Funciones de cálculo de tablas
En este artículo se presentan las funciones de cálculo de tabla y sus usos en Tableau. También se muestra cómo crear un cálculo de tabla mediante el editor de cálculo.
Por qué usar funciones de cálculo de tabla
Las funciones de cálculo de tabla le permiten realizar cálculos con los valores de una tabla.
Por ejemplo, puede calcular cuál es el porcentaje del total de una venta individual en el año o en varios años.
Funciones de cálculo de tabla disponibles en Tableau
Estas son las funciones de cálculo de tablas nativas que se pueden usar en Tableau sin una extensión de análisis externa.
FIRST( )
Indica el número de filas desde la fila actual a la primera fila en la participación. Por ejemplo, la siguiente vista muestra ventas por trimestre. Cuando se calcula FIRST() dentro de la división Fecha, la compensación de la primera fila con la segunda fila es -1.

Ejemplo
Cuando el índice de la fila actual es 3, FIRST()
= -2.
INDEX( )
Indica el índice de la fila actual en la división sin ordenar con respecto al valor. El índice de la primera fila comienza en 1. Por ejemplo, la siguiente tabla muestra ventas por trimestre. Cuando se calcula INDEX() dentro de la división Fecha, el índice de cada fila es 1, 2, 3, 4..., etc.

Ejemplo
Para la tercera fila de la división, INDEX() = 3.
LAST( )
Indica el número de filas desde la fila actual a la última fila de la división. Por ejemplo, la siguiente tabla muestra ventas por trimestre. Cuando se calcula LAST() dentro de la división Fecha, la compensación de la última fila con la segunda fila es 5.

Ejemplo
Cuando el índice de la fila actual es 3 de 7, LAST() = 4.
LOOKUP(expression, [offset])
Indica el valor de la expresión en una fila objetivo, especificada como compensación relativa desde la fila actual. Use FIRST() + n y LAST() - n como parte de su definición de compensación para un objetivo en relación con la primera/última fila en la división. Si se omite offset, la fila Comparar con debe configurarse en el menú de campo. Esta función indica NULL si la fila objetivo no se puede determinar.
La siguiente vista muestra ventas por trimestre. Cuando se calcula LOOKUP (SUM(Sales), 2) dentro de la división Fecha, cada fila muestra el valor de ventas de 2 trimestres en el futuro.

