关联基数和引用完整性
无论您如何组合数据,设置数据源都需要了解每个表的数据结构以及它们的组合方式。需要考虑几个关键要素:
- 详细级别:数据的详细程度 — 其粒度。可将其视为“行的定义是什么?”问题的答案。有关粒度的详细信息,请参见构造用于分析的数据
- 共享字段:至少必须有一个可用于在表之间形成链接的字段。对于联接,这些字段定义联接子句。在相关表中,它们建立了关系。
- 关联基数:共享字段有多少个唯一值(唯一性)。有关详细信息,请参见下一部分。
- 引用完整性:一个表中的值保证另一个表中具有匹配项。换句话说,一个表中不能有另一个表中没有相应记录的记录。有关详细信息,请参见下文。
关联基数
单个列或字段中的关联基数是指值的唯一程度。低关联基数意味着只有几个唯一值(例如在表示眼睛颜色的字段中)。高关联基数意味着有很多唯一值(例如在表示电话号码的字段中)。
表之间的关联基数相似,但指的是一个表中的行是否可以链接到另一个表中的多个行。(请务必记住,关联基数不会解决这两个表中是否有缺失数据的问题。缺少数据的情况是指引用完整性。尽管这些概念协同工作,但它们是关系的两个不同属性。)
选项包括一对一、一对多、多对一或多对多。
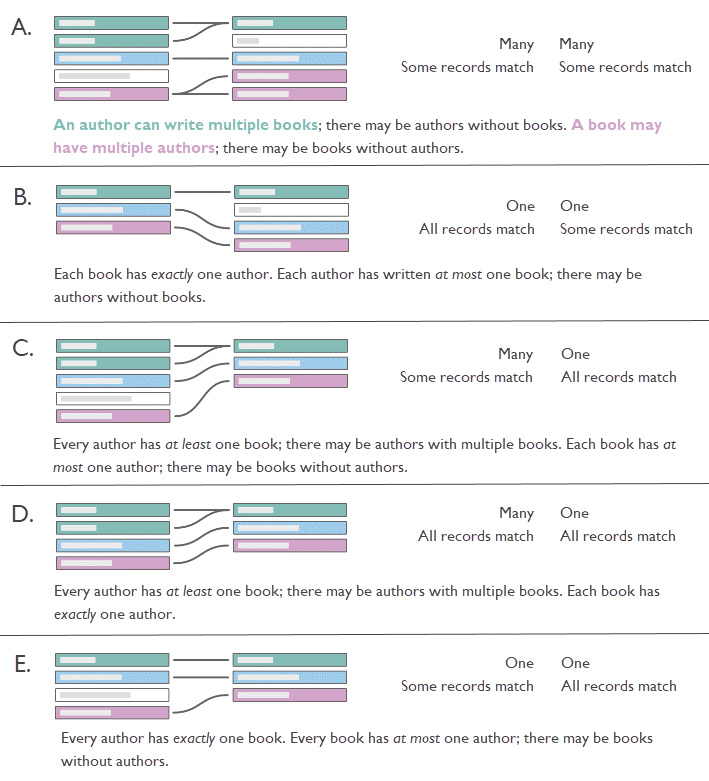
一对一
示例:每辆车都有自己的车牌,车牌是特定于一辆汽车的。汽车与车牌的关系是一对一的。 请注意,即使汽车未注册或车牌号尚未分配给汽车,该差异也由引用完整性描述。汽车只能有一个车牌,车牌只能分配给一辆车,所以关联基数一直是一对一。 |
 |
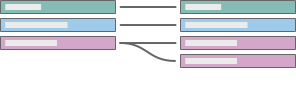
一对多或多对一
示例:多名雇员同属于一名经理。员工与经理的关系是多对一的。经理与员工的关系是一对多的。 |
|
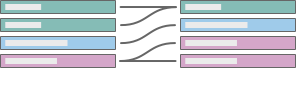
多对多
示例:一名演员出演多部电影,而一部电影有多名演员。演员与电影的关系是多对多的。在同一笔交易中可以购买多本书,也可以多次购买一本书。ISBN 与订单 ID 的关系是多对多的。 |
 |
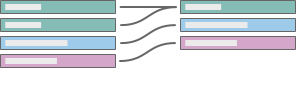
可以在“性能选项”设置中指定关联基数。有关详细信息,请参见使用性能选项优化关系查询。
引用完整性
有一个称为引用完整性的相关概念,这意味着一个表中的行在另一个表中将始终具有匹配行,由其共享字段的值确定。如果数据库不包含车辆无车牌或车牌或车辆的记录,则这种关系具有引用完整性。
在 Tableau 中,引用完整性在关系的每一端配置。在“性能选项”设置中,某些记录匹配意味着没有(或者您不知道是否有)引用完整性。所有记录匹配意味着存在引用完整性。默认设置是不假定引用完整性(某些记录匹配)。
