좋은 데이터 집합 찾기
Tableau를 사용한 데이터 분석 방법(또는 샘플이나 개념 증명 콘텐츠 작성 방법)을 배우는 좋은 방법은 관심이 있는 데이터 집합을 찾는 것입니다. 데이터를 사용하여 답변을 구하려는 실제 질문이 있는 경우 분석 단계가 더 쉬워지고 의미가 커집니다.
데이터 집합의 현실성
공식적인 비즈니스 영역의 데이터가 아닌 데이터 집합을 찾으려고 할 때 불가피하게 발생하는 두 가지 문제가 있습니다.
필요한 데이터를 찾을 수 없습니다.
- 필요한 것을 너무 엄격하게 기대하지 마십시오.
- 유연성을 가지고 열린 마음으로 지정된 프로젝트에 사용할 수 있을지 생각해야 합니다.
- 때로는 원하는 데이터에 비용을 지불해야 할 수도 있습니다. 그럴 가치가 있는지 결정하십시오.
데이터를 정리해야 합니다.
- 데이터가 분석에 적합하게 구조화될 수 있도록 기본적인 정리 및 형상화(링크가 새 창에서 열림)를 준비합니다.
- 다른 데이터 집합 가져오기(링크가 새 창에서 열림)가 필요할 수 있습니다.
- 데이터 사전 또는 메타데이터를 준비해야 할 수 있습니다.
- 계산이 필요할 수 있습니다.
좋은 데이터 집합의 구성 요소
좋은 데이터 집합은 목적에 맞는 데이터 집합입니다. 필요성이 충족된다면 좋은 데이터 집합입니다. 그러나 데이터 집합에서 목적에 맞지 않는 데이터를 제거해야 할 때 도움이 되는 몇 가지 고려 사항이 있습니다. 전체적으로 다음 조건을 충족하는 데이터 집합을 찾으십시오.
- 필요한 요소가 포함되어야 함
- 집계되지 않은 데이터여야 함
- 적어도 두 개의 차원과 두 개의 측정값이 있어야 함
- 양호한 메타데이터 또는 데이터 사전이 있어야 함
- 사용 가능해야 함(독점 형식이 아니고, 복잡하지 않고, 다루기 힘들지 않아야 함)
Superstore는 Tableau Desktop과 함께 제공되는 샘플 데이터 원본 중 하나입니다. (또한 Tableau Public 샘플 데이터 페이지(링크가 새 창에서 열림)에서 다운로드할 수도 있습니다.) 이것이 좋은 데이터 집합인 이유
- 필수 요소: Superstore에는 날짜, 지리적 데이터, 계층 관계가 있는 필드(Category(범주), Sub-Category(하위 범주), Product(제품)), 양수 및 음수인 측정값(Profit(수익)) 등이 있습니다. Superstore 단독으로 만들 수 없는 차트 유형은 일부이며 시연할 수 없는 기능은 거의 없습니다.
- 집계되지 않음: 행 수준 데이터는 거래의 각 항목입니다. 이러한 항목은 주문 수준까지(Order ID(주문 ID)를 통해) 또는 차원 중 하나(예: 날짜, 고객, 지역 등)를 기준으로 롤업할 수 있습니다.
- 차원 및 측정값: Superstore에는 범주 및 도시와 같이 항목별로 "쪼개서 분석"할 수 있는 여러 차원이 있습니다. 또한 여러 측정값과 날짜가 있어 차트 유형 및 계산도 시험해 볼 수 있습니다.
- 메타데이터: Superstore에는 명확하게 이름이 지정된 필드 및 값이 있습니다. 어떤 값인지 조사할 필요가 없습니다.
- 작고 잘 정리됨: Superstore는 몇 메가바이트 크기이므로 Tableau 설치 관리자에서 작은 공간만 차지합니다. 또한 정리된 데이터이며 각 필드에 정확한 값만 있고 데이터 구조가 양호합니다.
1. 양호한 데이터 집합에는 목적에 맞는 요소가 있습니다.
