配置数据集
注意:从版本 2020.4.1 开始,您现在可以在 Tableau Server 和 Tableau Cloud 中创建和编辑流程。除非另有说明,否则本主题中的内容适用于所有平台。有关在 Web 上制作流程的详细信息,请参见 Tableau Server(链接在新窗口中打开) 和 Tableau Cloud(链接在新窗口中打开) 帮助中的 Web 上的 Tableau Prep。
若要确定在流程中使用多少数据集,您可以配置数据集。当您连接到数据或将表拖到“流程”窗格中时,会自动向流程中添加一个输入步骤。
在“输入”步骤中,您可以决定要在流程中包含哪些数据以及包含多少数据。这始终是流程中的第一步。
您也可以从“输入”步骤中刷新数据。有关详细信息,请参见在“输入”步骤中添加更多数据(链接在新窗口中打开)。
在“输入”步骤中,您可以:
- 在流程窗格中右键单击或按住 Cmd 并单击 (MacOS) 输入步骤,以重命名或移除该步骤。
- 合并位于同一父目录或子目录中的多个文件。有关详细信息,请参见在输入步骤中合并文件和数据库表。
- (版本 2023.1 及更高版本)包括根据数据集的原始排序顺序自动生成的行号。请参见包括数据集中的行号。
- 搜索字段。
- 查看字段值的预览。
- 通过更改字段名称来配置字段属性,或为文本文件配置文本设置。
注意:包括方括号的字段值会自动转换为圆括号。
- 配置接收到您的流程中的数据样本。请参见选择数据样本大小。
- 移除不需要的字段。您始终可以返回到输入步骤并在以后包含它们。
- 隐藏不需要清理,但仍希望将其包括在流程输出中的字段。如果需要,您可以随时取消隐藏它们。
- 将筛选器应用于选定的字段。
- 更改支持它的数据连接的字段数据类型。
- (版本 2023.3 及更高版本)您可以设置 CSV 文件的标题和起始行。
- (版本 2024.1 及更高版本)您可以设置 Excel 文件的标题和起始行。
包括数据集中的行号
在 Tableau Prep Builder 版本 2023.1 及更高版本中以及在 Web 上支持 Microsoft Excel 和文本 (.csv) 文件。
注意:当前不支持为输入并集中包含的文件使用此选项。
从版本 2023.1 开始,Tableau Prep 会根据数据的原始排序顺序自动生成行号,您可以将其作为新字段包含在流程中。这仅适用于 Microsoft Excel 或文本 (.csv) 文件类型。
在以前的版本中,如果您想包含这些行号,则必须在将数据集添加到流程之前手动将它们添加到源中。
当连接到您的数据时,该字段在输入步骤中生成。默认情况下,它被排除在流程之外,但您可以单击一下将其包括在内。如果选择将其包括在内,它的行为与任何其他字段一样,可用于您的流程操作和计算字段。
Tableau Prep 还支持计算字段的 ROW_NUMBER 函数。当您的数据集中有可以定义排序的字段(例如 Row ID 或 Timestamp)时,此函数很有用。有关使用此函数的详细信息,请参见创建详细级别、排名和分片计算。
将源行号字段添加到您的流程
右键单击或按住 Cmd 单击 (MacOS) 字段,或单击“更多选项”
 菜单并选择 “包括字段”。
菜单并选择 “包括字段”。数据预览:

字段列表:

