Uw werk opslaan en delen
Vanaf 14 oktober 2025 is de naam van Data Cloud gewijzigd naar Data 360. In deze overgangsperiode kunt u verwijzingen naar Data Cloud tegenkomen in onze applicatie en documentatie. De naam is nieuw, maar de functionaliteit en inhoud blijven ongewijzigd.
U kunt op elk punt in uw flow uw werk handmatig opslaan of Tableau dit automatisch voor u laten doen wanneer u flows op het web maakt of bewerkt. Enkele dingen zijn anders wanneer u met flows werkt op het web.
Zie Tableau Prep op het web in de Help van Tableau Server(Link wordt in een nieuw venster geopend) en Tableau Cloud(Link wordt in een nieuw venster geopend) voor meer informatie over het maken van flows op het web.
| Tableau Prep Builder | Tableau Prep op het web |
|---|---|
|
|
Om de data actueel te houden, kunt u flows handmatig uitvoeren vanuit Tableau Prep Builder of vanaf de opdrachtregel. U kunt flows die naar Tableau Server of Tableau Cloud worden gepubliceerd ook handmatig of volgens een schema uitvoeren. Zie Een flow naar Tableau Server of Tableau Cloud publiceren voor meer informatie over het uitvoeren van flows.
Een flow opslaan
In Tableau Prep Builder kunt u uw flow handmatig opslaan om een back-up te maken van uw werk voordat u verdere bewerkingen uitvoert. Uw flow wordt opgeslagen in de Tableau Prep-bestandsindeling voor flows (.tfl).
U kunt ook uw lokale bestanden (Excel-bestanden, tekstbestanden en Tableau-extracten) in een pakket met uw flow opnemen om ze met anderen te delen, net zoals u een pakket maakt van een werkmap om te delen in Tableau Desktop. Alleen lokale bestanden kunnen in een pakket met een flow worden opgenomen. Data uit databaseverbindingen worden bijvoorbeeld niet opgenomen.
In het geval van webauthoring worden lokale bestanden automatisch in de flow verpakt. Directe bestandsverbindingen worden nog niet ondersteund.
Wanneer u een flowpakket opslaat, wordt dit opgeslagen als een verpakt Tableau-flowbestand (.tflx).
- Selecteer Bestand > Opslaan in het bovenste menu om uw flow handmatig op te slaan.
- Als u uw databestanden in Tableau Prep Builder in een pakket met uw flow wilt opnemen, voert u in het bovenste menu een van de volgende handelingen uit:
- Selecteer Bestand > Verpakte flow exporteren.
- Selecteer Bestand > Opslaan als. Selecteer vervolgens in het dialoogvenster Opslaan als de optie Verpakte Tableau-flowbestanden in het vervolgkeuzemenu Opslaan als type.
Uw flows automatisch opslaan op het web
Als u flows maakt of bewerkt op het web, wordt uw werk automatisch elke paar seconden als concept opgeslagen wanneer u een wijziging in de flow aanbrengt (verbinding maken met een databron, een stap toevoegen, enzovoort) om te voorkomen dat u werk kwijtraakt.
U kunt alleen flows opslaan op de server waarbij u momenteel bent aangemeld. U kunt geen conceptflow maken op een bepaalde server en deze vervolgens op een andere server opslaan of publiceren. Als u de flow naar een ander project op de server wilt publiceren, gebruikt u de menuoptie Bestand > Publiceren als en selecteert u vervolgens het project in het dialoogvenster.
Alleen u kunt conceptflows zien totdat u deze publiceert en beschikbaar stelt voor iedereen die toegang heeft tot het project op uw server. Flows in een conceptstatus worden getagd met een badge Concept, zodat u gemakkelijk kunt zien welke flows in uitvoering zijn. Als de flow nog nooit is gepubliceerd, wordt de badge Nooit gepubliceerd naast de badge Concept weergegeven.

Als een flow is gepubliceerd en u deze bewerkt en opnieuw publiceert, wordt er een nieuwe versie gemaakt. In het dialoogvenster Revisiegeschiedenis ziet u een lijst met flowversies. Klik op de pagina Verkennen op het menu ![]() Acties en selecteer Revisiegeschiedenis.
Acties en selecteer Revisiegeschiedenis.
Zie Werken met inhoudsrevisies(Link wordt in een nieuw venster geopend) in de Help van Tableau Desktop voor meer informatie over het beheren van de revisiegeschiedenis.
Opmerking: Automatisch opslaan is standaard ingeschakeld. Beheerders kunnen Automatisch opslaan voor een website uitschakelen, maar dat wordt niet aangeraden. Als u automatisch opslaan wilt uitschakelen, gebruikt u de Tableau Server REST API-methode 'Site bijwerken' en stelt u het kenmerk flowAutoSaveEnabled in op onwaar. Zie Tableau Server REST API-sitemethoden: site bijwerken(Link wordt in een nieuw venster geopend) voor meer informatie.
Automatisch bestandsherstel
Standaard wordt in Tableau Prep Builder automatisch een concept opgeslagen van alle open flows als de toepassing vastloopt of crasht. Conceptflows worden opgeslagen in de map Herstelde flows in uw Mijn Tableau Prep-opslagplaats. De volgende keer dat u de toepassing opent, wordt er een dialoogvenster weergegeven met een lijst met herstelde flows waaruit u kunt kiezen. U kunt een herstelde flow openen en doorgaan waar u was gebleven of u kunt het herstelde flowbestand verwijderen als u het niet meer nodig hebt.
Opmerking: Als er herstelde flows in uw map Herstelde flows staan, wordt dit dialoogvenster elke keer weergegeven wanneer u de toepassing opent, totdat de map leeg is.