有关详细信息,请参见使用性能选项优化关系查询。
自测
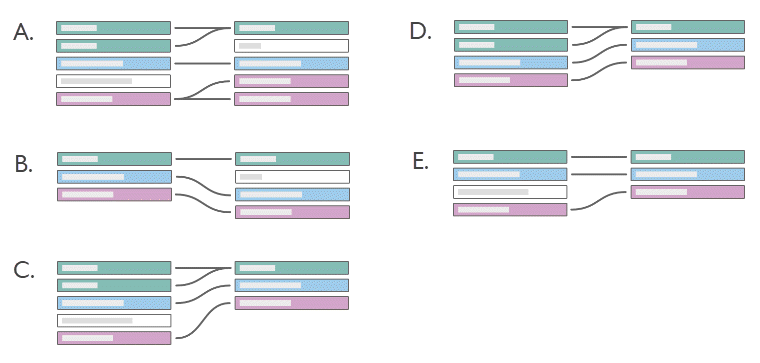
您能否定义每个图表的关联基数和引用完整性?这在文字上是什么意思?
示例:
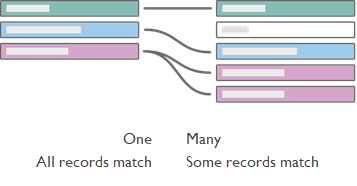
如果我们将左表设置为书籍,将右表设置为在 AuthorID 上链接的作者,将图表转换为文本:
- 一本书可以有多名作者(紫色记录在左侧的图书表中显示一行,与右侧作者表中的多条记录相对应)。
- 没有作者有多本书(右侧的每条作者记录仅指向的一条图书记录)。
- 不存在没有作者的图书(左侧没有记录不能与右侧的记录对应)。
- 有些作者可能没有图书(右侧的灰色作者记录在左侧没有对应的图书记录。)
单击下面的每个部分将共展开。
为什么这很重要?
正确配置关联基数或引用完整性设置可以通过查询优化提高性能。但是,不正确的配置可能会导致由于数据丢失或重复而出现聚合问题。默认的“性能选项”设置为对关联基础为“多”,对于引用完整性为“某些记录匹配”。只有在确定数据的正确特征时,才应调整这些设置。
有关 Tableau 如何处理每个设置的详细信息,请参见基数和引用完整性设置的含义。
Tableau 中的一个示例
让我们来探讨一下当关联基数配置不正确时会发生什么。
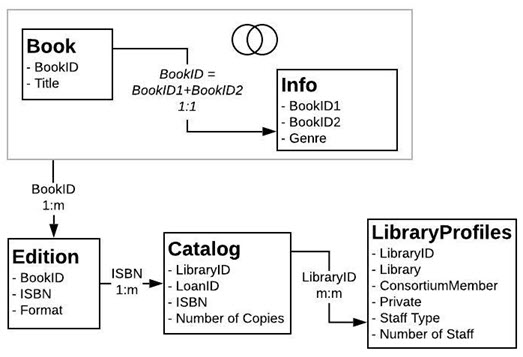
注意:以下示例使用Bookshop 数据集中表子集。您可以 下载工作簿进行操作,也可以下载原始数据以自行创建数据源。使用的表为 Bookshop.xlsx 中的“Books”(图书)、“Info”(信息)和“Edition”(版本)(只保留一些字段),以及 BookshopLibraries.xlsx 中的“LibraryProfile”(图书馆资料)和“Catalog”(目录)。
“Book”(图书)和“Info”(信息)表具有一对一的关系 —“Info”(信息)本质上是“Book”(图书)表的附加列。因此,虽然它们可能相关,但联接它们以创建包含所有列的新逻辑表是有意义的。“Edition”(版本)与这个组合表具有多对一的关系,因为单一图书可能有多个版本,通常具有不同的格式。(请注意,下图显示了从“Book+Info”(图书+信息)表到“Edition”(版本)的关系,因此为一对多。)
“Edition”(版本)与“Catalog”(目录)相关,作为 ISBN 上的一对多关系。“Catalog”(目录)和“LibraryProfile”(图书馆资料)表在“Library Id”(图书馆 ID)上具有多对多关系。关键点是,“LibraryProfiles”(图书馆资料)表的每个库有多个行,每个人员类型(图书馆员、图书馆助理、图书馆技术人员)一行。有关这些表的结构的详细信息,请参见Bookshop 数据集。