특정 비주얼리제이션을 작성하거나 특정 기능을 시연하기 위한 데이터 집합을 찾는다면 데이터 집합에 필요한 필드 유형이 있는지 확인하십시오. 예를 들어 맵은 시각적으로 뛰어나지만 지리적 데이터가 필요합니다. 기본적인 데모에 날짜 드릴다운이 필요한 경우가 많으므로 데이터에 날짜 필드가 적어도 하나는 있어야 합니다(드릴다운을 시연하려면 연도보다 세부적인 수준이어야 함). 모든 데이터 집합이 이러한 요소 모두를 가져야 하는 것은 아니지만, 목적에 맞는 데이터 집합이 무엇인지 알게 되면 주요 요소가 빠진 데이터 집합으로 시간을 낭비하지 않게 됩니다.
분석을 위한 공통 요소:
- 날짜
- 지리적 데이터
- 계층 데이터
- “관심” 측정값 - 크기 변화가 상당하거나 양수 및 음수 값이 있어야 합니다.
일부 기능 또는 비주얼리제이션 유형에는 다음과 같은 특정 데이터 특성이 필요할 수 있습니다.
- 클러스터(링크가 새 창에서 열림)
- 예측(링크가 새 창에서 열림)
- 추세선(링크가 새 창에서 열림)
- 사용자 필터(링크가 새 창에서 열림)
- 공간 계산(링크가 새 창에서 열림)
- 특정 계산(링크가 새 창에서 열림)
- 불릿 차트(링크가 새 창에서 열림)
2. 양호한 데이터는 집계되지 않은(원시) 데이터입니다.
데이터가 지나치게 집계되어(링크가 새 창에서 열림) 있는 경우 분석에서 할 수 있는 일이 많지 않습니다. 예를 들어 Google 검색에서 "펌킨 스파이스"를 찾는 사람들의 추세를 조사하고 싶지만 연도 데이터만 있다면 매우 개략적인 개요만 조사할 수 있습니다. 이상적이라면 일별 데이터를 원할 것입니다. 그래야 스타벅스가 #PSL 공급을 시작할 때 엄청난 검색 증가를 확인할 수 있을 것입니다.
집계되지 않은 카운트는 무엇인지가 분석에 따라 달라질 수 있습니다. 개인 정보 보호나 현실적인 이유로 인해 일부 데이터 집합은 완벽하게 세분화되지 않습니다. 예를 들어 말라리아 환자의 주소별 보고가 있는 데이터 집합은 거의 찾을 수 없을 것이므로 지역별 월간 총계가 충분한 상세 수준일 수 있습니다.
여러 이유에서 집계 및 세부 수준이 핵심 개념이라는 것을 이해해야 합니다. 이들은 유용한 데이터 집합 찾기, 필요한 비주얼리제이션 작성, 올바른 데이터 결합, LOD 식 사용 등에 영향을 미칩니다. 집계와 세부 수준은 완전히 반대되는 개념입니다.
집계는 데이터가 결합되는 방식을 나타냅니다. 예를 들어 모든 펌킨 스파이스 검색 수의 합계를 계산하거나 지정된 날짜에 시애틀 주변의 모든 온도 판독값 평균을 구하는 것이 여기에 포함됩니다.
- 기본적으로 Tableau의 측정값은 집계됩니다. 기본 집계는 SUM입니다. 이 집계를 평균, 중앙값, 고유 카운트, 최소값 등으로 변경할 수 있습니다.
세부 수준은 데이터가 얼마나 자세한지를 나타냅니다. 데이터 집합의 행(일명: 레코드)이 나타내는 것은 무엇입니까? 말라리아에 감염된 사람은? 특정 주/도에서 한 달 동안 발생한 말라리아 총 건수는? 이런 것이 세부 수준입니다. 데이터의 세부 수준을 아는 것이 중요합니다.
자세한 내용은 Tableau의 데이터 집계를 참조하십시오.
3. 좋은 데이터 집합에는 차원과 측정값이 있습니다.
많은 비주얼리제이션 유형에는 차원과 측정값이 필요합니다.
- 차원만 있는 경우 대부분 수 계산, 백분율 계산이나 테이블의 카운트 사용으로 제한됩니다.
- 측정값만 있는 경우 기준을 사용하여 값을 분석할 수 없습니다. 데이터 집계를 완전히 해제하거나 전체 SUM 또는 AVG 등을 계산할 수 있습니다.
