Tabellenberechnungsfunktionen
In diesem Artikel werden Tabellenberechnungsfunktionen sowie deren Verwendung in Tableau vorgestellt. Außerdem wird das Erstellen einer Tabellenberechnung mithilfe des Berechnungs-Editors dargestellt.
Warum werden Tabellenberechnungsfunktionen verwendet?
Mithilfe von Tabellenberechnungsfunktionen können Sie Berechnungen mit den Werten in einer Tabelle durchführen.
So können Sie beispielsweise den Prozentwert der Gesamtsumme eines einzelnen Verkaufsprodukts für das Jahr oder für mehrere Jahre berechnen.
In Tableau verfügbare Tabellenberechnungsfunktionen
Dies sind die nativen Tabellenberechnungsfunktionen, die in Tableau ohne eine externe Analytics-Erweiterung verwendet werden können.
FIRST( )
Gibt die Anzahl an Zeilen von der aktuellen Zeile bis zur ersten Zeile in der Partition zurück. In der Ansicht unten ist der Umsatz nach Quartal dargestellt. Wenn FIRST() mit der Datumspartition berechnet wird, beträgt der Versatz von der ersten Zeile zur zweiten Zeile -1.

Beispiel
Bei einem aktuellen Zeilenindex von 3 gilt: FIRST()
= -2.
INDEX( )
Gibt den Index der aktuellen Zeile in der Partition zurück, ohne nach einem Wert zu sortieren. Der Index der ersten Zeile beginnt bei 1. Beispiel: In der Tabelle unten ist der Umsatz nach Quartal dargestellt. Wenn INDEX() mit der Datumspartition berechnet wird, lautet der Index der jeweiligen Zeile 1, 2, 3, 4... usw.

Beispiel
Für die dritte Zeile in der Partition gilt: INDEX() = 3.
LAST( )
Gibt die Anzahl an Zeilen von der aktuellen Zeile bis zur letzten Zeile in der Partition zurück. Beispiel: In der Tabelle unten ist der Umsatz nach Quartal dargestellt. Wenn LAST() mit der Datumspartition berechnet wird, beträgt der Versatz von der letzten Zeile zur zweiten Zeile 5.

Beispiel
Bei einem aktuellen Zeilenindex von 3 von 7 gilt: LAST() = 4.
LOOKUP(expression, [offset])
Gibt den Wert des Ausdrucks in einer Zielzeile als relativen Versatz von der aktuellen Zeile zurück. Verwenden Sie FIRST() + n und LAST() - n als Teil der Versatzdefinition für ein Ziel relativ zur ersten/letzten Zeile in der Partition. Wenn der offset nicht angegeben wird, kann die Vergleichszeile im Feldmenü festgelegt werden. Diese Funktion gibt NULL zurück, wenn die Zielzeile nicht festgelegt werden kann.
In der Ansicht unten ist der Umsatz nach Quartal dargestellt. Wenn LOOKUP (SUM(Sales), 2) mit der Datumspartition berechnet wird, wird in jeder Zeile der Umsatzwert aus dem zweitfolgenden Quartal angezeigt.

