Cardinality and Referential Integrity
Setting up a data source, no matter how you combine the data, requires an understanding of the data structure of each table and how they can be combined. There are several key elements that should be considered:
- Level of detail: how detailed the data is – its granularity. This can be thought of as answering the question, ‘What defines a row?’. For more information on granularity, see Structure Data for Analysis
- Shared field: there must be at least one field that can be used to form the link between tables. For a join, these fields define the join clause. In related tables, they establish the relationship.
- Cardinality: how many or how few unique values there are for the shared field (uniqueness). For more information, see the next section.
- Referential Integrity: a value in one table is guaranteed to have a match in the other table. In other words, there can’t be a record in one table that does not have a corresponding record in the other table. For more information, see below.
Cardinality
Cardinality in a single column or field refers to how unique its values are. Low cardinality means there are only a few unique values (such as in a field for eye colour). High cardinality means there are a lot of unique values (such as in a field for phone numbers).
Cardinality between tables is similar, but refers to whether a row from one table could be linked with more than one row in another table. (It’s important to remember that cardinality does not address whether there is missing data in either table. The presence or absence of missing data is referential integrity. Although these concepts work together, they are two different attributes of the relationship.)
The options are one-to-one, one-to-many, many-to-one or many-to-many.
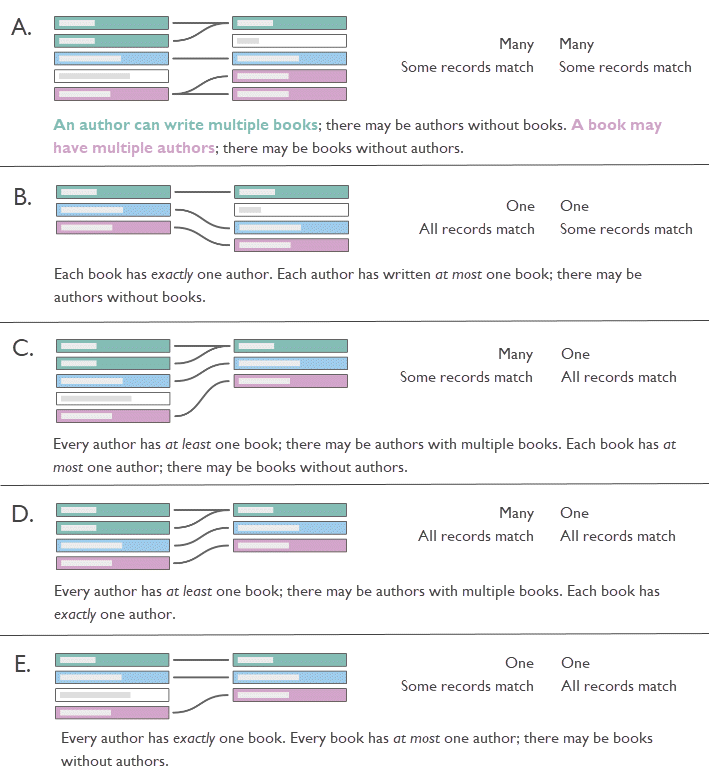
One-to-one
Example: Every car has its own number plate and a number plate is specific to an individual car. Car-to-number plate is one-to-one. Note that even if a car is unregistered or a registration number hasn’t yet been assigned to a car, that discrepancy is described by the referential integrity. A car can only have one number plate and a number plate can only be assigned to one car, so the cardinality remains one-to-one. |
 |
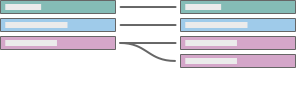
One-to-many or Many-to-one
Examples: Many employees have the same manager. Employees-to-manager is many-to-one. Manager-to-employee is one-to-many. |
|
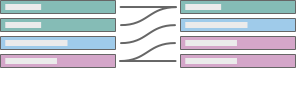
Many-to-many
Examples: An actor is in many films and a film has many actors. Actor-to-film is many-to-many. Multiple books can be purchased in the same transaction and a book can be purchased multiple times. ISBN-to-OrderID is many-to-many. |
 |
Cardinality can be specified in the Performance Options settings. For more information, see Optimise Relationship Queries Using Performance Options.