更改列表被清除,该字段现在是流程数据的一部分,您可以在后续流程步骤中看到生成的行号。
源行号详细信息
当您在数据集中包括“Source Row Number”时,以下选项和注意事项适用。
- 数据源行号在任何数据采样或筛选器之前应用。
- 这将创建一个名为“Source Row Number”的新字段,该字段在整个流程中持续存在。此字段名未本地化,但可以随时重命名。
- 如果已存在具有此名称的字段,则新字段名称递增 1。例如“Source Row Number-1”、“Source Row Number-2”,等等。
- 您可以在后续步骤中更改字段的数据类型。
- 您可以在流程操作和计算中使用此字段。
- 每次刷新输入数据或运行流程时,都会为整个数据集重新生成此值。
- 此字段不可用于输入并集。
设置标题和数据起始行
Tableau Prep Builder 版本 2023.3 及更高版本和 Web 上支持文本 (.csv) 文件,版本 2024.1 及更高版本支持 Excel (.xls) 文件。
对于 Excel 和文本 (.csv) 文件,您可以将特定行设置为字段标题行以及数据起始行。
连接到 Excel 或文本文件时,常见的情况是这些文件在前几行中使用元信息进行格式化,以使其易于阅读。默认情况下,Tableau Prep 将 CSV 文件的第一行解释为字段标题行。Excel 文件根据字段类型和空行进行解释。Tableau Prep 可以选择一行作为标题,也可以不包含标题行。
例如,在以下文件中,STORE DETAILS 被解释为标题行。
您可以排除元数据信息 (1),并通过将第 3 行设置为标题 (2),将第 4 行设置为数据起始行,以此来提供数据的正确架构结构。
CSV 文件:

Excel 文件:

例如,以下显示行标题和起始行的默认设置:

排除元数据后的数据如下:

注意:数据预览不反映数据样本设置的更改。
配置标题和起始行
使用数据预览输入视图,您可以直观地检查数据的架构结构,并设置标题和起始行以从输入源数据中排除元数据。
您可以将数据起始行设置为大于标题行值的任何值。默认情况下,Tableau Prep 将数据起始行设置为标题行后的下一个连续数字。标题行和数据起始行之间的任何行都将被忽略。
注意:数据预览和 Data interpreter 是互斥的。Data Interpreter 只会检测 Excel 电子表格中的子表,不支持为文本文件和电子表格指定起始行。
- 选择输入步骤。
- 从工具栏中,单击“数据预览”输入视图。
- 在要设置为标题的行上,单击“更多选项” 菜单并选择“设置为标题”。
- 在要设置为数据起始行的行上,单击“更多选项” 菜单并选择“设置为数据开始”。默认情况下,数据起始行设置为下一个连续行号。

“标题选项”菜单显示标题行和数据起始行的行号。或者,您可以直接在“标题选项”对话框中设置标题和起始行。

单个文件中的多个架构
如果单个文件包含多个数据源,您可以通过连接到同一数据源来创建附加输入步骤,然后为第二个数据源设置标题和数据起始行。例如,以下文件包含一个从第 3 行 (1) 开始的数据源,另一个单独的架构从第 28 行 (2) 开始。


对于此类数据源,请按照以下步骤操作。
- 选择第一个输入步骤。
- 从工具栏中,单击“数据预览”输入视图。
- 在要设置为标题的行上,单击“更多选项” 菜单并选择“设置为标题”。
- 在要设置为数据起始行的行上,单击“更多选项” 并选择“设置为数据开始”。默认情况下,数据起始行设置为下一个连续行号。
- 选择下一个输入步骤。
- 重复上述步骤,为其他数据源设置标题和起始行。
标题行和数据起始行之间的任何行都将被忽略。
合并多个表
在 Tableau Prep Builder 版本 2024.1 及更高版本中以及在 Web 上支持文本 (.csv) 文件。
您可以合并具有相同架构结构和元数据行的数据源中的多个表。
- 连接到文件并选择第一个输入步骤。
- 从工具栏中,单击“数据预览”输入视图。
- 在要设置为标题的行上,单击“更多选项” 并选择“设置为标题”。
- 在要设置为数据起始行的行上,单击“更多选项” 并选择“设置为数据开始”。
- 单击“表”选项卡并选择“合并多个表”。
- 单击“应用”合并文件,并保留输入并集中所有文件的标题和行选择。这一操作的假设是输入合并文件之间的文件结构和架构是相同的。

连接到自定义 SQL 查询
如果数据库支持使用自定义 SQL,您会看到“自定义 SQL”显示在“连接”窗格靠近底部的位置。双击“自定义 SQL”打开“自定义 SQL”选项卡,您可以在其中输入查询来预选择数据和使用特定于来源的操作。查询检索数据集之后,您可以选择要包括的字段、应用筛选器,或在将数据添加到流程之前更改数据类型。