Ejemplo
LOOKUP(SUM([Profit]),
FIRST()+2) calcula la SUM(Profit) en la tercera fila de la división.
Funciones MODEL_EXTENSION
Las funciones de extensión del modelo:
MODEL_EXTENSION_BOOL
MODEL_EXTENSION_INT
MODEL_EXTENSION_REAL
MODEL_EXTENSION_STRING
se utilizan para pasar datos a un modelo implementado en un servicio externo como R, TabPy o Matlab. Consulte Extensiones de análisis(El enlace se abre en una ventana nueva).
MODEL_PERCENTILE(target_expression, predictor_expression(s))
Devuelve la probabilidad (entre 0 y 1) de que el valor esperado sea menor o igual que la marca observada, definida por la expresión de destino y otros predictores. Esta es la función de distribución predictiva posterior, también conocida como función de distribución acumulativa (CDF).
Esta función es la inversa de MODEL_QUANTILE. Para obtener información sobre las funciones de modelado predictivo, consulte Funciones de modelado predictivo en Tableau.
Ejemplo
La siguiente fórmula devuelve el cuantil de la marca para la suma de ventas, ajustado para el recuento de pedidos.
MODEL_PERCENTILE(SUM([Sales]), COUNT([Orders]))
MODEL_QUANTILE(quantile, target_expression, predictor_expression(s))
Devuelve un valor numérico de destino dentro del intervalo probable definido por la expresión de destino y otros predictores, en un cuantil especificado. Este es el cuantil predictivo posterior.
Esta función es la inversa de MODEL_PERCENTILE. Para obtener información sobre las funciones de modelado predictivo, consulte Funciones de modelado predictivo en Tableau.
Ejemplo
La siguiente fórmula devuelve la suma media (0,5) de ventas prevista, ajustada para el recuento de pedidos.
MODEL_QUANTILE(0.5, SUM([Sales]), COUNT([Orders]))
PREVIOUS_VALUE(expression)
Indica el valor de este cálculo en la fila anterior. Indica la expresión dada si la fila actual es la primera fila de la división.
Ejemplo
SUM([Profit]) * PREVIOUS_VALUE(1) calcula el producto en ejecución de SUM(Profit).
RANK(expression, ['asc' | 'desc'])
Indica la clasificación de jerarquía para la competencia estándar para la fila actual en la división. Se asignan valores idénticos a clasificaciones distintas. Use el argumento 'asc' | 'desc' opcional para especificar un orden ascendente o descendente. El valor predeterminado es descendente.
Con esta función, el conjunto de valores (6, 9, 9, 14) se clasificaría como (4, 2, 2, 1).
Los valores nulos se ignoran en las funciones de clasificación. No se enumeran y no se cuentan contra el número total de registros en los cálculos de clasificación de percentil.
Para obtener información sobre las diferentes opciones de clasificación, consulte Cálculo Clasificación.
Ejemplo
La siguiente imagen muestra el efecto de las distintas funciones de clasificación (RANK, RANK_DENSE, RANK_MODIFIED, RANK_PERCENTILE y RANK_UNIQUE) en un conjunto de valores. El conjunto de datos contiene información de 14 estudiantes (de StudentA a StudentN); la columna Edad muestra la edad actual de cada estudiante (todos tienen entre 17 y 20 años). Las demás columnas muestran el efecto de cada función de clasificación en el conjunto de valores de edad; en todas se emplea el orden predeterminado (ascendente o descendente) para la función.
![]()
RANK_DENSE(expression, ['asc' | 'desc'])
Indica la clasificación densa para la fila actual de la división. Se asignan valores idénticos a una clasificación idéntica, pero no se insertan espacios en la secuencia numérica. Use el argumento 'asc' | 'desc' opcional para especificar un orden ascendente o descendente. El valor predeterminado es descendente.
Con esta función, el conjunto de valores (6, 9, 9, 14) se clasificaría como (3, 2, 2, 1).
Los valores nulos se ignoran en las funciones de clasificación. No se enumeran y no se cuentan contra el número total de registros en los cálculos de clasificación de percentil.
Para obtener información sobre las diferentes opciones de clasificación, consulte Cálculo Clasificación.
RANK_MODIFIED(expression, ['asc' | 'desc'])
Indica la clasificación de competencia modificada para la fila actual de la división. Se asignan valores idénticos a clasificaciones distintas. Use el argumento 'asc' | 'desc' opcional para especificar un orden ascendente o descendente. El valor predeterminado es descendente.
Con esta función, el conjunto de valores (6, 9, 9, 14) se clasificaría como (4, 3, 3, 1).
Los valores nulos se ignoran en las funciones de clasificación. No se enumeran y no se cuentan contra el número total de registros en los cálculos de clasificación de percentil.
Para obtener información sobre las diferentes opciones de clasificación, consulte Cálculo Clasificación.
RANK_PERCENTILE(expression, ['asc' | 'desc'])
Indica la clasificación de percentil para la fila actual de la división. Use el argumento 'asc' | 'desc' opcional para especificar un orden ascendente o descendente. El valor predeterminado es ascendente.
Con esta función, el conjunto de valores (6, 9, 9, 14) se clasificaría como (0.00, 0.67, 0.67, 1.00).
Los valores nulos se ignoran en las funciones de clasificación. No se enumeran y no se cuentan contra el número total de registros en los cálculos de clasificación de percentil.
Para obtener información sobre las diferentes opciones de clasificación, consulte Cálculo Clasificación.
RANK_UNIQUE(expression, ['asc' | 'desc'])
Indica la clasificación única para la fila actual de la división. Se asignan valores idénticos a clasificaciones idénticas. Use el argumento 'asc' | 'desc' opcional para especificar un orden ascendente o descendente. El valor predeterminado es descendente.
Con esta función, el conjunto de valores (6, 9, 9, 14) se clasificaría como (4, 2, 3, 1).
Los valores nulos se ignoran en las funciones de clasificación. No se enumeran y no se cuentan contra el número total de registros en los cálculos de clasificación de percentil.
Para obtener información sobre las diferentes opciones de clasificación, consulte Cálculo Clasificación.
RUNNING_AVG(expression)
Indica el promedio de ejecución de la expresión dada, desde la primera fila de la división hasta la fila actual.
La siguiente vista muestra ventas por trimestre. Cuando se calcula RUNNING_AVG(SUM([Sales]) dentro de la división Fecha, el resultado es un promedio móvil de los valores de venta de cada trimestre.

Ejemplo
RUNNING_AVG(SUM([Profit])) calcula el promedio de ejecución de SUM(Profit).
RUNNING_COUNT(expression)
Indica el conteo de ejecución de la expresión dada, desde la primera fila de la división hasta la fila actual.
Ejemplo
RUNNING_COUNT(SUM([Profit])) calcula el conteo de ejecución de SUM(Profit).
RUNNING_MAX(expression)
Indica el máximo de ejecución de la expresión dada, desde la primera fila de la división hasta la fila actual.

