预测建模中的计算依据和数据分区
通过在表计算中包括预测建模函数 MODEL_QUANTILE 或 MODEL_PERCENTILE,您可以依据数据进行预测。
请记住,所有表计算都必须指定 “计算依据”方向。有关不同寻址和分区维度如何影响结果的概述,请参见使用表计算转换值。
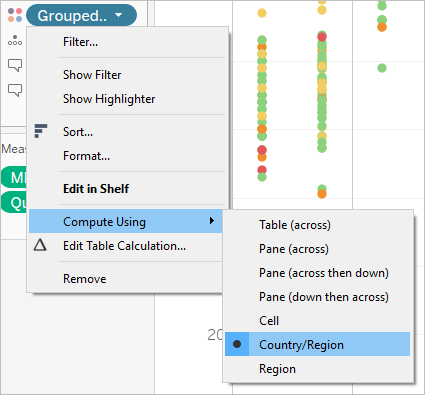
在预测建模函数中,“计算依据”选项用于对将用于构建预测模型的数据集进行分区(划定范围)。
预测建模函数没有寻址(定向)的概念,因为模型根据所选的预测因子返回每个标记的不同结果。也就是说,与“汇总”不同,寻址维度确定字段的添加顺序和结果的返回顺序,预测建模函数本质上是非连续的。它们使用模型,依据函数的目标和预测因子定义的数据,以可视化项指定的详细级别计算结果。在该数据中,除非使用有序的预测因子(例如日期维度),否则没有排序的概念。
此外,在定义用于构建模型的数据时,会始终使用可视化项的详细级别。所有表计算都与可视化项本身在同一详细级别运行,预测建模函数也不例外。
针对预测建模函数的建议
建议您在使用预测建模函数时选择要分区的特定维度。由于在单个可视化项或仪表板中可能有多个预测计算,因此选择特定的分区维度可确保为每个单独的函数使用相同的基础数据集构建模型,从而比较来自类似模型的结果。
在 Tableau 中使用预测建模函数时,必须确保在不同的实例处理中保持一致性,既在模型的不同迭代(例如,选择不同的预测因子时)中保持一致,也在不同的可视化项中保持一致。使用定向“计算依据”选项可能会使可视化数据中的细微更改显著影响用于构建模型的数据,从而影响其在不同可视化项中的有效性和一致性。
