Tableau 中的彙總函式
本文介紹 Tableau 中的彙總函式及其用途。它還示範如何使用範例建立彙總計算。
為何使用彙總函式
彙總函式允許您進行匯總或變更資料的資料粒度。
例如,您可能想要準確知道您的商店在特定年度有多少訂單。可以使用 COUNTD 函數來統計您公司擁有的唯一訂單的確切數量,然後按年份細分視覺效果。
計算可能如下所示:
COUNTD(Order ID)
視覺效果可能如下所示:
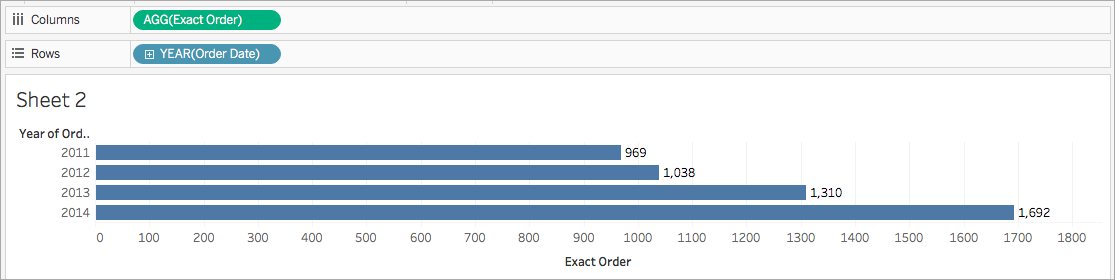
Tableau 中的可用彙總函式
彙總和浮點演算法:有些彙總的結果可能並非總是完全符合預期。例如,您可能會發現 SUM 函數為一欄數字傳回一個值,例如 -1.42e-14,而您知道這些數字的總和應該恰好為 0。出現這種情況的原因是電氣電子工程師學會 (IEEE) 755 浮點標準要求使用二進位格式儲存數字,這意味著數字有時會以極高的精度層級舍入。您可以使用 ROUND 函數(請參閱數位函數)或者透過將數位格式設定為顯示較少小數位來消除這種潛在誤差。
ATTR
| 語法 | ATTR(expression) |
| 定義 | 如果它的所有列都有一個值,則返回該運算式的值。否則返回星號。會忽略 Null 值。 |
AVG
| 語法 | AVG(expression) |
| 定義 | 返回運算式中所有值的平均值。會忽略 Null 值。 |
| 說明 | AVG 只能用於數字欄位。 |
收集
| 語法 | COLLECT(spatial) |
| 定義 | 將參數欄位中的值組合在一起的彙總計算。會忽略 Null 值。 |
| 說明 | COLLECT 只能用於空間欄位。 |
CORR
| 語法 | CORR(expression1, expression2) |
| 輸出 | 從 -1 到 1 的數字 |
| 定義 | 返回兩個運算式的皮爾森相關係數。 |
| 範例 | example |
| 說明 | 皮爾森相關係數衡量兩個變數之間的線性關係。結果範圍為 -1 至 +1(包括 -1 和 +1),其中 1 表示精確的正向線性關係,0 表示變異數之間沒有線性關係,而 −1 表示精確的反向關係。 CORR 結果的平方等於線性趨勢線模型的 R 平方值。請參閱趨勢線模型術語(連結在新視窗開啟)。 與表範圍 LOD 運算式一起使用: 您可以使用 CORR 來視覺化分解散點中的關聯性 表範圍的詳細資料層級運算式(連結在新視窗開啟)。例如: {CORR(Sales, Profit)}借助詳細層級運算式,關聯將在所有列上執行。如果您使用像 |
| 資料庫限制 |
對於其他資料來源,請考慮擷取資料或使用 |
COUNT
| 語法 | COUNT(expression) |
| 定義 | 傳回項目數量。不對 Null 值計數。 |
COUNTD
| 語法 | COUNTD(expression) |
| 定義 | 返回群組中不同項目的數量。不對 Null 值計數。 |
COVAR
| 語法 | COVAR(expression1, expression2) |
| 定義 | 傳回兩個運算式的樣本共變異數。 |
| 說明 | 共變數對兩個變數的共同變化方式進行量化。正共變數指明兩個變數趨向於向同一方向移動,平均來說,即一個變數的較大值趨向於與另一個變數的較大值對應。樣本共變異數使用非空資料點的數量 n - 1 來規範化共變異數計算,而不是使用母體共變異數(可用於 如果
|
| 資料庫限制 |
對於其他資料來源,請考慮擷取資料或使用 |
COVARP
| 語法 | COVARP(expression 1, expression2) |
| 定義 | 傳回兩個運算式的母體共變異數。 |
| 說明 | 共變數對兩個變數的共同變化方式進行量化。正共變數指明兩個變數趨向於向同一方向移動,平均來說,即一個變數的較大值趨向於與另一個變數的較大值對應。母體共變異數為樣本共變異數乘以 (n-1)/n,其中 n 是非 null 資料點的總數。如果存在可用於所有相關項目的資料,則母體共變異數是合適的選取,與之相反,在只有隨機項目子集的情況下,樣本共變異數(及 如果 |
| 資料庫限制 |
對於其他資料來源,請考慮擷取資料或使用 |
MAX
| 語法 | MAX(expression) 或 MAX(expr1, expr2) |
| 輸出 | 與引數相同的資料類型,若引數的任何部分為 NULL,則為 NULL 。 |
| 定義 | 傳回兩個引數中的最大值,這兩個引數必須具有相同的資料類型。
|
| 範例 | MAX(4,7) = 7 |
| 說明 | 對於字串
對於資料庫資料來源, 對於日期 對於日期, 作為彙總
作為比較
另請參閱 |
MEDIAN
| 語法 | MEDIAN(expression) |
