Tableau 中的聚合函数
本文介绍 Tableau 中的聚合函数及其用途。它还演示如何使用示例创建聚合计算。
为何使用聚合函数
聚合函数允许您进行汇总或更改数据的粒度。
例如,您可能想要准确知道您的商店在特定年度有多少订单。您可以使用 COUNTD 函数对您的公司具有的准确唯一订单数进行计数,然后按年对可视化项进行细分。
计算可能如下所示:
COUNTD(Order ID)
可视化项可能如下所示:
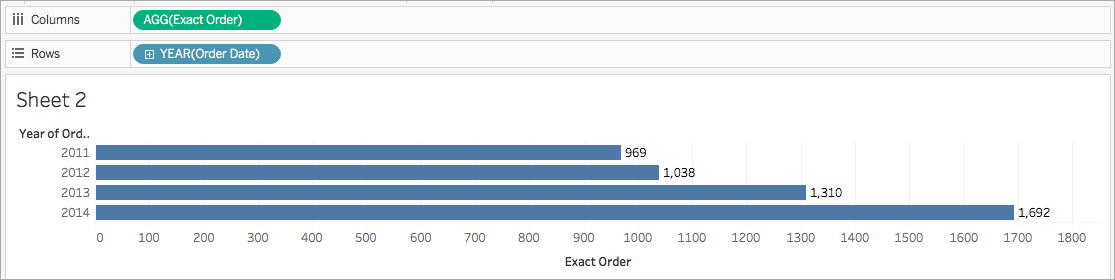
Tableau 中的可用聚合函数
聚合和浮点算法:有些聚合的结果可能并非总是完全符合预期。例如,您可能发现 SUM 函数返回值 -1.42e-14 作为列数,而您知道求和结果应该正好为 0。出现这种情况的原因是电气电子工程师学会 (IEEE) 754 浮点标准要求数字以二进制格式存储,这意味着数字有时会以极高的精度级别舍入。您可以使用 ROUND 函数(请参见数字函数)或者通过将数字格式设置为显示较少小数位来消除这种潜在误差。
ATTR
| 语法 | ATTR(expression) |
| 定义 | 如果它的所有行都有一个值,则返回该表达式的值。否则返回星号。会忽略 Null 值。 |
AVG
| 语法 | AVG(expression) |
| 定义 | 返回表达式中所有值的平均值。会忽略 Null 值。 |
| 说明 | AVG 只能用于数字字段。 |
COLLECT
| 语法 | COLLECT(spatial) |
| 定义 | 将参数字段中的值组合在一起的聚合计算。会忽略 Null 值。 |
| 说明 | COLLECT 只能用于空间字段。 |
CORR
| 语法 | CORR(expression1, expression2) |
| 输出 | 从 -1 到 1 的数字 |
| 定义 | 返回两个表达式的皮尔森相关系数。 |
| 示例 | example |
| 说明 | 皮尔森相关系数衡量两个变量之间的线性关系。结果范围为 -1 至 +1(包括 -1 和 +1),其中 1 表示精确的正向线性关系,0 表示方差之间没有线性关系,而 −1 表示精确的反向关系。 CORR 结果的平方等于线性趋势线模型的 R 平方值。请参见“趋势线模型术语”(链接在新窗口中打开)。 与表范围 LOD 表达式一起使用: 您可以使用 CORR,通过表范围的详细级别表达式(链接在新窗口中打开)来可视化解聚散点图中的相关性。例如: {CORR(Sales, Profit)}借助详细级别表达式,关联将在所有行上运行。如果您使用像 |
| 数据库限制 |
对于其他数据源,请考虑提取数据或使用 |
COUNT
| 语法 | COUNT(expression) |
| 定义 | 返回项目数。不对 Null 值计数。 |
COUNTD
| 语法 | COUNTD(expression) |
| 定义 | 返回组中不同项目的数量。不对 Null 值计数。 |
COVAR
| 语法 | COVAR(expression1, expression2) |
| 定义 | 返回两个表达式的样本协方差。 |
| 说明 | 协方差对两个变量的共同变化方式进行量化。正协方差指明两个变量趋向于向同一方向移动,平均来说,即一个变量的较大值趋向于与另一个变量的较大值对应。样本协方差使用非空数据点的数量 n - 1 来规范化协方差计算,而不是使用总体协方差(可用于 如果
|
| 数据库限制 |
对于其他数据源,请考虑提取数据或使用 |
COVARP
| 语法 | COVARP(expression 1, expression2) |
| 定义 | 返回两个表达式的总体协方差。 |
| 说明 | 协方差对两个变量的共同变化方式进行量化。正协方差指明两个变量趋向于向同一方向移动,平均来说,即一个变量的较大值趋向于与另一个变量的较大值对应。总体协方差等于样本协方差除以 (n-1)/n,其中 n 是非空数据点的总数。如果存在可用于所有相关项的数据,则总体协方差是合适的选择,与之相反,在只有随机项子集的情况下,样本协方差(及 如果 |
| 数据库限制 |
对于其他数据源,请考虑提取数据或使用 |
MAX
| 语法 | MAX(expression) 或 MAX(expr1, expr2) |
| 输出 | 与参数相同的数据类型,或者,如果参数的任何部分为 null,则为 NULL 。 |
| 定义 | 返回两个参数(必须为相同数据类型)中的最大值。
|
| 示例 | MAX(4,7) = 7 |
| 说明 | 对于字符串
对于数据库数据源, 对于日期 对于日期, 作为聚合
作为比较
另请参见 |
MEDIAN
| 语法 | MEDIAN(expression) |
