Configurer votre ensemble de données
Remarque : depuis la version 2020.4.1, vous pouvez désormais créer et modifier des flux dans Tableau Server et Tableau Cloud. Le contenu de cette rubrique s’applique à toutes les plates-formes, sauf mention spécifique. Pour plus d’informations sur la création de flux sur le Web, consultez Tableau Prep sur le Web dans l’aide de Tableau Server(Le lien s’ouvre dans une nouvelle fenêtre) et Tableau Cloud(Le lien s’ouvre dans une nouvelle fenêtre).
Pour déterminer la proportion de votre ensemble de données à utiliser dans le flux, vous pouvez configurer votre ensemble de données. Lorsque vous vous connectez à vos données ou que vous faites glisser des tables vers le volet Flux, une étape des données entrantes est automatiquement ajoutée au flux.
Dans l’étape des données entrantes, vous déterminez quelles données et combien de données inclure dans votre flux. Il s’agit toujours de la première étape de votre flux.
Vous pouvez également actualiser les données depuis l’étape des données entrantes. Pour plus d’informations, consultez Ajouter des données supplémentaires à l’étape des données entrantes(Le lien s’ouvre dans une nouvelle fenêtre).
À l’étape des données entrantes, vous pouvez :
- Faire un clic droit (ou Cmd-clic sur MacOS) dans l’étape des données entrantes sur le volet Flux pour la renommer ou la supprimer.
- Réunir plusieurs fichiers dans le même répertoire parent ou enfant. Pour plus d’informations, consultez Réunir des fichiers et des tables de base de données dans l’étape des données entrantes.
- (à partir de la version 2023.1) Incluez les numéros de ligne générés automatiquement en fonction de l’ordre de tri d’origine de votre ensemble de données. Consultez Inclure les numéros de ligne de votre ensemble de données.
- Rechercher des champs.
- Voir un aperçu des valeurs de champ.
- Configurer les propriétés du champ en modifiant le nom du champ ou configurer les paramètres de texte pour les fichiers texte.
Remarque : les crochets dans les valeurs de champ sont automatiquement convertis en parenthèses.
- Configurez l’échantillon de données ingéré dans votre flux. Consultez Définir la taille de votre échantillon de données.
- Supprimez les champs dont vous n’avez pas besoin. Vous pouvez toujours revenir à l’étape des données entrantes et les inclure ultérieurement.
- Hide fields that you don’t need to clean, but still want to include in your flow output. Vous pouvez les afficher à tout moment si nécessaire.
- Appliquez des filtres aux champs sélectionnés.
- Modifiez le type de données de champ pour les connexions de données qui le prennent en charge.
- (à partir de la version 2023.3) Vous pouvez définir l’en-tête et la ligne de début des fichiers CSV.
- (à partir de la version 2024.1) Vous pouvez définir l’en-tête et la ligne de début des fichiers Excel.
Inclure les numéros de ligne de votre ensemble de données
Pris en charge dans Tableau Prep Builder à partir de la version 2023.1 et sur le Web pour les fichiers Microsoft Excel et texte (.csv).
Remarque : cette option n’est actuellement pas prise en charge pour les fichiers inclus dans une union d’entrée.
Depuis la version 2023.1, Tableau Prep génère automatiquement des numéros de ligne en fonction de l’ordre de tri d’origine de vos données que vous pouvez inclure en tant que nouveau champ dans votre flux. Cette fonctionnalité est disponible uniquement pour les types de fichiers Microsoft Excel ou texte (.csv).
Dans les versions précédentes, si vous vouliez inclure ces numéros de ligne, vous deviez les ajouter manuellement à la source avant d’ajouter l’ensemble de données à votre flux.
Ce champ est généré à l’étape des données entrantes lorsque vous vous connectez à vos données. Par défaut, il est exclu du flux, mais vous pouvez l’inclure en un clic. Si vous choisissez de l’inclure, il se comporte comme n’importe quel autre champ et peut être utilisé dans vos opérations de flux et vos champs calculés.
Tableau Prep prend également en charge la fonction ROW_NUMBER pour les champs calculés. Cette fonction est utile lorsque votre ensemble de données contient des champs qui peuvent définir le tri, tels que l’ID de ligne ou l’horodatage. Pour plus d’informations sur l’utilisation de cette fonction, consultez Créer des calculs de niveau de détail, de classement et de section.
Ajouter le champ Numéro de ligne source à votre flux
Faites un clic droit ou Cmd-clic (MacOS) sur le champ, ou cliquez sur le menu Options supplémentaires
 et sélectionnez Inclure le champ.
et sélectionnez Inclure le champ.Aperçu des données :

