Save and Share Your Work
As of 14 October 2025, Data Cloud has been rebranded to Data 360. During this transition, you may see references to Data Cloud in our application and documentation. While the name is new, the functionality and content remains unchanged.
At any point in your flow you can manually save your work, or let Tableau automatically do it for you when creating or editing flows on the web. When working with flows on the web, there are a few differences.
For more information about authoring flows on the web, see Tableau Prep on the Web in the Tableau Server(Link opens in a new window) and Tableau Cloud(Link opens in a new window) help.
| Tableau Prep Builder | Tableau Prep on the web |
|---|---|
|
|
To keep data fresh, you can manually run your flows from Tableau Prep Builder or from the command line. You can also run flows published on Tableau Server or Tableau Cloud manually or on a schedule. For more information about running flows, see Publish a Flow to Tableau Server or Tableau Cloud.
Save a flow
In Tableau Prep Builder, you can manually save your flow to back up your work before performing any additional operations. Your flow is saved in the Tableau Prep flow (.tfl) file format.
You can also package your local files (Excel, Text Files, and Tableau extracts) with your flow to share with others, just like packaging a workbook for sharing in Tableau Desktop. Only local files can be packaged with a flow. Data from database connections, for example, aren't included.
In web authoring, local files are automatically packaged with our flow. Direct file connections aren't yet supported.
When you save a packaged flow, the flow is saved as a Packaged Tableau Flow File (.tflx).
- To manually save your flow, from the top menu, select File > Save.
- In Tableau Prep Builder, to package your data files with your flow, from the top menu, do one of the following:
- Select File > Export Packaged Flow
- Select File > Save As. Then in the Save As dialog, select Packaged Tableau Flow Files from the Save as type drop down menu.
Automatically save your flows on the web
If you create or edit flows on the web, when you make a change to the flow (connect to a data source, add a step and so on) your work is automatically saved every few seconds as a draft so you won't lose your work.
You can only save flows to the server you’re currently signed into. You can't create a draft flow on one server and try to save or publish it to another server. If you want to publish the flow to a different project on the server, use the File > Publish As menu option, then select your project from the dialog.
Draft flows can only be seen by you until you publish them and make them available to anyone who has permissions to access the project on your server. Flows in a draft status are tagged with a Draft badge, so you can easily find your flows that are in progress. If the flow has never been published, a Never Published badge is shown next to the Draft badge.

After a flow is published and you edit and republish the flow, a new version is created. You can see a list of flow versions in the Revision History dialog. From the Explore page, click the ![]() Actions menu and select Revision History.
Actions menu and select Revision History.
For more information about managing revision history, see Work with Content Revisions(Link opens in a new window) in the Tableau Desktop help.
Note: Autosave is enabled by default. It’s possible, but not recommended, for administrators to disable autosave on a site. To turn off autosave, use the Tableau Server REST API method "Update Site" and set the flowAutoSaveEnabled attribute to false. For more information, see Tableau Server REST API Site Methods: Update Site(Link opens in a new window).
Automatic file recovery
By default, Tableau Prep Builder automatically saves a draft of any open flows if the application freezes or crashes. Draft flows are saved in your Recovered Flows folder in your My Tableau Prep repository. The next time you open the application, a dialog is shown with a list of the recovered flows to select from. You can open a recovered flow and continue where you left off, or delete the recovered flow file if you don't need it.
Note: If you have recovered flows in your Recovered Flows folder, this dialog shows every time you open the application until that folder is empty.

