Scelta dei predittori
Quando si creano calcoli di previsione utilizzando le funzioni di modellazione predittiva in Tableau, è necessario scegliere i predittori. Un predittore è una variabile di input il cui valore viene utilizzato per prevedere una variabile di risultato, anche nota come obiettivo o risposta. Spesso utilizzerai dati di cui hai una conoscenza approfondita e avrai già un’idea chiara di quali campi sono strettamente correlati con il tuo obiettivo di previsione, in modo da creare predittori efficaci. È comunque consigliabile prendersi del tempo per valutare i predittori e assicurarsi di sceglierli con attenzione. È sempre necessario includere almeno un predittore (e in genere più di uno).
Innanzitutto, seleziona l’obiettivo. Può sembrare ovvio, ma assicurarsi di selezionare i predittori in base a ciò che si desidera prevedere è un primo passo di importanza critica. Ad esempio, i campi maggiormente correlati all’aspettativa di vita femminile potrebbero essere molto diversi dai campi maggiormente correlati all’aspettativa di vita maschile. Analogamente, i campi maggiormente correlati alle vendite potrebbero essere molto diversi dai campi maggiormente correlati ai profitti.
Un altro elemento da tenere presente è che, per impostazione predefinita, le funzioni di modellazione predittiva utilizzano la regressione lineare come modello statistico sottostante. Con questo modello, i predittori maggiormente correlati sono quelli che hanno una relazione lineare con l’obiettivo. Per informazioni sull’utilizzo di un altro modello supportato, consulta Scelta di un modello predittivo.
Per capire meglio come scegliere i migliori predittori per le domande a cui desideri rispondere, esaminiamo i dati relativi all’aspettativa di vita femminile. Per seguire gli esempi, scarica la seguente cartella di lavoro da Tableau Public: Choosing Predictors for Your Predictions.
Misure come predittori
Quando usi una misura come predittore, puoi valutarne la correlazione con l’obiettivo utilizzando Tableau. Un modo consiste nel creare un grafico a dispersione. Di seguito, viene confrontata l’aspettativa di vita femminile mediana di un paese con numerose altre misure.
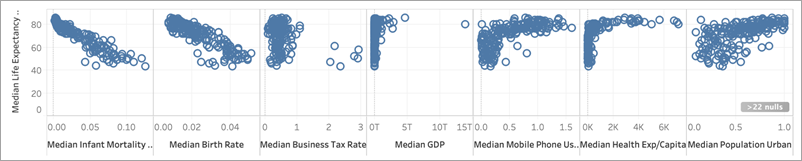
Per alcune misure, come la mortalità infantile e il tasso di natalità, c’è una chiara correlazione negativa con l’aspettativa di vita femminile, com’è possibile notare dalla pendenza negativa del grafico a dispersione. Per altre, è meno chiaro. Tuttavia, un elemento che possiamo vedere chiaramente è una distribuzione a forma di L per il PIL mediano, l’utilizzo del telefono cellulare mediano e la spesa sanitaria pro-capite mediana. Questa distribuzione a forma di L spesso indica che l’utilizzo di una trasformazione logaritmica può consentire di analizzare i dati in modo più accurato. Un altro indicatore è il fatto che tutti i valori di una colonna sono positivi. In Tableau, è possibile utilizzare una trasformazione logaritmica modificando la pillola e racchiudendo l’espressione in una funzione LOG:

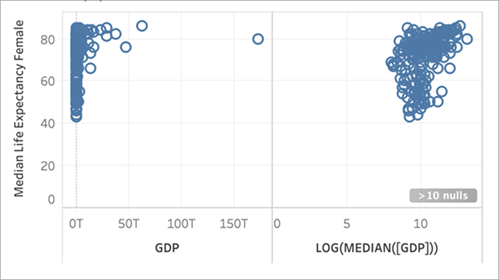
Questo ci porta dalla distribuzione a forma di L, dove è difficile distinguere tra gli estremi della scala, a una distribuzione più uniforme e meno compressa dagli estremi della scala.