Als u als beheerder niet wilt dat deze functie ingeschakeld is, kunt u deze tijdens of na de installatie uitschakelen. Lees Bestandherstel uitschakelen(Link wordt in een nieuw venster geopend) in de Implementatiegids voor Tableau Desktop en Tableau Prep voor meer informatie over hoe u deze functie uitschakelt.
Verwijderde flows herstellen
Ondersteund in Tableau Prep-webauthoring in Tableau Cloud en Tableau Server (versie 2025.3 en hoger).
Bij webauthoring kunt u eerder verwijderde flows uit de Prullenbak ophalen. Als de Prullenbak is ingeschakeld, worden flows niet permanent verwijderd, maar tijdelijk verplaatst naar de Prullenbak. Vanuit daar kunt u ze ophalen of permanent verwijderen. Flows die zich in een conceptstatus bevinden, worden nog steeds permanent verwijderd. Zie Prullenbak(Link wordt in een nieuw venster geopend) voor meer informatie.
Opmerking: Deze functie is niet beschikbaar Tableau Prep Builder.
Het volgende is vereist om deze functie te gebruiken:
Machtigingen: U moet de rol van Sitebeheerder, Serverbeheerder, Creator of Explorer (kan publiceren) toegewezen krijgen.
Locatie-instelling: De prullenbak is ingeschakeld voor uw site
Flowstatus: De flow moet gepubliceerd zijn.
Hoe lang berichten in de Prullenbak worden bewaard, wordt door uw beheerder ingesteld.
Een flow herstellen
Vouw het zijvenster op de startpagina uit en selecteer vervolgens Prullenbak.
Op de pagina Prullenbak selecteert u Flows in het keuzemenu Inhoudstype.
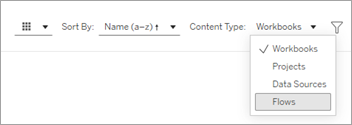
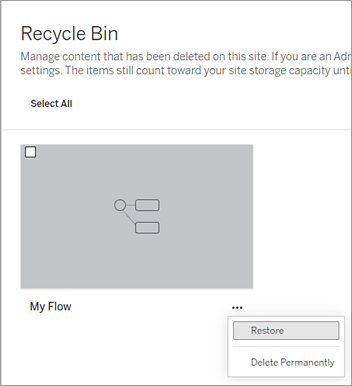
Selecteer het menu Meer acties voor de flow die u wilt herstellen en selecteer vervolgens Herstellen.
Selecteer een project als de herstellocatie.
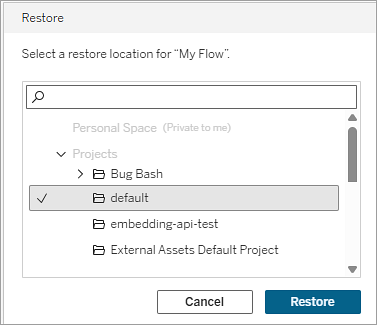
Selecteer Herstellen.
De flowuitvoer weergeven in Tableau Desktop
Opmerking: Deze optie is niet beschikbaar op het web.
Soms wilt u tijdens het opschonen van uw data de voortgang controleren door ernaar te kijken in Tableau Desktop. Wanneer uw flow wordt geopend in Tableau Desktop, maakt Tableau Prep Builder een permanent Tableau .hyper-bestand en een Tableau-databronbestand (.tds). Deze bestanden worden opgeslagen in het bestand Databronnen in uw Tableau-opslagplaats, zodat u op elk gewenst moment met uw data kunt experimenteren.
Wanneer u de flow opent in Tableau Desktop, kunt u de datasteekproef zien waarmee u in uw flow werkt, met de bewerkingen die erop zijn toegepast, tot aan de stap die u hebt geselecteerd.
Opmerking: U kunt weliswaar experimenteren met uw data, maar Tableau toont u slechts een steekproef van de data en u kunt de werkmap niet opslaan als een werkmappakket (.twbx). Wanneer u met uw data wilt gaan werken in Tableau, maakt u een uitvoerstap in uw flow en slaat u de uitvoer op in een bestand of als een gepubliceerde databron. Vervolgens maakt u verbinding met de volledige databron in Tableau.
Ga als volgt te werk om uw datasteekproef te bekijken in Tableau Desktop:
- Klik met de rechtermuisknop op de stap waarvan u de data wilt bekijken en selecteer Voorbeeld in Tableau Desktop vanuit het contextmenu.

- Tableau Desktop wordt geopend en u ziet het tabblad Blad.
Data-extractbestanden en gepubliceerde databronnen maken
Voer de flow uit om uw flowuitvoer te maken. Wanneer u de flow uitvoert, worden uw wijzigingen toegepast op de volledige dataset. Het uitvoeren van de flow resulteert in een Tableau-databron- (.tds) en een Tableau-data-extractbestand (.hyper).
Opmerking: Flows die ruimtelijke data bevatten, kunnen alleen worden uitgevoerd naar .hyper-bestanden of als een gepubliceerde databron. Andere uitvoertypen worden momenteel niet ondersteund. Zie Ruimtelijke berekeningen en joins maken(Link wordt in een nieuw venster geopend) voor meer informatie over het werken met ruimtelijke data.
Tableau Prep Builder
U kunt een extractbestand maken van uw flowuitvoer om te gebruiken in Tableau Desktop of om uw data te delen met derden. Maak een extractbestand in de volgende indelingen:
- Hyper-extract (.hyper): dit is het nieuwste Tableau-extractbestandstype.
- Door komma's gescheiden waarde (.csv): sla het extract op in een .csv-bestand om uw data met derden te delen. Het geëxporteerde CSV-bestand wordt gecodeerd volgens UTF-8 met BOM.
- Microsoft Excel (.xlsx): een Microsoft Excel-spreadsheet.
Tableau Prep Builder en Tableau op het web
Publiceer uw flowuitvoer als een gepubliceerde databron of uitvoer naar een database.
- Sla uw flowuitvoer op als een databron in Tableau Server of Tableau Cloud om uw data te delen en gecentraliseerde toegang te bieden tot de data die u hebt opgeschoond, vormgegeven en gecombineerd.
- Sla uw flowuitvoer op in een database, zodat u de tabeldata kunt maken, vervangen of toevoegen aan uw schone, voorbereide flowdata. Zie Flowuitvoerdata opslaan in externe databases voor meer informatie.
Gebruik incrementeel vernieuwen wanneer u uw flow uitvoert om tijd en middelen te besparen door alleen nieuwe data te vernieuwen in plaats van de volledige dataset. Zie Flowdata vernieuwen met incrementele vernieuwing voor informatie over het configureren en uitvoeren van uw flow met behulp van incrementeel vernieuwen.
Opmerking: De REST API voor Tableau Server moet zijn ingeschakeld om Tableau Prep Builder-uitvoer te publiceren naar Tableau Server. Zie Rest API-vereisten(Link wordt in een nieuw venster geopend) in de Help bij Tableau REST API voor meer informatie. Als u wilt publiceren naar een server die gebruikmaakt van SSL-versleutelingscertificaten (Secure Socket Layer), zijn er aanvullende configuratiestappen nodig op de computer waarop Tableau Prep Builder wordt uitgevoerd. Zie Voor de installatie(Link wordt in een nieuw venster geopend) in de gids Implementatie Tableau Desktop en Tableau Prep Builder voor meer informatie.
Parameters opnemen in uw flowuitvoer
Ondersteund in Tableau Prep Builder en Tableau op het web versie 2021.4 en later
Neem parameterwaarden op in de bestandsnamen, paden, tabelnamen of aangepaste SQL-scripts (versie 2022.1.1 en hoger) van uw flowuitvoer om uw flows eenvoudig uit te voeren voor verschillende datasets. Zie Parameters in flows maken en gebruiken voor meer informatie.
Een extract maken naar een bestand
Opmerking: Deze uitvoeroptie is niet beschikbaar bij het maken of bewerken van flows op het web.
- Klik op het pluspictogram
 voor een stap en selecteer Uitvoer toevoegen.
voor een stap en selecteer Uitvoer toevoegen.Als u de flow al eerder hebt uitgevoerd, klikt u op de knop Flow uitvoeren
 voor de uitvoerstap. Hiermee wordt de flow uitgevoerd en uw uitvoer bijgewerkt.
voor de uitvoerstap. Hiermee wordt de flow uitgevoerd en uw uitvoer bijgewerkt.Het deelvenster Uitvoer wordt geopend en u ziet een momentopname van uw data.