正确的设置
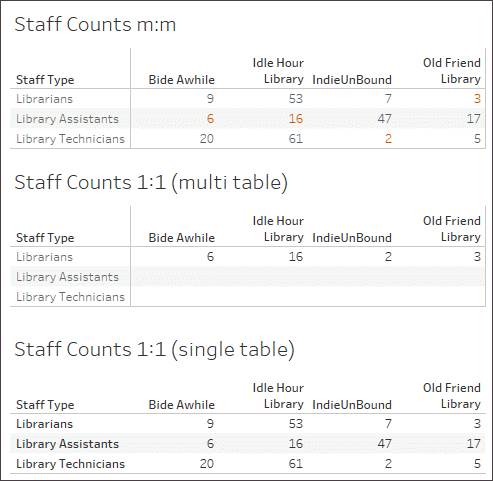
正确设置“Catalog-LibraryProfile”(目录-图书馆资料)关系后,我们可以创建一个简单的可视化项,显示每个图书馆对应于多本图书的工作人员数量。这个要建立的可视化项有点愚蠢,但它有助于说明这一点。Idle Hour Library(休闲图书馆)有 130 名员工, 不管我们谈论的是哪本书。员工类型有三个值,因此每个总计由三条记录(括号中的数字)组成。
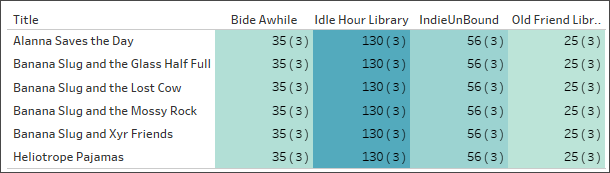
工作人员按图书馆和书名称计数。(括号中的数字表示每个标记中的记录数。)
错误的设置:一对一
当关系被错误地设置为一对一时,在可视化项中,“Catalog”(目录)中的每个书名仅与“LibraryProfile”(图书馆资料)表中的一条记录进行有效配对(如括号中的记录计数所示)。
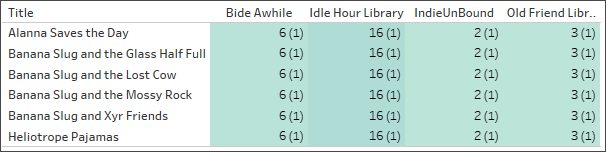
工作人员按图书馆和书名称计数。(括号中的数字表示每个标记中的记录数。)
在上面,我们可以看到每个图书馆只显示其最少工作人员数量。(请参阅下面的可视化项中的粗体数字。“Staff Count”(工作人员计数)可视化项中反映的数量是最少工作人员数量。
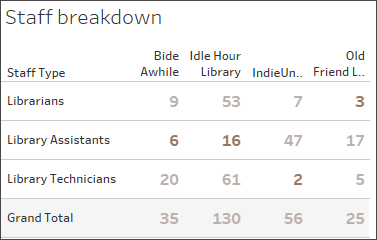
按类型和图书馆分列的工作人员。
有关关系如何成为可视化项的上下文联接的详细信息,请参见 Tableau 博客上的 Tableau 博客中的新数据建模简介(链接在新窗口中打开)。
错误的设置:联接
虽然有办法解决这类问题(详细级别表达式是通用的),但联接具有不同粒度或其关联基数为“多”的表可能会导致重复。在这里,对于只有一种格式的书名,工作人员计数是准确的,但对于在“Editions”(版本)表中具有两种格式的图书,传递到工作人员计数的值也会翻倍(请注意,括号中的记录计数为 6 而不是正确的 3)。
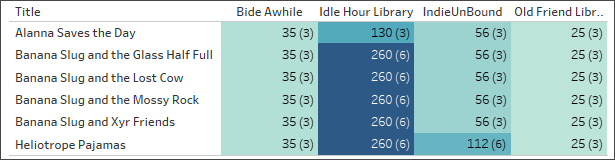
工作人员按图书馆和书名称计数。(括号中的数字表示每个标记中的记录数。)
错误的设置:错误地假设引用完整性
在不存在引用完整性的情况下,告知 Tableau 存在引用完整性(所有记录匹配)可能会导致值丢失。在这里,这两个可视化项是相似的,但右侧的一个来自配置为假定引用完整性的数据源。那个可视化项已经丢失了 null。虽然这在某些情况下可能没问题,但了解这些 null 代表什么非常重要。此处,如果可视化项显示每个图书馆中的版本数,则 null 表示版本表中存在但不属于任何图书馆的两个版本。这可能是一个重要的疏忽,而且错误地假设引用完整性会忽略这种疏忽。