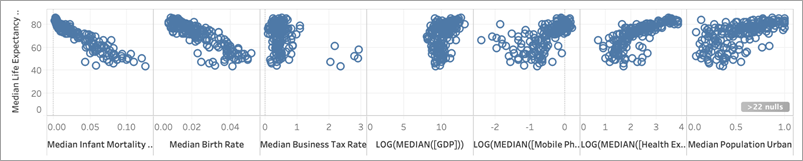
Ripetendo la stessa operazione con le altre distribuzioni a forma di L, otteniamo quanto segue:
Coefficiente di determinazione (o valore R al quadrato)
Più gli indicatori si avvicinano a una linea retta, maggiore è la correlazione tra le due misure. Per facilitare la valutazione della correlazione, puoi aggiungere linee di tendenza. Nel riquadro Analisi, trascina Linea di tendenza nella vista e rilasciala in Lineare. Passando il puntatore sulla linea di tendenza, verrà indicato il valore R al quadrato, o coefficiente di determinazione, che indica quanto la variabile dipendente (l’obiettivo) è spiegata dalla variabile indipendente (il predittore). I predittori con valori R al quadrato più vicini a 1 sono migliori dei predittori con valori R al quadrato più vicini a 0.
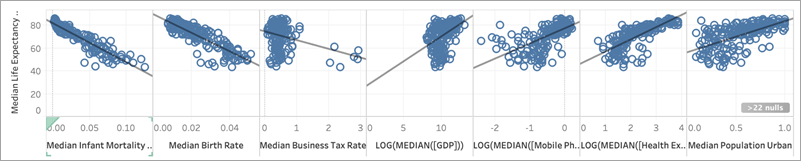
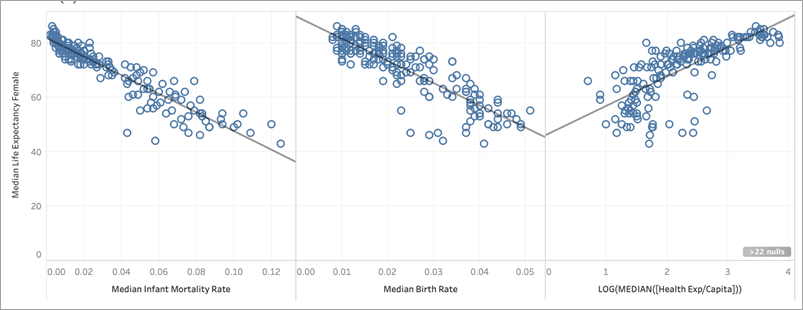
Osservando i nostri grafici a dispersione, possiamo vedere che il miglior predittore per l’aspettativa di vita femminile mediana è la mortalità infantile mediana, che ha un valore R al quadrato di 0,87:
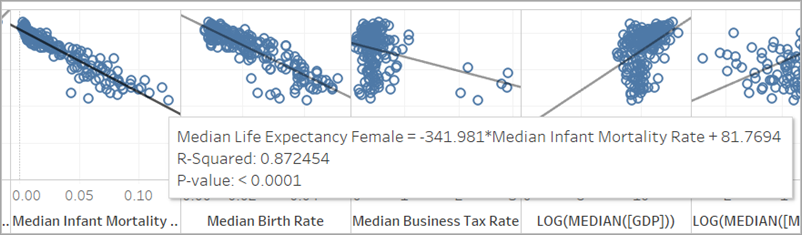
Altri buoni predittori sono il tasso di natalità mediano (R al quadrato: 0,76) e la trasformazione logaritmica della spesa sanitaria pro-capite mediana (R al quadrato: 0,56).