Beispiel
LOOKUP(SUM([Profit]),
FIRST()+2) berechnet in der dritten Zeile der Partition SUM(Profit).
MODEL_EXTENSION-Funktionen
Die Modellerweiterungsfunktionen:
MODEL_EXTENSION_BOOL
MODEL_EXTENSION_INT
MODEL_EXTENSION_REAL
MODEL_EXTENSION_STRING
werden verwendet, um Daten an ein bereitgestelltes Modell auf einem externen Dienst wie R, TabPy oder Matlab zu übergeben. Siehe Analyse-Erweiterungen(Link wird in neuem Fenster geöffnet).
MODEL_PERCENTILE(target_expression, predictor_expression(s))
Gibt die Wahrscheinlichkeit (zwischen 0 und 1) zurück, dass der erwartete Wert kleiner oder gleich der beobachteten Markierung ist, die durch den Zielausdruck und andere Prädiktoren definiert wird. Dies ist die A-Posteriori-Verteilungsfunktion oder kumulative Verteilungsfunktion (CDF, Cumulative Distribution Function).
Diese Funktion ist die Umkehrung von MODEL_QUANTILE. Informationen zu prädiktiven Modellierungsfunktionen finden Sie unter Funktionsweise der Vorhersagemodellierungsfunktionen in Tableau.
Beispiel
Die folgende Formel gibt das Quantil der Markierung für die Summe der Umsätze zurück, bereinigt um die Anzahl der Aufträge.
MODEL_PERCENTILE(SUM([Sales]), COUNT([Orders]))
MODEL_QUANTILE(quantile, target_expression, predictor_expression(s))
Gibt einen numerischen Zielwert innerhalb des wahrscheinlichen Bereichs zurück, der durch den Zielausdruck und andere Prädiktoren bei einem angegebenen Quantil definiert wird. Dies ist das A-Posteriori-Quantil.
Diese Funktion ist die Umkehrung von MODEL_PERCENTILE. Informationen zu prädiktiven Modellierungsfunktionen finden Sie unter Funktionsweise der Vorhersagemodellierungsfunktionen in Tableau.
Beispiel
Die folgende Formel gibt den Median der vorhergesagten Umsatzsumme (0,5) zurück, bereinigt um die Anzahl der Aufträge.
MODEL_QUANTILE(0.5, SUM([Sales]), COUNT([Orders]))
PREVIOUS_VALUE(expression)
Gibt den Wert dieser Berechnung in der vorherigen Zeile zurück. Gibt den entsprechenden Ausdruck zurück, wenn die aktuelle Zeile die erste Zeile der Partition ist.
Beispiel
SUM([Profit]) * PREVIOUS_VALUE(1) errechnet das laufende Produkt von SUM(Profit).
RANK(expression, ['asc' | 'desc'])
Gibt den standardmäßigen Konkurrenzrang für die aktuelle Zeile in der Partition zurück. Identischen Werten wird ein identischer Rang zugewiesen. Verwenden Sie das optionale Argument 'asc' | 'desc', um die aufsteigende oder absteigende Reihenfolge anzugeben. Die Standardeinstellung ist absteigend.
Gemäß dieser Funktion würde der Wertesatz (6, 9, 9, 14) die Rangfolge (4, 2, 2, 1) aufweisen.
Nullen werden in Rangfunktionen ignoriert. Sie werden nicht nummeriert und nicht auf die Gesamtanzahl Datensätze bei Perzentil-Rangberechnungen angerechnet.
Informationen zu verschiedenen Rangoptionen finden Sie unter Berechnung "Rang".
Beispiel
Die folgende Abbildung zeigt die Wirkung der verschiedenen Rangfunktionen (RANK, RANK_DENSE, RANK_MODIFIED, RANK_PERCENTILE und RANK_UNIQUE) auf einen Wertesatz. Der Datensatz umfasst Informationen zu 14 Studenten (Student A bis N). Die Spalte Alter zeigt das aktuelle Alter der Studenten an (alle Studenten sind zwischen 17 und 20 Jahre alt). Die restlichen Spalten zeigen die Auswirkung von jeder Rang-Funktion auf den Wertesatz für das Alter. Dabei wird vorausgesetzt, dass die Standard-Sortierreihenfolge (auf- oder absteigend) für die Funktion verwendet wird.
![]()
RANK_DENSE(expression, ['asc' | 'desc'])
Gibt den dichten Rang für die aktuelle Zeile in der Partition zurück. Identischen Werten wird der gleiche Rang zugewiesen. In die Zahlenreihenfolge werden keine Leerstellen eingefügt. Verwenden Sie das optionale Argument 'asc' | 'desc', um die aufsteigende oder absteigende Reihenfolge anzugeben. Die Standardeinstellung ist absteigend.
Gemäß dieser Funktion würde der Wertesatz (6, 9, 9, 14) die Rangfolge (3, 2, 2, 1) aufweisen.
Nullen werden in Rangfunktionen ignoriert. Sie werden nicht nummeriert und nicht auf die Gesamtanzahl Datensätze bei Perzentil-Rangberechnungen angerechnet.
Informationen zu verschiedenen Rangoptionen finden Sie unter Berechnung "Rang".
RANK_MODIFIED(expression, ['asc' | 'desc'])
Gibt den geänderten Konkurrenzrang für die aktuelle Zeile in der Partition zurück. Identischen Werten wird ein identischer Rang zugewiesen. Verwenden Sie das optionale Argument 'asc' | 'desc', um die aufsteigende oder absteigende Reihenfolge anzugeben. Die Standardeinstellung ist absteigend.
Gemäß dieser Funktion würde der Wertesatz (6, 9, 9, 14) die Rangfolge (4, 3, 3, 1) aufweisen.
Nullen werden in Rangfunktionen ignoriert. Sie werden nicht nummeriert und nicht auf die Gesamtanzahl Datensätze bei Perzentil-Rangberechnungen angerechnet.
Informationen zu verschiedenen Rangoptionen finden Sie unter Berechnung "Rang".
RANK_PERCENTILE(expression, ['asc' | 'desc'])
Gibt den Perzentilrang für die aktuelle Zeile in der Partition zurück. Verwenden Sie das optionale Argument 'asc' | 'desc', um die aufsteigende oder absteigende Reihenfolge anzugeben. Die Standardeinstellung ist aufsteigend.
Gemäß dieser Funktion würde der Wertesatz (6, 9, 9, 14) die Rangfolge (0,00, 0,67, 0,67, 1,00) aufweisen.
Nullen werden in Rangfunktionen ignoriert. Sie werden nicht nummeriert und nicht auf die Gesamtanzahl Datensätze bei Perzentil-Rangberechnungen angerechnet.
Informationen zu verschiedenen Rangoptionen finden Sie unter Berechnung "Rang".
RANK_UNIQUE(expression, ['asc' | 'desc'])
Gibt den eindeutigen Rang für die aktuelle Zeile in der Partition zurück. Identischen Werten werden unterschiedlich Ränge zugewiesen. Verwenden Sie das optionale Argument 'asc' | 'desc', um die aufsteigende oder absteigende Reihenfolge anzugeben. Die Standardeinstellung ist absteigend.
Gemäß dieser Funktion würde der Wertesatz (6, 9, 9, 14) die Rangfolge (4, 2, 3, 1) aufweisen.
Nullen werden in Rangfunktionen ignoriert. Sie werden nicht nummeriert und nicht auf die Gesamtanzahl Datensätze bei Perzentil-Rangberechnungen angerechnet.
Informationen zu verschiedenen Rangoptionen finden Sie unter Berechnung "Rang".
RUNNING_AVG(expression)
Gibt den laufenden Durchschnitt des Ausdrucks zurück, von der ersten Zeile der Partition bis zur aktuellen Zeile.
In der Ansicht unten ist der Umsatz nach Quartal dargestellt. Wenn RUNNING_AVG(SUM([Sales]) mit der Datumspartition berechnet wird, ist das Ergebnis ein laufender Durchschnitt der Umsatzwerte für jedes Quartal.