- Selecteer in het linkerdeelvenster de optie Bestand in de vervolgkeuzelijst Uitvoergegevens opslaan in. In eerdere versies selecteert u Opslaan in bestand.
- Klik op de knop Bladeren, typ in het dialoogvenster Extract opslaan als een naam voor het bestand en klik op Accepteren.
- Selecteer een van de volgende typen uitvoergegevens in het veld Type uitvoergegevens:
- Tableau-data-extract (.hyper)
- Door komma's gescheiden waarden (.csv)
(Tableau Prep Builder) Bekijk in het gedeelte Schrijfopties de standaard schrijfoptie voor het schrijven van de nieuwe data naar uw bestanden en breng indien nodig wijzigingen aan. Zie Schrijfopties configureren voor meer informatie.
- Tabel maken: met deze optie wordt een nieuwe tabel gemaakt of wordt de bestaande tabel vervangen door de nieuwe uitvoer.
- Toevoegen aan tabel: met deze optie worden de nieuwe data aan uw bestaande tabel toegevoegd. Als de tabel nog niet bestaat, wordt er een nieuwe tabel gemaakt en worden bij volgende uitvoeringen nieuwe rijen aan deze tabel toegevoegd.
Opmerking: Toevoegen aan tabel wordt niet ondersteund voor uitvoergegevens van het type .csv. Zie Opties voor flowvernieuwing voor meer informatie over ondersteunde vernieuwingscombinaties.
- Klik op Flow uitvoeren om de flow uit te voeren en het extractbestand te genereren.
Een extract maken naar een Microsoft Excel-werkblad
Ondersteund in Tableau Prep Builder-versie 2021.1.2 en hoger. Deze uitvoeroptie is niet beschikbaar bij het maken of bewerken van flows op het web, en ook niet bij het genereren van uitvoer voor workflows die ruimtelijke data bevatten.
Wanneer u flowdata naar een Microsoft Excel-werkblad uitvoert, kunt u een nieuw werkblad maken of de data in een bestaand werkblad toevoegen of vervangen. De volgende voorwaarden zijn van toepassing:
- Alleen Microsoft Excel .xlsx-bestandsindelingen worden ondersteund.
- De werkbladrijen beginnen bij cel A1.
- Bij het toevoegen of vervangen van data wordt ervan uitgegaan dat de eerste rij kopteksten zijn.
- Koptekstnamen worden toegevoegd bij het maken van een nieuw werkblad, maar niet bij het toevoegen van data aan een bestaand werkblad.
- Eventuele opmaak of formules in bestaande werkbladen worden niet toegepast op de flowuitvoer.
- Schrijven naar tabellen of bereiken met een naam wordt momenteel niet ondersteund.
- Incrementeel vernieuwen wordt momenteel niet ondersteund.
Flowdata uitvoeren naar een Microsoft Excel-werkbladbestand
- Klik op het pluspictogram voor een stap en selecteer Uitvoer toevoegen.
Als u de flow al eerder hebt uitgevoerd, klikt u op de knop Flow uitvoeren
voor de uitvoerstap. Hiermee wordt de flow uitgevoerd en uw uitvoer bijgewerkt.Het deelvenster Uitvoer wordt geopend en u ziet een momentopname van uw data.

- Selecteer in het linkerdeelvenster de optie Bestand in de vervolgkeuzelijst Uitvoergegevens opslaan in.
- Klik op de knop Bladeren, typ in het dialoogvenster Extract opslaan als een bestandsnaam of selecteer een bestandsnaam en klik op Accepteren.
- Selecteer Microsoft Excel (.xlsx) in het veld Type uitvoergegevens.

- Selecteer in het veld Werkblad het werkblad waarnaar u uw resultaten wilt schrijven of typ in plaats daarvan een nieuwe naam in het veld en klik vervolgens op Nieuwe tabel maken.
- Selecteer een van de volgende schrijfopties in het gedeelte Schrijfopties:
- Tabel maken: maakt het werkblad met uw flowdata of maakt het werkblad opnieuw (als het bestand al bestaat).
- Toevoegen aan tabel: voegt nieuwe rijen toe aan een bestaand werkblad. Als het werkblad niet bestaat, wordt er een werkblad gemaakt. Bij volgende flowuitvoeringen worden er rijen aan dat werkblad toegevoegd.
- Data vervangen: vervangt alle bestaande data, behalve de eerste rij in een bestaand werkblad, door de flowdata.
Met een veldvergelijking ziet u welke velden in uw flow overeenkomen met de velden in uw werkblad, als dat al bestaat. Als het een nieuw werkblad is, worden één-op-één overeenkomsten voor alle velden weergegeven. Velden die niet overeenkomen, worden genegeerd.

- Klik op Flow uitvoeren om de flow uit te voeren en het Microsoft Excel-extractbestand te genereren.
Een gepubliceerde databron maken
- Klik op het pluspictogram voor een stap en selecteer Uitvoer toevoegen.
Opmerking: Tableau Prep Builder vernieuwt eerder gepubliceerde databronnen en behoudt daarbij alle datamodellering (bijvoorbeeld berekende velden, nummeropmaak, enzovoort) die mogelijk in de databron is opgenomen. Als de databron niet kan worden vernieuwd, wordt deze vervangen, inclusief datamodellering.
- Het deelvenster Uitvoer wordt geopend en u ziet een momentopname van uw data.