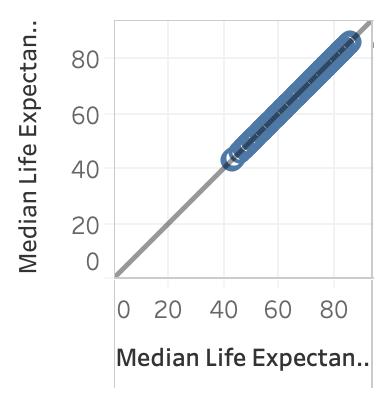
Nell’immagine seguente, abbiamo visualizzato l’aspettativa di vita femminile mediana rispetto all’aspettativa di vita femminile mediana e la visualizzazione risultante è una linea perfettamente retta su un angolo di 45 gradi: come previsto, c’è una perfetta correlazione tra il valore sull’asse x e il valore sull’asse y, con un valore R al quadrato di 1:
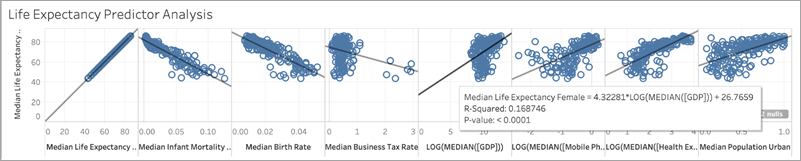
Tuttavia, come mostrato di seguito, anche se LOG(MEDIAN([GDP])) ha una linea di tendenza inclinata più ripidamente rispetto alle altre, il suo punteggio R al quadrato è basso (pari a solo 0,169). Ciò è dovuto alla scala dell’asse x per il riquadro:
Inoltre, vediamo come alcuni indicatori possono influenzare in modo significativo la pendenza di una linea di tendenza. Ingrandendo il grafico a dispersione per l’aliquota fiscale per le imprese mediana possiamo vedere che la maggior parte degli indicatori ha un’aliquota fiscale compresa tra 0 e circa 1, con sei paesi che hanno aliquote molto più elevate, tra 2 e 3. Il valore R al quadrato per tutti gli indicatori è 0,0879:
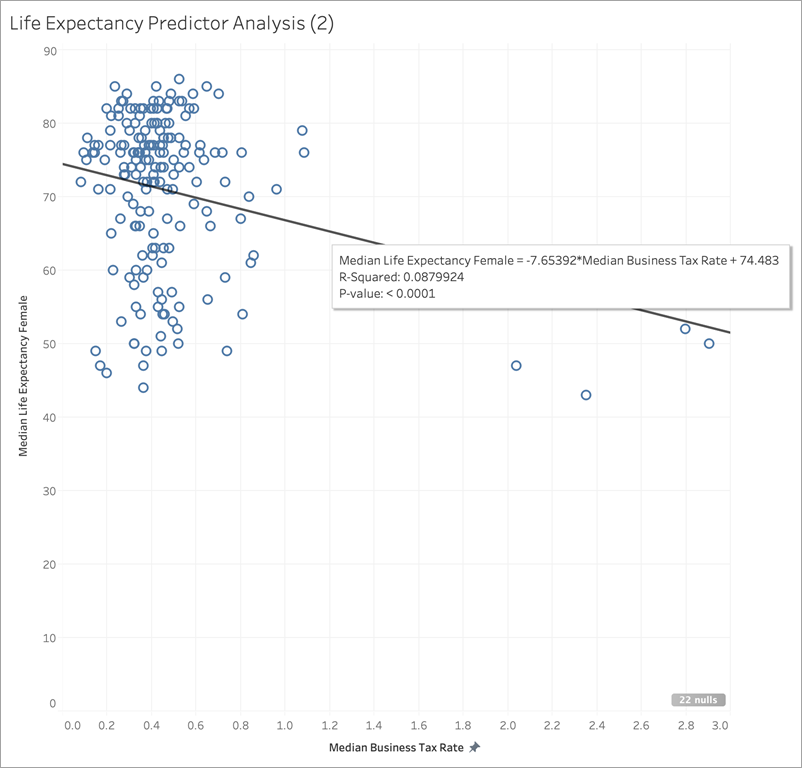
Tuttavia, vediamo cosa succede se rimuoviamo questo gruppo di sei indicatori:
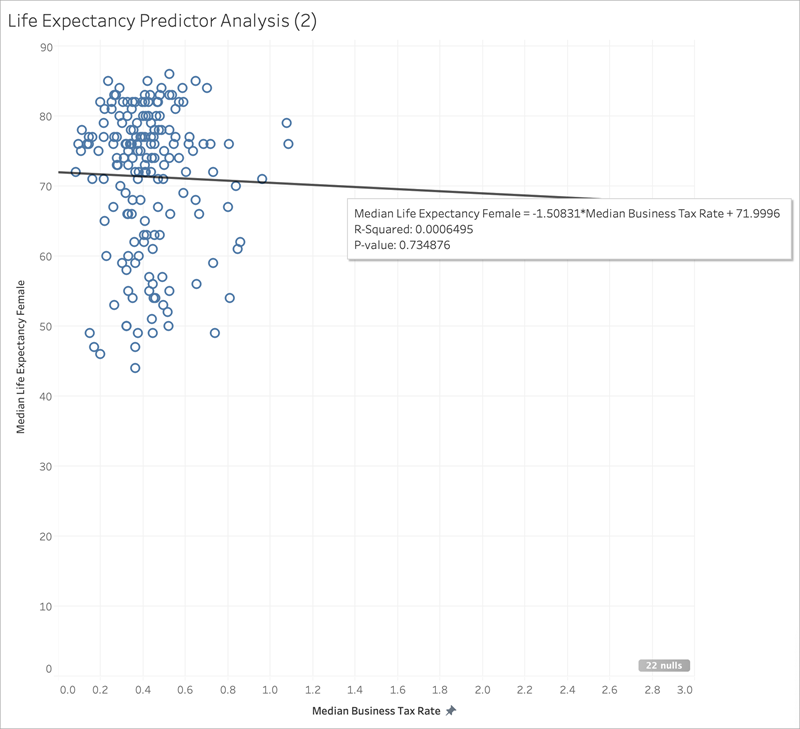
La linea di tendenza diventa quasi piatta e il valore R al quadrato scende a 0,0006, a indicare che non c’è essenzialmente alcuna correlazione tra l’aliquota fiscale per le imprese mediana e l’aspettativa di vita femminile mediana. Quando si visualizzano i dati e si utilizzano efficaci metodi statistici per selezionare i predittori, è importante valutare attentamente se esistono outlier o altre caratteristiche dei dati che potrebbero influire sulle conclusioni.
Dimensioni come predittori
Quando utilizzi dimensioni come predittori, puoi utilizzare una procedura simile per determinare la correlazione. Tuttavia, potresti scoprire che c’è una discrepanza significativa tra le diverse dimensioni nel loro livello di relazione con l’obiettivo. Ad esempio, quando esegui la suddivisione per Regione, una regione può essere un ottimo predittore per l’obiettivo, mentre un’altra può avere una correlazione significativamente inferiore. Ciò non significa che non dovresti usare tale dimensione come predittore, ma è consigliabile considerare se l’uso di misure o dimensioni aggiuntive consentirà di migliorare il modello e, a sua volta, le previsioni.
