Enregistrer et partager votre travail
Depuis le 14 octobre 2025, Data Cloud a été rebaptisé « Data 360 ». Au cours de cette transition, vous verrez peut-être des références à Data Cloud dans notre application et dans notre documentation. Bien que le nom soit nouveau, la fonctionnalité et le contenu restent inchangés.
À tout moment de votre flux, vous pouvez enregistrer manuellement votre travail, ou confier cette tâche automatique à Tableau lors de la création ou de la modification de flux sur le Web. Il y a quelques différences lorsque vous travaillez avec des flux sur le Web.
Pour plus d’informations sur la création de flux sur le Web, consultez Tableau Prep sur le Web dans l’aide de Tableau Server(Le lien s’ouvre dans une nouvelle fenêtre) et Tableau Cloud(Le lien s’ouvre dans une nouvelle fenêtre).
| Tableau Prep Builder | Tableau Prep sur le Web |
|---|---|
|
|
Pour garder les données à jour, vous pouvez exécuter manuellement des flux individuels depuis Tableau Prep Builder ou à la ligne de commande. Vous pouvez également exécuter des flux publiés sur Tableau Server ou Tableau Cloud manuellement ou de manière programmée. Pour plus d’informations sur l’exécution de flux, consultez Publier un flux sur Tableau Server ou Tableau Cloud.
Enregistrer un flux
Dans Tableau Prep Builder, vous pouvez enregistrer manuellement votre flux pour sauvegarder votre travail avant d’effectuer toute opération supplémentaire. Votre flux est enregistré au format de fichier de flux Tableau Prep (.tfl).
Vous pouvez également compresser vos fichiers locaux (Excel, fichiers texte et extraits Tableau) avec votre flux pour les partager avec d’autres, de la même manière que vous compressez un classeur pour le partager dans Tableau Desktop. Seuls les fichiers locaux peuvent être compressés avec un flux. Les données issues des connexions à des bases de données, par exemple, ne sont pas incluses.
En mode de création Web, les fichiers locaux sont automatiquement compressés avec notre flux. Les connexions de fichiers directs ne sont pas encore prises en charge.
Lorsque vous enregistrez un flux compressé, ce flux est enregistré en tant que fichier de flux compressé Tableau (.tflx).
- Pour enregistrer votre flux manuellement, dans le menu supérieur, sélectionnez Fichier > Enregistrer.
- Dans Tableau Prep Builder, pour compresser vos fichiers de données avec votre flux, dans le menu supérieur, effectuez l’une des opérations suivantes :
- Sélectionnez Fichier > Exporter le flux compressé
- Sélectionnez Fichier > Enregistrer sous. Ensuite, dans la boîte de dialogue Enregistrer sous, sélectionnez Fichiers de flux compressés Tableau dans le menu déroulant Type de fichier.
Enregistrer automatiquement vos flux sur le Web
Si vous créez ou modifiez des flux sur le Web, lorsque vous modifiez le flux (connexion à une source de données, ajout d’une étape, etc.), votre travail est automatiquement enregistré toutes les quelques secondes sous forme de brouillon pour vous éviter de perdre votre travail.
Vous ne pouvez enregistrer les flux que sur le serveur auquel vous êtes actuellement connecté. Vous ne pouvez pas créer un brouillon de flux sur un serveur et tenter de l’enregistrer ou de le publier sur un autre serveur. Si vous souhaitez publier le flux sur un autre projet sur le serveur, utilisez l’option de menu Fichier > Publier en tant que, puis sélectionnez votre projet dans la boîte de dialogue.
Tant que vous n’avez pas publié les brouillons de flux et que vous ne les avez pas rendus accessibles à des personnes autorisées à accéder au projet sur votre serveur, vous seul pouvez les consulter. Les flux présentant un statut de brouillon sont marqués avec un badge Brouillon afin que vous puissiez facilement retrouver vos flux en cours. Si le flux n’a jamais été publié, un badge Jamais publié s’affiche à côté du badge Brouillon.

Une fois qu’un flux est publié et que vous modifiez et republiez le flux, une nouvelle version est créée. Vous pouvez voir une liste des versions du flux dans la boîte de dialogue Historique des révisions. À partir de la page Explorer, cliquez sur le menu ![]() Actions et sélectionnez Historique des révisions.
Actions et sélectionnez Historique des révisions.
Pour plus d’informations sur la gestion de l’historique des révisions, consultez Utiliser des révisions de contenu(Le lien s’ouvre dans une nouvelle fenêtre) dans l’Aide de Tableau Desktop.
Remarque : la fonction d’enregistrement automatique est activée par défaut. Les administrateurs ont la possibilité de désactiver la fonction d’enregistrement automatique sur un site, mais ce n’est pas recommandé. Pour désactiver l’enregistrement automatique, utilisez la méthode d’API REST Tableau Server « Mise à jour de site » et définissez l’attribut flowAutoSaveEnabled sur « false ». Pour plus d’informations, voir Méthodes du site de l’API REST Tableau Server : Mettre à jour le site(Le lien s’ouvre dans une nouvelle fenêtre).
Récupération automatique de fichiers
Par défaut, Tableau Prep Builder enregistre automatiquement un brouillon de tout flux ouvert en cas de blocage ou de panne de l’application. Les brouillons de flux sont enregistrés dans votre dossier Flux récupérés sur Mon dossier Tableau Prep. La prochaine fois que vous ouvrez l’application, une boîte de dialogue affiche la liste des flux récupérés que vous pouvez sélectionner. Vous pouvez ouvrir un flux récupéré et reprendre là où vous vous étiez arrêté, ou supprimer le fichier de flux récupéré si vous n’en avez pas besoin.
Remarque : si vous avez récupéré des flux dans votre dossier Flux récupérés, cette boîte de dialogue s’affiche chaque fois que vous ouvrez l’application jusqu’à ce que ce dossier soit vide.

