작업 저장 및 공유
2025년 10월 14일 기준으로 Data Cloud의 브랜드가 Data 360으로 변경되었습니다. 전환하는 과정에서 응용 프로그램 및 설명서에서 Data Cloud를 언급한 내용이 나타날 수도 있습니다. 이름만 새롭게 변경될 뿐, 기능과 내용은 변경되지 않습니다.
흐름의 어느 시점에서든 수동으로 작업을 저장하거나 웹에서 흐름을 만들거나 편집할 때 Tableau가 자동으로 작업을 수행하도록 할 수 있습니다. 웹에서 흐름을 작업할 때 몇 가지 다른 점이 있습니다.
웹에서 흐름을 작성하는 것에 대한 자세한 내용은 Tableau Server(링크가 새 창에서 열림) 및 Tableau Cloud(링크가 새 창에서 열림) 도움말에서 웹에서의 Tableau Prep을 참조하십시오.
| Tableau Prep Builder | 웹에서의 Tableau Prep |
|---|---|
|
|
데이터를 최신 상태로 유지하려면 Tableau Prep Builder 또는 명령줄에서 수동으로 흐름을 실행할 수 있습니다. Tableau Server 또는 Tableau Cloud에 게시된 흐름을 수동으로 또는 일정에 따라 실행할 수도 있습니다. 흐름 실행에 대한 자세한 내용은 Tableau Server 또는 Tableau Cloud에 흐름 게시을 참조하십시오.
흐름 저장
Tableau Prep Builder에서 추가 작업을 수행하기 전에 수동으로 흐름을 저장하여 작업을 백업할 수 있습니다. 흐름은 Tableau Prep 흐름(.tfl) 파일 형식으로 저장됩니다.
또한 Tableau Desktop에서 공유하기 위해 통합 문서를 패키지화하는 것처럼, 흐름과 로컬 파일(Excel, 텍스트 파일 및 Tableau 추출)을 패키지화하여 다른 사용자와 공유할 수 있습니다. 로컬 파일만 흐름과 함께 패키지화할 수 있습니다. 예를 들어 데이터베이스 연결의 데이터는 패키지에 포함되지 않습니다.
웹 작성에서 로컬 파일은 흐름과 함께 자동으로 패키징됩니다. 직접 파일 연결은 아직 지원되지 않습니다.
패키지화된 흐름을 저장하면 흐름이 패키지 Tableau 흐름 파일(.tflx)로 저장됩니다.
- 수동으로 흐름을 저장하려면 상단 메뉴에서 파일 > 저장을 선택합니다.
- Tableau Prep Builder에서 흐름과 데이터 파일을 패키지화하려면 상단 메뉴에서 다음 작업 중 하나를 수행합니다.
- 파일 > 패키지 흐름 내보내기를 선택합니다.
- 파일 > 다른 이름으로 저장을 선택합니다. 그런 다음 다른 이름으로 저장 대화 상자의 파일 형식 드롭다운 메뉴에서 패키지 Tableau 흐름 파일을 선택합니다.
웹에서 흐름을 자동으로 저장
웹에서 흐름을 만들거나 편집하는 경우 흐름을 변경하면(데이터 원본에 연결, 단계 추가 등) 몇 초 후에 자동으로 작업이 초안으로 저장되므로 작업이 손실되지 않습니다.
현재 로그인한 서버에만 흐름을 저장할 수 있습니다. 한 서버에서 초안 흐름을 만들고 다른 서버에 저장하거나 게시해볼 수는 없습니다. 흐름을 서버의 다른 프로젝트에 게시하려면 파일 > 다른 이름으로 게시 메뉴 옵션을 사용한 다음 대화 상자에서 프로젝트를 선택합니다.
초안 흐름은 서버에 게시하여 서버의 프로젝트에 액세스할 수 있는 권한이 있는 모든 사용자가 사용할 수 있도록 만들기 전에는 사용자만 볼 수 있습니다. 초안 상태의 흐름은 초안 배지로 태그가 지정되므로 진행 중인 흐름을 쉽게 찾을 수 있습니다. 흐름이 게시된 적이 없는 경우 초안 배지 옆에 게시 안 함 배지가 표시됩니다.

흐름이 게시된 후 흐름을 편집하고 다시 게시하면 새 버전이 만들어집니다. 변경 내역 대화 상자에서 흐름 버전 목록을 볼 수 있습니다. 탐색 페이지에서 ![]() 동작 메뉴를 클릭하고 변경 내역을 선택합니다.
동작 메뉴를 클릭하고 변경 내역을 선택합니다.
변경 내역 관리에 대한 자세한 내용은 Tableau Desktop 도움말에서 콘텐츠 수정 버전 작업(링크가 새 창에서 열림)을 참조하십시오.
참고: 자동 저장은 기본적으로 사용하도록 설정됩니다. 관리자가 사이트에서 자동 저장을 사용하지 않도록 설정할 수 있지만 권장되지 않습니다. 자동 저장을 해제하려면 Tableau Server REST API 메서드 "사이트 업데이트"를 사용하여 flowAutoSaveEnabled 특성을 false로 설정합니다. 자세한 내용은 Tableau Server REST API 사이트 메서드: 사이트 업데이트(영문)(링크가 새 창에서 열림)를 참조하십시오.
자동 파일 복구
기본적으로는 Tableau Prep Builder는 응용 프로그램이 중단되거나 충돌하는 경우 모든 열려 있는 흐름의 초안을 자동으로 저장합니다. 초안 흐름은 내 Tableau Prep 리포지토리의 복구된 흐름 폴더에 저장됩니다. 다음에 응용 프로그램을 열면 선택할 수 있는 복구된 흐름 목록이 있는 대화 상자가 표시됩니다. 복구된 흐름을 열고 중단한 시점부터 계속하거나 필요하지 않은 경우 복구된 흐름 파일을 삭제할 수 있습니다.
참고: 복구된 흐름 폴더에 복구된 흐름이 있는 경우 이 대화 상자는 해당 폴더가 비워질 때까지 응용 프로그램을 열 때마다 표시됩니다.

이 기능을 사용하지 않으려면 관리자가 설치 중이나 설치 후에 이 기능을 해제할 수 있습니다. 이 기능을 해제하는 방법에 대한 자세한 내용은 Tableau Desktop 및 Tableau Prep 배포 가이드에서 파일 복구 해제(링크가 새 창에서 열림)를 참조하십시오.
삭제된 흐름 복구
Tableau Cloud의 Tableau Prep 웹 작성 및 Tableau Server 버전 2025.3 이상에서 지원됩니다.
웹 작성의 휴지통에서 이전에 삭제한 흐름을 검색할 수 있습니다. 휴지통이 설정되어 있으면 흐름이 영구적으로 삭제되지 않고 일시적으로 휴지통으로 이동되며, 이 휴지통에서 흐름을 검색하거나 영구적으로 삭제할 수 있습니다. 초안 상태의 흐름은 계속해서 영구적으로 삭제됩니다. 휴지통에 대한 자세한 내용은 휴지통(링크가 새 창에서 열림)을 참조하십시오.
참고: 이 기능은 아직 Tableau Prep Builder에서 사용할 수 없습니다.
이 기능을 사용하려면 다음이 필요합니다.
사용 권한: 사이트 관리자, 서버 관리자, Creator 또는 Explorer(게시 가능) 역할을 할당받아야 합니다.
사이트 설정: 사이트에서 휴지통의 사용을 설정해야 합니다.
흐름 상태: 흐름을 게시해야 합니다.
흐름이 휴지통에 저장되는 기간은 관리자가 설정합니다.
흐름 복구
홈 페이지에서 측면 패널을 확장한 다음 휴지통을 선택합니다.
휴지통 페이지의 콘텐츠 유형 드롭다운 메뉴에서 흐름을 선택합니다.