Dal momento che abbiamo determinato i migliori predittori per il nostro insieme di dati sono la mortalità infantile mediana, il tasso di natalità mediano e la trasformazione logaritmica della spesa sanitaria pro-capite mediana, limitiamo la visualizzazione a queste tre variabili:
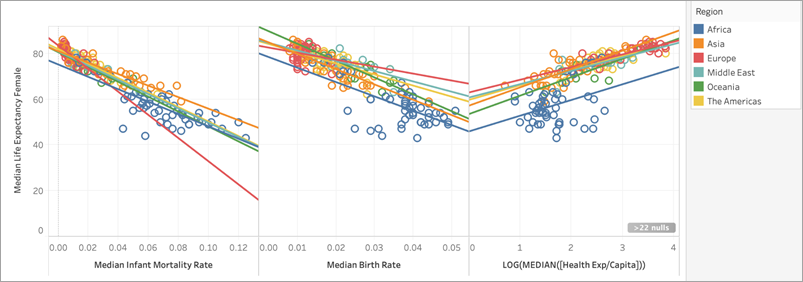
Partizioniamo quindi i dati aggiungendo Regione a Colore nella scheda Indicatori e vediamo cosa succede alla visualizzazione:
Confronto dei valori R al quadrato tra predittori
Esaminiamo il confronto dei valori R al quadrato per ciascuna delle linee di tendenza Regione per ogni predittore:
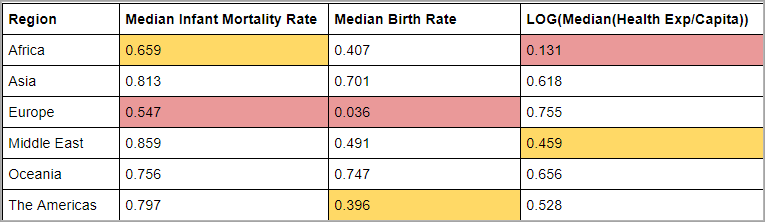
Nella tabella precedente, il valore R al quadrato più basso per ogni predittore è evidenziato in rosso e il secondo più basso in giallo.
L’Europa ha i valori R al quadrato più bassi per la mortalità infantile mediana e il tasso di natalità mediano, mentre l’Africa ha il valore R al quadrato più basso per la trasformazione logaritmica della spesa sanitaria pro-capite mediana (evidenziata in rosso). L’Africa ha anche valori R al quadrato più bassi sia per il tasso di mortalità infantile mediano che per il tasso di natalità mediano.
L’aggiunta di una dimensione può fornire al modello ulteriori informazioni e l’aggiunta di ulteriori informazioni può migliorare la qualità della previsione. Tuttavia, all’interno di una determinata suddivisione (una regione, in questo caso), la qualità della previsione potrebbe migliorare o diminuire. In alcuni casi, può essere utile creare un singolo modello per ogni suddivisione in base alle misure che rappresentano i migliori predittori per il gruppo specifico.
In questo caso, la mortalità infantile ha una correlazione ragionevolmente forte con l’aspettativa di vita femminile per tutte le regioni (anche se è un po' più debole in Africa e in Europa), il tasso di natalità mediano è un buon predittore per l’Oceania e l’Asia, ma non ha quasi alcuna correlazione con l’aspettativa di vita femminile in Europa e la trasformazione logaritmica della spesa sanitaria mediana è un predittore ragionevole per tutte le regioni tranne l’Africa. Possiamo aspettarci che il modello creato con tutti e quattro i predittori (mortalità infantile, tasso di natalità, trasformazione logaritmica della spesa sanitaria e regione) avrà le previsioni meno accurate per i paesi in Europa e Africa: potremmo voler analizzare più a fondo i dati per determinare se ci sono predittori aggiuntivi o alternativi che potremmo usare per creare modelli più adatti per l’Europa e l’Africa.
Creazione della funzione di modellazione predittiva
Ora che abbiamo trovato predittori efficaci, possiamo creare e applicare una funzione di modellazione predittiva per vederla in azione.
Apri il menu Analisi nella parte superiore, quindi seleziona Crea campo calcolato.
Nell’editor di calcolo, esegui le seguenti operazioni:
Assegna al calcolo il nome: Quantile_LifeExpFemale_HealthExpend,BirthRate,Mortality,Region
Immetti la seguente formula:
MODEL_QUANTILE(0.5,MEDIAN([Life Expectancy Female]),
LOG(MEDIAN([Health Exp/Capita])),
MEDIAN([Birth Rate]),
MEDIAN([Infant Mortality Rate]),
ATTR([Region]))
Questo calcolo restituirà il valore mediano (0,5) dell’intervallo delle aspettative di vita femminile mediana modellate, in base ai predittori selezionati: spesa sanitaria, tasso di natalità, mortalità infantile e regione.