Ejemplo
RUNNING_MAX(SUM([Profit])) calcula el máximo de ejecución de SUM(Profit).
RUNNING_MIN(expression)
Indica el mínimo de ejecución de la expresión dada, desde la primera fila de la división hasta la fila actual.

Ejemplo
RUNNING_MIN(SUM([Profit])) calcula el mínimo de ejecución de SUM(Profit).
RUNNING_SUM(expression)
Indica la suma de ejecución de la expresión dada, desde la primera fila de la división hasta la fila actual.

Ejemplo
RUNNING_SUM(SUM([Profit])) calcula la suma de ejecución de SUM(Profit)
SIZE()
Indica el número de filas que hay en la división. Por ejemplo, la siguiente vista muestra ventas por trimestre. En la división Fecha, hay siete filas, por lo que el Size() de la división Fecha es 7.

Ejemplo
SIZE() = 5 cuando la división actual contiene cinco filas.
Funciones SCRIPT_
Las funciones del script:
SCRIPT_BOOL
SCRIPT_INT
SCRIPT_REAL
SCRIPT_STRING
se utilizan para pasar datos a un servicio externo como R, TabPy o Matlab. Consulte Extensiones de análisis(El enlace se abre en una ventana nueva).
TOTAL(expression)
Indica el total para la expresión dada en una división de cálculo de tablas.
Ejemplo
Supongamos que partimos de esta vista:

Abrimos el editor de cálculos y creamos un campo nuevo con el nombre Totalidad:

Luego colocamos Totalidad en Texto para reemplazar SUM(Ventas). La vista cambia y suma los valores basados en el valor predeterminado de Computar usando:

Esto suscita una cuestión: ¿qué es el valor predeterminado de Computar usando? Al hacer clic con el botón derecho (Control + clic en un Mac) en Totalidad en el panel Datos y elegir Editar, aparece un dato nuevo adicional:

El valor predeterminado de Computar usando es Tabla (a lo largo). El resultado es que Totalidad suma los valores de cada fila de la tabla. Por lo tanto, el valor que vemos en cada fila es la suma de los valores de la versión original de la tabla.
Los valores de la fila 2011/Q1 en la tabla original eran 8601 $, 6579 $, 44 262 $ y 15 006 $. Los valores que hay en la tabla después de reemplazar SUM(Ventas) por Totalidad son todos 74 448 $, que es la suma de los valores originales.
Fíjese en el triángulo que aparece junto a Totalidad después de colocarlo en Texto:

Esto indica que este campo usa un cálculo de tablas. Puede hacer clic con el botón derecho en el campo y elegir Editar cálculo de tablas para redirigir la función a otro valor de Computar usando. Por ejemplo, lo puede establecer en Tabla (vertical). En este caso, la tabla tendría este aspecto:

