Tableau의 집계 함수
이 문서에서는 Tableau의 집계 함수와 관련 사용법을 소개합니다. 또한 예제를 사용하여 집계 계산을 만드는 방법을 보여 줍니다.
집계 함수를 사용하는 이유
집계 함수를 사용하면 데이터를 요약하거나 세부 수준을 변경할 수 있습니다.
예를 들어 특정 연도에 상점이 처리한 주문 수를 정확히 알고 싶다고 가정합니다. COUNTD 함수를 사용하면 회사의 정확한 고유 주문 수를 집계한 다음 비주얼리제이션을 연도별로 분류할 수 있습니다.
계산은 다음과 비슷한 모양입니다.
COUNTD(Order ID)
비주얼리제이션은 다음과 비슷한 모양입니다.
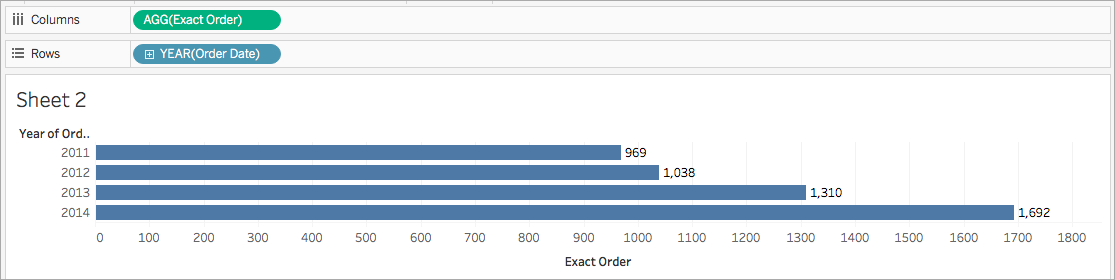
Tableau에서 사용할 수 있는 집계 함수
집계 및 부동 소수점 산술: 일부 집계의 결과가 항상 예상한 결과와 정확하게 일치하는 것은 아닙니다. 예를 들어 SUM 함수는 합계가 정확하게 0이 되어야 한다고 간주되는 숫자 열에 대해 -1.42e-14와 같은 값을 반환한다는 사실을 발견할 수 있습니다. 이는 IEEE(Institute of Electrical and Electronics Engineers) 754 부동 소수점 표준에 따라 숫자는 이진 형식으로 저장해야 하기 때문입니다. 즉, 숫자는 때때로 매우 세밀한 정밀도 수준에서 반올림/반내림됩니다. 소수 자릿수를 덜 표시하도록 숫자의 형식을 지정하거나 ROUND 함수(숫자 함수 참조)를 사용하여 이 잠재적 혼란을 없앨 수 있습니다.
ATTR
| 구문 | ATTR(expression) |
| 정의 | 모든 행에 대해 단일 값이 있으면 식의 값을 반환합니다. 그렇지 않으면 별표를 반환합니다. Null 값은 무시됩니다. |
AVG
| 구문 | AVG(expression) |
| 정의 | 식에서 모든 값의 평균을 반환합니다. Null 값은 무시됩니다. |
| 참고 | AVG는 숫자 필드에서만 사용할 수 있습니다. |
COLLECT
| 구문 | COLLECT(spatial) |
| 정의 | 인수 필드의 값을 결합하는 집계 계산입니다. Null 값은 무시됩니다. |
| 참고 | COLLECT는 공간 필드에만 사용할 수 있습니다. |
CORR
| 구문 | CORR(expression1, expression2) |
| 출력 | -1부터 1까지의 숫자 |
| 정의 | 두 식의 피어슨 상관 계수를 반환합니다. |
| 예 | example |
| 참고 | 피어슨 상관 계수는 두 변수 간의 선형 관계를 측정합니다. 결과는 -1에서 +1(포함) 사이이며, 1은 정확한 양의 선형 관계를 나타내고 0은 변화 사이에 선형 관계가 없음을 나타내고, −1은 정확한 음의 관계를 나타냅니다. CORR 결과의 제곱은 선형 추세선 모델의 R-제곱 값에 해당합니다. 자세한 내용은 추세선 모델 용어(링크가 새 창에서 열림)를 참조하십시오. 테이블 범위 LOD 식과 함께 사용: CORR을 사용하면 테이블 범위 세부 수준 식(링크가 새 창에서 열림)을 통해 집계되지 않은 분산의 상관 관계를 시각화할 수 있습니다. 예: {CORR(Sales, Profit)}세부 수준 식을 사용하면 상관 관계가 모든 행에서 실행됩니다. |