Liste des champs :

La liste des modifications est supprimée, le champ fait désormais partie des données de flux et vous pouvez voir les numéros de ligne générés dans les étapes de flux suivantes.
Détails des numéros de ligne source
Lorsque vous incluez le Numéro de ligne source dans votre ensemble de données, les options et considérations suivantes s’appliquent.
- Les numéros de ligne de la source de données sont appliqués avant l’échantillonnage ou le filtrage des données.
- Il en résulte un nouveau champ appelé Numéro de ligne source qui persiste tout au long du flux. Ce nom de champ n’est pas localisé, mais peut être renommé à tout moment.
- S’il existe déjà un champ du même nom, le nouveau nom de champ est incrémenté de 1, par exemple Numéro de ligne source-1, Numéro de ligne source-2, etc.
- Vous pouvez modifier le type de données du champ dans les étapes suivantes.
- Vous pouvez utiliser ce champ dans les opérations de flux et les calculs.
- Cette valeur est générée de nouveau pour l’intégralité de l’ensemble de données chaque fois que les données d’entrée sont actualisées ou que le flux est exécuté.
- Ce champ n’est pas disponible pour les unions d’entrée.
Définir l’en-tête et la ligne de début des données
Pris en charge dans Tableau Prep Builder à partir de la version 2023.3 et sur le Web pour les fichiers texte (.csv) et à partir de la version 2024.1 pour les fichiers Excel (.xls).
Vous pouvez définir une ligne spécifique comme ligne d’en-tête de champ et identifier la ligne de début des données pour les fichiers Excel et texte (.csv).
Lors de la connexion à des fichiers Excel ou texte, il arrive souvent que les fichiers texte soient formatés avec des méta-informations dans les premières lignes afin de les rendre lisibles par un utilisateur humain. Par défaut, Tableau Prep interprète les premières lignes des fichiers CSV comme étant la ligne d’en-tête de champ. Les fichiers Excel sont interprétés en fonction des types de champs et des lignes vides. Tableau Prep peut sélectionner une ligne comme en-tête ou ne pas inclure de ligne d’en-tête.
Par exemple, dans les fichiers suivants, STORE DETAILS est interprété comme la ligne d’en-tête.
Vous pouvez exclure les informations de métadonnées (1) et fournir la structure de schéma correcte de vos données en définissant la ligne 3 comme en-tête (2) et la ligne 4 comme ligne de début des données.
Fichiers CSV :

Fichiers Excel :

Par exemple, l’exemple suivant montre les paramètres par défaut pour l’en-tête de ligne et la ligne de début :

Voici comment se présentent les données en cas d’exclusion des métadonnées :

Remarque : l’aperçu des données ne reflète pas les modifications apportées aux paramètres des échantillons de données.
Configurer la ligne d’en-tête et la ligne de début
À l’aide de la vue d’entrée Aperçu des données, vous pouvez inspecter visuellement la structure du schéma de vos données et définir les lignes d’en-tête et de début pour exclure les métadonnées des données de la source d’entrée.
Vous pouvez définir la ligne de début des données sur n’importe quelle valeur supérieure à la valeur de la ligne d’en-tête. Par défaut, Tableau Prep définit la ligne de début des données sur le numéro consécutif suivant la ligne d’en-tête. Toutes les lignes situées entre la ligne d’en-tête et la ligne de début des données sont ignorées.
Remarque : l’aperçu des données et l’interpréteur de données s’excluent mutuellement. L’interpréteur de données détecte uniquement les sous-tables dans vos feuilles de calcul Excel et ne prend pas en charge la spécification de la ligne de début pour les fichiers texte et les feuilles de calcul.
- Sélectionnez l’étape des données entrantes.
- Dans la barre d’outils, cliquez sur la vue d’entrée Aperçu des données.
- Sur la ligne que vous souhaitez définir comme en-tête, cliquez sur le menu Options supplémentaires et sélectionnez Définir comme en-tête.
- Sur la ligne que vous souhaitez définir comme ligne de début des données, cliquez sur le menu Options supplémentaires et sélectionnez Définir comme début des données. Par défaut, la ligne de début des données est définie sur le numéro de ligne consécutif suivant.