Costruiamo quindi un grafico a dispersione che mostra sia l’aspettativa di vita femminile mediana effettiva che l’aspettativa di vita femminile mediana prevista:
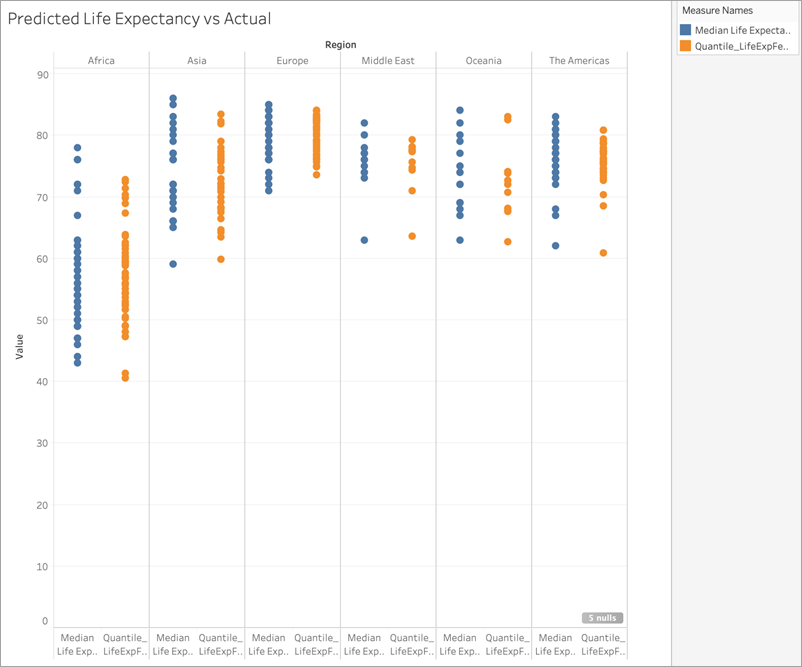
Ben fatto! Le previsioni sono sostanzialmente in linea con i valori effettivi per ogni area.
Eseguiamo un altro passaggio per capire dove le previsioni sono più lontane dall’indicatore. Crea un altro calcolo denominato Residual_LifeExpFemale_HealthExpend,BirthRate,Mortality,Region, come indicato di seguito:
MEDIAN([Life Expectancy Female]) - [Quantile_LifeExpFemale_HealthExpend,BirthRate,Mortality,Region]
Questo calcolo residuo restituirà la differenza tra la mediana prevista e la mediana effettiva, aiutandoci a individuare i paesi in cui è maggiore la discrepanza tra l’aspettativa di vita femminile mediana effettiva e prevista.
Applichiamo quindi questo calcolo residuo a Colore:
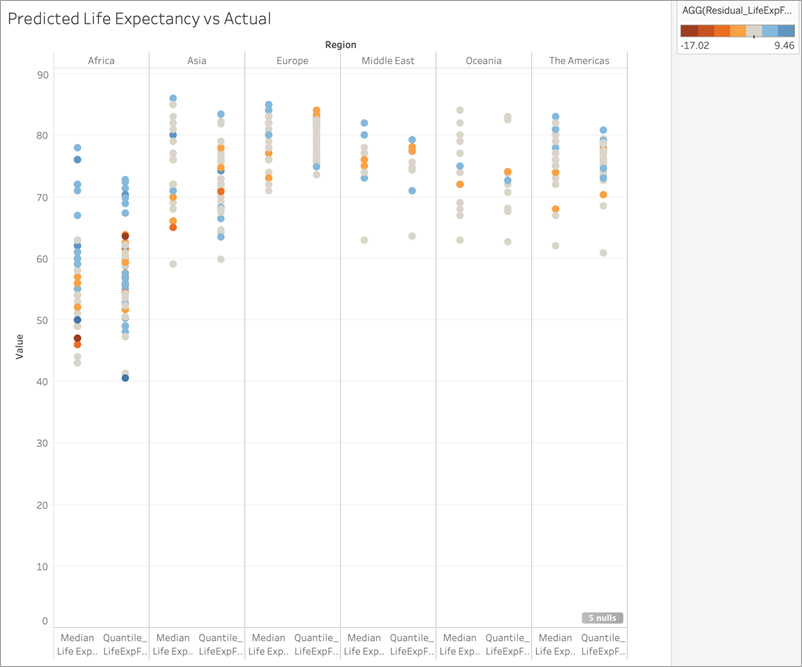
Come puoi osservare nella visualizzazione precedente, la maggior parte dei paesi, nella maggior parte delle regioni, presenta basse discrepanze tra le previsioni e i valori effettivi. L’Africa è la regione con il maggior numero di paesi con discrepanze significative. Eseguiamo un altro passaggio per capire che tipo di differenze stiamo osservando.