If you don't want this feature enabled, as an Administrator, you can turn it off during install or after install. For more information about how to turn off this feature, see Turn off file recovery(Link opens in a new window) in the Tableau Desktop and Tableau Prep Deployment Guide.
Recover deleted flows
Supported in Tableau Prep Web Authoring in Tableau Cloud and Tableau Server version 2025.3 and later.
In web authoring, you can retrieve previously deleted flows from the Recycle Bin. If Recycle Bin is turned on, instead of being permanently deleted, flows are temporarily moved to the Recycle Bin, where you can retrieve or permanently delete them. Flows in a draft state are still permanently deleted. For more information about Recycle Bin, see Recycle Bin(Link opens in a new window).
Note: This feature is not available in Tableau Prep Builder.
The following is required to use this feature:
Permissions: You must be assigned the role of Site Administrator, Server Administrator, Creator or Explorer (can publish).
Site setting: Recycle bin is turned on for your site
Flow status: Flow must be published.
The length of time that flows are stored in the Recycle Bin is set by your administrator.
Recover a flow
From the Home page, expand the side pane and then select Recycle Bin.
On the Recycle Bin page, select Flows from the Content Type dropdown menu.
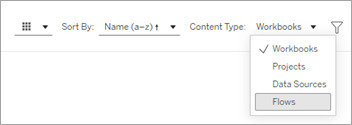
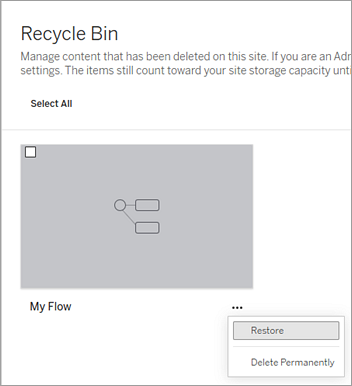
Select the More actions menu for the flow that you want to restore, and then select Restore.
Select a project as the restore location.
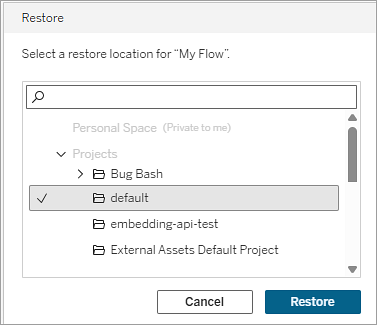
Select Restore.
View flow output in Tableau Desktop
Note: This option isn’t available on the web.
Sometimes when you’re cleaning your data you might want to check your progress by looking at it in Tableau Desktop. When your flow opens in Tableau Desktop, Tableau Prep Builder creates a permanent Tableau .hyper file and a Tableau data source (.tds) file. These files are saved in your Tableau repository in the Data sources file so you can experiment with your data at any time.
When you open the flow in Tableau Desktop, you can see the data sample that you’re working with in your flow with the operations applied to it, up to the step that you selected.
Note: While you can experiment with your data, Tableau only shows you a sample of your data and you won't be able to save the workbook as a packaged workbook (.twbx). When you’re ready to work with your data in Tableau, create an output step in your flow and save the output to a file or as a published data source, then connect to the full data source in Tableau.
To view your data sample in Tableau Desktop do the following:
- Right-click on the step where you want to view your data, and select Preview in Tableau Desktop from the context menu.

- Tableau Desktop opens on the Sheet tab.
Create data extract files and published data sources
To create your flow output, run your flow. When you run your flow, your changes are applied to your entire data set. Running the flow results in a Tableau Data Source (.tds) and a Tableau Data Extract (.hyper) file.
Note: Flows that include spatial data can only be output to .hyper files or as a published data source. Other output types aren’t currently supported. For more information about working with spatial data, see Create Spatial Calculations and Joins.(Link opens in a new window)
Tableau Prep Builder
You can create an extract file from your flow output to use in Tableau Desktop or to share your data with third parties. Create an extract file in the following formats:
- Hyper Extract (.hyper): This the latest Tableau extract file type.
- Comma Separated Value (.csv): Save the extract to a .csv file to share your data with third parties. The encoding of the exported CSV file will be UTF-8 with BOM.
- Microsoft Excel (.xlsx): A Microsoft Excel spreadsheet.
Tableau Prep Builder and on the web
Publish your flow output as a published data source or output to a database.
- Save your flow output as a data source to Tableau Server or Tableau Cloud to share your data and provide centralised access to the data you’ve cleaned, shaped and combined.
- Save your flow output to a database to create, replace or append the table data with your clean, prepared flow data. For more information, see Save flow output data to external databases.
Use incremental refresh when running your flow to save time and resources by refreshing only new data instead of your full data set. For information about how to configure and run your flow using incremental refresh, see Refresh Flow Data Using Incremental Refresh.
Note: To publish Tableau Prep Builder output to Tableau Server, the Tableau Server REST API must be enabled. For more information, see Rest API Requirements(Link opens in a new window) in the Tableau Rest API Help. To publish to a server that uses Secure Socket Layer (SSL) encryption certificates, additional configuration steps are needed on the machine running Tableau Prep Builder. For more information, see the Before you Install(Link opens in a new window) in the Tableau Desktop and Tableau Prep Builder Deployment Guide.
Include parameters in your flow output
Supported in Tableau Prep Builder and on the web starting in version 2021.4
Include parameter values in your flow output filenames, paths, table names or custom SQL scripts (version 2022.1.1 and later) to easily run your flows for different data sets. For more information, see Create and Use Parameters in Flows.
Create an extract to a file
Note: This output option is not available when creating or editing flows on the web.
- Click the plus icon
 on a step and select Add Output.
on a step and select Add Output.If you have run the flow before, click the run flow
 button on the Output step. This runs the flow and updates your output.
button on the Output step. This runs the flow and updates your output.The Output pane opens and shows you a snapshot of your data.