- Selecteer in de vervolgkeuzelijst Uitvoergegevens opslaan in de optie Gepubliceerde databron (Publiceren als databron in eerdere versies). Vul de volgende velden in:
- Server (alleen Tableau Prep Builder): selecteer de server waarop u de databron en het data-extract wilt publiceren. Als u niet bent aangemeld bij een server, wordt u gevraagd zich aan te melden.
Opmerking: Met ingang van Tableau Prep Builder versie 2020.1.4 onthoudt Tableau Prep Builder nadat u zich hebt aangemeld bij uw server uw servernaam en inlogdata wanneer u de toepassing sluit. De volgende keer dat u de toepassing opent, bent u al aangemeld bij uw server.
Op de Mac wordt u mogelijk gevraagd om toegang te verlenen tot uw Mac-sleutelketen, zodat Tableau Prep Builder veilig SSL-certificaten kan gebruiken om verbinding te maken met uw Tableau Server- of Tableau Cloud-omgeving.
Als u uitvoert naar Tableau Cloud, dient u de pod waarop uw site wordt gehost op te nemen in de serverUrl. Bijvoorbeeld: https://eu-west-1a.online.tableau.com en niet https://online.tableau.com.
- Project: selecteer het project waaruit u de databron en het extract wilt laden.
- Naam: voer een bestandsnaam in.
- Beschrijving: voer een beschrijving van de databron in.
- Server (alleen Tableau Prep Builder): selecteer de server waarop u de databron en het data-extract wilt publiceren. Als u niet bent aangemeld bij een server, wordt u gevraagd zich aan te melden.
- (Tableau Prep Builder) Bekijk in het gedeelte Schrijfopties de standaard schrijfoptie voor het schrijven van de nieuwe data naar uw bestanden en breng indien nodig wijzigingen aan. Zie Schrijfopties configureren voor meer informatie
- Tabel maken: met deze optie wordt een nieuwe tabel gemaakt of wordt de bestaande tabel vervangen door de nieuwe uitvoer.
- Toevoegen aan tabel: met deze optie worden de nieuwe data aan uw bestaande tabel toegevoegd. Als de tabel nog niet bestaat, wordt er een nieuwe tabel gemaakt en worden bij volgende uitvoeringen nieuwe rijen aan deze tabel toegevoegd.
- Klik op Flow uitvoeren om de flow uit te voeren en de databron te publiceren.
Flowuitvoerdata opslaan in externe databases
Deze uitvoeroptie is niet beschikbaar bij het maken of bewerken van flows die ruimtelijke data bevatten.
Belangrijk: met deze functie kunt u data in een externe database permanent verwijderen en vervangen. Zorg dat u over de juiste rechten beschikt om naar de database te schrijven.
Om dataverlies te voorkomen, kunt u de optie Aangepaste SQL gebruiken om een kopie van uw tabeldata te maken en deze uit te voeren voordat u de flowdata naar de tabel schrijft.
U kunt verbinding maken met data vanaf elke connector die Tableau Prep Builder of op het web ondersteunt en data uitvoeren naar een externe database. Zo kunt u elke keer dat de flow wordt uitgevoerd data aan uw database toevoegen of deze bijwerken met schone, voorbereide data uit uw flow. Deze functie is beschikbaar voor zowel incrementeel als voor volledig vernieuwen, tenzij anders is vermeld. Zie Flowdata vernieuwen met incrementele vernieuwing voor meer informatie over het configureren van incrementeel vernieuwen.
Wanneer u uw flowuitvoer opslaat in een externe database, gaat Tableau Prep als volgt te werk:
- Genereert de rijen en voert eventuele SQL-opdrachten uit op de database.
- Schrijft de data naar een tijdelijke tabel (of het staginggebied bij uitvoer naar Snowflake) in de uitvoerdatabase.
- Als de bewerking succesvol is, worden de data verplaatst van de tijdelijke tabel (of het staginggebied voor Snowflake) naar de doeltabel.
- Voert alle SQL-opdrachten uit die u wilt uitvoeren nadat de data naar de database zijn geschreven.
Als het SQL-script mislukt, mislukt de flow ook. Uw data worden dan echter nog wel in uw databasetabellen geladen. U kunt proberen de flow opnieuw uit te voeren of het SQL-script handmatig op uw database uitvoeren om de flow toe te passen.
Uitvoeropties
U kunt de volgende opties selecteren wanneer u data naar een database schrijft. Als de tabel nog niet bestaat, wordt deze gemaakt wanneer de flow voor het eerst wordt uitgevoerd.
- Toevoegen aan tabel: met deze optie voegt u data toe aan een bestaande tabel. Als de tabel niet bestaat, wordt deze gemaakt wanneer de flow voor het eerst wordt uitgevoerd. Bij elke volgende flowuitvoering worden er data aan die tabel toegevoegd.
- Tabel maken: met deze optie wordt een nieuwe tabel gemaakt met de data uit uw flow. Als de tabel al bestaat, worden de tabel en eventuele bestaande datastructuur of -eigenschappen die voor de tabel zijn gedefinieerd, verwijderd en vervangen door een nieuwe tabel die de datastructuur van de flow gebruikt. Alle velden die in de flow voorkomen, worden toegevoegd aan de nieuwe databasetabel.
- Data vervangen: met deze optie worden de data in uw bestaande tabel verwijderd en vervangen door de data in uw flow, maar blijven de structuur en eigenschappen van de databasetabel behouden. Als de tabel niet bestaat, wordt de tabel gemaakt wanneer de flow voor het eerst wordt uitgevoerd en worden de tabeldata bij elke volgende flowuitvoering vervangen.
Extra opties
Naast de schrijfopties kunt u ook aangepaste SQL-scripts opnemen in of nieuwe tabellen toevoegen aan uw database.
- Aangepaste SQL-scripts: voer uw aangepaste SQL in en selecteer of u uw script wilt uitvoeren vóór, na of zowel vóór als na het schrijven van data naar de databasetabellen. Met deze scripts kunt u een kopie van uw databasetabel maken, een index toevoegen, andere tabeleigenschappen toevoegen, enzovoort voordat de flowdata naar de tabel worden geschreven.
Opmerking: Met ingang van versie 2022.1.1 kunt u ook parameters in uw SQL-scripts invoegen. Zie Gebruikersparameters toepassen op uitvoerstappen voor meer informatie.
- Een nieuwe tabel toevoegen: voeg een nieuwe tabel met een unieke naam toe aan de database in plaats van een tabel te selecteren in de lijst met bestaande tabellen. Als u een ander schema wilt toepassen dan het standaardschema (Microsoft SQL Server en PostgreSQL), kunt u dit opgeven met behulp van de syntaxis
[schema name].[table name].
Ondersteunde databases en databasevereisten
Tableau Prep ondersteunt het schrijven van flowdata naar tabellen in een beperkt aantal databases. Flows die volgens een schema in Tableau Cloud worden uitgevoerd, kunnen alleen naar deze databases schrijven als deze in de cloud worden gehost.
Als u verbinding maakt met databronnen op locatie, kunt u vanaf versie 2025.1 een Tableau Bridge-client gebruiken om verbinding te maken met uw data in Tableau Cloud en om deze te vernieuwen. Hiervoor is een Tableau Bridge-client vereist die is geconfigureerd in een Bridge-clientpool, waarbij het domein is toegevoegd aan de Toelatingslijst van privénetwerken. Wanneer u in Tableau Prep Builder en op internet verbinding maakt met uw databron, moet u ervoor zorgen dat de server-URL overeenkomt met het domein in de Bridge-pool. Zie 'Databases' in het gedeelte Tableau Cloud in Een flow publiceren vanuit Tableau Prep Builder(Link wordt in een nieuw venster geopend) voor meer informatie.
Voor sommige databases gelden beperkingen of vereisten voor de data. Tableau Prep kan ook limieten opleggen voor optimale prestaties bij het schrijven van data naar de ondersteunde databases. In de onderstaande tabel staan de databases waarin u uw flowdata kunt opslaan, evenals eventuele databasebeperkingen of -vereisten. Data die niet aan deze vereisten voldoen, kunnen fouten veroorzaken bij het uitvoeren van de flow.
Opmerking: Het instellen van tekenlimieten voor uw velden wordt nog niet ondersteund. U kunt echter de tabellen met beperkingen voor het aantal tekens maken in uw database en vervolgens de optie Data vervangen kiezen om uw data te vervangen maar de tabelstructuur in uw database te behouden.
| Database | Vereisten of beperkingen |
|---|---|
| Amazon Redshift |
|
| Amazon S3 (alleen uitvoer) | Zie Flowuitvoerdata opslaan in Amazon S3 |
| Databricks |
|
| Google BigQuery |
|
| Microsoft SQL Server |
|
| MySQL |
|
| Oracle |
|
| Pivotal Greenplum Database |
|
| PostgreSQL |
|
| SAP HANA |
|
| Snowflake |
|
| Teradata |
|
| Vertica |
|
Flowdata opslaan in een database
Opmerking: U kunt uw referenties voor de database insluiten wanneer u de flow publiceert. Zie de sectie Databases in Een flow van Tableau Prep Builder publiceren voor meer informatie over het insluiten van referenties
- Klik op het pluspictogram voor een stap en selecteer Uitvoer toevoegen.
- Selecteer Database en cloudopslag in de vervolgkeuzelijst Uitvoergegevens opslaan in.
- Voer op het tabblad Instellingen de volgende informatie in:
- Selecteer in de vervolgkeuzelijst Verbinding de databaseconnector waarnaar u uw flowuitvoer wilt schrijven. Alleen ondersteunde connectors worden weergegeven. Dit kan dezelfde connector zijn die u voor uw flowinvoer hebt gebruikt, maar het kan ook een andere connector zijn. Als u een andere connector selecteert, wordt u gevraagd u aan te melden.
Belangrijk: zorg ervoor dat u schrijfrechten hebt voor de database die u selecteert. Anders kan het zijn dat de flow de data slechts gedeeltelijk verwerkt.
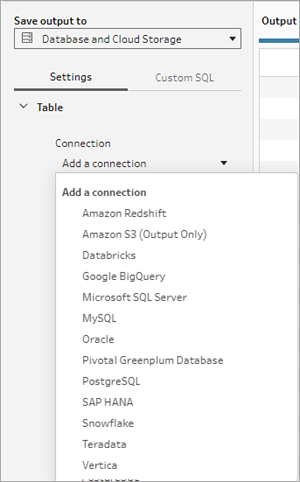
- Selecteer in de vervolgkeuzelijst Database de database waarin u de uitvoerdata van uw flow wilt opslaan. Schema's of databases moeten minimaal één tabel bevatten om zichtbaar te zijn in de vervolgkeuzelijst.
- Selecteer in de vervolgkeuzelijst Tabel de tabel waarin u de uitvoerdata van uw flow wilt opslaan. Afhankelijk van de schrijfoptie die u selecteert, wordt er een nieuwe tabel gemaakt, worden de bestaande data in de tabel vervangen door de flowdata of worden de flowdata aan de bestaande tabel toegevoegd.
Als u een nieuwe tabel in de database wilt maken, typt u een unieke tabelnaam in het veld en klikt u op Nieuwe tabel maken. Wanneer u de flow voor de eerste keer uitvoert, wordt de tabel in de database volgens hetzelfde schema als de flow gemaakt, ongeacht de schrijfoptie die u selecteert.

