Data Connect について
2025 年 9 月の時点で、新しい展開で Tableau Data Connect を利用することができなくなりました。既存のお客様は、Data Connect 展開を プライベート接続(新しいウィンドウでリンクが開く)または Tableau Bridge(新しいウィンドウでリンクが開く)に移行することをお勧めします。Data Connect は今後廃止される予定です。
Data Connect を使用すると、Tableau Cloud ユーザーはプライベート ネットワークまたはクラウド サービス上のデータ ソースにアクセスできます。Data Connect は責任共有モデルでとして機能します。このモデルでは、お客様が物理的または仮想的コンピューティング リソースを提供し、Tableau がそれらのリソース上で Data Connect Kubernetes クラスターをホストおよび管理します。
お使いの環境では、Data Connect Kubernetes クラスターが一連のコンテナを監視します。コンテナは、1 つまたは複数の Bridge クライアントで構成されるランタイム環境をサポートします。Bridge クライアントは、タスクを実行したり、組織間でファイアウォールを介して安全に通信できるようにしたりするプログラムです。
Data Connect サービスには以下が含まれます。
-
クラスターの監視とトラブルシューティング: Tableau は、Bridge クライアントの状態と使用状況を監視します。リソースが最も効果的かつ効率的に使用されるようにするために、テレメトリ データを収集します。
-
クラスターのメンテナンス: アップグレードは自動的に展開され、クラスターの操作とメンテナンスについては、Tableau が所有者として完全に実行します。Data Connect は、ニーズと利用可能なコンピューティング プールに基づいて、ワークロードの展開を自動的に最適化します。
-
アラート監視: 問題を迅速に解決してビジネスへの影響を抑えるために、インシデント管理が継続的に提供されます。
コネクタのサポート
Data Connect は、Tableau Bridge for Linux でサポートされているのと同じコネクタをサポートします。接続オプションの詳細については、「Bridge を使用した接続」を参照してください。
環境のサポート
現在、Data Connect はオンプレミス環境と VCP 環境 (Amazon Web Services (AWS)、Microsoft Azure、Google Cloud Platform (GCP)) をサポートしています。Data Connect ノードは、単一の Tableau Cloud サイトと互換性があります。ノードはデータと同じネットワークにインストールする必要があります。そのため、サービスの可用性を維持するために、お客様はプライベート ネットワークごとに少なくとも 3 つのノードを計画する必要があります。Data Connect ノードは Data Connect 専用にする必要があります。Tableau が所有するクラスターに他のコンテナを展開することはできません。また、既存のクラスターを Data Connect に使用することはできません。
アーキテクチャ
Data Connect アーキテクチャは、3 つの主要コンポーネントと責任境界で構成されます。一部は重複しますが、Tableau は主にアプリケーション層とオーケストレーション層に責任を持ち、お客様はインフラ (コンピューティング、OS、ネットワーク、ストレージ) とその配置場所に責任を持ちます。
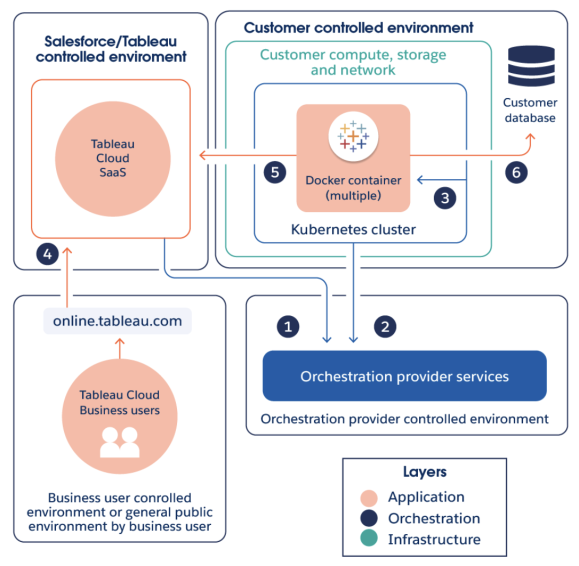
-
Tableau Cloud は Kubernetes オーケストレーション サービスと通信して、Kubernetes オーケストレーションを展開、監視、管理します。
-
Data Connect を開始すると、ポート 443 を介してオーケストレーション プロバイダー サービスとの安全な接続が確立されます。
-
サービスが構成されると、Kubernetes クラスターは Bridge クライアントを使用して コンテナを展開します。これらの Bridge クライアントは、Tableau ワークロードの実行を担当します。
-
Tableau Cloud ユーザーは Tableau Cloud にサインインして、Data Connect サービスとやり取りします。
-
Bridge クライアントはセットアップ時に、HTTPS を使用して、Tableau Cloud との接続を開始します。接続が成功すると、Bridge クライアントは、WebSocket (wss://) 接続を使用して、Tableau Cloud 環境との安全な双方向通信を開始します。
-
Tableau Cloud から開始されたクエリは、エンド ユーザーの分析をサポートするために、データベースに対して実行されます。
セキュリティ
「Data Connect のセキュリティ」を参照してください。
データ接続のコンポーネント

