Encontrar a Segunda data com o Tableau Prep
Uma necessidade comum na análise é determinar a data que um segundo evento acontece, como quando um cliente fez uma segunda compra (se tornando, então, um cliente recorrente) ou se um motorista recebe uma segunda multa de trânsito. Encontrar a data de um primeiro evento é fácil; é simplesmente a data mínima. Encontrar a segunda data é mais complexo.
Neste tutorial de duas partes, definiremos os dados de infração trânsito e responderemos às seguintes perguntas:
Qual foi a duração em dias entre a primeira e a segunda infração de cada motorista?
Compare os valores das multas da primeira e da segunda infração. Elas estão correlacionadas?
Qual motorista pagou mais no total? Quem pagou menos?
Quantos motoristas tinham vários tipos de infrações?
Qual foi o valor médio da multa para os motoristas que nunca fizeram autoescola?
No primeiro estágio, usaremos o Tableau Prep Builder para reestruturar os dados para nossa análise. No segundo estágio, Análise com a segunda data no Tableau Desktop, prosseguiremos para a análise no Tableau Desktop.
A meta deste tutorial é apresentar vários conceitos no contexto de um cenário da vida real e trabalhar com as opções, sem estabelecer uma que seja a melhor de maneira prescritiva. Ao fim, você deve entender melhor como a estrutura de dados influencia os cálculos e as análises, assim como obter uma maior familiaridade com vários aspectos do Tableau Prep e dos cálculos no Tableau Desktop.
Observação: para completar as tarefas neste tutorial, é necessário ter o Tableau Prep Builder (instalado e por navegador) e os dados baixados. Para a segunda parte, você também precisará do Tableau Desktop instalado.
O conjunto de dados é Traffic Violations.xlsx. É recomendado salvá-lo em sua pasta Meu repositório do Tableau Prep > Fontes de dados.
Para instalar o Tableau Prep Builder e o Tableau Desktop antes de continuar com este tutorial, consulte o Guia de implantação do Tableau Desktop e do Tableau Prep(O link abre em nova janela). Caso contrário, é possível baixar as versões gratuitas de avaliação do Tableau Prep(O link abre em nova janela) e do Tableau Desktop(O link abre em nova janela).
Os dados
Para este exemplo, analisamos os dados de infração de trânsito. Cada linha é uma infração. O motorista, a data, o tipo de infração, se o motorista deveria frequentar a autoescola e o valor da multa estão gravados.
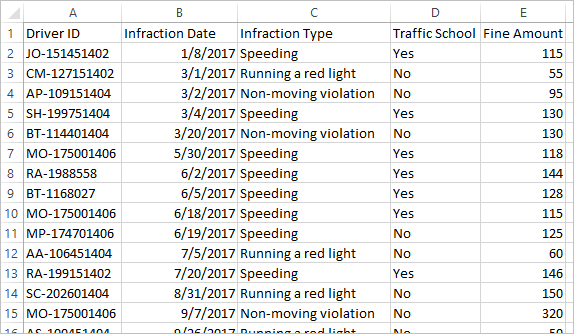
Estrutura de dados desejada
Os dados estão atualmente estruturados de forma que cada linha é uma infração. Um motorista com várias infrações aparece em várias linhas, e não há uma maneira simples de dizer qual foi a primeira ou a segunda infração.
Para investigar os infratores recorrentes, queremos um conjunto de dados que separe as datas da primeira e segunda infrações, além das informações associadas a cada uma delas, e cada linha é um motorista.

Reestruturação dos dados
Como fazemos isso com o Tableau Prep? Criaremos o fluxo em estágios, começando por retirar a data da primeira infração, em seguida a segunda e definindo o conjunto de dados final conforme desejado. Certifique-se de que tenha baixado o arquivo Excel (Traffic Violations.xlsx) para acompanhar.
Agregação inicial da data da primeira infração
Primeiro, vamos conectar ao arquivo Traffic Violations.xlsx.
Abra o Tableau Prep Builder.
Na tela inicial, clique em Conectar aos dados.
No painel Conexões, clique em Microsoft Excel. Navegue até onde você salvou o Traffic Violations.xlsx e clique em Abrir.
A planilha Infrações deverá ser trazida automaticamente para o painel Fluxo.
Para obter mais informações sobre como se conectar a dados, consulte Conectar a dados.
Em seguida, precisamos identificar a data da primeira infração de cada motorista. Usaremos uma etapa Agregação para isso, criando um mini conjunto de dados de ID do motorista e Data mínima da infração.
Ao usar uma etapa de Agregação no Tableau Prep, qualquer campo que defina o que faz uma linha é um Campo agrupado. (Para nós, é a ID do motorista.) Qualquer campo que será agregado e apresentado no nível dos campos agrupados é um Campo agregado. (Para nós, é a Data da infração).
No painel Fluxo, selecione Infrações, clique no ícone de adição
 e selecione Agregação.
e selecione Agregação.Arraste ID do motorista até a área para soltar Campos agrupados.
Arraste Data da infração até a área Campos agregados. A agregação padrão é CNT (contagem). Clique em CNT e altere a agregação para Mínimo.