- In the left pane select File from the Save output to drop-down list. In prior versions, select Save to file.
- Click the Browse button, then in the Save Extract As dialog, enter a name for the file and click Accept.
- In the Output type field, select from the following output types:
- Tableau Data Extract (.hyper)
- Comma Separated Values (.csv)
(Tableau Prep Builder) In the Write Options section, view the default write option to write the new data to your files and make any changes as needed. For more information, see Configure write options.
- Create table: This option creates a new table or replaces the existing table with the new output.
- Append to table: This option adds the new data to your existing table. If the table doesn't already exist, a new table is created and subsequent runs add new rows to this table.
Note: Append to table isn't supported for .csv output types. For more information about supported refresh combinations, see Flow refresh options.
- Click Run Flow to run the flow and generate the extract file.
Create an extract to a Microsoft Excel Worksheet
Supported in Tableau Prep Builder version 2021.1.2 and later. This output option is not available when creating or editing flows on the web or when creating outputs for flows that include spatial data.
When you output flow data to a Microsoft Excel worksheet you can create a new worksheet or append or replace data in an existing worksheet. The following conditions apply:
- Only Microsoft Excel .xlsx file formats are supported.
- The worksheet rows begin at cell A1.
- When appending or replacing data, the first row is assumed to be headers.
- Header names are added when creating a new worksheet, but not when adding data to an existing worksheet.
- Any formatting or formulas in existing worksheets aren't applied to the flow output.
- Writing to named tables or ranges is not currently supported.
- Incremental refresh is not currently supported.
Output flow data to a Microsoft Excel worksheet file
- Click the plus icon on a step and select Add Output.
If you have run the flow before, click the run flow
button on the Output step. This runs the flow and updates your output.The Output pane opens and shows you a snapshot of your data.

- In the left pane select File from the Save output to drop-down list.
- Click the Browse button, then in the Save Extract As dialog, enter or select the file name and click Accept.
- In the Output type field, select Microsoft Excel (.xlsx).

- In the Worksheet field, select the worksheet you want to write your results to, or enter a new name in the field instead, then click on Create new table.
- In the Write Options section, select one of the following write options:
- Create table: Creates or re-creates (if the file already exists) the worksheet with your flow data.
- Append to table: Adds new rows to an existing worksheet. If the worksheet doesn't exist, one is created and subsequent flow runs add rows to that worksheet.
- Replace data: Replaces all of the existing data except the first row in an existing worksheet with the flow data.
A field comparison shows you the fields in your flow that match the fields in your worksheet, if it already exists. If the worksheet is new, then a one-to-one field match is shown. Any fields that don't match are ignored.

- Click Run Flow to run the flow and generate the Microsoft Excel extract file.
Create a published data source
- Click the plus icon on a step and select Add Output.
Note: Tableau Prep Builder refreshes previously published data sources and maintains any data modelling (for example calculated fields, number formatting, and so on) that might be included in the data source. If the data source can’t be refreshed, the data source, including data modelling, will be replaced instead.
- The output pane opens and shows you a snapshot of your data.

