Optimise for Extract Query-Heavy Environments
The topic provides guidance on setting up a specific Tableau Server topology and configurations to help optimise and improve performance in an extract query-heavy environment.
What is an extract query-heavy environment? Extracts and federated data sources are queried while loading workbooks, views and dashboards creating a lot of query workload. Therefore, if you have a lot of extracts and federated data sources, you can be said to have a ‘extract query-heavy environment’.
If your environment is extract query-heavy, as defined above, the next couple of sections can help you decide if this configuration is right for you.
When to use this configuration
Key reasoning behind this configuration: Hyper is Tableau’s memory-optimised Data Engine technology suited for fast data ingests and analytical processing, making it key to optimising query-heavy workloads. As your extract use grows, we recommend configuring Data Engine on dedicated nodes of the Tableau Server cluster. This configuration allows Tableau Server to scale out the infrastructure to optimise performance when querying extracts.
There are several factors that affect Tableau Server performance when viewing content using extracts and federated data sources. The goal here is to achieve consistent and reliable query performance when viewing content on the Server. Use this configuration if one of the following conditions applies to your environment:
You are seeing wide variability in workbook loading times and the workbook uses extracts or federated data sources.
Your Tableau Server deployment is growing in the number of Creators, Explorers, Viewers and extract-based content, so you want to scale out efficiently.
- You are seeing resource contention between Data Engine and VizQL Server when File Store is present on the machine.
You analyse large amounts of data. This configuration helps in optimising performance in big data scenarios, in both data ingestion and analysis. To learn more about Tableau and big data, see Hyper-charge big data analytics using Tableau.
Note: Use Server-side performance recording to determine query execution times. To determine resource usage of Tableau use Performance monitor for Windows installations, and sysstat or vmstat tools for Linux installations.
Benefits of using this configuration
These are the key benefits to configuring dedicated nodes for Data Engine:
Dedicated Data Engine nodes will reduce resource contention between extract queries and other resource-intensive workloads such as those processed by VizQL Server.
- Extract queries are load-balanced dynamically on the dedicated nodes, taking into account the current state of the system to ensure that no one node is over- or under-utilised.
More consistent performance in user experience when loading extract-dependent workbooks. The focus here is to establish a consistent and reliable performance rather than making individual queries better.
You have more control over scaling out Tableau Server processes that need more resources. If VizQL Server, Data Engine and Backgrounder are all running on the same node and slow extract queries are the problem, it will be difficult to see performance improvements by adding a second node with all three processes. With this configuration, you can add more nodes that will specifically improve extract query workloads.
Helps improve availability and up-time. In the event of a failure and one of the dedicated Data Engine nodes being unavailable, VizQL Server will attempt to route the pending requests on the problem node to other dedicated Data Engine nodes.
Data Engine leverages as many cores as available on the machine. Given this, you have the flexibility to add more resources to the dedicated Data Engine nodes to reduce query response time and variability on expensive extract queries or add more dedicated Data Engine nodes to get more extract query throughput in your Server.
Data Engine has a default configuration limiting it to an average 75% of CPU per hour. This is intended to help avoid contention with other Tableau Server processes. If you are running Data Engine on a dedicated node, you can increase this average to 95%. For information on doing this, see hyper.srm_cpu_limit_percentage.
When not to use this configuration
If you are not experiencing issues with extract-based query load, hardware resources may be better allocated to other portions of Tableau Server.
On nodes where File Store, Data Engine and VizQL Server co-exist, you are not seeing resource contention between Data Engine and VizQL Server.
Before implementing this configuration, it is highly recommended that you evaluate your CPU usage for VizQL Server and for the node where Data Engine is installed with the File Store.
Configuration
The main goal of this configuration is to have Data Engine on one or more dedicated nodes.
In deployments where File Store is installed locally, this means configuring File Store on one or more dedicated nodes. Data Engine is automatically installed on the same node as the File Store.
In deployments where you are configuring External File store, you can still configure Data Engine on dedicated nodes on Tableau Server.
By separating VizQL Server and File Store processes, the load between querying extracts and viewing or interacting with views can be balanced and better managed. This configuration is targeted at consistent performance when querying extracts.
