테이블 계산 함수
이 문서에서는 Tableau의 테이블 계산 함수와 관련 사용법을 소개합니다. 또한 계산 에디터를 사용하여 테이블 계산을 만드는 방법을 보여 줍니다.
테이블 계산 함수를 사용하는 이유
테이블 계산 함수를 사용하면 테이블 내의 값에 대한 계산을 수행할 수 있습니다.
예를 들어 개별 매출의 1년 기준 또는 여러 해 기준의 구성 비율을 계산할 수 있습니다.
Tableau에서 사용할 수 있는 테이블 계산 함수
이는 외부 분석 확장 프로그램 없이도 Tableau에서 사용할 수 있는 기본 테이블 계산 함수입니다.
FIRST( )
현재 행에서 파티션에 있는 첫 번째 행까지의 행 수를 반환합니다. 예를 들어 아래 뷰는 분기별 매출을 보여 줍니다. Date 파티션 내에서 FIRST()를 계산하는 경우, 두 번째 행에서 첫 번째 행의 오프셋은 -1입니다.

예
현재 행 인덱스가 3이면 FIRST()
= -2입니다.
INDEX( )
값에 대한 정렬 없이 파티션에 있는 현재 행의 인덱스를 반환합니다. 첫 번째 행 인덱스는 1에서 시작합니다. 예를 들어 아래 테이블은 분기별 매출을 보여 줍니다. Date 파티션 내에서 INDEX()를 계산하는 경우 각 행의 인덱스는 1, 2, 3, 4 등입니다.

예
파티션의 세 번째 행의 경우 INDEX() = 3입니다.
LAST( )
현재 행에서 파티션에 있는 마지막 행까지의 행 수를 반환합니다. 예를 들어 아래 테이블은 분기별 매출을 보여 줍니다. Date 파티션 내에서 LAST()를 계산하는 경우 두 번째 행에서 마지막 행의 오프셋은 5입니다.

예
현재 행 인덱스가 3/7인 경우 LAST() = 4입니다.
LOOKUP(expression, [offset])
현재 행의 기준 오프셋으로 지정된 대상 행에서 식의 값을 반환합니다. 파티션의 첫 번째/마지막 행을 기준으로 대상에 대한 오프셋 정의의 일부분으로 FIRST() + n 및 LAST() - n을 사용합니다. offset이 생략되면 필드 메뉴에서 비교 대상 행을 설정할 수 있습니다. 대상 행을 확인할 수 없으면 함수는 NULL을 반환합니다.
아래 뷰는 분기별 매출을 보여 줍니다. Date 파티션 내에서 LOOKUP (SUM(Sales), 2)를 계산하는 경우 각 행에 이후 2분기의 매출 값이 표시됩니다.