有关使用自定义 SQL 的详细信息,请参见使用自定义 SQL 连接到数据。
在输入步骤中应用清理操作
只能在“输入”步骤中执行部分清理操作。您可以在“输入”字段列表中进行以下任何更改。系统会在“更改”窗格中跟踪您所做的更改,并会在“流程”窗格中“输入”步骤的左侧以及“输入”字段列表中添加注释。
- 隐藏字段:隐藏字段而不是移除它们以减少流程中的混乱。如果需要,您可以随时取消隐藏这些字段。当您运行流程时,隐藏字段仍将包含在输出中。
- 筛选:使用计算编辑器筛选值,或者从版本 2023.1 开始,您也可以使用“相对日期筛选器”对话框以快速指定任何日期或日期和时间字段的日期范围。
- 重命名字段:在“字段名”字段中,双击或按住 Ctrl 并单击 (MacOS)字段名,并输入一个新字段名。
- 更改数据类型:单击字段的数据类型,并从菜单中选择一个新数据类型。Microsoft Excel、文本和 PDF 文件、Box、Dropbox、Google Drive 和 OneDrive 数据源目前支持此选项。所有其他数据源都可以在清理步骤中更改。
选择要包括在流程中的字段
注意:从版本 2023.1 开始,您可以选择多个字段来隐藏、取消隐藏、移除或包含它们。在以前的版本中,您一次可以处理一个字段并选中或清除复选框以包含或移除字段。
“输入”窗格显示数据集中的字段列表。默认情况下,除自动生成的字段“Source Row Number”外,所有字段都包括在内。使用“数据预览”或“列表”视图来管理您的字段。
- 搜索:查找字段。
- 隐藏字段:隐藏要包含在流程输出中但不需要清理的字段。
- 在字段列表中,单击眼睛
 图标或从“更多选项” 菜单中选择“隐藏字段”。
图标或从“更多选项” 菜单中选择“隐藏字段”。 - 在数据预览中,从“更多选项” 菜单中选择“隐藏字段”。
字段在运行时由流程处理。如果需要,您也可以随时“取消隐藏”字段。有关详细信息,请参见隐藏字段(链接在新窗口中打开)。
- 在字段列表中,单击眼睛
- 包含字段:将已标记为已移除的字段添加到流程中。
- 在字段列表中,选择一行或多行并单击鼠标右键,按住 Cmd 单击 (MacOS),或单击“更多选项” 菜单并选择“包含字段”,添加回标记为已移除的字段。
- 在数据预览中,在要包含在流程中的字段上单击“更多选项” 菜单,然后选择“包含字段”。
- 在字段列表中,选择一行或多行并单击鼠标右键,按住 Cmd 单击 (MacOS),或单击“更多选项”
- 移除字段:
- 在字段列表中,选择一行或多行并单击鼠标右键,按住 Cmd 单击 (MacOS),单击“X”,或单击“更多选项” 菜单并选择 “移除字段”,移除您不想包含在流程中的字段。
- 在数据预览中,在要移除的字段上单击“更多选项” 菜单,然后选择“移除字段”。
- 在字段列表中,选择一行或多行并单击鼠标右键,按住 Cmd 单击 (MacOS),单击“X”,或单击“更多选项”
将筛选器应用于输入步骤中的字段
在输入步骤中应用筛选器以减少您从数据源摄取的数据量。通过消除运行流程时不想处理的数据,您可以获得交互式性能效率和更有用的数据样本。
在输入步骤中,您可以使用计算编辑器应用筛选器。从版本 2023.1 开始,您还可以使用“相对日期筛选器”对话框以指定要包含在日期和日期和时间字段类型中的确切日期值范围。有关详细信息,请参见筛选您的数据(链接在新窗口中打开)中的“相对日期筛选器”。
您可以在“清理”步骤或其他步骤类型中使用其他筛选器选项。有关详细信息,请参见筛选您的数据(链接在新窗口中打开)。
应用计算筛选器
- 在工具栏中,单击“筛选值”。使用以下方法之一筛选数据:
在字段列表中,从字段名称中单击“更多选项”
菜单,然后选择“筛选器”>“计算...”。在数据预览中,从字段名称中单击“更多选项”
菜单,然后选择“筛选器”>“计算...”。