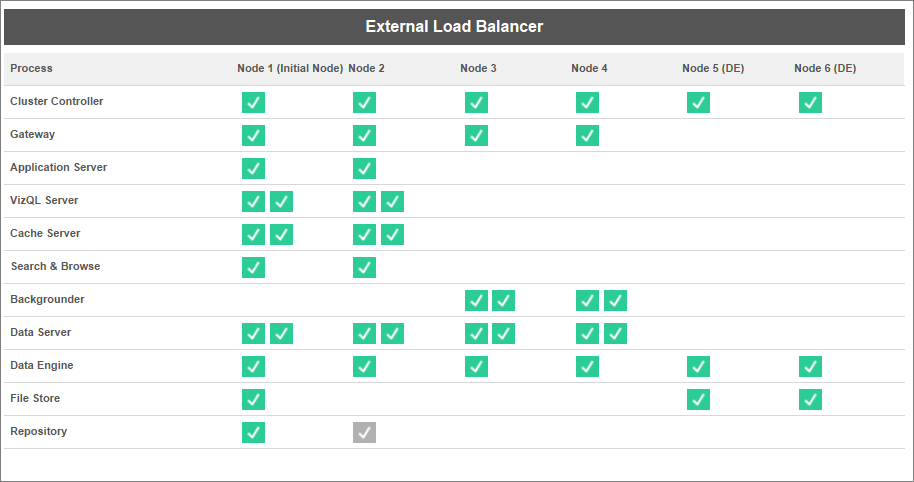
Below is a visual representation of the configuration where the Data Engine/File Store processes have two dedicated nodes, nodes 5 and 6. This is an example where File Store is configured locally, which is why the Data Engine and File Store processes are co-located.
The same configuration works for deployments with External File Store, but Nodes 5 and 6 will only have Data Engine configured in that case.
Additionally, since Node 1 also has the Repository and File Store processes, all of the data needed to perform a backup exist on Node 1, which can improve backup performance.
Hardware Guidance
To get the most out of this configuration, you will need to experiment with various hardware sizes and configurations to see what best fits your peak load performance objectives. Hyper is a high-performance database technology and the key resources that impact performance are memory, cores and storage I/O. Understanding how Hyper uses resources to process queries will help you make your hardware selection and understand the reason between different configurations.
Memory: When an extract-based query is processed for a user or background process, Tableau Server selects a dedicated Data Engine node to process the query. That dedicated Data Engine node will then copy the extract from local storage, most often the server hard disk, into memory. Having more available system memory allows the operating system to better manage memory usage for Tableau. Dedicated Data Engine nodes use system memory to store the result set of executed queries. If the result set is still valid and the operating system has not cleared it from memory, the result set in memory can be reused.
Tableau Server’s minimum hardware recommendation is 32 GB of memory, but if you are expecting a high volume of extract-based workbook loads, you should consider 64 GB or 128 GB. If you are hitting other resource limits in addition to memory (like cores), instead of scaling up to 128 GB of memory, it might be better to scale out to an additional 64 GB dedicated Data Engine node.
The process of copying the extract from local storage into memory can take time, and optimising disk performance may be necessary. Optimising disk performance is covered in the Storage I/O section.
Cores: When processing an extract-based query, the number of cores is an important hardware resource that can impact performance and scalability. CPU cores are responsible for executing a query, and having more available cores will result in faster execution time. Generally speaking, doubling the number of cores will reduce the query execution time in half. For example, a 10-second query currently utilising 4 physical cores or 8 vCPUs, will take 5 seconds if you upgrade to 8 physical cores or 16 vCPUs.
The current Tableau Server minimum hardware recommendation is 8 cores, but if your deployment utilises extracts, consider 16 or 32 core machines. An important thing to note is that if memory and I/O are your bottlenecks, then increasing available cores will not improve your query performance.
- Storage I/O: Hyper is designed to leverage the available performance of your extract storage device to speed up query processing. We recommend picking fast disk storage like Solid State Drives (SSD) with high read/write speeds. Currently, SSDs that utilise NVMe storage protocol offer the fastest available speeds.