복원하려는 흐름의 추가 동작 메뉴를 선택한 다음 복원을 선택합니다.
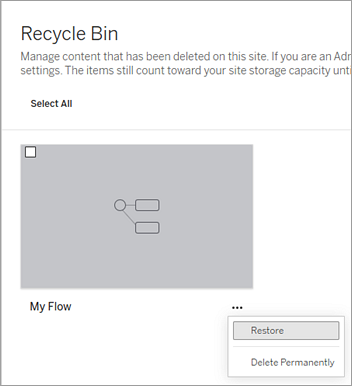
프로젝트를 복원 위치로 선택합니다.
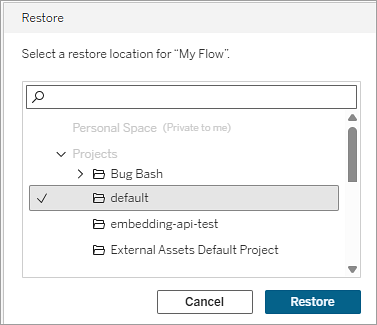
복원을 선택합니다.
Tableau Desktop에서 흐름 출력 보기
참고: 웹에서는 이 옵션을 사용할 수 없습니다.
데이터를 정리할 때 Tableau Desktop에서 하는 것처럼 진행 상황을 확인하고 싶을 수 있습니다. Tableau Desktop에서 흐름을 열면 Tableau Prep Builder가 영구적인 Tableau .hyper 파일과 Tableau 데이터 원본(.tds) 파일을 만듭니다. 이러한 파일은 Tableau 리포지토리의 데이터 원본 파일에 저장되므로 언제라도 데이터를 자유롭게 실험할 수 있습니다.
Tableau Desktop에서 흐름을 열면 흐름에서 작업 중인 데이터 샘플과 데이터에 적용된 작업을 선택한 단계까지 확인할 수 있습니다.
참고: 데이터를 자유롭게 실험할 수 있지만 Tableau에 데이터 샘플만 표시되며 통합 문서를 패키지 통합 문서(.twbx)로 저장할 수 없습니다. Tableau에서 데이터로 작업할 준비가 되었으면 흐름의 출력 단계를 만들고 출력을 파일 또는 게시된 데이터 원본으로 저장한 다음 Tableau에서 전체 데이터 원본에 연결합니다.
Tableau Desktop에서 데이터 샘플을 보려면 다음 작업을 수행합니다.
- 데이터를 보려는 단계를 마우스 오른쪽 단추로 클릭하고 상황에 맞는 메뉴에서 Tableau Desktop에서 미리 보기를 선택합니다.

- Tableau Desktop에서 시트 탭이 열립니다.
데이터 추출 파일 만들기 및 게시된 데이터 원본
흐름 출력을 만들려면 흐름을 실행합니다. 흐름을 실행할 때 변경 사항이 전체 데이터 집합에 적용됩니다. 흐름을 실행하면 Tableau 데이터 원본(.tds) 및 Tableau 데이터 추출(.hyper) 파일이 만들어집니다.
참고: 공간 데이터가 포함된 흐름은 .hyper 파일 또는 게시된 데이터 원본으로만 출력할 수 있습니다. 다른 출력 유형은 현재 지원되지 않습니다. 공간 데이터를 사용한 작업에 대한 자세한 내용은 공간 계산 및 조인 만들기(링크가 새 창에서 열림)를 참조하십시오.
Tableau Prep Builder
흐름 출력에서 추출 파일을 만들어 Tableau Desktop에서 사용하거나 제3자와 데이터를 공유할 수 있습니다. 다음과 같은 형식으로 추출 파일을 만듭니다.
- Hyper 추출(.hyper): 최신 Tableau 추출 파일 형식입니다.
- 쉼표로 구분된 값(.csv): 추출을 제3자와 데이터를 공유할 수 있도록 .csv 파일로 저장합니다. 내보낸 CSV 파일의 인코딩은 BOM이 있는 UTF-8입니다.
- Microsoft Excel(.xlsx): Microsoft Excel 스프레드시트입니다.
Tableau Prep Builder 및 웹
흐름 출력을 게시된 데이터 원본 또는 출력으로 데이터베이스에 게시합니다.
- 흐름 출력을 데이터 원본으로 Tableau Server 또는 Tableau Cloud에 저장하여 데이터를 공유하고 정리, 변형 및 결합한 데이터에 대한 중앙 집중식 액세스를 제공합니다.
- 흐름 출력을 데이터베이스에 저장하여 정리되고 준비된 흐름 데이터로 테이블 데이터를 만들거나 대체하거나 추가합니다. 자세한 내용은 흐름 출력 데이터를 외부 데이터베이스 저장을 참조하십시오.
흐름을 실행할 때 증분 새로 고침을 사용하면 전체 데이터 집합이 아니라 새 데이터만 새로 고쳐 시간 및 리소스를 절약할 수 있습니다. 증분 새로 고침을 사용하여 흐름을 구성하고 실행하는 방법에 대한 자세한 내용은 증분 새로 고침을 사용하여 흐름 데이터 새로 고치기를 참조하십시오.
참고: Tableau Prep Builder 출력을 Tableau Server에 게시하려면 Tableau Server REST API를 사용하도록 설정해야 합니다. 자세한 내용은 Tableau Rest API 도움말에서 Rest API 요구 사항(링크가 새 창에서 열림)을 참조하십시오. SSL(Secure Socket Layer) 암호화 인증서를 사용하는 서버에 게시하려면 Tableau Prep Builder를 실행하는 컴퓨터에서 추가적인 구성 단계가 필요합니다. 자세한 내용은 Tableau Desktop 및 Tableau Prep Builder 배포 가이드에서 설치 전 수행할 작업(링크가 새 창에서 열림)을 참조하십시오.
흐름 출력에 매개 변수 포함
Tableau Prep Builder와 버전 2021.4의 웹 공유에서 지원됩니다.
흐름 출력 파일 이름, 경로, 테이블 이름 또는 사용자 지정 SQL 스크립트(버전 2022.1.1 이상)에 매개 변수 값을 포함하여 다양한 데이터 집합에 대한 흐름을 간편하게 실행합니다. 자세한 내용은 매개 변수 만들기 및 흐름에서 사용을 참조하십시오.
추출을 파일로 만들기
참고: 이 출력 옵션은 웹에서 흐름을 만들거나 편집할 때 사용할 수 없습니다.
- 단계의 더하기 아이콘
 을 클릭하고 출력 추가를 선택합니다.
을 클릭하고 출력 추가를 선택합니다.이전에 흐름을 실행한 경우 출력 단계의 흐름 실행
 단추를 클릭합니다. 이렇게 하면 흐름이 실행되고 출력이 업데이트됩니다.
단추를 클릭합니다. 이렇게 하면 흐름이 실행되고 출력이 업데이트됩니다.출력 패널이 열리고 데이터 스냅샷이 표시됩니다.

