(O link abre em nova janela) e Criar um aplicativo cliente externo(O link abre em nova janela)
Para aplicativo conectado: Habilitar configurações de OAuth para integração de API e Criar um aplicativo conectado para API de ingestão do Data Cloud
Como parte da configuração do seu aplicativo cliente externo ou aplicativo conectado para API de ingestão, você deve selecionar os seguintes escopos OAuth:
- Acesse e gerencie os dados da API de ingestão de Data Cloud (cdp_ingest_api)
- Gerencie dados de perfil do Data Cloud (cdp_profile_api)
- Execute consultas ANSI SQL nos dados do Data Cloud (cdp_query_api)
- Gerenciar dados do usuário por meio de APIs (api)
- Realizar solicitações em seu nome a qualquer momento (refresh_token, offline_access)
Requisitos de esquema
Para criar uma origem de API de ingestão no Data Cloud, o arquivo de esquema carregado deve atender a requisitos específicos. Consulte Requisitos para esquema de API de ingestão.
- Os esquemas carregados devem estar em formato OpenAPI válido com extensão .yml ou .yaml. A versão 3.0.x do OpenAPI é suportada.
- Os objetos não podem ter objetos aninhados.
- Cada esquema deve ter pelo menos um objeto. Cada objeto deve ter pelo menos um campo.
- Os objetos não podem ter mais de 1.000 campos.
- Os objetos não podem ter mais de 80 caracteres.
- Os nomes dos objetos devem conter apenas a-z, A-Z, 0–9, _, -. Sem caracteres Unicode.
- Os nomes dos campos devem conter apenas a-z, A-Z, 0–9, _, -. Sem caracteres Unicode.
- Os nomes dos campos não podem ser nenhuma destas palavras reservadas: date_id, location_id, dat_account_currency, dat_exchange_rate, pacing_period, pacing_end_date, row_count, version. Os nomes dos campos não podem conter a cadeia de caracteres __.
- Os nomes de campo não podem exceder 80 caracteres.
- Os campos atendem ao seguinte tipo e formato:
- Para texto ou tipo booleano: cadeia de caracteres
- Para tipo de número: número
- Para tipo de data: cadeia de caracteres; formato: data-hora
- Os nomes dos objetos não podem ser duplicados; não diferencia maiúsculas de minúsculas.
- Os objetos não podem ter nomes de campos duplicados; não diferencia maiúsculas de minúsculas.
- Os campos de tipo de dados DateTime em suas cargas devem estar em ISO 8601 UTC Zulu com formato aaaa-MM-dd’T’HH:mm:ss.SSS’Z'.
Ao atualizar seu esquema, esteja ciente de que:
- Os tipos de dados de campo existentes não podem ser alterados.
- Ao atualizar um objeto, todos os campos existentes para esse objeto deverão estar presentes.
- Seu arquivo de esquema atualizado inclui apenas objetos alterados, portanto você não precisa fornecer todas as vezes uma lista abrangente de objetos.
- Um campo de data e hora deve estar presente para objetos destinados à categoria de trabalho. Objetos do tipo
profileouothernão impõem esse mesmo requisito.
Exemplos de arquivo YAML
openapi: 3.0.3
components:
schemas:
owner:
type: object
required:
- id
- name
- region
- createddate
properties:
id:
type: integer
format: int64
name:
type: string
maxLength: 50
region:
type: string
maxLength: 50
createddate:
type: string
format: date-time
car:
type: object
required:
- car_id
- color
- createddate
properties:
car_id:
type: integer
format: int64
color:
type: string
maxLength: 50
createddate:
type: string
format: date-time Salvar dados de saída de fluxo no Amazon S3
Disponível no Tableau Prep Builder 2024.2 e posterior, criação na Web e Tableau Cloud. Esse recurso ainda não está disponível no Tableau Server.
Você pode se conectar aos dados de qualquer um dos conectores suportados pelo Tableau Prep Builder ou pela Web e salvar a saída do fluxo como um arquivo .parquet ou .csv no Amazon S3. A saída pode ser salva como novos dados ou você pode substituir os dados S3 existentes. Para evitar a perda de dados, você pode usar a opção SQL personalizado para fazer uma cópia dos dados da tabela e executá-la antes de salvar os dados de fluxo no S3.
Salvar sua saída de fluxo e conectar-se ao conector S3 são independentes um do outro. Não é possível reutilizar uma conexão S3 existente usada como conexão de entrada do Tableau Prep.
O volume total de dados e o número de objetos que você pode armazenar no Amazon S3 são ilimitados. Os objetos individuais do Amazon S3 podem variar em tamanho, de no mínimo 0 bytes a no máximo 5 TB. O maior objeto que pode ser carregado em um único PUT é de 5 GB. Para objetos maiores que 100 MB, os clientes devem considerar o uso do recurso de upload em várias partes. Consulte Fazendo upload e copiando objetos usando upload de várias partes.
Permissões
Para gravar no bucket do Amazon S3, você precisa da região do bucket, do nome do bucket, do ID da chave de acesso e da chave de acesso secreta. Para obter essas chaves, você precisará criar um usuário de gerenciamento de identidade e acesso (IAM) na AWS. Consulte Gerenciar chaves de acesso para usuários do IAM.
Salvar dados de fluxo no Amazon S3
- Clique no ícone de adição em uma etapa e selecione Adicionar saída.
- Na lista suspensa Salvar saída, selecione Banco de dados e Armazenamento na nuvem.
- Na seção Tabela > Conexão, selecione Amazon S3 (somente saída).
- No formulário Amazon S3 (somente saída), adicione as seguintes informações:
- ID da chave de acesso: a ID da chave que você usou para assinar as solicitações enviadas ao Amazon S3.
- Chave de acesso secreta: credenciais de segurança (senhas, chaves de acesso) usadas para verificar se você tem permissão para acessar o recurso da AWS.
- Região do intervalo: o local do bucket do Amazon S3 (endpoint da região da AWS). Por exemplo: us-east-2.
- Nome do intervalo: o nome do bucket S3 em que você deseja gravar a saída do fluxo. Os nomes dos buckets de duas contas da AWS na mesma região não podem ser iguais.
Observação: para encontrar sua região S3 e o nome do bucket, faça login em sua conta AWS S3 e navegue até o console AWS S3.
- Clique em Fazer logon.
- No campo S3 URI, insira o nome do arquivo
.csvou.parquet. Por padrão, o campo é preenchido coms3://<your_bucket_name>. O nome do arquivo deve incluir a extensão.csvou.parquet.Você pode salvar a saída do fluxo como um novo objeto S3 ou substituir um objeto S3 existente.
- Para um novo objeto S3, digite o nome do arquivo
.parquetou.csv. O URI é mostrado no texto de visualização. Por exemplo:s3://<bucket_name><name_file.csv>. - Para substituir um objeto S3 existente, digite o nome do arquivo
.parquetou.csvou clique em Navegar para encontrar os arquivos S3 existentes.parquetou.csv.Observação: a janela Procurar objeto mostrará apenas arquivos que foram salvos de logins anteriores no Amazon S3.
- Para um novo objeto S3, digite o nome do arquivo
- Para Opções de gravação, um novo objeto S3 é criado com os dados do seu fluxo. Se os dados já existirem, qualquer estrutura de dados ou propriedades existentes definidas para o objeto serão excluídas e substituídas por novos dados de fluxo. Todos os campos existentes no fluxo são adicionados ao novo objeto S3.
- Clique em Executar para executar o fluxo e gravar seus dados para S3.
Você pode verificar se os dados foram salvos no S3 fazendo login em sua conta AWS S3 e navegando até o console AWS S3.