- From the Save output to drop-down list, select Published data source (Publish as data source in previous versions) . Complete the following fields:
- Server (Tableau Prep Builder only): Select the server where you want to publish the data source and data extract. If you aren't signed in to a server you will be prompted to sign in.
Note: Starting in Tableau Prep Builder version 2020.1.4, after you sign in to your server, Tableau Prep Builder remembers your server name and credentials when you close the application. The next time you open the application, you are already signed into your server.
On Mac, you may be prompted to provide access to your Mac keychain so that Tableau Prep Builder can securely use SSL certificates to connect to your Tableau Server or Tableau Cloud environment.
If you are outputting to Tableau Cloud, include the pod your site is hosted on in the "serverUrl". For example, "https://eu-west-1a.online.tableau.com" not "https://online.tableau.com".
- Project: Select the project where you want to load the data source and extract.
- Name: Enter a file name.
- Description: Enter a description for the data source.
- Server (Tableau Prep Builder only): Select the server where you want to publish the data source and data extract. If you aren't signed in to a server you will be prompted to sign in.
- (Tableau Prep Builder) In the Write Options section, view the default write option to write the new data to your files and make any changes as needed. For more information, see Configure write options
- Create table: This option creates a new table or replaces the existing table with the new output.
- Append to table: This option adds the new data to your existing table. If the table doesn't already exist, a new table is created and subsequent runs will add new rows to this table.
- Click Run Flow to run the flow and publish the data source.
Save flow output data to external databases
This output option is not available when creating outputs for flows that include spatial data.
Important: This feature enables you to permanently delete and replace data in an external database. Be sure that you have permissions to write to the database.
To prevent data loss, you can use the Custom SQL option to make a copy of your table data and run it before writing the flow data to the table.
You can connect to data from any of the connectors that Tableau Prep Builder or the web supports and output data to an external database. This enables you to add or update data in your database with clean, prepped data from your flow each time the flow is run. This feature is available for both incremental and full refresh options unless otherwise noted. For more information about how to configure incremental refresh, see Refresh Flow Data Using Incremental Refresh.
When you save your flow output to an external database, Tableau Prep does the following:
- Generates the rows and runs any SQL commands against the database.
- Writes the data to a temporary table (or staging area if outputting to Snowflake) in the output database.
- If the operation is successful, the data is moved from the temporary table (or your staging area for Snowflake) into the destination table.
- Runs any SQL commands that you want to run after writing the data to the database.
If the SQL script fails, the flow will fail. However your data will still be loaded to your database tables. You can try running the flow again or manually run your SQL script on your database to apply it.
Output options
You can select the following options when writing data to a database. If the table doesn't already exist, it's created when the flow is first run.
- Append to table: This option adds data to an existing table. If the table doesn't exist, the table is created when the flow is first run and data is added to that table with each subsequent flow run.
- Create table: This option creates a new table with the data from your flow. If the table already exists, the table and any existing data structure or properties defined for the table is deleted and replaced with a new table that uses the flow data structure. Any fields that exist in the flow are added to the new database table.
- Replace data: This option deletes the data in your existing table and replaces it with the data in your flow, but preserves the structure and properties of the database table. If the table doesn't exist, the table is created when the flow is first run and the table data is replaced with each subsequent flow run.
Additional options
In addition to the write options, you can also include custom SQL scripts or add a new tables to your database.
- Custom SQL scripts: Enter your custom SQL and select whether to run your script before, after or both before and after data is written to the database tables. You can use these scripts to create a copy of your database table before the flow data is written to the table, add an index, add other table properties and so on.
Note: Starting in version 2022.1.1, you can also insert parameters in your SQL scripts. For more information, see Apply user parameters to output steps.
- Add a new table: Add a new table with a unique name to the database instead of selecting one from the existing table list. If you want to apply a schema other than the default schema (Microsoft SQL Server and PostgreSQL), you can specify it using the syntax
[schema name].[table name].
Supported databases and database requirements
Tableau Prep supports writing flow data to tables in a select number of databases. Flows that run on a schedule in Tableau Cloud can only write to these databases if they are cloud-hosted.
If you connect to on-premises data sources, starting in version 2025.1, you can use a Tableau Bridge Client to connect to and refresh your data in Tableau Cloud. This requires a Tableau Bridge client configured in a Bridge Client pool, with the domain added to the Private Network Allowlist. In Tableau Prep Builder and on the web, when you connect to your data source, make sure that the server URL matches the domain in the bridge pool. For more information, see "Databases" in the Tableau Cloud section in Publish a flow from Tableau Prep Builder(Link opens in a new window).
Some databases have data restrictions or requirements. Tableau Prep may also impose some limits to maintain peak performance when writing data to the supported databases. The following table lists the databases where you can save your flow data and any database restrictions or requirements. Data that doesn't meet these requirements can result in errors when running the flow.
Note Setting character limits for your fields isn’t yet supported. However, you can create the tables in your database that include character limit constraints, then use the Replace data option to replace your data but maintain the table's structure in your database.
| Database | Requirements or restrictions |
|---|---|
| Amazon Redshift |
|
| Amazon S3 (Output only) | See Save flow output data to Amazon S3 |
| Databricks |
|
| Google BigQuery |
|
| Microsoft SQL Server |
|
| MySQL |
|
| Oracle |
|
| Pivotal Greenplum Database |
|
| PostgreSQL |
|
| SAP HANA |
|
| Snowflake |
|
| Teradata |
|
| Vertica |
|
Save flow data to a database
Note: You can embed your credentials for the database when publishing the flow. For more information about embedding credentials, see the Databases section in Publish a flow from Tableau Prep Builder
- Click the plus icon on a step and select Add Output.
- From the Save output to drop-down list, select Database and Cloud Storage.
- In the Settings tab, enter the following information:
- In the Connection drop down list , select the database connector where you want to write your flow output. Only supported connectors are shown. This can be the same connector that you used for your flow input or a different connector. If you select a different connector, you'll be prompted to sign in.
Important: Make sure you have write permission to the database you select. Otherwise the flow might only partially process the data.
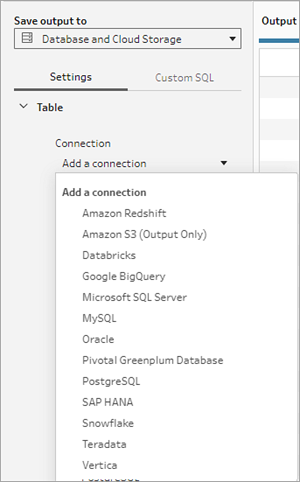
- In the Database drop-down list, select the database where you want to save your flow output data. Schemas or databases must have at least one table in them to be visible in the dropdown list.
- In the Table drop-down list, select the table where you want to save your flow output data. Depending on the Write Option you select, a new table will be created, the flow data will replace any existing data in the table or flow data will be added to the existing table.
To create a new table in the database, enter a unique table name in the field instead, then click on Create new table. When you run the flow for the first time, no matter which write option you select, the table is created in the database using the same schema as the flow.

- In the Connection drop down list , select the database connector where you want to write your flow output. Only supported connectors are shown. This can be the same connector that you used for your flow input or a different connector. If you select a different connector, you'll be prompted to sign in.
- The output pane shows you a snapshot of your data. A field comparison shows you the fields in your flow that match the fields in your table, if the table already exists. If the table is new, then a one-to-one field match is shown.