Si vous ne souhaitez pas activer cette fonctionnalité, en tant qu’administrateur, vous pouvez la désactiver pendant ou après l’installation. Pour plus d’informations sur la désactivation de cette fonctionnalité, consultez Désactiver la récupération de fichiers(Le lien s’ouvre dans une nouvelle fenêtre) dans le guide de déploiement de Tableau Desktop et Tableau Prep.
Récupérer les flux supprimés
Pris en charge dans la création Web Tableau Prep dans Tableau Cloud et Tableau Server à partir de la version 2025.3.
Dans la création Web, vous pouvez récupérer des flux précédemment supprimés à partir de la corbeille. Si la corbeille est activée, au lieu d’être supprimés définitivement, les flux sont temporairement déplacés vers la corbeille où vous pouvez les récupérer ou les supprimer définitivement. Les flux à l’état de brouillon continuent d’être supprimés définitivement. Pour plus d’informations sur la corbeille, consultez Corbeille(Le lien s’ouvre dans une nouvelle fenêtre).
Remarque : cette fonctionnalité n’est pas disponible dans Tableau Prep Builder.
Les conditions suivantes sont requises pour utiliser cette fonctionnalité :
Autorisations : vous devez avoir le rôle Administrateur de site, Administrateur de serveur, Creator ou Explorer (peut publier).
Paramètre du site : la corbeille est activée pour votre site.
Statut du flux : le flux doit être publié.
La durée de stockage des flux dans la corbeille est définie par votre administrateur.
Récupérer un flux
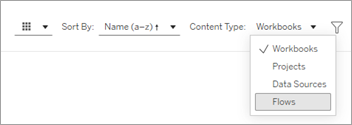
Depuis la page d’accueil, développez le volet latéral, puis sélectionnez Corbeille.
Dans la page Corbeille, sélectionnez Flux dans le menu déroulant Type de contenu .
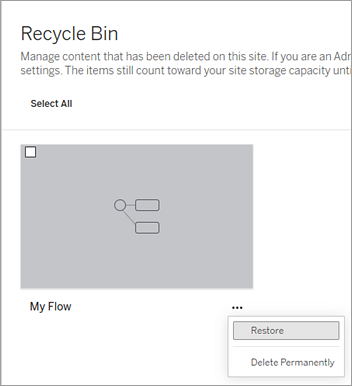
Sélectionnez le menu Plus d’actions du flux que vous souhaitez restaurer, puis sélectionnez Restaurer.
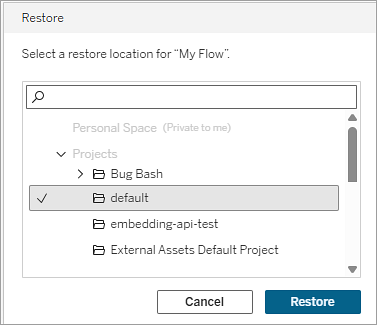
Sélectionnez un projet comme emplacement de restauration.
Sélectionnez Restaurer.
Afficher la sortie de flux dans Tableau Desktop
Remarque : cette option n’est pas disponible sur le Web.
Lorsque vous nettoyez vos données, il arrive que vous souhaitiez vérifier l’avancement de l’opération en la consultant dans Tableau Desktop. Lorsque votre flux s’ouvre dans Tableau Desktop, Tableau Prep Builder crée un fichier Tableau .hyper permanent et un fichier de source de données Tableau (.tds). Les fichiers sont enregistrés dans votre référentiel Tableau dans le fichier Sources de données afin que vous puissiez expérimenter avec vos données à tout moment.
Lorsque vous ouvrez le flux dans Tableau Desktop, vous pouvez voir l’échantillon de données avec lequel vous travaillez dans votre flux et les opérations qui s’y appliquent, jusqu’à l’étape que vous avez sélectionnée.
Remarque : bien que vous puissiez expérimenter avec vos données, Tableau ne vous présente qu’un échantillon de vos données et vous ne pouvez pas enregistrer le classeur en tant que classeur complet (.twbx). Lorsque vous êtes prêt à travailler avec vos données dans Tableau, créez une étape de sortie dans votre flux et enregistrez la sortie dans un fichier ou en tant que source de données publiée, puis connectez-vous à la source de données complète dans Tableau.
Pour afficher votre échantillon de données dans Tableau Desktop, procédez comme suit :
- Faites un clic droit sur l’étape où vous souhaitez afficher vos données et sélectionnez Aperçu dans Tableau Desktop depuis le menu contextuel.

- Tableau Desktop s’ouvre dans l’onglet Feuille.
Créer des fichiers d’extrait de données et des sources de données publiées
Pour créer une sortie de flux, exécutez votre flux. Lorsque vous exécutez votre flux, vos modifications sont appliquées à l’intégralité de l’ensemble de données. L’exécution du flux entraîne la création d’un fichier de source de données Tableau (.tds) et d’un extrait (.hyper).
Remarque : les flux qui incluent des données spatiales ne peuvent être générés que vers des fichiers .hyper ou en tant que source de données publiée. Les autres types de sortie ne sont pas pris en charge actuellement. Pour plus d’informations sur l’utilisation des données spatiales, consultez Créer des calculs et des jointures de données spatiales(Le lien s’ouvre dans une nouvelle fenêtre).
Tableau Prep Builder
Vous pouvez créer un fichier d’extrait depuis votre sortie de flux pour l’utiliser dans Tableau Desktop ou partager vos données avec des tiers. Créez un fichier d’extrait aux formats suivants :
- Extrait Hyper (.hyper): il s’agit du type de fichier d’extrait Tableau le plus récent.
- Valeurs séparées par des virgules (.csv) : enregistrez l’extrait dans un fichier .csv pour partager vos données avec des tiers. Le codage du fichier CSV exporté sera UTF-8 avec BOM.
- Microsoft Excel (.xlsx) : feuille de calcul Microsoft Excel.
Tableau Prep Builder et sur le Web
Publiez la sortie de votre flux en tant que source de données publiée ou sortie dans une base de données.
- Enregistrez la sortie de votre flux en tant que source de données sur Tableau Server ou Tableau Cloud pour partager vos données et fournir un accès centralisé aux données que vous avez nettoyées, mises en forme et combinées.
- Enregistrez votre sortie de flux dans une base de données pour créer, remplacer ou compléter les données de la table avec vos données de flux nettoyées et préparées. Pour plus d’informations, voir Enregistrer les données de sortie de flux dans des bases de données externes.
Utilisez l’actualisation incrémentielle lors de l’exécution de votre flux pour gagner du temps et des ressources en actualisant uniquement les nouvelles données au lieu de votre ensemble de données complet. Pour plus d’informations sur la configuration et l’exécution de votre flux à l’aide d’une actualisation incrémentielle, consultez Actualiser les données de flux à l’aide d’une actualisation incrémentielle.
Remarque : pour que vous puissiez publier votre sortie Tableau Prep Builder sur Tableau Server, l’API REST de Tableau Server doit être activée. Pour plus d’informations, consultez Rest API Requirements(Le lien s’ouvre dans une nouvelle fenêtre) (Configuration requise pour l’API Rest) dans l’aide de l’API Rest Tableau. Pour publier sur un serveur qui utilise des certificats de cryptage SSL (Secure Socket Layer), des étapes de configuration supplémentaires sont nécessaires sur l’ordinateur exécutant Tableau Prep Builder. Pour plus d’informations, consultez Avant l’installation(Le lien s’ouvre dans une nouvelle fenêtre) dans le Guide de déploiement de Tableau Desktop et de Tableau Prep Builder.
Inclure des paramètres dans votre sortie de flux
Pris en charge dans Tableau Prep Builder et sur le Web à partir de la version 2021.4
Incluez des valeurs de paramètre dans les noms de fichier de sortie de votre flux, les chemins d’accès, les noms de table ou les scripts SQL personnalisés (version 2022.1.1 et versions ultérieures) pour exécuter facilement vos flux pour différents ensembles de données. Pour plus d’informations, consultez Créer et utiliser des paramètres dans les flux.
Créer un extrait dans un fichier
Remarque : cette option de sortie n’est pas disponible lors de la création ou de la modification de flux sur le Web.
- Cliquez sur l’icône plus
 dans une étape et sélectionnez Ajouter une sortie.
dans une étape et sélectionnez Ajouter une sortie.Si vous avez exécuté le flux précédemment, cliquez sur le bouton Exécuter le flux
 dans l’étape Sortie. Cela exécute le flux et met à jour votre sortie.
dans l’étape Sortie. Cela exécute le flux et met à jour votre sortie.Le volet Sortie s’ouvre et affiche un instantané de vos données.