TOTAL(expression)
Indica el total para la expresión dada en una división de cálculo de tablas.
Ejemplo
Supongamos que partimos de esta vista:
Abrimos el editor de cálculos y creamos un campo nuevo con el nombre Totalidad:
Luego colocamos Totalidad en Texto para reemplazar SUM(Ventas). La vista cambia y suma los valores basados en el valor predeterminado de Computar usando:
Esto suscita una cuestión: ¿qué es el valor predeterminado de Computar usando? Al hacer clic con el botón derecho (Control + clic en un Mac) en Totalidad en el panel Datos y elegir Editar, aparece un dato nuevo adicional:
El valor predeterminado de Computar usando es Tabla (a lo largo). El resultado es que Totalidad suma los valores de cada fila de la tabla. Por lo tanto, el valor que vemos en cada fila es la suma de los valores de la versión original de la tabla.
Los valores de la fila 2011/Q1 en la tabla original eran 8601 $, 6579 $, 44 262 $ y 15 006 $. Los valores que hay en la tabla después de reemplazar SUM(Ventas) por Totalidad son todos 74 448 $, que es la suma de los valores originales.
Fíjese en el triángulo que aparece junto a Totalidad después de colocarlo en Texto:
Esto indica que este campo usa un cálculo de tablas. Puede hacer clic con el botón derecho en el campo y elegir Editar cálculo de tablas para redirigir la función a otro valor de Computar usando. Por ejemplo, lo puede establecer en Tabla (vertical). En este caso, la tabla tendría este aspecto:
WINDOW_AVG(expression, [start, end])
Indica el promedio de la expresión dentro de la ventana. La ventana se define como compensaciones de la fila actual. Use FIRST()+n y LAST()-n para compensaciones de la primera o última fila de la división. Si se omite el comienzo y el final, se utiliza la división completa.
Existe una función de agregación equivalente: AVG. Consulte Funciones de Tableau (alfabéticamente)(El enlace se abre en una ventana nueva).
Ejemplo
La siguiente fórmula indica la ventana promedio de SUM(Profit) desde las dos filas anteriores hasta la fila actual.
WINDOW_AVG(SUM[Profit]), -2, 0)
WINDOW_CORR(expression1, expression2, [start, end])
Indica el coeficiente de correlación de Pearson de dos expresiones en la ventana. La ventana se define como compensaciones de la fila actual. Use FIRST()+n y LAST()-n para compensaciones de la primera o última fila de la división. Si se omite el comienzo y el final, se utiliza la división completa.
La correlación de Pearson mide la relación lineal entre dos variables. Los resultados oscilan entre -1 y +1 (ambos incluidos), donde 1 indica una relación lineal positiva exacta, como cuando un cambio positivo en una variable implica un cambio positivo de la magnitud correspondiente en el otro; 0 indica que no hay ninguna relación lineal entre la varianza y −1 es una relación negativa exacta.
Existe una función de agregación equivalente: CORR. Consulte Funciones de Tableau (alfabéticamente)(El enlace se abre en una ventana nueva).
Ejemplo
La siguiente fórmula indica la correlación de Pearson de SUM(Profit) y SUM(Sales) desde las cinco filas anteriores hasta la fila actual.
WINDOW_CORR(SUM[Profit]), SUM([Sales]), -5, 0)
WINDOW_COUNT(expression, [start, end])
Indica el conteo de la expresión dentro de la ventana. La ventana se define mediante las compensaciones de la fila actual. Use FIRST()+n y LAST()-n para compensaciones de la primera o última fila de la división. Si se omite el comienzo y el final, se usa la división completa.
Ejemplo
WINDOW_COUNT(SUM([Profit]), FIRST()+1, 0) calcula el conteo de SUM(Profit) desde la segunda fila hasta la actual
WINDOW_COVAR(expression1, expression2, [start, end])
Indica la covarianza de muestra de dos expresiones en la ventana. La ventana se define como compensaciones de la fila actual. Use FIRST()+n y LAST()-n para compensaciones de la primera o última fila de la división. Si se omiten los argumentos inicial y final, la ventana será la división completa.
La covarianza de muestra utiliza el número de puntos de datos no nulos n - 1 para normalizar el cálculo de la covarianza, en vez de utilizar n, que se utiliza en la covarianza de población (con la función WINDOW_COVARP). La covarianza de muestra es la opción adecuada si los datos representan una muestra aleatoria utilizada para estimar la covarianza de una población elevada.
Existe una función de agregación equivalente: COVAR. Consulte Funciones de Tableau (alfabéticamente)(El enlace se abre en una ventana nueva).
Ejemplo
La siguiente fórmula indica la covarianza de muestra de SUM(Profit) y SUM(Sales) desde las dos filas anteriores hasta la fila actual.
WINDOW_COVAR(SUM([Profit]), SUM([Sales]), -2, 0)
WINDOW_COVARP(expression1, expression2, [start, end])
Indica la covarianza de población de dos expresiones en la ventana. La ventana se define como compensaciones de la fila actual. Use FIRST()+n y LAST()-n para compensaciones de la primera o última fila de la división. Si se omite el comienzo y el final, se utiliza la división completa.
La covarianza de población es la covarianza de muestra multiplicada por (n-1)/n, donde n es el número total de puntos de datos no nulos. La covarianza de población es la opción adecuada si hay datos disponibles para todos los elementos de interés, a diferencia de cuando solo hay un subconjunto aleatorio de elementos, en cuyo caso se recomienda utilizar la covarianza de muestra (con la función WINDOW_COVAR).
Existe una función de agregación equivalente: COVARP. Funciones de Tableau (alfabéticamente)(El enlace se abre en una ventana nueva).
Ejemplo
La siguiente fórmula indica la covarianza de población de SUM(Profit) y SUM(Sales) desde las dos filas anteriores hasta la fila actual.
WINDOW_COVARP(SUM([Profit]), SUM([Sales]), -2, 0)
WINDOW_MEDIAN(expression, [start, end])
Indica la mediana de la expresión dentro de la ventana. La ventana se define mediante las compensaciones de la fila actual. Use FIRST()+n y LAST()-n para compensaciones de la primera o última fila de la división. Si se omite el comienzo y el final, se usa la división completa.
Por ejemplo, la siguiente vista muestra las ganancias trimestrales. Una mediana de ventana en la división Fecha indica las ganancias medias en todas las fechas.