Beispiel
RUNNING_AVG(SUM([Profit])) errechnet das laufende Produkt von SUM(Profit).
RUNNING_COUNT(expression)
Gibt die laufende Anzahl des Ausdrucks zurück, von der ersten Zeile der Partition bis zur aktuellen Zeile.
Beispiel
RUNNING_COUNT(SUM([Profit])) errechnet die laufende Anzahl von SUM(Profit).
RUNNING_MAX(expression)
Gibt das laufende Maximum des Ausdrucks zurück, von der ersten Zeile der Partition bis zur aktuellen Zeile.

Beispiel
RUNNING_MAX(SUM([Profit])) errechnet das laufende Maximum von SUM(Profit).
RUNNING_MIN(expression)
Gibt das laufende Minimum des Ausdrucks zurück, von der ersten Zeile der Partition bis zur aktuellen Zeile.

Beispiel
RUNNING_MIN(SUM([Profit])) errechnet das laufende Minimum von SUM(Profit).
RUNNING_SUM(expression)
Gibt die laufende Summe des Ausdrucks zurück, von der ersten Zeile der Partition bis zur aktuellen Zeile.

Beispiel
RUNNING_SUM(SUM([Profit])) errechnet die laufende Summe von SUM(Profit).
SIZE()
Gibt die Anzahl an Zeilen in der Partition zurück. In der Ansicht unten ist der Umsatz nach Quartal dargestellt. Innerhalb der Datumspartition gibt es sieben Zeilen. Somit ist Size() der Datumspartition gleich 7.

Beispiel
SIZE() = 5, wenn die aktuelle Partition fünf Zeilen enthält.
SCRIPT_-Funktionen
Die Skriptfunktionen:
SCRIPT_BOOL
SCRIPT_INT
SCRIPT_REAL
SCRIPT_STRING
werden verwendet, um Daten an einen externen Dienst wie R, TabPy oder Matlab zu übergeben. Siehe Analyse-Erweiterungen(Link wird in neuem Fenster geöffnet).
TOTAL(expression)
Gibt den Gesamtwert für den angegebenen Ausdruck in einer Tabellenberechnungspartition zurück.
Beispiel
Angenommen, Sie starten mit dieser Ansicht:

Sie öffnen den Berechnungs-Editor und erstellen ein neues Feld mit dem Namen Gesamtwert:

Dann ziehen Sie das Feld Gesamtwert auf "Text", um SUMME(Umsatz) zu ersetzen. Ihre Ansicht ändert sich insoweit, dass die Werte basierend auf dem Standardwert für Berechnung per summiert werden:

Dabei stellt sich die Frage: "Was ist der Standardwert für Berechnung per?" Wenn Sie mit der rechten Maustaste (Strg-Mausklick auf einem Mac) im Bereich "Daten" auf Gesamtwert klicken, und die Option Bearbeiten auswählen, stehen nun weitere Informationen zur Verfügung:

Der Standardwert für Berechnung per ist Tabelle (quer). Das Ergebnis ist, dass das Feld Gesamtwert die Werte aus jeder Zeile in Ihrer Tabelle summiert. Daher ist der Wert, den Sie in jeder Zeile sehen können, die Summe der Werte aus der Originalversion der Tabelle.
Die Werte in der Zeile "2011/Q1" in der Originaldatei lauten $8601, $6579, $44262 und $15006. Die Werte in der Tabelle, nachdem SUMME(Umsatz) durch Gesamtwert ersetzt wurde, lauten alle $74,448. Dies ist die Summe der vier Originalwerte.
Beachten Sie das Dreieck neben "Gesamtwert", nachdem Sie das Feld auf "Text" gezogen haben:

Dieses gibt an, dass es sich bei dem Feld um eine Tabellenberechnung handelt. Sie können mit der rechten Maustaste auf das Feld klicken und die Option Tabellenberechnung auswählen, um Ihre Funktion mit einem anderen Wert für Berechnung per zu verknüpfen. Sie könnten beispielsweise Tabelle (abwärts) auswählen. In diesem Fall würde Ihre Tabelle wie folgt aussehen:

TOTAL(expression)
Gibt den Gesamtwert für den angegebenen Ausdruck in einer Tabellenberechnungspartition zurück.
Beispiel
Angenommen, Sie starten mit dieser Ansicht:
Sie öffnen den Berechnungs-Editor und erstellen ein neues Feld mit dem Namen Gesamtwert:
Dann ziehen Sie das Feld Gesamtwert auf "Text", um SUMME(Umsatz) zu ersetzen. Ihre Ansicht ändert sich insoweit, dass die Werte basierend auf dem Standardwert für Berechnung per summiert werden:
Dabei stellt sich die Frage: "Was ist der Standardwert für Berechnung per?" Wenn Sie mit der rechten Maustaste (Strg-Mausklick auf einem Mac) im Bereich "Daten" auf Gesamtwert klicken, und die Option Bearbeiten auswählen, stehen nun weitere Informationen zur Verfügung:
Der Standardwert für Berechnung per ist Tabelle (quer). Das Ergebnis ist, dass das Feld Gesamtwert die Werte aus jeder Zeile in Ihrer Tabelle summiert. Daher ist der Wert, den Sie in jeder Zeile sehen können, die Summe der Werte aus der Originalversion der Tabelle.
Die Werte in der Zeile "2011/Q1" in der Originaldatei lauten $8601, $6579, $44262 und $15006. Die Werte in der Tabelle, nachdem SUMME(Umsatz) durch Gesamtwert ersetzt wurde, lauten alle $74,448. Dies ist die Summe der vier Originalwerte.
Beachten Sie das Dreieck neben "Gesamtwert", nachdem Sie das Feld auf "Text" gezogen haben:
Dieses gibt an, dass es sich bei dem Feld um eine Tabellenberechnung handelt. Sie können mit der rechten Maustaste auf das Feld klicken und die Option Tabellenberechnung auswählen, um Ihre Funktion mit einem anderen Wert für Berechnung per zu verknüpfen. Sie könnten beispielsweise Tabelle (abwärts) auswählen. In diesem Fall würde Ihre Tabelle wie folgt aussehen:
WINDOW_AVG(expression, [start, end])
Gibt den Mittelwert des Ausdrucks im Fenster zurück. Das Fenster ist jeweils als Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn der Start und das Ende ausgelassen werden, wird die gesamte Partition verwendet.
Es gibt eine gleichwertige Aggregationsfunktion: AVG. Informationen finden Sie unter Tableau-Funktionen (alphabetisch)(Link wird in neuem Fenster geöffnet).
Beispiel
Die folgende Formel gibt den Fenster-Mittelwert von SUM(Gewinn) und von den beiden vorausgehenden Zeilen bis zur aktuellen Zeile zurück.
WINDOW_AVG(SUM[Profit]), -2, 0)
WINDOW_CORR(expression1, expression2, [Start, Ende])
Gibt den Pearson-Korrelationskoeffizienten von zwei Ausdrücken innerhalb des Fensters zurück. Das Fenster ist jeweils als Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn der Start und das Ende ausgelassen werden, wird die gesamte Partition verwendet.
Bei der Kennzahl der Pearson-Korrelation handelt es sich um eine lineare Beziehung zwischen zwei Variablen. Der Ergebnisbereich liegt zwischen -1 und +1 einschließlich, wobei 1 eine exakte positive lineare Beziehung bezeichnet, d. h. eine positive Änderung einer Variablen impliziert eine positive Änderung des zugehörigen Wertes der anderen Variablen. 0 bedeutet, dass keine lineare Beziehung zwischen der Varianz besteht, und -1 bedeutet eine exakte negative Beziehung.
Es gibt eine gleichwertige Aggregationsfunktion: CORR. Informationen finden Sie unter Tableau-Funktionen (alphabetisch)(Link wird in neuem Fenster geöffnet).
Beispiel
Die folgende Formel gibt die Pearson-Korrelation von SUM(Gewinn) und SUM(Umsatz) von den fünf vorausgehenden bis zur aktuellen Zeile zurück.
WINDOW_CORR(SUM[Profit]), SUM([Sales]), -5, 0)
WINDOW_COUNT(expression, [start, end])
Gibt die Anzahl für den Ausdruck im Fenster zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
Beispiel
WINDOW_COUNT(SUM([Profit]), FIRST()+1, 0) berechnet die Anzahl für SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
WINDOW_COVAR(expression1, expression2, [start, end])
Gibt die Stichprobenkovarianz von zwei Ausdrücken innerhalb des Fensters zurück. Das Fenster ist jeweils als Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn die Start- und Endargumente ausgelassen werden, wird das Fenster zur gesamten Partition.
Die Stichprobenkovarianz verwendet die Anzahl an n – 1 Datenpunkten, die nicht null sind, zum Normalisieren der Kovarianzberechnung, anstelle von n, das von der Populationskovarianz verwendet wird (mit der Funktion "WINDOW_COVARP"). Die Stichprobenkovarianz ist dann die richtige Wahl, wenn es sich bei den Daten um eine Zufallsstichprobe handelt, die zum Schätzen der Kovarianz für eine größere Population verwendet wird.
Es gibt eine gleichwertige Aggregationsfunktion: COVAR. Informationen finden Sie unter Tableau-Funktionen (alphabetisch)(Link wird in neuem Fenster geöffnet).
Beispiel
Die folgende Formel gibt die Stichprobenkovarianz von SUM(Gewinn) und SUM(Umsatz) von den beiden vorausgehenden bis zur aktuellen Zeile zurück.
WINDOW_COVAR(SUM([Profit]), SUM([Sales]), -2, 0)
WINDOW_COVARP(expression1, expression2, [start, end])
Gibt die Populationskovarianz von zwei Ausdrücken innerhalb des Fensters zurück. Das Fenster ist jeweils als Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn der Start und das Ende ausgelassen werden, wird die gesamte Partition verwendet.
Bei der Populationskovarianz handelt es sich um die Stichprobenkovarianz multipliziert mit (n–1)/n, wobei n für die Gesamtanzahl an Datenpunkten steht, die nicht null sind. Die Populationskovarianz ist die geeignete Wahl, wenn für alle gewünschten Elemente Daten vorhanden sind, im Gegensatz zu den Fällen, in denen nur eine zufällige Teilmenge an Elementen vorhanden ist. In solchen Fällen ist die Stichprobenkovarianz (mit der Funktion "WINDOW_COVAR") die geeignete Wahl.
Es gibt eine gleichwertige Aggregationsfunktion: COVARP. Tableau-Funktionen (alphabetisch)(Link wird in neuem Fenster geöffnet).
Beispiel
Die folgende Formel gibt die Populationskovarianz von SUM(Gewinn) und SUM(Umsatz) von den beiden vorausgehenden bis zur aktuellen Zeile zurück.
WINDOW_COVARP(SUM([Profit]), SUM([Sales]), -2, 0)
WINDOW_MEDIAN(expression, [start, end])
Gibt den Median für den Ausdruck im Fenster zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
Beispiel: In der Ansicht unten ist der Gewinn nach Quartal dargestellt. Ein innerhalb der Datumspartition berechneter Fenster-Median gibt den Medianwert des Gewinns über alle Datumsangaben hinweg zurück.

