Ottimizzazione per ambienti con numerose query di estrazione
L’argomento fornisce indicazioni sull’impostazione di una specifica topologia di Tableau Server e di configurazioni per ottimizzare e migliorare le prestazioni in un ambiente con numerose query di estrazione.
Che cos’è un ambiente con numerose query di estrazione? Le estrazioni e le origini dati federate vengono sottoposte a query durante il caricamento di cartelle di lavoro, viste e dashboard, generando un carico di lavoro di query elevato. Pertanto, se disponi di molte estrazioni e origini dati federate, lavori in un "ambiente con numerose query di estrazione".
Se il tuo ambiente è di questo tipo, le sezioni seguenti possono essere utili per valutare se questa configurazione è adatta per te.
Quando utilizzare questa configurazione
Principali motivi alla base di questa configurazione: Hyper è la tecnologia del motore dati ottimizzata per la memoria di Tableau, adatta per l’acquisizione rapida dei dati e l’elaborazione analitica, che la rende fondamentale per ottimizzare i carichi di lavoro con numerose query. Man mano che l’utilizzo delle estrazioni aumenta, è consigliabile configurare il motore dati su nodi dedicati del cluster Tableau Server. Questa configurazione consente a Tableau Server di espandere l’infrastruttura per ottimizzare le prestazioni durante l’esecuzione delle query sulle estrazioni.
Esistono diversi fattori che influiscono sulle prestazioni di Tableau Server durante la visualizzazione del contenuto che utilizza estrazioni e origini dati federate. L’obiettivo in questo caso è ottenere prestazioni delle query uniformi e affidabili durante la visualizzazione del contenuto sul server. Utilizza questa configurazione se nel tuo ambiente si verifica una delle condizioni seguenti:
Stai riscontrando un’ampia variabilità nei tempi di caricamento di una cartella di lavoro e la cartella di lavoro utilizza estrazioni o origini dati federate.
La tua distribuzione di Tableau Server si sta ampliando in termini di numero di utenti Creator, Explorer, Viewer e contenuti basati su estrazioni, quindi desideri espanderla in modo efficiente.
- Noti un conflitto di risorse tra il motore dati e VizQL Server quando Archivio file è presente nel computer.
Analizzi grandi quantità di dati. Questa configurazione aiuta a ottimizzare le prestazioni negli scenari Big Data, sia nell’acquisizione e inserimento dei dati che nella relativa analisi. Per saperne di più su Tableau e i Big Data, consulta Hyper-charge big data analytics using Tableau.
Nota: utilizza la registrazione delle prestazioni lato server per individuare i tempi di esecuzione delle query. Per determinare l’utilizzo delle risorse di Tableau, usa Monitoraggio delle prestazioni per le installazioni di Windows e gli strumenti sysstat o vmstat per le installazioni Linux.
Vantaggi dell’utilizzo di questa configurazione
Questi sono i principali vantaggi della configurazione di nodi dedicati per il motore dati:
I nodi dedicati per il motore dati ridurranno il conflitto di risorse tra le query di estrazione e altri carichi di lavoro con un utilizzo elevato di risorse, come quelli elaborati da VizQL Server.
- Le query di estrazione vengono bilanciate in modo dinamico sui nodi dedicati, tenendo conto dello stato corrente del sistema per garantire che nessun nodo sia sovrautilizzato o sottoutilizzato.
Prestazioni più coerenti nell’esperienza utente durante il caricamento di cartelle di lavoro dipendenti dalle estrazioni. L’obiettivo in questo caso è ottenere prestazioni uniformi e affidabili piuttosto che migliorare le singole query.
Hai maggiore controllo sulla scalabilità orizzontale dei processi di Tableau Server che richiedono più risorse. Se VizQL Server, il motore dati e Gestione componenti in background sono tutti in esecuzione sullo stesso nodo e le query di estrazione risultano lente, sarà difficile osservare miglioramenti delle prestazioni aggiungendo un secondo nodo con tutti e tre i processi. Con questa configurazione, puoi aggiungere più nodi che miglioreranno in modo specifico i carichi di lavoro delle query di estrazione.