Referential Integrity
There’s a related concept called referential integrity, which means a row in one table will always have a matching row in the other table, as determined by the value of their shared fields. If the database contains no records for cars without number plates or number plates without cars, that relationship has referential integrity.
In Tableau, referential integrity is configured on each side of the relationship. In the Performance Options settings, Some records match means there isn’t (or you don’t know if there is) referential integrity. All records match means there is referential integrity. The default setting is to not assume referential integrity (Some records match).
For more information, see Optimise Relationship Queries Using Performance Options.
Test yourself
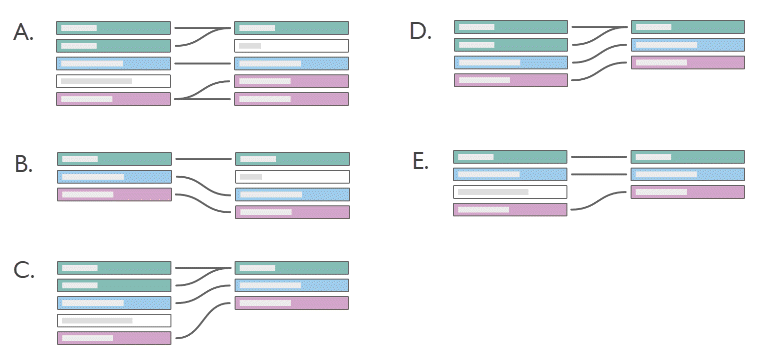
Can you define the cardinality and referential integrity of each diagram? What does this mean in words?
Example:
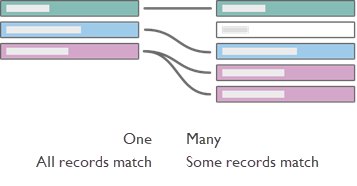
If we set the left table as books and the right table as authors linked on AuthorID, translate the diagram into words:
- One book can have multiple authors (the purple records show one row in the book table on the left corresponding to multiple records in the author table on the right).
- No authors have more than one book (each author record on the right leads only one book record on the left).
- There are no books without authors (no records on the left fail to correspond to a record on the right).
- Some authors may not have books (the grey author record on the right has no corresponding book record on the left.)
Click each section below to expand it.
Why does it matter?
Correctly configuring the cardinality or referential integrity settings can boost performance through query optimisation. Incorrect configurations, however, can lead to issues of aggregation due to loss or duplication of data. The default Performance Option settings are Many for cardinality and Some records match for referential integrity. These should only be adjusted if you are sure of the correct characteristics of your data.
For more information about how Tableau handles each setting, see What the Cardinality and Referential Integrity settings mean.
An example in Tableau
Let’s explore what happens when cardinality is configured improperly.
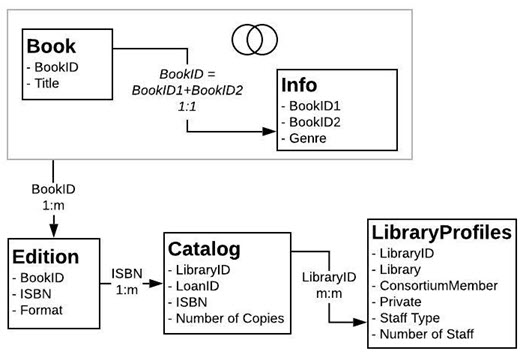
Note: The following example uses a subset of tables from The Bookshop Dataset. You can download the workbook to follow along, or download the raw data to create the data sources yourself. The tables used are Books, Info and Edition from Bookshop.xlsx (keeping only some fields) and LibraryProfile and Catalogue from BookshopLibraries.xlsx.
The Book and Info tables have a one-to-one relationship – Info is essentially additional columns for the Book table. Because of this, while they could be related, it makes sense to join them to create a new logical table that has all the columns. Edition has a many-to-one relationship with this combined table as there can be multiple editions for a single book, usually with different formats. (Note that the diagram below shows the relationship from the Book+Info table to Edition, so it is one-to-many.)