If there are any field mismatches, a status note shows you any errors.
- No match: Field is ignored: Fields exist in the flow but not in the database. The field won't be added to the database table unless you select the Create table write option and perform a full refresh. Then the flow fields are added to the database table and use the flow output schema.
- No match: Field will contain Null values: Fields exist in the database but not in the flow. The flow passes a Null value to the database table for the field. If the field does exist in the flow, but is mismatched because the field name is different, you can navigate to a cleaning step and edit the field name to match the database field name. For information about how to edit field name, see Apply cleaning operations.
- Error: Field data types do not match: The data type assigned to a field in both the flow and the database table you are writing your output to must match, otherwise the flow will fail. You can navigate to a cleaning step and edit the field data type to fix this. For more information about changing data types, see Review the data types assigned to your data.
- Select a write option. You can select a different option for full and incremental refresh and the option is applied when you select your flow run method. For more information about running our flow using incremental refresh, see Refresh Flow Data Using Incremental Refresh.
- Append to table: This option adds data to an existing table. If the table doesn't exist, the table is created when the flow is first run and data is added to that table with each subsequent flow run.
- Create table: This option creates a new table. If the table with the same name already exists, the existing table is deleted and replaced with the new table. Any existing data structure or properties defined for the table are also deleted and replaced with the flow data structure. Any fields that exist in the flow are added to the new database table.
- Replace data: This option deletes the data in your existing table and replaces it with the data in your flow, but preserves the structure and properties of the database table.
- (optional) Click on the Custom SQL tab and enter your SQL script. You can enter a script to run Before and After the data is written to the table.

- Click Run Flow to run the flow and write your data to your selected database.
Save flow output data to Datasets in CRM Analytics
Supported in Tableau Prep Builder and on the web starting in version 2022.3.
Note: CRM Analytics has several requirements and some limitations when integrating data from external sources. To make sure that you can successfully write your flow output to CRM Analytics, see Considerations before integrating data into datasets(Link opens in a new window) in the Salesforce help.
Clean your data using Tableau Prep and get better prediction results in CRM Analytics. Simply connect to data from any of the connectors that Tableau Prep Builder or Tableau Prep on the web supports. Then, apply transformations to clean your data and output your flow data directly to Datasets in CRM Analytics that you have access to.
Flows that output data to CRM Analytics can't be run using the command line interface. You can run flows manually using Tableau Prep Builder or using a schedule on the web with Tableau Prep Conductor.
Prerequisites
To output flow data to CRM Analytics, check that you have the following licences, access and permissions in Salesforce and Tableau.
Salesforce Requirements
| requirement | description |
|---|---|
| Salesforce Permissions | You must be assigned to either the CRM Analytics Plus or CRM Analytics Growth licence. The CRM Analytics Plus licence includes the permission sets:
The CRM Analytics Growth licence includes the permission sets:
For more information, see Learn About CRM Analytics Licences and Permissions Sets(Link opens in a new window) and Select and assign user permissions sets(Link opens in a new window) in the Salesforce help. |
Administrator settings | Salesforce administrators will need to configure:
|
Tableau Prep Requirements
| requirement | description |
|---|---|
Tableau Prep licence and permissions | Creator licence. As a creator you need to sign in to your Salesforce.org account and authenticate before you can select Apps and Datasets to output your flow data. |
OAuth Data Connections | As a Server Administrator, configure Tableau Server with an OAuth client ID and secret on the connector. This is required to run flows on Tableau Server. For more information, see Configure Tableau Server for Salesforce.com Oauth(Link opens in a new window) in the Tableau Server help. |
Save flow data to CRM Analytics
The following CRM Analytics input limits apply when saving from Tableau Prep Builder to CRM Analytics.
- Maximum file size for external data uploads: 40 GB
- Maximum file size for all external data uploads in a rolling 24-hour period: 50 GB
- Click the plus icon on a step and select Add Output.
- From the Save output to drop-down list, select CRM Analytics.

- In the Dataset section, connect to Salesforce.
Sign in to Salesforce and click Allow to give Tableau access to CRM Analytics Apps and datasets or select an existing Salesforce connection
- In the Name field, select an existing data set name. This will overwrite and replace the data set with your flow output. Otherwise, type a new name and click Create new dataset to create a new dataset in the selected CRM Analytics App.
Note: Dataset names can’t exceed 80 characters.

- Below the Name field, verify that the App shown is the App you have permissions to write to.
To change the App, click Browse Datasets. Then select the App from the list, enter the dataset name in the Name field and click Accept.