Consente di migliorare la disponibilità e il tempo di attività. Se a causa di un errore uno dei nodi dedicati per il motore dati non è disponibile, VizQL Server tenterà di instradare le richieste in sospeso sul nodo in cui si è verificato il problema ad altri nodi dedicati per il motore dati.
Il motore dati sfrutta tutti i core disponibili nel computer. Di conseguenza, puoi aggiungere in modo flessibile ulteriori risorse ai nodi dedicati per il motore dati, in modo da ridurre i tempi di risposta delle query e la variabilità sulle query di estrazione costose. In alternativa, puoi aggiungere altri nodi dedicati per il motore dati per ottenere una maggiore velocità delle query di estrazione nel server.
Il motore dati ha una configurazione predefinita che ne limita l’utilizzo medio al 75% della CPU ogni ora. Lo scopo di questa limitazione è evitare conflitti con altri processi di Tableau Server. Se esegui il motore dati su un nodo dedicato, puoi aumentare questo utilizzo medio al 95%. Per informazioni su come eseguire questa operazione, consulta hyper.srm_cpu_limit_percentage.
Quando non utilizzare questa configurazione
Se non riscontri problemi con il caricamento delle query basate su estrazioni, potrebbe essere preferibile allocare le risorse hardware ad altre parti di Tableau Server.
Nei nodi in cui coesistono Archivio file, il motore dati e VizQL Server non si verificano conflitti di risorse tra il motore dati e VizQL Server.
Prima di implementare la configurazione, è consigliabile valutare l’utilizzo della CPU per VizQL Server e per il nodo in cui il motore dati è installato con Archivio file.
Configurazione
L’obiettivo principale di questa configurazione è avere il motore dati su uno o più nodi dedicati.
Nelle distribuzioni in cui Archivio file è installato in locale, questo significa configurare Archivio file su uno o più nodi dedicati. Il motore dati viene installato automaticamente sullo stesso nodo di Archivio file.
Nelle distribuzioni che prevedono la configurazione di un archivio file esterno, puoi comunque configurare il motore dati su nodi dedicati in Tableau Server.
Separando i processi di VizQL Server e Archivio file, il carico tra le query delle estrazioni e la visualizzazione o l’interazione con le viste può essere bilanciato e gestito in modo migliore. Questa configurazione è pensata per garantire prestazioni uniformi durante l’esecuzione di query sulle estrazioni.
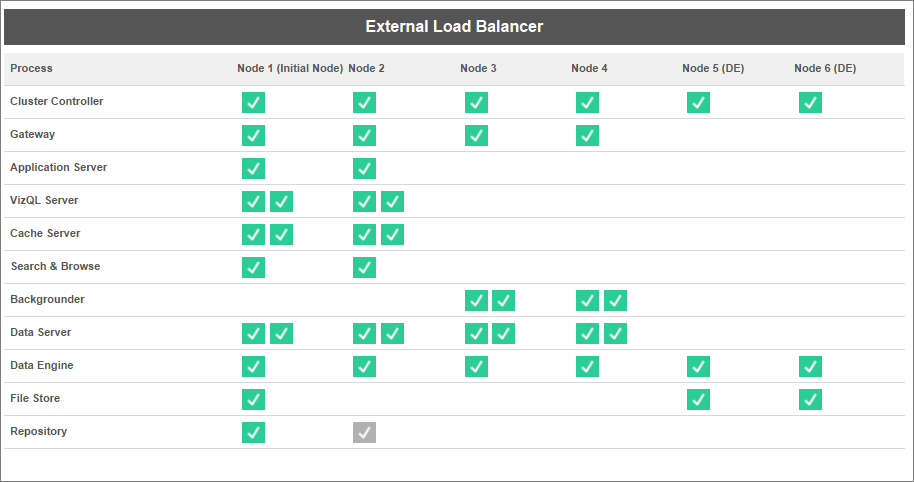
Di seguito è riportata una rappresentazione visiva della configurazione, in cui i processi Motore dati/Archivio file hanno due nodi dedicati, i nodi 5 e 6. Questo è un esempio in cui Archivio file è configurato in locale, pertanto i processi Motore dati e Archivio file sono nella stessa posizione.