차원만 있는 데이터 집합은 유용할 수 없다고 말하는 것은 아닙니다. 인구 통계 데이터는 차원 중심 데이터의 예이며 인구 통계와 관련된 많은 분석은 개수 계산이나 백분율 기반입니다. 그러나 분석적으로 가능성이 풍부한 데이터 집합에는 적어도 몇 개의 차원과 측정값이 필요합니다.
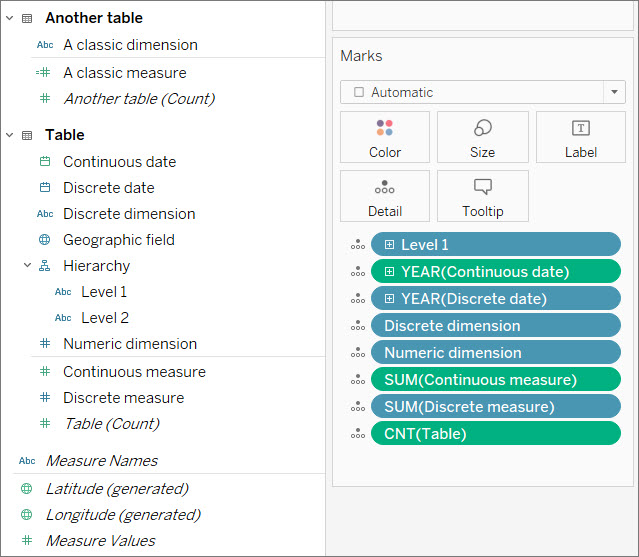
위 이미지에서 숫자 차원은 마크 카드에 집계가 없지만 연속형 측정값과 불연속형 측정값은 모두 집계가 있습니다.
차원 및 측정값
필드는 데이터 패널에서 가로 선을 사용하여 차원과 측정값으로 분류됩니다. Tableau에서 차원은 뷰에 그 자체로 나타나지만 측정값은 자동으로 집계됩니다. 측정값의 기본 집계는 SUM입니다.
- 차원은 정성적입니다. 즉, 설명할 수 있지만 측정할 수 없습니다.
- 차원은 대개 도시나 국가, 눈동자 색상, 범주, 팀 이름 등과 같은 것들입니다.
- 차원은 일반적으로 불연속형입니다.
- 측정값은 정량적입니다. 즉, 측정할 수 있으며 기록(숫자)할 수 있습니다.
- 측정값은 대개 매출, 키, 클릭 수 등과 같은 것들입니다.
- 측정값은 대개 연속형입니다.
필드로 수학을 할 수 있는 경우 측정값입니다. 필드가 측정값인지, 아니면 차원인지 잘 모르겠으면 값으로 의미 있는 수학을 할 수 있는지 생각해 보십시오. AVG(RowID), 두 주민등록번호의 합계 또는 우편 번호를 10으로 나눈 값에 의미가 있습니까? 의미가 없습니다. 이들은 숫자로 쓰여진 차원입니다. 영숫자 우편 번호를 사용하는 국가가 몇 개인지 생각해 보십시오. 미국은 숫자만 사용하지만 이들은 레이블일 뿐입니다. Tableau는 숫자 필드를 나타내는 많은 필드명이 실제로는 ID이거나 우편 번호라는 것을 인식할 수 있으며 이들을 차원으로 만들려고 시도하지만 완벽하지는 않습니다. "수학을 할 수 있는지 여부" 테스트를 사용하여 숫자 필드가 측정값인지, 아니면 차원인지 결정하고 필요에 따라 데이터 패널에 다시 배치하십시오.
참고: 날짜로 수학을 할 수 있지만(예: DATEDIFF 계산) 표준 규칙은 날짜를 차원으로 분류하는 것입니다.
불연속형 및 연속형
불연속형 또는 연속형 필드는 어느 정도 차원 및 측정값 개념과 연결되지만 동일하지는 않습니다.
- 불연속형 필드는 고유 값을 포함합니다. 이들은 뷰에서 머리글 또는 레이블이 되며 알약 모양은 파란색입니다.
- 연속형 필드는 “분리되지 않는 전체를 형성”합니다. 이들은 뷰에서 축이 되며 알약 모양은 녹색입니다.