| 定义 | 返回表达式在所有记录中的中位数。会忽略 Null 值。 |
| 说明 | MEDIAN 只能用于数字字段。 |
| 数据库限制 |
对于其他数据源类型,可以将数据提取到数据提取文件以使用此函数。请参见提取数据(链接在新窗口中打开)。 |
MIN
| 语法 | MIN(expression) 或 MIN(expr1, expr2) |
| 输出 | 与参数相同的数据类型,或者,如果参数的任何部分为 null,则为 NULL 。 |
| 定义 | 返回两个参数(必须为相同数据类型)中的最小值。
|
| 示例 | MIN(4,7) = 4 |
| 说明 | 对于字符串
对于数据库数据源, 对于日期 对于日期, 作为聚合
作为比较
另请参见 |
PERCENTILE
| 语法 | PERCENTILE(expression, number) |
| 定义 | 从给定表达式返回与指定 <number> 对应的百分位处的值。<number> 必须介于 0 到 1 之间(含 0 和 1),并且必须是数值常量。 |
| 示例 | PERCENTILE([Score], 0.9) |
| 数据库限制 | 此函数可用于以下数据源:非旧版 Microsoft Excel 和文本文件连接、数据提取和仅数据提取数据源类型(例如 Google Analytics、OData 或 Salesforce)、Sybase IQ 15.1 及更高版本数据源、Oracle 10 及更高版本的数据源、Cloudera Hive 和 Hortonworks Hadoop Hive 数据源、EXASolution 4.2 及更高版本的数据源。 对于其他数据源类型,可以将数据提取到数据提取文件以使用此函数。请参见提取数据(链接在新窗口中打开)。 |
STDEV
| 语法 | STDEV(expression) |
| 定义 | 基于群体样本返回给定表达式中所有值的统计标准差。 |
STDEVP
| 语法 | STDEVP(expression) |
| 定义 | 基于有偏差群体返回给定表达式中所有值的统计标准差。 |
SUM
| 语法 | SUM(expression) |
| 定义 | 返回表达式中所有值的总计。会忽略 Null 值。 |
| 说明 | SUM 只能用于数字字段。 |
VAR
| 语法 | VAR(expression) |
| 定义 | 基于群体样本返回给定表达式中所有值的统计方差。 |
VARP
| 语法 | VARP(expression) |
| 定义 | 对整个群体返回给定表达式中所有值的统计方差。 |
创建聚合计算
按照下面的步骤进行操作以了解如何创建聚合计算。
- 在 Tableau Desktop 中,连接到 Tableau 附带的示例 - 超市已保存数据源。
- 导航到工作表,并选择“分析”>“创建计算字段”。
- 在打开的计算编辑器中,执行以下操作:
- 将计算字段命名为“Margin”(利润)。
- 输入以下公式:
IIF(SUM([Sales]) !=0, SUM([Profit])/SUM([Sales]), 0)注意:您可以使用函数引用来查找聚合函数和其他函数(如此示例中的逻辑 IIF 函数),并将其添加到计算公式。有关详细信息,请参见在计算编辑器中使用函数引用。
- 完成后,单击“确定”。
新的聚合计算将出现在“数据”窗格中的“度量”下。就像其他字段一样,您可以在一个或多个可视化项中使用该字段。
注意:聚合计算始终为度量。
当将“Margin”(利润)放在工作表中的功能区或卡上时,它的名称将更改为“AGG(Margin)”,表示它是聚合计算,并且无法进一步聚合。
聚合计算的规则
适用于聚合计算的规则如下:
- 任何聚合计算中不得同时包括聚合值和解聚值。例如,
SUM(Price)*[Items]不是有效的表达式,因为 SUM(Price) 已聚合,而 Items 则没有。不过,SUM(Price*Items)和SUM(Price)*SUM(Items)都有效。 - 表达式中的常量可根据情况充当聚合值或解聚值。例如:例如:
SUM(Price*7)和SUM(Price)*7都是有效表达式。 - 所有函数都可用聚合值进行计算。但是,任何给定函数的参数必须或者全部聚合,或者全部解聚。例如,
MAX(SUM(Sales),Profit)不是有效表达式,原因是 Sales 是聚合的,而 Profit 则不是。不过,MAX(SUM(Sales),SUM(Profit))是有效表达式。 - 聚合计算的结果始终为度量。这包括像 ATTR(Dimension) 或 MIN(Dimension) 这样的表达式。
- 与预定义聚合一样,聚合计算可正确地进行总计计算。有关详细信息,请参见“总计”。