Data Connect ソリューションの主なコンポーネントはクラスターです。クラスターは、1 つ以上のノードで構成される Kubernetes クラスターです。各 Kubernetes ノードは少なくとも 1 つのコンテナをホストし、そのコンテナは Bridge クライアントをホストします。Bridge クライアントはライブ クエリと抽出クエリを実行します。
プールは、特定のクエリを完了するクラスターを指定するネットワーク ルールの論理グループです。展開計画のコンテキストでは、プールは負荷分散を目的としてエンドポイント (ドメインまたは IP アドレス) のコレクションをホストします。ドメインには、プライベート クラウド データ、リレーショナル データ、ファイル データなどが含まれます。
クラスターがデータ ソースにアクセスして更新できるようにするために、各プールがクラスターに割り当てられます。負荷を分散するために、クラスターに複数のプールを追加できます。
展開の概要

開始するには、各 Linux サーバーでスクリプトを実行します。このスクリプトは、環境内に Tableau によって管理される Kubernetes クラスターを構成します。Kubernetes クラスターは Tableau によって管理されます。
Kubernetes が構成されたら、Docker コンテナをクラスターに展開します。その後、Tableau はコンテナ内に Bridge クライアントを展開し、リモートで管理します。Tableau でこの構成が確立されたら、プライベート ネットワーク データ ソースに接続をマッピングします。
Data Connect の導入については、ホワイトペーパー「Tableau Cloud でプライベート ネットワーク データにアクセスする - Data Connect と Tableau Bridge のベスト プラクティス(新しいウィンドウでリンクが開く)」(英語) をダウンロードしてください。
データベース接続
クエリはクラスター内の Bridge クライアントから管理されます。データは、Bridge クライアントから Tableau Cloud に直接送信されます。Data Connect では、外部ネットワーク アクセス、ファイアウォール ホール、またはリモート マシン アクセスは必要ありません。

-
Bridge クライアントが、安全な WebSocket (wss://) を使用して Tableau Cloud Data Connect サービスへの永続的な接続を確立します。クライアントが Tableau Cloud からの要求を待ちます。
-
- ライブ接続または仮想接続を使用したデータ ソースの場合、Tableau Cloud が Bridge クライアントへのクエリを開始します。
- 更新スケジュールを使用する抽出接続を持つデータ ソースの場合、クライアントが更新スケジュールの要求を受信し、 データ ソース (.tds) ファイルへの安全な接続 (https://) を使用して、Tableau Cloud に接触します。
-
Bridge クライアントは、ジョブ要求に含まれている認証資格情報を使用してプライベート ネットワーク データに接続します。
-
データベースがクエリの結果を返します。
-
Bridge クライアントはペイロードを受信し、それを Data Connect サービスに返します。