Tableau Prep으로 두 번째 날짜 구하기
분석에서 공통적으로 필요한 사항은 두 번째 이벤트가 발생한 날짜를 결정하는 것입니다. 예를 들어 고객이 두 번째 구매를 한 날짜 즉, 반복 고객이 된 날짜나 운전자가 두 번째 교통 위반을 한 날짜를 결정해야 하는 경우가 많습니다. 첫 번째 이벤트의 날짜를 구하는 것은 쉽습니다. 단순히 가장 이른 날짜를 구하면 됩니다. 하지만 두 번째 날짜를 구하는 것은 다소 까다롭습니다.
두 부분으로 구성된 이 자습서에서는 교통 위반 데이터를 변형하고 다음과 같은 질문에 답합니다.
각 운전자에 대한 첫 번째 위반과 두 번째 위반 사이의 간격(일)은 얼마입니까?
첫 번째 위반과 두 번째 위반에 대한 벌금을 비교합니다. 상관 관계가 있습니까?
가장 많은 벌금을 낸 운전자는 누구입니까? 가장 적은 벌금을 낸 운전자는 누구입니까?
위반 유형이 여러 개인 운전자는 몇 명입니까?
교통 안전 교육을 받은 적이 없는 운전자의 평균 벌금 액수는 얼마입니까?
첫 번째 단계에서는 데이터를 분석할 수 있도록 Tableau Prep Builder를 사용하여 재구성합니다. 두 번째 단계인 Tableau Desktop에서 두 번째 날짜를 사용하여 분석에서는 Tableau Desktop에서 분석을 수행합니다.
이 자습서의 목표는 생활 속 시나리오의 관점에서 다양한 개념을 제안하고 옵션을 살펴보는 것입니다. 따라서, 어떤 옵션이 최선인지에 대해서는 다루지 않습니다. 이 자습서를 끝내면 Tableau Prep의 다양한 특성과 Tableau Desktop의 계산에 대해 더 잘 알게 되며 데이터 구조가 계산 및 분석에 미치는 영향을 더 잘 이해하게 됩니다.
참고: 이 자습서의 작업을 완료하려면 Tableau Prep Builder(브라우저를 통하거나 설치된 버전)가 필요하며 선택적으로 Tableau Desktop을 설치하고 데이터를 다운로드해야 합니다. 두 번째 부분의 경우 Tableau Desktop도 설치해야 합니다.
데이터 집합은 Traffic Violations.xlsx입니다. 이 파일을 [내 Tableau Prep 리포지토리] > [데이터 원본] 폴더에 저장하는 것이 좋습니다.
이 자습서를 계속하기 전에 Tableau Prep Builder 및 Tableau Desktop을 설치하려면 Tableau Desktop 및 Tableau Prep 배포 가이드(링크가 새 창에서 열림)를 참조하십시오. 또는 Tableau Prep(링크가 새 창에서 열림) 및 Tableau Desktop(링크가 새 창에서 열림) 무료 평가판을 다운로드할 수 있습니다.
데이터
이 예제의 경우 교통 위반 데이터를 조사합니다. 각 위반은 행을 구성합니다. 운전자, 날짜, 위반 유형, 운전자가 교통 안전 교육에 참석하도록 요구받았는지 여부 및 벌금 액수가 기록됩니다.

바람직한 데이터 구조
데이터는 현재 각 위반이 행이 되도록 구성되어 있습니다. 여러 위반을 한 운전자는 여러 행에 나타나고 어느 것이 첫 번째 위반 또는 두 번째 위반인지 알 수 있는 쉬운 방법이 없습니다.
반복적인 위반자를 조사하기 위해 첫 번째 위반 날짜와 두 번째 위반 날짜를 구분하는 데이터 집합과 각 위반과 관련된 정보가 필요하지만 행은 운전자별로 구성되어 있습니다.