- 왼쪽 패널의 출력 저장 위치 드롭다운 목록에서 파일을 선택합니다. 이전 버전에서는 파일에 저장을 선택합니다.
- 찾아보기 단추를 클릭하고 추출을 다른 이름으로 저장 대화 상자에서 파일의 이름을 입력한 다음 동의를 클릭합니다.
- 출력 유형 필드에서 다음 출력 유형 중에서 선택합니다.
- Tableau 데이터 추출(.hyper)
- 쉼표로 구분된 값(.csv)
(Tableau Prep Builder) 쓰기 옵션 섹션에서 새 데이터를 파일에 쓰는 기본 쓰기 옵션을 확인하고 필요에 따라 변경합니다. 자세한 내용은 쓰기 옵션 구성을 참조하십시오.
- 테이블 만들기: 이 옵션은 새 테이블을 만들거나 기존 테이블을 새 출력으로 바꿉니다.
- 테이블에 추가: 이 옵션은 새 데이터를 기존 테이블에 추가합니다. 아직 테이블이 없는 경우 새 테이블이 만들어지고 후속 실행에서 새 행이 이 테이블에 추가됩니다.
참고: .csv 출력 유형에는 테이블에 추가가 지원되지 않습니다. 지원되는 새로 고침 조합에 대한 자세한 내용은 흐름 새로 고침 옵션을 참조하십시오.
- 흐름 실행을 클릭하여 흐름을 실행하고 추출 파일을 생성합니다.
Microsoft Excel 워크시트로 추출 만들기
Tableau Prep Builder 버전 2021.1.2 이상에서 지원됩니다. 이 출력 옵션은 웹에서 흐름을 만들거나 편집할 때 또는 공간 데이터가 포함된 흐름에 대한 출력을 만들 때 사용할 수 없습니다.
흐름 데이터를 Microsoft Excel 워크시트로 출력하는 경우 새 워크시트를 만들거나 기존 워크시트의 데이터를 추가 또는 대체할 수 있습니다. 다음과 같은 조건이 적용됩니다.
- Microsoft Excel .xlsx 파일 형식만 지원됩니다.
- 워크시트 행은 셀 A1에서 시작됩니다.
- 데이터를 추가하거나 대체하는 경우 첫 번째 행을 머리글로 가정합니다.
- 새 워크시트를 만들면 머리글 이름이 추가되지만 데이터를 기존 워크시트에 추가할 때는 그렇지 않습니다.
- 기존 워크시트의 서식 또는 수식은 흐름 출력에 적용되지 않습니다.
- 명명된 테이블 또는 범위에 쓰기는 현재 지원되지 않습니다.
- 증분 새로 고침은 현재 지원되지 않습니다.
Microsoft Excel 워크시트 파일로 흐름 데이터 출력
- 단계의 더하기 아이콘 을 클릭하고 출력 추가를 선택합니다.
이전에 흐름을 실행한 경우 출력 단계의 흐름 실행
단추를 클릭합니다. 이렇게 하면 흐름이 실행되고 출력이 업데이트됩니다.출력 패널이 열리고 데이터 스냅샷이 표시됩니다.

- 왼쪽 패널의 출력 저장 위치 드롭다운 목록에서 파일을 선택합니다.
- 찾아보기 단추를 클릭하고 추출을 다른 이름으로 저장 대화 상자에서 파일 이름을 입력하거나 선택한 다음 동의를 클릭합니다.
- 출력 유형 필드에서 Microsoft Excel(.xlsx)을 선택합니다.

- 워크시트 필드에서 결과를 쓰려는 워크시트를 선택하거나 필드에 새 이름을 입력한 다음 새 테이블 만들기를 클릭합니다.
- 쓰기 옵션 섹션에서 다음 쓰기 옵션 중 하나를 선택합니다.
- 테이블 만들기: 흐름 데이터로 워크시트를 만들거나 파일이 이미 있는 경우 다시 만듭니다.
- 테이블에 추가: 기존 워크시트에 새 행을 추가합니다. 워크시트가 없는 경우 워크시트가 만들어지고 후속 흐름이 실행될 때 이 워크시트에 행이 추가됩니다.
- 데이터 바꾸기: 기존 워크시트의 첫 번째 행을 제외한 모든 기존 데이터를 흐름 데이터로 바꿉니다.
워크시트가 이미 있는 경우 필드 비교에 테이블의 필드와 일치하는 흐름의 필드가 표시됩니다. 워크시트가 새 워크시트인 경우 일대일 필드 일치가 표시됩니다. 일치하지 않는 필드는 무시됩니다.

- 흐름 실행을 클릭하여 흐름을 실행하고 Microsoft Excel 추출 파일을 생성합니다.
게시된 데이터 원본 만들기
- 단계의 더하기 아이콘 을 클릭하고 출력 추가를 선택합니다.
참고: Tableau Prep Builder는 이전에 게시된 데이터 원본을 새로 고치고 해당 데이터 원본에 포함될 수 있는 모든 데이터 모델링(예: 계산된 필드, 숫자 형식 등)을 유지합니다. 데이터 원본을 새로 고칠 수 없는 경우 데이터 모델링을 포함한 데이터 원본이 대신 대체됩니다.
- 출력 패널이 열리고 데이터 스냅샷이 표시됩니다.