- Selecteer in de vervolgkeuzelijst Verbinding de databaseconnector waarnaar u uw flowuitvoer wilt schrijven. Alleen ondersteunde connectors worden weergegeven. Dit kan dezelfde connector zijn die u voor uw flowinvoer hebt gebruikt, maar het kan ook een andere connector zijn. Als u een andere connector selecteert, wordt u gevraagd u aan te melden.
- In het uitvoervenster ziet u een momentopname van uw data. Met een veldvergelijking ziet u welke velden in uw flow overeenkomen met de velden in uw tabel, als de tabel al bestaat. Als het een nieuwe tabel is, worden één-op-één overeenkomsten voor alle velden weergegeven.

Als er velden zonder overeenkomst zijn, wordt dit in een statusnotitie weergegeven.
- Geen overeenkomst: veld wordt genegeerd: velden komen voor in de flow, maar niet in de database. Het veld wordt niet toegevoegd aan de databasetabel, tenzij u de schrijfoptie Tabel maken selecteert en een volledige vernieuwing uitvoert. Vervolgens worden de flowvelden toegevoegd aan de databasetabel en wordt het flowuitvoerschema gebruikt.
- Geen overeenkomst: veld bevat null-waarden: velden komen voor in de database, maar niet in de flow. De flow geeft een null-waarde door aan de databasetabel voor het veld. Als het veld wel in de flow voorkomt, maar er geen overeenkomst gevonden wordt omdat de veldnaam niet hetzelfde is, kunt u naar een opschoonstap gaan en de veldnaam bewerken zodat deze overeenkomt met de veldnaam in de database. Zie Opschoonbewerkingen toepassen voor informatie over het bewerken van de veldnaam.
- Fout: velddatatypen komen niet overeen: het datatype dat is toegewezen aan een veld moet hetzelfde zijn in de flow en in de databasetabel waarnaar u uw uitvoer schrijft, anders mislukt de flow. U kunt naar een opschoonstap navigeren en het velddatatype bewerken om dit op te lossen. Zie De datatypen bekijken die aan uw data zijn toegewezen voor meer informatie over het wijzigen van datatypen.
- Selecteer een schrijfoptie. U kunt een andere optie selecteren voor volledig en incrementeel vernieuwen. Dan wordt die optie toegepast wanneer u de uitvoeringsmethode voor uw flow selecteert. Zie Flowdata vernieuwen met incrementele vernieuwing voor meer informatie over het uitvoeren van een flow met incrementeel vernieuwen.
- Toevoegen aan tabel: met deze optie voegt u data toe aan een bestaande tabel. Als de tabel niet bestaat, wordt deze gemaakt wanneer de flow voor het eerst wordt uitgevoerd. Bij elke volgende flowuitvoering worden er data aan die tabel toegevoegd.
- Tabel maken: met deze optie wordt een nieuwe tabel gemaakt. Als de tabel met dezelfde naam al bestaat, wordt de bestaande tabel verwijderd en vervangen door de nieuwe tabel. Eventuele bestaande datastructuur of -eigenschappen die voor de tabel zijn gedefinieerd, worden ook verwijderd en vervangen door de datastructuur van de flow. Alle velden die in de flow voorkomen, worden toegevoegd aan de nieuwe databasetabel.
- Data vervangen: met deze optie worden de data in uw bestaande tabel verwijderd en vervangen door de data in uw flow, maar blijven de structuur en eigenschappen van de databasetabel behouden.
- (optioneel) Klik op het tabblad Aangepaste SQL en voer uw SQL-script in. U kunt een script opgeven om te worden uitgevoerd voor- en nadat de data naar de tabel zijn geschreven.

- Klik op Flow uitvoeren om de flow uit te voeren en uw data naar de geselecteerde database te schrijven.
Flowuitvoerdata opslaan in datasets in CRM Analytics
Ondersteund in Tableau Prep Builder en Tableau op het web vanaf versie 2022.3
Opmerking: CRM Analytics legt diverse vereisten en beperkingen op bij het integreren van data uit externe bronnen. Zie Overwegingen bij het integreren van gegevens in gegevenssets(Link wordt in een nieuw venster geopend) in de Help van Salesforce om er zeker van te zijn dat u uw flowuitvoer probleemloos naar CRM Analytics kunt schrijven.
Schoon uw data op met Tableau Prep voor betere voorspellingen in CRM Analytics. Maak eenvoudig verbinding met data van een van de connectors die Tableau Prep Builder of Tableau Prep op het web ondersteunt. Pas vervolgens transformaties toe om uw data op te schonen en voer uw flowdata rechtstreeks uit naar datasets in CRM Analytics waartoe u toegang hebt.
Flows die data naar CRM Analytics uitvoeren, kunnen niet worden uitgevoerd via de opdrachtregelinterface. U kunt flows handmatig uitvoeren met Tableau Prep Builder of met een schema op het web met Tableau Prep Conductor.
Vereisten
Controleer of u over de volgende licenties, toegang en machtigingen in Salesforce en Tableau beschikt om flowdata te kunnen uitvoeren naar CRM Analytics.
Salesforce-vereisten
| vereiste | beschrijving |
|---|---|
| Salesforce-machtigingen | U moet zijn toegewezen aan de CRM Analytics Plus- of de CRM Analytics Growth-licentie. De CRM Analytics Plus-licentie omvat de volgende machtigingensets:
De CRM Analytics Growth-licentie omvat de volgende machtigingensets:
Zie Meer informatie over CRM Analytics-platformlicenties en -machtigingensets(Link wordt in een nieuw venster geopend) en Gebruikersmachtigingensets selecteren en toewijzen(Link wordt in een nieuw venster geopend) in de Help van Salesforce voor meer informatie. |
Beheerdersinstellingen | Salesforce-beheerders moeten het volgende configureren:
|
Tableau Prep-vereisten
| vereiste | beschrijving |
|---|---|
Tableau Prep-licentie en -machtigingen | Creator-licentie. Als Creator moet u zich aanmelden bij uw Salesforce-organisatieaccount en u verifiëren voordat u apps en datasets kunt selecteren voor de uitvoer van uw flowdata. |
OAuth-dataverbindingen | Configureer in uw rol als serverbeheerder Tableau Server met een OAuth-client-ID en -geheim op de connector. Dit is vereist om flows uit te voeren op Tableau Server. Zie Tableau Server configureren voor Salesforce.com Oauth(Link wordt in een nieuw venster geopend) in de Help bij Tableau Server voor meer informatie. |
Flowdata opslaan in CRM Analytics
De volgende CRM Analytics-invoerlimieten zijn van toepassing bij het opslaan van Tableau Prep Builder in CRM-analyses.
- Maximale bestandsgrootte voor het uploaden van externe data: 40 GB
- Maximale bestandsgrootte voor alle uploads van externe data gedurende een periode van 24 uur: 50 GB
- Klik op het pluspictogram voor een stap en selecteer Uitvoer toevoegen.
- SelecteerCRM Analytics in de vervolgkeuzelijst Uitvoergegevens opslaan in.

