À propos de Data Connect
Depuis septembre 2025, Tableau Data Connect n’est plus disponible pour les nouveaux déploiements. Nous recommandons aux clients existants de migrer leur déploiement Data Connect vers Connexion privée(Le lien s’ouvre dans une nouvelle fenêtre) ou Tableau Bridge(Le lien s’ouvre dans une nouvelle fenêtre). Data Connect sera supprimé prochainement.
Data Connect permet aux utilisateurs de Tableau Cloud d’accéder aux sources de données sur votre service réseau ou cloud privé. Data Connect fonctionne comme un modèle de responsabilité partagée. Avec ce modèle, les clients fournissent les ressources de calcul physiques ou virtuelles, et Tableau héberge et gère le cluster Data Connect Kubernetes sur ces ressources.
Dans votre environnement, le cluster Data Connect Kubernetes supervise un ensemble de conteneurs. Les conteneurs prennent en charge l’environnement d’exécution composé d’un ou de plusieurs clients Bridge. Le client Bridge est le programme qui exécute les tâches et permet de sécuriser les communications qui passent par le pare-feu dans votre organisation.
Les services Data Connect comprennent :
Surveillance et dépannage de cluster : Tableau surveille l’intégrité et l’utilisation du client Bridge. Les données de télémétrie sont collectées pour garantir que les ressources sont utilisées de la manière la plus efficace et la plus efficiente possible.
Maintenance du cluster : les mises à niveau sont automatiquement déployées, et l’exploitation et la maintenance du cluster appartiennent et reviennent entièrement à Tableau. Data Connect optimise automatiquement le déploiement de votre charge de travail en fonction des besoins et du pool de calcul disponible.
Surveillance des alertes : la gestion des incidents est assurée en continu afin de résoudre les problèmes rapidement et d’en limiter l’impact pour l’entreprise.
Prise en charge des connecteurs
Data Connect prend en charge les mêmes connecteurs que Tableau Bridge pour Linux. Pour un aperçu complet des options de connectivité, veuillez consulter Connectivité avec Bridge.
Prise en charge de l’environnement
Data Connect prend actuellement en charge les environnements sur site et VCP : Amazon Web Services (AWS), Microsoft Azure et Google Cloud Platform (GCP). Les nœuds Data Connect sont compatibles avec un seul site Tableau Cloud. Ils doivent être installés sur le même réseau que les données. Les clients doivent donc prévoir au moins trois nœuds par réseau privé pour maintenir la disponibilité du service. Les nœuds Data Connect doivent être dédiés à Data Connect. Vous ne pouvez pas déployer d’autres conteneurs sur le cluster appartenant à Tableau. et vous ne pouvez pas utiliser un cluster existant pour Data Connect.
Architecture
L’architecture Data Connect repose sur trois composants principaux et des limites de responsabilité. Il existe bien quelques chevauchements, mais Tableau est principalement responsable des couches d’application et d’orchestration, et les clients sont responsables de l’infrastructure (calcul, système d’exploitation, réseau et stockage) et de son emplacement.
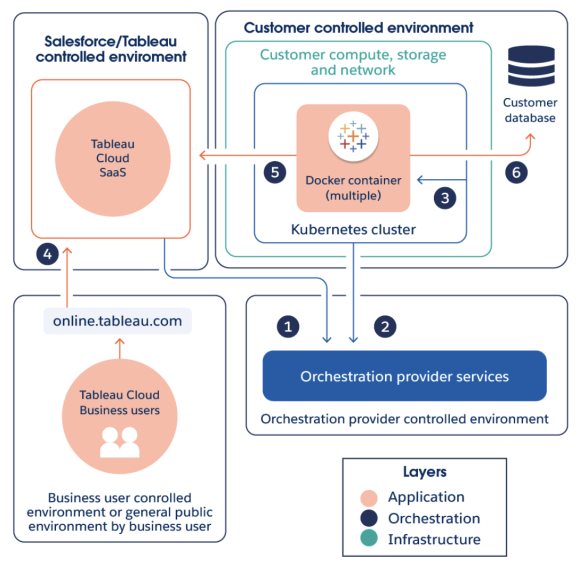
Tableau Cloud communique avec le service d’orchestration Kubernetes pour déployer, surveiller et gérer l’orchestration Kubernetes.
Lorsque vous initialisez Data Connect, une connexion sécurisée est établie avec le service du fournisseur d’orchestration via le port 443.
Une fois le service configuré, un cluster Kubernetes déploie un ou plusieurs conteneurs avec un ou plusieurs clients Bridge. Ces clients Bridge seront responsables de l’exécution des charges de travail Tableau.
Les utilisateurs de Tableau Cloud se connectent à Tableau Cloud pour interagir avec le service Data Connect.
Lors de la configuration, les clients Bridge initialisent une connexion avec Tableau Cloud en utilisant HTTPS. Une fois la connexion établie, les clients Bridge initient une communication bidirectionnelle sécurisée avec votre environnement Tableau Cloud à l’aide d’une connexion WebSocket (wss://).
Les requêtes initiées depuis Tableau Cloud sont exécutées sur votre base de données de manière à prendre en charge l’analyse de l’utilisateur final.
Sécurité
Voir Sécurité de Data Connect.
Composants de Data Connect

