Stratégie en matière de données
Ce contenu fait partie de Tableau Blueprint, un cadre de maturité vous permettant d’approfondir et d’améliorer la façon dont votre organisation utilise les données pour générer de l’impact. Pour commencer votre voyage, faites notre évaluation(Le lien s’ouvre dans une nouvelle fenêtre).
Les exigences et les solutions au niveau de l’infrastructure de données varient d’une entreprise à l’autre. Tableau respecte les choix de chaque entreprise et s’intègre à votre stratégie de données existante. En plus de l’entrepôt de données d’entreprise, de nombreuses nouvelles sources de données apparaissent à l’intérieur et à l’extérieur de votre organisation : applications et données nuage, bases de données massives, dépôts structurés et non structurés. Des groupements Hadoop aux bases de données NoSQL, et bien d’autres, le flux de données n’a plus besoin d’être centralisé autour de l’entrepôt de données d’entreprise (EDW) comme destination finale.
L’architecture de données moderne repose sur de nouvelles exigences opérationnelles (rapidité, agilité, volume) et de nouvelles technologies. Vous choisissez de fournir l’accès aux données en place ou d’enrichir les données avec d’autres sources. Associez à cela les solutions infonuagiques désormais omniprésentes qui permettent à l’infrastructure et aux services de mettre en place des pipelines de données en quelques heures, vous obtenez le processus idéal pour assurer une mobilité inédite des données au sein de l’entreprise. Malheureusement, la nouvelle occasion est largement ratée si le manuel de gestion des données de votre organisation a été rédigé selon l’état d’esprit traditionnel des compartiments de données d’entreprise en matière de données. L’astuce pour passer des catégories aux pipelines est d’accepter que les réponses à toutes les questions de données au sein d’une organisation puissent être obtenues à partir d’une seule source de données. Le schéma d’une architecture de données moderne est présenté ci-dessous.
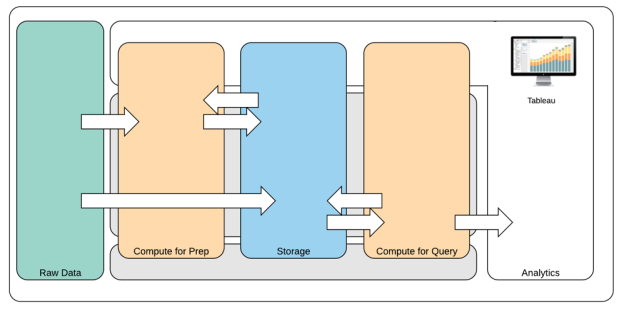
Architecture de données moderne
- Données brutes : sources de données, par exemple, données transactionnelles chargées dans la plateforme de données qui doivent souvent être transformées de plusieurs façons : nettoyage, inspection pour PII, etc.
- Calcul pour la préparation : le traitement des données brutes peut nécessiter des ressources de calcul importantes, donc c’est plus que l’ETL traditionnel. Souvent, les applications de science des données se trouvent ici. Elles peuvent en fait créer de nouvelles données de grande valeur.
- Stockage : Les plateformes de données modernes sont construites sur le principe du stockage des données, car vous ne savez jamais comment elles pourraient être utilisées à l’avenir. De plus en plus, nous stockons des données intermédiaires et plusieurs versions et formats des mêmes données. Le stockage est donc superposé.
- Calcul selon les requêtes : Le moteur de base de données analytique typique, y compris les extraits Hyper, mais aussi Hadoop, etc.
- Analytique : Tableau se trouve dans l’analytique.
Architecture de données hybride de Tableau
L’architecture de données hybride de Tableau offre deux modes d’interaction avec les données, à l’aide d’une connexion en direct ou d’un extrait en mémoire. La commutation entre les deux est aussi facile que de sélectionner la bonne option pour votre cas d’utilisation.
Connexion en direct
Les connecteurs de données de Tableau exploitent votre infrastructure de données existante en envoyant des requêtes dynamiques directement à la base de données source plutôt qu’en important toutes les données. Cela signifie que si vous avez investi dans des bases de données rapides et optimisées par l’analytique, vous pouvez profiter des avantages de cet investissement en vous connectant en direct à vos données. Cela laisse les données détaillées dans le système source et envoie les résultats agrégés des requêtes à Tableau. De plus, cela signifie que Tableau peut utiliser efficacement des quantités illimitées de données. En fait, Tableau est le client d’analyse de première ligne d’un grand nombre des plus grandes bases de données au monde. Tableau a optimisé chaque connecteur pour tirer parti des caractéristiques uniques de chaque source de données.