Ejemplo
WINDOW_MEDIAN(SUM([Profit]), FIRST()+1, 0) calcula la mediana de SUM(Profit) desde la segunda fila hasta la actual.
WINDOW_MAX(expression, [start, end])
Indica el máximo de la expresión dentro de la ventana. La ventana se define mediante las compensaciones de la fila actual. Use FIRST()+n y LAST()-n para compensaciones de la primera o última fila de la división. Si se omite el comienzo y el final, se usa la división completa.
Por ejemplo, la siguiente vista muestra ventas por trimestre. Un máximo de ventana en la división Fecha indica las ventas máximas en todas las fechas.

Ejemplo
WINDOW_MAX(SUM([Profit]), FIRST()+1, 0) calcula el máximo de SUM(Profit) desde la segunda fila hasta la actual.
WINDOW_MIN(expression, [start, end])
Indica el mínimo de la expresión dentro de la ventana. La ventana se define mediante las compensaciones de la fila actual. Use FIRST()+n y LAST()-n para compensaciones de la primera o última fila de la división. Si se omite el comienzo y el final, se usa la división completa.
Por ejemplo, la siguiente vista muestra ventas por trimestre. Un mínimo de ventana en la división Fecha indica las ventas mínimas en todas las fechas.

Ejemplo
WINDOW_MIN(SUM([Profit]), FIRST()+1, 0) calcula el mínimo de SUM(Profit) desde la segunda fila hasta la actual.
WINDOW_PERCENTILE(expression, number, [start, end])
Indica el valor que corresponde al percentil especificado en la ventana. La ventana se define mediante las compensaciones de la fila actual. Use FIRST()+n y LAST()-n para compensaciones de la primera o última fila de la división. Si se omite el comienzo y el final, se usa la división completa.
Ejemplo
WINDOW_PERCENTILE(SUM([Profit]), 0.75, -2, 0) indica el percentil n.º 75 de SUM(Profit) desde las dos filas anteriores hasta la actual.
WINDOW_STDEV(expression, [start, end])
Indica la desviación estándar de muestra de la expresión dentro de la ventana. La ventana se define mediante las compensaciones de la fila actual. Use FIRST()+n y LAST()-n para compensaciones de la primera o última fila de la división. Si se omite el comienzo y el final, se usa la división completa.
Ejemplo
WINDOW_STDEV(SUM([Profit]), FIRST()+1, 0) calcula la desviación estándar de SUM(Profit) desde la segunda fila hasta la actual.
WINDOW_STDEVP(expression, [start, end])
Indica la desviación estándar parcial de la expresión dentro de la ventana. La ventana se define mediante las compensaciones de la fila actual. Use FIRST()+n y LAST()-n para compensaciones de la primera o última fila de la división. Si se omite el comienzo y el final, se usa la división completa.
Ejemplo
WINDOW_STDEVP(SUM([Profit]), FIRST()+1, 0) calcula la desviación estándar de SUM(Profit) desde la segunda fila hasta la actual.
WINDOW_SUM(expression, [start, end])
Indica la suma de la expresión dentro de la ventana. La ventana se define mediante las compensaciones de la fila actual. Use FIRST()+n y LAST()-n para compensaciones de la primera o última fila de la división. Si se omite el comienzo y el final, se usa la división completa.
Por ejemplo, la siguiente vista muestra ventas por trimestre. Una suma de ventana calculada en la división Fecha indica la suma de las ventas en todos los trimestres.