Beispiel
WINDOW_MEDIAN(SUM([Profit]), FIRST()+1, 0) berechnet den kleinsten Wert für SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
WINDOW_MAX(expression, [start, end])
Gibt das Maximum für den Ausdruck im Fenster zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
In der Ansicht unten ist der Umsatz nach Quartal dargestellt. Ein innerhalb der Datumspartition berechneter Fenster-Maximalwert gibt den höchsten Umsatz über alle Datumsangaben hinweg zurück.

Beispiel
WINDOW_MAX(SUM([Profit]), FIRST()+1, 0) berechnet den größten Wert für SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
WINDOW_MIN(expression, [start, end])
Gibt das Minimum für den Ausdruck im Fenster zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
In der Ansicht unten ist der Umsatz nach Quartal dargestellt. Ein innerhalb der Datumspartition berechneter Fenster-Minimalwert gibt den geringsten Umsatz über alle Datumsangaben hinweg zurück.

Beispiel
WINDOW_MIN(SUM([Profit]), FIRST()+1, 0) berechnet den kleinsten Wert für SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
WINDOW_PERCENTILE(expression, number, [start, end])
Gibt den Wert zurück, der dem angegebenen Perzentil innerhalb des Fensters entspricht. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
Beispiel
WINDOW_PERCENTILE(SUM([Profit]), 0.75, -2, 0) gibt das 75. Perzentil für SUM(Profit) von den beiden vorangegangenen Zeilen bis zur aktuellen Zeile zurück.
WINDOW_STDEV(expression, [start, end])
Gibt die Beispielstandardabweichung für den Ausdruck im Fenster zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
Beispiel
WINDOW_STDEV(SUM([Profit]), FIRST()+1, 0) berechnet die Standardabweichung für SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
WINDOW_STDEVP(expression, [start, end])
Gibt die unausgewogene Standardabweichung für den Ausdruck im Fenster zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
Beispiel
WINDOW_STDEVP(SUM([Profit]), FIRST()+1, 0) berechnet die Standardabweichung für SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
WINDOW_SUM(expression, [start, end])
Gibt die Summe des Ausdrucks innerhalb des Fensters zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
In der Ansicht unten ist der Umsatz nach Quartal dargestellt. Eine innerhalb der Datumspartition berechnete Fenster-Summe gibt die Summe der Umsätze über alle Quartale hinweg zurück.