예
LOOKUP(SUM([Profit]),
FIRST()+2)는 파티션의 세 번째 행에서 SUM(Profit)을 계산합니다.
MODEL_EXTENSION 함수
모델 확장 프로그램 함수는 다음과 같습니다.
MODEL_EXTENSION_BOOL
MODEL_EXTENSION_INT
MODEL_EXTENSION_REAL
MODEL_EXTENSION_STRING
이들은 R, TabPy 또는 Matlab과 같은 외부 서비스에서 배포된 모델에 데이터를 전달하는 데 사용됩니다. 분석 확장 프로그램(링크가 새 창에서 열림)을 참조하십시오.
MODEL_PERCENTILE(target_expression, predictor_expression(s))
대상 식 및 기타 예측자에 의해 정의된 대로 예상 값이 관찰된 마크보다 작거나 같을 확률(0과 1 사이)을 반환합니다. 이것은 누적 분포 함수(CDF)라고도 하는 사후 예측 분포 함수입니다.
이 함수는 MODEL_QUANTILE의 역입니다. 예측 모델링 함수에 대한 자세한 내용은 Tableau에서 예측 모델링 함수가 작동하는 방식을 참조하십시오.
예
다음 수식은 주문 수에 대해 조정된 매출 합계에 대한 마크의 사분위수를 반환합니다.
MODEL_PERCENTILE(SUM([Sales]), COUNT([Orders]))
MODEL_QUANTILE(quantile, target_expression, predictor_expression(s))
지정된 사분위수에서 대상 식 및 기타 예측자에 의해 정의되는 확률 범위 내에서 대상 숫자 값을 반환합니다. 이것은 사후 예측 사분위수입니다.
이 함수는 MODEL_PERCENTILE의 역입니다. 예측 모델링 함수에 대한 자세한 내용은 Tableau에서 예측 모델링 함수가 작동하는 방식을 참조하십시오.
예
다음 수식은 주문 수에 대해 중앙값(0.5) 예측 매출 합계를 반환합니다.
MODEL_QUANTILE(0.5, SUM([Sales]), COUNT([Orders]))
PREVIOUS_VALUE(expression)
이전 행에서 이 계산의 값을 반환합니다. 현재 행이 파티션의 첫 번째 행이면 주어진 식을 반환합니다.
예
SUM([Profit]) * PREVIOUS_VALUE(1)은 SUM(Profit)의 누계 곱을 계산합니다.
RANK(expression, ['asc' | 'desc'])
파티션에 있는 현재 행의 표준 경쟁 순위를 반환합니다. 같은 값에 같은 순위가 할당되었습니다. 오름차순 또는 내림차순을 지정하려면 선택 사항 'asc' | 'desc' 인수를 사용합니다. 기본 순서는 내림차순입니다.
이 함수를 사용하면 값 집합 (6, 9, 9, 14)의 순위가 (4, 2, 2, 1)로 지정됩니다.
Null은 순위 지정 함수에서 무시됩니다. Null은 번호가 지정되지 않고 백분위수 순위 계산에서 총 레코드 수에 대해 계산되지 않습니다.
서로 다른 순위 지정 옵션에 대한 자세한 내용은 순위 계산를 참조하십시오.
예
다음 그림은 값 집합에 대한 다양한 순위 함수(RANK, RANK_DENSE, RANK_MODIFIED, RANK_PERCENTILE 및 RANK_UNIQUE)의 효과를 보여 줍니다. 데이터 집합에는 14명의 학생(Student A ~ Student N)에 대한 정보가 포함되어 있습니다. Age 열에는 각 학생의 현재 나이가 표시됩니다. 모든 학생은 17살에서 20살 사이입니다. 나머지 열에는 항상 함수의 기본 순서(오름차순 또는 내림차순)를 전제로 하여 나이 값 집합에 대한 각 순위 함수의 효과가 표시됩니다.
![]()
RANK_DENSE(expression, ['asc' | 'desc'])
파티션에 있는 현재 행의 조밀 순위를 반환합니다. 동일한 값에는 동일한 순위가 할당되지만 숫자 시퀀스에 간격이 삽입되지 않습니다. 오름차순 또는 내림차순을 지정하려면 선택 사항 'asc' | 'desc' 인수를 사용합니다. 기본 순서는 내림차순입니다.
이 함수를 사용하면 값 집합 (6, 9, 9, 14)의 순위가 (3, 2, 2, 1)로 지정됩니다.
Null은 순위 지정 함수에서 무시됩니다. Null은 번호가 지정되지 않고 백분위수 순위 계산에서 총 레코드 수에 대해 계산되지 않습니다.
서로 다른 순위 지정 옵션에 대한 자세한 내용은 순위 계산를 참조하십시오.
RANK_MODIFIED(expression, ['asc' | 'desc'])
파티션에 있는 현재 행의 수정된 경쟁 순위를 반환합니다. 같은 값에 같은 순위가 할당되었습니다. 오름차순 또는 내림차순을 지정하려면 선택 사항 'asc' | 'desc' 인수를 사용합니다. 기본 순서는 내림차순입니다.
이 함수를 사용하면 값 집합 (6, 9, 9, 14)의 순위가 (4, 3, 3, 1)로 지정됩니다.
Null은 순위 지정 함수에서 무시됩니다. Null은 번호가 지정되지 않고 백분위수 순위 계산에서 총 레코드 수에 대해 계산되지 않습니다.
서로 다른 순위 지정 옵션에 대한 자세한 내용은 순위 계산를 참조하십시오.
RANK_PERCENTILE(expression, ['asc' | 'desc'])
파티션에 있는 현재 행의 백분위수 순위를 반환합니다. 오름차순 또는 내림차순을 지정하려면 선택 사항 'asc' | 'desc' 인수를 사용합니다. 기본값은 오름차순입니다.
이 함수를 사용하면 값 집합 (6, 9, 9, 14)의 순위가 (0.00, 0.67, 0.67, 1.00)으로 지정됩니다.
Null은 순위 지정 함수에서 무시됩니다. Null은 번호가 지정되지 않고 백분위수 순위 계산에서 총 레코드 수에 대해 계산되지 않습니다.
서로 다른 순위 지정 옵션에 대한 자세한 내용은 순위 계산를 참조하십시오.
RANK_UNIQUE(expression, ['asc' | 'desc'])
파티션에 있는 현재 행의 고유 순위를 반환합니다. 값이 동일하면 다른 순위가 할당됩니다. 오름차순 또는 내림차순을 지정하려면 선택 사항 'asc' | 'desc' 인수를 사용합니다. 기본 순서는 내림차순입니다.
이 함수를 사용하면 값 집합 (6, 9, 9, 14)의 순위가 (4, 2, 3, 1)로 지정됩니다.
Null은 순위 지정 함수에서 무시됩니다. Null은 번호가 지정되지 않고 백분위수 순위 계산에서 총 레코드 수에 대해 계산되지 않습니다.
서로 다른 순위 지정 옵션에 대한 자세한 내용은 순위 계산를 참조하십시오.
RUNNING_AVG(expression)
파티션에 있는 첫 번째 행에서 현재 행까지 주어진 식의 누계 평균을 반환합니다.
아래 뷰는 분기별 매출을 보여 줍니다. Date 파티션 내에서 RUNNING_AVG(SUM([Sales])를 계산하는 경우 결과는 각 분기에 대한 매출 값의 누계 평균입니다.