Ejemplo
WINDOW_SUM(SUM([Profit]), FIRST()+1, 0) calcula la suma de SUM(Profit) desde la segunda fila hasta la actual.
WINDOW_VAR(expression, [start, end])
Indica la discordancia de muestra de la expresión dentro de la ventana. La ventana se define mediante las compensaciones de la fila actual. Use FIRST()+n y LAST()-n para compensaciones de la primera o última fila de la división. Si se omite el comienzo y el final, se usa la división completa.
Ejemplo
WINDOW_VAR((SUM([Profit])), FIRST()+1, 0) calcula la discordancia de SUM(Profit) desde la segunda fila hasta la actual.
WINDOW_VARP(expression, [start, end])
Indica la discordancia parcial de la expresión dentro de la ventana. La ventana se define mediante las compensaciones de la fila actual. Use FIRST()+n y LAST()-n para compensaciones de la primera o última fila de la división. Si se omite el comienzo y el final, se usa la división completa.
Ejemplo
WINDOW_VARP(SUM([Profit]), FIRST()+1, 0) calcula la discordancia de SUM(Profit) desde la segunda fila hasta la actual.
Funciones de cálculo de tabla de extensión de análisis disponibles en Tableau
Las extensiones de análisis son conexiones entre Tableau y un servicio externo como TabPy para Python, Matlab y R. Para usar extensiones de análisis en su análisis, primero debe configurar una conexión(El enlace se abre en una ventana nueva) entre Tableau y un servicio externo como un servidor TabPy. Luego, puede usar scripts dentro de cálculos de tablas específicos (MODEL_EXTENSION_ para usar modelos nombrados publicados o SCRIPT_ para pasar una expresión al servicio externo). Los datos en la visualización (la "tabla" del cálculo de tabla) se pasan de forma segura al servidor externo, se ejecuta el script y los resultados se devuelven como salida del cálculo.
Funciones de extensión del modelo
Para usar con modelos con nombre implementados en un servicio externo TabPy.
MODEL_EXTENSION_BOOL (model_name, arguments, expression)
Devuelve el resultado booleano de una expresión calculada por un modelo con nombre implementado en un servicio externo de TabPy.
Model_name es el nombre del modelo de análisis implementado que desea utilizar.
Cada argumento es una sola cadena que establece los valores de entrada que acepta el modelo implementado y está definido por el modelo de análisis.
Utilice expresiones para definir los valores que se envían desde Tableau al modelo analítico. Asegúrese de utilizar funciones de agregación (SUM, AVG, etc.) para agregar los resultados.
Al usar la función, los tipos de datos y el orden de las expresiones deben coincidir con los de los argumentos de entrada.
Ejemplo
MODEL_EXTENSION_BOOL ("isProfitable","inputSales", "inputCosts", SUM([Sales]), SUM([Costs]))
MODEL_EXTENSION_INT (model_name, arguments, expression)
Devuelve un resultado entero de una expresión calculada por un modelo con nombre implementado en un servicio externo de TabPy.
Model_name es el nombre del modelo de análisis implementado que desea utilizar.
Cada argumento es una sola cadena que establece los valores de entrada que acepta el modelo implementado y está definido por el modelo de análisis.
Utilice expresiones para definir los valores que se envían desde Tableau al modelo analítico. Asegúrese de utilizar funciones de agregación (SUM, AVG, etc.) para agregar los resultados.
Al usar la función, los tipos de datos y el orden de las expresiones deben coincidir con los de los argumentos de entrada.
Ejemplo
MODEL_EXTENSION_INT ("getPopulation", "inputCity", "inputState", MAX([City]), MAX ([State]))
MODEL_EXTENSION_REAL (model_name, arguments, expression)
Devuelve un resultado real de una expresión calculada por un modelo con nombre implementado en un servicio externo de TabPy.
