使用 Tableau Prep 查找第二个日期
分析中的一项常见需求是确定第二个事件(例如客户进行第二次购买并从而成为常客,或者司机第二次交通违章时)的日期。查找第一个事件的日期很容易,它只是最小日期。查找第二个日期则较为复杂。
在这个由两部分组成的教程中,我们将调整交通违章数据并回答以下问题:
每个司机第一次和第二次违章相隔多长时间(以天数为单位)?
比较第一次和第二次违章的罚款金额。这些金额是否相关?
总体而言,哪个司机支付的罚款最多?谁支付的最少?
有多少司机有过多种类型的违章?
从未上过交通法规学习班的司机的平均罚款金额是多少?
在第一个阶段中,我们将使用 Tableau Prep Builder 针对分析重构数据。在第二个阶段Tableau Desktop 中包含第二个日期的分析中,我们将转而讲述 Tableau Desktop 中的分析。
本教程的目标是在一个真实场景的上下文中呈现各种概念并演练各个选项 — 而不是规定式地确定哪一个是最好的。最后,您应该会对数据结构对计算和分析的影响有更深的认识,并更加熟悉 Tableau Prep 的各项功能以及 Tableau Desktop 中的计算。
注意:为了完成本教程中的任务,您需要 Tableau Prep Builder(安装或通过浏览器访问),并下载相关数据。对于第二部分,您还需要安装 Tableau Desktop。
数据集为 Traffic Violations.xlsx。建议将其保存在 我的 Tableau Prep 存储库 > Datasources 文件夹中。
若要在继续学习本教程之前安装 Tableau Prep Builder 和 Tableau Desktop,请参见 Tableau Desktop 和 Tableau Prep 部署指南(链接在新窗口中打开)。否则,您可以下载 Tableau Prep(链接在新窗口中打开) 和 Tableau Desktop(链接在新窗口中打开) 免费试用版。
数据
对于此示例,我们将探讨交通违章数据。每条违章为一行。将记录司机、日期、违章类型、司机是否需要参加交通法规学习班以及罚款金额。

所需的数据结构
数据当前的构造方式是每条违章为一行。有多次违章的司机将出现在多行中,并且无法轻松分辨哪条违章是他们的第一次或第二次违章。
为了调查屡屡违章的司机,我们需要一个能够分出第一次和第二次违章日期的数据集、与其中每条违章关联的信息,并且需要每一行为一个司机。

重构数据
那么如何使用 Tableau Prep 达到该目的?我们将分阶段构建流程,首先抽取第一次违章日期,然后抽取第二次违章日期,接着根据需要调整最终数据。确保已下载了 Excel 文件 (Traffic Violations.xlsx) 以便继续操作。
第一次违章日期的初始聚合
首先,我们将连接到 Traffic Violations.xlsx 文件。
打开 Tableau Prep Builder。
从开始屏幕中,单击“连接到数据”。
在“连接”窗格中,单击“Microsoft Excel”。导航到 Traffic Violations.xlsx 的保存位置,并单击“打开”。
“Infractions”(违章)工作表应会自动显示在“流程”窗格中。
有关连接到数据的详细信息,请参见连接到数据。
接着,我们需要标识每个司机的第一次违章日期。我们将使用“聚合”步骤来执行此操作,同时创建一个包含“Driver ID”(司机 ID)和“Minimum Infraction Date”(最早违章日期)的微型数据集。
在 Tableau Prep 中使用“聚合”步骤时,任何应定义行组成内容的字段为“分组字段”。(对我们来说,该字段为“Driver ID”(司机 ID)。)任何将聚合并显示在分组字段级别的字段为“聚合字段”。(对我们来说,该字段为“Infraction Date”(违章日期)。)
在“流程”窗格中,选择“Infractions”(违章),单击加号
 图标,并选择“聚合”。
图标,并选择“聚合”。将“Driver ID”(司机 ID)拖到“分组字段”放置区域。
将“Infraction Date”(违章日期)拖到“聚合字段”区域。默认聚合为 CNT(计数)。单击“CNT”,并将聚合更改为“Minimum”。