예
RUNNING_AVG(SUM([Profit]))는 SUM(Profit)의 누계 평균을 계산합니다.
RUNNING_COUNT(expression)
파티션에 있는 첫 번째 행에서 현재 행까지 주어진 식의 누계 카운트를 반환합니다.
예
RUNNING_COUNT(SUM([Profit]))는 SUM(Profit)의 누계 카운트를 계산합니다.
RUNNING_MAX(expression)
파티션에 있는 첫 번째 행에서 현재 행까지 주어진 식의 누계 최대값을 반환합니다.

예
RUNNING_MAX(SUM([Profit]))는 SUM(Profit)의 누계 최대값을 계산합니다.
RUNNING_MIN(expression)
파티션에 있는 첫 번째 행에서 현재 행까지 주어진 식의 누계 최소값을 반환합니다.

예
RUNNING_MIN(SUM([Profit]))는 SUM(Profit)의 누계 최소값을 계산합니다.
RUNNING_SUM(expression)
파티션에 있는 첫 번째 행에서 현재 행까지 주어진 식의 누계 합계를 반환합니다.

예
RUNNING_SUM(SUM([Profit]))는 SUM(Profit)의 누계 합계를 계산합니다.
SIZE()
파티션의 행 수를 반환합니다. 예를 들어 아래 뷰는 분기별 매출을 보여 줍니다. Date 파티션 내에 일곱 개의 행이 있으며 Date 파티션의 Size()는 7입니다.

예
현재 파티션에 5개의 행이 있으면 SIZE() = 5입니다.
SCRIPT_ 함수
스크립트 함수:
SCRIPT_BOOL
SCRIPT_INT
SCRIPT_REAL
SCRIPT_STRING
이들은 R, TabPy, Matlab 등의 외부 서비스에 데이터를 전달하는 데 사용됩니다. 분석 확장 프로그램(링크가 새 창에서 열림)을 참조하십시오.
TOTAL(expression)
테이블 계산 파티션 내의 지정된 식에 대한 총계를 반환합니다.
예
다음 뷰에서 시작한다는 것을 전제로 합니다.

계산 에디터를 열고 총액을 나타내는 Totality로 이름을 지정하여 새 필드를 만듭니다.

그런 다음 Totality를 텍스트로 끌어와 SUM(Sales)를 바꿉니다. 뷰는 기본 다음을 사용하여 계산 값을 기반으로 값을 합계하는 방식으로 변경됩니다.

그렇다면 기본 다음을 사용하여 계산 값은 무엇일까요? 데이터 패널에서 Totality를 마우스 오른쪽 단추로 클릭(Mac의 경우 Control 클릭)하여 편집을 선택하면 정보의 추가 부분을 사용할 수 있게 됩니다.

기본 다음을 사용하여 계산 값은 테이블(옆으로)입니다. 결과에서 Totality는 테이블의 각 행별 값의 합계입니다. 따라서 각 행에 나타나는 값은 원래 버전의 테이블 값의 합계입니다.
원래 테이블의 2011/Q1 행 값은 $8601, $6579, $44262 및 $15006였습니다. Totality가 SUM(Sales)을 바꾼 후에 테이블의 값은 모두 $74,448이며 이는 원래 값 4개의 합계입니다.
Totality를 텍스트로 끌어오면 그 옆에 삼각형이 표시됩니다.

이는 이 필드가 테이블 계산임을 나타냅니다. 필드를 마우스 오른쪽 단추로 클릭하고 테이블 계산 편집을 선택하여 함수를 다른 다음을 사용하여 계산 값으로 리디렉션합니다. 예를 들어 테이블(아래로)로 설정할 수 있습니다. 이 경우 테이블 모양은 다음과 같습니다.