Extrait en mémoire
Si vous disposez d’une architecture de données basée sur des bases de données transactionnelles ou si vous souhaitez réduire la charge de travail de l’infrastructure de données de base, le moteur de données de Tableau alimenté par la technologie Hyper fournit un stockage de données en mémoire optimisé pour les analyses. Vous pouvez vous connecter et extraire vos données pour les mettre en mémoire afin d’effectuer des requêtes dans Tableau en un clic. L’utilisation d’extraits de données Tableau peut grandement améliorer l’expérience utilisateur en réduisant le temps nécessaire pour effectuer une nouvelle requête dans la base de données. En retour, les extraits libèrent le serveur de base de données du trafic de requête redondant.
Les extraits sont une excellente solution pour les systèmes transactionnels très actifs qui ne peuvent pas se permettre les ressources requises pour traiter les requêtes fréquentes. L’extrait peut être actualisé tous les soirs et mis à la disposition des utilisateurs pendant la journée. Les extraits peuvent également être des sous-ensembles de données fondés sur un nombre fixe d’enregistrements, un pourcentage d’enregistrements totaux ou des critères filtrés. Le moteur de données peut même effectuer des extractions incrémentielles qui mettent à jour les extraits existants avec de nouvelles données. Les extraits ne sont pas destinés à remplacer votre base de données, sélectionnez donc la taille de l’extrait en fonction de l’analyse à effectuer.
Si vous devez partager vos classeurs avec des utilisateurs qui n’ont pas un accès direct aux sources de données sous-jacentes, vous pouvez exploiter les extraits. Les classeurs intégrés de Tableau (type de fichier .twbx) contiennent toutes les analyses et les données utilisées pour le classeur, ce qui le rend à la fois portable et partageable avec d’autres utilisateurs Tableau.
Si un utilisateur publie un classeur en utilisant un extrait, ce dernier est également publié sur Tableau Server ou Tableau Cloud. L’interaction future avec le classeur utilisera l’extrait au lieu de demander des données en direct. S’il est activé, le classeur peut être configuré pour demander une actualisation automatique de l’extrait en fonction d’une programmation.
Requête fédérée
Lorsque des données connexes sont stockées dans des tableaux dans différentes bases de données ou fichiers, vous pouvez utiliser une jointure entre bases de données pour combiner les tableaux. Pour créer une jointure entre bases de données, vous créez une source de données multiconnexion Tableau en ajoutant les différentes bases de données (y compris les fichiers Excel et texte), puis en vous connectant à chacune d’elle, avant de joindre les tables. Les jointures entre bases de données peuvent être utilisées avec des connexions en direct ou des extraits en mémoire.
Serveur de données
Inclus avec Tableau Server et Tableau Cloud, le serveur de données offre des fonctionnalités de partage et de gestion centralisée des extraits de données Tableau et des connexions aux bases de données proxy communes. Tous les utilisateurs de Tableau Server ou de Tableau Cloud peuvent ainsi accéder à des sources de données gouvernées, mesurées et gérées sans dupliquer d’extrait ni de connexion aux données dans plusieurs classeurs.
Dans la mesure où plusieurs classeurs peuvent se connecter à une même source de données, vous pouvez limiter la prolifération des sources de données incorporées, et réduire l’espace de stockage requis et les temps de traitement. Lorsque quelqu’un télécharge un classeur connecté à une source de données publiée qui elle-même est connectée à un extrait, l’extrait reste sur Tableau Server ou Tableau Cloud, ce qui réduit le trafic réseau. Enfin, si une connexion nécessite un pilote de base de données, vous devez installer et gérer le pilote sur Tableau Server uniquement, et non sur l’ordinateur de chaque utilisateur. De même, sur Tableau Cloud, les pilotes de base de données sont gérés par Tableau pour les sources de données prises en charge.