- Maak verbinding met Salesforce in de sectie Dataset.
Meld u aan bij Salesforce en klik op Toestaan om Tableau toegang te geven tot CRM Analytics-apps en -datasets of selecteer een bestaande Salesforce-verbinding
- Selecteer een bestaande datasetnaam in het veld Naam. Hiermee wordt de dataset overschreven en vervangen door uw flowuitvoer. Anders typt u een nieuwe naam en klikt u op Nieuwe dataset maken om een nieuwe dataset te maken in de geselecteerde CRM Analytics-app.
Opmerking: Datasetnamen mogen niet meer dan 80 tekens bevatten.

- Controleer onder het veld Naam of de weergegeven app de app is waarvoor u schrijfmachtigingen hebt.
Als u de app wilt wijzigen, klikt u op Bladeren in datasets, selecteert u de app in de lijst, typt u de naam van de dataset in het veld Naam en klikt u op Accepteren.

- In de sectie Schrijfopties zijn Volledig vernieuwen en Tabel maken de enige ondersteunde opties.
- Klik op Flow uitvoeren om de flow uit te voeren en uw data naar de CRM Analytics-dataset te schrijven.
Als de flow zonder problemen wordt uitgevoerd, kunt u de uitvoerresultaten controleren in CRM Analytics op het tabblad Bewaken van gegevensbeheer. Zie De upload van externe gegevens bewaken(Link wordt in een nieuw venster geopend) in de Help bij Salesforce voor meer informatie over deze functie.
Flowuitvoerdata opslaan in Data Cloud
Ondersteund in Tableau Prep Builder en Tableau op het web vanaf versie 2023.3
Bereid uw data voor met Tableau Prep en koppel ze vervolgens aan bestaande datasets in Data Cloud. Gebruik een van de connectors die Tableau Prep Builder of Tableau Prep op het web ondersteunt om uw data te importeren, op te schonen en voor te bereiden. Voer uw flowdata vervolgens rechtstreeks uit naar Data Cloud met behulp van de Opname-API.
Vereiste machtigingen
Salesforce-licentie | Zie Standaard editions en licenties van Data Cloud in de Help bij Salesforce voor informatie over Data Cloud-edities en add-onlicenties. |
| Dataruimtemachtigingen | U moet zijn toegewezen aan een dataruimte en aan een van de volgende machtigingensets in Data Cloud:
Zie Dataruimten beheren(Link wordt in een nieuw venster geopend) en Dataruimten met verouderde machtigingensets beheren(Link wordt in een nieuw venster geopend) voor meer informatie. |
De machtiging voor opname in Data Cloud | Voor veldtoegang voor opname in Data Cloud moet u zijn toegewezen aan:
Zie Object- en veldmachtigingen inschakelen voor meer informatie. |
| Salesforce-profielen | Schakel profieltoegang in voor:
|
| Tableau Prep-licentie en -machtigingen | Creator-licentie. Als Creator moet u zich aanmelden bij uw Salesforce-organisatieaccount en u verifiëren voordat u apps en datasets kunt selecteren voor de uitvoer van uw flowdata. |
Flowdata opslaan in Data Cloud
Als u de Opname-API al gebruikt en de API's handmatig aanroept om datasets op te slaan in Data Cloud, kunt u die workflow vereenvoudigen met Tableau Prep. De vereiste configuratie is hetzelfde voor Tableau Prep.
Als dit de eerste keer is dat u data opslaat in Data Cloud, volgt u de installatievereisten in Configuratievereisten voor Data Cloud.
- Klik op het pluspictogram voor een stap en selecteer Uitvoer toevoegen.
- Selecteer Salesforce Data Cloud in de vervolgkeuzelijst Uitvoergegevens opslaan in.
- Selecteer in het gedeelte Object de Salesforce Data Cloud-organisatie waarbij u zich wilt aanmelden.

- Klik op Aanmelden in het Salesforce Data Cloud-menu.
- Meld u met uw gebruikersnaam en wachtwoord aan bij de Data Cloud-organisatie.
- Klik op Toestaan in het formulier Toegang verlenen.
- Typ in het gedeelte Uitvoergegevens opslaan in de naam van de Opname-API-connector en het Object.
- Om de naam van de Opname-API-connector en de bijbehorende Objectnaam te vinden, gaat u als volgt te werk:
Meld u aan bij Salesforce Data Cloud en navigeer naar Data Cloud-configuratie.
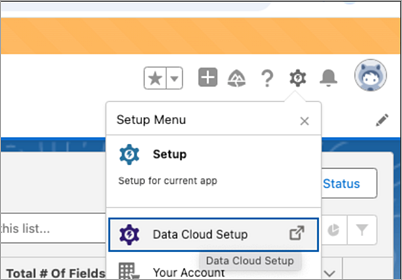
Typ Opname-API in het vak Snel zoeken en selecteer Opname-API in de resultaten.
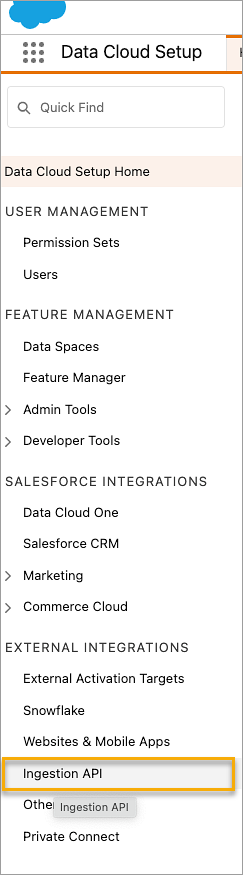
Op de pagina Opname-API ziet u de beschikbare connectors vermeld onder Connectornaam.
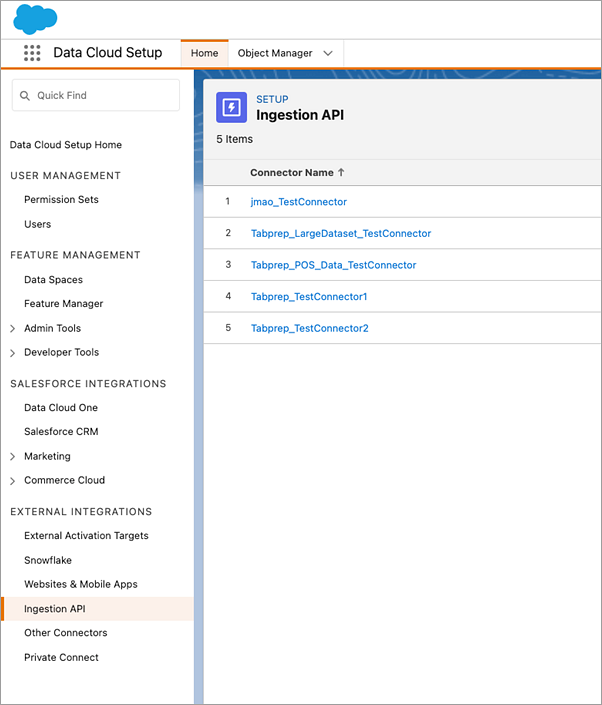
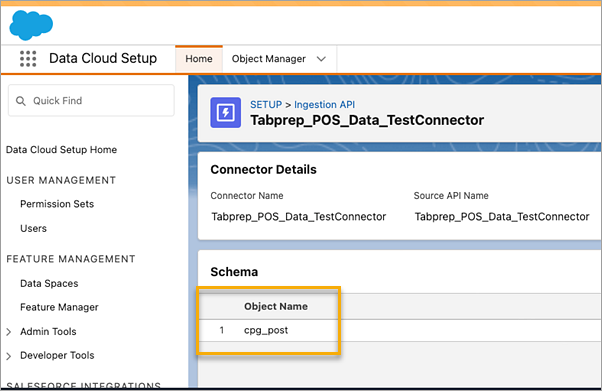
Om de overeenkomstige Objectnaam te vinden voor de connector die u wilt gebruiken, selecteert u een connector in de lijst. Op de pagina Connectorgegevens onder de sectie Schema, ziet u de overeenkomstige objecten vermeld onder Objectnaam.
- In het gedeelte Schrijfopties wordt aangegeven dat bestaande rijen worden bijgewerkt als de opgegeven waarde al voorkomt in een tabel en dat er een nieuwe rij wordt ingevoegd als de opgegeven waarde nog niet voorkomt.
- Klik op Flow uitvoeren om de flow uit te voeren en uw data naar de Data Cloud te schrijven.
- Valideer de data in Data Cloud door de uitvoeringsstatus te bekijken in de datastream en de objecten in Data Explorer.