TOTAL(expression)
테이블 계산 파티션 내의 지정된 식에 대한 총계를 반환합니다.
예
다음 뷰에서 시작한다는 것을 전제로 합니다.
계산 에디터를 열고 총액을 나타내는 Totality로 이름을 지정하여 새 필드를 만듭니다.
그런 다음 Totality를 텍스트로 끌어와 SUM(Sales)를 바꿉니다. 뷰는 기본 다음을 사용하여 계산 값을 기반으로 값을 합계하는 방식으로 변경됩니다.
그렇다면 기본 다음을 사용하여 계산 값은 무엇일까요? 데이터 패널에서 Totality를 마우스 오른쪽 단추로 클릭(Mac의 경우 Control 클릭)하여 편집을 선택하면 정보의 추가 부분을 사용할 수 있게 됩니다.
기본 다음을 사용하여 계산 값은 테이블(옆으로)입니다. 결과에서 Totality는 테이블의 각 행별 값의 합계입니다. 따라서 각 행에 나타나는 값은 원래 버전의 테이블 값의 합계입니다.
원래 테이블의 2011/Q1 행 값은 $8601, $6579, $44262 및 $15006였습니다. Totality가 SUM(Sales)을 바꾼 후에 테이블의 값은 모두 $74,448이며 이는 원래 값 4개의 합계입니다.
Totality를 텍스트로 끌어오면 그 옆에 삼각형이 표시됩니다.
이는 이 필드가 테이블 계산임을 나타냅니다. 필드를 마우스 오른쪽 단추로 클릭하고 테이블 계산 편집을 선택하여 함수를 다른 다음을 사용하여 계산 값으로 리디렉션합니다. 예를 들어 테이블(아래로)로 설정할 수 있습니다. 이 경우 테이블 모양은 다음과 같습니다.
WINDOW_AVG(expression, [start, end])
창 내 식의 평균을 반환합니다. 창은 현재 행의 오프셋으로 정의됩니다. 파티션의 첫 번째 또는 마지막 행의 오프셋에 대해 FIRST()+n 및 LAST()-n을 사용합니다. 시작 및 끝을 생략하면 전체 파티션이 사용됩니다.
동등한 집계 함수인 AVG가 있습니다. 자세한 내용은 Tableau 함수(사전순)(링크가 새 창에서 열림)을 참조하십시오.
예
다음 수식은 이전 2개 행에서 현재 행까지 SUM(Profit)의 창 평균을 반환합니다.
WINDOW_AVG(SUM[Profit]), -2, 0)
WINDOW_CORR(expression1, expression2, [start, end])
두 식의 창 내 피어슨 상관 계수를 반환합니다. 창은 현재 행의 오프셋으로 정의됩니다. 파티션의 첫 번째 또는 마지막 행의 오프셋에 대해 FIRST()+n 및 LAST()-n을 사용합니다. 시작 및 끝을 생략하면 전체 파티션이 사용됩니다.
피어슨 상관 계수는 두 변수 간의 선형 관계를 측정합니다. 결과는 -1에서 +1(포함) 사이이며, 1은 정확한 양의 선형 관계 즉, 한 변수가 양의 방향으로 변화하면 다른 변수도 해당하는 양만큼 양의 방향으로 변화하는 관계를 나타내고 0은 변화 사이에 선형 관계가 없음을 나타내고, −1은 정확한 음의 관계를 나타냅니다.
동등한 집계 함수인 CORR이 있습니다. 자세한 내용은 Tableau 함수(사전순)(링크가 새 창에서 열림)을 참조하십시오.
예
다음 수식은 이전 5개 행에서 현재 행까지 SUM(Profit) 및 SUM(Sales)의 피어슨 상관 관계를 반환합니다.
WINDOW_CORR(SUM[Profit]), SUM([Sales]), -5, 0)
WINDOW_COUNT(expression, [start, end])
창 내 식의 카운트를 반환합니다. 창은 현재 행의 오프셋으로 정의됩니다. 파티션의 첫 번째 또는 마지막 행의 오프셋에 대해 FIRST()+n 및 LAST()-n을 사용합니다. 시작 및 끝을 생략하면 전체 파티션이 사용됩니다.
예
WINDOW_COUNT(SUM([Profit]), FIRST()+1, 0)은 두 번째 행에서 현재 행까지의 SUM(Profit)의 개수를 계산합니다.
WINDOW_COVAR(expression1, expression2, [start, end])
창 내 두 식의 표본 공분산을 반환합니다. 창은 현재 행의 오프셋으로 정의됩니다. 파티션의 첫 번째 또는 마지막 행의 오프셋에 대해 FIRST()+n 및 LAST()-n을 사용합니다. 시작 및 끝 인수를 생략하면 창은 전체 파티션입니다.
표본 공분산에서는 Null이 아닌 n - 1개의 데이터 요소를 사용하여 공분산 계산을 정규화합니다. 모집단 공분산(COVARP 함수로 사용할 수 있음)에서 사용되는 n개가 아니라는 것에 주의하십시오. 데이터가 대규모 모집단의 분산을 예측하는 데 사용되는 임의 샘플인 경우 표본 공분산을 선택하는 것이 좋습니다.
동등한 집계 함수인 COVAR이 있습니다. 자세한 내용은 Tableau 함수(사전순)(링크가 새 창에서 열림)을 참조하십시오.
예
다음 수식은 이전 2개 행에서 현재 행까지 SUM(Profit) 및 SUM(Sales)의 표본 공분산을 반환합니다.
WINDOW_COVAR(SUM([Profit]), SUM([Sales]), -2, 0)
WINDOW_COVARP(expression1, expression2, [start, end])
창 내 두 식의 모집단 공분산을 반환합니다. 창은 현재 행의 오프셋으로 정의됩니다. 파티션의 첫 번째 또는 마지막 행의 오프셋에 대해 FIRST()+n 및 LAST()-n을 사용합니다. 시작 및 끝을 생략하면 전체 파티션이 사용됩니다.
모집단 공분산은 표본 공분산에 (n-1)/n을 곱한 값입니다. 여기서, n은 Null이 아닌 데이터 요소의 총 수입니다. 항목의 임의 하위 집합만 있어 WINDOW_COVAR 함수를 사용하는 표본 공분산이 적합한 경우와 달리 관심 대상인 모든 항목에서 데이터를 사용할 수 있는 경우 모집단 공분산을 선택하는 것이 좋습니다.
동등한 집계 함수인 COVARP가 있습니다. 자세한 내용은 Tableau 함수(사전순)(링크가 새 창에서 열림)을 참조하십시오.
예
다음 수식은 이전 2개 행에서 현재 행까지 SUM(Profit) 및 SUM(Sales)의 모집단 공분산을 반환합니다.
WINDOW_COVARP(SUM([Profit]), SUM([Sales]), -2, 0)
WINDOW_MEDIAN(expression, [start, end])
창 내 식의 중앙값을 반환합니다. 창은 현재 행의 오프셋으로 정의됩니다. 파티션의 첫 번째 또는 마지막 행의 오프셋에 대해 FIRST()+n 및 LAST()-n을 사용합니다. 시작 및 끝을 생략하면 전체 파티션이 사용됩니다.
예를 들어 아래 뷰는 분기별 수익을 보여 줍니다. Date 파티션 내의 창 중앙값은 모든 날짜의 수익 중앙값을 반환합니다.