- In the Write Options section, Full refresh and Create table are the only supported options.
- Click Run Flow to run the flow and write your data to the CRM Analytics dataset.
If your flow run is successful, you can verify the output results in CRM Analytics in the Monitor tab of the data manager. For more information about this feature, see Monitor an External Data Load(Link opens in a new window) in the Salesforce help.
Save flow output data to Data Cloud
Supported in Tableau Prep Builder and on the web starting in version 2023.3.
Prepare your data with Tableau Prep and then associate the data with existing data sets in Data Cloud. Use any of the connectors that Tableau Prep Builder or Tableau Prep on the web supports to import your data, clean and prep your data, and then output your flow data directly to Data Cloud using Ingestion API.
Permission prerequisites
Salesforce licence | For information about Data Cloud editions and add-on licenses, see Data Cloud Standard Editions and Licences in the Salesforce help. Also see Data Cloud Limits and Guidelines. |
| Data Space permissions | You must be assigned to a Data Space and be assigned to one of the following permission sets in Data Cloud:
For more information, see Manage Data Spaces(Link opens in a new window) and Manage Data Spaces with Legacy Permission Sets(Link opens in a new window). |
Ingestion to Data Cloud permission | You must be assigned to the following for field access for ingestion to Data Cloud:
For more information, see Enable Object and Field Permissions. |
| Salesforce Profiles | Enable the profile access for:
|
| Tableau Prep licence and permissions | Creator licence. As a creator you must sign into your Salesforce org account and authenticate before you can select Apps and Datasets to output your flow data. |
Save flow data to Data Cloud
If you’re already using Ingestion API and manually calling the APIs to save data sets to Data Cloud, you can simplify that workflow using Tableau Prep. The prerequisite configurations are the same for Tableau Prep.
If this is the first time you’re saving data to Data Cloud, follow the setup requirements in Data Cloud setup prerequisites.
- Click the plus icon on a step and select Add Output.
- From the Save output to drop-down list, select Salesforce Data Cloud.
- From the Object section, select the Salesforce Data Cloud org to sign into.

- From the Salesforce Data Cloud menu, click Sign In.
- Sign into the Data Cloud org using your user name and password.
- In the Allow Access form, click Allow.
- In the “Save output to” section, enter the Ingestion API Connector and Object Name.
- To find the Ingestion API Connector name and corresponding Object Name, do the following:
Log in to Salesforce Data Cloud and navigate to Data Cloud Setup.
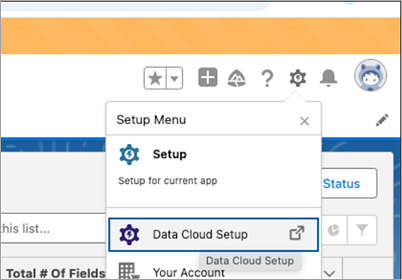
In the Quick Find box, type Ingestion API, then select Ingestion API from the results.
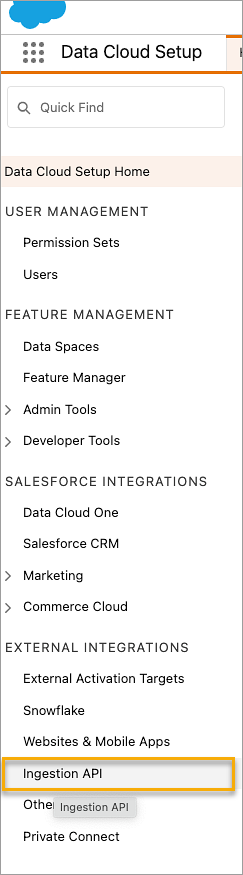
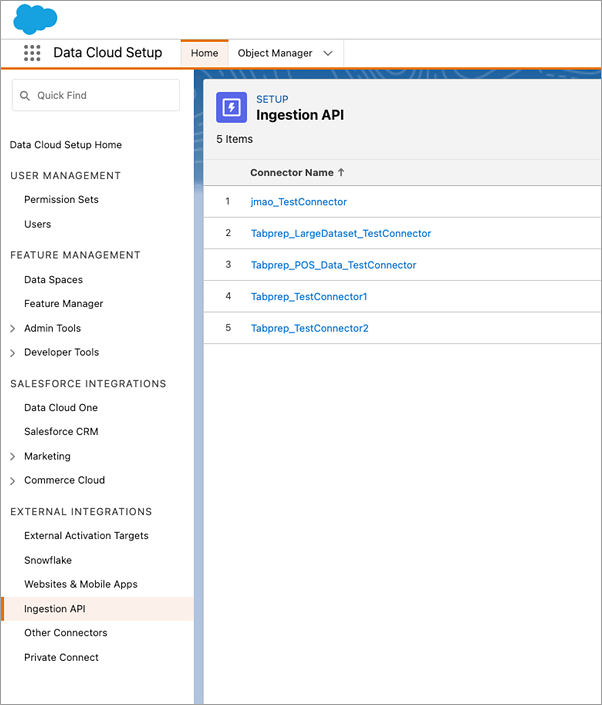
On the Ingestion API page, you'll see the available connectors listed under Connector Name.
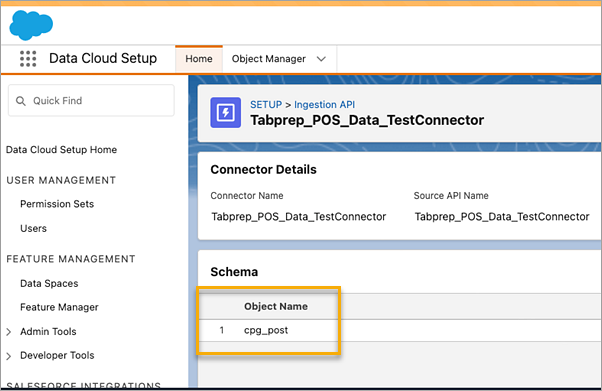
To find the corresponding Object Name for the connector you want to use, select a connector in the list. In the Connector Details page under the Schema section, you will see the corresponding objects listed under Object Name.
- The Write Options section indicates that existing rows will be updated if the specified value already exists in a table, or a new row will be inserted if the specified value doesn't already exist.
- Click Run Flow to run the flow and write your data to Data Cloud.
- Validate the data in Data Cloud by viewing the run status in the Data Stream and the objects in the Data Explorer.