- Dans le volet gauche, sélectionnez Fichier dans la liste déroulante Enregistrer la sortie sur. Dans les versions précédentes, sélectionnez Enregistrer dans le fichier.
- Cliquez sur le bouton Parcourir, puis dans la boîte de dialogue Enregistrer l’extrait sous, entrez un nom pour le fichier et cliquez sur Accepter.
- Dans le champ Type de sortie, sélectionnez l’un des types de sortie suivants :
- Extrait (. hyper)
- Valeurs séparées par des virgules (.csv)
(Tableau Prep Builder et versions ultérieures) Dans la section Options d’écriture, affichez l’option d’écriture par défaut pour écrire les nouvelles données sur vos fichiers et apporter des modifications si nécessaire. Pour plus d’informations, consultez Configurer les options d’écriture.
- Créer une table : cette option crée une nouvelle table ou remplace la table existante par la nouvelle sortie.
- Ajouter à la table : cette option ajoute les nouvelles données à votre table existante. Si la table n’existe pas déjà, une nouvelle table est créée et les exécutions suivantes ajoutent de nouvelles lignes à cette table.
Remarque : l’option Ajouter à la table n’est pas prise en charge pour les types de sortie .csv. Pour plus d’informations sur les combinaisons d’actualisations prises en charge, consultez Options d’actualisation de flux.
- Cliquez sur Exécuter le flux pour exécuter le flux et générer le fichier d’extrait.
Créer un extrait dans une feuille de calcul Microsoft Excel
Pris en charge dans Tableau Prep Builder à partir de la version 2021.1.2. Cette option de sortie n’est pas disponible lors de la création ou de la modification de flux sur le Web, ni lors de la création de sorties pour des flux incluant des données spatiales.
Lorsque vous extrayez des données de flux vers une feuille de calcul Microsoft Excel, vous pouvez créer une nouvelle feuille de calcul ou bien ajouter ou remplacer des données dans une feuille de calcul existante. Les conditions suivantes s’appliquent :
- Seuls les fichiers au format .xlsx Microsoft Excel sont pris en charge.
- Les lignes de feuille de calcul commencent à la cellule A1.
- Lors de l’ajout ou du remplacement de données, la première ligne est présupposée être un en-tête.
- Les noms d’en-tête sont ajoutés lors de la création d’une nouvelle feuille de calcul, mais pas lors de l’ajout de données à une feuille de calcul existante.
- Les éventuels formats ou formules dans les feuilles de calcul existantes ne sont pas appliqués à la sortie de flux.
- L’écriture sur des tables ou des plages nommées n’est pas prise en charge actuellement.
- L’actualisation incrémentielle n’est pas prise en charge actuellement.
Données de flux de sortie vers un fichier de feuille de calcul Microsoft Excel
- Cliquez sur l’icône plus dans une étape et sélectionnez Ajouter une sortie.
Si vous avez exécuté le flux précédemment, cliquez sur le bouton Exécuter le flux
dans l’étape Sortie. Cela exécute le flux et met à jour votre sortie.Le volet Sortie s’ouvre et affiche un instantané de vos données.

- Dans le volet gauche, sélectionnez Fichier dans la liste déroulante Enregistrer la sortie sur.
- Cliquez sur le bouton Parcourir, puis dans la boîte de dialogue Enregistrer l’extrait, entrez un nom pour le fichier et cliquez sur Accepter.
- Dans le champ Type de sortie, sélectionnez Microsoft Excel (.xlsx).

- Dans le champ Feuille de calcul, sélectionnez la feuille de calcul sur laquelle vous souhaitez écrire vos résultats, ou entrez un nouveau nom dans le champ à la place, puis cliquez sur Créer une nouvelle table.
- Dans la boîte de dialogue Options d’écriture, sélectionnez l’une des options suivantes :
- Créer une table : crée ou recrée (si le fichier existe déjà) la feuille de calcul avec vos données de flux.
- Ajouter à la table : ajoute de nouvelles lignes à une feuille de calcul existante. Si la feuille de calcul n’existe pas, une feuille est créée et les flux ultérieurs ajoutent des lignes à cette feuille de calcul.
- Remplacer les données : remplace toutes les données existantes à l’exception de la première ligne d’une feuille de calcul existante par les données de flux.
Une comparaison de champ vous montre les champs de votre flux qui correspondent aux champs de votre table, si celle-ci existe déjà. Si la feuille de calcul est nouvelle, une correspondance élément par élément s’affiche. Tous les champs qui n’ont pas de correspondance sont ignorés.

- Cliquez sur Exécuter maintenant pour exécuter le flux et générer le fichier d’extrait Microsoft Excel.
Créer une source de données publiée
- Cliquez sur l’icône plus dans une étape et sélectionnez Ajouter une sortie.
Remarque : Tableau Prep Builder actualise les sources de données précédemment publiées et gère les modélisations de données (par exemple, les champs calculés, le formatage des nombres, et ainsi de suite) qui pourraient être incluses dans la source de données. Si la source de données ne peut pas être actualisée, la source de données, y compris la modélisation des données, sera remplacée à la place.
- Le volet Sortie s’ouvre et affiche un instantané de vos données.