Le menu Options d’en-tête affiche la ligne d’en-tête et le numéro de la ligne de début des données. Vous pouvez éventuellement définir l’en-tête et la première ligne directement dans la boîte de dialogue Options d’en-tête.

Plusieurs schémas dans un seul fichier
Si un seul fichier comprend plusieurs sources de données, vous pouvez créer une étape des données entrantes supplémentaire en vous connectant à la même source de données, puis définir les lignes d’en-tête et de début des données pour la deuxième source de données. Par exemple, le fichier suivant contient une source de données commençant à la ligne numéro 3 (1), avec un second schéma différent, distinct commençant à la ligne numéro 28 (2).


Pour ce type de source de données, procédez comme suit.
- Sélectionnez la première étape des données entrantes.
- Dans la barre d’outils, cliquez sur la vue d’entrée Aperçu des données.
- Sur la ligne que vous souhaitez définir comme en-tête, cliquez sur le menu Options supplémentaires et sélectionnez Définir comme en-tête.
- Sur la ligne que vous souhaitez définir comme ligne de début des données, cliquez sur Options supplémentaires et sélectionnez Définir comme début des données. Par défaut, la ligne de début des données est définie sur le numéro de ligne consécutif suivant.
- Sélectionnez l’étape des données entrantes suivante.
- Répétez les étapes ci-dessus pour définir l’en-tête et la ligne de début des sources de données supplémentaires.
Toutes les lignes situées entre la ligne d’en-tête et la ligne de début des données sont ignorées.
Réunir plusieurs tables
Pris en charge dans Tableau Prep Builder à partir de la version 2024.1 et sur le Web pour les fichiers texte (.csv).
Vous pouvez réunir plusieurs tables à partir de sources de données ayant la même structure de schéma et la même ligne de métadonnées.
- Connectez-vous aux fichiers et sélectionnez la première étape des données entrantes.
- Dans la barre d’outils, cliquez sur la vue d’entrée Aperçu des données.
- Sur la ligne que vous souhaitez définir comme en-tête, cliquez sur Options supplémentaires et sélectionnez Définir comme en-tête.
- Sur la ligne que vous souhaitez définir comme ligne de début des données, cliquez sur Options supplémentaires et sélectionnez Définir comme début des données.
- Cliquez sur l’onglet Tables et sélectionnez Réunir plusieurs tables.
- Cliquez sur Appliquer pour réunir les fichiers et conserver la sélection d’en-tête et de ligne pour tous les fichiers de l’union des données entrantes. Cela suppose que la structure des fichiers et le schéma des fichiers de données entrantes sont identiques.

Se connecter à une requête SQL personnalisée
Si votre base de données prend en charge SQL personnalisé, vous verrez s’afficher SQL personnalisé dans la partie inférieure du volet Connexions. Double-cliquez sur SQL personnalisé pour ouvrir l’onglet SQL personnalisé où vous pouvez entrer des requêtes pour présélectionner les données et utiliser des opérations spécifiques aux sources. Une fois que la requête a récupéré les données, vous pouvez sélectionner les champs à inclure, appliquer des filtres, ou modifier le type de données avant d’ajouter les données à votre flux.

