Comprendre les termes de Salesforce et de Data Cloud
Depuis le 14 octobre 2025, Data Cloud a été rebaptisé « Data 360 ». Au cours de cette transition, vous verrez peut-être des références à Data Cloud dans notre application et dans notre documentation. Bien que le nom soit nouveau, la fonctionnalité et le contenu restent inchangés.
À mesure que Tableau Next et Tableau(Le lien s’ouvre dans une nouvelle fenêtre) développent des intégrations plus complexes, nous ajoutons la possibilité d’effectuer des analyses où vous le souhaitez, quel que soit l’emplacement où résident vos données. Cela signifie que la terminologie et la philosophie de Tableau et Data Cloud commencent à toucher un public de plus en plus large. Les utilisateurs qui sont familiers avec un écosystème peuvent trouver l’autre écosystème déroutant ou étranger, mais au bout du compte, il ne s’agit que de données.
Cette rubrique a pour but d’aider les utilisateurs à s’orienter, quel que soit le système auquel ils sont habitués ou dans lequel ils travaillent.
Remarque : Data 360 s’appelait auparavant « Data Cloud ».
Termes et concepts essentiels relatifs aux données
Les mots pour décrire les données ne manquent pas. Au sens le plus générique, un ensemble de données est la collection de données avec laquelle vous travaillez.
- Une base de données désigne la plate-forme technologique qui contient réellement les données, comme Amazon Redshift, Firebird, Google Sheets ou Oracle.
- Les données sont souvent stockées sous la forme d’une table de données. Dans une base de données, il peut y avoir plusieurs tables ou vues. Dans Excel ou Google Sheets, chaque onglet de feuille est une table. Dans un fichier CSV, le fichier entier constitue la table.
- Si les données dont vous avez besoin sont réparties sur plusieurs tables, elles doivent être connectées dans un modèle de données. Un modèle de données est la représentation abstraite de la manière dont les tables sont connectées les unes aux autres.
Données dans Salesforce
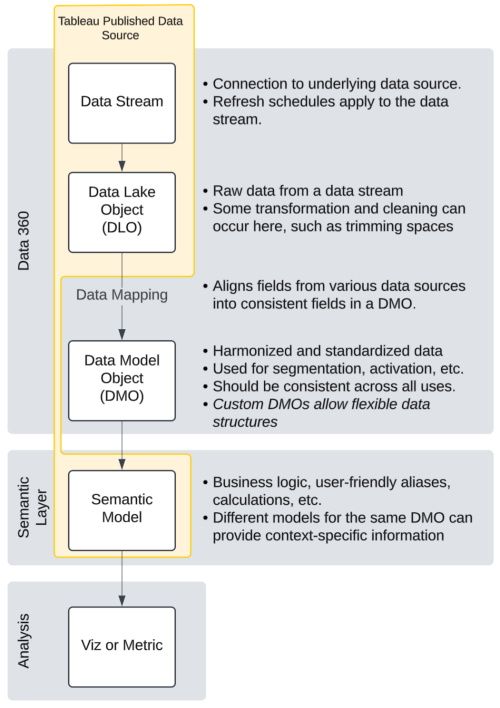
Dans Data 360, les données sont décomposées en différents concepts.
| Type de données | Description |
|---|---|
| Flux de données(Le lien s’ouvre dans une nouvelle fenêtre) | Informations de connexion, telles que la source d’origine (S3, Amazon, Google BigQuery, etc.), ainsi que les champs introduits, le champ représentant la clé primaire, la fréquence d’actualisation des données, etc. |
| Objet lac de données (DLO)(Le lien s’ouvre dans une nouvelle fenêtre) | Les données ingérées dans Data 360 ou référencées à partir d’un système externe tel que Snowflake, sont stockées dans un DLO. Les données stockées dans un DLO sont nettoyées, transformées et préparées à des fins de calcul et d’analyse. Chaque table de données est son propre DLO. |
| Objet modèle de données (DMO)(Le lien s’ouvre dans une nouvelle fenêtre) | Objet Data 360 qui décrit la structure et le schéma des données stockées dans un ou plusieurs objets lac de données. Un DMO est une table de données, mais il peut provenir d’un ou de plusieurs DLO. Le DMO prend les données du DLO et les mappe dans un format fiable. Les ensembles de règles de résolution d’identité et autres mises en forme de modèles sont appliqués dans le DMO. Il existe des DMO standards et personnalisés. La puissance d’harmonisation de Data 360 réside dans le mappage des données(Le lien s’ouvre dans une nouvelle fenêtre) entre un DLO et un DMO et la nature modélisée de la plupart des DMO. |
| Objet connaissance calculée (DSI)(Le lien s’ouvre dans une nouvelle fenêtre) | Objet modèle de données créé après le traitement d’une connaissance calculée. Les connaissances calculées aident à créer des métriques de type cube avec des mesures et des dimensions sur les données de Data 360. Vous pouvez connecter un DSI existant dans Data 360 et l’ajouter en tant que ressource de données dans votre espace de travail. |
| Fichier CSV (valeurs séparées par des virgules)(Le lien s’ouvre dans une nouvelle fenêtre) | Fichier texte qui stocke les données dans un format de type table. Les fichiers CSV sont couramment utilisés pour déplacer des données entre des applications et des programmes. Pour Tableau Next : il est possible d’intégrer un fichier CSV dans un espace de travail Tableau Next, puis de charger et stocker les données dans Data 360 sous forme de DLO. |
Petit aparté sur les objets de données Salesforce pour le public Tableau
Le flux de données constitue les informations de connexion.