Puoi vedere che le differenze variano tra -17 e +9, quindi dividiamo la visualizzazione in gruppi con una differenza inferiore ±3 anni, una differenza inferiore ±5 anni, una differenza inferiore ±10 anni e una differenza superiore ±10 anni.
Crea un altro calcolo denominato Grouped_Residual_LifeExpFemale_HealthExpend,BirthRate,Mortality,Region, come indicato di seguito:
IF [Residual_LifeExpFemale_HealthExpend,BirthRate,Mortality,Region]
<= 3
AND [Residual_LifeExpFemale_HealthExpend,BirthRate,Mortality,Region]
>= -3
THEN
"±3"
ELSEIF
[Residual_LifeExpFemale_HealthExpend,BirthRate,Mortality,Region] <= 5
AND [Residual_LifeExpFemale_HealthExpend,BirthRate,Mortality,Region] >= -5
THEN
"±5"
ELSEIF
[Residual_LifeExpFemale_HealthExpend,BirthRate,Mortality,Region] <= 10
AND [Residual_LifeExpFemale_HealthExpend,BirthRate,Mortality,Region] >= -10
THEN
"±10"
ELSE
"> ±10"
END
Ancora una volta, aggiungiamo il calcolo a Colore:
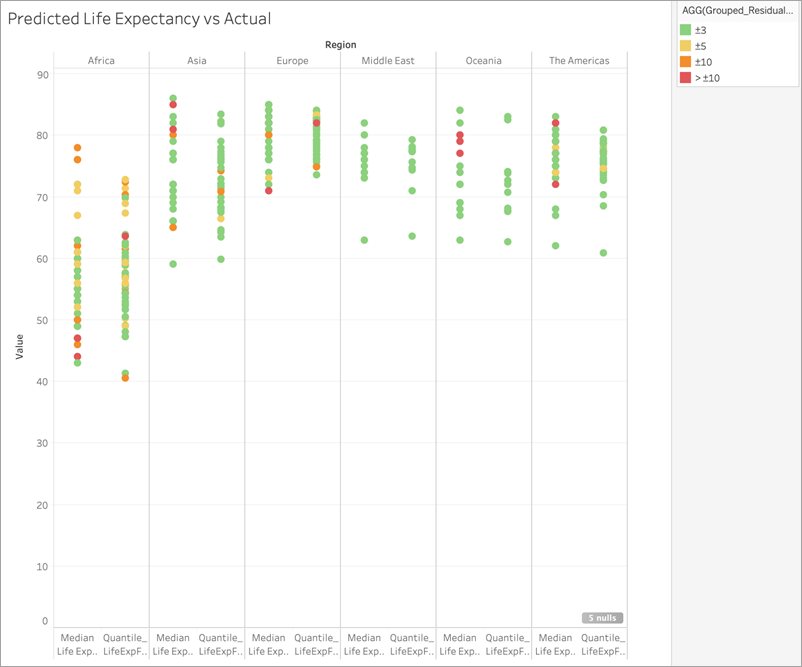
Puoi notare che la stragrande maggioranza delle previsioni non è corretta per meno di 3 anni e che solo molto poche variano per più di 10 anni. Nel complesso, piuttosto buono!
Ciò significa che l’utilizzo di questo modello ci consentirebbe di identificare con precisione i paesi con aspettative di vita femminile mediane che sono outlier oppure di fornire l’aspettativa di vita femminile modellata per un paese in cui questi dati mancavano.