Model_name es el nombre del modelo de análisis implementado que desea utilizar.
Cada argumento es una sola cadena que establece los valores de entrada que acepta el modelo implementado y está definido por el modelo de análisis.
Utilice expresiones para definir los valores que se envían desde Tableau al modelo analítico. Asegúrese de utilizar funciones de agregación (SUM, AVG, etc.) para agregar los resultados.
Al usar la función, los tipos de datos y el orden de las expresiones deben coincidir con los de los argumentos de entrada.
Ejemplo
MODEL_EXTENSION_REAL ("profitRatio", "inputSales", "inputCosts", SUM([Sales]), SUM([Costs]))
MODEL_EXTENSION_STRING (model_name, arguments, expression)
Devuelve el resultado de cadena de una expresión calculada por un modelo con nombre implementado en un servicio externo de TabPy.
Model_name es el nombre del modelo de análisis implementado que desea utilizar.
Cada argumento es una sola cadena que establece los valores de entrada que acepta el modelo implementado y está definido por el modelo de análisis.
Utilice expresiones para definir los valores que se envían desde Tableau al modelo analítico. Asegúrese de utilizar funciones de agregación (SUM, AVG, etc.) para agregar los resultados.
Al usar la función, los tipos de datos y el orden de las expresiones deben coincidir con los de los argumentos de entrada.
Ejemplo
MODEL_EXTENSION_STR ("mostPopulatedCity", "inputCountry", "inputYear", MAX ([Country]), MAX([Year]))
Funciones de script
En lugar de utilizar un modelo externo definido como las funciones MODEL_EXPRESSION, se utilizan funciones SCRIPT para especificar la expresión directamente en el cálculo de la tabla.
Nota: Las llamadas esperan que se devuelva una sola columna que contiene el mismo número de filas que se envió a la función.
SCRIPT_BOOL
Indica un resultado booleano de la expresión especificada. La expresión se pasa directamente a una instancia de extensión de análisis en ejecución.
En las expresiones R, utilice .argn (con un punto inicial) para hacer referencia a parámetros (.arg1, .arg2, etc.).
En las expresiones de Python, utilice _argn (con un guion bajo inicial).
Ejemplos
En este ejemplo de R, .arg1 equivale a SUM([Profit]):
SCRIPT_BOOL("is.finite(.arg1)", SUM([Profit]))
El siguiente ejemplo indica True para las ID de almacenamiento en el estado de Washington, y False en otros casos. Este ejemplo puede ser la definición de un campo calculado llamado StoreInWa.
SCRIPT_BOOL('grepl(".*_WA", .arg1, perl=TRUE)',ATTR([Store ID]))
Un comando de Python tendría esta forma:
SCRIPT_BOOL("return map(lambda x : x > 0, _arg1)", SUM([Profit]))
SCRIPT_INT
Indica un número entero como resultado de la expresión especificada. La expresión se pasa directamente a una instancia de extensión de análisis en ejecución.
En las expresiones R, utilice .argn (con un punto inicial) para hacer referencia a parámetros (.arg1, .arg2, etc.).
En las expresiones de Python, utilice _argn (con un guion bajo inicial).
Ejemplos
En este ejemplo de R, .arg1 equivale a SUM([Profit]):
SCRIPT_INT("is.finite(.arg1)", SUM([Profit]))
En el siguiente ejemplo se utiliza agrupamiento k-means para crear tres conjuntos:
SCRIPT_INT('result <- kmeans(data.frame(.arg1,.arg2,.arg3,.arg4), 3);result$cluster;', SUM([Petal length]), SUM([Petal width]),SUM([Sepal length]),SUM([Sepal width]))
Un comando de Python tendría esta forma:
SCRIPT_INT("return map(lambda x : int(x * 5), _arg1)", SUM([Profit]))
SCRIPT_REAL
Indica un resultado real de la expresión especificada. La expresión se pasa directamente a una instancia de extensión de análisis en ejecución. En