A browser window will open to https://login.salesforce.com/.



Considerations
- You can run one flow at a time. The run must be completed in Data Cloud before another Save output can be run.
- Wait times for saving a flow to Data Cloud can take some time to complete. Check the status in Data Cloud.
- The data is saved to Data Cloud using the Upsert function. If a record in a file matches an existing record, the existing record is updated with the values in your data. If no match is found, the record is created as a new entity.
- For Prep Conductor, if you schedule the same flow to run automatically, the data won’t be updated. This is because only Upsert is supported.
- You can’t abort the job during the save to Data Cloud process.
- There’s no validation of fields that are saved to Data Cloud. Validate the data in Data Cloud.
Data Cloud setup prerequisites
These steps are a prerequisite for saving Tableau Prep flows to Data Cloud. For detailed information about Data Cloud concepts and mapping data between Tableau data sources and Data Cloud, see About Salesforce Data Cloud.
Set up an Ingestion API Connector
Create an Ingestion API data stream from your source objects by uploading a schema file in OpenAPI (OAS) format with a .yaml file extension. The schema file describes how data from your website is structured. For more information, see the YAML file example and Ingestion API.
- Click the Setup gear icon and then Data Cloud Setup.
- Click Ingestion API.
- Click New and provide a Connector name.
- On the details page for the new connector, upload a schema file in OpenAPI (OAS) format with a
.yamlfile extension. The schema file describes how data transferred via the API is structured. - Click Save on the Preview Schema form.
Note: Ingestion API schemas have set requirements. See Schema requirements before ingestion.
Create a data stream
Data streams are a data source that is brought into Data Cloud. It consists of the connections and associated data ingested into Data Cloud.
- Go to App Launcher and select Data Cloud.
- Click the Data Streams tab.
- Click New and select Ingestion API, then click Next.
- Select the ingestion API and objects.
- Select the Data Space, Category and Primary Key, then click Next.
- Click Deploy.
A true Primary Key must be used for Data Cloud. If one doesn’t exist, you need to create a Formula Field for the Primary Key.
For Category, choose between Profile, Engagement or Other. A datetime field must be present for objects that are intended for the engagement category. Objects of type profile or other don’t impose this same requirement. For more information, see Category and Primary Key.
You now have a data stream and a data lake object. Your data stream can now be added to a data space.

Add your data stream to a data space
When you bring in data from any source to the Data Cloud, you associate the Data Lake Objects (DLOs) to the relevant data space with or without filters.
- Click the Data Spaces tab.
- Choose the default Data Space or the name of the Data Space that you’re assigned to.
- Click Add Data.
- Select the Data Lake Object you created and click Next.
- (Optional) select filters for the object.
- Click Save.

Map the Data Lake Object to Salesforce objects
Data mapping relates Data Lake Object fields to Data Model Object (DMO) fields.
- Go to the Data Stream tab and select the Data Stream you created.