Note: Sizing resources for dedicated Data Engine nodes only impacts the extract query performance. When loading a workbook, there are many other processes involved that make up total VizQL load request time. The VizQL Server process, for example, is responsible for taking the data from the Data Engine and rendering the visualisation.
Other Performance Tuning and Optimisations:
There are additional features you can use to optimise performance beyond the basic configuration described above. The optimisations described below are applicable to both local File Store and External File Store deployments.
Extract Query Load Balancing: To determine where to route the extract query, Data Engine uses a server health metric – the amount of resources Data Engine is consuming and the load from other Tableau processes that may be running on the same node. In addition to evaluating system resources, whether an extract already exists in memory on the node is also taken into account to make sure an extract query is sent to the node that has the most available resources to process the query. This results in more efficient memory and disk utilisation, and extracts are not duplicated in memory across nodes. See the Extract Query Load Balancing help article for more details.
The extract query load balancing feature is enabled by default in Tableau Server version 2020.2 and later.
Workload optimisations using node roles: With Backgrounder and File Store node roles, server administrators have more flexibility and control over which nodes should be dedicated for running extract queries and extract refreshes. As mentioned in the topology diagram above, certain Data Engine nodes are dedicated to processing extract queries and run only the File Store and Data Engine processes. Node Roles are available with Advanced Management. For more information on node roles, see Workload Management through Node Roles.
The diagram below uses the same topology as the basic configuration described above but with the node roles.
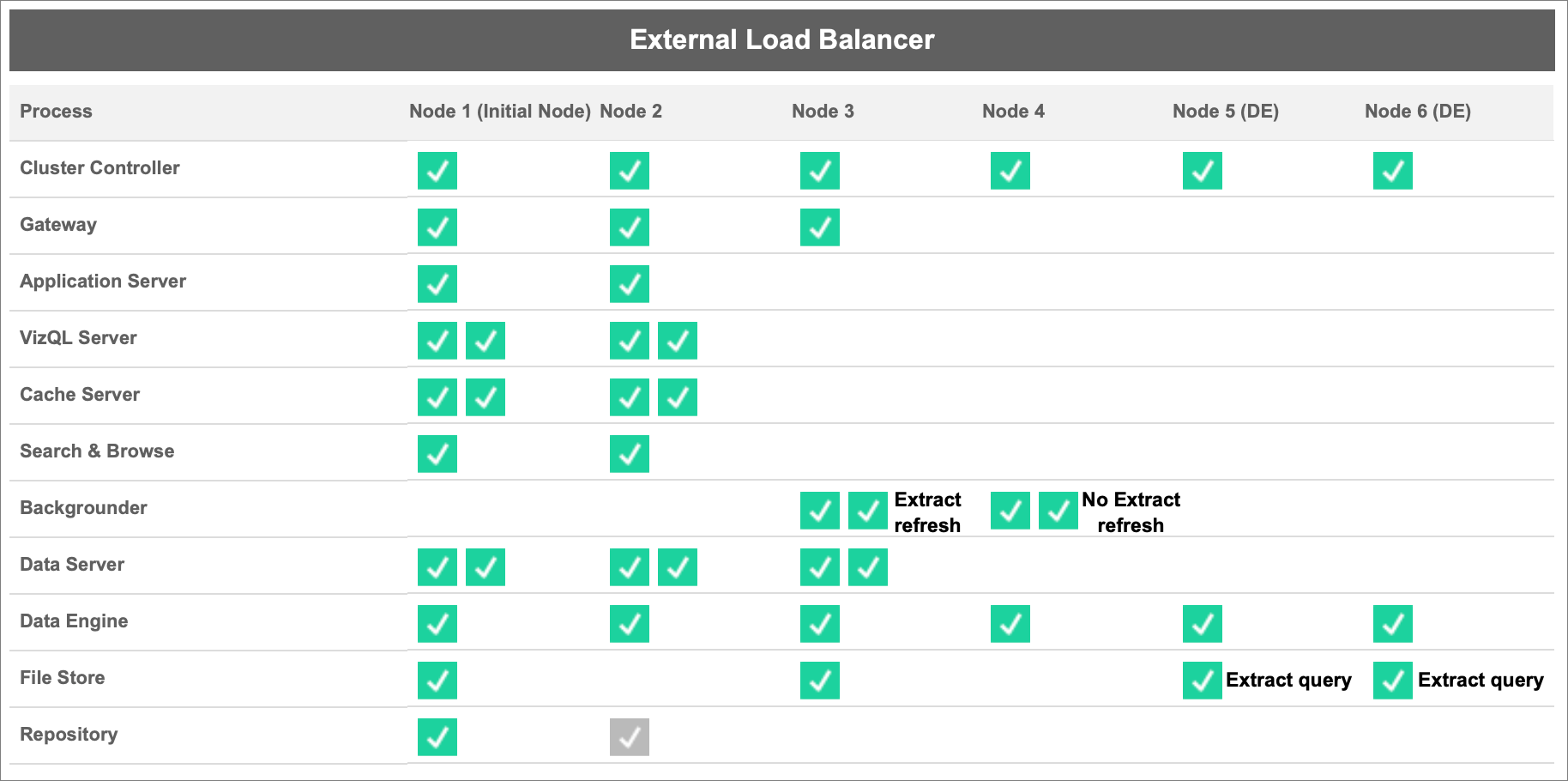
Extract Refreshes Backgrounder node role: By setting Node 3 to extract-refreshes Backgrounder node role, only incremental refreshes, full refreshes and encryption/decryption jobs will run on this node. By setting Node 4 to no-extract-refreshes Backgrounder node role, all background jobs other than extract refreshes will run on this node. Data Server and Gateway help the extract refresh jobs when using federated and shadow extracts. For more information on Backgrounder node roles, see File Store node roles.
Additionally, since Node 1 also has the Repository and File Store processes, all of the data needed to perform a backup exist on Node 1, which can improve backup performance.
The Backgrounder node roles are available with Advanced Management in Tableau Server version 2019.3 and later.