불연속형 및 연속형을 이해하는 좋은 방법은 날짜 필드를 살펴보는 것입니다. 날짜는 불연속형이거나 연속형일 수 있습니다.
- 10년 동안 또는 100년 동안의 8월 평균 온도를 조사하는 것은 “8월”이 불연속형이며 정성적인 날짜 부분으로 사용된다는 의미입니다.
- 1960년 이후 보고된 말라리아 사례의 전체적인 추세를 살펴보면 끊어지지 않는 단일 축을 얻게 됩니다. 즉, 날짜가 연속형인 정량적 값으로 사용됩니다.
자세한 내용은 차원 및 측정값, 파란색 및 녹색을 참조하십시오.
Tableau는 데이터 집합에 무엇인지에 관계없이 자동으로 최소 3개의 필드를 만듭니다.
- 측정값 이름(차원)
- 측정값(측정값)
- TableName(Count)(측정값)
또한 데이터 집합에 지리적 필드가 있는 경우 Tableau는 위도(생성됨) 및 경도(생성됨) 필드도 만듭니다.
측정값 이름과 측정값은 유용한 2가지 필드입니다. 자세한 내용은 측정값 및 측정값 이름을 참조하십시오.
테이블의 카운트는 행 수를 계산하여 테이블의 레코드 수를 제공합니다. 이를 사용해 데이터 집합에서 적어도 하나의 측정값을 가질 수 있으며 일부 분석에도 이용할 수 있습니다. 행 수의 의미를 정의할 수 있으려면 데이터의 세부 수준(행이 나타내는 대상)을 이해해야 합니다.
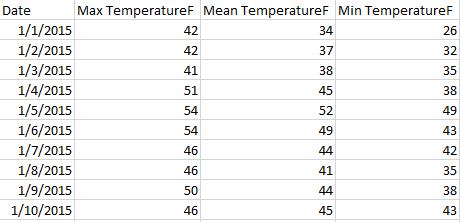
여기서, 각 행은 날짜이므로 테이블의 카운트는 일 수입니다.
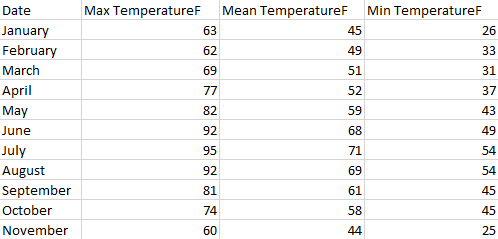
여기서, 각 행은 월이므로 테이블의 카운트는 월 수입니다.
4. 좋은 데이터 집합에는 메타데이터 또는 데이터 사전이 있습니다.
데이터 집합은 데이터의 의미를 아는 경우에만 유용합니다. 다음과 같이 표시되는 파일을 여는 것보다 좋은 데이터를 찾는 노력을 하는 것이 덜 답답합니다.
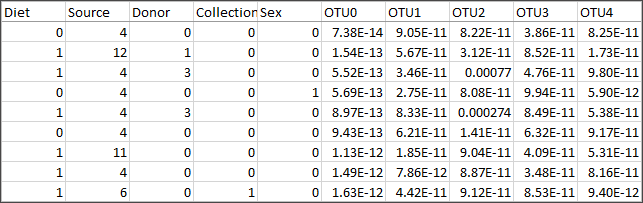
원본 4 또는 12는 무엇을 의미합니까? OTU0-OTU4 필드에 있는 정보는 무엇입니까?
좋은 데이터 집합에는 레이블이 잘 적용된 필드와 멤버 또는 데이터 사전이 있으므로 직접 데이터에 레이블을 지정할 수 있습니다. Superstore를 생각해 보십시오. 필드와 해당 값의 의미를 즉시 알 수 있습니다. Category(범주)와 해당 멤버인 Technology, Furniture, Office Supplies를 예로 들 수 있습니다. 또는 위의 이미지에 있는 microbiome 데이터 집합의 경우 각 원본을 설명하는 데이터 사전(링크가 새 창에서 열림)(4는 대변이고 12는 복부)과 각 OTU의 분류(OTU3은 파라박테로이데스 속의 박테리아)가 있습니다.