Beispiel
WINDOW_SUM(SUM([Profit]), FIRST()+1, 0) berechnet die Summe für SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
WINDOW_VAR(expression, [start, end])
Gibt die Beispielvarianz für den Ausdruck im Fenster zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
Beispiel
WINDOW_VAR((SUM([Profit])), FIRST()+1, 0) errechnet die Varianz von SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
WINDOW_VARP(expression, [start, end])
Gibt die unausgewogene Varianz für den Ausdruck im Fenster zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
Beispiel
WINDOW_VARP(SUM([Profit]), FIRST()+1, 0) errechnet die Varianz von SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
In Tableau verfügbare Tabellenberechnungsfunktionen von Analytics-Erweiterungen
Analyse-Erweiterungen sind Verbindungen zwischen Tableau und einem externen Dienst wie TabPy für Python, Matlab und R. Um Analyse-Erweiterungen in Ihrer Analyse verwenden zu können, müssen Sie zunächst zwischen Tableau und einem externen Dienst wie einem TabPy-Server eine Verbindung konfigurieren(Link wird in neuem Fenster geöffnet). Anschließend können Sie Skripte in bestimmten Tabellenberechnungen verwenden (MODEL_EXTENSION_ zum Verwenden veröffentlichter benannter Modelle oder SCRIPT_ zum Übergeben eines Ausdrucks an den externen Dienst). Die Daten in der Visualisierung (die „Tabelle“ der Tabellenberechnung) werden sicher an den externen Server übergeben, das Skript wird ausgeführt und die Ergebnisse werden als Ausgabe der Berechnung zurückgegeben.
Modellerweiterungsfunktionen
Zur Verwendung mit benannten Modellen, die auf einem externen TabPy-Dienst bereitgestellt werden.
MODEL_EXTENSION_BOOL (Modellname, Argumente, Ausdruck)
Gibt das boolesche Ergebnis eines Ausdrucks zurück, wie es von einem benannten Modell berechnet wurde, das in einem externen TabPy-Dienst bereitgestellt wird.
Der Modellname ist der Name des bereitgestellten Analysemodells, das Sie verwenden möchten.
Jedes Argument ist eine einzelne Zeichenfolge, die die Eingabewerte festlegt, die das bereitgestellte Modell akzeptiert, und wird durch das Analysemodell definiert.
Verwenden Sie Ausdrücke, um die Werte zu definieren, die von Tableau an das Analysemodell gesendet werden. Achten Sie darauf, Aggregationsfunktionen (SUM, AVG usw.) zu verwenden, um die Ergebnisse zu aggregieren.
Bei Verwendung der Funktion müssen die Datentypen und die Reihenfolge der Ausdrücke mit denen der Eingabeargumente übereinstimmen.
Beispiel
MODEL_EXTENSION_BOOL ("isProfitable","inputSales", "inputCosts", SUM([Sales]), SUM([Costs]))
MODEL_EXTENSION_INT (Modellname, Argumente, Ausdruck)
Gibt ein ganzzahliges Ergebnis eines Ausdrucks zurück, wie von einem benannten Modell berechnet, das in einem externen TabPy-Dienst bereitgestellt wird.
Der Modellname ist der Name des bereitgestellten Analysemodells, das Sie verwenden möchten.
Jedes Argument ist eine einzelne Zeichenfolge, die die Eingabewerte festlegt, die das bereitgestellte Modell akzeptiert, und wird durch das Analysemodell definiert.
Verwenden Sie Ausdrücke, um die Werte zu definieren, die von Tableau an das Analysemodell gesendet werden. Achten Sie darauf, Aggregationsfunktionen (SUM, AVG usw.) zu verwenden, um die Ergebnisse zu aggregieren.
Bei Verwendung der Funktion müssen die Datentypen und die Reihenfolge der Ausdrücke mit denen der Eingabeargumente übereinstimmen.
Beispiel
MODEL_EXTENSION_INT ("getPopulation", "inputCity", "inputState", MAX([City]), MAX ([State]))
MODEL_EXTENSION_REAL (Modellname, Argumente, Ausdruck)
Gibt ein echtes Ergebnis eines Ausdrucks zurück, wie von einem benannten Modell berechnet, das in einem externen TabPy-Dienst bereitgestellt wird.
Der Modellname ist der Name des bereitgestellten Analysemodells, das Sie verwenden möchten.
Jedes Argument ist eine einzelne Zeichenfolge, die die Eingabewerte festlegt, die das bereitgestellte Modell akzeptiert, und wird durch das Analysemodell definiert.