| 定義 | 返回運算式在所有記錄中的中位數。會忽略 Null 值。 |
| 說明 | MEDIAN 只能用於數字欄位。 |
| 資料庫限制 |
對於其他資料來源類型,可以將資料擷取到擷取檔案以使用此函數。請參閱擷取您的資料(連結在新視窗開啟)。 |
MIN
| 語法 | MIN(expression) 或 MIN(expr1, expr2) |
| 輸出 | 與引數相同的資料類型,若引數的任何部分為 NULL,則為 NULL 。 |
| 定義 | 傳回兩個引數(必須為相同資料類型)的最小值。
|
| 範例 | MIN(4,7) = 4 |
| 說明 | 對於字串
對於資料庫資料來源, 對於日期 對於日期, 作為彙總
作為比較
另請參閱 |
PERCENTILE
| 語法 | PERCENTILE(expression, number) |
| 定義 | 從給定運算式傳回與指定 <number> 對應的百分位數值。<number> 必須介於 0 到 1 之間(含 0 和 1)並且必須是數字常數。 |
| 範例 | PERCENTILE([Score], 0.9) |
| 資料庫限制 | 此功能適用於以下資料來源:非舊版 Microsoft Excel 和文字檔案連線、擷取和僅擷取資料來源類型(例如 Google Analytics、OData 或 Salesforce)、Sybase IQ 15.1 及更高版本資料來源、Oracle 10 及更高版本的資料來源、Cloudera Hive 和Hortonworks Hadoop Hive 資料來源、EXASolution 4.2 及更高版本的資料來源。 對於其他資料來源類型,可以將資料擷取到擷取檔案以使用此函數。請參閱擷取您的資料(連結在新視窗開啟)。 |
STDEV
| 語法 | STDEV(expression) |
| 定義 | 基於群體樣本返回給定運算式中所有值的統計標準差。 |
STDEVP
| 語法 | STDEVP(expression) |
| 定義 | 基於有偏差群體返回給定運算式中所有值的統計標準差。 |
SUM
| 語法 | SUM(expression) |
| 定義 | 返回運算式中所有值的總計。會忽略 Null 值。 |
| 說明 | SUM 只能用於數字欄位。 |
VAR
| 語法 | VAR(expression) |
| 定義 | 基於群體樣本返回給定運算式中所有值的統計變異數。 |
VARP
| 語法 | VARP(expression) |
| 定義 | 對整個群體返回給定運算式中所有值的統計變異數。 |
建立彙總計算
按照下面的步驟進行操作以瞭解如何建立彙總計算。
- 在 Tableau Desktop 中,連線到 Tableau 附帶的[範例 - 超級市場]已儲存資料來源。
- 巡覽到工作表,並選取 [分析] > [建立計算欄位]。
- 在開啟的計算編輯器中,執行以下操作:
- 將計算欄位命名為 [Margin] (利潤)。
- 輸入以下公式:
IIF(SUM([Sales]) !=0, SUM([Profit])/SUM([Sales]), 0)附註:您可以使用函數引用來尋找彙總函式和其他函數(如此範例中的邏輯 IIF 函數),並將其新增到計算公式。有關詳情,請參閱在計算編輯器中使用函數引用。
- 完成後,按一下 [確定]。
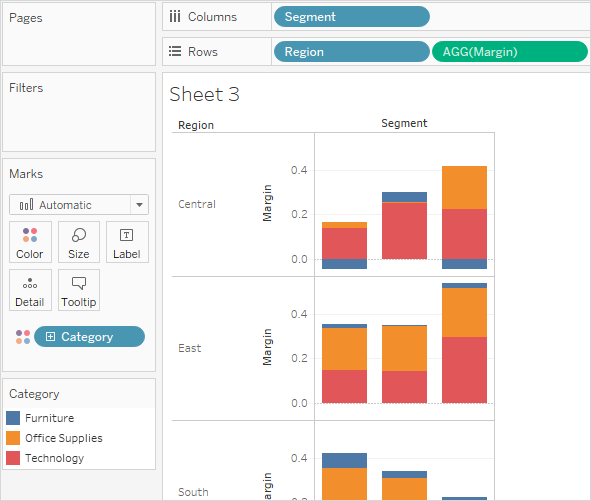
新的彙總計算將出現在 [資料] 窗格中的 [度量] 下。就像其他欄位一樣,您可以在一個或多個視覺效果中使用該欄位。
附註:彙總計算始終為度量。
當將 [Margin] (利潤)放在工作表中的架或卡上時,它的名稱將變更為 [AGG(Margin)] ,表示它是彙總計算,並且無法進一步彙總。
彙總計算的規則
適用于彙總計算的規則如下:
- 任何彙總計算中不得同時包括彙總值和分解值。例如,
SUM(Price)*[Items]不是有效的運算式,因為 SUM(價格) 為彙總,而「項目」不是。但是,SUM(Price*Items)和SUM(Price)*SUM(Items)都是有效的運算式。 - 運算式中的常量可根據情況充當彙總值或分解值。例如:
SUM(Price*7)和SUM(Price)*7都是有效的運算式。 - 所有函數都可用彙總值進行計算。但是,任何給定函數的參數必須或者全部彙總,或者全部分解。例如:
MAX(SUM(Sales),Profit)不是有效的運算式,因為「銷售額」為彙總,而「利潤」不是。但是,MAX(SUM(Sales),SUM(Profit))是有效的運算式。 - 彙總計算的結果始終為度量。這包括 ATTR(維度) 或 MIN(維度) 等運算式。
- 與預定義彙總一樣,彙總計算可正確地進行總計計算。有關詳情,請參閱 [總計] 。