데이터 재구성
Tableau Prep을 사용하여 이러한 목적을 달성하려면 어떻게 해야 할까요? 먼저 첫 번째 위반 날짜를 가져오고 두 번째 날짜를 가져온 다음 원하는 대로 최종적인 데이터 집합을 변형하여 단계별로 흐름을 구축할 것입니다. 따라 할 Excel 파일(Traffic Violations.xlsx)을 다운로드했는지 확인하십시오.
첫 번째 위반 날짜에 대한 초기 집계
먼저 Traffic Violations.xlsx 파일에 연결합니다.
Tableau Prep Builder를 엽니다.
시작 화면에서 데이터에 연결을 클릭합니다.
연결 패널에서 Microsoft Excel을 클릭합니다. Traffic Violations.xlsx를 저장한 위치로 이동하고 열기를 클릭합니다.
Infractions 시트가 자동으로 흐름 패널에 열려야 합니다.
데이터 연결에 대한 자세한 내용은 데이터에 연결을 참조하십시오.
다음으로, 운전자별로 첫 번째 위반 날짜를 식별해야 합니다. 이를 위해 집계 단계를 사용할 것입니다. Driver ID(운전자 ID)와 Minimum Infraction Date(최소 위반 날짜)로 구성된 작은 데이터 집합을 만듭니다.
Tableau Prep에서 집계 단계를 사용할 때 행을 구성하는 필드로 정의되어야 하는 모든 필드는 그룹화된 필드입니다. (이 경우 Driver ID(운전자 ID)입니다.) 그룹화된 필드 수준에서 집계되고 표시되는 모든 필드는 집계된 필드입니다. (이 경우 Infraction Date(위반 날짜)입니다.)
흐름 패널에서 Infractions(위반)를 선택하고 더하기
 아이콘을 클릭한 다음 집계를 선택합니다.
아이콘을 클릭한 다음 집계를 선택합니다.Driver ID(운전자 ID)를 끌어 그룹화된 필드 영역에 놓습니다.
Infraction Date(위반 날짜)를 끌어 집계된 필드 영역에 놓습니다. 기본 집계는 CNT(카운트)입니다. CNT를 클릭하고 집계를 최소값으로 변경합니다.

이렇게 하면 가장 작은(가장 이른) 날짜 즉, 운전자별로 첫 번째 위반 날짜가 식별됩니다.
집계에 대한 자세한 내용은 데이터 정리 및 변형를 참조하십시오.
흐름 패널에서 집계 1을 선택하고 더하기
아이콘을 클릭한 다음 집계의 출력을 정리할 수 있도록 정리 단계를 선택합니다.프로필 패널에서 필드명 Infraction Date(위반 날짜)를 두 번 클릭하고 1st Infraction Date(첫 번째 위반 날짜)로 변경합니다.
이 단계에서 흐름 및 프로필 패널은 다음과 같이 표시됩니다.

이 정리 단계의 프로필 패널에서 이제 데이터가 39개 행과 2개 필드만으로 구성된다는 것을 확인할 수 있습니다. 그룹화 또는 집계에 사용되지 않는 모든 필드는 손실됩니다. 하지만 원래 정보 중 일부를 유지하고 싶습니다. 세부 수준을 변경해야 하거나 필드를 집계해야 하지만 이러한 필드를 그룹화 또는 집계에 추가하거나 이 미니 데이터 집합을 원래 데이터 집합에 다시 조인하여 원래 데이터에 1st Infraction Date(첫 번째 위반 날짜)에 대한 새 열을 추가합니다. 이제 조인을 수행하겠습니다.
흐름 패널에서 Infractions(위반)를 선택하고 더하기
아이콘을 클릭한 다음 정리 단계를 선택합니다.위반 단계와 집계 단계 사이의 선이 아니라 위반 단계 위로 직접 마우스오버해야 합니다. 분기가 아닌 둘 사이에 새 정리 단계가 삽입된 경우 도구 모음의 실행 취소 화살표를 사용하고 다시 시도하십시오. 메뉴에 삽입이 아닌 추가가 표시되어야 합니다.

그러면 모든 원래 데이터가 있는 흐름으로 분기됩니다. 이제 집계 결과를 이 전체 데이터 복사본에 조인하겠습니다. Driver ID(운전자 ID)를 기준으로 조인하여 집계의 최소 날짜를 원래 데이터에 추가합니다.
정리 2 단계를 선택하고 정리 1 단계 위로 끈 다음 조인 위에 놓습니다.
기본 조인 구성이 정확해야 합니다. 즉, Driver ID(운전자 ID) = Driver ID(운전자 ID)에 대한 내부 조인이어야 합니다.

조인에 대한 자세한 내용은 데이터 조인을 참조하십시오.
조인 절에 있는 필드와 같은 일부 필드가 조인 중에 중복될 수 있으므로 일반적으로 조인을 수행한 후 불필요한 필드를 정리하는 것이 좋습니다.
흐름 패널에서 조인 1을 선택하고 더하기
아이콘을 클릭한 다음 정리 단계를 선택합니다.프로필 패널에서 Driver ID-1(운전자 ID-1) 카드를 마우스 오른쪽 단추로 클릭(MacOS의 경우 Ctrl-클릭)하고 제거를 선택합니다.
필드 순서를 변경하려면 1st Infraction Date(첫 번째 위반 날짜) 카드를 Driver ID(운전자 ID)와 Infraction Date(위반 날짜) 사이의 검은색 선이 나타나는 위치로 끌어옵니다.
이 단계에서 흐름은 다음과 같이 표시됩니다.