这将标识最小(最早)日期,即每个司机的第一次违章日期。
有关聚合的详细信息,请参见清理和调整数据。
在“流程”窗格中,选择“聚合 1”,单击加号
图标,并选择“清理步骤”,以便我们能够清理聚合的输出。在“配置”窗格中,双击字段名“Infraction Date”(违章日期),并将其更改为“1st Infraction Date”(第一次违章日期)。
在此阶段,流程和配置窗格应如下所示:

从此“清理”步骤的“配置”窗格中,我们可以看到数据现在包含 39 行,并且只包含 2 个字段。未用于分组或聚合的任何字段已丢失。但我们想要能够保留一些原始信息。我们可将这些字段添加到分组或聚合中(但这样做会更改详细级别或者需要对字段进行聚合),或者将此微型数据集联接回原始数据集(本质上是为“1st Infraction Date”(第一次违章日期)向原始数据中添加一个新列)。让我们执行联接。
在“流程”窗格中,选择“Infractions”(违章),单击加号
图标,并选择“清理步骤”。请确保将鼠标直接悬停在违章步骤上,而不是它与聚合步骤之间的线上。如果在两者之间(而不是分支之间)插入新“清理”步骤,请使用工具栏中的“撤消”箭头,然后重试。菜单应显示“添加”,而不是“插入”。

这会使用所有原始数据将您的流程分支。我们会将聚合的结果联接到完整数据的这一副本。通过依据“Driver ID”(司机 ID)进行联接,我们会将聚合中的最小日期添加到原始数据中。
选择步骤“清理 2”,并将其拖到步骤“清理 1”上,放在“联接”上。
默认联接配置应该是正确的:基于“Driver ID = Driver ID”的内部联接。

有关联接的详细信息,请参见联接数据。
由于在联接过程中某些字段可能是重复的,例如联接子句中的字段,因此在执行联接之后清理无关的字段通常是个好主意。
在“流程”窗格中,选择“Join 1”(联接 3),单击加号
图标,并选择“清理步骤”。在“配置”窗格中,右键单击或按住 Ctrl 单击 (MacOS)“Driver ID-1”(司机 ID-1)卡,然后选择“移除” 。
若要更改字段顺序,请将“1st Infraction Date”(第一次违章日期)卡拖到“Driver ID”(司机 ID)和“Infraction Date”(违章日期)之间您看到黑色行出现的位置。
在此阶段,流程应如下所示:

查看下面的数据网格,我们可以看到新的合并数据集。我们有了添加到数据集中每一行的每个司机的最小(即第一次)违章日期。
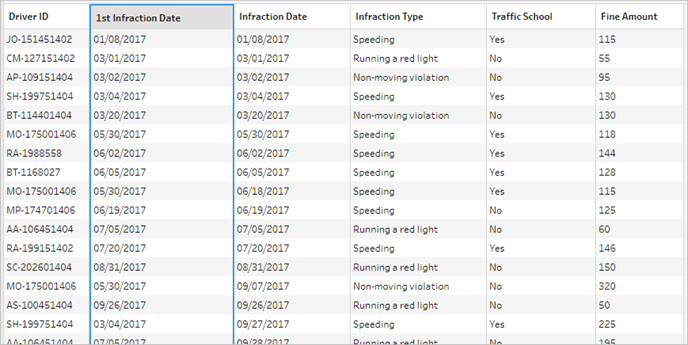
第二次违章日期的第二个聚合
我们还需要确定第二次违章日期。为此,我们需要筛选出违章日期等于最小日期的任何行 — 从而移除第一个日期。我们随后可以使用另一个聚合步骤获取剩余日期的最小值,剩下的就是第一次违章日期,为了清楚起见,我们将重命名该日期。
注意:由于我们将需要使用当前位于流程后面“清理 3”中的数据,因此我们将添加另一个“清理”步骤来获取第二次违章日期。这将在稍后使“清理 3”中数据的当前状态可用。
在“流程”窗格中,选择“Clean 3”(清理 3),单击加号
图标,并选择“清理步骤”。在“配置”窗格上的工具栏中,选择“筛选值”。创建一个筛选器
[Infraction Date] != [1st Infraction Date]。移除字段“1st Infraction Date”(第一次违章日期)。
在“流程”窗格中,选择“Clean 4”(清理 4),单击加号
图标,并选择“聚合”。将“Driver ID”(司机 ID)拖到“分组字段”放置区域。将“Infraction Date”(违章日期)拖到“聚合字段”区域,并将聚合更改为“Minimum”。
在“流程”窗格中,选择“Aggregate 2”(聚合 2),单击加号
图标,并选择“清理步骤”。将“Infraction Date”(违章日期)重命名为“2nd Infraction Date”(第二次违章日期)。
在此阶段,流程应如下所示:

我们现在为每个司机标识了第二次违章日期。为了获取与每次违章关联的所有其他信息(类型、罚款、交通法规学习班),我们需要再次将此项联接回整个数据集。
选择“清理 5”,并将其拖到步骤“清理 3”,放在“联接”上。
同样,默认联接配置应该是正确的:基于“Driver ID = Driver ID”的内部联接。
在“流程”窗格中,选择“Join 2”(联接 2),单击加号
图标,并选择“清理步骤”。删除字段“Driver ID-1”(司机 ID-1)和“1st Infraction Date”(第一次违章日期),因为不再需要这些字段。
在此阶段,流程应如下所示:

为第一次和第二次违章创建完整数据集
在执行任何进一步操作之前,让我们回顾一下,想一想我们已有的所有内容以及要如何将它们结合在一起。我们期望的最终状态是一个像这样的数据集:包含一个“Driver ID”(司机 ID)列,然后包含日期、类型、交通法规学习班列,以及第一次和第二次违章的罚款金额。
我们怎样从这里实现该目标?
在步骤“Clean 3”(清理 3)中,我们有完整的数据集,其中有一列重复显示每个司机的第一次违章日期。

我们想要清除不是第一次违章的司机的所有行,同时构建一个只包含第一次违章的数据集。也就是说,我们只想保留“第一次违章日期”与“违章日期”相等时给定司机的信息。筛选为只保留第一次违章的行之后,我们可以移除“Infraction Date”(筛选日期)字段,并整理字段名称。
同样,在进行第二次聚合和联接之后,我们有了完整的数据集,其中有一列表示第二次违章日期。

我们可以执行类似的筛选器“2nd Infraction Date = Infraction Date”以仅保留每个司机的第二次违章的信息行。同样,我们也可以移除现在多余的“Infraction Date”(违章日期)并整理字段名称。
我们将从第一个违章数据集开始。
在“流程”窗格中,选择“Clean 3”(清理 3),单击加号
图标,并选择“清理步骤”。如上文步骤 10 所示,我们希望为新的清洁步骤添加一个分支,而不是将其插入“Clean 3”(清理 3)和“Clean 4”(清理 4) 之间。
在这个新的“清理”步骤处于选定状态的情况下,在“配置”窗格的工具栏中单击“筛选值”。创建一个筛选器
[1st Infraction Date] = [Infraction Date]。移除字段“Infraction Date”(违章日期)。
将“Infraction Type”(违章类型)、“Traffic School”(交通法规学习班)和“Fine Amount”(罚款金额)字段重命名为以“1st”开头。
在“流程”窗格中的步骤下双击名称“Clean 7”(清理 7),并将其重命名为“Robust 1st”。
现在为第二个违章数据集执行操作。
在“流程”窗格中的最后一个联接后选择“Clean 6”(清理 6)。
在工具栏中单击“筛选值”。创建一个筛选器
[2nd Infraction Date] = [Infraction Date]。移除字段“Infraction Date”(违章日期)。
将“Infraction Type”(违章类型)、“Traffic School”(交通法规学习班)和“Fine Amount”(罚款金额)字段重命名为以“2nd”开头。
在“流程”窗格中的步骤下双击名称“Clean 6”(清理 6),并将其重命名为“Robust 2nd”。
在此阶段,流程应如下所示:

创建完整数据集
既然我们有了这两个包含各个司机第一次和第二次违章完整信息的两个整齐数据集,我们就可以基于“Driver ID”(司机 ID)将它们重新联接在一起,并最终生成我们期望的数据结构。
选择“Robust 2nd”,并将其拖到“Robust 1st”,放在“联接”上。
默认联接子句“Driver ID = Driver ID”应该是正确的。
由于我们不想删除没有第二次违章的司机,我们需要将此联接设为左联接。在“联接类型”区域中,单击“Robust 1st”旁边图表的无阴影区域,将其转换为“左”联接。
在“流程”窗格中,选择“Join 3”(联接 3),单击加号
图标,并选择“清理步骤”。移除重复字段“Driver ID-1”(司机 ID-1)。
数据处于期望状态,因此我们可以创建输出并继续进行分析。
在“流程”窗格中,选择新添加的“Clean 6”(清理 6),单击加号
图标,并选择“添加输出”。在“输出”窗格中,将“输出类型”更改为 .csv,然后单击“浏览”。为名称输入“Driver Infractions”(司机违章),并在单击“接受”保存之前选择所需的位置。
单击窗格底部的“运行流程”
 按钮生成输出。在状态对话框中单击“完成”关闭对话框。
按钮生成输出。在状态对话框中单击“完成”关闭对话框。
提示:有关输出和运行流程的详细信息,请参见保存和共享工作。
最终流程应如下所示:

注意:您可以下载完成的流程文件来检查您的工作:Driver Infractions.tflx
总结
对于此教程的第一个阶段,我们的目标是获取原始数据集,并准备将其用于涉及第一次和第二次违章日期的分析。该过程由三个阶段组成:
确定第一次和第二次违章日期:
创建用于保留“Driver ID”(司机 ID)和“MIN Infraction Date”(最小违章日期)的聚合。将此聚合与原始数据集联接,创建一个“中间数据集”,其中包含为每一行重复的第一次(最小)违章日期。
在新步骤上,筛选出“1st Infraction Date”(第一次违章日期)与“Infraction Date”(违章日期)相同的所有行。从该筛选的数据集中,创建用于保留“Driver ID”(司机 ID )和“MIN Infraction date”(最小违章日期)的聚合。将此聚合与第一个步骤中的中间数据集联接。这将标识第二次违章日期。
为第一次和第二次违章构建干净的数据集:
返回并依据中间数据集创建一个分支,并筛选为仅包含“1st Infraction Date”(第一次违章日期)与“Infraction Date”(违章日期)相同的行。这将只会为第一次违章构建数据集。通过移除任何不必要的字段对其进行整理,并重命名所有所需字段(“Driver ID”(司机 ID)除外),以指明它们用于第一次违章。这是“Robust 1st”数据集。
针对第二次违章日期整理数据集。通过筛选为仅保留“2nd Infraction Date”(第二次违章日期)与“Infraction Date”(违章日期)相同的行,对步骤 2 中的联接结果进行清理。移除任何不必要的字段,并重命名所有所需字段(“Driver ID”(司机 ID)除外),以指明它们用于第二次违章。这是“Robust 2nd”数据集。
将第一次和第二次违章数据合并为一个数据集:
联接“Robust 1st”和“Robust 2nd”数据集,同时确保保留“Robust 1st”中的所有记录以防止丢失没有第二次违章的任何司机。
接着,我们想要探索如何能在 Tableau Desktop 中分析此数据。
注意:特别感谢 Ann Jackson 的 Workout Wednesday 主题 Do Customers Spend More on Their First or Second Purchase?(客户在第一次或第二次购买时是否花费更多?)(链接在新窗口中打开)以及 Andy Kriebel 的 Tableau Prep 技巧 Returning the First and Second Purchase Dates(返回第一次和第二次购买日期)(链接在新窗口中打开),这些文章为本教程提供了最初的灵感。单击这些链接会使您离开 Tableau 网站。Tableau 对外部提供商所维护的页面的准确性或新鲜度不担负任何责任。如果您对其内容有任何疑问,请与所有者联系。