Pour plus d’informations sur l’utilisation de SQL personnalisé, consultez Utiliser SQL personnalisé pour la connexion aux données.
Appliquer des opérations de nettoyage à une étape des données entrantes
Seules quelques opérations de nettoyage sont disponibles dans une étape des données entrantes. Vous pouvez apporter n’importe laquelle des modifications suivantes dans la liste des champs d’entrée. Vos modifications sont enregistrées dans le volet Modifications et des annotations sont ajoutées à gauche de l’étape des données entrantes dans le volet Flux et dans la liste des champs d’entrée.
- Masquer le champ : masquez les champs plutôt que de les supprimer afin de réduire l’encombrement de votre flux. Vous pourrez toujours les afficher de nouveau si nécessaire. Les champs masqués sont toujours inclus lorsque vous exécutez votre flux.
- Filtre : utilisez l’éditeur de calcul pour filtrer les valeurs. Depuis la version 2023.1, vous pouvez également utiliser la boîte de dialogue Filtre de dates relatives pour spécifier rapidement des plages de dates applicables à tout champ de date ou de date/heure.
- Renommer un champ : dans le champ Nom du champ, double-cliquez (Ctrl+clic sur MacOS) sur le nom du champ et entrez un nouveau nom de champ.
- Modifier le type de données : cliquez sur le type de données du champ et sélectionnez un nouveau type de données dans le menu. Cette option est actuellement prise en charge pour les fichiers Microsoft Excel, les fichiers texte et PDF, les sources de données Box, Dropbox, Google Drive et OneDrive. Toutes les autres sources de données peuvent être modifiées dans une étape de nettoyage.
Sélectionner les champs à inclure dans le flux
Remarque : depuis la version 2023.1, vous pouvez sélectionner plusieurs champs pour les masquer, les afficher, les supprimer ou les inclure. Dans les versions précédentes, vous pouviez utiliser un champ à la fois et cocher ou décocher les cases afin d’inclure ou de supprimer des champs.
Le volet Entrée affiche une liste des champs de votre ensemble de données. Par défaut, tous les champs sont inclus sauf le champ généré automatiquement, Numéro de ligne source. Utilisez la vue Aperçu des données ou Liste pour gérer vos champs.
- Rechercher : recherchez des champs.
- Masquer les champs : masquez les champs que vous souhaitez inclure dans votre sortie de flux, mais que vous n’avez pas besoin de nettoyer.
- Dans la liste des champs, cliquez sur l’icône d’œil
 ou sélectionnez Masquer les champs dans le menu Options supplémentaires.
ou sélectionnez Masquer les champs dans le menu Options supplémentaires. - Dans l’aperçu des données, sélectionnez Masquer les champs dans le menu Options supplémentaires.
Les champs sont traités par le flux pendant l’exécution. Vous pouvez également afficher les champs à tout moment si nécessaire. Pour plus d’informations, consultez Masquer des champs(Le lien s’ouvre dans une nouvelle fenêtre).
- Dans la liste des champs, cliquez sur l’icône d’œil
- Inclure les champs: ajoutez à votre flux des champs qui ont été marqués comme supprimés.
- Dans la liste des champs, sélectionnez une ou plusieurs lignes et faites un clic droit (Cmd+clic sur MacOS) ou cliquez sur le menu Options supplémentaires et sélectionnez Inclure des champs pour réintégrer des champs marqués comme supprimés.
- Dans l’aperçu des données, cliquez sur le menu Options supplémentaires dans le champ que vous souhaitez inclure dans votre flux et sélectionnez Inclure des champs.
- Dans la liste des champs, sélectionnez une ou plusieurs lignes et faites un clic droit (Cmd+clic sur MacOS) ou cliquez sur le menu Options supplémentaires
- Supprimer des champs :
- Dans la liste des champs, sélectionnez une ou plusieurs lignes et faites un clic droit (Cmd-clic sur MacOS), cliquez sur le symbole « X », ou cliquez sur le menu Options supplémentaires puis sélectionnez Supprimer des champs pour supprimer les champs que vous ne souhaitez pas inclure dans le flux.
- Dans l’aperçu des données, cliquez sur le menu Options supplémentaires dans le champ que vous souhaitez supprimer et sélectionnez Supprimer le champ.
- Dans la liste des champs, sélectionnez une ou plusieurs lignes et faites un clic droit (Cmd-clic sur MacOS), cliquez sur le symbole « X », ou cliquez sur le menu Options supplémentaires
Appliquer des filtres au champ dans l’étape des données entrantes
Appliquez des filtres à l’étape des données entrantes pour réduire la quantité de données que vous ingérez à partir de vos sources de données. Vous pouvez gagner en efficacité en termes de performances interactives et obtenir un échantillon de données plus utile en éliminant les données que vous ne souhaitez pas traiter lors de l’exécution du flux.
Dans l’étape des données entrantes, vous pouvez appliquer des filtres à l’aide de l’éditeur de calcul. Depuis la version 2023.1, vous pouvez également utiliser la boîte de dialogue Filtre de dates relatives pour spécifier une plage de dates exacte de valeurs à inclure pour les types de champs de date et de date/heure. Pour plus d’informations, consultez « Filtre de dates relatives » dans Filtrer vos données(Le lien s’ouvre dans une nouvelle fenêtre).
Vous pouvez utiliser d’autres options de filtre dans l’étape de nettoyage ou d’autres types d’étapes. Pour plus d’informations, consultez Filtrer vos données(Le lien s’ouvre dans une nouvelle fenêtre).
Appliquer un filtre de calcul
- Dans la barre d’outils, cliquez sur Filtrer les valeurs. Utilisez l’une des méthodes suivantes pour filtrer vos données :
Dans la liste des champs, cliquez sur le menu Options supplémentaires
à partir du nom du champ et sélectionnez Filtre > Calcul….Dans l’aperçu des données, cliquez sur le menu Options supplémentaires
à partir du nom du champ et sélectionnez Filtre > Calcul....