아래 데이터 그리드를 살펴보면 결합된 새 데이터 집합을 확인할 수 있습니다. 데이터 집합의 각 행에 각 운전자의 최소(첫 번째) 위반 날짜가 추가되었습니다.
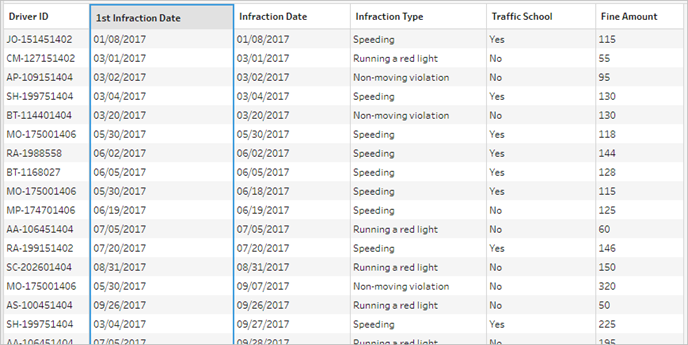
두 번째 위반 날짜에 대한 두 번째 집계
두 번째 위반 날짜도 결정해야 합니다. 이 작업을 수행하기 위해 위반 날짜가 최소값과 같은 모든 행을 필터링하여 첫 번째 날짜를 제거하려고 합니다. 그런 다음 또 다른 집계 단계를 사용하여 나머지 데이터에서 최소값을 구할 수 있습니다. 이렇게 하면 두 번째 위반 날짜가 구해지며 쉽게 구분할 수 있도록 이름을 변경할 것입니다.
참고: 나중에 흐름에서 현재 정리 3에 있는 데이터를 그대로 사용하고 싶기 때문에 두 번째 위반 날짜를 구하기 위해 또 다른 정리 단계를 추가합니다. 이렇게 하면 나중에 사용 가능한 정리 3의 현재 데이터 상태가 유지됩니다.
흐름 패널에서 정리 3을 선택하고 더하기
아이콘을 클릭한 다음 정리 단계를 선택합니다.프로필 패널의 툴바에서 필터 값을 선택합니다.
[Infraction Date] != [1st Infraction Date]필터를 만듭니다.1st Infraction Date(첫 번째 위반 날짜) 필드를 제거합니다.
흐름 패널에서 정리 4를 선택하고 더하기
아이콘을 클릭한 다음 집계를 선택합니다.Driver ID(운전자 ID)를 끌어 그룹화된 필드 영역에 놓습니다. Infraction Date(위반 날짜)를 끌어 집계된 필드 영역에 놓은 다음 집계를 Minimum(최소값)으로 변경합니다.
흐름 패널에서 집계 2를 선택하고 더하기
아이콘을 클릭한 다음 정리 단계를 선택합니다. Infraction Date(위반 날짜)를 2nd Infraction Date(두 번째 위반 날짜)로 이름을 바꿉니다.
이 단계에서 흐름은 다음과 같이 표시됩니다.

이제 각 운전자의 두 번째 위반 날짜를 식별했습니다. 각 위반과 연관된 다른 모든 정보(유형, 벌금, 교통 안전 교육)를 가져오기 위해 이 단계를 다시 전체 데이터 집합과 조인해야 합니다.
정리 5를 선택하고 정리 3 위로 끈 다음 조인 위에 놓습니다.
이번에도 기본 조인 구성이 정확해야 합니다. 즉, Driver ID(운전자 ID) = Driver ID(운전자 ID)에 대한 내부 조인이어야 합니다.
흐름 패널에서 조인 2를 선택하고 더하기
아이콘을 클릭한 다음 정리 단계를 선택합니다. 더 이상 필요하지 않은 Driver ID-1(운전자 ID-1) 및 1st Infraction Date(첫 번째 위반 날짜) 필드를 삭제합니다.
이 단계에서 흐름은 다음과 같이 표시됩니다.

첫 번째 및 두 번째 위반에 대한 전체 데이터 집합 만들기
더 진행하기 전에, 잠시 시간을 내어 우리가 가지고 있는 모든 정보와 그것들을 어떻게 결합할 것인지에 대해 생각해 보겠습니다. 우리가 원하는 최종 상태는 Driver ID(운전자 ID)에 대한 열과 첫 번째 및 두 번째 위반에 대한 날짜, 유형, 교통 안전 교육 및 벌금 액수에 대한 열이 있는 다음과 같은 모양의 데이터 집합입니다.
이 목표를 달성하려면 어떻게 해야 할까요?
정리 3 단계에는 각 운전자에 대한 첫 번째 위반 날짜를 반복하는 열이 있는 완전한 데이터 집합이 있습니다.