예
WINDOW_MEDIAN(SUM([Profit]), FIRST()+1, 0)은 두 번째 행에서 현재 행까지의 SUM(Profit)의 중앙값을 계산합니다.
WINDOW_MAX(expression, [start, end])
창 내 식의 최대값을 반환합니다. 창은 현재 행의 오프셋으로 정의됩니다. 파티션의 첫 번째 또는 마지막 행의 오프셋에 대해 FIRST()+n 및 LAST()-n을 사용합니다. 시작 및 끝을 생략하면 전체 파티션이 사용됩니다.
예를 들어 아래 뷰는 분기별 매출을 보여 줍니다. Date 파티션 내의 창 최대값은 모든 날짜의 최대 매출을 반환합니다.

예
WINDOW_MAX(SUM([Profit]), FIRST()+1, 0)은 두 번째 행에서 현재 행까지의 SUM(Profit)의 최대값을 계산합니다.
WINDOW_MIN(expression, [start, end])
창 내 식의 최소값을 반환합니다. 창은 현재 행의 오프셋으로 정의됩니다. 파티션의 첫 번째 또는 마지막 행의 오프셋에 대해 FIRST()+n 및 LAST()-n을 사용합니다. 시작 및 끝을 생략하면 전체 파티션이 사용됩니다.
예를 들어 아래 뷰는 분기별 매출을 보여 줍니다. Date 파티션 내의 창 최소값은 모든 날짜의 최소 매출을 반환합니다.

예
WINDOW_MIN(SUM([Profit]), FIRST()+1, 0)은 두 번째 행에서 현재 행까지의 SUM(Profit)의 최소값을 계산합니다.
WINDOW_PERCENTILE(expression, number, [start, end])
창 내의 지정된 백분위수에 해당하는 값을 반환합니다. 창은 현재 행의 오프셋으로 정의됩니다. 파티션의 첫 번째 또는 마지막 행의 오프셋에 대해 FIRST()+n 및 LAST()-n을 사용합니다. 시작 및 끝을 생략하면 전체 파티션이 사용됩니다.
예
WINDOW_PERCENTILE(SUM([Profit]), 0.75, -2, 0)은 이전 두 행에서 현재 행까지의 SUM(Profit)에 대한 75번째 백분위수를 반환합니다.
WINDOW_STDEV(expression, [start, end])
창 내 식의 샘플 표준 편차를 반환합니다. 창은 현재 행의 오프셋으로 정의됩니다. 파티션의 첫 번째 또는 마지막 행의 오프셋에 대해 FIRST()+n 및 LAST()-n을 사용합니다. 시작 및 끝을 생략하면 전체 파티션이 사용됩니다.
예
WINDOW_STDEV(SUM([Profit]), FIRST()+1, 0)은 두 번째 행에서 현재 행까지의 SUM(Profit)의 표준 편차를 계산합니다.
WINDOW_STDEVP(expression, [start, end])
창 내 식의 편향 표준 편차를 반환합니다. 창은 현재 행의 오프셋으로 정의됩니다. 파티션의 첫 번째 또는 마지막 행의 오프셋에 대해 FIRST()+n 및 LAST()-n을 사용합니다. 시작 및 끝을 생략하면 전체 파티션이 사용됩니다.
예
WINDOW_STDEVP(SUM([Profit]), FIRST()+1, 0)은 두 번째 행에서 현재 행까지의 SUM(Profit)의 표준 편차를 계산합니다.
WINDOW_SUM(expression, [start, end])
창 내 식의 합계를 반환합니다. 창은 현재 행의 오프셋으로 정의됩니다. 파티션의 첫 번째 또는 마지막 행의 오프셋에 대해 FIRST()+n 및 LAST()-n을 사용합니다. 시작 및 끝을 생략하면 전체 파티션이 사용됩니다.
예를 들어 아래 뷰는 분기별 매출을 보여 줍니다. Date 파티션 내에서 계산된 창 합계는 모든 분기의 매출 합계를 반환합니다.