Entrez vos critères de filtre dans l’éditeur de calcul.

Appliquer un filtre de dates relatives
- Sélectionnez un champ avec un type de données Date ou Date et heure, puis utilisez l’une des méthodes suivantes pour appliquer un filtre de dates relatives.
- Dans la liste des champs, faites un clic droit (ou Cmd-clic sous MacOS) ou cliquez sur le menu Options supplémentaires dans la colonne Nom du champ et sélectionnez Filtre > Dates relatives.
- Dans l’aperçu des données, cliquez sur le menu Options supplémentaires dans le champ et sélectionnez Filtre > Dates relatives.

- Dans la liste des champs, faites un clic droit (ou Cmd-clic sous MacOS) ou cliquez sur le menu Options supplémentaires
Dans la boîte de dialogue Filtre de dates relatives, spécifiez la plage exacte d’années, de trimestres, de mois, de semaines ou de jours que vous voulez inclure dans votre flux. Vous pouvez également configurer un ancrage relatif à une date spécifique et inclure les valeurs null.
Remarque : par défaut, le filtre fonctionne par rapport à la date à laquelle le flux est exécuté ou prévisualisé dans l’expérience de création.

Modifier les noms de fichiers
Utilisez l’une des méthodes suivantes pour modifier le nom d’un champ.
Une annotation est ajoutée à la grille de champs et dans le volet Flux à gauche de l’étape des données entrantes. Vos modifications sont également enregistrées dans le volet Modifications.
- Dans la liste des champs, sélectionnez un champ dans la colonne Nom du champ et cliquez sur Renommer le champ. Entrez le nouveau nom du champ.
- Dans l’aperçu des données, sélectionnez un champ et cliquez sur Renommer le champ. Entrez le nouveau nom du champ.


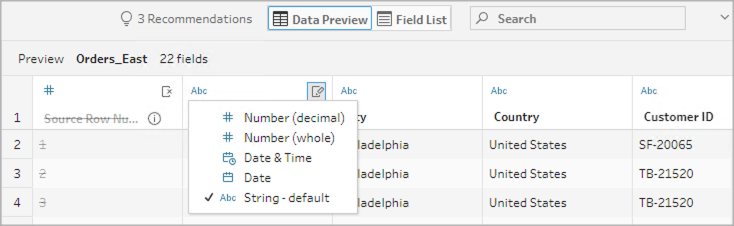
Modifier les types de données
Actuellement pris en charge pour les fichiers Microsoft Excel, les fichiers texte et PDF, les sources de données Box, Dropbox, Google Drive et OneDrive. Toutes les autres sources de données peuvent être modifiées dans une étape de nettoyage.
Remarque : le type de données pour le numéro de ligne source (à partir de la version 2023.1) ne peut être modifié que dans une étape de nettoyage ou un autre type d’étape.
Pour modifier le type de données d’un champ, procédez comme suit :
- Cliquez sur le type de données pour le champ.
- Sélectionnez le nouveau type de données dans le menu.
- Aperçu des données :
- Vue du champ :