La stessa configurazione funziona per le distribuzioni con un archivio file esterno, ma in questo caso nei nodi 5 e 6 sarà configurato solo il motore dati.
Inoltre, poiché Nodo 1 include anche i processi Repository e Archivio file, tutti i dati necessari per eseguire un backup sono presenti su Nodo 1, il che può migliorare le prestazioni di backup.
Indicazioni per l’hardware
Per ottenere il massimo da questa configurazione, dovrai sperimentare varie dimensioni e configurazioni hardware per vedere quale si adatta meglio ai tuoi obiettivi di prestazioni per il carico di picco. Hyper è una tecnologia di database ad alte prestazioni e le risorse chiave che influiscono sulle prestazioni sono memoria, core e I/O di archiviazione. Comprendere come Hyper utilizza le risorse per elaborare le query ti aiuterà a selezionare l’hardware e a valutare le diverse configurazioni.
Memoria: quando una query basata su estrazione viene elaborata per un utente o un processo in background, Tableau Server seleziona un nodo dedicato per il motore dati per elaborare la query. Tale nodo dedicato per il motore dati copierà quindi in memoria l’estrazione dall’archiviazione locale, in genere il disco rigido del server. Una maggiore disponibilità di memoria di sistema consente al sistema operativo di gestire meglio l’utilizzo della memoria per Tableau. I nodi dedicati per il motore dati utilizzano la memoria di sistema per archiviare l’insieme di risultati delle query eseguite. Se l’insieme di risultati è ancora valido e il sistema operativo non lo ha cancellato dalla memoria, l’insieme di risultati in memoria può essere riutilizzato.
La raccomandazione hardware minima per Tableau Server è 32 GB di memoria, ma se prevedi un volume elevato di carichi associati a cartelle di lavoro basate su estrazioni, dovresti prendere in considerazione 64 GB o 128 GB. Se stai raggiungendo altri limiti di risorse oltre alla memoria (come i core), invece di eseguire la scalabilità verticale fino a 128 GB di memoria, potrebbe essere preferibile effettuare la scalabilità orizzontale fino a un nodo dedicato aggiuntivo da 64 GB per il motore dati.
Il processo di copia dell’estrazione dall’archiviazione locale alla memoria può richiedere tempo e potrebbe essere necessaria l’ottimizzazione delle prestazioni del disco. L’ottimizzazione delle prestazioni del disco è trattata nella sezione I/O di archiviazione.
Core: durante l’elaborazione di una query basata su estrazione, il numero di core è un’importante risorsa hardware che può influire sulle prestazioni e sulla scalabilità. I core della CPU sono responsabili dell’esecuzione di una query e una maggiore disponibilità di core si tradurrà in tempi di esecuzione più rapidi. In generale, raddoppiando il numero di core si dimezza il tempo di esecuzione della query. Ad esempio, una query di 10 secondi che attualmente utilizza 4 core fisici o 8 vCPU, impiegherà 5 secondi se esegui l’upgrade a 8 core fisici o 16 vCPU.
L’attuale raccomandazione relativa all’hardware minimo per Tableau Server è di 8 core, ma se la tua distribuzione utilizza le estrazioni, prendi in considerazione computer da 16 o 32 core. Una cosa importante da notare è che se i colli di bottiglia sono la memoria e l’I/O, l’aumento dei core disponibili non migliorerà le prestazioni delle query.