Le DLO est le vidage brut des données du flux de données. Chaque DLO est une table unique.
Un DMO n’a pas d’équivalent direct dans Tableau. Un DMO peut être mappé à partir de plusieurs DLO (comme une « vue » dans une base de données) et chaque DMO est une table unique.
Un DSI n’a pas d’équivalent dans Tableau où les calculs sont simplement des champs dans une source de données comme n’importe quelle autre.
Données dans Tableau
Une source de données(Le lien s’ouvre dans une nouvelle fenêtre) Tableau comprend des informations de connexion à la base de données, le modèle de données, des informations sur la manière d’accéder aux données (identifiants d’accès, etc.) ou de les actualiser, des informations sémantiques, voire les données elles-mêmes. Les deux principaux éléments de l’interface utilisateur pour la création et la modification d’une source de données sont l’onglet Source de données et le volet Données.
Onglet Source de données : c’est dans cet onglet qu’ont lieu les connexions de données à la base de données ou aux fichiers sous-jacents et que vous créez le modèle de données en combinant les tables d’une ou de plusieurs bases de données en une seule source de données à l’aide de relations, de jointures ou d’unions(Le lien s’ouvre dans une nouvelle fenêtre). Si les données sont laissées dans leur base de données d’origine, il s’agit d’une connexion en direct. Il est également possible d’intégrer une copie des données dans Tableau sous la forme d’un extrait qui peut être actualisé si vous le souhaitez.
Volet Données : le volet Données est l’emplacement où les informations sémantiques sont capturées, y compris les noms de champs, les alias de membres, les hiérarchies, les groupes, les ensembles, les calculs, les agrégations et les couleurs par défaut, ainsi que les descriptions de champs.
Source de données : prises ensemble, les modifications apportées dans l’onglet Source de données et le volet Données constituent la source de données. Une source de données peut être une ressource publiée ou un fichier, ou être contenue dans le classeur dans lequel elle a été créée.
- Une source de données publiée (PDS) est une ressource autonome sur Tableau Cloud ou Tableau Server.
- Localement, vous pouvez également avoir des versions basées sur des fichiers d’une source de données Tableau :
.tdsest l’extension de fichier d’une source de données Tableau qui contient des informations autres que les données (connexion et sémantique uniquement)..tdsxest l’extension de fichier d’une source de données Tableau complète qui contient des informations autres que les données, ainsi que les données elles-mêmes..hyperest l’extension de fichier pour un extrait (précédemment.tde), qui contient une copie des données (les données elles-mêmes).
Remarque : une source de données publiée est l’équivalent le plus proche d’une couche sémantique ou d’un modèle sémantique dans Tableau.
Petit aparté sur les données Tableau pour le public Salesforce
Tableau exploite des données provenant d’une grande variété de bases de données et de technologies, qu’elles soient locales ou dans le cloud. Étant donné que les données ne proviennent pas d’un cloud Salesforce spécifique avec tous les objets de données spécifiques que cela implique, la modélisation et la mise en forme des données sont très flexibles et il n’y a pas vraiment de concept de formats de données modélisés.
Les modèles de normalisation et les modèles sémantiques sont principalement capturés à l’aide de sources de données publiées (PDS).
Fondamentaux de la sémantique des données
- Les données sont les faits bruts (chiffres, observations et mesures).
- Les informations sont l’interprétation de ces données ou les connaissances qui découlent du traitement et de la compréhension des données.
- La sémantique est le tremplin entre les données sous-jacentes et les informations qui en sortent.
Le terme vient du concept linguistique de sémantique vs syntaxe. La syntaxe est la manière dont vous dites quelque chose, la sémantique en est la signification. Ce concept « La sémantique est la signification » s’applique à la sémantique en tant que contexte des données. La sémantique comprend par exemple la manière dont les tables sont combinées dans le modèle de données, les informations sur les champs ou les colonnes de données et la façon dont elles peuvent interagir les unes avec les autres, des informations supplémentaires telles que l’agrégation par défaut et les calculs effectués en plus des données brutes.