Het browservenster https://login.salesforce.com/ wordt geopend.



Overwegingen
- U kunt één flow tegelijk uitvoeren. De uitvoering moet in Data Cloud zijn voltooid voordat een andere Opslaan-uitvoer kan worden uitgevoerd.
- Het kan enige tijd duren voordat een flow is opgeslagen in Data Cloud. Controleer de status in Data Cloud.
- De data worden met behulp van de Upsert-functie opgeslagen in Data Cloud. Als een record in een bestand overeenkomt met een bestaande record, wordt de bestaande record bijgewerkt met de waarden in uw data. Als er geen overeenkomst wordt gevonden, wordt de record als een nieuwe entiteit aangemaakt.
- Als u dezelfde flow automatisch laat uitvoeren in Prep Conductor, worden de data niet bijgewerkt. Dit komt omdat alleen Upsert wordt ondersteund.
- U kunt de taak niet afbreken tijdens het opslaan in Data Cloud.
- Er wordt geen validatie uitgevoerd van velden die in Data Cloud worden opgeslagen. Valideer de data in Data Cloud.
Configuratievereisten voor Data Cloud
Deze stappen zijn vereist voor het opslaan van Tableau Prep-flows in Data Cloud. Zie Over Salesforce Data Cloud voor gedetailleerde informatie over Data Cloud-concepten en het toewijzen van data tussen Tableau-databronnen en Data Cloud.
Een Opname-API-connector instellen
Maak een Opname-API-datastream van uw bronobjecten door een schemabestand te uploaden in de OpenAPI (OAS)-indeling met een .yaml-bestandsextensie. Het schemabestand beschrijft hoe de data van uw website zijn gestructureerd. Zie het Voorbeeld YAML-bestand en Opname-API voor meer informatie.
- Klik eerst op het tandwielpictogram Instellen en vervolgens op Data Cloud-configuratie.
- Klik op Opname-API.
- Klik op Nieuw en geef een connectornaam op.
- Upload op de detailpagina voor de nieuwe connector een schemabestand in de OpenAPI (OAS)-indeling met de bestandsextensie
.yaml. Het schemabestand beschrijft hoe de data die via de API worden overgedragen, zijn gestructureerd. - Klik op Opslaan op het formulier Voorbeeldschema.
Opmerking: Voor Opname-API-schema's gelden vastgestelde vereisten. Zie Schemavereisten vóór inname.
Een datastream maken
Datastreams zijn een databron die worden overgebracht naar Data Cloud. Ze bestaan uit de verbindingen en bijbehorende data die in Data Cloud worden opgenomen.
- Ga naar App Launcher en selecteer Data Cloud.
- Klik op het tabblad Datastreams.
- Klik op Nieuw, selecteer Opname-API en klik op Volgende.
- Selecteer de Opname-API en objecten.
- Selecteer de dataruimte, categorie en primaire sleutel en klik op Volgende.
- Klik op Implementeren.
Voor Data Cloud moet een echte primaire sleutel worden gebruikt. Als er nog geen sleutel bestaat, dient u een formuleveld te maken voor de primaire sleutel.
Kies bij Categorie tussen Profiel, Betrokkenheid of Overige. Er moet een veld DatumTijd aanwezig zijn voor objecten die bedoeld zijn voor de categorie Betrokkenheid. Voor objecten van het type profiel of van een ander type geldt deze eis niet. Zie Categorie en Primaire sleutel voor meer informatie.
U hebt nu een datastream en een gegevens-lakeobject. Uw datastream kan nu aan een dataruimte worden toegevoegd.

Uw datastream toevoegen aan een dataruimte
Wanneer u data uit welke bron dan ook overbrengt naar Data Cloud, koppelt u de gegevens-lakeobjecten (Data Lake Objects, ofwel DLO's) aan de relevante dataruimte, met of zonder filters.
- Klik op het tabblad Dataruimten.
- Kies de standaard dataruimte of de naam van de dataruimte waaraan u bent toegewezen.
- Klik op Data toevoegen.
- Selecteer het gegevens-lakeobject dat u hebt gemaakt en klik op Volgende.
- (Optioneel) Selecteer filters voor het object.
- Klik op Opslaan.

Het gegevens-lakeobject toewijzen aan Salesforce-objecten
Met datamapping worden DLO-velden gekoppeld aan DMO-velden (Data Model Object, gegevensmodelobject).
- Ga naar het tabblad Datastream en selecteer de datastream die u hebt gemaakt.