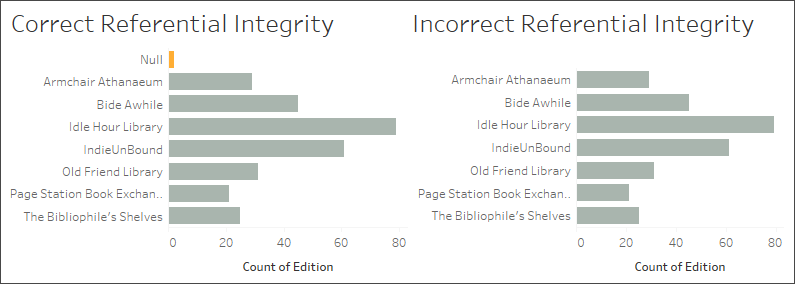
浏览工作簿及其数据源,了解合并不当的表可能产生哪些其他问题。
性能影响
如果这些设置配置错误可能导致数据丢失或重复,为什么 Tableau 允许更改它们?在许多情况下,您可以而且应该保留默认设置:关联表而不是联接,将关联基数保留为多对多,并且不假定引用完整性。特别是在您不确定设置应该是什么的情况下更应如此。
但是,关联基数和引用完整性是性能选项,因为可能会对默认值产生性能影响。如果您确定数据的结构,配置正确的设置可以减少查询执行,从而提高速度。
在幕后
注意:本节使用与其他数据组合技术类似的技术来仅提供概念框架。它不是有关 Tableau 如何使用关系性能设置的技术描述。
关联基数
关系的关联基数会影响聚合的发生时间。这可以从混合的角度来考虑。数据混合会独立查询两个数据源。无论其他数据源如何,每个数据源都会根据需要聚合到视图所需的详细级别。对于关系,关联基数设置会影响聚合是在联接之前还是之后发生。
在上面的示例中,“多”设置表示在将数据与图书信息合并之前对每个图书馆的工作人员数量进行聚合,从而确保每本书都有正确的数量。当关联基数错误地设置为“一” 时,在将工作人员数量与图书数据合并之前不会聚合,从而导致不正确的值。
请注意,不仅会显示不正确的值,所有值都分配给工作人员类型“ Librarians”(图书馆员),尽管它们来自所有三种工作人员类型。此设置配置错误可能会导致不可预测和不正确的值。只有在视图中使用来自错误设置的关系另一端的另一个表的字段时,才会发生此结果筛选。
但是,在这些值唯一的情况下,如果 Tableau 优化查询,则可以自由移除联接前的聚合。
引用完整性
尽管引用完整性是指关系的设置,但可以从联接类型的角度考虑它。完全外部联接将保留所有记录,无论另一个表中是否有匹配项,但会以性能成本计算。如果您不确定记录是否会丢失,外部联接会更安全。当可能没有引用完整性时,这是处理表的方式(某些记录匹配)。
内部联接将仅保留两个表中有匹配项的记录,同时会删除不出现在每个表中的记录。如果您知道内部联接不会消除必要的数据,则效率更高。如果“性能选项”设置为“所有记录匹配”,则假定引用完整性,并在不考虑不匹配值的情况下执行联接。
不正确的引用完整性设置可能会对组合数据产生类似筛选器的效果,从而移除不匹配的值。有关保留不匹配记录的功能的详细信息,请参见 Tableau 博客上的跨多个相关表提出问题。有关联接类型数据的详细信息,请参见联接数据。
保留默认值
如果您的分析具有可接受的性能,我们强烈建议将默认的“性能选项”设置保留为多对多,而不是假定引用完整性。关系的力量来自于它们根据分析中使用的表提供准确、上下文适当的结果的能力。更改这些设置会移除关系的语义灵活性。