| 데이터베이스 제한 사항 |
다른 데이터 원본의 경우 데이터를 추출하거나 |
COUNT
| 구문 | COUNT(expression) |
| 정의 | 항목 수를 반환합니다. Null 값은 계산되지 않습니다. |
COUNTD
| 구문 | COUNTD(expression) |
| 정의 | 그룹의 고유 항목 수를 반환합니다. Null 값은 계산되지 않습니다. |
COVAR
| 구문 | COVAR(expression1, expression2) |
| 정의 | 두 식의 표본 공분산을 반환합니다. |
| 참고 | 공분산은 두 변수가 함께 변화하는 정도를 정량화합니다. 양의 공분산은 두 변수가 같은 방향으로 이동하는 경향을 나타냅니다. 즉, 한 변수의 값이 커질수록 다른 변수의 값도 평균적으로 커집니다. 표본 공분산에서는 Null이 아닌 n - 1개의 데이터 요소를 사용하여 공분산 계산을 정규화합니다. 모집단 공분산(
|
| 데이터베이스 제한 사항 |
다른 데이터 원본의 경우 데이터를 추출하거나 |
COVARP
| 구문 | COVARP(expression 1, expression2) |
| 정의 | 두 식의 모집단 공분산을 반환합니다. |
| 참고 | 공분산은 두 변수가 함께 변화하는 정도를 정량화합니다. 양의 공분산은 두 변수가 같은 방향으로 이동하는 경향을 나타냅니다. 즉, 한 변수의 값이 커질수록 다른 변수의 값도 평균적으로 커집니다. 모집단 공분산은 표본 공분산에 (n-1)/n을 곱한 값입니다. 여기서, n은 Null이 아닌 데이터 요소의 총 수입니다. 항목의 임의 하위 집합만 있어
|
| 데이터베이스 제한 사항 |
다른 데이터 원본의 경우 데이터를 추출하거나 |
MAX
| 구문 | MAX(expression) 또는 MAX(expr1, expr2) |
| 출력 | 인수와 동일한 데이터 유형이거나, 인수의 일부가 null인 경우 NULL 값이 출력됩니다. |
| 정의 | 두 인수의 최대값을 반환합니다(두 인수가 동일한 데이터 유형이어야 함).
|
| 예 | MAX(4,7) = 7 |
| 참고 | 문자열의 경우
데이터베이스 데이터 원본의 경우 날짜의 경우 날짜의 경우 집계 형식
비교 형식
|
MEDIAN
| 구문 | MEDIAN(expression) |
| 정의 | 모든 레코드에 대한 식의 중앙값을 반환합니다. Null 값은 무시됩니다. |
| 참고 | MEDIAN는 숫자 필드에서만 사용할 수 있습니다. |
| 데이터베이스 제한 사항 |
다른 데이터 원본의 경우 데이터를 추출 파일로 추출하여 이 함수를 사용할 수 있습니다. 데이터 추출(링크가 새 창에서 열림)을 참조하십시오. |
MIN
| 구문 | MIN(expression) 또는 MIN(expr1, expr2) |
| 출력 | 인수와 동일한 데이터 유형이거나, 인수의 일부가 null인 경우 NULL 값이 출력됩니다. |
| 정의 | 두 인수의 최소값을 반환합니다(두 인수가 동일한 데이터 유형이어야 함).