- From the Data Mapping section, click Start.
The field-mapping canvas shows your source DLOs on the left and target DMOs on the right. For more information, see Map Data Model Objects.
Create an External Client App or Connected App for Data Cloud Ingestion API
Before you can send data into Data Cloud using Ingestion API, you must configure Salesforce to use an external client app (recommended) or connected app (deprecated). For more details, see the following in the Salesforce Help:
For external client apps: Configure the External Client App OAuth Settings(Link opens in a new window) and Create an External Client App(Link opens in a new window)
For connected apps: Enable OAuth Settings for API Integration and Create a connected App for Data Cloud Ingestion API
As part of your External Client App or Connected App set up for Ingestion API, you must select the following OAuth scopes:
- Access and manage your Data Cloud Ingestion API data (cdp_ingest_api)
- Manage Data Cloud profile data (cdp_profile_api)
- Perform ANSI SQL queries on Data Cloud data (cdp_query_api)
- Manage user data via APIs (api)
- Perform requests on your behalf at any time (refresh_token, offline_access)
Schema requirements
To create an ingestion API source in Data Cloud, the schema file you upload must meet specific requirements. See Requirements for Ingestion API Schema.
- Uploaded schemas have to be in valid OpenAPI format with a .yml or .yaml extension. OpenAPI version 3.0.x is supported.
- Objects can’t have nested objects.
- Each schema must have at least one object. Each object must have at least one field.
- Objects can’t have more than 1000 fields.
- Objects can’t be longer than 80 characters.
- Object names must contain only a–z, A–Z, 0–9, _, –. No unicode characters.
- Field names must contain only a–z, A–Z, 0–9, _, –. No unicode characters.
- Field names can’t be any of these reserved words: date_id, location_id, dat_account_currency, dat_exchange_rate, pacing_period, pacing_end_date, row_count, version. Field names can’t contain the string __.
- Field names can’t exceed 80 characters.
- Fields meet the following type and format:
- For text or boolean type: string
- For number type: number
- For date type: string; format: date-time
- Object names can’t be duplicated; case-insensitive.
- Objects can’t have duplicate field names; case-insensitive.
- DateTime data type fields in your payloads must be in ISO 8601 UTC Zulu with format yyyy-MM-dd’T’HH:mm:ss.SSS’Z'.
When updating your schema, be aware that:
- Existing field data types can’t be changed.
- Upon updating an object, all the existing fields for that object must be present.
- Your updated schema file only includes changed objects, so you don’t have to provide a comprehensive list of objects each time.
- A datetime field must be present for objects that are intended for the engagement category. Objects of type
profileorotherdon’t impose this same requirement.
YAML file example
openapi: 3.0.3
components:
schemas:
owner:
type: object
required:
- id
- name
- region
- createddate
properties:
id:
type: integer
format: int64
name:
type: string
maxLength: 50
region:
type: string
maxLength: 50
createddate:
type: string
format: date-time
car:
type: object
required:
- car_id
- color
- createddate
properties:
car_id:
type: integer
format: int64
color:
type: string
maxLength: 50
createddate:
type: string
format: date-time Save flow output data to Amazon S3
Available in Tableau Prep Builder 2024.2 and later and Web Authoring and Tableau Cloud. This feature is not available in Tableau Server yet.
You can connect to data from any of the connectors that Tableau Prep Builder or the web supports and save your flow output as a .parquet or .csv file to Amazon S3. The output can be saved as new data or you can overwrite existing S3 data. To prevent data loss, you can use the Custom SQL option to make a copy of your table data and run it before saving the flow data to S3.
Saving your flow output and connecting to the S3 connector are independent of each other. You can’t reuse an existing S3 connection that you used as a Tableau Prep input connection.
The total volume of data and number of objects you can store in Amazon S3 are unlimited. Individual Amazon S3 objects can range in size from a minimum of 0 bytes to a maximum of 5 TB. The largest object that can be uploaded in a single PUT is 5 GB. For objects larger than 100 MB, customers should consider using the multipart upload capability. See Uploading and copying objects using multipart upload.
Permissions
To write to your Amazon S3 bucket, you need your bucket region, bucket name, access key ID and secret access key. To get these keys, you will need to create an Identity and Access Management (IAM) user within AWS. See Managing access keys for IAM users.
Save flow data to Amazon S3
- Click the plus icon on a step and select Add Output.
- From the Save output to drop-down list, select Database and Cloud Storage.
- From the Table > Connection section, select Amazon S3 (Output Only).
- In the Amazon S3 (Output Only) form, add the following information:
- Access Key ID: The Key ID that you used to sign the requests you send to Amazon S3.
- Secret Access Key: Security credentials (passwords, access keys) used to verify that you have permission to access the AWS resource.
- Bucket Region: The Amazon S3 bucket location (AWS Region endpoint). For example: us-east-2.
- Bucket name: The name of the S3 bucket where you want to write the flow output. The bucket names of any two AWS accounts in the same region can't be the same.
Note: To find your S3 region and bucket name, log in to your AWS S3 account and navigate to the AWS S3 console.
- Click Sign In.
- In the S3 URI field, enter the name of the
.csvor.parquetfile. By default, the field is populated withs3://<your_bucket_name>. The file name must include the extension.csvor.parquet.You can save the flow output as a new S3 object or overwrite an existing S3 object.
- For a new S3 object, type the name of the
.parquetor.csvfile. The URI is shown in the Preview text. For example:s3://<bucket_name><name_file.csv>. - To overwrite an existing S3 object, type the name of the
.parquetor.csvfile or click Browse to find existing S3.parquetor.csvfiles.Note: The Browse Object window will only show files that have been saved from previous sign-ins to Amazon S3.
- For a new S3 object, type the name of the
- For Write Options, a new S3 object is created with the data from your flow. If the data already exists, any existing data structure or properties defined for the object are deleted and replaced with new flow data. Any fields that exist in the flow are added to the new S3 object.
- Click Run Flow to run the flow and write your data to S3.
You can verify the data was saved to S3 by logging in to your AWS S3 account and navigating to the AWS S3 console.