- Extract Queries File Store node role: Node 5 and 6, which are the dedicated Data Engine nodes, have the extract-queries File Store node role to ensure they only process queries for viz loads, subscriptions and data-driven alerts.
Extract Queries Interactive File Store node role: For dedicated Data Engine nodes, which have extract-queries File Store node role, server administrators can further isolate the interactive and scheduled workloads to run on specific dedicated Data Engine nodes. This is useful for times when there are a lot of users interacting and loading workbooks during high-volume subscription times. For example, let’s say there are 1000 subscriptions scheduled for 8 AM on a Monday morning. At the same time, many users are also loading dashboards at the beginning of their day. The combined volume of subscription and user queries can result in users experiencing slower, more variable workbook load times. With the extract-queries-interactive File Store node role, you can designate dedicated Data Engine nodes to only accept queries for interactive users (the ones who are looking at their screens waiting). These dedicated Data Engine nodes that are prioritised for interactive workloads would be protected from the high volume of competing subscription jobs and provide more consistent query times. Additionally, Server Admins can use this node role to better plan for growth since they can add dedicated Data Engine nodes for interactive and scheduled workloads independently. For more information, see File Store node roles.
The File Store node roles are available with Advanced Management in Tableau Server version 2020.4 and later.
Optimisations using External File Store: This feature allows you to use a network share as the storage for File Store instead of using the local disk on a Tableau Server node. By having the storage on a centralised location, you can significantly reduce the amount of network traffic spent on replicating data between the File Store nodes. For example, in the case when File Store is using a local disk, when a 1 GB extract is refreshed using local File Store, the 1 GB of data is replicated across the network to all nodes that are running the File Store process. In the case where Tableau Server is configured with External File Store, the 1 GB extract only needs to be copied to the network share once and all File Store nodes can access that single copy. The centralisation of storage also reduces the total amount of local storage needed on File Store nodes.
Additionally, Tableau Server backups leverage snapshot technology to significantly reduce the time to complete a backup.
While you don’t need a dedicated Data Engine node configuration to gain the benefits of External File Store, the additional workload management features with File Store node role and the Extract Query Interactive node role can be used together. See the Tableau Server External File Store topic for more details.
External File Store is available with Advanced Management in Tableau Server version 2020.1 and later.