Vous pouvez également modifier le type de données des champs dans d’autres types d’étape du flux ou affecter des types de données pour vous aider à valider vos valeurs de champ. Pour plus d’informations sur la modification de votre type de données ou l’utilisation de types de données, voir Vérifier les types de données affectés à vos données(Le lien s’ouvre dans une nouvelle fenêtre) et Utiliser les rôles des données pour valider vos données(Le lien s’ouvre dans une nouvelle fenêtre).
Configurer les propriétés des champs
Lorsque vous travaillez avec des fichiers texte, vous voyez s’afficher un onglet Paramètres où vous pouvez modifier votre connexion et configurer les propriétés du texte, par exemple le séparateur de champs pour les fichiers texte. Vous pouvez également modifier la connexion aux fichiers dans le volet Connexions ou configurer les paramètres d’actualisation incrémentielle. Pour plus d’informations sur la configuration de l’actualisation incrémentielle pour votre flux, consultez Actualiser les données de flux à l’aide d’une actualisation incrémentielle.
Lorsque vous travaillez avec des fichiers texte ou Excel, vous pouvez corriger les types de données qui ont été incorrectement induits avant que vous commenciez votre flux. Les types de données peuvent toujours être modifiés par étapes consécutives dans le volet Profil après le démarrage de votre flux.
Configurer les paramètres de texte dans les fichiers texte
Pour modifier les paramètres utilisés pour analyser les fichiers texte, faites votre choix parmi les options suivantes :
La première ligne contient l’en-tête (par défaut) : sélectionnez cette option pour utiliser la première ligne comme étiquettes de champs.
Générer les noms de champs automatiquement : sélectionnez cette option si vous souhaitez que Tableau Prep Builder génère automatiquement les en-têtes de champ. La convention de dénomination des champs suit le même modèle que Tableau Desktop, par exemple F1, F2 etc.
Séparateur de champs : sélectionnez un caractère dans la liste à utiliser pour séparer les colonnes. Sélectionnez Autre pour entrer un caractère personnalisé.
Qualificateur de texte : sélectionnez le caractère qui entoure les valeurs dans le fichier.
Jeu de caractères : sélectionnez le jeu de caractères qui décrit le codage du fichier texte.
Paramètres régionaux : sélectionnez les paramètres régionaux à utiliser pour analyser le fichier. Ce paramètre indique quelle décimale et quel séparateur de milliers utiliser.
Définir la taille de votre échantillon de données
La sélection de lignes stratifiées est prise en charge dans Tableau Prep Builder version 2023.3 et versions ultérieures.
Par défaut, Tableau Prep détermine par défaut le nombre maximum de lignes requises pour explorer et préparer efficacement les données pour un échantillon représentatif de votre ensemble de données. D’après l’exemple d’algorithme de Tableau Prep, plus vos données d’entrée contiennent de champs, plus le nombre de lignes autorisées est petit.
Lorsque les données sont échantillonnées, l’échantillon résultant peut inclure ou non toutes les lignes dont vous avez besoin, selon la manière dont l’échantillon a été calculé et retourné. Par exemple, par défaut, Tableau Prep utilise la méthode de sélection rapide pour échantillonner les données.
Avec cette méthode, les lignes supérieures sont chargées, et si votre ensemble de données est volumineux et que les données sont structurées chronologiquement, vous verrez peut-être vos premières données échantillonnées, mais pas une représentation complète de toutes les données. Si vous ne voyez pas les données attendues, vous pouvez modifier les paramètres de l’échantillon de données pour exécuter à nouveau la requête.
Lorsque vous créez ou modifiez des flux à l’aide de la création Web, le nombre maximum de lignes qu’un utilisateur peut sélectionner lors de l’utilisation d’ensembles de données volumineux est configuré par l’administrateur Tableau Server. Dans Tableau Cloud, cette limite est fixe et ne peut pas être modifiée par l’administrateur. Pour plus d’informations, consultez Échantillons de données et limites de traitement dans l’aide de Tableau Server(Le lien s’ouvre dans une nouvelle fenêtre) ou Tableau Cloud(Le lien s’ouvre dans une nouvelle fenêtre).
Préparation de vos données pour l’échantillonnage
Si vous savez que certaines valeurs ne sont pas requises pour votre analyse, supprimez les champs de l’étape des données entrantes afin que les données ne soient pas incluses lorsque vous créez ou exécutez votre flux.
Si vous disposez d’un ensemble de données volumineux qui déclenche l’échantillonnage, la suppression des champs à l’étape des données entrantes augmente le nombre de lignes chargées par Tableau Prep. Lorsque l’échantillonnage n’est pas appliqué, la suppression des champs à l’étape des données entrantes réduit le volume de données chargé par Tableau Prep.
Après avoir supprimé les champs et les valeurs inutiles de l’ensemble de données, vous pouvez modifier la quantité de données chargées pour l’échantillonnage ou la méthode d’échantillonnage.
Modification des paramètres d’échantillon de données
Les échantillons de données facilitent l’expérience interactive et rendent la modification du flux plus efficace que le profilage de toutes les données et l’application de modifications à des ensembles de données plus volumineux pendant que vous travaillez. Toutes les données sont utilisées lorsque vous exécutez le flux. Toutes les modifications que vous apportez dans la section d’échantillon s’appliquent au flux actuel.
Pour valider vos données après le nettoyage et la mise en forme, exécutez le flux et affichez le résultat dans Tableau Desktop.
Remarque : exécutez le flux complet plutôt que d’afficher un échantillon dans Tableau Desktop pour pouvoir voir l’intégralité de vos données. Si vous voyez des valeurs inattendues ou incorrectes qui ne figuraient pas dans l’échantillon, vous pouvez revenir dans Tableau Prep pour résoudre ce problème.
- Supprimez les champs et les valeurs inutiles de l’ensemble de données.
- Sélectionnez une étape des données entrantes, puis cliquez sur l’onglet Échantillon de données.