데이터 사전은 메타데이터, 지표, 변수 정의, 용어집 등 다양한 이름으로 불립니다. 결국 가장 중요한 것은, 데이터 사전이 열 이름과 열의 멤버에 대한 정보를 제공한다는 것입니다. 이 정보는 다음과 같은 여러 방법으로 데이터 원본이나 비주얼리제이션으로 가져올 수 있습니다.
- 더 이해하기 쉽도록 열 이름을 바꿉니다(데이터 집합 자체 또는 Tableau에서 수행할 수 있음).
- 필드 멤버의 별칭을 바꿉니다(데이터 집합 자체 또는 Tableau에서 수행할 수 있음).
- 계산을 만들어 데이터 사전 정보를 추가합니다.
- Tableau에서 필드에 대한 설명을 추가합니다(설명은 게시된 비주얼리제이션에는 나타나지 않고 작성 환경에만 나타남).
- 데이터 사전을 또 다른 데이터 원본으로 사용하고 두 데이터 원본을 결합합니다.
데이터 사전이 없으면 데이터 집합이 쓸모가 없을 수 있습니다. 데이터 집합을 책갈피에 추가하는 경우 데이터 사전도 책갈피에 추가합니다. 다운로드하는 경우 둘 모두를 다운로드하여 한 장소에 보관합니다.
5. 좋은 데이터 집합은 사용 가능한 데이터 집합입니다.
데이터 집합에 대해 파악하고 있고 데이터 집합에 필요한 정보가 있으면 작은 데이터 집합도 분석에 유용할 수 있습니다. 데이터 집합이 작을수록 저장, 공유 및 게시가 쉬우며 대개 성능이 좋습니다.
마찬가지로, 필요에 맞는 “완벽한” 데이터 집합을 찾은 경우에도 정리에 비현실적인 수준의 노력이 필요하다면 전혀 완벽하지 않은 것입니다. 지나치게 어수선한 데이터 집합을 버릴 줄 아는 것이 중요합니다.
예를 들어 이 데이터 집합은 Wikipedia 문서의 상대 문자 빈도에 대한 것입니다. 처음에는 84개 행과 16개 열이었습니다(1,245개 행과 3개 열로 피벗됨). Excel 파일은 16KB입니다. 몇 가지 그룹, 집합, 계산 및 기타 조작이 있지만 견고한 분석과 흥미로운 시각 자료를 지원합니다.
통합 문서를 다운로드하려면 이미지를 클릭하십시오.
데이터 레이블 바꾸기
좋은 데이터 집합을 찾았으면 대개 레이블을 바꾸게 됩니다. 데이터 레이블을 바꾸는 것은 샘플 또는 개념 증명을 위한 모의 데이터를 만들거나 데이터의 가독성을 높일 때 유용합니다.
필드 이름 바꾸기는 Tableau에서 필드가 나타나는 방식을 변경합니다. 예를 들어 “매출”을 “파이프라인 매출”로 바꾸거나 “주”를 “지자체”로 바꿀 수 있습니다.
별칭 바꾸기는 필드의 멤버가 표시되는 방식을 변경합니다. 예를 들어 Country(국가) 필드의 값에서 CHN을 China로, RUS를 Russia로 별칭을 바꿀 수 있습니다.
- 불연속형 차원 필드의 값을 멤버라고 합니다. 멤버만 별칭을 바꿀 수 있습니다. 온도에 대한 측정값 필드가 있다고 가정합니다. 화씨 54도의 값은 데이터 자체를 변경하지 않고는 변경할 수 없습니다. 하지만 Country(국가) 필드의 멤버 “CHN”을 “China”로 별칭을 바꾸는 것은 다른 방식으로 레이블만 지정한 동일한 정보입니다.
이름 바꾸기와 별칭 바꾸기는 거의 같은 것입니다. 필드는 이름을 바꾸고 멤버는 별칭을 바꾸는 것이 Tableau의 규칙입니다. 자세한 내용은 데이터 패널의 필드 구성 및 사용자 지정 및 별칭을 만들어 뷰의 멤버 이름 바꾸기를 참조하십시오.
참고: 이름 바꾸기나 별칭 바꾸기는 Tableau Desktop의 표시만 변경합니다. 변경 사항이 기초 데이터에 기록되지 않습니다.