En las expresiones R, utilice .argn (con un punto inicial) para hacer referencia a parámetros (.arg1, .arg2, etc.).
En las expresiones de Python, utilice _argn (con un guion bajo inicial).
Ejemplos
En este ejemplo de R, .arg1 equivale a SUM([Profit]):
SCRIPT_REAL("is.finite(.arg1)", SUM([Profit]))
El siguiente ejemplo convierte los valores de temperatura de Celsius a Fahrenheit.
SCRIPT_REAL('library(udunits2);ud.convert(.arg1, "celsius", "degree_fahrenheit")',AVG([Temperature]))
Un comando de Python tendría esta forma:
SCRIPT_REAL("return map(lambda x : x * 0.5, _arg1)", SUM([Profit]))
SCRIPT_STR
Indica un resultado de cadena de la expresión especificada. La expresión se pasa directamente a una instancia de extensión de análisis en ejecución.
En las expresiones R, utilice .argn (con un punto inicial) para hacer referencia a parámetros (.arg1, .arg2, etc.).
En las expresiones de Python, utilice _argn (con un guion bajo inicial).
Ejemplos
En este ejemplo de R, .arg1 equivale a SUM([Profit]):
SCRIPT_STR("is.finite(.arg1)", SUM([Profit]))
El siguiente ejemplo extrae una abreviación de estado de una cadena más complicada (en la forma original 13XSL_CA, A13_WA):
SCRIPT_STR('gsub(".*_", "", .arg1)',ATTR([Store ID]))
Un comando de Python tendría esta forma:
SCRIPT_STR("return map(lambda x : x[:2], _arg1)", ATTR([Region]))
Crear un cálculo de tabla mediante el editor de cálculo
Siga los pasos que se indican a continuación para obtener información sobre cómo crear un cálculo de tabla mediante el editor de cálculo.
Nota: Hay varias maneras de crear cálculos de tabla en Tableau. Con este ejemplo se muestra una de ellas. Para obtener más información, consulte Transformar valores con cálculos de tablas(El enlace se abre en una ventana nueva).
Paso 1: crear la visualización
En Tableau Desktop, conéctese a la fuente de datos guardada Sample-Superstore, que se incluye con Tableau.
Vaya a una hoja de trabajo.
Desde el panel Datos, en Dimensiones, arrastre Fecha de pedido al estante Columnas.
En el panel Datos, en Dimensiones, arrastre Subcategoría al estante Filas.
Desde el panel Datos, en Medidas, arrastre Ventas hasta Texto en la tarjeta Marcas.
Su visualización se convertirá en una tabla de texto.
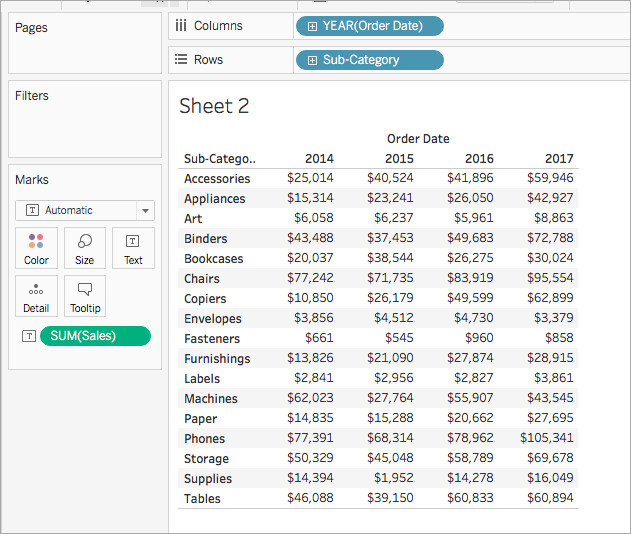
Paso 2: crear el cálculo de tabla
Seleccione Análisis > Crear campo calculado.
En el editor de cálculo que se abre, haga lo siguiente:
- Ponga este nombre al campo calculado: Suma de ejecución de beneficios.
Escriba la fórmula siguiente:
RUNNING_SUM(SUM([Profit]))Esta fórmula calcula la suma acumulada de ganancias de las ventas. Se calcula con los valores de toda la tabla.
Cuando haya terminado, haga clic en Aceptar.
El nuevo campo de cálculo de tabla aparece debajo de Medidas, en el panel Datos. Igual que con el resto de los campos, puede usarlo en una o más visualizaciones.
Paso 3: usar el cálculo de tabla en la visualización
En el panel Datos, en Medidas, arrastre Suma acumulada de ganancias hasta Color en la tarjeta Marcas.
En la tarjeta Marcas, haga clic en la lista desplegable Tipo de marca y seleccione Cuadrado.
La visualización se convierte en una tabla de resaltado:
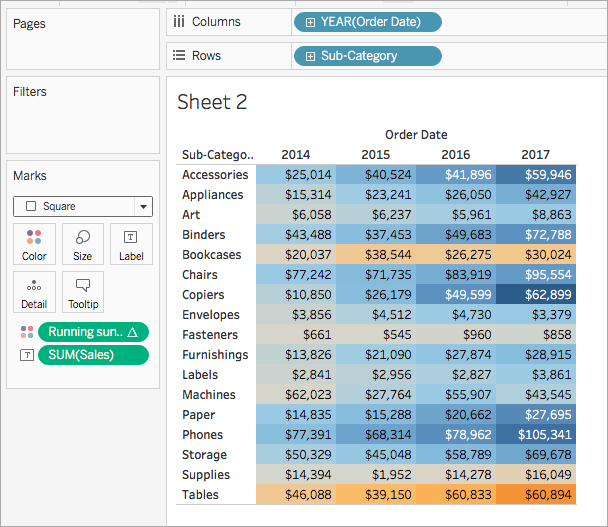
Paso 4: editar el cálculo de tabla
- En la tarjeta Marcas, haga clic con el botón derecho en Suma acumulada de ganancias y seleccione Editar cálculo de tabla.
En el cuadro de diálogo Cálculo de tablas que se muestra, en Calcular usando, seleccione Tabla (abajo).
La visualización se convierte en lo siguiente:
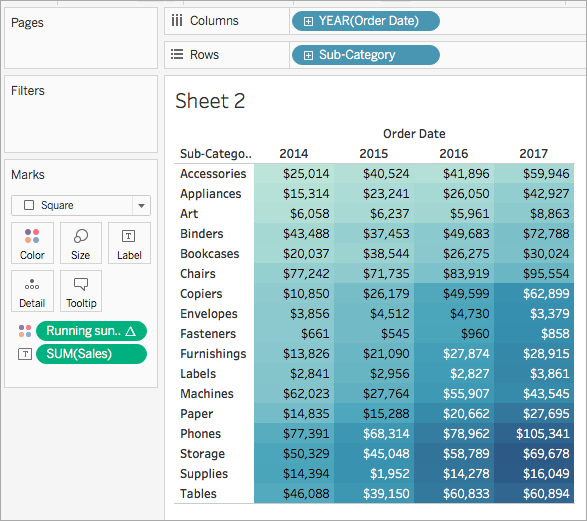
Consulte también
Crear un cálculo de tabla(El enlace se abre en una ventana nueva)
Personalizar cálculos de tablas(El enlace se abre en una ventana nueva)