Sélectionnez le nombre de lignes que vous souhaitez charger pour l’échantillonnage des données. Le nombre de lignes que vous choisissez a un effet sur les performances.
- Automatique : (par défaut) charge les données rapidement et calcule automatiquement le nombre de lignes afin qu’il y ait suffisamment de données pour un échantillon. Le nombre de lignes chargées est égal ou inférieur à 393 216.
Spécifier : généralement utilisé pour charger un petit nombre de lignes afin que vous puissiez comprendre la structure des données et réduire les temps de chargement. Spécifiez un nombre de lignes inférieur à 1 million.
Remarque : dans la création Web, le nombre maximum de lignes qu’un utilisateur peut sélectionner lors de l’utilisation d’ensembles de données volumineux est configuré par l’administrateur Tableau Server. Dans Tableau Cloud, cette limite est fixe et ne peut pas être modifiée par l’administrateur. En tant qu’utilisateur, vous pouvez sélectionner le nombre de lignes jusqu’à cette limite.
- Maximum : charge autant de données que possible pour une sélection de lignes inférieure ou égale à 1 048 576. Assurez-vous de satisfaire aux Exigences de hautes performances pour les ensembles de données volumineux.
Sélectionnez la méthode à appliquer au nombre de lignes renvoyées pour l’échantillonnage. Les performances peuvent être affectées si vous sélectionnez l’option Aléatoire ou Stratifié.
Remarque : la sélection de lignes n’est prise en charge que si votre source de données d’entrée est compatible avec l’échantillonnage aléatoire. Si ce n’est pas le cas, la méthode par défaut de sélection rapide est utilisée.
Sélection rapide : (par défaut) échantillonne les données en fonction des performances car les lignes sont renvoyées le plus rapidement possible. Certaines lignes peuvent ne pas être incluses dans l’échantillon. Les lignes utilisées pour l’échantillonnage peuvent être les N premiers nombres de lignes ou les lignes que la base de données a mises en cache dans la mémoire lors d’une précédente requête. Bien qu’il s’agisse presque toujours d’un résultat plus rapide qu’un échantillonnage, l’échantillon renvoyé peut être biaisé (par exemple, des données pour une seule année plutôt que pour toutes les années présentes dans les données, si les enregistrements sont triés par ordre chronologique).
Aléatoire : vous permet d’échantillonner un ensemble de données volumineux et de renvoyer une représentation générale de l’ensemble de la sélection de lignes. Tableau Prep renvoie des lignes aléatoires en fonction de toutes les lignes sélectionnées chargées. Cette option peut avoir une incidence sur les performances lors de la récupération initiale des données.
- Stratifié : vous permet d’effectuer un regroupement selon un champ spécifié, puis d’échantillonner les données au sein de chaque sous-groupe. Prep renvoie le nombre demandé de lignes réparties dans le champ sélectionné en vue d’un regroupement de la façon la plus équitable possible. Dans certains cas, en fonction de la source de données, certaines valeurs du champ peuvent comporter plus de lignes que d’autres.
Exemples
Ces exemples sont basés sur l’ensemble de données Indicateurs Mondiaux inclus dans Tableau Prep. Le premier échantillon utilise l’option Automatique pour le nombre de lignes et l’option Aléatoire pour la méthode d’échantillonnage ou le nombre de lignes à renvoyer pour l’échantillonnage.

Une fois ces valeurs sélectionnées, 3 000 lignes sont sélectionnées au hasard et utilisées pour représenter l’ensemble des données.

Le deuxième exemple utilise l’option Spécifier pour le nombre de lignes et l’option Stratifié pour la méthode d’échantillonnage. Le nombre de lignes spécifié est défini sur la valeur 7 et le champ Taux de natalité est utilisé pour le regroupement.

Les nouveaux exemples de valeurs affichent une distribution unifiée de 7 lignes de valeurs uniques à travers tous les champs.