- Dans la liste déroulante Enregistrer la sortie dans, sélectionnez Source de données publiée (Publier en tant que source de données dans les versions antérieures). Renseignez les champs suivants :
- Serveur (Tableau Prep Builder uniquement) : sélectionnez le serveur où vous souhaitez publier la source de données et l’extrait de données. Si vous n’êtes pas connecté à un serveur, vous serez invité à vous connecter.
Remarque : depuis Tableau Prep Builder version 2020.1.4, une fois que vous vous êtes connecté à votre serveur, Tableau Prep Builder mémorise le nom et les informations d’identification de votre serveur lorsque vous fermez l’application. La prochaine fois que vous ouvrez l’application, vous êtes déjà connecté à votre serveur.
Sur un Mac, vous pouvez être invité à donner accès à votre trousseau Mac afin que Tableau Prep Builder puisse utiliser les certificats SSL en toute sécurité pour se connecter à votre environnement Tableau Server ou Tableau Cloud.
Si vous effectuez une sortie vers Tableau Cloud, incluez le pod sur lequel votre site est hébergé dans « serverUrl », par exemple, « https://eu-west-1a.online.tableau.com », et non « https://online.tableau.com ».
- Projet : sélectionnez le projet où vous souhaitez charger la source de données et l’extrait.
- Nom : entrez un nom de fichier.
- Description : entrez une description pour la source de données.
- Serveur (Tableau Prep Builder uniquement) : sélectionnez le serveur où vous souhaitez publier la source de données et l’extrait de données. Si vous n’êtes pas connecté à un serveur, vous serez invité à vous connecter.
- (Tableau Prep Builder et versions ultérieures) Dans la section Options d’écriture, affichez l’option d’écriture par défaut pour écrire les nouvelles données sur vos fichiers et apporter des modifications si nécessaire. Pour plus d’informations, consultez Configurer les options d’écriture.
- Créer une table : cette option crée une nouvelle table ou remplace la table existante par la nouvelle sortie.
- Ajouter à la table : cette option ajoute les nouvelles données à votre table existante. Si la table n’existe pas déjà, une nouvelle table est créée et les exécutions suivantes ajoutent de nouvelles lignes à cette table.
- Cliquez sur Exécuter le flux pour exécuter le flux et publier la source de données.
Enregistrer les données de sortie de flux dans des bases de données externes
Cette option de sortie n’est pas disponible lors de la création ou de la modification de flux incluant des données spatiales.
Important : cette fonctionnalité vous permet de supprimer et de remplacer définitivement des données dans une base de données externe. Assurez-vous de disposer d’autorisations en écriture sur la base de données.
Pour éviter la perte de données, vous pouvez utiliser l’option SQL personnalisé pour faire une copie des données de votre table et l’exécuter avant d’écrire les données de flux sur la table.
Vous pouvez vous connecter aux données depuis n’importe lequel des connecteurs pris en charge par Tableau Prep Builder ou le Web, et envoyer des données à une base de données externe. Vous pouvez ainsi ajouter ou mettre à jour les données dans votre base de données avec des données nettoyées et préparées à partir de votre flux chaque fois que le flux est exécuté. Cette fonctionnalité est disponible à la fois pour les actualisations incrémentielles et les actualisations complètes, sauf mention contraire. Pour plus d’informations sur la configuration d’une actualisation incrémentielle, consultez Actualiser les données de flux à l’aide d’une actualisation incrémentielle.
Lorsque vous enregistrez votre sortie de flux dans une base de données externe, Tableau Prep effectue les opérations suivantes :
- Génère les lignes et exécute toutes les commandes SQL sur la base de données.
- Écrit les données dans une table temporaire (ou zone de transit en cas de sortie sur Snowflake) dans la base de données de sortie.
- Si l’opération réussit, les données sont déplacées de la table temporaire (ou de votre zone de transit pour Snowflake) dans la table de destination.
- Exécute toutes les commandes SQL que vous souhaitez exécuter après avoir écrit les données sur la base de données.
Si le script SQL échoue, le flux échoue. Toutefois, vos données seront toujours chargées dans vos tables de base de données. Vous pouvez essayer de réexécuter le flux ou d’exécuter manuellement votre script SQL sur votre base de données pour l’appliquer.
Options de sortie
Vous pouvez sélectionner les options suivantes lors de l’écriture de données sur une base de données. Si la table n’existe pas déjà, elle est créée lors de la première exécution du flux.
- Ajouter à la table : cette option ajoute des données à une table existante. Si la table n’existe pas, la table est créée lors de l’exécution initiale du flux et des données sont ajoutées à cette table à chaque exécution ultérieure du flux.
- Créer une table : cette option crée une nouvelle table avec les données de votre flux. Si la table existe déjà, la table et toute structure de données ou de propriétés existante définie pour la table sont supprimées et remplacées par une nouvelle table qui utilise la structure de données du flux. Tous les champs existant dans le flux sont ajoutés à la nouvelle table de base de données.
- Remplacer les données : cette option supprime les données de votre table existante et les remplace par les données de votre flux, mais conserve la structure et les propriétés de la table de base de données. Si la table n’existe pas, la table est créée lors de l’exécution initiale du flux et les données de table sont remplacées lors de chaque exécution ultérieure du flux.
Options supplémentaires
En plus des options d’écriture, vous pouvez également inclure des scripts SQL personnalisés ou ajouter une nouvelle table à votre base de données.
- Scripts SQL personnalisés : entrez votre SQL personnalisé et sélectionnez si vous souhaitez exécuter votre script avant, après ou à la fois avant et après l’écriture des données dans les tables de la base de données. Vous pouvez utiliser ces scripts pour créer une copie de votre table de base de données avant que les données de flux ne soient écrites dans la table, ajouter un index, ajouter d’autres propriétés de table, etc.
Remarque : depuis la version 2022.1.1, vous pouvez également insérer des paramètres dans vos scripts SQL. Pour plus d’informations, consultez Appliquer des paramètres utilisateur aux étapes de sortie.
- Ajouter une nouvelle table : ajoutez une nouvelle table portant un nom unique à la base de données au lieu d’en sélectionner une dans la liste de table existante. Si vous souhaitez appliquer un schéma autre que le schéma par défaut (Microsoft SQL Server et PostgreSQL), vous pouvez le spécifier à l’aide de la syntaxe
[schema name].[table name].
Bases de données prises en charge et exigences relatives aux bases de données
Tableau Prep prend en charge l’écriture de données de flux sur des tables dans un certain nombre de bases de données. Les flux qui s’exécutent de manière programmée dans Tableau Cloud ne peuvent écrire sur ces bases de données que s’ils sont hébergés dans le Cloud.
Si vous vous connectez à des sources de données sur site, à compter de la version 2025.1, vous pouvez utiliser un client Tableau Bridge pour vous connecter et actualiser vos données dans Tableau Cloud. Vous aurez besoin d’un client Tableau Bridge configuré dans un pool de clients Bridge, en ajoutant le domaine à la Liste d’autorisations de réseau privé. Dans Tableau Prep Builder et sur le Web, lorsque vous vous connectez à votre source de données, assurez-vous que l’URL du serveur correspond au domaine du pool Bridge. Pour plus d’informations, consultez « Bases de données » dans la section Tableau Cloud dans Publier un flux depuis Tableau Prep Builder(Le lien s’ouvre dans une nouvelle fenêtre).
Des restrictions ou des exigences en matière de données s’appliquent à certaines bases de données. Tableau Prep peut également imposer certaines limites afin de conserver des performances maximales lors de l’écriture de données sur les bases de données prises en charge. Le tableau suivant répertorie les bases de données où vous pouvez enregistrer vos données de flux et toutes les restrictions ou exigences relatives aux bases de données. Les données qui ne répondent pas à ces exigences peuvent générer des erreurs lors de l’exécution du flux.
Remarque : il n’est pas encore possible de fixer des limites de caractères pour vos champs. Par contre, vous pouvez créer, dans votre base de données, des tables qui incluent des contraintes de limite de caractères, puis utiliser l’option Remplacer les données pour remplacer vos données tout en conservant la structure de la table dans votre base de données.
| Base de données | Exigences ou restrictions |
|---|---|
| Amazon Redshift |
|
| Amazon S3 (sortie uniquement) | Consultez Enregistrer les données de sortie de flux dans Amazon S3 |
| Databricks |
|
| Google BigQuery |
|
| Microsoft SQL Server |
|
| MySQL |
|
| Oracle |
|
| Pivotal Greenplum Database |
|
| PostgreSQL |
|
| SAP HANA |
|
| Snowflake |
|
| Teradata |
|
| Vertica |
|
Enregistrer les données de flux dans une base de données
Remarque : vous pouvez intégrer vos informations d’identification pour la base de données lors de la publication du flux. Pour plus d’informations sur l’intégration d’informations d’identification, consultez la section Bases de données dans Publier un flux depuis Tableau Prep Builder
- Cliquez sur l’icône plus dans une étape et sélectionnez Ajouter une sortie.
- Dans la liste déroulante Enregistrer la sortie dans, sélectionnez Stockage sur les bases de données et le cloud.
- Sous l’onglet Paramètres, entrez les informations suivantes :
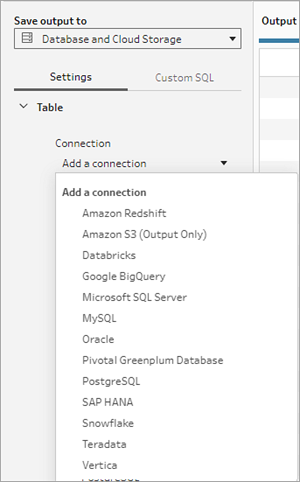
- Dans la liste déroulante Connexion, sélectionnez le connecteur de base de données où vous souhaitez écrire votre sortie de flux. Seuls les connecteurs pris en charge s’affichent. Il peut s’agir du même connecteur que celui que vous avez utilisé pour votre entrée de flux ou d’un connecteur différent. Si vous sélectionnez un autre connecteur, vous serez invité à vous connecter.
Important: assurez-vous d’avoir l’autorisation d’écriture sur la base de données que vous sélectionnez. Dans le cas contraire, le flux risque de ne traiter les données que partiellement.
- Dans la liste déroulante Base de données, sélectionnez la base de données où vous souhaitez enregistrer vos données de sortie de flux. Les schémas ou les bases de données doivent contenir au moins une table pour être visibles dans la liste déroulante.
- Dans la liste déroulante Table, sélectionnez la table où vous souhaitez enregistrer vos données de sortie de flux. Selon l’Option d’écriture que vous sélectionnez, une nouvelle table sera créée, les données de flux remplaceront toutes les données existantes dans la table, ou les données de flux seront ajoutées à la table existante.
Pour créer une table dans la base de données, entrez plutôt un nom de table unique dans le champ, puis cliquez sur Créer une nouvelle table. Lorsque vous exécutez le flux pour la première fois, quelle que soit l’option d’écriture que vous sélectionnez, la table est créée dans la base de données en utilisant le même schéma que le flux.

