Part 2 - Understanding the Tableau Server Deployment Reference Architecture
Note: Tableau no longer updates the Enterprise Deployment Guide. Although we still recommend the reference architecture described here as a valid deployment model for Tableau Server in AWS, specific configuration procedures may have changed since the last update. Always cross-reference these steps with the latest Tableau Server Help(Link opens in a new window) documentation to ensure accuracy.
The following image shows the relevant Tableau Server processes and how they are deployed in the reference architecture. This deployment is considered the minimal enterprise-appropriate Tableau Server deployment.
The process diagrams in this topic are intended to show the major, defining processes of each node. There are many supporting processes that also run on the nodes that are not shown in the diagrams. For a list of all processes, see the configuration section of this guide, Part 4 - Installing and Configuring Tableau Server.
Tableau Server Processes
The Tableau Server reference architecture is a four node Tableau Server cluster deployment with external repository on PostgreSQL:
- Tableau Server initial node (Node 1): Runs required TSM administrative and licensing services that can only be run on a single node in the cluster. In the enterprise context, the Tableau Server initial node is the primary node in the cluster. This node also runs redundant application services with Node 2.
- Tableau Server application nodes (Node 1 and Node 2): The two nodes serve client requests, connect to and query data sources and to the data nodes.
- Tableau Server data nodes (Node 3 and Node 4): Two nodes that are dedicated to managing data.
- External PostgreSQL: this host runs the Tableau Server Repository process. For HA deployment you must run an additional PostgreSQL host for active/passive redundancy.
You can also run PostgreSQL on Amazon RDS. For more information about the differences between running the repository on RDS vs an EC2 instance, see Tableau Server External Repository (Linux(Link opens in a new window)).
Deploying Tableau Server with an external repository requires a Tableau Advanced Management license.
If your organization does not have in-house DBA expertise, you may optionally run the Tableau Server Repository process in the default, internal PostgreSQL configuration. In the default scenario, the Repository is run on a Tableau node with embedded PostgreSQL. In this case, we recommend running the Repository on a dedicated Tableau node, and a passive Repository on an additional dedicated node to support Repository failover. See Repository Failover (Linux(Link opens in a new window)).
By way of example, the AWS implementation described in this Guide explains how to deploy the external repository on PostgreSQL running on an EC2 instance.
-
Optional: If your organization uses external storage, you may deploy the Tableau File Store as an external service. This Guide does not include the External File Store in the core deployment scenario. See Install Tableau Server with External File Store (Linux(Link opens in a new window)).
Deploying Tableau Server with an external File Store requires a Tableau Advanced Management license.
PostgresSQL Repository
Tableau Server Repository is a PostgresSQL database that stores server data. This data includes information about Tableau Server users, groups and group assignments, permissions, projects, data sources, and extract metadata and refresh information.
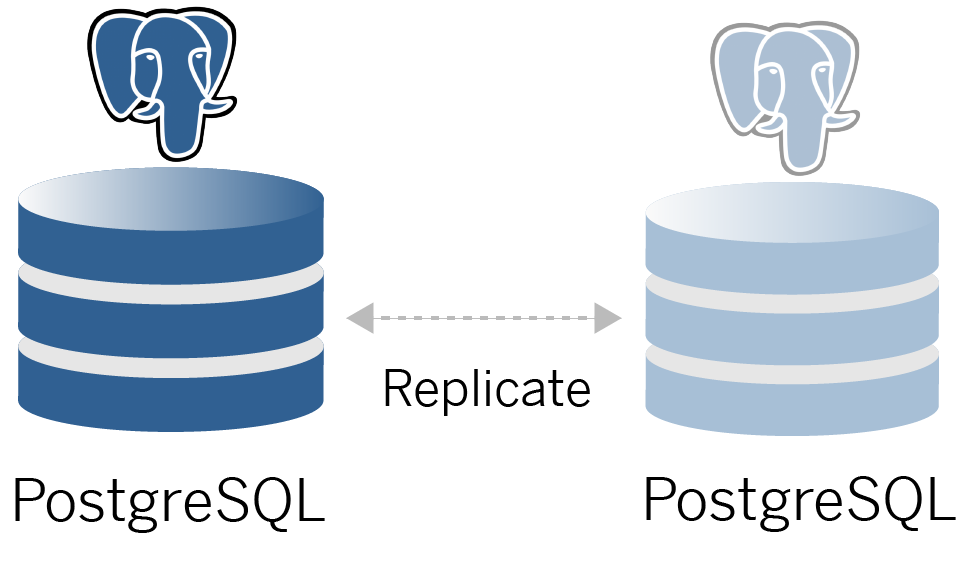
The default PostgresSQL deployment consumes almost 50% of system memory resources. Based on its usage (for production and large production deployments) resource usage can go up. For this reason, we recommend running the Repository process on a computer that is not running any other resource-intensive server components like VizQL, Backgrounder, or Data Engine. Running the Repository process along with any of these components will create IO contentions, resource constraint, and will degrade overall performance of the deployment.