운전자에 대해 첫 번째 위반이 아닌 모든 행을 제거하여 첫 번째 위반만 있는 데이터 집합을 구성하고 싶습니다. 다시 말해 지정된 운전자에 대해 1st Infraction Date(첫 번째 위반 날짜) = Infraction Date(위반 날짜)인 정보만 유지하고 싶습니다. 첫 번째 위반 행만 유지하도록 필터링한 후 Infraction Date(위반 날짜) 필드를 제거하고 필드명을 정리할 수 있습니다.
마찬가지로, 두 번째 집계 및 조인 후에 두 번째 위반 날짜에 대한 열이 있는 완전한 데이터 집합을 가지고 있습니다.

유사한 필터 2nd Infraction Date(두 번째 위반 날짜) = Infraction Date(위반 날짜)를 실행하여 각 운전자의 두 번째 위반에 대한 정보 행만 유지할 수 있습니다. 이번에도 중복되는 Infraction Date(위반 날짜)를 제거하고 필드명을 정리할 수 있습니다.
첫 번째 위반 데이터 집합부터 시작합니다.
흐름 패널에서 정리 3을 선택하고 더하기
아이콘을 클릭한 다음 정리 단계를 선택합니다.위의 10단계에서와 같이 새 정리 단계에 대한 분기를 추가하고 정리 3과 정리 4 사이에 삽입하지 않습니다.
이 새로운 정리 단계가 선택된 상태로 프로필 패널에서 툴바의 필터 값을 클릭합니다.
[1st Infraction Date] = [Infraction Date]필터를 만듭니다.Infraction Date(위반 날짜) 필드를 제거합니다.
Infraction Type(위반 유형), Traffic School(교통 안전 교육) 및 Fine Amount(벌금 액수) 필드명을 "1st"로 시작하도록 변경합니다.
흐름 패널의 단계 아래에서 정리 7을 두 번 클릭하고 이름을 Robust 1st(분명한 첫 번째)로 변경합니다.
이제 두 번째 위반 데이터 집합의 차례입니다.
흐름 패널에서 마지막 조인 뒤에 있는 정리 6을 선택합니다.
툴바에서 필터 값을 클릭합니다.
[2nd Infraction Date] = [Infraction Date]필터를 만듭니다.Infraction Date(위반 날짜) 필드를 제거합니다.
Infraction Type(위반 유형), Traffic School(교통 안전 교육) 및 Fine Amount(벌금 액수) 필드명을 "2nd"로 시작하도록 변경합니다.
흐름 패널의 단계 아래에서 정리 6을 두 번 클릭하고 이름을 Robust 2nd(분명한 두 번째)로 변경합니다.
이 단계에서 흐름은 다음과 같이 표시됩니다.

완전한 데이터 집합 만들기
이제 운전자별로 첫 번째 및 두 번째 위반에 대한 완전한 정보가 있는 두 개의 정리된 데이터 집합이 있으며, 이 두 데이터 집합을 Driver ID(운전자 ID)를 기준으로 다시 조인하여 원하는 데이터 구조를 구성합니다.
Robust 2nd(분명한 두 번째)를 선택하고 Robust 1st(분명한 첫 번째) 위로 끌어온 다음 조인 위에 놓습니다.
기본 조인 구성이 Driver ID(운전자 ID) = Driver ID(운전자 ID)로 정확해야 합니다.
두 번째 위반이 없는 운전자를 삭제하고 싶지 않기 때문에 이 조인을 왼쪽 조인으로 만들어야 합니다. 조인 유형 영역에서 다이어그램의 Robust 1st(분명한 첫 번째) 옆에 있는 음영이 없는 영역을 클릭하여 Left(왼쪽) 조인으로 바꿉니다.
흐름 패널에서 조인 3을 선택하고 더하기
아이콘을 클릭한 다음 정리 단계를 선택합니다. 중복되는 Driver ID-1(운전자 ID-1) 필드를 제거합니다.
데이터가 원하는 상태가 되었으므로 출력을 만들고 분석을 진행할 수 있습니다.
흐름 패널에서 새로 추가한 정리 6을 선택하고 더하기
아이콘을 클릭한 다음 출력 추가를 선택합니다.출력 패널에서 출력 유형을 .csv로 변경한 다음 찾아보기를 클릭합니다. 이름으로 Driver Infractions(운전자 위반 수)를 입력하고 원하는 위치를 선택한 다음 적용을 클릭하여 저장합니다.
패널 맨 아래에서 흐름 실행
 단추를 클릭하여 출력을 생성합니다. 상태 대화 상자에서 완료를 클릭하여 대화 상자를 닫습니다.
단추를 클릭하여 출력을 생성합니다. 상태 대화 상자에서 완료를 클릭하여 대화 상자를 닫습니다.
팁: 출력 및 흐름 실행에 대한 자세한 내용은 작업 저장 및 공유를 참조하십시오.
최종 흐름은 다음과 같이 표시됩니다.