- 출력 저장 위치 드롭다운 목록에서 게시된 데이터 원본(이전 버전에서는 데이터 원본으로 게시)을 선택합니다. 다음 필드를 완성합니다.
- 서버(Tableau Prep Builder만 해당): 데이터 원본 및 데이터 추출을 게시하려는 서버를 선택합니다. 서버에 로그인되어 있지 않은 경우 로그인하라는 메시지가 나타납니다.
참고: Tableau Prep Builder 버전 2020.1.4부터는 서버에 로그인한 후 응용 프로그램을 닫으면 Tableau Prep Builder에 서버 이름과 자격 증명이 기억됩니다. 다음에 응용 프로그램을 열면 서버에 미리 로그인됩니다.
Mac에서는 Tableau Prep Builder가 안전하게 SSL 인증서를 사용하여 Tableau Server 또는 Tableau Cloud 환경에 연결할 수 있도록 Mac 키 체인에 대한 액세스 권한을 제공하라는 메시지가 표시될 수 있습니다.
Tableau Cloud로 출력하는 경우 "serverUrl"에서 사이트가 호스팅되는 포드를 포함하십시오. 예를 들어 "https://online.tableau.com"이 아닌 "https://eu-west-1a.online.tableau.com"입니다.
- 프로젝트: 데이터 원본 및 추출을 로드하려는 프로젝트를 선택합니다.
- 이름: 파일 이름을 입력합니다.
- 설명: 데이터 원본의 설명을 입력합니다.
- 서버(Tableau Prep Builder만 해당): 데이터 원본 및 데이터 추출을 게시하려는 서버를 선택합니다. 서버에 로그인되어 있지 않은 경우 로그인하라는 메시지가 나타납니다.
- (Tableau Prep Builder) 쓰기 옵션 섹션에서 새 데이터를 파일에 쓰는 기본 쓰기 옵션을 확인하고 필요에 따라 변경합니다. 자세한 내용은 쓰기 옵션 구성을 참조하십시오.
- 테이블 만들기: 이 옵션은 새 테이블을 만들거나 기존 테이블을 새 출력으로 바꿉니다.
- 테이블에 추가: 이 옵션은 새 데이터를 기존 테이블에 추가합니다. 아직 테이블이 없는 경우 새 테이블이 만들어지고 후속 실행에서 새 행이 이 테이블에 추가됩니다.
- 흐름 실행을 클릭하여 흐름을 실행하고 데이터 원본을 게시합니다.
흐름 출력 데이터를 외부 데이터베이스 저장
이 출력 옵션은 공간 데이터가 포함된 흐름에 대한 출력을 만들 때 사용할 수 없습니다.
중요: 이 기능을 사용하면 외부 데이터베이스의 데이터를 영구적으로 삭제하고 바꿀 수 있습니다. 해당 데이터베이스에 쓸 수 있는 권한이 있는지 확인하십시오.
데이터 손실을 방지하려면 흐름 데이터를 테이블에 쓰기 전에 사용자 지정 SQL 옵션을 사용하여 테이블 데이터의 복사본을 만들고 실행하면 됩니다.
Tableau Prep Builder 또는 웹이 지원하는 모든 커넥터의 데이터에 연결하고 외부 데이터베이스로 데이터를 출력할 수 있습니다. 이렇게 하면 흐름을 실행할 때마다 정리되고 준비된 흐름 데이터를 데이터베이스에 추가하거나 이러한 데이터로 데이터베이스를 업데이트할 수 있습니다. 달리 명시되지 않은 한 이 기능은 증분 및 전체 새로 고침 옵션 모두에서 사용할 수 있습니다. 증분 새로 고침을 구성하는 방법에 대한 자세한 내용은 증분 새로 고침을 사용하여 흐름 데이터 새로 고치기를 참조하십시오.
흐름 출력을 외부 데이터베이스에 저장하는 경우 Tableau Prep은 다음을 수행합니다.
- 행을 생성하고 데이터베이스에 대해 SQL 명령을 실행합니다.
- 출력 데이터베이스의 임시 테이블(또는 Snowflake로 출력하는 경우 준비 영역)에 데이터를 씁니다.
- 작업이 성공적인 경우 임시 테이블(또는 Snowflake의 준비 영역)의 데이터가 대상 테이블로 이동합니다.
- 데이터를 데이터베이스에 쓴 후 실행하려는 SQL 명령을 실행합니다.
SQL 스크립트가 실패하면 흐름이 실패합니다. 그러나 데이터는 여전히 데이터베이스 테이블에 로드됩니다. 흐름을 다시 실행하거나 데이터베이스에서 수동으로 SQL 스크립트를 실행하여 적용할 수 있습니다.
출력 옵션
데이터를 데이터베이스에 쓸 때 다음 옵션을 선택할 수 있습니다. 테이블이 아직 없는 경우 흐름을 처음 실행할 때 만들어집니다.
- 테이블에 추가: 이 옵션은 데이터를 기존 테이블에 추가합니다. 테이블이 없는 경우 흐름을 처음 실행할 때 테이블이 만들어지고 후속 흐름 실행 시 해당 테이블에 데이터가 추가됩니다.
- 테이블 만들기: 이 옵션은 흐름의 데이터를 사용하여 새 테이블을 만듭니다. 테이블이 이미 있는 경우 테이블과 테이블에 정의된 기존 데이터 구조 또는 속성이 삭제되고 흐름 데이터 구조를 사용하는 새 테이블로 바뀝니다. 흐름에 있는 모든 필드가 새 데이터베이스 테이블에 추가됩니다.
- 데이터 바꾸기: 이 옵션은 기존 테이블의 데이터를 삭제하고 흐름의 데이터로 바꾸지만 데이터베이스 테이블의 구조와 속성은 유지합니다. 테이블이 없는 경우 흐름을 처음 실행할 때 테이블이 만들어지고 후속 흐름 실행 시 테이블 데이터가 바뀝니다.
추가 옵션
쓰기 옵션에 더해 데이터베이스에 사용자 지정 SQL 스크립트를 포함하거나 새 테이블을 추가할 수 있습니다.
- 사용자 지정 SQL 스크립트: 사용자 지정 SQL을 입력하고 데이터가 데이터베이스 테이블에 기록되기 전, 후 또는 전/후 모두에 스크립트를 실행할지 여부를 선택합니다. 이러한 스크립트를 사용하여 흐름 데이터가 테이블에 기록되기 전, 인덱스를 추가하기 전, 다른 테이블 속성을 추가하기 전에 데이터베이스 테이블의 복사본을 만들 수 있습니다.
참고: 버전 2022.1.1부터는 SQL 스크립트에도 매개 변수를 삽입할 수 있습니다. 자세한 내용은 출력 단계에 사용자 매개 변수 적용을 참조하십시오.
- 새 테이블 추가: 기존 테이블 목록에서 선택하지 않고 고유한 이름으로 새 테이블을 데이터베이스에 추가합니다. 기본 스키마(Microsoft SQL Server 및 PostgreSQL) 외의 스키마를 적용하려는 경우
[schema name].[table name]구문을 사용하여 스키마를 지정할 수 있습니다.
지원되는 데이터베이스 및 데이터베이스 요구 사항
Tableau Prep에서는 선별된 데이터베이스의 테이블에 흐름 데이터를 쓸 수 있습니다. Tableau Cloud에서 일정에 따라 실행되는 흐름은 클라우드에서 호스팅되는 데이터베이스에만 쓸 수 있습니다.
2025.1 버전부터 온프레미스 데이터 원본에 연결하는 경우 Tableau Bridge 클라이언트를 사용하여 Tableau Cloud에 연결하고 Tableau Cloud의 데이터를 새로 고칠 수 있습니다. 이를 위해서는 사설망 허용 목록에 도메인을 추가하고 Bridge 클라이언트 풀에 구성된 Tableau Bridge 클라이언트가 필요합니다. Tableau Prep Builder 및 웹에서 데이터 원본에 연결할 때 서버 URL이 Bridge 풀의 도메인과 일치하는지 확인합니다. 자세한 내용은 Tableau Prep Builder에서 흐름 게시(링크가 새 창에서 열림)의 Tableu Cloud 섹션에서 "데이터베이스"를 참조하십시오.
일부 데이터베이스에는 데이터 제한 또는 요구 사항이 있습니다. 또한 Tableau Prep은 데이터를 지원되는 데이터베이스에 쓸 때 최고 성능을 유지하기 위해 일부 제한을 적용할 수 있습니다. 다음 표에는 흐름 데이터를 저장할 수 있는 데이터베이스와 데이터베이스 제한 사항 또는 요구 사항이 나열되어 있습니다. 이러한 요구 사항을 충족하지 않는 데이터가 있는 경우 흐름을 실행할 때 오류가 발생할 수 있습니다.
참고: 필드에 대한 문자 제한 설정은 아직 지원되지 않습니다. 그러나 문자 제한 제약 조건이 있는 데이터베이스에 테이블을 만드는 경우 데이터 바꾸기 옵션을 사용하여 데이터베이스의 테이블 구조를 유지하면서 데이터를 바꿀 수 있습니다.
| 데이터베이스 | 요구 사항 또는 제한 사항 |
|---|---|
| Amazon Redshift |
|
| Amazon S3(출력 전용) | 흐름 출력 데이터를 Amazon S3에 저장 참조 |
| Databricks |
|
| Google BigQuery |
|
| Microsoft SQL Server |
|
| MySQL |
|
| Oracle |
|
| Pivotal Greenplum Database |
|
| PostgreSQL |
|
| SAP HANA |
|
| Snowflake |
|
| Teradata |
|
| Vertica |
|
흐름 데이터를 데이터베이스 저장
참고: 흐름을 게시할 때 데이터베이스에 대한 자격 증명을 내장할 수 있습니다. 자격 증명 내장에 대한 자세한 내용은 Tableau Prep Builder에서 흐름 게시의 데이터베이스 섹션을 참조하십시오.
- 단계의 더하기 아이콘 을 클릭하고 출력 추가를 선택합니다.
- 출력을 다른 형식으로 저장 드롭다운 목록에서 데이터베이스 및 클라우드 저장소를 선택합니다.
- 설정 탭에서 다음 정보를 입력합니다.
- 연결 드롭다운 목록에서 흐름 출력을 쓸 데이터베이스 커넥터를 선택합니다. 지원되는 커넥터만 표시됩니다. 흐름 입력에 사용한 동일한 커넥터 또는 다른 커넥터를 선택할 수 있습니다. 다른 커넥터를 선택하는 경우 로그인 메시지가 표시됩니다.
중요: 선택한 데이터베이스에 대한 쓰기 권한이 있는지 확인하십시오. 그렇지 않으면 흐름에서 데이터가 부분적으로만 처리될 수 있습니다.
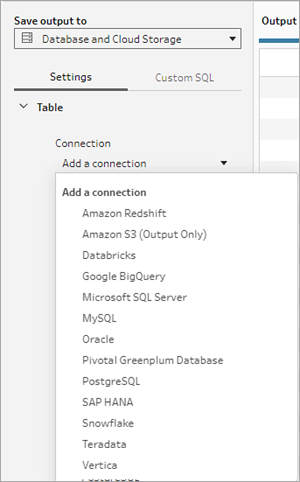
- 데이터베이스 드롭다운 목록에서 흐름 출력 데이터를 저장할 데이터베이스를 선택합니다. 하나 이상의 테이블이 있는 스키마 또는 데이터베이스만 드롭다운 목록에 표시됩니다.
- 테이블 드롭다운 목록에서 흐름 출력 데이터를 저장할 테이블을 선택합니다. 선택한 쓰기 옵션에 따라 새 테이블이 만들어지거나 테이블의 기존 데이터가 흐름 데이터로 바뀌거나 기존 테이블에 흐름 데이터가 추가됩니다.
데이터베이스에 새 테이블을 만들려면 필드에 고유한 테이블 이름을 입력한 다음 새 테이블 만들기를 클릭합니다. 흐름을 처음 실행하면 선택한 쓰기 옵션에 관계없이 흐름과 동일한 스키마의 테이블이 데이터베이스에 만들어집니다.