모의 데이터를 만들기 위한 레이블 바꾸기
기존 데이터 집합의 레이블을 바꾸는 것은 샘플 또는 개념 증명 콘텐츠의 설득력을 높이는 좋은 방법입니다.
- Superstore와 같은 쉬운 데이터 집합을 사용하여 원하는 콘텐츠(특정 차트 유형, 특정 기능 시연 등)를 작성합니다.
- 관련 필드의 이름을 바꾸고, 도구 설명을 변경하고, 텍스트 특성을 변경하는 등, 데이터가 실제 나타내는 내용을 표현합니다.
중요: 모의 정보라는 것이 명확할 때에만 이렇게 하십시오. 사람들이 실제 데이터라고 생각하고 분석에 사용하게 되지 않도록 주의하십시오. 예를 들어 색상이나 동물 이름 같은 웃기거나 의미 없는 필드명을 사용합니다.
데이터를 쉽게 사용할 수 있도록 별칭 바꾸기
데이터를 문자열 값보다 숫자 값으로 저장하는 것이 훨씬 효율적이지만 숫자 인코딩을 사용하면 데이터를 이해하기 힘들어질 수 있습니다. 작은 데이터 집합인 경우 대개 성능에 미치는 영향이 크지 않으므로 데이터를 쉽게 이해할 수 있게 만드는 것에 우선 순위를 두십시오.
별칭 바꾸기의 단점은 더 이상 수치 값에 액세스할 수 없다는 것입니다(정렬을 수행하거나 색상 그라데이션을 할당하기 어려워짐). 필드를 복제하여 복사본의 별칭을 바꾸는 것을 고려하십시오. 또한 Tableau의 계산이 원래 정보를 보존하면서 더 쉽게 이해할 수 있게 만드는 좋은 방법이 될 수 있습니다.
CASE 함수로 별칭 바꾸기
계산은 매우 강력한 별칭 바꾸기 기능이 될 수 있습니다. 예를 들어 CASE(링크가 새 창에서 열림) 함수를 사용하면 '이 필드의 값이 A인 경우 X를 반환하고, 값이 B인 경우 Y를 반환'하게 할 수 있습니다.
여기서 CASE 함수는 토네이도 데이터 집합에서 F-척도를 조사하여 각 수치 값과 관련된 텍스트 설명을 제공합니다.
CASE [F-scale]
WHEN "0" THEN "Some damage to chimneys; branches broken off trees; shallow-rooted trees pushed over; sign boards damaged."
WHEN "1" THEN "The lower limit is the beginning of hurricane wind speed; peels surface off roofs; mobile homes pushed off foundations or overturned; moving autos pushed off the roads..."
WHEN "2" THEN "Roofs torn off frame houses; mobile homes demolished; boxcars overturned; large trees snapped or uprooted; highrise windows broken and blown in; light-object missiles generated."
WHEN "3" THEN "Roofs and some walls torn off well-constructed houses; trains overturned; most trees in forest uprooted; heavy cars lifted off the ground and thrown."
WHEN "4" THEN "Well-constructed houses leveled; structures with weak foundations blown away some distance; cars thrown and large missiles generated."
WHEN "5" THEN "Strong frame houses lifted off foundations and carried considerable distances to disintegrate; ... trees debarked; steel reinforced concrete structures badly damaged."
END
이제 비주얼리제이션에서 원래 "F-척도" 필드(0-5)나 "F-척도 손상 설명" 필드 중 하나를 선택하여 사용할 수 있습니다.
데이터 집합을 찾을 때 팁
참고: "데이터 집합의 행(일명: 레코드)이 나타내는 것은 무엇입니까?"라는 질문에 대답할 수 있어야 합니다. 분명하게 답할 수 없는 경우 데이터를 활용할 수 있을 정도로 충분히 이해하지 못한 것이거나 데이터가 분석에 적합하지 않은 잘못된 구조일 수 있습니다.
- 데이터의 출처를 추적해야 합니다.
- 데이터와 함께 데이터 사전 정보를 유지합니다.