Isso identifica a menor data (mais recente), que é a primeira data da infração por motorista.
Para obter mais informações sobre as agregações, consulte Limpar e formatar dados.
No painel Fluxo, selecione Agregação 1, clique no ícone de adição
e selecione Etapa de limpeza para que possamos limpar a saída da agregação.No painel Perfil, clique duas vezes no nome do campo Data da infração e altere-o para Data da primeira infração.
Neste estágio, o painel de fluxo e perfil devem ter esta aparência:

No painel Perfil, nesta etapa Limpar, podemos ver que nossos dados agora consistem em 39 linhas e apenas dois campos. Os grupos não usados para agrupamento ou agregação são perdidos. Mas queremos manter algumas das informações originais. Podemos adicionar esses campos ao agrupamento ou à agregação (mas fazer isso altera o nível de detalhe ou requer que os campos sejam agregados) ou unir as colunas desse mini conjunto de dados de volta ao original (adicionando uma nova coluna aos dados originais para a Data da primeira infração). Vamos fazer a união de colunas.
No painel Fluxo, selecione Horários, clique no ícone de adição
e selecione Etapa de limpeza.Certifique-se de focalizar a etapa de Infrações diretamente, não a linha entre ela e a etapa de Agregação. Se a nova etapa de Limpeza for inserida entre os dois em vez de ramificar, use a seta Desfazer na barra de ferramentas e tente novamente. O menu deve indicar Adicionar não Inserir.

Isso ramifica o fluxo com todos os dados originais. Uniremos as colunas dos resultados da agregação a esta cópia dos dados completos. Ao unir colunas na ID do motorista, adicionamos a data mínima da nossa agregação aos dados originais.
Selecione a etapa Limpeza 2, arraste-a para o início da etapa Limpeza 1 e solte em Unir colunas.
A configuração padrão da união de colunas deve estar correta: uma união de colunas interna em ID do motorista = ID do motorista.

Para obter mais informações sobre uniões, consulte Unir colunas de dados.
Como alguns campos podem ser duplicados durante uma união, como os campos na cláusula de união, é uma boa ideia limpar campos irrelevantes após executar uma união de colunas.
No painel Fluxo, selecione União de colunas 1, clique no ícone de adição
e selecione Adicionar etapa.No painel Perfil, clique com o botão direito do mouse ou Ctrl -clique (MacOS) no cartão para Driver ID-1 e selecione Remover.
Para alterar a ordem do campo, arraste o cartão Data da primeira infração entre ID do motorista e Data da infração, onde você verá a linha preta aparecer.
Neste estágio, o fluxo deve ter esta aparência:

Observando a grade de dados abaixo, podemos ver nosso novo conjunto de dados combinado. Temos a data da infração mínima (ou seja, a primeira) de cada motorista adicionada a cada linha no conjunto de dados.
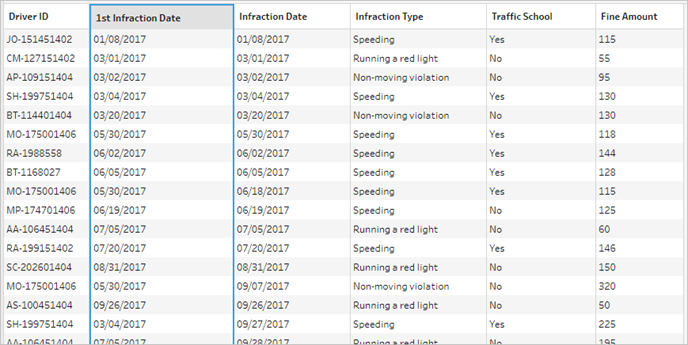
Segunda agregação da data da segunda infração
Também é preciso determinar a data da segunda infração. Para isso, devemos filtrar as linhas onde a data da infração é igual a mínima, removendo, então, a primeira data. Em seguida, podemos pegar o mínimo das datas restantes usando outra etapa de agregação, deixando apenas a data da segunda infração, que renomearemos para ficar mais claro.
Observação: como queremos usar os dados como estão no momento em Limpeza 3, futuramente no fluxo, adicionaremos outra etapa de Limpeza para obter a data da segunda infração. Isso deixará o estado atual dos dados em Limpeza 3 disponível posteriormente.
No painel Fluxo, selecione Limpeza 3, clique no ícone de adição
e selecione Etapa de limpeza.Na barra de ferramentas, no painel Perfil, selecione Filtrar valores. Crie um filtro
[Infraction Date] != [1st Infraction Date].Remova o campo Data da primeira infração.
No painel Fluxo, selecione Limpeza 4, clique no ícone de adição
e selecione Agregação.Arraste ID do motorista até a área para soltar Campos agrupados. Arrase Data da infração até a área Campos agregados e altere a agregação para Mínimo.
No painel Fluxo, selecione Agregação 2, clique no ícone de adição
e selecione Etapa de limpeza. Renomeie Data da infração e Datada segunda infração.
Neste estágio, o fluxo deve ter esta aparência:

Agora temos nossa data da segunda infração identificada para cada motorista. Para obter todas as outras informações associadas a cada infração (tipo, multa, autoescola) precisamos unir colunas novamente ao conjunto de dados completo.
Selecione Limpeza 5, arraste-a para o início da etapa Limpeza 3 e solte em Unir colunas.
Novamente, a configuração padrão da união de colunas deve estar correta: uma união de colunas interna em ID do motorista = ID do motorista.
No painel Fluxo, selecione União de colunas 2, clique no ícone de adição
e selecione Adicionar etapa. Como não eles são mais necessários, exclua os campos ID do motorista-1 e Data da primeira infração.
Neste estágio, o fluxo deve ter esta aparência:

Criar conjuntos de dados completos para a primeira e a segunda infrações
Antes de continuar, vamos voltar e pensar sobre tudo que temos e como queremos unir todas as informações. O estado final que desejamos é um conjunto de dados que pareça com isto, com uma coluna para ID do motorista e colunas para data, tipo, autoescola e montante da multa das primeira e da segunda infração.
Como faremos isso?
Na etapa Limpeza 3, temos nosso conjunto de dados completo com uma coluna que repete a data da primeira infração para cada motorista.

Queremos eliminar todas as linhas de um motorista que não está na primeira infração, criando um conjunto de dados de apenas primeiras infrações. Ou seja, queremos mantes apenas as informações de um determinado motorista quando Data da primeira infração = Data da infração. Depois de filtrar para manter apenas a linha da primeira infração, podemos remover o campo Data da infração organizar os nomes de campo.
De forma semelhante, depois da segunda agregação e união de colunas, teremos nosso conjunto de dados completo com uma coluna para a data da segunda infração.

Podemos executar um filtro semelhante a Data da segunda infração = Data da infração para manter apenas a linha das informações para cada segunda infração do motorista. Novamente, podemos remover também a Data da infração e organizar os nomes de campo.
Começaremos com o conjunto de dados da primeira infração.
No painel Fluxo, selecione Limpeza 3, clique no ícone de adição
e selecione Etapa de limpeza.Como na etapa 10 acima, queremos adicionar uma ramificação para a nova etapa de limpeza, não inseri-la entre Limpeza 3 e Limpeza 4.
Com essa nova etapa Limpeza selecionada, no painel Perfil, clique em Filtrar valores na barra de ferramentas. Crie um filtro
[1st Infraction Date] = [Infraction Date].Remova o campo Data da infração.
Renomeie os campos Tipo de infração, Autoescola e Valor da multa para que comecem com "1º".
Clique duas vezes no nome Limpeza 7 na etapa do painel Fluxo e renomeie como 1º Robusto.
Agora para o conjunto de dados da segunda infração.
No painel Fluxo, selecione Limpeza 6, depois da última união de colunas.
Clique em Filtrar valores na barra de ferramentas. Crie um filtro
[2nd Infraction Date] = [Infraction Date].Remova o campo Data da infração.
Renomeie os campos Tipo de infração, Autoescola e Valor da multa para que comecem com "2º".
Clique duas vezes no nome Limpeza 6 na etapa do painel Fluxo e renomeie como 2º Robusto.
Neste estágio, o fluxo deve ter esta aparência:

Criar o conjunto de dados completo
Agora que temos esses dois conjuntos de dados com informações completas para a primeira e segunda infração por motorista, podemos unir as colunas novamente na ID do motorista e concluir nossa estrutura de dados desejada.
Selecione 2º Robusto, arraste-o para o início do etapa 1º Robusto e solte em Unir colunas.
A cláusula padrão da união de colunas deve estar correta como ID do motorista = ID do motorista.
Como não queremos soltar motoristas que não possuem uma segunda infração, precisamos torná-la uma união de colunas à esquerda. Na área Tipo de união de colunas, clique na área que não está sombreada do diagrama próximo a 1º Robusto, tornando uma união de colunas à esquerda.
No painel Fluxo, selecione União de colunas 3, clique no ícone de sinal de mais
e selecione Etapa de limpeza. Remova o campo ID do motorista-1 duplicado.
Os dados estão no estado esperado, então podemos criar uma saída e prosseguir para a análise.
No painel Fluxo, selecione a Limpeza 6 recém-adicionada, clique no ícone de adição
e selecione Adicionar saída.No painel Saída, altere o Tipo de saída para .csv e clique em Procurar. Insira Infrações do motorista para o nome e selecione o local desejado antes de clicar em Aceitar para salvar.
Clique no botão Executar fluxo
 na parte inferior do painel para gerar a saída. Clique em Concluído na caixa de diálogo do status e feche-a.
na parte inferior do painel para gerar a saída. Clique em Concluído na caixa de diálogo do status e feche-a.
Dica: para obter mais informações sobre as saídas e a execução de um fluxo, consulte Salvar e compartilhar seu trabalho.
O fluxo final deve ter esta aparência:

Observação: é possível baixar o arquivo de fluxo completo para verificar seu trabalho: Driver Infractions.tflx
Resumo
Na primeira etapa desse tutorial, nosso objetivo era pegar o conjunto de dados original e prepará-lo para análise, envolvendo as datas da primeira e da segunda infração. O processo consiste em três fases:
Identificar as datas da primeira e da segunda infração:
Crie uma agregação que mantenha a ID do motorista e Data da infração mínima. Una as colunas ao conjunto de dados original para criar um "conjunto de dados intermediário" que tenha a data da primeira infração (mínima) repetida em cada linha.
Em uma nova etapa, filtre todas as linhas onde a Data da primeira infração seja a mesma da Data da infração. A partir desse conjunto de dados filtrado, crie uma agregação que mantenha a ID do motorista e Data da infração mínima. Una as colunas ao conjunto de dados intermediário da primeira etapa. Isso identifica a segunda data da infração.
Crie conjuntos de dados limpos para a primeira e a segunda infração.
Volte e crie uma extensão a partir do conjunto de dados intermediário e filtre para manter apenas as linhas onde a Data da primeira infração seja a mesma da Data da infração. Isso cria um conjunto de dados apenas para a primeira infração. Organize-o removendo campos desnecessários e renomeie todos os campos desejados (exceto ID do motorista) para indicar que eles são da primeira infração. Este é o conjunto de dados 1º Robusto.
Organize o conjunto de dados para a data da segunda infração. Limpe os resultados da união de colunas da etapa dois filtrando para manter apenas as linhas onde a Data da segunda infração seja a mesma da Data da infração. Remova os campos desnecessários e renomeie todos os campos desejados (exceto ID do motorista) para indicar que eles são da primeira infração. Este é o conjunto de dados 2º Robusto.
Combine os dados da primeira e segunda infração em um conjunto de dados:
Una as colunas aos conjuntos de dados 1º Robusto e 2º Robusto, certificando-se de manter todos os registros do 1º Robusto para evitar perder quaisquer drivers sem uma segunda infração.
Em seguida, queremos explorar como esses dados podem ser analisados no Tableau Desktop.
Observação: agradecimento especial ao tópico do Workout Wednesday da Ann Jackson Os clientes gastam mais na primeira ou na segunda compra?(O link abre em nova janela) e a dica para o Tableau Prep do Andy Kriebel Retornar a primeira e a segunda data de compra(O link abre em nova janela), que forneceram a inspiração inicial para este tutorial. Clicar nestes links o levará para fora do site do Tableau. A Tableau não pode ser responsabilizada pela exatidão ou pela atualidade de páginas mantidas por provedores externos. Entre em contato com os proprietários se você tiver dúvidas a respeito do conteúdo deles.