- 연결 드롭다운 목록에서 흐름 출력을 쓸 데이터베이스 커넥터를 선택합니다. 지원되는 커넥터만 표시됩니다. 흐름 입력에 사용한 동일한 커넥터 또는 다른 커넥터를 선택할 수 있습니다. 다른 커넥터를 선택하는 경우 로그인 메시지가 표시됩니다.
- 출력 패널에 데이터 스냅샷이 표시됩니다. 테이블이 이미 있는 경우 필드 비교에 테이블의 필드와 일치하는 흐름의 필드가 표시됩니다. 테이블이 새 테이블인 경우 일대일 필드 일치가 표시됩니다.

필드 불일치가 있는 경우 상태 메모에 오류가 표시됩니다.
- 일치 항목 없음: 필드가 무시됨: 필드가 흐름에 있지만 데이터베이스에는 없습니다. 테이블 만들기 쓰기 옵션을 선택하고 전체 새로 고침을 수행하지 않으면 필드가 데이터베이스 테이블에 추가되지 않습니다. 이 경우 흐름 필드가 데이터베이스 테이블에 추가되고 흐름 출력 스키마가 사용됩니다.
- 일치 항목 없음: 필드에 Null 값이 포함됨: 필드가 데이터베이스에 있지만 흐름에는 없습니다. 흐름이 필드에 대한 데이터베이스 테이블에 Null 값을 전달합니다. 필드가 흐름에 있지만 필드명이 달라서 일치하지 않는 경우 정리 단계로 이동하여 데이터베이스 필드명과 일치하는 이름으로 필드명을 편집할 수 있습니다. 필드명을 편집하는 방법에 대한 자세한 내용은 정리 작업 적용을 참조하십시오.
- 오류: 필드 데이터 유형이 일치하지 않음: 흐름 테이블의 필드에 할당된 데이터 유형과 출력을 쓰는 데이터베이스 테이블의 필드에 할당된 데이터 유형은 일치해야 합니다. 그렇지 않으면 흐름이 실패합니다. 정리 단계로 이동하고 필드 데이터 유형을 편집하여 이 문제를 해결할 수 있습니다. 데이터 유형 변경에 대한 자세한 내용은 데이터에 할당된 데이터 유형 검토를 참조하십시오.
- 쓰기 옵션을 선택합니다. 전체 및 증분 새로 고침에 대해 서로 다른 옵션을 선택할 수 있으며 옵션은 흐름 실행 방법을 선택할 때 적용됩니다. 증분 새로 고침을 사용한 흐름 실행에 대한 자세한 내용은 증분 새로 고침을 사용하여 흐름 데이터 새로 고치기를 참조하십시오.
- 테이블에 추가: 이 옵션은 데이터를 기존 테이블에 추가합니다. 테이블이 없는 경우 흐름을 처음 실행할 때 테이블이 만들어지고 후속 흐름 실행 시 해당 테이블에 데이터가 추가됩니다.
- 테이블 만들기: 이 옵션은 새 테이블을 만듭니다. 동일한 이름의 테이블이 이미 있는 경우 기존 테이블이 삭제되고 새 테이블로 바뀝니다. 테이블에 정의된 기존 데이터 구조 또는 속성도 삭제되고 흐름 데이터 구조로 바뀝니다. 흐름에 있는 모든 필드가 새 데이터베이스 테이블에 추가됩니다.
- 데이터 바꾸기: 이 옵션은 기존 테이블의 데이터를 삭제하고 흐름의 데이터로 바꾸지만 데이터베이스 테이블의 구조와 속성은 유지합니다.
- (선택 사항) 사용자 지정 SQL 탭을 클릭하고 SQL 스크립트를 입력합니다. 데이터를 테이블에 쓰기 전과 후에 실행할 스크립트를 입력할 수 있습니다.

- 흐름 실행을 클릭하여 흐름을 실행하고 선택한 데이터베이스에 흐름을 씁니다.
흐름 출력 데이터를 CRM Analytics의 데이터 집합에 저장
Tableau Prep Builder와 버전 2022.3의 웹 공유에서 지원됩니다.
참고: CRM Analytics에서는 외부 원본의 데이터를 통합할 때 몇 가지 요구 사항과 제한 사항이 있습니다. CRM Analytics에 흐름 출력을 성공적으로 기록하려면 Salesforce 도움말에서 데이터를 데이터 집합에 통합하기 전 고려 사항(영문)(링크가 새 창에서 열림)을 참조하십시오.
Tableau Prep을 사용하여 데이터를 정리하고 CRM Analytics에서 더 나은 예측 결과를 얻을 수 있습니다. 간단히 웹의 Tableau Prep Builder 또는 Tableau Prep이 지원하는 커넥터의 데이터에 연결하기만 하면 됩니다. 그런 다음 변환을 적용하여 데이터를 정리하고 액세스 권한이 있는 CRM Analytics의 데이터 집합에 흐름 데이터를 직접 출력합니다.
CRM Analytics로 데이터를 출력하는 흐름은 명령줄 인터페이스를 사용하여 실행할 수 없습니다. Tableau Prep Builder를 사용하거나 Tableau Prep Conductor와 함께 웹에서 일정을 사용하여 수동으로 흐름을 실행할 수 있습니다.
필수 요건
CRM Analytics로 흐름 데이터를 출력하려면 Salesforce 및 Tableau에 다음과 같은 라이선스, 액세스 및 사용 권한이 있는지 확인합니다.
Salesforce 요구 사항
| 요구 사항 | 설명 |
|---|---|
| Salesforce 사용 권한 | CRM Analytics Plus 또는 CRM Analytics Growth 라이선스 중 하나를 할당받아야 합니다. CRM Analytics Plus 라이선스에는 다음 사용 권한 집합이 포함됩니다.
CRM Analytics Growth 라이선스에는 다음 사용 권한 집합이 포함됩니다.
자세한 내용은 Salesforce 도움말의 CRM Analytics 라이선스 및 사용 권한 집합에 대해 자세히 알아보기(영문)(링크가 새 창에서 열림) 및 사용자 권한 집합 선택 및 할당(영문)(링크가 새 창에서 열림)을 참조하십시오. |
관리자 설정 | Salesforce 관리자는 다음을 구성해야 합니다.
|
Tableau Prep 요구 사항
| 요구 사항 | 설명 |
|---|---|
Tableau Prep 라이선스 및 사용 권한 | Creator 라이선스. Creator는 Salesforce org 계정에 로그인하고 인증해야 흐름 데이터를 출력할 앱 및 데이터 집합을 선택할 수 있습니다. |
OAuth 데이터 연결 | 서버 관리자는 커넥터의 OAuth 클라이언트 ID 및 암호로 Tableau Server를 구성합니다. 이는 Tableau Server에서 흐름을 실행하는 데 필요합니다. 자세한 내용은 Tableau Server 도움말에서 Salesforce.com OAuth에 대해 Tableau Server 구성(링크가 새 창에서 열림)을 참조하십시오. |
CRM Analytics에 흐름 데이터 저장
Tableau Prep Builder에서 CRM Analytics에 저장할 때 다음 CRM Analytics 입력 제한이 적용됩니다.
- 외부 데이터 업로드를 위한 최대 파일 크기: 40GB
- 24시간 동안 모든 외부 데이터 업로드를 위한 최대 파일 크기: 50GB
- 단계의 더하기 아이콘 을 클릭하고 출력 추가를 선택합니다.
- 출력을 다른 형식으로 저장 드롭다운 목록에서 CRM Analytics를 선택합니다.