- I/O di archiviazione: Hyper è progettato per sfruttare le prestazioni disponibili del dispositivo di archiviazione dell’estrazione per accelerare l’elaborazione delle query. È consigliabile scegliere un’archiviazione su disco veloce come unità SSD (Solid State Drive) con velocità di lettura/scrittura elevate. Attualmente, le unità SSD che utilizzano il protocollo di archiviazione NVMe offrono le velocità più elevate disponibili.
Nota: il dimensionamento delle risorse per i nodi dedicati per il motore dati influisce solo sulle prestazioni delle query di estrazione. Quando si carica una cartella di lavoro, sono coinvolti molti altri processi che determinano il tempo totale della richiesta di caricamento di VizQL. Il processo VizQL Server, ad esempio, è responsabile dell’acquisizione dei dati dal motore dati e del rendering della visualizzazione.
Altre ottimizzazioni delle prestazioni:
Esistono funzionalità aggiuntive che puoi utilizzare per ottimizzare le prestazioni oltre alla configurazione di base descritta in precedenza. Le ottimizzazioni illustrate di seguito sono applicabili sia alle distribuzioni con archivio file locale che a quelle con archivio file esterno.
Bilanciamento del carico delle query di estrazione: per determinare dove instradare la query di estrazione, il motore dati utilizza una metrica di integrità del server: la quantità di risorse che il motore dati sta consumando e il carico da altri processi di Tableau che potrebbero essere in esecuzione sullo stesso nodo. Oltre a valutare le risorse di sistema, viene preso in considerazione anche l’eventuale presenza di un’estrazione in memoria sul nodo, per garantire che una query di estrazione venga inviata al nodo con la maggiore quantità di risorse disponibili per elaborare la query. Ciò si traduce in un utilizzo più efficiente della memoria e del disco e le estrazioni non vengono duplicate in memoria tra i nodi. Per ulteriori dettagli, consulta l’articolo della Guida Bilanciamento del carico delle query di estrazione.
La funzionalità di bilanciamento del carico delle query di estrazione è abilitata per impostazione predefinita in Tableau Server versione 2020.2 e successive.
Ottimizzazioni del carico di lavoro utilizzando i ruoli dei nodi: con i ruoli dei nodi Gestione componenti in background e Archivio file, gli amministratori del server hanno maggiore flessibilità e controllo su quali nodi devono essere dedicati per l’esecuzione di query di estrazione e aggiornamenti delle estrazioni. Come indicato nel diagramma della topologia riportato sopra, alcuni nodi del motore dati sono dedicati all’elaborazione di query di estrazione ed eseguono solo i processi Archivio file e Motore dati. I ruoli del nodo sono disponibili con Advanced Management. Per maggiori informazioni sui ruoli dei nodi, consulta Gestione del carico di lavoro attraverso i ruoli dei nodi.
Il diagramma seguente utilizza la stessa topologia della configurazione di base descritta in precedenza, ma con i ruoli del nodo.