Verwenden Sie Ausdrücke, um die Werte zu definieren, die von Tableau an das Analysemodell gesendet werden. Achten Sie darauf, Aggregationsfunktionen (SUM, AVG usw.) zu verwenden, um die Ergebnisse zu aggregieren.
Bei Verwendung der Funktion müssen die Datentypen und die Reihenfolge der Ausdrücke mit denen der Eingabeargumente übereinstimmen.
Beispiel
MODEL_EXTENSION_REAL ("profitRatio", "inputSales", "inputCosts", SUM([Sales]), SUM([Costs]))
MODEL_EXTENSION_STRING (Modellname, Argumente, Ausdruck)
Gibt das Zeichenfolgenergebnis eines Ausdrucks zurück, wie es von einem benannten Modell berechnet wurde, das in einem externen TabPy-Dienst bereitgestellt wird.
Der Modellname ist der Name des bereitgestellten Analysemodells, das Sie verwenden möchten.
Jedes Argument ist eine einzelne Zeichenfolge, die die Eingabewerte festlegt, die das bereitgestellte Modell akzeptiert, und wird durch das Analysemodell definiert.
Verwenden Sie Ausdrücke, um die Werte zu definieren, die von Tableau an das Analysemodell gesendet werden. Achten Sie darauf, Aggregationsfunktionen (SUM, AVG usw.) zu verwenden, um die Ergebnisse zu aggregieren.
Bei Verwendung der Funktion müssen die Datentypen und die Reihenfolge der Ausdrücke mit denen der Eingabeargumente übereinstimmen.
Beispiel
MODEL_EXTENSION_STR ("mostPopulatedCity", "inputCountry", "inputYear", MAX ([Country]), MAX([Year]))
Skriptfunktionen
Anstatt ein definiertes externes Modell wie etwa MODEL_EXPRESSION-Funktionen zu verwenden, werden SCRIPT-Funktionen verwendet, um den Ausdruck direkt in der Tabellenberechnung zu spezifizieren.
Hinweis: Die Aufrufe erwarten, dass eine einzelne Spalte zurückgegeben wird, die die gleiche Anzahl von Zeilen enthält, die an die Funktion gesendet wurden.
SCRIPT_BOOL
Gibt ein Boolesches Ergebnis für den angegebenen Ausdruck zurück. Der Ausdruck wird direkt an eine laufende Dienstinstanz einer Analyse-Erweiterung übergeben.
In R-Ausdrücken verweisen Sie mit .argn (mit vorangestelltem Punkt) auf Parameter (.arg1, .arg2, usw.).
In Python-Ausdrücken verwenden Sie dagegen _argn (mit vorangestelltem Unterstrich).
Beispiele
In diesem R-Beispiel steht .arg1 für SUM([Profit]):
SCRIPT_BOOL("is.finite(.arg1)", SUM([Profit]))
Das nächste Beispiel gibt "true" für Store-IDs im Bundesstaat Washington zurück, andernfalls "false". Bei diesem Beispiel kann es sich um die Definition für ein berechnetes Feld mit dem Titel IsStoreInWA handeln.
SCRIPT_BOOL('grepl(".*_WA", .arg1, perl=TRUE)',ATTR([Store ID]))
Ein Befehl für Python würde dieses Formular verwenden:
SCRIPT_BOOL("return map(lambda x : x > 0, _arg1)", SUM([Profit]))
SCRIPT_INT
Gibt eine Ganzzahl für den angegebenen Ausdruck zurück. Der Ausdruck wird direkt an eine laufende Dienstinstanz einer Analyse-Erweiterung übergeben.
In R-Ausdrücken verweisen Sie mit .argn (mit vorangestelltem Punkt) auf Parameter (.arg1, .arg2, usw.).
In Python-Ausdrücken verwenden Sie dagegen _argn (mit vorangestelltem Unterstrich).
Beispiele
In diesem R-Beispiel steht .arg1 für SUM([Profit]):
SCRIPT_INT("is.finite(.arg1)", SUM([Profit]))
Im nächsten Beispiel wird k-means-Clustering zur Erstellung von drei Clustern verwendet:
SCRIPT_INT('result <- kmeans(data.frame(.arg1,.arg2,.arg3,.arg4), 3);result$cluster;', SUM([Petal length]), SUM([Petal width]),SUM([Sepal length]),SUM([Sepal width]))
Ein Befehl für Python würde dieses Formular verwenden:
SCRIPT_INT("return map(lambda x : int(x * 5), _arg1)", SUM([Profit]))
SCRIPT_REAL
Gibt eine reelle Zahl für den angegebenen Ausdruck zurück. Der Ausdruck wird direkt an eine laufende Dienstinstanz einer Analyse-Erweiterung übergeben. In
In R-Ausdrücken verweisen Sie mit .argn (mit vorangestelltem Punkt) auf Bezugsparameter (.arg1, .arg2 usw.).
In Python-Ausdrücken verwenden Sie dagegen _argn (mit vorangestelltem Unterstrich).
Beispiele
In diesem R-Beispiel steht .arg1 für SUM([Profit]):