- 데이터 집합 섹션에서 Salesforce에 연결합니다.
Salesforce에 로그인하고 Allow(허용)을 클릭하여 Tableau에 CRM Analytics 앱 및 데이터 집합에 대한 액세스 권한을 부여하거나 기존 Salesforce 연결을 선택합니다.
- Name(이름) 필드에서 기존 데이터 집합 이름을 선택합니다. 이렇게 하면 데이터 집합이 덮어써지고 흐름 출력으로 바뀝니다. 그렇지 않으면 새 이름을 입력하고 Create new dataset(새 데이터 집합 만들기)를 클릭하여 선택한 CRM Analytics 앱에 새 데이터 집합을 만듭니다.
참고: 데이터 집합 이름은 80자를 초과할 수 없습니다.

- Name(이름) 필드 아래에서 표시된 앱이 쓰기 권한이 있는 앱인지 확인합니다.
앱을 변경하려면 Browse Datasets(데이터 집합 찾아보기)를 클릭한 다음 목록에서 App(앱)을 선택하고 Name(이름) 필드에 데이터 집합 이름을 입력한 다음 Accept(수락)를 클릭합니다.

- Write Options(쓰기 옵션) 섹션에서 Full refresh(전체 새로 고침) 및 Create table(테이블 만들기)만이 지원됩니다.
- 흐름 실행을 클릭하여 흐름을 실행하고 CRM Analytics 데이터 집합에 데이터를 기록합니다.
흐름 실행에 성공하면 데이터 관리자의 Monitor(모니터) 탭에서 CRM Analytics의 출력 결과를 확인할 수 있습니다. 이 기능에 대한 자세한 내용은 Salesforce 도움말의 외부 데이터 로드 모니터링(영문)(링크가 새 창에서 열림)을 참조하십시오.
흐름 출력 데이터를 Data Cloud에 저장
버전 2023.3부터 Tableau Prep Builder와 웹에서 지원됩니다.
Tableau Prep을 사용하여 데이터를 준비한 다음 데이터를 Data Cloud의 기존 데이터 집합에 연결합니다. Tableau Prep Builder 또는 웹 기반 Tableau Prep이 지원하는 커넥터를 사용하여 데이터를 가져오고, 데이터를 정리 및 준비한 다음, 수집 API를 사용하여 흐름 데이터를 Data Cloud에 직접 출력할 수 있습니다.
사용 권한 필수 요건
Salesforce 라이선스 | Data Cloud 버전 및 Add-on 라이선스에 대한 자세한 내용은 Salesforce 도움말에서 Data Cloud Standard Edition 및 라이선스(영문)를 참조하십시오. 또한 Data Cloud 제한 및 지침을 참조하십시오. |
| 데이터 공간 사용 권한 | 데이터 공간에 할당되어야 하며 Data Cloud에서 다음 사용 권한 집합 중 하나에 할당되어야 합니다.
자세한 내용은 데이터 공간 관리(영문)(링크가 새 창에서 열림) 및 기존 사용 권한 집합으로 데이터 공간 관리(영문)(링크가 새 창에서 열림)를 참조하십시오. |
Data Cloud에 수집 사용 권한 | Data Cloud에 수집을 위한 필드 액세스를 위해서는 다음에 할당되어야 합니다.
자세한 내용은 개체 및 필드 권한 활성화를 참조하십시오. |
| Salesforce 프로필 | 다음에 대해 프로필 액세스를 사용하도록 설정합니다.
|
| Tableau Prep 라이선스 및 사용 권한 | Creator 라이선스. Creator는 Salesforce org 계정에 로그인하고 인증해야 흐름 데이터를 출력할 앱 및 데이터 집합을 선택할 수 있습니다. |
흐름 데이터를 Data Cloud에 저장
이미 수집 API를 사용하고 있고 API를 수동으로 호출하여 데이터 집합을 Data Cloud에 저장하고 있다면 Tableau Prep을 사용하여 해당 워크플로우를 단순화할 수 있습니다. 필수 구성은 Tableau Prep과 동일합니다.
Data Cloud에 데이터를 처음 저장하는 경우 Data Cloud 설정 필수 요건의 설정 요구 사항을 따르십시오.
- 단계의 더하기 아이콘 을 클릭하고 출력 추가를 선택합니다.
- 출력을 다른 형식으로 저장 드롭다운 목록에서 Salesforce Data Cloud를 선택합니다.
- 개체 섹션에서 로그인할 Salesforce Data Cloud 조직을 선택합니다.

- Salesforce Data Cloud 메뉴에서 로그인을 클릭합니다.
- 사용자 이름 및 비밀번호를 사용하여 Data Cloud 조직에 로그인합니다.
- 액세스 허용 양식에서 허용을 클릭합니다.
- '출력을 다른 형식으로 저장' 섹션에서 수집 API 커넥터와 개체 이름을 입력합니다.
- 수집 API 커넥터 이름과 해당 개체 이름을 찾으려면, 다음을 수행하십시오.
Salesforce Data Cloud에 로그인하고 Data Cloud Setup(Data Cloud 설정)으로 이동합니다.
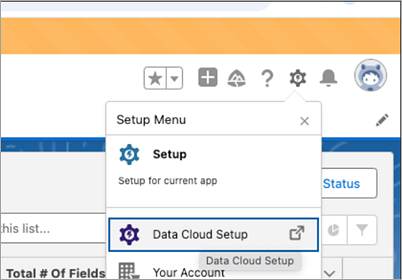
Quick Find(빠른 찾기) 상자에 Ingestion API를 입력한 다음 결과에서 Ingestion API(수집 API)를 선택합니다.
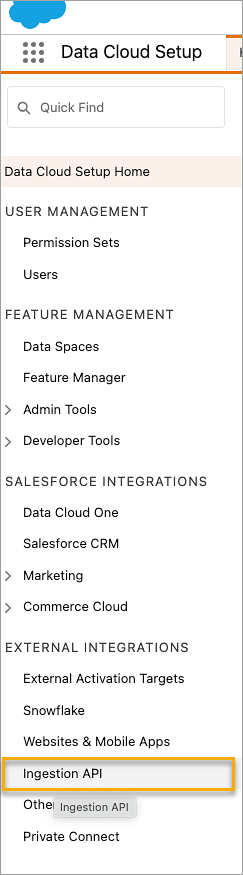
Ingestion API(수집 API) 페이지에서 사용 가능한 커넥터가 Connector Name(커넥터 이름) 아래에 나열되어 있습니다.
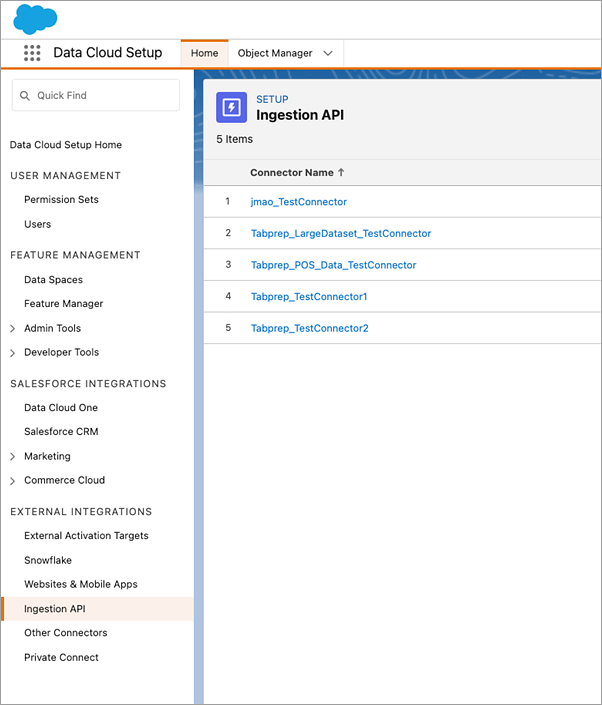
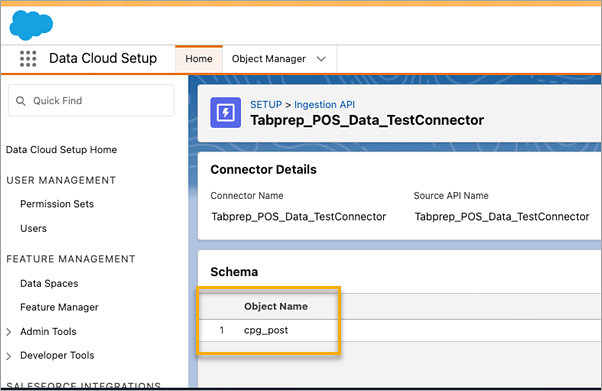
사용하려는 커넥터에 해당하는 Object Name(개체 이름)을 찾으려면 목록에서 커넥터를 선택합니다. Schema(스키마) 섹션 아래의 Connector Details(커넥터 세부 정보) 페이지에서 Object Name(개체 이름) 아래에 해당 개체가 나열됩니다.
- 쓰기 옵션 섹션은 지정된 값이 테이블에 이미 존재하는 경우 기존 행이 업데이트되고 지정된 값이 아직 존재하지 않는 경우 새 행이 삽입됨을 나타냅니다.
- 흐름 실행을 클릭하여 흐름을 실행하고 데이터를 Data Cloud에 씁니다.
- 데이터 스트림의 실행 상태와 데이터 탐색기의 개체를 확인하여 Data Cloud에서 데이터의 유효성을 확인합니다.