예
WINDOW_SUM(SUM([Profit]), FIRST()+1, 0)은 두 번째 행에서 현재 행까지의 SUM(Profit)의 합계를 계산합니다.
WINDOW_VAR(expression, [start, end])
창 내 식의 샘플 분산을 반환합니다. 창은 현재 행의 오프셋으로 정의됩니다. 파티션의 첫 번째 또는 마지막 행의 오프셋에 대해 FIRST()+n 및 LAST()-n을 사용합니다. 시작 및 끝을 생략하면 전체 파티션이 사용됩니다.
예
WINDOW_VAR((SUM([Profit])), FIRST()+1, 0)은 두 번째 행에서 현재 행까지의 SUM(Profit)의 분산을 계산합니다.
WINDOW_VARP(expression, [start, end])
창 내 식의 편향 분산을 반환합니다. 창은 현재 행의 오프셋으로 정의됩니다. 파티션의 첫 번째 또는 마지막 행의 오프셋에 대해 FIRST()+n 및 LAST()-n을 사용합니다. 시작 및 끝을 생략하면 전체 파티션이 사용됩니다.
예
WINDOW_VARP(SUM([Profit]), FIRST()+1, 0)은 두 번째 행에서 현재 행까지의 SUM(Profit)의 분산을 계산합니다.
Tableau에서 사용할 수 있는 분석 확장 프로그램 테이블 계산 함수
분석 확장 프로그램은 Tableau와 Python, Matlab 및 R용 TabPy와 같은 외부 서비스 간의 연결입니다. 분석에 분석 확장 프로그램을 사용하려면 먼저 Tableau와 TabPy 서버와 같은 외부 서비스 간의 연결(링크가 새 창에서 열림)을 구성해야 합니다. 그런 다음 특정 테이블 계산 내부에서 스크립트를 사용할 수 있습니다(게시된 명명된 모델을 사용하는 경우 MODEL_EXTENSION_, 외부 서비스에 식을 전달하는 경우 SCRIPT_). 비주얼리제이션의 데이터(테이블 계산의 'table')가 외부 서버로 안전하게 전달되고, 스크립트가 실행되고, 결과가 계산의 출력으로 다시 전달됩니다.
모델 확장 프로그램 함수
TabPy 외부 서비스에 배포된 명명된 모델과 함께 사용됩니다.
MODEL_EXTENSION_BOOL(모델_이름, 인수, 식)
TabPy 외부 서비스에서 배포한 명명된 모델로 계산된 식의 부울 결과를 반환합니다.
모델_이름은 사용하려는 배포된 분석 모델의 이름입니다.
각 인수는 배포된 모델이 수락하는 입력 값을 설정하는 단일 문자열이며 분석 모델에 의해 정의됩니다.
Tableau에서 분석 모델로 전송되는 값을 정의할 때는 식을 사용합니다. 집계 함수(SUM, AVG 등)를 사용하여 결과를 집계해야 합니다.
함수를 사용할 때는 식의 데이터 유형 및 순서가 입력 인수의 데이터 유형 및 순서와 일치해야 합니다.
예
MODEL_EXTENSION_BOOL ("isProfitable","inputSales", "inputCosts", SUM([Sales]), SUM([Costs]))
MODEL_EXTENSION_INT(모델_이름, 인수, 식)
TabPy 외부 서비스에서 배포한 명명된 모델로 계산된 식의 정수 결과를 반환합니다.
모델_이름은 사용하려는 배포된 분석 모델의 이름입니다.
각 인수는 배포된 모델이 수락하는 입력 값을 설정하는 단일 문자열이며 분석 모델에 의해 정의됩니다.
Tableau에서 분석 모델로 전송되는 값을 정의할 때는 식을 사용합니다. 집계 함수(SUM, AVG 등)를 사용하여 결과를 집계해야 합니다.
함수를 사용할 때는 식의 데이터 유형 및 순서가 입력 인수의 데이터 유형 및 순서와 일치해야 합니다.
예
MODEL_EXTENSION_INT ("getPopulation", "inputCity", "inputState", MAX([City]), MAX ([State]))
MODEL_EXTENSION_REAL(모델_이름, 인수, 식)
TabPy 외부 서비스에서 배포한 명명된 모델로 계산된 식의 실수 결과를 반환합니다.
모델_이름은 사용하려는 배포된 분석 모델의 이름입니다.
각 인수는 배포된 모델이 수락하는 입력 값을 설정하는 단일 문자열이며 분석 모델에 의해 정의됩니다.