Un ensemble de données peut contenir toutes les informations dont vous avez besoin, mais si vous n’arrivez pas à en tirer un sens, elles ne servent à rien(Le lien s’ouvre dans une nouvelle fenêtre). Il a besoin de sémantique pour être utile.
Le cas d’utilisation métier est indissociable des détails de la sémantique. La sémantique est la description des données ou de leur contexte métier. La sémantique peut être décomposée en catégories telles que la modélisation des données ; les métadonnées et la description des champs ; les agrégations par défaut ; les hiérarchies, les groupes et les ensembles ; et les calculs.
Quelques exemples :
- Modélisation des données
- Comment connecter les tables de données es unes aux autres ? Faut-il réunir les quatre tables de ventes trimestrielles ? La table des médecins doit-elle être directement reliée à la table des patients, ou les deux doivent-elles être reliées à la table des rendez-vous ?
- Métadonnées des champs (nom du champ, type de données, alias de membre)
- Le Nom est-il le nom d’un compte ou d’un contact ?
- La Remise est-elle un champ booléen indiquant si une remise est appliquée ou non, un champ de chaîne pour le type Remise ou une mesure discrète du montant de la remise ?
- Description des champs
- Par exemple, ce peut être un commentaire indiquant que APR, dans cet ensemble de données, désigne « Adjusted Pitching Runs », et non pas « Annual Percent Return », et qu’il est calculé comme suit
APR = L * IP - R / pf(P): où L : nombre moyen de points inscrits à chaque manche dans la ligue, IP : manches lancées, R : points alloués, pf(P) : facteur de parc pour le parc domicile du joueur P.
- Par exemple, ce peut être un commentaire indiquant que APR, dans cet ensemble de données, désigne « Adjusted Pitching Runs », et non pas « Annual Percent Return », et qu’il est calculé comme suit
- Agrégations par défaut
- Les listes doivent-elles être agrégées en tant que COUNT (comptabilisation de chaque instance) ou COUNTD (comptabilisation des valeurs uniques seulement) ?
- L’agrégation par défaut d’une mesure doit-elle être SUM ou AVG ?
- Hiérarchies, ensembles, groupes
- Dans un ensemble de départements d’une université, le département d’ingénierie peut être son propre collège, alors que les départements d’histoire, de littérature, de philosophie et de sciences politiques peuvent, tous ensemble, former le collège des arts libéraux.
- Calculs
- Champs dérivés de champs qui existent nativement dans les données, mais qui doivent être manipulés ou combinés, par exemple définir un cas de support obsolète comme un dossier ouvert depuis 10 jours pour un compte standard, mais seulement 2 jours pour un compte premium.
Sémantique dans Tableau et Sémantique Tableau
En l’absence d’une couche sémantique réutilisable, les modèles de données, les définitions sémantiques et les champs calculés peuvent être créés de manière ponctuelle, ce qui entraîne des inefficacités et des risques d’erreur ou de désalignement.
Sémantique dans Tableau
La sémantique n’a rien de nouveau pour le public de Tableau. Elle fait simplement partie de la source de données, en particulier d’une source de données publiée (PDS). La source de données publiée est l’endroit où vous contrôlez les définitions sémantiques de vos données.
En raison de la philosophie du cycle de l’analytique visuelle(Le lien s’ouvre dans une nouvelle fenêtre) de Tableau, la sémantique n’a jamais été abstraite en une couche distincte. L’environnement de création est l’emplacement où le modèle de données (onglet Source de données) et la sémantique (le volet Données) sont développés.
Sémantique Tableau
La Sémantique Tableau(Le lien s’ouvre dans une nouvelle fenêtre) reprend l’approche de séparation de la sémantique en une couche distincte de l’analyse afin que les modèles sémantiques puissent être créés une seule fois et utilisés dans une variété d’analyses ou même de produits. La Sémantique Tableau s’intègre dans les environnements Data 360 et Tableau Next en tant que couche sémantique autonome, distincte des données ou de l’analyse. L’unité d’une couche sémantique est un modèle sémantique. Le modèle sémantique contient à la fois le modèle de données et les définitions sémantiques des données. Dans la Sémantique Tableau, le Générateur de modèle sémantique est l’interface utilisateur permettant de créer un modèle sémantique. Ces modèles sémantiques peuvent être créés dans Data 360 ou Tableau Next.
Interopérabilité
Avec le connecteur Sémantique Tableau pour Tableau, vous pouvez effectuer des analyses dans Tableau en utilisant un modèle sémantique de Tableau Next. Ou bien, en créant un modèle sémantique à partir d’une source de données publiée (PDS),(Le lien s’ouvre dans une nouvelle fenêtre)vous pouvez effectuer une analyse dans Tableau Next en utilisant une source de données de Tableau.