- Dans la liste déroulante Connexion, sélectionnez le connecteur de base de données où vous souhaitez écrire votre sortie de flux. Seuls les connecteurs pris en charge s’affichent. Il peut s’agir du même connecteur que celui que vous avez utilisé pour votre entrée de flux ou d’un connecteur différent. Si vous sélectionnez un autre connecteur, vous serez invité à vous connecter.
- Le volet Sortie affiche un instantané de vos données. Une comparaison de champ vous montre les champs de votre flux qui correspondent aux champs de votre table, si la table existe déjà. Si la table est nouvelle, une correspondance élément par élément s’affiche.

En cas de non-correspondance de champ, une note d’état vous montre toutes les erreurs.
- Aucune correspondance : le champ est ignoré : les champs existent dans le flux mais pas dans la base de données. Le champ ne sera pas ajouté à la table de base de données sauf si vous sélectionnez l’option d’écriture Créer une table et effectuez une actualisation complète. Ensuite, les champs de flux sont ajoutés à la table de base de données et utilisent le schéma de sortie de flux.
- Aucune correspondance : le champ contiendra des valeurs null : des champs existent dans la base de données, mais pas dans le flux. Le flux transmet une valeur null à la table de base de données du champ. Si le champ existe dans le flux, mais qu’il n’y a pas de correspondance parce que le nom du champ est différent, vous pouvez accéder à une étape de nettoyage et modifier le nom du champ afin qu’il corresponde au nom du champ de base de données. Pour savoir comment modifier le nom d’un champ, consultez Appliquer des opérations de nettoyage.
- Erreur : les types de données de champ ne correspondent pas : le type de données attribué à un champ dans le flux et la table de base de données sur laquelle vous écrivez votre sortie doit correspondre, sinon le flux échouera. Vous pouvez accéder à une étape de nettoyage et modifier le type de données de champ pour résoudre ce problème. Pour plus d’informations sur la modification des types de données, consultez Vérifier les types de données affectés à vos données.
- Sélectionnez une option d’écriture. Vous pouvez sélectionner une option différente pour l’actualisation complète et incrémentielle et l’option est appliquée lorsque vous sélectionnez la méthode d’exécution de votre flux. Pour plus d’informations sur l’exécution de notre flux à l’aide d’une actualisation incrémentielle, consultez Actualiser les données de flux à l’aide d’une actualisation incrémentielle.
- Ajouter à la table : cette option ajoute des données à une table existante. Si la table n’existe pas, la table est créée lors de l’exécution initiale du flux et des données sont ajoutées à cette table à chaque exécution ultérieure du flux.
- Créer une table : cette option crée une nouvelle table. S’il existe déjà une table du même nom, la table existante est supprimée et remplacée par la nouvelle table. Toutes les structures ou les propriétés de données existantes définies pour la table sont également supprimées et remplacées par la structure de données du flux. Tous les champs existant dans le flux sont ajoutés à la nouvelle table de base de données.
- Remplacer les données : cette option supprime les données de votre table existante et les remplace par les données de votre flux, mais conserve la structure et les propriétés de la table de base de données.
- (facultatif) Cliquez sur l’onglet SQL personnalisé et entrez votre script SQL. Vous pouvez entrer un script à exécuter avant et après l’écriture des données sur la table.

- Cliquez sur Exécuter le flux pour exécuter le flux et écrire vos données dans votre base de données sélectionnée.
Enregistrer les données de sortie de flux vers des ensembles de données dans CRM Analytics
Pris en charge dans Tableau Prep Builder et sur le Web à partir de la version 2022.3.
Remarque : CRM Analytics a plusieurs exigences et certaines limitations pour l’intégration de données provenant de sources externes. Pour être sûr de pouvoir écrire correctement votre sortie de flux dans CRM Analytics, consultez Considérations avant d’intégrer des données dans des ensembles de données(Le lien s’ouvre dans une nouvelle fenêtre) dans l’aide de Salesforce.
Nettoyez vos données à l’aide de Tableau Prep et obtenez de meilleurs résultats de prédiction dans CRM Analytics. Connectez-vous simplement aux données de l’un des connecteurs pris en charge par Tableau Prep Builder ou Tableau Prep sur le Web. Ensuite, appliquez des transformations pour nettoyer vos données et exportez vos données de flux directement vers les ensembles de données dans CRM Analytics auxquels vous avez accès.
Les flux qui envoient des données vers CRM Analytics ne peuvent pas être exécutés à l’aide de l’interface de ligne de commande. Vous pouvez exécuter des flux manuellement à l’aide de Tableau Prep Builder ou à l’aide d’un programme sur le Web avec Tableau Prep Conductor.
Conditions préalables
Pour envoyer des données de flux vers CRM Analytics, vérifiez que vous disposez des licences, accès et autorisations suivants dans Salesforce et Tableau.
Exigences Salesforce
| exigence | description |
|---|---|
| Autorisations Salesforce | Une licence CRM Analytics Plus ou CRM Analytics Growth doit vous avoir été attribuée. La licence CRM Analytics Plus inclut les ensembles d’autorisations :
La licence CRM Analytics Growth inclut les ensembles d’autorisations :
Pour plus d’informations, consultez En savoir plus sur les licences et les ensembles d’autorisations CRM Analytics(Le lien s’ouvre dans une nouvelle fenêtre) et Sélectionner et attribuer des ensembles d’uatoirsation utilisateur(Le lien s’ouvre dans une nouvelle fenêtre) dans l’aide de Salesforce. |
Paramètres de l’administrateur | Les administrateurs Salesforce devront configurer les éléments suivants :
|
Exigences Tableau Prep
| exigence | description |
|---|---|
Licence et autorisations Tableau Prep | Licence Creator. En tant que Creator, vous devez vous connecter à votre compte d’org Salesforce et vous authentifier avant de pouvoir sélectionner des applications et des ensembles de données pour générer vos données de flux. |
Connexion de données OAuth | En tant qu’administrateur de serveur, configurez Tableau Server avec un ID client OAuth et un secret sur le connecteur. Cette étape est nécessaire pour exécuter des flux sur Tableau Server. Pour plus d’informations consultez Configurer Tableau Server pour Salesforce.com OAuth(Le lien s’ouvre dans une nouvelle fenêtre) dans l’aide de Tableau Server. |
Enregistrer les données de flux dans CRM Analytics
Les limites suivantes d’entrées pour CRM Analytics s’appliquent lors de l’enregistrement depuis Tableau Prep Builder sur CRM Analytics.
- Taille maximale du fichier pour les chargements de données externes : 40 Go
- Taille de fichier maximale pour tous les chargements de données externes sur une période glissante de 24 heures : 50 Go
- Cliquez sur l’icône plus dans une étape et sélectionnez Ajouter une sortie.
- Dans la liste déroulante Enregistrer la sortie dans, sélectionnez CRM Analytics.