Edition is related to Catalogue as a one-to-many relationship on ISBN. The Catalogue and LibraryProfile tables are related many-to-many on Library ID. The key point is that the LibraryProfiles table has multiple rows per library, one for each staff type (Librarian, Library Assistant, Library Technician). For more information about the structure of these tables, see The Bookshop Dataset.
The right settings
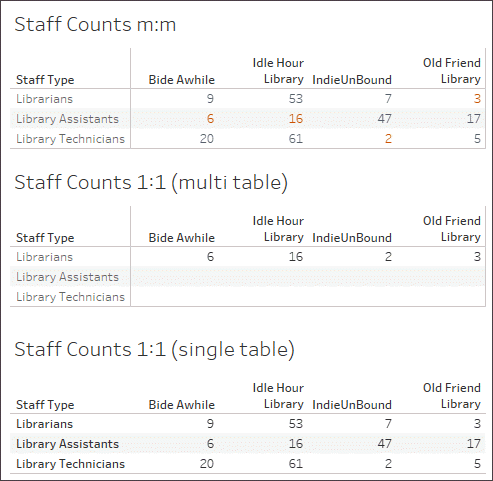
When the Catalogue-LibraryProfile relationship is set up correctly, we can make a simple viz that shows the number of staff for each library for several books. This is a silly viz to make, but it’s useful to illustrate the point. Idle Hour Library has 130 staff regardless of which book we’re talking about. There are three values for staff type, so each total is made up of three records – the number in parentheses.
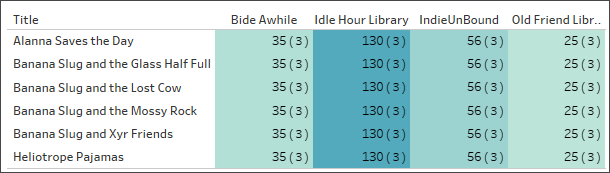
Staff count by library and title. (Numbers in parentheses indicate the number of records in each mark.)
The wrong settings: one-to-one
When the relationship is erroneously set as one-to-one, in the viz each title from Catalogue is effectively paired with only one record from the LibraryProfile table (as indicated by the record count in parentheses).
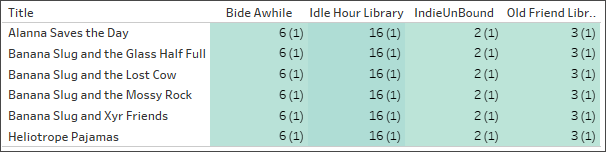
Staff count by library and title. (Numbers in parentheses indicate the number of records in each mark.)
Above, we can see that each library only displays their minimum number of staff. (Refer to the bold numbers in the viz below. The lowest number of staff is the number reflected in the Staff Count viz.)
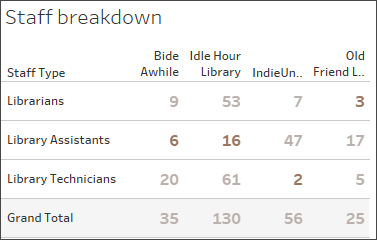
Staff breakdown by type and library.
For more information about how relationships become contextual joins for a viz, see Introducing the new data modelling in Tableau(Link opens in a new window) on the Tableau blog.
The wrong setting: joining
While there are ways to work around this sort of issue – Level of Detail expressions being a common one – joining tables that have different granularity or ‘many’ in their cardinality can cause duplication. Here, the staff counts are accurate for titles that only have one format, but for the books that have two formats in the Editions table, that doubling is passed along to the staff counts as well (note the record counts in parentheses that are 6 instead of the correct 3).
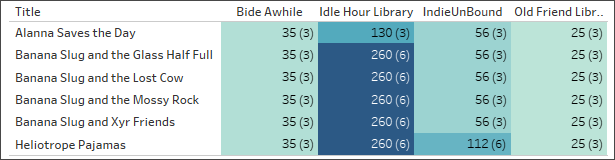
Staff count by library and title. (Numbers in parentheses indicate the number of records in each mark.)