选择维度
以下示例都使用 Tableau Desktop 附带的示例 - 超市数据源。
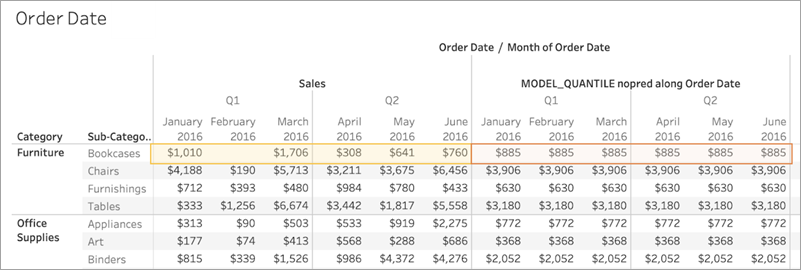
选择维度时,请记住 Tableau 将跨该维度构建预测模型。也就是说,如果选择“Order Date”(订单日期)作为分区维度,Tableau 将使用任何其他已建立的分区内的数据,但沿使“Order Date”(订单日期)的值分布。
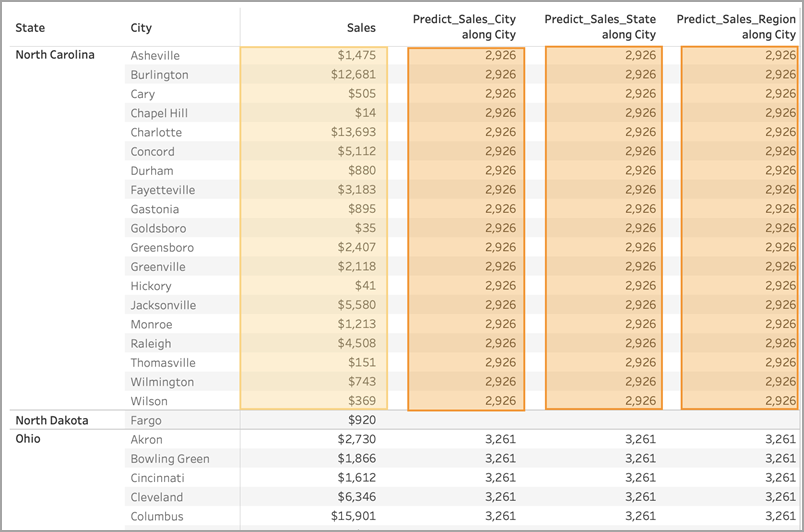
下图显示了用于构建以黄色突出显示的模型的数据,以及用于构建以橙色突出显示的模型输出的数据。在这种情况下,由于没有任何预测因子,因此给定“Sub-Category”(子类)中的所有响应都是相同的;选择最佳预测因子将帮助您生成更有意义的结果。有关最佳预测因子的信息,请参见选择预测因子。
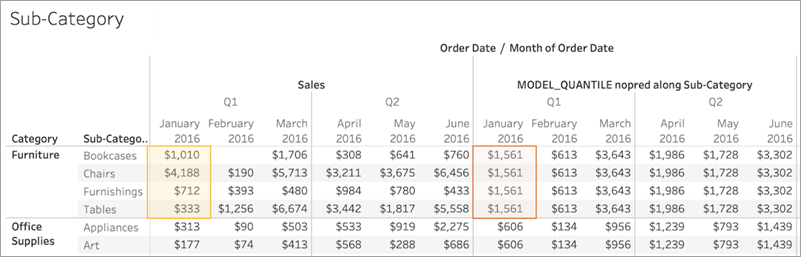
同样,如果选择了“Sub-Category”(子类)作为分区维度,Tableau 将使用给定月份内的数据,但沿多个子类分布,如下所示。如果数据进一步细分为区,则在构建模型时会考虑区边界。
关于分区的注意事项
请注意,直观地对数据进行分区对用于生成模型和生成预测的数据有显著影响。添加更高的详细级别(例如,在单个功能区上同时包括“State”(州/省/市/自治区)和 “City”(城市))将按更高的 LOD 对数据进行分区。无论按什么样的顺序将“胶囊”放在功能区上,情况都是如此。例如,这些将返回相同的预测:
 |  |