Node 1: Initial node
The initial node runs a small number of important processes and shares the application load with Node 2.
The first computer you install Tableau on, the "initial node," has some unique characteristics. Three processes run only on the initial node and cannot be moved to any other node except in a failure situation, the License Service (License Manager), Activation Service, and TSM Controller (Administration Controller).
Node 1 failover and automated restoration
The License, Activation, and TSM Controller services are critical to the health of a Tableau Server deployment. In the event of a Node 1 failure, users will still be able to connect to the Tableau Server deployment, as a properly configured reference architecture will route requests to Node 2. However without these core services, the deployment will be in a critical state of pending failure. See Initial node automated recovery.
Nodes 1 and 2: Application servers
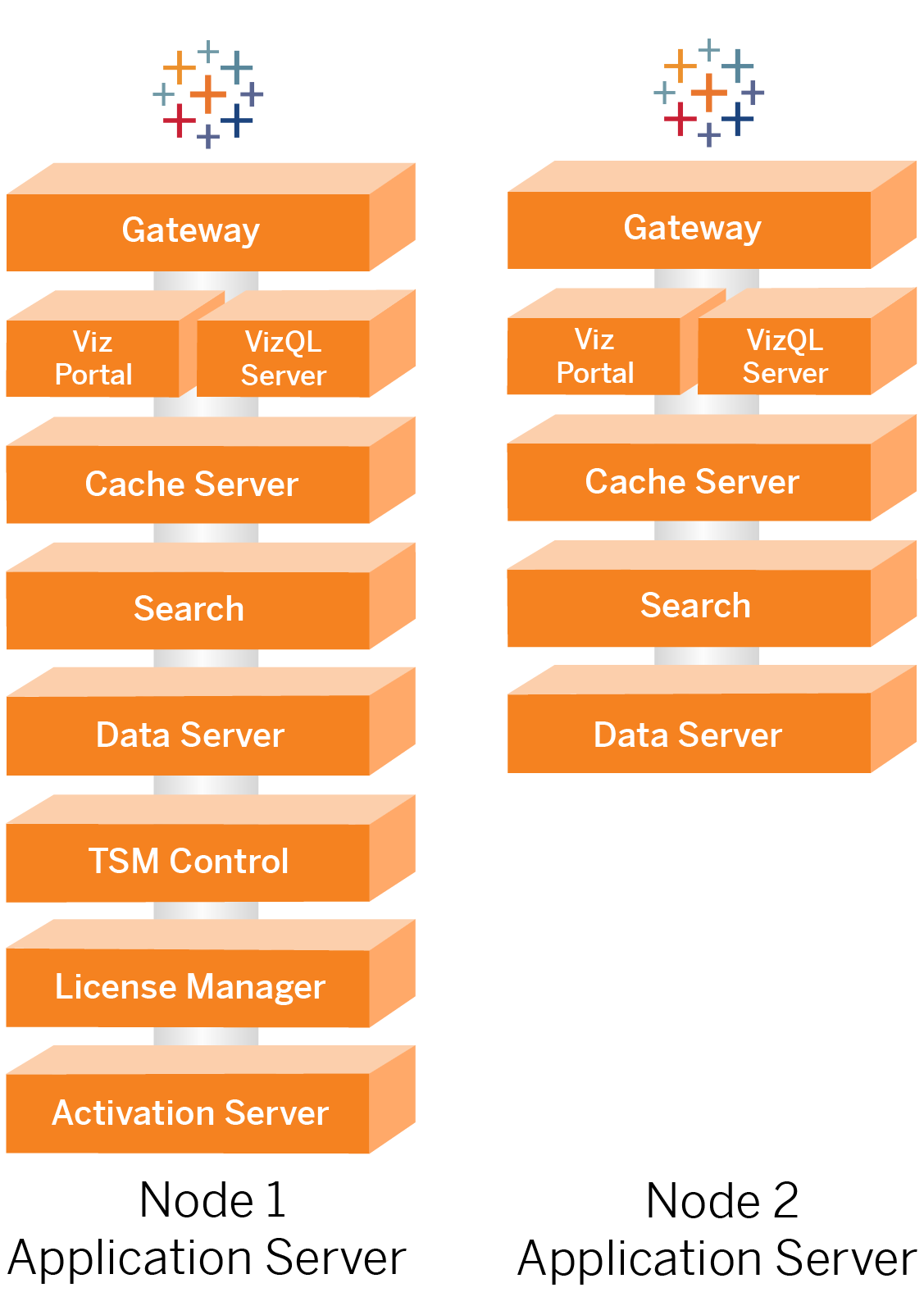
Nodes 1 and 2 run the Tableau Server processes that serve client requests, query data sources, generate visualizations, handle content and administration, and other core Tableau business logic. The application servers do not store user data.
Note: "Application Server" is a term that also refers to a Tableau Server process that is listed in TSM. The underlying process for "Application Server" is VizPortal.
Run in parallel, Node 1 and Node 2 scale to service requests from the load-balancing logic run on the reverse proxy servers. As redundant nodes, should one of these nodes fail, then client requests and servicing are handled by the remaining node.
The reference architecture has been designed so that complimentary application processes run on the same computer. This means the processes are not competing for computing resources and creating contention.
For example, VizQL, a core processing service on application servers, is highly CPU and memory-bound, VizQL uses almost 60-70% of the CPU and memory on the computer. For this reason, the reference architecture is designed so that no other memory or CPU-bound processes are on the same node as VizQL. Testing shows that the amount of the load or number users doesn’t affect the memory or CPU usage on VizQL nodes. For example, reducing the number of concurrent users in our load test only effects the performance of the dashboard or the visualization loading process, but does not reduce resource utilization. Therefore, based on the available memory and CPU during peak usage, you may consider adding more VizQL processes. As a starting place for typical workbooks, allocate 4 cores per VizQL process.
Scaling application servers
The reference architecture is designed for scale based on a use-based model. As a general starting point, we recommend a minimum of two application servers, each supporting up to 1000 users. As user base increases, plan to add an application server for each additional 1000 users. Monitor usage and performance to tune the user base per host for your organization.