À l’aide des données initiales collectées grâce aux cas d’utilisation de chaque équipe, l’administrateur de base de données ou le gestionnaire de données publie une source de données certifiée pour chaque source à laquelle les utilisateurs peuvent accéder selon les autorisations qui leur ont été accordées. Les utilisateurs peuvent se connecter directement à une source de données publiée à partir de Tableau Desktop et de Tableau Server ou de Tableau Cloud.
Les sources de données publiées empêchent la prolifération des silos de données et des données non fiables pour l’extrait et les connexions en direct. Les actualisations d’extrait peuvent être programmées. Ainsi, les utilisateurs de toute l’entreprise utilisent les mêmes données partagées et les mêmes définitions. Une source de données publiée peut être configurée de façon à se connecter directement aux données en direct avec une connexion de base de données mandataire. Cela signifie que votre organisation dispose d’un moyen de gérer de façon centralisée les connexions de données, la logique des jointures, les métadonnées et les champs calculés.
En même temps, pour permettre un libre-service et une flexibilité, les utilisateurs peuvent étendre le modèle de données en fusionnant de nouvelles données ou en créant de nouveaux calculs, et permettre de livrer le modèle de données nouvellement défini à la production de manière agile. Les données gérées de façon centralisée ne changeront pas, mais les utilisateurs conservent une certaine souplesse.
Sources de données certifiées
Les administrateurs de base de données et/ou les gestionnaires de données devraient certifier les sources de données publiées pour indiquer aux utilisateurs que les données sont fiables. Les sources de données certifiées arborent un badge de certification unique dans Tableau Server, Tableau Cloud et Tableau Desktop. La zone des commentaires vous permet d’expliquer pourquoi une source de données peut être digne de confiance. Ces notes, ainsi que le nom de la personne qui l’a certifiée, sont accessibles dans Tableau lorsque vous consultez cette source de données. Les sources de données certifiées bénéficient d’un traitement préférentiel dans les résultats de recherche et sont mises en avant dans les listes de sources de données de Tableau Server, Tableau Cloud et Tableau Desktop. Les responsables de projet, les administrateurs de site Tableau Cloud et les administrateurs de site Tableau Server sont autorisés à certifier des sources de données. Pour en savoir plus, consultez l’article Sources de données certifiées.
Sécurité des données
La sécurité des données est de la plus haute importance dans chaque entreprise. Tableau permet aux clients de s’appuyer sur leurs ressources de sécurité des données existantes. Les administrateurs informatiques ont la possibilité de mettre en œuvre la sécurité dans la base de données avec l’authentification de la base de données, dans Tableau avec les autorisations, ou une approche hybride des deux. La sécurité sera appliquée, que les utilisateurs accèdent aux données à partir de vues publiées sur le Web, sur des appareils mobiles ou par Tableau Desktop et Tableau Prep Builder. Les clients privilégient souvent l’approche hybride pour sa flexibilité à gérer différents types de cas d’utilisation. Commencez par établir une classification de sécurité des données pour définir les différents types de données et les niveaux de sensibilité qui existent dans votre organisation.
La méthode d’authentification à la base de données joue un rôle essentiel dans la sécurisation de cette dernière. Ce processus d’authentification est différent de celui de Tableau Server ou de Tableau Cloud : lorsqu’un utilisateur se connecte à Tableau Server ou à Tableau Cloud, il n’est pas encore connecté à la base de données. Ainsi, pour que les mesures de sécurité au niveau des bases de données soient appliquées, les utilisateurs de Tableau Server et de Tableau Cloud doivent également disposer d’identifiants (nom d’utilisateur/mot de passe individuels ou de compte de service) pour se connecter aux bases de données. Pour protéger davantage vos données, Tableau n’a besoin que d’un accès en lecture à la base de données, ce qui empêche les éditeurs de modifier accidentellement les données sous-jacentes. Sinon, dans certains cas, il est utile de donner à l’utilisateur de la base de données la permission de créer des tableaux temporaires. Cela peut offrir des avantages du point de vue des performances et de la sécurité, puisque les données temporaires sont stockées dans la base de données plutôt que dans Tableau. Pour Tableau Cloud, vous devez intégrer les identifiants afin d’actualiser automatiquement les informations de connexion pour la source de données. Pour les sources de données Google et Salesforce.com/fr-ca/, vous pouvez intégrer les identifiants sous la forme de jetons d’accès OAuth 2.0.