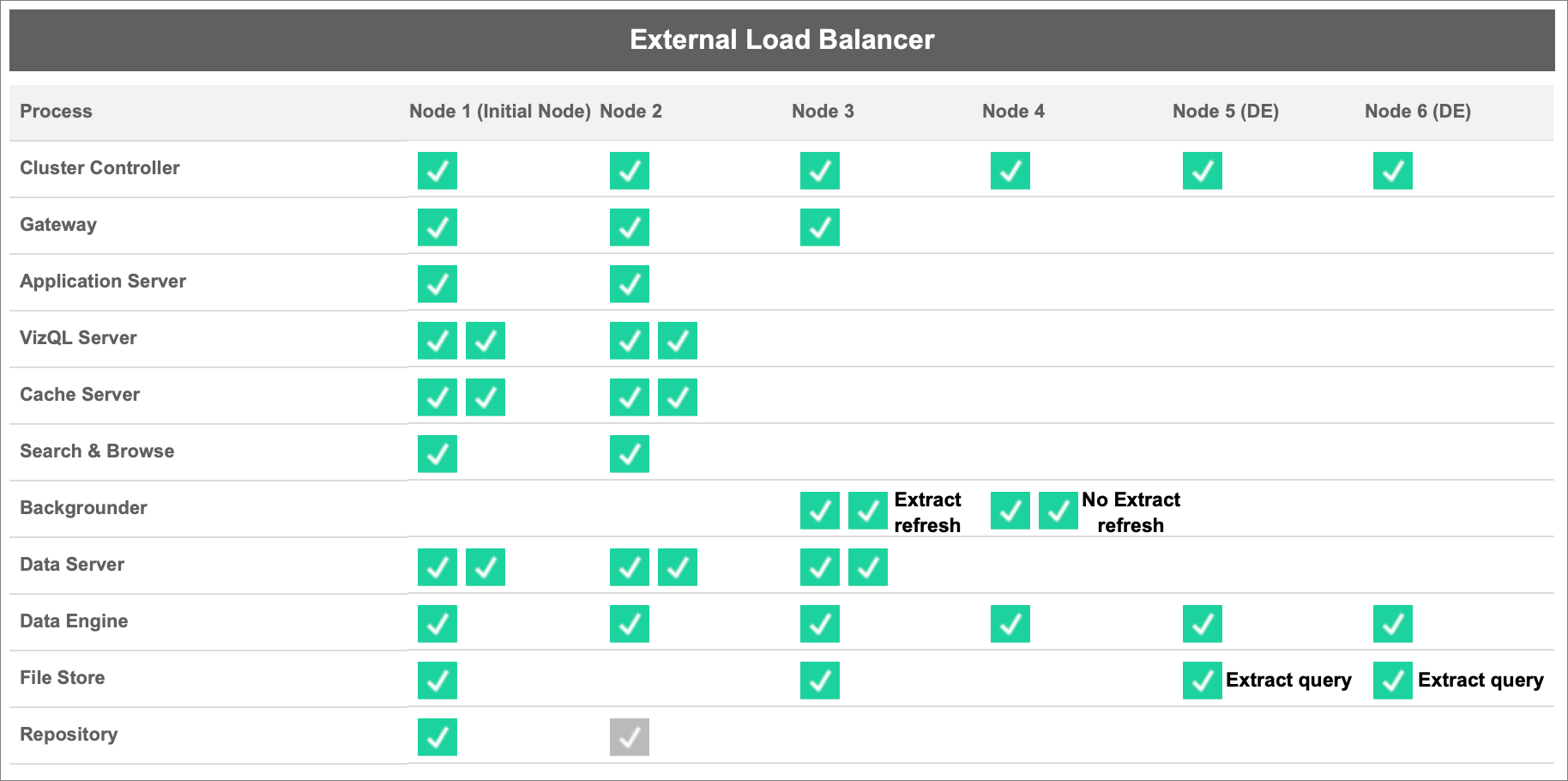
Ruolo del nodo di Gestione componenti in background: impostando il Nodo 3 sul ruolo del nodo di Gestione componenti in background extract-refreshes, in questo nodo verranno eseguiti solo gli aggiornamenti incrementali, gli aggiornamenti completi e i processi di crittografia/decrittografia. Impostando il Nodo 4 sul ruolo del nodo di Gestione componenti in background no-extract-refresh, in questo nodo verranno eseguiti tutti i processi in background diversi dagli aggiornamenti delle estrazioni. Data Server e Gateway supportano i processi di aggiornamento delle estrazioni quando si utilizzano estrazioni federate e shadow. Per maggiori informazioni sui ruoli dei nodi di Gestione componenti in background, consulta Ruoli del nodo Archivio file.