在计算编辑器中输入筛选条件。

应用相对日期筛选器
- 选择数据类型为“日期”或“日期和时间”的字段,并使用以下方法之一应用相对日期筛选器。
- 在字段列表中,右键单击、按住 Cmd 单击 (MacOS),或从“字段名称”列中单击“更多选项”菜单,然后选择“筛选器”>“相对日期”。
- 在数据预览中,从字段中单击“更多选项” 菜单,然后选择“筛选器”>“相对日期”。

- 在字段列表中,右键单击、按住 Cmd 单击 (MacOS),或从“字段名称”列中单击“更多选项”
使用“相对日期筛选器”对话框,指定要包含在流程中的年、季度、月、周或天的确切范围。您也可以配置相对于特定日期锚点,并包括 null 值。
注意:默认情况下,筛选器相对于流在创作体验中运行或预览的日期运行。

更改字段名称
使用以下方法之一更改字段的名称。
将会在字段网格以及“输入”步骤左侧的流程窗格中添加注释。系统也会在“更改”窗格中跟踪您所做的更改。
- 在字段列表中,从“字段名称”列中选择一个字段,然后单击“重命名字段”。在字段中键入新名称。
- 在数据预览中,选择一个字段并单击“重命名字段”。在字段中键入新名称。


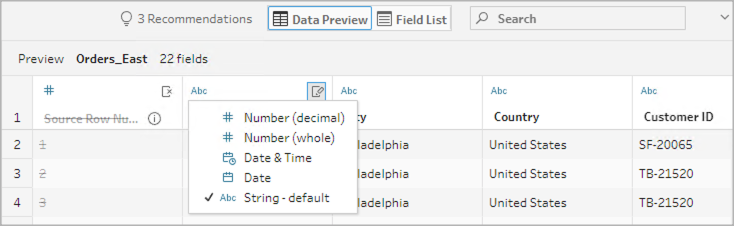
更改数据类型
Microsoft Excel、文本和 PDF 文件、Box、Dropbox、Google Drive 和 OneDrive 数据源目前支持。所有其他数据源都可以在清理步骤中更改。
注意:源行号(版本 2023.1 及更高版本)的数据类型只能在清理步骤或其他步骤类型中更改。
若要更改字段的数据类型,请执行以下操作:
- 单击字段的数据类型。
- 从菜单中选择新数据类型。
- 数据预览:
- 字段视图:

您还可以更改流程中其他步骤类型中的字段的数据类型,或分配数据角色来帮助验证字段值。有关更改数据类型或使用数据角色的详细信息,请参见查看分配给数据的数据类型(链接在新窗口中打开)和使用数据角色验证数据(链接在新窗口中打开)。
配置字段属性
处理文本文件时,您会看到“设置”选项卡,在该选项卡中,您可以编辑连接和配置文本属性,例如文本文件的字段分隔符。您也可以在“连接”窗格中编辑文件连接或配置增量刷新设置。有关为流程设置增量刷新的详细信息,请参见使用增量刷新来刷新流程数据。
处理文本或 Excel 文件时,您可以纠正在开始流程之前错误推断的数据类型。在开始流程之后,始终可以在后续步骤中通过“配置”窗格更改数据类型。
配置文本文件中的文本设置
若要更改用于解析文本文件的设置,请从以下选项中选择:
第一行包含标题(默认值):选择此选项以使用第一行作为字段标签。
自动生成字段名称:如果希望 Tableau Prep Builder 自动生成字段标题,请选择此选项。字段命名约定采用与 Tableau Desktop 相同的模式。例如,F1、F2 等。
字段分隔符:从列表中选择一个字符用于分隔各个列。选择“其他”以输入自定义字符。
文本限定符:选择用于在文件中将值引起来的字符。
字符集:选择用于描述文本文件编码的字符集。
区域设置:选择要用于解析文件的区域设置。此设置指明要使用哪个小数分隔符和千位分隔符。
选择数据样本大小
Tableau Prep Builder 版本 2023.3 及更高版本支持分层行选择。
默认情况下,Tableau Prep 确定为数据的代表性样本有效浏览和准备数据所需的最大行数。根据 Tableau Prep 示例算法,输入数据中的字段越多,允许的行数就越少。
对数据进行采样时,得到的样本可能包含您需要的所有行,也可能不包含,这取决于样本是如何计算和返回的。例如,默认情况下,Tableau Prep 使用快速选择方法对数据进行采样。
使用此方法,会加载最上面的行,如果您的数据集很大并且数据按时间顺序排列,您可能会看到最早的采样数据,但不是所有数据的完整表示。如果看不到预期数据,您可以更改数据样本设置以再次运行查询。
使用 Web 制作创建或编辑流程时,用户在使用大型数据集时可以选择的最大行数由 Tableau Server 管理员配置。在 Tableau Cloud 中,此限制是固定的,管理员无法更改。有关详细信息,请参见 Tableau Server(链接在新窗口中打开) 或 Tableau Cloud(链接在新窗口中打开) 帮助中的“示例数据和处理限制”。
为采样准备数据
如果您知道分析不需要某些值,请移除输入步骤中的字段,以便在制作或运行流程时不包含数据。
如果您有触发采样的大型数据集,则在输入步骤中移除字段会增加 Tableau Prep 加载的行数。未应用采样时,移除输入步骤中的字段会减少 Tableau Prep 加载的数据量。
从数据集中移除不必要的字段和值后,您可以更改为采样加载的数据量或采样方法。
更改数据样本设置
与在工作时分析所有数据并将更改应用到更大的数据集相比,样本数据有助于提供交互式体验,并使编辑流程更加高效。运行流程时将使用所有数据。您在样本部分中所做的任何更改都会应用于当前流程。
若要在清理和调整后验证数据,请运行流程并在 Tableau Desktop 中查看输出。
注意:运行完整流程而不是“Tableau Desktop 中的视图样本”,以便能够查看完整的数据。如果您看到样本中没有的意外或不正确的值,您可以返回 Tableau Prep 来解决此问题。
- 从数据集中删除不必要的字段和值。
- 选择一个输入步骤,然后单击“数据样本”选项卡。

选择要为数据采样加载的行数。您选择的行数会影响性能。
- 自动:(默认)快速加载数据并自动计算行数,以便为样本提供足够的数据。加载的行数等于或小于 393,216。
指定:通常用于加载少量行,以便您可以理解数据的结构并快速加载。指定小于 100 万行的行数。
注意:在 Web 制作中:用户在使用大型数据集时可以选择的最大行数由 Tableau Server 管理员配置。在 Tableau Cloud 中,此限制是固定的,管理员无法更改。作为用户,您可以选择最多达到该限制的行数。
- 最大值:为行选择加载尽可能多的数据,等于或小于 1,048,576。确保您满足大型数据集的高性能要求。
选择用于采样返回的行数的方法。选择“随机”或“分层”时,性能可能会受到影响。
注意:仅当您的输入数据源支持随机采样时才支持行选择。如果您的数据源不支持随机采样,则使用默认的“快速选择”方法。
快速选择:(默认)根据性能对数据进行采样,因为行会尽快返回。样本中可能不包括某些行。用于采样的行可能是前 N 行,或是上一次查询中数据库缓存在内存中的行数。虽然这几乎总是比随机抽样更快的结果,但它可能会返回有偏差的样本(例如,如果记录按时间顺序排序,则只返回一年的数据,而不是数据中存在的所有年份的数据)。
随机:允许您对大型数据集进行采样,并返回整个选定行的一般表示形式。Tableau Prep 根据加载的所有选定行返回随机行。在首次检索数据时,此选项可能会影响性能。
- 分层:允许您按指定字段进行分组,然后对每个子组内的数据进行采样。Prep 返回分布在所选字段中的请求行数,以便尽可能均匀地进行分组。在某些情况下,根据数据源,这可能会导致字段的某些值比其他值具有更多行。
示例
这些示例基于 Tableau Prep 附带的全球世界指标数据集。第一个样本使用“自动”作为行数,使用“随机”作为采样方法或要返回的采样行数。

选择这些值后,将随机选择 3000 行并用于表示整个数据集。

第二个样本使用“指定”作为行数,并使用“分层”作为样本方法。指定的行数设置为值 7,并且“Birth Rate”(出生率)字段用于分组。

新的样本值显示所有字段中 7 行唯一值的统一分布。