Tableau에서 분석 모델로 전송되는 값을 정의할 때는 식을 사용합니다. 집계 함수(SUM, AVG 등)를 사용하여 결과를 집계해야 합니다.
함수를 사용할 때는 식의 데이터 유형 및 순서가 입력 인수의 데이터 유형 및 순서와 일치해야 합니다.
예
MODEL_EXTENSION_REAL ("profitRatio", "inputSales", "inputCosts", SUM([Sales]), SUM([Costs]))
MODEL_EXTENSION_STRING(모델_이름, 인수, 식)
TabPy 외부 서비스에서 배포한 명명된 모델로 계산된 식의 문자열 결과를 반환합니다.
모델_이름은 사용하려는 배포된 분석 모델의 이름입니다.
각 인수는 배포된 모델이 수락하는 입력 값을 설정하는 단일 문자열이며 분석 모델에 의해 정의됩니다.
Tableau에서 분석 모델로 전송되는 값을 정의할 때는 식을 사용합니다. 집계 함수(SUM, AVG 등)를 사용하여 결과를 집계해야 합니다.
함수를 사용할 때는 식의 데이터 유형 및 순서가 입력 인수의 데이터 유형 및 순서와 일치해야 합니다.
예
MODEL_EXTENSION_STR ("mostPopulatedCity", "inputCountry", "inputYear", MAX ([Country]), MAX([Year]))
스크립트 함수
MODEL_EXPRESSION 함수와 같은 정의된 외부 모델을 사용하는 대신 SCRIPT 함수를 사용하여 테이블 계산에서 직접 표현식을 지정합니다.
참고: 호출을 실행하면 단일 열이 반환될 것으로 예상되며, 여기에는 함수로 전송된 것과 동일한 수의 행이 포함됩니다.
SCRIPT_BOOL
지정된 표현식의 부울 결과를 반환합니다. 표현식은 실행 중인 Analytics 확장 프로그램 서비스 인스턴스로 직접 전달됩니다.
R 식에서는 .argn(선행 마침표 사용)을 사용하여 매개 변수를 참조합니다(.arg1, .arg2 등).
Python 식에서는 _argn(선행 밑줄 사용)을 사용합니다.
예
이 R 예제에서 .arg1은 SUM([Profit])에 해당합니다.
SCRIPT_BOOL("is.finite(.arg1)", SUM([Profit]))
다음 예는 워싱턴 주의 상점 ID에 대해 True를 반환하고, 그렇지 않은 경우 False를 반환합니다. 이 예는 제목이 IsStoreInWA인 계산된 필드에 대한 정의일 수 있습니다.
SCRIPT_BOOL('grepl(".*_WA", .arg1, perl=TRUE)',ATTR([Store ID]))
Python 명령은 다음과 같은 형식입니다.
SCRIPT_BOOL("return map(lambda x : x > 0, _arg1)", SUM([Profit]))
SCRIPT_INT
지정된 표현식의 정수 결과를 반환합니다. 표현식은 실행 중인 Analytics 확장 프로그램 서비스 인스턴스로 직접 전달됩니다.
R 식에서는 .argn(선행 마침표 사용)을 사용하여 매개 변수를 참조합니다(.arg1, .arg2 등).
Python 식에서는 _argn(선행 밑줄 사용)을 사용합니다.
예
이 R 예제에서 .arg1은 SUM([Profit])에 해당합니다.
SCRIPT_INT("is.finite(.arg1)", SUM([Profit]))
다음 예에서 k-평균 클러스터링은 세 가지 클러스터를 만드는 데 사용됩니다.
SCRIPT_INT('result <- kmeans(data.frame(.arg1,.arg2,.arg3,.arg4), 3);result$cluster;', SUM([Petal length]), SUM([Petal width]),SUM([Sepal length]),SUM([Sepal width]))
Python 명령은 다음과 같은 형식입니다.
SCRIPT_INT("return map(lambda x : int(x * 5), _arg1)", SUM([Profit]))
SCRIPT_REAL
지정된 표현식의 실수 결과를 반환합니다. 표현식은 실행 중인 Analytics 확장 프로그램 서비스 인스턴스로 직접 전달됩니다. R
R 식에서는 .argn(선행 마침표 사용)을 사용하여 매개 변수를 참조합니다(.arg1, .arg2 등).