Nodes 3 and 4: Data servers
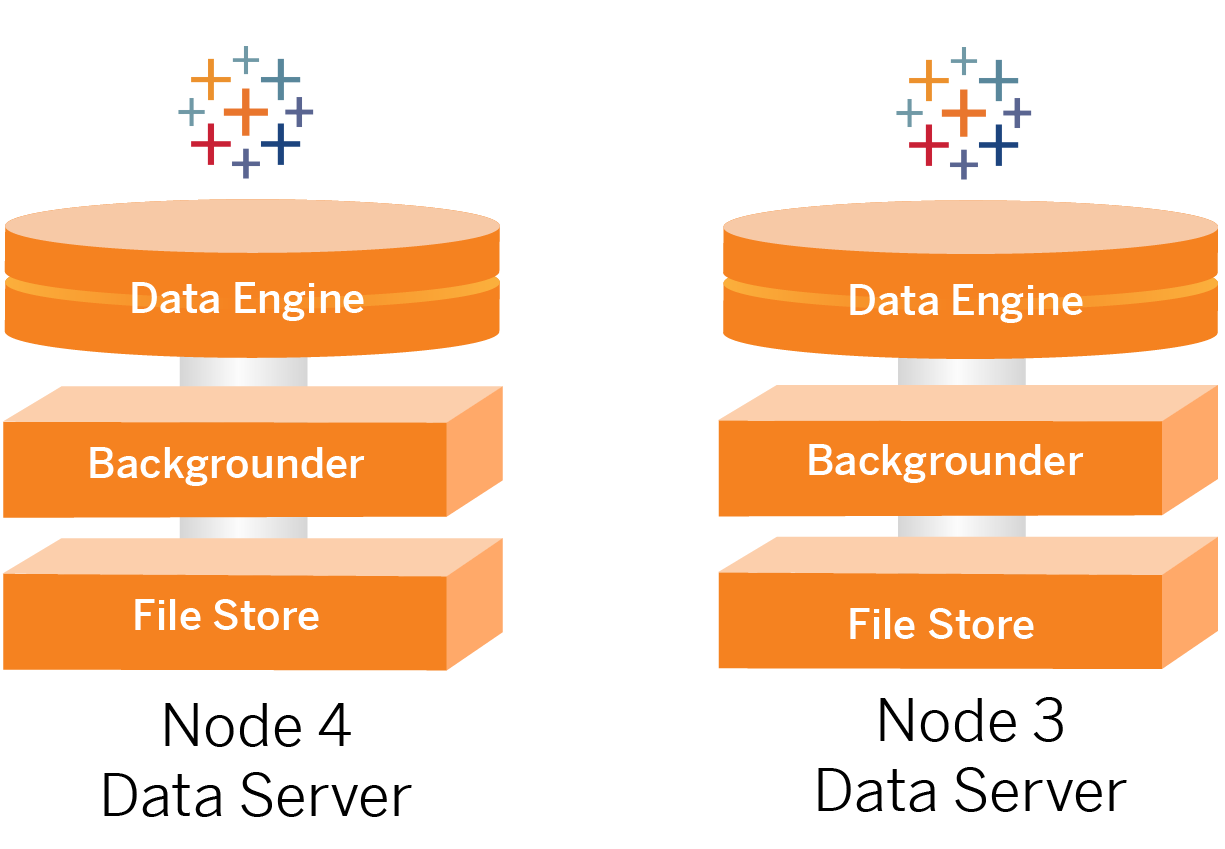
The File Store, Data Engine (Hyper), and Backgrounder processes are co-located on Nodes 3 and 4 for the following reasons:
- Extract optimization: Running Backgrounder, Hyper, and File Store on the same node optimizes performance and reliability. During the extraction process, Backgrounder queries the target database, creates the Hyper file on the same node, and then uploads to File Store. By co-locating these processes on the same node the extraction creation workflow does not require copying amounts of data across the network or the nodes.
- Complimentary resource balancing: Backgrounder is mainly CPU intensive. Data Engine is a memory-intensive process. Coupling these processes allows maximum resource utilization on each node.
- Consolidation of data processes: Since each of these processes are back-end data processes, it makes sense to run them in the most secure data tier. In future versions of the reference architecture, the application and data servers will run in separate tiers. However, due to application dependencies in the Tableau architecture, application and data servers must run in the same tier at this time.
Scaling data servers
As with application servers, planning the resources that are required for Tableau data servers requires use-based modeling. In general, assume each data server can support up to 2000 extract refresh jobs per day. As your extract jobs increase, add additional data servers without the File Store service. Generally, the two-node data server deployment is suitable for deployments that use the local filesystem for the File Store service. Note that adding more application servers does not impact performance or scale on data servers in a linear fashion. In fact, with the exception of some overhead from additional user queries, the impact of adding more application hosts and users is minimal.