SCRIPT_REAL("is.finite(.arg1)", SUM([Profit]))
Das nächste Beispiel konvertiert Temperaturwerte von Celsius in Fahrenheit.
SCRIPT_REAL('library(udunits2);ud.convert(.arg1, "celsius", "degree_fahrenheit")',AVG([Temperature]))
Ein Befehl für Python würde dieses Formular verwenden:
SCRIPT_REAL("return map(lambda x : x * 0.5, _arg1)", SUM([Profit]))
SCRIPT_STR
Gibt eine Zeichenfolge für den angegebenen Ausdruck zurück. Der Ausdruck wird direkt an eine laufende Dienstinstanz einer Analyse-Erweiterung übergeben.
In R-Ausdrücken verweisen Sie mit .argn (mit vorangestelltem Punkt) auf Parameter (.arg1, .arg2, usw.).
In Python-Ausdrücken verwenden Sie dagegen _argn (mit vorangestelltem Unterstrich).
Beispiele
In diesem R-Beispiel steht .arg1 für SUM([Profit]):
SCRIPT_STR("is.finite(.arg1)", SUM([Profit]))
Das nächste Beispiel extrahiert die Abkürzung für einen Bundesstaat aus einer komplexeren Zeichenfolge (in der Originalform 13XSL_CA, A13_WA):
SCRIPT_STR('gsub(".*_", "", .arg1)',ATTR([Store ID]))
Ein Befehl für Python würde dieses Formular verwenden:
SCRIPT_STR("return map(lambda x : x[:2], _arg1)", ATTR([Region]))
Erstellen einer Tabellenberechnung mithilfe des Berechnungs-Editors
Sehen Sie sich die nachfolgenden Schritte an, um mehr über das Erstellen einer Tabellenberechnung mithilfe des Berechnungs-Editors zu erfahren.
Hinweis: Es gibt viele Möglichkeiten, Tabellenberechnungen in Tableau zu erstellen. In diesem Beispiel wird nur eine der Möglichkeiten dargestellt. Weitere Informationen finden Sie unter Umwandeln von Werten mit Tabellenberechnungen(Link wird in neuem Fenster geöffnet).
Schritt 1: Erstellen der Visualisierung
Stellen Sie in Tableau Desktop eine Verbindung zur standardmäßig in Tableau enthaltenen gespeicherten Datenquelle Beispiel – Superstore her.
Navigieren Sie zu einem Arbeitsblatt.
Ziehen Sie den Wert Bestelldatum aus dem Bereich Daten unter "Dimensionen" in den Spalten-Container.
Ziehen Sie den Wert Unterkategorie aus dem Bereich Daten unter "Dimensionen" in den Zeilen-Container.
Ziehen Sie den Wert Umsatz aus dem Bereich Daten unter "Kennzahlen" in den Bereich Text auf der Karte "Markierungen".
Ihre Visualisierung wird aktualisiert und zeigt eine Texttabelle.
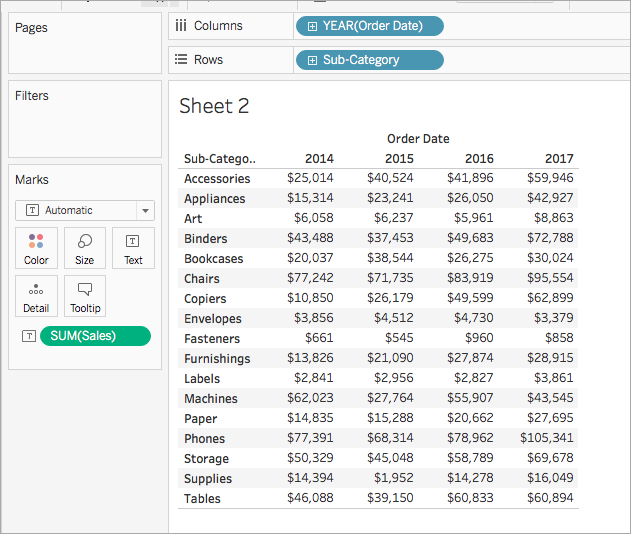
Schritt 2: Erstellen der Tabellenberechnung
Wählen Sie Analyse > Berechnetes Feld erstellen aus.
Gehen Sie in dem Berechnungs-Editor, der daraufhin geöffnet wird, wie folgt vor:
- Geben Sie dem berechnetes Feld den Namen "Laufende Gewinnsumme".
Geben Sie die folgende Formel ein:
RUNNING_SUM(SUM([Profit]))Mit dieser Formel berechnen Sie die laufende Summe der Gewinnumsätze. Sie wird über die gesamte Tabelle hinweg berechnet.
Klicken Sie auf OK, wenn Sie fertig sind.
Das neue Tabellenberechnungsfeld wird unter "Kennzahlen" im Datenbereich angezeigt. Wie bei Ihren anderen Feldern ist die Verwendung in mindestens einer Visualisierung möglich.
Schritt 3: Verwenden der Tabellenberechnung in der Visualisierung
Ziehen Sie den Wert Laufende Gewinnsumme aus dem Bereich "Daten" unter "Kennzahlen" in den Bereich Farbe auf der Karte "Markierungen".
Klicken Sie auf der Karte "Markierungen" auf die Dropdown-Liste "Markierungstyp", und wählen Sie Quadrat aus.
Die Visualisierung wird aktualisiert und zeigt eine Hervorhebungstabelle an:
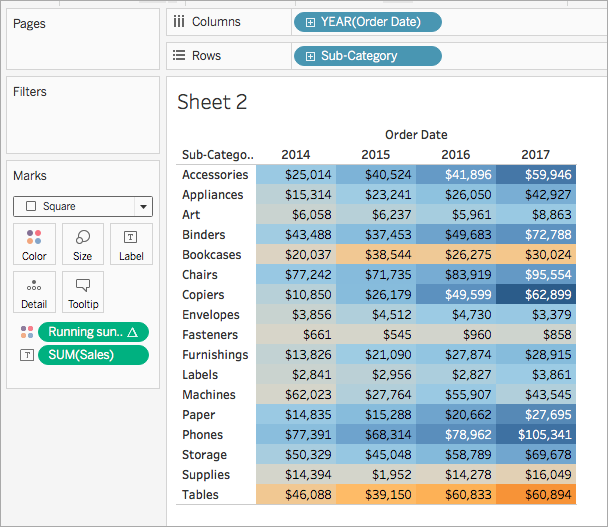
Schritt 4: Bearbeiten der Tabellenberechnung
- Klicken Sie auf der Karte "Markierungen" mit der rechten Maustaste auf Laufende Gewinnsumme, und wählen Sie Tabellenberechnung bearbeiten aus.
Wählen Sie im daraufhin geöffneten Dialogfeld "Tabellenberechnung" die Option Tabelle (Abwärts) unter "Berechnen per" aus.
Die Visualisierung wird aktualisiert und zeigt Folgendes an:
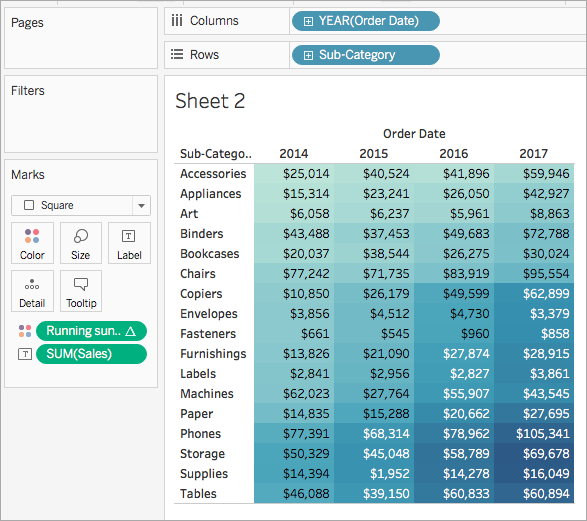
Siehe auch
Erstellen einer Tabellenberechnung(Link wird in neuem Fenster geöffnet)
Typen von Tabellenberechnungen
Anpassen von Tabellenberechnungen(Link wird in neuem Fenster geöffnet)