- Dans la section Ensemble de données, connectez-vous à Salesforce.
Connectez-vous à Salesforce et cliquez sur Autoriser pour autoriser Tableau à accéder aux applications et aux ensembles de données CRM Analytics ou sélectionnez une connexion Salesforce existante
- Dans le champ Nom, sélectionnez un nom d’ensemble de données existant. L’ensemble de données existant sera remplacé par la sortie de votre flux. Sinon, saisissez un nouveau nom et cliquez sur Créer un nouvel ensemble de données pour créer un nouvel ensemble de données dans l’application CRM Analytics sélectionnée.
Remarque : les noms des ensembles de données ne peuvent pas dépasser 80 caractères.

- Sous le champ Nom, vérifiez que l’application affichée est l’application sur laquelle vous êtes autorisé à écrire.
Pour changer d’application, cliquez sur Parcourir les ensembles de données, puis sélectionnez l’application dans la liste, saisissez le nom de l’ensemble de données dans le champ Nom et cliquez sur Accepter.

- Dans la section Options d’écriture, Actualisation complète et Créer une table sont les seules options prises en charge.
- Cliquez sur Exécuter le flux pour exécuter le flux et écrire vos données dans l’ensemble de données CRM Analytics.
Si l’exécution de votre flux réussit, vous pouvez vérifier les résultats de sortie dans CRM Analytics à partir de l’onglet Surveiller du Gestionnaire de données. Pour plus d’informations sur cette fonctionnalité, consultez Surveillance d’un chargement de données externes(Le lien s’ouvre dans une nouvelle fenêtre) dans l’aide de Salesforce.
Enregistrer les données de sortie de flux dans Data Cloud
Pris en charge dans Tableau Prep Builder et sur le Web à partir de la version 2023.3.
Préparez vos données avec Tableau Prep, puis associez-les aux ensembles de données existants dans Data Cloud. Utilisez l’un des connecteurs pris en charge par Tableau Prep Builder ou Tableau Prep sur le Web pour importer vos données, nettoyer et préparer vos données, puis générer vos données de flux directement vers Data Cloud à l’aide de l’API d’ingestion.
Conditions préalables à l’autorisation
Licence Salesforce | Pour plus d’informations sur les éditions de Data Cloud et les licences complémentaires, consultez Éditions et licences Data Cloud standard dans l’aide de Salesforce. Consultez également Limites et consignes de Data Cloud. |
| Autorisations pour l’espace de données | Vous devez être affecté à un espace de données ainsi qu’à l’un des ensembles d’autorisations suivants dans Data Cloud :
Pour plus d’informations, voir Gérer les espaces de données(Le lien s’ouvre dans une nouvelle fenêtre) et Gérer les espaces de données avec d’anciens ensembles d’autorisations(Le lien s’ouvre dans une nouvelle fenêtre). |
Autorisation d’ingestion vers Data Cloud | Vous devez être affecté aux éléments suivants pour accéder aux champs d’ingestion vers Data Cloud :
Pour plus d’informations, voir Activer les autorisations d’objet et de champ. |
| Profils Salesforce | Activez l’accès au profil pour :
|
| Licence et autorisations Tableau Prep | Licence Creator. En tant que Creator, vous devez vous connecter à votre compte d’org Salesforce et vous authentifier avant de pouvoir sélectionner des applications et des ensembles de données pour générer vos données de flux. |
Enregistrer les données de flux dans Data Cloud
Si vous utilisez déjà l’API d’ingestion et appelez manuellement les API pour enregistrer des ensembles de données dans Data Cloud, vous pouvez simplifier ce flux de travail à l’aide de Tableau Prep. Les configurations préalables sont les mêmes pour Tableau Prep.
Si c’est la première fois que vous enregistrez des données dans Data Cloud, suivez les exigences de configuration décrites dans Conditions préalables à la configuration de Data Cloud.
- Cliquez sur l’icône plus dans une étape et sélectionnez Ajouter une sortie.
- Dans la liste déroulante Enregistrer la sortie dans, sélectionnez Salesforce Data Cloud.
- Dans la section Objet, sélectionnez l’org Salesforce Data Cloud à laquelle vous connecter.

- Dans le menu Salesforce Data Cloud, cliquez sur Connexion.
- Connectez-vous à l’org Data Cloud à l’aide de votre nom d’utilisateur et de votre mot de passe.
- Dans le formulaire Autoriser l’accès, cliquez sur Autoriser.
- Dans la section Enregistrer la sortie dans, entrez le Connecteur de l’API Ingestion et le Nom de l’objet.
- Pour trouver le Connecteur de l’API Ingestion et le Nom de l’objet correspondant, procédez comme suit :
Connectez-vous à Salesforce Data Cloud et accédez à Configuration de Data Cloud.
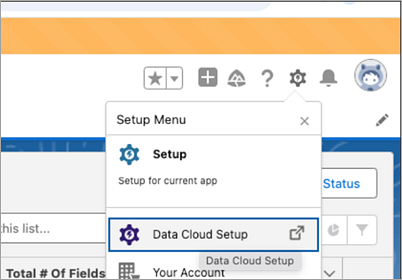
Dans la zone de recherche rapide, saisissez API Ingestion, puis sélectionnez API Ingestion dans les résultats.
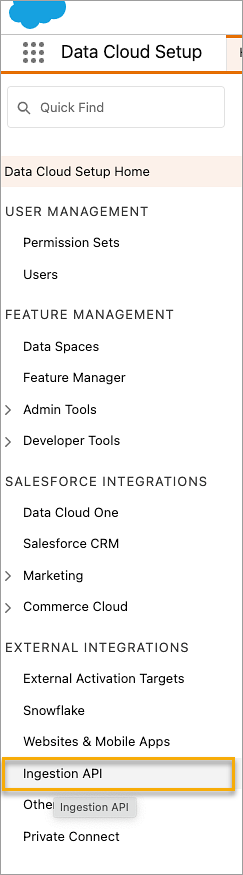
Dans la page API Ingestion, vous verrez les connecteurs disponibles répertoriés sous Nom du connecteur.
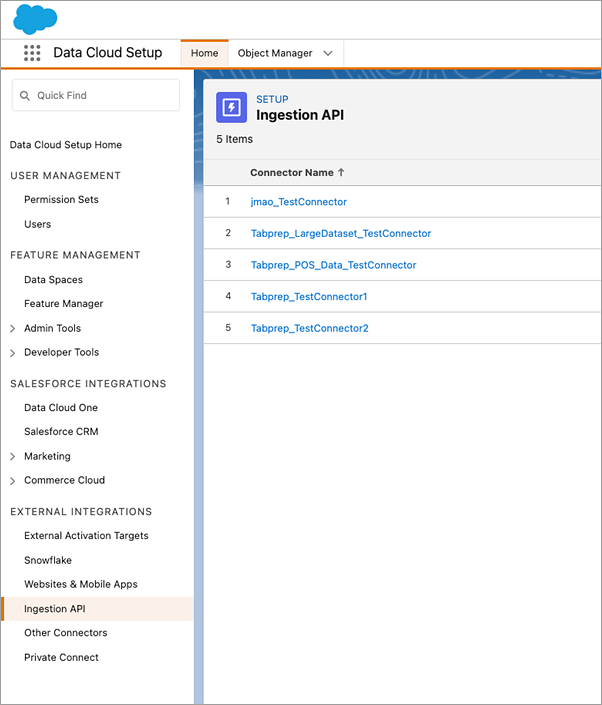
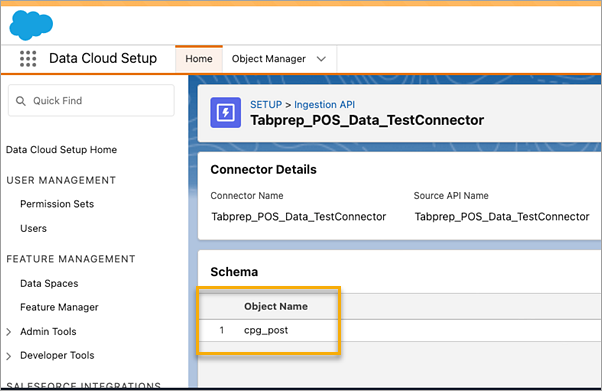
Pour trouver le Nom de l’objet correspondant pour le connecteur que vous souhaitez utiliser, sélectionnez un connecteur dans la liste. Dans la page Détails du connecteur sous la section Schéma, vous verrez les objets correspondants répertoriés sous Nom de l’objet.
- La section Options d’écriture indique que les lignes existantes seront mises à jour si la valeur spécifiée existe déjà dans une table, ou qu’une nouvelle ligne sera insérée si la valeur spécifiée n’existe pas déjà.
- Cliquez sur Exécuter le flux pour exécuter le flux et écrire vos données dans Data Cloud.
- Validez les données dans Data Cloud en affichant l’état d’exécution dans le flux de données et les objets dans l’explorateur de données.