Le composant principal de la solution Data Connect est un cluster. Le cluster est un cluster Kubernetes composé d’un ou plusieurs nœuds. Chaque nœud Kubernetes héberge au moins un conteneur, lequel, à son tour, héberge le client Bridge. Le client Bridge exécute des requêtes en direct et d’extrait.
Un pool est un regroupement logique de règles réseau qui spécifient quels clusters doivent répondre à des requêtes spécifiques. Dans le contexte de la planification du déploiement, un pool héberge une collection de points de terminaison (domaines ou adresses IP) à des fins d’équilibrage de charge. Les domaines incluent les données de cloud privé, les données relationnelles, les données de fichiers, etc.
Pour permettre à un cluster d’accéder aux sources de données et de les actualiser, chaque pool est attribué à un cluster. Pour répartir la charge, vous pouvez ajouter plusieurs pools à un cluster.
Présentation du déploiement

Pour commencer, exécutez un script sur chacun de vos serveurs Linux. Ce script configure un cluster Kubernetes géré par Tableau dans votre environnement. Le cluster Kubernetes est géré par Tableau.
Une fois Kubernetes configuré, vous déployez un conteneur Docker sur le cluster. Ensuite, Tableau déploie et gère à distance le client Bridge au sein du conteneur. Une fois cette configuration avec Tableau établie, vous allez mapper les connexions à vos sources de données de réseau privé.
Pour plus d’informations sur le déploiement de Data Connect, téléchargez le livre blanc Accéder aux données de votre réseau privé avec Tableau Cloud - Meilleures pratiques pour Data Connect et Tableau Bridge(Le lien s’ouvre dans une nouvelle fenêtre).
Connectivité de la base de données
Les requêtes sont gérées depuis le client Bridge dans le cluster. Vos données sont transmises directement depuis le client Bridge à Tableau Cloud. Data Connect n’a pas besoin d’un accès au réseau externe, de perçage de pare-feu ni d’accès à une machine distante.

Le client Bridge établit une connexion persistante avec le service Data Connect Tableau Cloud en utilisant des WebSockets sécurisés (wss://). Le client attend ensuite que Tableau Cloud envoie une demande.
- Pour les sources de données avec des connexions en direct ou des connexions virtuelles, Tableau Cloud lance une requête auprès du client Bridge.
- Pour les sources de données avec connexion aux extraits qui utilisent des programmations d’actualisation, le client reçoit la demande de programmation d’actualisation et contacte Tableau Cloud via une connexion sécurisée (https://) pour les fichiers de source de données (.tds).
Le client Bridge se connecte aux données de réseau privé à l’aide des informations d’identification intégrées dans la demande de travail.
La base de données renvoie les résultats de la requête.
Le client Bridge reçoit la charge utile et la renvoie au service Data Connect.