The wrong setting: incorrectly assuming referential integrity
Telling Tableau there is referential integrity (all records match) when this isn’t the case can cause dropped values. Here, these two vizzes are similar but the one on the right is from a data source configured to assume referential integrity. That viz has lost the nulls. While this can be fine in some circumstances, it’s important to understand what those nulls represent. Here, where the viz shows the number of editions in each library, the nulls indicate two editions that are present in the edition table but aren’t held by any library. This could be an important oversight, and it’s one that incorrectly assuming referential integrity would overlook.
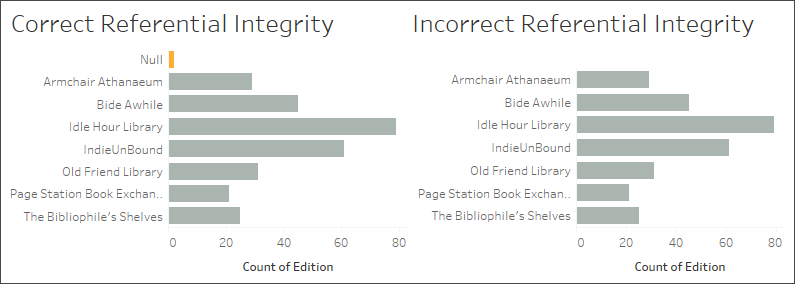
Explore the workbook and its data sources to see what other issues may arise from improperly combined tables.
Performance impacts
If mis-configuring these settings can cause missing or duplicated data, why does Tableau allow them to be changed at all? In many cases, you can and should leave the default settings: relate tables instead of joining, leave the cardinality as many-to-many and don’t assume referential integrity. Especially if you’re not sure what the settings should be.
However, cardinality and referential integrity are Performance Options because there can be performance implications to the defaults. If you’re sure about the structure of your data, configuring the correct settings can reduce the query execution to improve the speed.
Under the hood
Note: This section uses analogies to other data combination techniques to provide a conceptual framework only. It is not a technical description of how Tableau uses the performance settings for relationships.
Cardinality
The cardinality of the relationship impacts when aggregation happens. This can be thought of in terms of blending. Data blending queries two data sources independently. Each data source is aggregated as necessary to the desired level of detail for the view regardless of the other data source. For relationships, the cardinality setting impacts whether the aggregation happens before or after the join.
In the example above, the Many setting means the number of staff for each library is aggregated before combining that data with the book information, thus ensuring every book has the correct numbers. When the cardinality was incorrectly set to One, the number of staff was not aggregated before it was combined with the book data, leading to incorrect values.
Note that not only are the incorrect values shown, all the values are assigned to the staff type Librarians, despite the fact that they are taken from all three staff types. Misconfiguration of this setting can cause unpredictable and incorrect values. This filtering of results only happens when a field from another table on the other side of the incorrectly set relationship is used in the view.
If the values are unique, however, Tableau is free to remove the pre-join aggregation if it optimises the query.
Referential Integrity
Although referential integrity refers to a setting for relationships, it can be thought of in terms of join types. A full outer join will retain all records, regardless of whether or not there is a match in the other table, but at a performance cost. If you’re not sure if records would be lost, an outer join is safer. This is how tables are treated when there may not be referential integrity (Some records match).
An inner join will retain only those records where there is a match from both tables, dropping records that do not appear in each table. If you know an inner join won’t eliminate necessary data, it is more efficient. If the Performance Options are set to All records match, referential integrity is assumed and joins are performed without considering unmatched values.
An incorrect referential integrity setting can have a filter-like effect on the combined data, removing unmatched values. For more information on the power of retaining unmatched records, see Asking questions across multiple related tables on the Tableau blog. For more information on join types, see Join Your Data.
Keep the defaults
If your analysis has acceptable performance, we strongly encourage leaving the default Performance Option settings of many-to-many and not assuming referential integrity. The power of relationships comes from their ability to provide accurate, contextually appropriate results based on the tables that are used in the analysis. Changing these settings removes the semantic flexibility of relationships.