Une fenêtre de navigateur s’ouvrira pour https://login.salesforce.com/.



Considérations
- Vous ne pouvez exécuter qu’un flux à la fois. L’exécution doit être terminée dans Data Cloud avant qu’une autre sortie de sauvegarde puisse être exécutée.
- L’enregistrement d’un flux dans Data Cloud peut demander un certain temps. Vérifiez l’état dans Data Cloud.
- Les données sont enregistrées dans Data Cloud à l’aide de la fonction Upsert. Si un enregistrement dans un fichier correspond à un enregistrement existant, l’enregistrement existant est mis à jour avec les valeurs de vos données. Si aucune correspondance n’est trouvée, l’enregistrement est créé en tant que nouvelle entité.
- Pour Prep Conductor, si vous planifiez l’exécution automatique du même flux, les données ne seront pas mises à jour. En effet, seul Upsert est pris en charge.
- Vous ne pouvez pas abandonner le travail pendant le processus d’enregistrement dans Data Cloud.
- Les champs enregistrés dans Data Cloud ne font pas l’objet d’une validation. Validez les données dans Data Cloud.
Conditions préalables à la configuration de Data Cloud
Ces étapes sont une condition préalable à l’enregistrement des flux Tableau Prep dans Data Cloud. Pour des informations détaillées sur les concepts de Data Cloud et le mappage des données entre les sources de données Tableau et Data Cloud, consultez À propos de Salesforce Data Cloud.
Configurer un connecteur d’API Ingestion
Créez un flux de données d’API Ingestion à partir de vos objets source en chargeant un fichier de schéma au format OpenAPI (OAS) avec une extension de fichier .yaml. Le fichier de schéma décrit la façon dont les données de votre site Web sont structurées. Pour plus d’informations, consultez les articles Exemples de fichier YAML et API d’ingestion.
- Clique l’icône d’engrenage Installation, puis sur Installation de Data Cloud.
- Cliquez sur API Ingestion.
- Cliquez sur Nouveau et fournissez un nom de connecteur.
- Dans la page de détails du nouveau connecteur, chargez un fichier de schéma au format OpenAPI (OAS) avec une extension de fichier
.yaml. Le fichier de schéma décrit la façon dont les données transférées via l’API sont structurées. - Cliquez sur Enregistrer dans le formulaire d’aperçu du schéma.
Remarque : les schémas de l’API Ingestion ont des exigences définies. Voir Exigences du schéma avant l’ingestion.
Créer un flux de données
Un flux de données est une source de données importée dans Data Cloud. Il se compose des connexions et des données associées ingérées dans Data Cloud.
- Accédez au lanceur d’applications et sélectionnez Data Cloud.
- Cliquez sur l’onglet Flux de données.
- Cliquez sur Nouveau et sélectionnez API Ingestion, puis cliquez sur Suivant.
- Sélectionnez l’API Ingestion et les objets.
- Sélectionnez l’espace de données, la catégorie et la clé primaire, puis cliquez sur Suivant.
- Cliquez sur Déployer.
Une véritable clé primaire doit être utilisée pour Data Cloud. S’il n’en existe pas, vous devez créer un champ de formule pour la clé primaire.
Pour Catégorie, choisissez entre Profil, Engagement ou Autre. Un champ datetime doit être présent pour les objets destinés à la catégorie d’engagement. Les objets de type profil ou autre n’imposent pas cette même exigence. Pour plus d’informations, voir Catégorie et Clé primaire.
Vous disposez désormais d’un flux de données et d’un objet lac de données. Votre flux de données peut désormais être ajouté à un espace de données.

Ajouter votre flux de données à un espace de données
Lorsque vous importez des données depuis n’importe quelle source vers Data Cloud, vous associez les objet lac de données (DLO, pour Data Lake Objects) à l’espace de données approprié avec ou sans filtres.
- Cliquez sur l’onglet Espaces de données.
- Choisissez l’espace de données par défaut ou le nom de l’espace de données auquel vous êtes affecté.
- Cliquez sur Ajouter des données.
- Sélectionnez l’objet lac de données que vous avez créé et cliquez sur Suivant.
- (Facultatif) sélectionnez des filtres pour l’objet.
- Cliquez sur Enregistrer.

Mapper l’objet lac de données aux objets Salesforce
Le mappage des données relie les champs Objet lac de données aux champs Objet modèle de données (DMO, pour Data Model Object).
- Accédez à l’onglet Flux de données et sélectionnez le flux de données que vous avez créé.