- Klik in het gedeelte Datamapping op Begin.
In het canvas voor veldtoewijzing worden de bron-DLO's links en de doel-DMO's rechts weergegeven. Zie Gegevensmodelobjecten toewijzen voor meer informatie.
Een externe client-app of verbonden app maken voor de Opname-API in Data Cloud
Voordat u data naar Data Cloud kunt verzenden via de Opname-API, moet u Salesfoce configureren om een externe client-app (aanbevolen) of een verbonden app (verouderd) te gebruiken. Zie de volgende onderwerpen in de Help van Salesforce voor meer details:
Voor externe client-apps: OAuth-instellingen voor de externe client-app configureren(Link wordt in een nieuw venster geopend) en Een externe client-app maken(Link wordt in een nieuw venster geopend)
Voor verbonden apps: OAuth-instellingen inschakelen voor API-integratie en Een verbonden app maken voor de Opname-API in Data Cloud
Als onderdeel van de configuratie van uw externe client-app of verbonden app voor de Opname-API dient u het volgende Oauth-bereik te selecteren:
- Toegang tot en beheer van uw Opname-API-data voor Data Cloud (cdp_ingest_api)
- Data Cloud-profieldata beheren (cdp_profile_api)
- ANSI SQL-query's uitvoeren op Data Cloud-data (cdp_query_api)
- Gebruikersdata beheren via API's (api)
- Op elk gewenst moment namens u verzoeken uitvoeren (refresh_token, offline_access)
Schemavereisten
Het schemabestand dat u uploadt, moet aan specifieke vereisten voldoen om een Opname-API-bron in Data Cloud te kunnen maken. Zie Vereisten voor het schemabestand van de opname-API.
- Geüploade schema's dienen een geldige OpenAPI-indeling te hebben met een .yml- of .yaml-extensie. OpenAPI versie 3.0.x wordt ondersteund.
- Objecten mogen geen geneste objecten bevatten.
- Elk schema moet ten minste één object bevatten. Elk object moet ten minste één veld bevatten.
- Objecten mogen niet meer dan 1000 velden bevatten.
- Objecten mogen niet langer zijn dan 80 tekens.
- Objectnamen mogen alleen de tekens a-z, A-Z, 0–9, _, - bevatten. Unicode-tekens zijn niet toegestaan.
- Veldnamen mogen alleen de tekens a-z, A-Z, 0–9, _, - bevatten. Unicode-tekens zijn niet toegestaan.
- Veldnamen mogen geen van de volgende gereserveerde woorden bevatten: date_id, location_id, dat_account_currency, dat_exchange_rate, pacing_period, pacing_end_date, row_count, version. Veldnamen mogen de tekenreeks __ niet bevatten.
- Veldnamen mogen niet meer dan 80 tekens bevatten.
- Velden dienen te voldoen aan het volgende type en de volgende notatie:
- Voor het type Tekst of Booleaans: tekenreeks
- Voor het type Nummer: nummer
- Voor het type Datum: tekenreeks; notatie: datum-tijd
- Objectnamen mogen niet worden gedupliceerd en zijn niet hoofdlettergevoelig.
- Objecten mogen geen dubbele veldnamen bevatten en zijn niet hoofdlettergevoelig.
- Velden van het datatype DatumTijd in uw payloads moeten ISO 8601 UTC Zulu volgen met de indeling yyyy-MM-dd'T'UU:mm:ss.SSS'Z'.
Houd tijdens het bijwerken van uw schema rekening met het volgende:
- Bestaande velddatatypen kunnen niet worden gewijzigd.
- Tijdens het bijwerken van een object moeten alle bestaande velden voor dat object aanwezig zijn.
- Uw bijgewerkte schemabestand bevat alleen de gewijzigde objecten, dus u hoeft niet elke keer een volledige lijst met objecten te verstrekken.
- Er moet een veld DatumTijd aanwezig zijn voor objecten die bedoeld zijn voor de categorie Betrokkenheid. Voor objecten van het type
profileofothergeldt deze eis niet.
Voorbeeld YAML-bestand
openapi: 3.0.3
components:
schemas:
owner:
type: object
required:
- id
- name
- region
- createddate
properties:
id:
type: integer
format: int64
name:
type: string
maxLength: 50
region:
type: string
maxLength: 50
createddate:
type: string
format: date-time
car:
type: object
required:
- car_id
- color
- createddate
properties:
car_id:
type: integer
format: int64
color:
type: string
maxLength: 50
createddate:
type: string
format: date-time Flowuitvoerdata opslaan in Amazon S3
Beschikbaar in Tableau Prep Builder 2024.2 en later en Webauthoring en Tableau Cloud. Deze functie is nog niet beschikbaar in Tableau Server.
U kunt verbinding maken met data via alle connectors die Tableau Prep Builder of op het web ondersteunt en u kunt uw flowuitvoer opslaan als een .parquet- of .csv-bestand in Amazon S3. De uitvoer kan worden opgeslagen als nieuwe data of u kunt bestaande S3-data overschrijven. Om dataverlies te voorkomen, kunt u de optie Aangepaste SQL gebruiken om een kopie van uw tabeldata te maken en deze uit te voeren voordat u de flowdata opslaat in S3.
Het opslaan van uw flowuitvoer en het verbinden met de S3-connector zijn procedures die onafhankelijk van elkaar zijn. U kunt een bestaande S3-verbinding die u als Tableau Prep-invoerverbinding hebt gebruikt niet opnieuw gebruiken.
U kunt een onbeperkte hoeveelheid data en een onbeperkt aantal objecten opslaan in Amazon S3. Individuele Amazon S3-objecten kunnen in grootte variëren van minimaal 0 bytes tot maximaal 5 TB. Het grootste object dat in één PUT kan worden geüpload is 5 GB. Als objecten groter zijn dan 100 MB, kunnen klanten beter de functie voor meerdelig uploaden gebruiken. Zie Objecten uploaden en kopiëren met behulp van meerdelige uploads (in het Engels).
Machtigingen
Om naar uw Amazon S3-bucket te kunnen schrijven, hebt u de bucketregio, bucketnaam, toegangssleutel-ID en geheime toegangssleutel nodig. U dient een IAM-gebruiker (Identity and Access Management) aan te maken in AWS om deze sleutels te verkrijgen. Zie Toegangssleutels voor IAM-gebruikers beheren (in het Engels).
Flowdata opslaan in Amazon S3
- Klik op het pluspictogram voor een stap en selecteer Uitvoer toevoegen.
- Selecteer Database en cloudopslag in de vervolgkeuzelijst Uitvoergegevens opslaan in.
- Selecteer in het gedeelte Tabel > Verbinding de optie Amazon S3 (alleen uitvoer).
- Voeg de volgende informatie toe in het formulier Amazon S3 (alleen uitvoer):
- Toegangssleutel-ID: de sleutel-ID die u gebruikt om de verzoeken te ondertekenen die u naar Amazon S3 verzendt.
- Geheime toegangssleutel: beveiligingsreferenties (wachtwoorden, toegangssleutels) waarmee wordt geverifieerd of u toegang mag krijgen tot de AWS-bron.
- Bucketregio: de locatie van de Amazon S3-bucket (AWS-regio-eindpunt). Bijvoorbeeld: us-east-2.
- Bucketnaam: de naam van de S3-bucket waarnaar u de flowuitvoer wilt schrijven. De bucketnamen van twee AWS-accounts in dezelfde regio mogen niet hetzelfde zijn.
Opmerking: Als u uw S3-regio en bucketnaam wilt achterhalen, meldt u zich aan bij uw AWS S3-account en navigeert u naar de AWS S3-console.
- Klik op Aanmelden.
- Voer in het veld S3 URI de naam in van het
.csv- of.parquet-bestand. Standaard wordts3://<your_bucket_name>ingevuld in het veld. De bestandsnaam moet de extensie.csvof.parquet.bevatten.U kunt de flowuitvoer opslaan als een nieuw S3-object of u kunt een bestaand S3-object overschrijven.
- Voor een nieuw S3-object typt u de naam van het
.parquet- of.csv-bestand. De URI wordt weergegeven in de voorbeeldtekst. Bijvoorbeelds3://<bucket_name><name_file.csv>. - Als u een bestaand S3-object wilt overschrijven, typt u de naam van het
.parquet- of.csv-bestand of klikt u op Bladeren om bestaande S3.parquet- of.csv-bestanden te vinden.Opmerking: In het venster Door objecten bladeren worden alleen bestanden weergegeven die zijn opgeslagen bij eerdere aanmeldingen bij Amazon S3.
- Voor een nieuw S3-object typt u de naam van het
- Voor Schrijfopties wordt een nieuw S3-object gemaakt met de data uit uw flow. Als de data al bestaan, worden eventuele bestaande datastructuren of -eigenschappen die voor het object zijn gedefinieerd, verwijderd en vervangen door nieuwe flowdata. Alle velden die in de flow aanwezig zijn, worden toegevoegd aan het nieuwe S3-object.
- Klik op Flow uitvoeren om de flow uit te voeren en uw data naar S3 te schrijven.
U kunt controleren of de data zijn opgeslagen in S3 door in te loggen op uw AWS S3-account en naar de AWS S3-console te gaan.