Inoltre, poiché Nodo 1 include anche i processi Repository e Archivio file, tutti i dati necessari per eseguire un backup sono presenti su Nodo 1, il che può migliorare le prestazioni di backup.
I ruoli dei nodi di Gestione componenti in background sono disponibili con Advanced Management in Tableau Server versione 2019.3 e successive.
- Ruolo del nodo di Archivio file extract-queries: i Nodi 5 e 6, che sono i nodi dedicati per il motore dati, hanno il ruolo del nodo di Archivio file extract-queries per garantire che elaborino solo le query per i caricamenti delle visualizzazioni, le sottoscrizioni e gli avvisi basati sui dati.
Ruolo del nodo di Archivio file extract-queries-interactive: per i nodi dedicati per il motore dati con il ruolo del nodo di Archivio file extract-queries, gli amministratori del server possono isolare i carichi di lavoro interattivi e pianificati per l’esecuzione su specifici nodi dedicati per il motore dati. Questo è utile quando ci sono molti utenti che interagiscono e caricano cartelle di lavoro durante periodi con volumi di sottoscrizioni elevati. Ad esempio, supponiamo che siano pianificate 1000 sottoscrizioni per le 8:00 di lunedì mattina. Allo stesso tempo, molti utenti caricano anche le dashboard all’inizio della giornata. Il volume combinato delle query utente e delle sottoscrizioni può comportare per gli utenti tempi di caricamento delle cartelle di lavoro più lenti e variabili. Con il ruolo del nodo Archivio file extract-queries-interactive, puoi designare nodi dedicati del motore dati in modo che accettino solo query per gli utenti interattivi (quelli che stanno osservando i propri schermi in attesa). Questi nodi dedicati per il motore dati a cui viene assegnata la priorità per i carichi di lavoro interattivi saranno protetti dall’elevato volume di processi di sottoscrizione concorrenti e forniranno tempi di query più uniformi. Inoltre, gli amministratori del server possono utilizzare questo ruolo del nodo per pianificare meglio l’espansione, poiché possono aggiungere nodi dedicati per il motore dati per i carichi di lavoro interattivi e pianificati in modo indipendente. Per maggiori informazioni, consulta Ruoli del nodo Archivio file.
I ruoli dei nodi di Archivio file sono disponibili con Advanced Management in Tableau Server versione 2020.4 e successive.
Ottimizzazioni tramite l’archivio file esterno: questa funzionalità consente di utilizzare una condivisione di rete come archiviazione per l’archivio file invece di utilizzare il disco locale su un nodo di Tableau Server. Disponendo dell’archiviazione in una posizione centralizzata, è possibile ridurre significativamente la quantità di traffico di rete per la replica dei dati tra i nodi dell’archivio file. Ad esempio, se l’archivio file utilizza un disco locale, quando un’estrazione da 1 GB viene aggiornata utilizzando l’archivio file in locale, viene replicato in rete 1 GB di dati su tutti i nodi che eseguono il processo Archivio file. Se Tableau Server è configurato con l’archivio file esterno, l’estrazione da 1 GB deve essere copiata nella condivisione di rete solo una volta e tutti i nodi Archivio file possono accedere a quella singola copia. La centralizzazione dell’archiviazione riduce anche la quantità totale di archiviazione locale necessaria sui nodi Archivio file.
Inoltre, i backup di Tableau Server sfruttano la tecnologia snapshot per ridurre significativamente il tempo necessario per completare un backup.
Sebbene non sia necessaria una configurazione con nodi dedicati per il motore dati allo scopo di ottenere i vantaggi dell’archivio file esterno, le funzionalità aggiuntive di gestione del carico di lavoro con il ruolo del nodo Archivio file e il ruolo del nodo Query di estrazione possono essere usate insieme. Consulta l’argomento Archivio file esterno di Tableau Server per maggiori dettagli.
L’Archivio file esterno è disponibile con Advanced Management in Tableau Server versione 2020.1 e successive.