如果数据添加到“行”或“列”功能区,或添加到“标记”卡上的“颜色”、“大小”、“标签”、“详细信息”或“形状”,则添加可修改详细级别的“胶囊”数据将对数据进行分区。将不同详细级别的“胶囊”添加到工具提示不会对数据进行分区。
在下面的示例中,模型按“Category”(类别)自动分区,因为“Category”(类别)和“Sub-Category”(子类)均位于“行”上。预测计算在更高级别“胶囊”“Category”(类别)的边界内跨“Sub-Category”(子类)进行运算。
这对于预测因子的应用方式有影响。让我们看看下面的示例。在本例中,我们应用了三个 MODEL_QUANTILE 表计算:
| Predict_Sales_City | Predict_Sales_State | Predict_Sales_Region |
MODEL_QUANTILE(0.5,sum([Sales]),
| MODEL_QUANTILE(0.5,sum([Sales]),
| MODEL_QUANTILE(0.5,sum([Sales]),
|
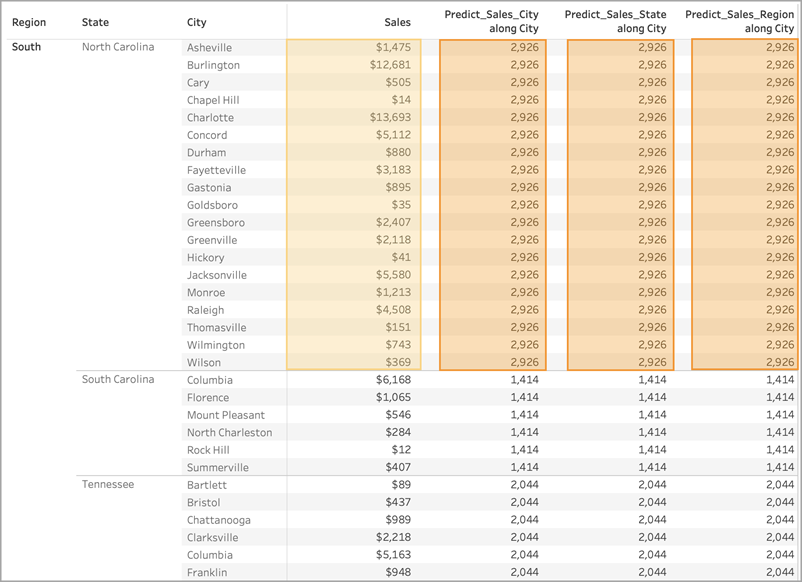
对于所有三个计算,我们都选择了“计算依据”>“City”(城市)。让我们来看看北卡罗来纳州的一些城市:
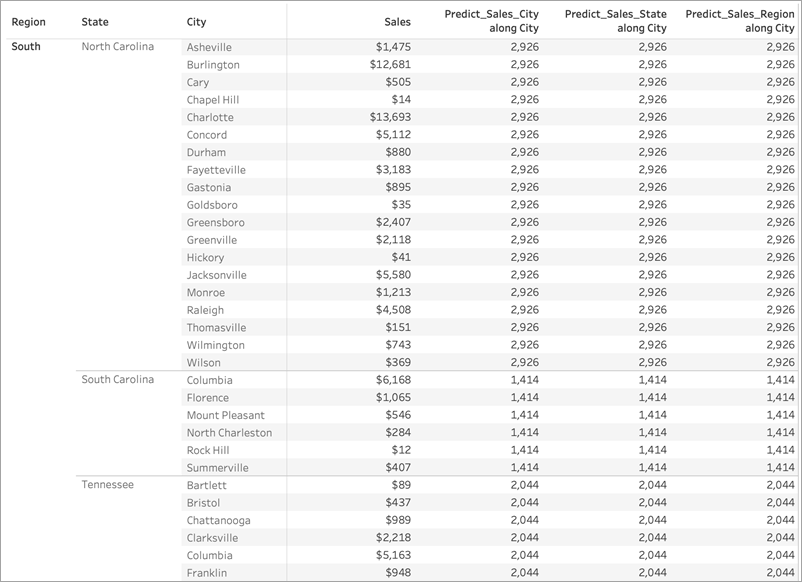
请注意,尽管使用不同的预测因子,但所有三个计算的结果在给定的州内是相同的。
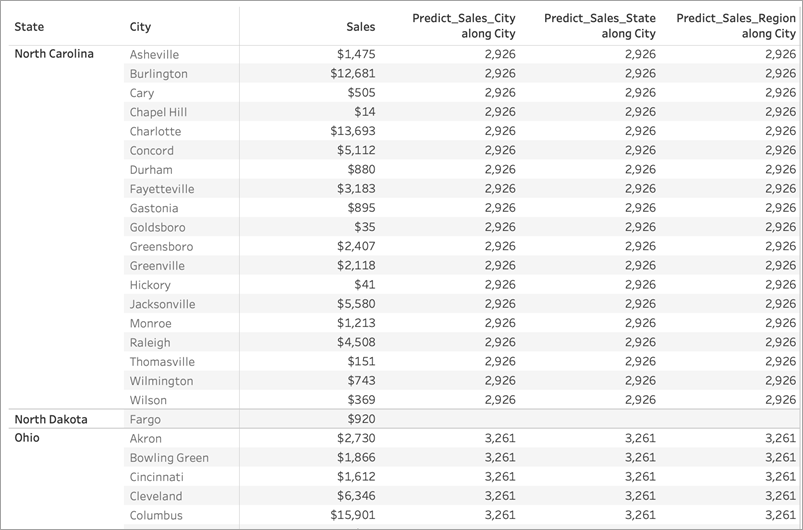
如果我们从“行”功能区中移除“Region”(区域),则结果不会发生任何情况 - 它们在给定的州内仍然完全相同:
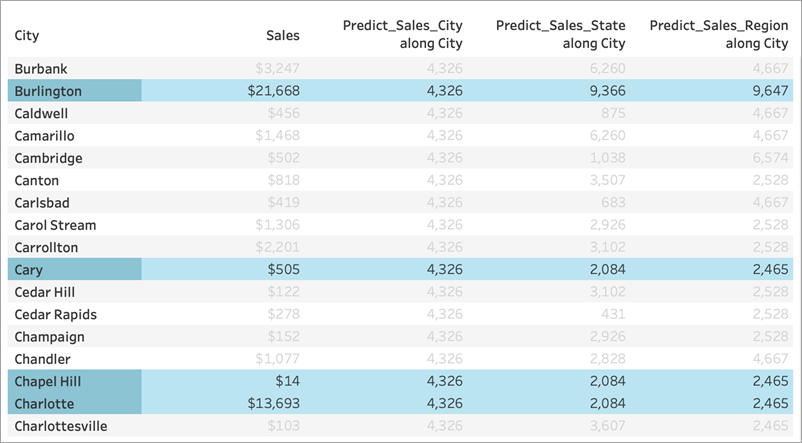
但是,当我们从“行”功能区中移除“State”(州/省/市/自治区),对于每个计算我们会看到不同结果:
怎么回事?
在第一个示例中,“行”功能区上的“Region”(区域)和“State”(州/省/市/自治区)对城市进行分区。因此,Predict_Sales_City、Predict_Sales_State 和 Predict_Sales_Region 的模型接收相同的数据并生成相同的预测。
由于我们已经直观地对“State”(州/省/市/自治区)和“Region”(区域)内的数据进行了分区,因此我们的预测因子都没有为模型添加任何值,并且不会影响结果:
当我们从“行”功能区中移除“Region”(区域)时,我们仍然按“State”(州/省/市/自治区)进行分区,因此对用于构建模型的数据没有更改。同样,由于我们已经直观地对“State”(州/省/市/自治区)内的数据进行了分区,因此我们的预测因子都不会为模型添加任何值或对结果产生任何影响。
但是,当我们移除“State”(州/省/市/自治区)时,数据将被解分区,因此对于每个计算我们将看到不同的预测。让我们仔细看看那里发生了什么:
对于 Predict_Sales_City,我们使用 ATTR([City]) 作为预测因子。由于这与可视化项处于相同的详细级别,因此它未添加任何值,并且会被忽略。我们正在聚合所有城市的“Sales”(销售额),将它们传递到统计引擎,并计算预测的销售额。由于未包括其他预测因子,因此对于每个城市都会看到相同的结果;如果我们包括了一个或多个度量,我们将看到结果的变化。