브라우저 창이 https://login.salesforce.com/으로 열립니다.



고려 사항
- 한 번에 한 흐름만 실행 수 있습니다. 다른 저장 출력을 실행하려면 먼저 Data Cloud에서 실행을 완료해야 합니다.
- Data Cloud에 흐름을 저장하는 작업을 완료하는 데 다소 시간이 걸릴 수 있습니다. Data Cloud에서 상태를 확인하십시오.
- 데이터는 Upsert 함수를 사용하여 Data Cloud에 저장됩니다. 파일의 레코드가 기존 레코드와 일치하면 기존 레코드가 데이터의 값으로 업데이트됩니다. 일치하는 항목이 없으면 레코드가 새 엔터티로 생성됩니다.
- Prep Conductor의 경우 동일한 흐름이 자동으로 실행되도록 예약하면 데이터가 업데이트되지 않습니다. 이는 Upsert만 지원되기 때문입니다.
- Data Cloud에 저장하는 프로세스 중에는 작업을 중단할 수 없습니다.
- Data Cloud에 저장된 필드의 유효성은 검증되지 않습니다. Data Cloud에서 데이터의 유효성을 검증하십시오.
Data Cloud 설정 필수 요건
다음 단계는 Tableau Prep 흐름을 Data Cloud에 저장하기 위한 필수 요건입니다. Data Cloud 개념 및 Tableau 데이터 원본과 Data Cloud 간의 데이터 매핑에 대한 자세한 내용은 Salesforce Data Cloud 정보를 참조하십시오.
수집 API 커넥터 설정
.yaml 파일 확장명이 있는 OAS(OpenAPI) 형식의 스키마 파일을 업로드하여 원본 개체에서 수집 API 데이터 스트림을 생성합니다. 스키마 파일은 웹 사이트에서 데이터가 구성되는 방식을 설명합니다. 자세한 내용은 YAML 파일 예 및 수집 API를 참조하십시오.
- 설정 기어 아이콘을 클릭한 다음 Data Cloud 설정을 클릭합니다.
- 수집 API를 클릭합니다.
- 새로 만들기를 클릭하고 커넥터 이름을 제공합니다.
- 새 커넥터의 세부 정보 페이지에서
.yaml파일 확장명이 있는 OpenAPI(OAS) 형식의 스키마 파일을 업로드합니다. 스키마 파일은 API를 통해 전송된 데이터의 구조 방식을 설명합니다. - 스키마 미리 보기 양식에서 저장을 클릭합니다.
참고: 수집 API 스키마에는 요구 사항이 설정되어 있습니다. 수집 이전에 스키마 요구 사항을 확인하십시오.
데이터 스트림 만들기
데이터 스트림은 Data Cloud로 가져오는 데이터 원본입니다. 이는 연결 및 Data Cloud로 수집된 관련 데이터로 구성됩니다.
- 앱 실행기로 이동하고 Data Cloud를 선택합니다.
- 데이터 스트림 탭을 클릭합니다.
- 새로 만들기를 클릭하고 수집 API를 선택한 후 다음을 클릭합니다.
- 수집 API 및 개체를 선택합니다.
- 데이터 공간, 범주, 기본 키를 선택한 후 다음을 클릭합니다.
- 배포를 클릭합니다.
Data Cloud에는 실제 기본 키를 사용해야 합니다. 존재하지 않는 경우 기본 키에 대한 수식 필드를 만들어야 합니다.
범주의 경우 Profile(프로필), Engagement(참여) 또는 Other(기타) 중에서 선택합니다. engagement 범주의 개체에는 날짜/시간 필드가 있어야 합니다. profile 유형이나 other 유형의 개체에는 이와 동일한 요구 사항이 적용되지 않습니다. 자세한 내용은 범주 및 기본 키를 참조하십시오.
이제 데이터 스트림과 데이터 레이크 개체가 있습니다. 이제 데이터 스트림을 데이터 공간에 추가할 수 있습니다.

데이터 공간에 데이터 스트림 추가
원본에서 Data Cloud로 데이터를 가져올 때 필터 유무에 관계없이 DLO(데이터 레이크 개체)를 관련 데이터 공간에 연결합니다.
- 데이터 공간 탭을 클릭합니다.
- 기본 데이터 공간 또는 할당받은 데이터 공간의 이름을 선택합니다.
- 데이터 추가를 클릭합니다.
- 만든 데이터 레이크 개체를 선택하고 다음을 클릭합니다.
- (선택 사항) 개체에 대한 필터를 선택합니다.
- 저장을 클릭합니다.

데이터 레이크 개체를 Salesforce 개체에 매핑
데이터 매핑은 데이터 레이크 개체 필드를 DMO(데이터 모델 개체) 필드와 연결합니다.
- 데이터 스트림 탭으로 이동하고 만든 데이터 스트림을 선택합니다.