- Dans la section Mappage de données, cliquez sur Commencer.
L’espace de mappage de champs affiche vos objets DLO sources à gauche et vos objets DMO cibles à droite. Pour plus d’informations, consultez Carte des objets modèle de données.
Créer une application cliente externe ou une application connectée pour l’API Ingestion de Data Cloud
Avant de pouvoir envoyer des données dans Data Cloud à l’aide de l’API Ingestion, vous devez configurer Salesforce de manière à utiliser une application cliente externe (recommandé) ou une application connectée (obsolète). Pour plus d’informations, consultez les articles suivants dans l’aide de Salesforce :
Pour les applications clientes externes : Configuration des paramètres OAuth de l’application cliente externe(Le lien s’ouvre dans une nouvelle fenêtre) et Création d’une application cliente externe(Le lien s’ouvre dans une nouvelle fenêtre)
Pour les applications connectées : Activation des paramètres OAuth pour l’intégration à l’API et Création d’une application connectée pour l’API Ingestion de Data Cloud.
Dans le cadre de la configuration de votre application cliente externe ou de votre application connectée pour l’API Ingestion, vous devez sélectionner les portées OAuth suivantes :
- Accéder et gérer vos données d’API Ingestion de Data Cloud (cdp_ingest_api).
- Gérer les données de profil Data Cloud (cdp_profile_api)
- Exécuter des requêtes SQL ANSI sur les données Data Cloud (cdp_query_api)
- Gérer les données des utilisateurs via des API (api)
- Exécuter des demandes en votre nom à n’importe quel moment (refresh_token, offline_access)
Exigences du schéma
Pour créer une source API Ingestion dans Data Cloud, le fichier de schéma que vous téléchargez doit répondre à des exigences spécifiques. Voir Configuration requise pour le fichier de schéma API Ingestion.
- Les schémas téléchargés doivent être dans un format OpenAPI valide avec une extension .yml ou .yaml. La version OpenAPI 3.0.x est prise en charge.
- Les objets ne peuvent pas avoir d’objets imbriqués.
- Chaque schéma doit avoir au moins un objet. Chaque objet doit avoir au moins un champ.
- Les objets ne peuvent pas avoir plus de 1000 champs.
- Les objets ne peuvent pas comporter plus de 80 caractères.
- Les noms d’objet doivent uniquement contenir les caractères a-z, A-Z, 0–9, _, -. Il ne doit pas y avoir de caractères Unicode.
- Les noms de champs doivent uniquement contenir les caractères a-z, A-Z, 0–9, _, -. Il ne doit pas y avoir de caractères Unicode.
- Les noms de champs ne peuvent pas être l’un de ces mots réservés : date_id, location_id, dat_account_currency, dat_exchange_rate, pacing_period, pacing_end_date, row_count, version. Les noms de champs ne peuvent pas contenir la chaîne __.
- Les noms de champs ne peuvent pas excéder 80 caractères.
- Les champs répondent au type et au format suivants :
- Pour le type texte ou booléen : chaîne
- Pour le type de numéro : numéro
- Pour le type de date : chaîne ; format : date-heure
- Les noms d’objet ne peuvent pas être dupliqués ; insensible à la casse.
- Les objets ne peuvent pas avoir de noms de champs en double ; insensible à la casse.
- Les champs de type de données DateTime dans vos charges utiles doivent être au format ISO 8601 UTC Zulu au format aaaa-MM-jj’T’HH:mm:ss.SSS’Z’.
Lors de la mise à jour de votre schéma, sachez que :
- Les types de données de champ existants ne peuvent pas être modifiés.
- Lors de la mise à jour d’un objet, tous les champs existants pour cet objet doivent être présents.
- Votre fichier de schéma mis à jour inclut uniquement les objets modifiés. Vous n’avez donc pas besoin de fournir une liste complète des objets à chaque fois.
- Un champ datetime doit être présent pour les objets destinés à la catégorie d’engagement. Les objets de type
profileouothern’imposent pas cette même exigence.
Exemples de fichier YAML
openapi: 3.0.3
components:
schemas:
owner:
type: object
required:
- id
- name
- region
- createddate
properties:
id:
type: integer
format: int64
name:
type: string
maxLength: 50
region:
type: string
maxLength: 50
createddate:
type: string
format: date-time
car:
type: object
required:
- car_id
- color
- createddate
properties:
car_id:
type: integer
format: int64
color:
type: string
maxLength: 50
createddate:
type: string
format: date-time Enregistrer les données de sortie de flux dans Amazon S3
Disponible dans Tableau Prep Builder à partir de la version 2024.2, dans la création Web et Tableau Cloud. Cette fonctionnalité n’est pas encore disponible dans Tableau Server.
Vous pouvez vous connecter aux données de n’importe quel connecteur pris en charge par Tableau Prep Builder ou la création Web et enregistrer votre sortie de flux sous forme de fichier .parquet ou .csv sur Amazon S3. La sortie peut être enregistrée en tant que nouvelles données ou vous pouvez remplacer les données S3 existantes. Pour éviter la perte de données, vous pouvez utiliser l’option SQL personnalisé pour faire une copie des données de votre table et l’exécuter avant d’enregistrer les données de flux sur S3.
La sauvegarde de votre sortie de flux et la connexion au connecteur S3 sont indépendantes l’une de l’autre. Vous ne pouvez pas réutiliser une connexion S3 existante que vous avez utilisée comme connexion d’entrée Tableau Prep.
Le volume total de données et le nombre d’objets que vous pouvez stocker dans Amazon S3 sont illimités. La taille des objets Amazon S3 individuels peut varier d’un minimum de 0 octet à un maximum de 5 To. L’objet le plus volumineux pouvant être téléchargé dans un seul PUT est de 5 Go. Pour les objets de plus de 100 Mo, les clients doivent envisager d’utiliser la fonctionnalité de téléchargement partitionné. Consultez Téléchargement et copie d’objets à l’aide du téléchargement partitionné.
Autorisations
Pour écrire dans votre compartiment Amazon S3, vous avez besoin des éléments suivants : région et nom du compartiment, ID de la clé d’accès et clé d’accès secrète. Pour obtenir ces clés, vous devrez créer un utilisateur de gestion des identités et des accès (IAM) au sein d’AWS. Consultez Gestion des clés d’accès pour les utilisateurs IAM.
Enregistrer les données de flux dans Amazon S3
- Cliquez sur l’icône plus dans une étape et sélectionnez Ajouter une sortie.
- Dans la liste déroulante Enregistrer la sortie dans, sélectionnez Stockage sur les bases de données et le cloud.
- Dans la section Table > Connexion, sélectionnez Amazon S3 (sortie uniquement).
- Dans le formulaire Amazon S3 (sortie uniquement), ajoutez les informations suivantes :
- ID de clé d’accès : ID de clé utilisé pour signer les demandes que vous envoyez à Amazon S3.
- Clé d’accès secrète : informations d’identification de sécurité (mots de passe, clés d’accès) utilisées pour vérifier que vous avez l’autorisation d’accéder à la ressource AWS.
- Région du compartiment : emplacement du compartiment Amazon S3 (point de terminaison de la région AWS). Par exemple : us-east-2.
- Nom du compartiment : le nom du compartiment S3 dans lequel vous souhaitez écrire la sortie du flux. Les noms de compartiment de deux comptes AWS dans la même région ne peuvent pas être identiques.
Remarque : pour trouver votre région S3 et le nom de votre compartiment, connectez-vous à votre compte AWS S3 et accédez à la console AWS S3.
- Cliquez sur Connexion.
- Dans le champ URI S3, saisissez le nom du fichier
.csvou.parquet. Par défaut, le champ est renseigné avecs3://<your_bucket_name>. Le nom du fichier doit inclure l’extension.csvou.parquet.Vous pouvez enregistrer la sortie du flux en tant que nouvel objet S3 ou remplacer un objet S3 existant.
- Pour un nouvel objet S3, entrez le nom du fichier
.parquetou.csv. L’URI est affiché dans le texte d’aperçu. Par exemple :s3://<bucket_name><name_file.csv>. - Pour remplacer un objet S3 existant, saisissez le nom du fichier
.parquetou.csvou cliquez sur Parcourir pour trouver les fichiers S3.parquetou.csvexistants.Remarque : la fenêtre Parcourir l’objet affichera uniquement les fichiers qui ont été enregistrés lors de connexions précédentes à Amazon S3.
- Pour un nouvel objet S3, entrez le nom du fichier
- Pour les options d’écriture, un nouvel objet S3 est créé avec les données de votre flux. Si les données existent déjà, les structures ou propriétés de données existantes définies pour l’objet sont supprimées et remplacées par de nouvelles données de flux. Tous les champs du flux sont ajoutés au nouvel objet S3.
- Cliquez sur Exécuter le flux pour lancer l’opération et écrire vos données sur S3.
Vous pouvez vérifier que les données ont été enregistrées sur S3 en vous connectant à votre compte AWS S3 et en accédant à la console AWS S3.