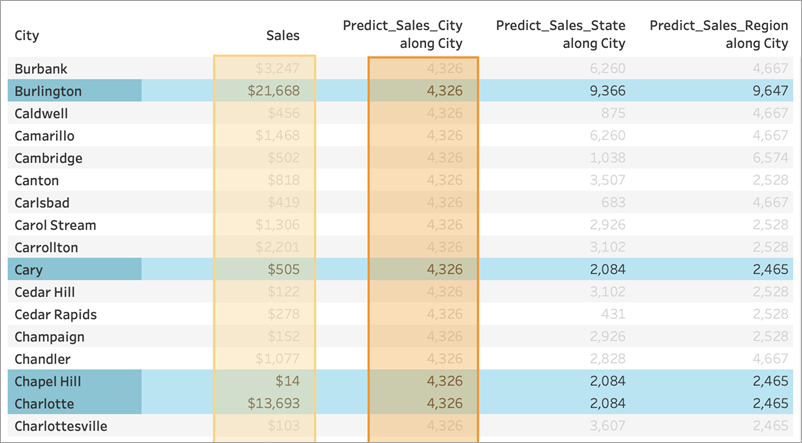
对于 Predict_Sales_State,我们使用 ATTR([State]) 作为预测因子。预测因子按“State”(州/省/市/自治区)对所有“City”(城市)数据进行分区。我们希望在一个州内看到相同的结果,但对于每个州看到不同的结果。
但请注意,这并不完全是我们所得到的。正如我们所料,卡里市、教堂山市和夏洛特市的预测都一样,都是 2084 美元。然而,伯灵顿向我们展示了 9366 美元的不同预测:
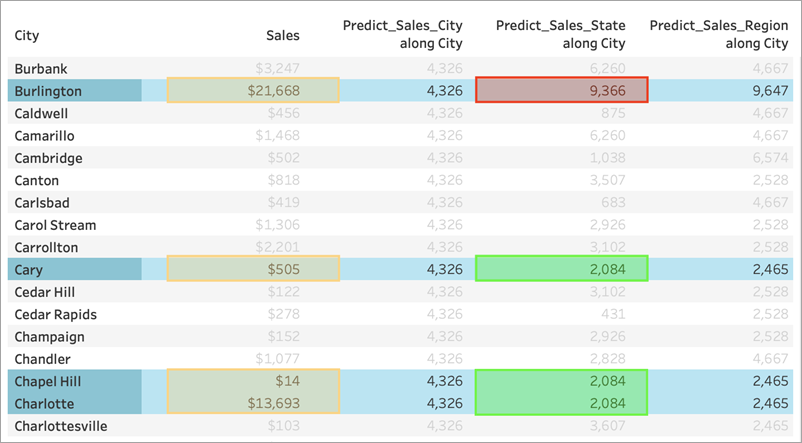
这是因为名为“伯灵顿”的城市存在于多个州(爱荷华州、北卡罗来纳州和佛蒙特州)。因此,“State”(州/省/市/自治区)解析为 *,意思是“多个值”。“State”(州/省/市/自治区)解析为 * 的所有标记将一起计算,因此在多个州中也存在任何其他城市的预测也会为 9366 美元。
对于 Predict_Sales_Region,我们使用 ATTR([Region]) 作为预测因子。预测因子按“Region”(区域)对所有“City”(城市)数据进行分区。您希望在一个区域内看到相同的结果,但对于每个区域看到不同的结果。
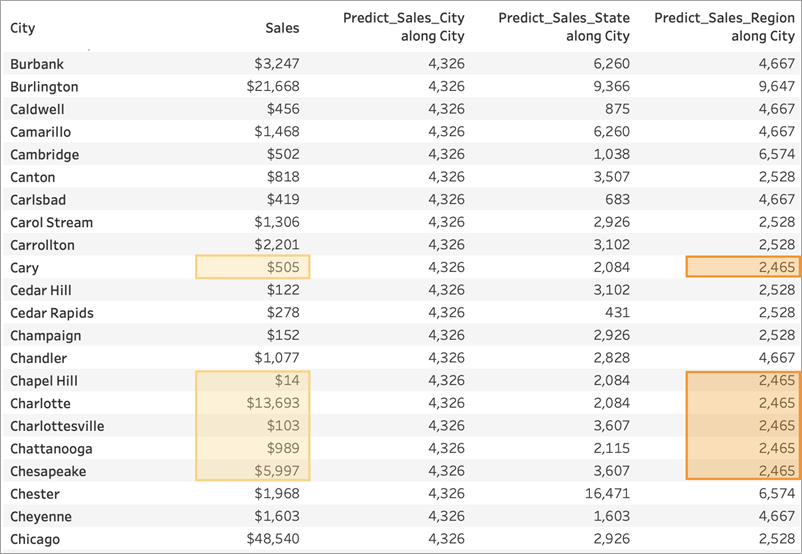
同样,由于伯灵顿存在于多个区域(中部、东部和南部)内,因此“Region”(区域)解析为 *。伯灵顿的预测将只与存在于多个区域内的城市相匹配。
如您所见,确保任何维度预测因子与可视化项的详细级别和分区正确对齐非常重要。按任何维度细分可视化项可能会对预测产生意外影响。