- 데이터 매핑 섹션에서 시작을 클릭합니다.
필드 매핑 캔버스는 왼쪽에 원본 DLO를 표시하고 오른쪽에 대상 DMO를 표시합니다. 자세한 내용은 데이터 모델 개체 매핑을 참조하십시오.
외부 클라이언트 앱 또는 Data Cloud 수집 API용 연결된 앱 만들기
수집 API를 사용하여 Data Cloud로 데이터를 보내려면 먼저 외부 클라이언트 앱을 사용하거나(권장) 연결된 앱을 사용하도록(사용 중단) Salesforce를 구성해야 합니다. 자세한 내용은 Salesforce 도움말에서 다음을 참조하십시오.
외부 클라이언트 앱의 경우: 외부 클라이언트 앱 OAuth 설정 구성(영문)(링크가 새 창에서 열림) 및 외부 클라이언트 앱 만들기(영문)(링크가 새 창에서 열림)
연결된 앱의 경우: API 통합에 OAuth 설정 사용(영문) 및 Data Cloud 수집 API용 연결된 앱 만들기(영문)
외부 클라이언트 앱 또는 수집 API용 연결된 앱을 설정하는 과정에서 다음 OAuth 범위를 선택해야 합니다.
- Data Cloud 수집 API 데이터 액세스 및 관리(cdp_ingest_api)
- Data Cloud 프로필 데이터 관리(cdp_profile_api)
- Data Cloud 데이터에서 ANSI SQL 쿼리 수행(cdp_query_api)
- API를 통해 사용자 데이터 관리(api)
- 언제든지 자동으로 요청(refresh_token, offline_access)
스키마 요구 사항
Data Cloud에서 수집 API 원본을 만들려면 업로드하는 스키마 파일이 특정 요구 사항을 충족해야 합니다. 수집 API 스키마 파일 요구 사항을 참조하십시오.
- 업로드된 스키마는 확장명이 .yml 또는 .yaml인 유효한 OpenAPI 형식이어야 합니다. OpenAPI 버전 3.0.x가 지원됩니다.
- 개체에 중첩된 개체가 있을 수 없습니다.
- 각 스키마에는 하나 이상의 개체가 있어야 합니다. 각 개체에는 하나 이상의 필드가 있어야 합니다.
- 개체에 있는 필드는 1000개를 초과할 수 없습니다.
- 개체는 80자를 초과할 수 없습니다.
- 개체 이름에는 a-z, A-Z, 0-9, _, -만 포함되어야 합니다. 유니코드 문자는 안 됩니다.
- 필드명에는 a-z, A-Z, 0-9, _, -만 포함되어야 합니다. 유니코드 문자는 안 됩니다.
- 필드명에 예약어, 즉 date_id, location_id, dat_account_currency, dat_exchange_rate, pacing_period, pacing_end_date, row_count, version을 사용할 수 없습니다. 필드명에 문자열 __을 포함할 수 없습니다.
- 필드명은 80자를 초과할 수 없습니다.
- 필드는 다음 유형과 형식을 충족해야 합니다.
- 텍스트 또는 부울 유형의 경우: 문자열
- 숫자 유형의 경우: 숫자
- 날짜 유형의 경우: 문자열, 형식: 날짜/시간
- 개체 이름은 중복될 수 없으며, 대/소문자를 구분하지 않습니다.
- 개체에는 중복된 필드명이 있을 수 없으며, 개체는 대/소문자를 구분하지 않습니다.
- 페이로드의 날짜/시간 데이터 유형 필드는 yyyy-MM-dd'T'HH:mm:ss.SSS'Z' 형식의 ISO 8601 UTC Zulu여야 합니다.
스키마를 업데이트할 때 다음 사항에 유의하십시오.
- 기존 필드 데이터 유형을 변경할 수 없습니다.
- 개체를 업데이트할 때 해당 개체에 대한 모든 기존 필드가 존재해야 합니다.
- 업데이트된 스키마 파일에는 변경된 개체만 포함되므로 매번 개체의 전체 목록을 제공할 필요가 없습니다.
- engagement 범주의 개체에는 날짜/시간 필드가 있어야 합니다.
profile유형이나other유형의 개체에는 이와 동일한 요구 사항이 적용되지 않습니다.
YAML 파일 예
openapi: 3.0.3
components:
schemas:
owner:
type: object
required:
- id
- name
- region
- createddate
properties:
id:
type: integer
format: int64
name:
type: string
maxLength: 50
region:
type: string
maxLength: 50
createddate:
type: string
format: date-time
car:
type: object
required:
- car_id
- color
- createddate
properties:
car_id:
type: integer
format: int64
color:
type: string
maxLength: 50
createddate:
type: string
format: date-time 흐름 출력 데이터를 Amazon S3에 저장
Tableau Prep Builder 2024.2 이상과 웹 작성 및 Tableau Cloud에서 사용할 수 있습니다. 이 기능은 아직 Tableau Server에서 사용할 수 없습니다.
Tableau Prep Builder 또는 웹이 지원하는 모든 커넥터의 데이터에 연결하고 흐름 출력을 Amazon S3에 .parquet 또는 .csv 파일로 저장할 수 있습니다. 출력을 새 데이터로 저장하거나 기존 S3 데이터를 덮어쓸 수 있습니다. 데이터 손실을 방지하려면 흐름 데이터를 S3에 저장하기 전에 사용자 지정 SQL 옵션을 사용하여 테이블 데이터의 복사본을 만들고 실행하면 됩니다.
흐름 출력을 저장하는 것과 S3 커넥터에 연결하는 것은 서로 독립적입니다. Tableau Prep 입력 연결로 사용한 기존 S3 연결은 재사용할 수 없습니다.
Amazon S3에 저장할 수 있는 총 데이터 볼륨과 개체 수에는 제한이 없습니다. 개별 Amazon S3 개체의 크기는 최소 0바이트에서 최대 5TB까지 가능합니다. 단일 PUT에 업로드할 수 있는 가장 큰 개체는 5GB입니다. 100MB보다 큰 개체의 경우 고객은 멀티파트 업로드 기능 사용을 고려해야 합니다. 멀티파트 업로드를 사용하여 개체 업로드 및 복사를 참조하십시오.
사용 권한
Amazon S3 버킷에 쓰려면 버킷 리전, 버킷 이름, 액세스 키 ID 및 보안 액세스 키가 필요합니다. 이러한 키를 얻으려면 AWS 내에서 IAM(Identity and Access Management) 사용자를 생성해야 합니다. IAM 사용자용 액세스 키 관리를 참조하십시오.
흐름 데이터를 Amazon S3에 저장
- 단계의 더하기 아이콘 을 클릭하고 출력 추가를 선택합니다.
- '출력을 다른 형식으로 저장' 드롭다운 목록에서 데이터베이스 및 클라우드 저장소를 선택합니다.
- 테이블 > 연결 섹션에서 Amazon S3(출력 전용)을 선택합니다.
- Amazon S3(출력 전용) 양식에 다음 정보를 추가합니다.
- 액세스 키 ID: Amazon S3에 보내는 요청에 서명하는 데 사용한 키 ID입니다.
- 암호 액세스 키: AWS 리소스에 액세스할 수 있는 권한이 있는지 확인하는 데 사용되는 보안 자격 증명(암호, 액세스 키)입니다.
- 버킷 지역: Amazon S3 버킷 위치(AWS 리전 끝점)입니다. 예를 들어 us-east-2입니다.
- 버킷 이름: 흐름 출력을 쓰려는 S3 버킷의 이름입니다. 동일한 리전에 있는 두 AWS 계정의 버킷 이름은 같을 수 없습니다.
참고: S3 리전과 버킷 이름을 찾으려면 AWS S3 계정에 로그인하고 AWS S3 콘솔로 이동하십시오.
- 로그인을 클릭합니다.
- S3 URI 필드에
.csv또는.parquet파일 이름을 입력합니다. 기본적으로 필드는s3://<your_bucket_name>으로 채워집니다. 파일 이름에는.csv또는.parquet.확장명이 포함되어야 합니다.흐름 출력을 새 S3 개체로 저장하거나 기존 S3 개체를 덮어쓸 수 있습니다.
- 새 S3 개체의 경우 이름을
.parquet또는.csv파일에 입력합니다. URI는 미리 보기 텍스트에 표시됩니다. 예:s3://<bucket_name><name_file.csv>. - 기존 S3 개체를 덮어쓰려면
.parquet또는.csv파일의 이름을 입력하거나 찾아보기를 클릭하여 기존 S3.parquet또는.csv파일을 찾습니다.참고: 개체 찾아보기 창에는 이전에 Amazon S3에 로그인하여 저장한 파일만 표시됩니다.
- 새 S3 개체의 경우 이름을
- 쓰기 옵션의 경우 흐름의 데이터를 사용하여 새 S3 개체가 생성됩니다. 데이터가 이미 있는 경우 개체에 정의된 기존 데이터 구조 또는 속성이 삭제되고 새 흐름 데이터로 바뀝니다. 흐름에 있는 모든 필드가 새 S3 개체에 추가됩니다.
- 흐름 실행을 클릭하여 흐름을 실행하고 데이터를 S3에 씁니다.
AWS S3 계정에 로그인하고 AWS S3 콘솔로 이동하면 데이터가 S3에 저장되었는지 확인할 수 있습니다.