|
| 예 | MIN(4,7) = 4 |
| 참고 | 문자열의 경우
데이터베이스 데이터 원본의 경우 날짜의 경우 날짜의 경우 집계 형식
비교 형식
|
PERCENTILE
| 구문 | PERCENTILE(expression, number) |
| 정의 | 지정된 식에서 지정한 <number>에 해당하는 백분위수 값을 반환합니다. <number>는 0과 1을 포함하여 0에서 1 사이의 상수여야 합니다. |
| 예 | PERCENTILE([Score], 0.9) |
| 데이터베이스 제한 사항 | 이 함수는 레거시가 아닌 Microsoft Excel 및 텍스트 파일 연결, 추출 및 추출 전용 데이터 원본 유형(예: Google Analytics, OData 또는 Salesforce), Sybase IQ 15.1 이상 데이터 원본, Oracle 10 이상 데이터 원본, Cloudera Hive 및 Hortonworks Hadoop Hive 데이터 원본, EXASolution 4.2 이상 데이터 원본 등의 데이터 원본에 사용할 수 있습니다. 다른 데이터 원본의 경우 데이터를 추출 파일로 추출하여 이 함수를 사용할 수 있습니다. 데이터 추출(링크가 새 창에서 열림)을 참조하십시오. |
STDEV
| 구문 | STDEV(expression) |
| 정의 | 샘플 모집단을 기준으로 주어진 식에 있는 모든 값의 통계적 표준 편차를 반환합니다. |
STDEVP
| 구문 | STDEVP(expression) |
| 정의 | 편향 모집단을 기준으로 주어진 식에 있는 모든 값의 통계적 표준 편차를 반환합니다. |
SUM
| 구문 | SUM(expression) |
| 정의 | 식에서 모든 값의 합계를 반환합니다. Null 값은 무시됩니다. |
| 참고 | SUM는 숫자 필드에서만 사용할 수 있습니다. |
VAR
| 구문 | VAR(expression) |
| 정의 | 샘플 모집단을 기준으로 주어진 식에 있는 모든 값의 통계적 분산을 반환합니다. |
VARP
| 구문 | VARP(expression) |
| 정의 | 전체 모집단을 기준으로 주어진 식에 있는 모든 값의 통계적 분산을 반환합니다. |
집계 계산 만들기
아래의 단계를 수행하여 집계 계산을 만드는 방법을 배워 보십시오.
- Tableau Desktop에서 Tableau와 함께 제공된 샘플 – 슈퍼스토어라는 저장된 데이터 원본에 연결합니다.
- 워크시트로 이동하고 분석 > 계산된 필드 만들기를 선택합니다.
- 계산 에디터가 열리면 다음을 수행합니다.
- 계산된 필드의 이름을 Margin으로 지정합니다.
- 다음 수식을 입력합니다.
IIF(SUM([Sales]) !=0, SUM([Profit])/SUM([Sales]), 0)참고: 함수 참조를 사용하여 집계 함수 및 다른 함수(이 예의 경우 논리 IIF 함수)를 찾고 계산 수식에 추가할 수 있습니다. 자세한 내용은 계산 에디터에서 함수 참조 사용을 참조하십시오.
- 작업을 마쳤으면 확인을 클릭합니다.
새 집계 계산이 데이터 패널의 측정값 아래에 나타납니다. 다른 필드와 마찬가지로, 하나 이상의 비주얼리제이션에서 이 필드를 사용할 수 있습니다.
참고: 집계 계산은 항상 측정값입니다.
Margin을 워크시트의 카드 또는 선반에 배치하면 해당 이름이 AGG(Margin)으로 자동 변경되어 집계 계산임을 알 수 있으며 더 이상 집계할 수 없습니다.
집계 계산의 규칙
집계 계산에 적용되는 규칙은 다음과 같습니다.
- 집계 계산에 집계된 값과 집계 해제된 값을 함께 사용할 수 없습니다. 예를 들어
SUM(Price)*[Items]는 SUM(Price)만 집계이고 Items는 집계가 아니기 때문에 유효한 식이 아닙니다. 그러나,SUM(Price*Items)및SUM(Price)*SUM(Items)는 모두 유효합니다. - 식의 상수 항은 집계된 값이나 집계 해제된 값으로 적절하게 적용됩니다. 예를 들면 다음과 같습니다.
SUM(Price*7)과SUM(Price)*7은 둘 다 유효한 식입니다. - 집계된 값에서 모든 함수를 계산할 수 있습니다. 그러나 지정된 함수의 인수는 모두 집계된 상태이거나 모두 집계 해제된 상태여야 합니다. 예를 들어
MAX(SUM(Sales),Profit)의 경우 Sales는 집계되고 Profit은 집계되지 않기 때문에 유효한 식이 아닙니다. 그러나,MAX(SUM(Sales),SUM(Profit))는 유효한 식입니다. - 집계 계산의 결과는 항상 측정값입니다. 여기에는 ATTR(차원) 또는 MIN(차원)과 같은 식이 포함됩니다.
- 미리 정의된 집계와 마찬가지로 집계 계산을 통해 총합계를 올바르게 계산할 수 있습니다. 자세한 내용은 총합계를 참조하십시오.