- 콘텐츠를 최신 상태로 유지해야 하는 경우 오래된 데이터를 방지합니다. 찾을 대상:
- 업데이트 가능한 데이터(주식, 날씨, 정기적으로 발표되는 보고서 등)
- 시대를 초월하는 데이터(다양한 동물의 평균 체중은 해가 바뀌어도 변하지 않음)
- 인위적으로 이전 날짜 또는 장래 날짜로 변경하여 미래에도 사용할 수 있는 데이터
- 찾으려는 데이터 집합을 Google에서 검색해 보면 놀랄 수 있습니다.
- 준비에 너무 많은 작업이 필요한 경우 데이터 집합을 포기하는 것을 주저하지 마십시오.
데이터를 찾을 위치
어디에서 데이터를 찾을 수 있습니까? 데이터 집합을 찾을 수 있는 엄청나게 많은 장소가 있습니다. 다음은 시작할 때 사용할 수 있는 몇 가지 옵션입니다. 데이터 집합의 현실성은 이러한 사이트에 적용되지 않습니다. 아마 지금 생각하고 있는 대상을 찾지 못할 것이며 대개 분석에 사용할 수 있는 데이터를 얻으려면 일부 정리를 수행해야 할 수 있습니다.
고지 사항: Tableau는 정확하고 최신 상태이며 관련성이 있는 외부 웹 사이트 링크를 제공하기 위해 모든 노력을 기울이지만 외부 공급자에 의해 유지 관리되는 페이지의 정확성 또는 적합성에 대해서는 책임을 지지 않습니다. 여기에서 사이트를 나열하는 것은 특정 콘텐츠나 조직을 홍보하기 위한 것이 아닙니다. 외부 사이트 콘텐츠와 관련된 질문은 해당 사이트에 문의하십시오.
Tableau Public(링크가 새 창에서 열림): Tableau Public은 Tableau 지원 데이터 집합을 얻을 수 있는 놀라운 리소스입니다. 관심이 있는 주제에 대한 통합 문서를 검색하고 영감을 주는 통합 문서를 찾은 다음 다운로드하여 데이터에 액세스합니다. 또는 조정된 샘플 데이터(링크가 새 창에서 열림)를 확인해 보십시오.
Wikipedia 테이블(링크가 새 창에서 열림): Wikipedia 테이블의 데이터를 가져오려면 복사하여 스프레드시트에 붙여 넣거나, 복사하여 Tableau에 직접 붙여 넣거나, Google 스프레드시트 및 IMPORTHTML 함수(링크가 새 창에서 열림)를 사용하여 데이터를 Google 스프레드시트로 만들 수 있습니다.
Google 데이터 집합 검색(링크가 새 창에서 열림): "조각난 온라인 데이터 집합의 세계를 통일하는 검색 엔진입니다."
Data is Plural(링크가 새 창에서 열림): 데이터 집합을 포함하는 주간 뉴스레터를 구독하거나 아카이브(링크가 새 창에서 열림)를 찾아보십시오.
Makeover Monday(링크가 새 창에서 열림): “매주 월요일 우리와 함께 지정된 데이터 집합을 처리하여 더 정확하고 보다 효과적인 비주얼리제이션을 만들고, 더욱 쉽게 액세스할 수 있는 정보를 만들도록 도와주세요.” 다른 사용자들이 동일한 데이터 집합을 사용하여 무엇을 했는지 확인하여 분석의 시작점으로 삼거나 영감을 얻을 수 있습니다. 참여하려면 Twitter에서 #makeovermonday(링크가 새 창에서 열림)를 사용하십시오.
기타 사이트
- Tableau 웹 데이터 커넥터(링크가 새 창에서 열림)
- Data.world(링크가 새 창에서 열림) 및 해당 WDC for Tableau(링크가 새 창에서 열림)
- Github Open Data(링크가 새 창에서 열림)
- Kaggle(링크가 새 창에서 열림)
- datahub.io(링크가 새 창에서 열림)
- r/datasets(링크가 새 창에서 열림)
- WHO(링크가 새 창에서 열림)
- Data.UN.org(링크가 새 창에서 열림)
- WorldBank(링크가 새 창에서 열림)
- data.gov(링크가 새 창에서 열림), data.gov.au(링크가 새 창에서 열림), data.gov.uk(링크가 새 창에서 열림) 등
- Airbnb(링크가 새 창에서 열림)
- Yelp(링크가 새 창에서 열림)
- Zillow(링크가 새 창에서 열림)