Le chiffrement des extraits au repos est une fonctionnalité de sécurité des données vous permettant de chiffrer les extraits .hyper lorsqu'ils sont stockés sur Tableau Server. Les administrateurs de Tableau Server peuvent appliquer le chiffrement de tous les extraits de leur site ou permettre aux utilisateurs de spécifier le chiffrement de tous les extraits associés à des classeurs ou des sources de données publiés spécifiques. Pour plus d’informations, consultez Chiffrement d’extrait au repos.
Si votre entreprise déploie le chiffrement des extraits de données au repos, vous avez la possibilité de configurer Tableau Server pour utiliser AWS comme KMS pour le chiffrement d’extrait. Pour activer AWS KMS ou Azure KMS, vous devez déployer Tableau Server dans AWS ou dans Azure, respectivement, et disposer d’une licence Tableau Advanced Management pour Tableau Server. Dans le scénario AWS, Tableau Server utilise la clé maître client (CMK) de AWS KMS pour générer une clé de données AWS. Tableau Server utilise la clé de données AWS comme clé racine principale pour tous les extraits chiffrés. Dans le scénario Azure, Tableau Server utilise Azure Key Vault pour chiffrer la clé RMK (root master key, ou clé racine principale) pour tous les extraits chiffrés. Cependant, même lorsqu’il est configuré pour une intégration à AWS KMW ou à Azure KMS, le keystore Java natif et le système de gestion de clés local sont toujours utilisés pour le stockage sécurisé des secrets sur Tableau Server. Le AWS KMS ou Azure KMS sert uniquement à chiffrer la clé principale racine pour les extraits chiffrés. Pour en savoir plus, consultez Système de gestion des clés.
Pour Tableau Cloud, toutes les données sont chiffrées au repos par défaut. Avec Advanced Management pour Tableau Cloud, vous pouvez toutefois avoir plus de contrôle sur la rotation et la vérification des clés en exploitant les clés de chiffrement gérées par les clients. Les clés de chiffrement gérées par les clients vous offrent un niveau de sécurité supplémentaire en vous permettant de chiffrer les extraits de données de votre site avec une clé propre au site et gérée par le client. L’instance du système de gestion de clés (KMS) de Salesforce stocke la clé de chiffrement propre au site par défaut pour toute personne qui active le chiffrement sur un site. Le processus de chiffrement suit une hiérarchie de clés. Tout d’abord, Tableau Cloud chiffre un extrait. Ensuite, le système de gestion de clés de Tableau Cloud recherche une clé de données appropriée dans ses caches de clés. Si une clé est introuvable, une clé est générée par l’API KMS GenerateDataKey, à l’aide de l’autorisation accordée par la stratégie de clé associée à la clé. AWS KMS utilise la clé maître client pour générer une clé de données et renvoie une copie en texte brut et une copie chiffrée à Tableau Cloud. Tableau Cloud utilise la copie en texte brut de la clé de données pour chiffrer les données et stocke la copie chiffrée de la clé avec les données chiffrées.
Dans Tableau Server et Tableau Cloud, vous pouvez restreindre l’accès aux données en définissant des filtres utilisateur sur les sources de données. Ainsi, vous pouvez mieux contrôler les données auxquelles les utilisateurs ont accès dans une vue publiée, en fonction de leur compte de connexion à Tableau Server. Grâce à cette technique, une directrice régionale peut accéder aux données concernant la région dont elle a la charge, mais pas celles des autres régions. En combinant ces méthodes, vous pouvez publier une vue ou un tableau de bord unique afin de permettre à un large éventail d’utilisateurs de Tableau Cloud ou de Tableau Server de consulter et d’analyser des données personnalisées et sécurisées. Pour en savoir plus, consultez les pages Sécurité des données et Restreindre l’accès au niveau des lignes de données. Si la sécurité au niveau des lignes est primordiale pour votre cas d’utilisation analytique, vous pouvez exploiter les connexions virtuelles avec des stratégies de données pour mettre en œuvre le filtrage des utilisateurs à grande échelle avec Tableau Data Management, Pour en savoir plus, consultez Connexions virtuelles et stratégie de données.