Python 식에서는 _argn(선행 밑줄 사용)을 사용합니다.
예
이 R 예제에서 .arg1은 SUM([Profit])에 해당합니다.
SCRIPT_REAL("is.finite(.arg1)", SUM([Profit]))
다음 예는 온도 값을 섭씨에서 화씨로 변환합니다.
SCRIPT_REAL('library(udunits2);ud.convert(.arg1, "celsius", "degree_fahrenheit")',AVG([Temperature]))
Python 명령은 다음과 같은 형식입니다.
SCRIPT_REAL("return map(lambda x : x * 0.5, _arg1)", SUM([Profit]))
SCRIPT_STR
지정된 표현식의 문자열 결과를 반환합니다. 표현식은 실행 중인 Analytics 확장 프로그램 서비스 인스턴스로 직접 전달됩니다.
R 식에서는 .argn(선행 마침표 사용)을 사용하여 매개 변수를 참조합니다(.arg1, .arg2 등).
Python 식에서는 _argn(선행 밑줄 사용)을 사용합니다.
예
이 R 예제에서 .arg1은 SUM([Profit])에 해당합니다.
SCRIPT_STR("is.finite(.arg1)", SUM([Profit]))
다음 예는 더 복잡한 문자열에서 시/도 약어를 추출합니다(원래 형식: 13XSL_CA, A13_WA).
SCRIPT_STR('gsub(".*_", "", .arg1)',ATTR([Store ID]))
Python 명령은 다음과 같은 형식입니다.
SCRIPT_STR("return map(lambda x : x[:2], _arg1)", ATTR([Region]))
계산 에디터를 사용하여 테이블 계산 만들기
아래의 단계를 수행하여 계산 에디터를 사용해 테이블 계산을 만드는 방법을 배워 보십시오.
참고: Tableau에서 여러 가지 방법으로 테이블 계산을 들 수 있습니다. 이 예제에서는 이러한 방법 중 하나만 보여 줍니다. 자세한 내용은 테이블 계산으로 값 변환(링크가 새 창에서 열림)을 참조하십시오.
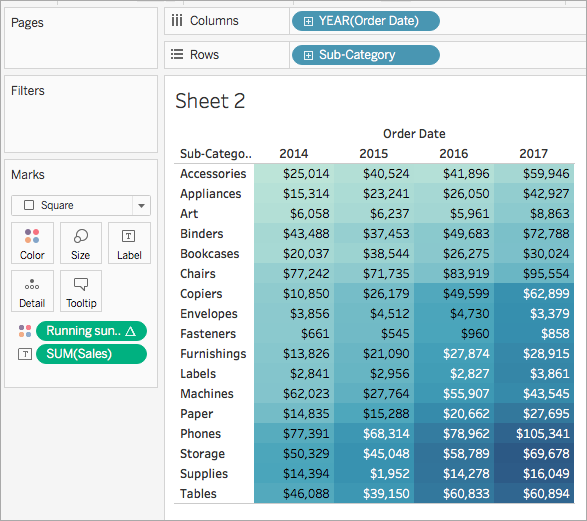
1단계: 비주얼리제이션 만들기
Tableau Desktop에서 Tableau와 함께 제공된 샘플 – 슈퍼스토어라는 저장된 데이터 원본에 연결합니다.
워크시트로 이동합니다.
데이터 패널의 차원에서 Order Date(주문 날짜)를 열 선반에 끌어 놓습니다.
데이터 패널의 차원에서 Sub-Category(하위 범주)를 행 선반에 끌어 놓습니다.
데이터 패널의 측정값 아래에서 Sales(매출)를 마크 카드의 텍스트에 끌어 놓습니다.
비주얼리제이션이 텍스트 테이블로 업데이트됩니다.
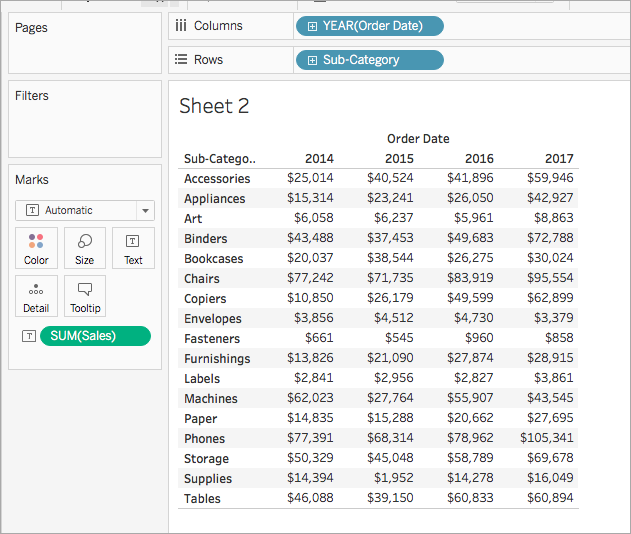
2단계: 테이블 계산 만들기
분석 > 계산된 필드 만들기를 선택합니다.
계산 에디터가 열리면 다음을 수행합니다.
- 계산된 필드의 이름을 Running Sum of Profit(수익의 누계 합계)로 지정합니다.
다음 수식을 입력합니다.
RUNNING_SUM(SUM([Profit]))이 수식은 매출 수익의 누계 합계를 계산합니다. 수식은 전체 테이블에서 계산됩니다.
작업을 마쳤으면 확인을 클릭합니다.
새 테이블 계산 필드가 데이터 패널의 측정값 아래에 나타납니다. 다른 필드와 마찬가지로, 하나 이상의 비주얼리제이션에서 이 필드를 사용할 수 있습니다.
3단계: 비주얼리제이션에서 테이블 계산 사용
데이터 패널의 측정값 아래에서 Running Sum of Profit(수익의 누계 합계)를 마크 카드의 색상에 끌어 놓습니다.
마크 카드에서 마크 유형 드롭다운을 클릭한 다음 사각형을 선택합니다.
비주얼리제이션이 업데이트되고 테이블이 하이라이트됩니다.
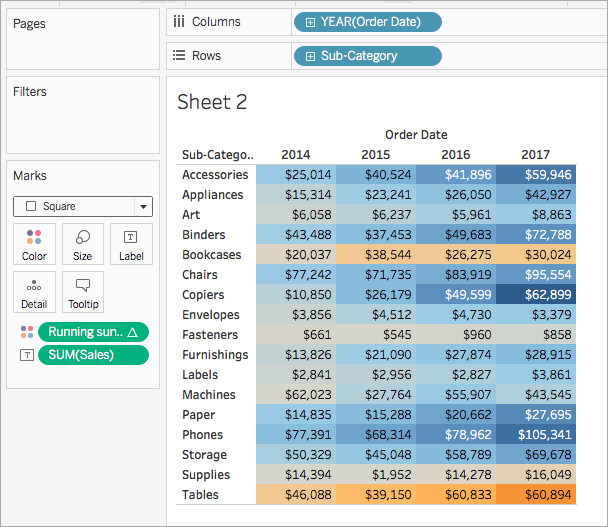
4단계: 테이블 계산 편집
- 마크 카드에서 Running Sum of Profit(수익의 누계 합계)를 마우스 오른쪽 단추로 클릭하고 테이블 계산 편집을 선택합니다.
테이블 계산 대화 상자가 열리면 다음을 사용하여 계산에서 테이블(아래로)를 선택합니다.
비주얼리제이션이 다음과 같이 업데이트됩니다.