참고: 완성된 흐름 파일(Driver Infractions.tflx)을 다운로드하여 작업을 확인할 수 있습니다.
복습
이 자습서의 첫 번째 단계에서 목표는 원래 데이터 집합을 가져와 첫 번째 및 두 번째 위반 날짜와 관련된 분석을 할 수 있도록 준비하는 것이었습니다. 이 프로세스 세 단계로 구성됩니다.
첫 번째 및 두 번째 위반 날짜 식별:
Driver ID(운전자 ID)와 최소 Infraction Date(위반 날짜)를 유지하는 집계를 만듭니다. 이 집계를 원래 데이터 집합과 조인하여 매 행마다 첫 번째(최소) 위반 날짜가 반복되는 "중간 데이터 집합"을 만듭니다.
새 단계에서 1st Infraction Date(첫 번째 위반 날짜)가 Infraction Date(위반 날짜)와 같은 모든 행을 필터링합니다. 필터링된 데이터 집합에서 Driver ID(운전자 ID)와 최소 Infraction Date(위반 날짜)를 유지하는 집계를 만듭니다. 이 집계를 첫 번째 단계의 중간 데이터 집합과 조인합니다. 이렇게 하면 두 번째 위반 날짜가 식별됩니다.
첫 번째 및 두 번째 위반에 대한 정리된 데이터 집합을 작성합니다.
뒤로 돌아가 중간 데이터 집합에서 분기를 만들고 1st Infraction Date(첫 번째 위반 날짜)가 Infraction Date(위반 날짜)와 같은 행만 유지되도록 필터링합니다. 이렇게 하면 첫 번째 위반에 대한 데이터 집합이 작성됩니다. 불필요한 필드를 제거하여 데이터 집합을 정리하고 Driver ID(운전자 ID)를 제외한 모든 필요한 필드의 이름을 바꿔 첫 번째 위반에 대한 것임을 나타냅니다. 이것이 Robust 1st(분명한 첫 번째) 데이터 집합입니다.
두 번째 위반 날짜에 대한 데이터 집합을 정리합니다. 2nd Infraction Date(두 번째 위반 날짜)가 Infraction Date(위반 날짜)와 같은 행만 유지하도록 필터링하여 2단계의 조인 결과를 정리합니다. 불필요한 필드를 제거하고 Driver ID(운전자 ID)를 제외한 모든 필요한 필드의 이름을 바꿔 두 번째 위반에 대한 것임을 나타냅니다. 이것이 Robust 2nd(분명한 두 번째) 데이터 집합입니다.
첫 번째와 두 번째 위반 데이터를 단일 데이터 집합으로 결합합니다.
Robust 1st(분명한 첫 번째) 및 Robust 2nd(분명한 두 번째) 데이터 집합을 조인합니다. 두 번째 위반이 없는 운전자가 손실되지 않도록 Robust 1st(분명한 첫 번째)의 모든 레코드가 유지되는지 확인합니다.
다음으로, 이 데이터를 Tableau Desktop에서 어떻게 분석할 수 있는지 살펴보겠습니다.
참고: 이 자습서의 초기 영감을 제공한 Workout Wednesday 주제 Do Customers Spend More on Their First or Second Purchase?(고객이 첫 번째 또는 두 번째 구매에서 더 많은 소비를 합니까?)(링크가 새 창에서 열림)의 Ann Jackson과 Tableau Prep 팁 Returning the First and Second Purchase Dates(첫 번째 및 두 번째 구매 날짜 반환)(링크가 새 창에서 열림)의 Andy Kriebel에게 특별한 감사를 전합니다. 이러한 링크를 클릭하면 Tableau 웹 사이트 외부로 이동합니다. Tableau는 외부 공급자에 의해 유지 관리되는 페이지가 정확하며 최신 상태인지에 대해 책임을 지지 않습니다. 콘텐츠와 관련된 질문이 있는 경우 해당 소유자에게 문의하십시오.