Comprendre les termes de Salesforce et de Data Cloud
Le 14 octobre 2025, Data Cloud a été rebaptisé Data 360. Au cours de cette transition, vous verrez peut-être des références à Data Cloud dans notre application et dans notre documentation. Bien que le nom soit nouveau, la fonctionnalité et le contenu restent inchangés.
Alors que Tableau Next et Tableau(Le lien s’ouvre dans une nouvelle fenêtre) renforcent leurs intégrations, nous ajoutons la possibilité d’effectuer des analyses où vous le souhaitez, peu importe où vos données sont hébergées. Cela signifie que la terminologie et les approches de Tableau et Data Cloud commencent à converger. Les utilisateurs habitués à un écosystème peuvent trouver l’autre écosystème déroutant ou étranger, mais au final, il s’agit toujours de données.
Cette rubrique vise à aider les utilisateurs à s’orienter, quel que soit le système qu’ils utilisent habituellement ou dans lequel ils sont amenés à travailler.
Remarque : Data 360 était anciennement appelé « Data Cloud ».
Termes et concepts de données essentiels
Le vocabulaire relatif aux données est riche et varié. Au sens large, un ensemble de données désigne l’ensemble des données que vous utilisez.
- Une base de données est la plateforme technologique qui stocke réellement les données, comme Amazon Redshift, Firebird, Google Sheets ou Oracle.
- Les données sont souvent stockées sous la forme d’une table de données. Dans une base de données, il peut y avoir plusieurs tables ou vues. Dans Excel ou Google Sheets, chaque onglet de feuille est une table. Dans un fichier CSV, le fichier entier constitue la table.
- Si les données dont vous avez besoin sont réparties dans plusieurs tables, elles doivent être connectées dans un modèle de données. Un modèle de données est une représentation abstraite des relations entre les tables.
Données dans Salesforce
Dans Data 360, les données sont ventilées selon différents concepts.
| Type de données | Description |
|---|---|
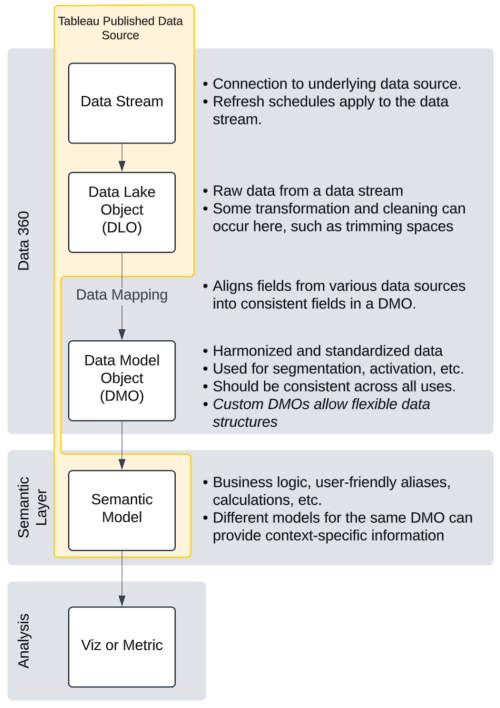
| Flux de données(Le lien s’ouvre dans une nouvelle fenêtre) | Les informations de connexion, comme la source d’origine (S3, Amazon, Google BigQuery, etc.), les champs importés, le champ utilisé comme clé primaire, la fréquence d’actualisation des données, etc. |
| Objet de lac de données (DLO)(Le lien s’ouvre dans une nouvelle fenêtre) | Les données ingérées dans Data 360 ou référencées depuis un système externe, comme Snowflake, sont stockées dans un DLO. Les données stockées dans un DLO sont nettoyées, transformées et préparées pour le calcul et l’analyse. Chaque table de données correspond à un DLO distinct. |
| Objet de modèle de données (DMO)(Le lien s’ouvre dans une nouvelle fenêtre) | Un objet Data 360 décrivant la structure et le schéma des données stockées dans un ou plusieurs objets de lac de données. Un DMO est une table de données, mais il peut provenir d’un ou de plusieurs DLO. Le DMO convertit les données du DLO et les transforme en un format standardisé. Les ensembles de règles de résolution d’identité et autres mises en forme modélisés sont appliqués dans le DMO. Il existe des DMO standard et personnalisés. Le mappage des données(Le lien s’ouvre dans une nouvelle fenêtre) d’un DLO vers un DMO, combiné à la nature modélisée de la plupart des DMO, constituent la puissance d’harmonisation de Data 360. |
| Objet de connaissance calculée (CIO)(Le lien s’ouvre dans une nouvelle fenêtre) | Un objet de modèle de données créé après le traitement d’une connaissance calculée. Les connaissances calculées aident à créer des métriques de type cube avec des mesures et des dimensions à partir des données de Data 360. Vous pouvez connecter un objet de connaissance calculée (Calculated insight object, CIO) existant dans Data 360 et l’ajouter comme ressource de données dans votre espace de travail. |
| Valeurs séparées par des virgules (CSV)(Le lien s’ouvre dans une nouvelle fenêtre) | Fichier texte qui stocke les données dans un format de table. Les fichiers CSV sont couramment utilisés pour transférer des données entre applications et programmes. Pour Tableau Next : un fichier CSV peut être importé dans un espace de travail Tableau Next, et ses données peuvent être téléversées et stockées dans Data 360 en tant que DLO. |
Note sur les objets de données Salesforce pour les utilisateurs Tableau
Le flux de données correspond aux informations de connexion.
Le DLO est la copie brute des données du flux de données. Chaque DLO est une table unique.
Un DMO n’a pas d’équivalent direct dans Tableau. Un DMO peut être généré par plusieurs DLO (comme une « vue » dans une base de données) et chaque DMO correspond à une seule table.
Un CIO n’a pas d’équivalent dans Tableau, où les calculs sont des champs standards dans la source de données, comme tout autre champ.
Données dans Tableau
Une source de données(Le lien s’ouvre dans une nouvelle fenêtre) Tableau comprend des informations de connexion à la base de données, le modèle de données, des informations d’accès aux données (identifiants d’accès, etc.) et d’actualisation de données, des informations sémantiques, et parfois même les données elles-mêmes. Les deux principaux éléments de l’interface utilisateur pour créer et modifier une source de données sont l’onglet Source de données et le volet Données.
Onglet Source de données : Dans l’onglet Source de données, les connexions de données à la base de données ou aux fichiers sous-jacents sont établies, le modèle de données est créé en combinant des tables d’une ou de plusieurs bases de données en une seule source de données via des relations, des jointures et des unions(Le lien s’ouvre dans une nouvelle fenêtre). Si les données restent dans leur base de données d’origine, il s’agit d’une connexion en direct. Une copie des données peut également être importée dans Tableau sous forme d’extrait qui peut être actualisé si nécessaire.
Volet Données : Dans le volet Données, les informations sémantiques sont définies, notamment les noms de champs, les alias de membres, les hiérarchies, les groupes, les ensembles, les calculs, les agrégations et couleurs par défaut, et les descriptions de champs.
Source de données : Ensemble, les modifications apportées dans l’onglet Source de données et le volet Données forment la source de données. Une source de données peut être un actif publié ou un fichier. Elle peut également être intégrée directement au classeur où elle a été créée.
- Une source de données publiée (PDS) est un actif autonome dans Tableau Cloud ou Tableau Server.
- Localement, vous pouvez également avoir des versions basées sur des fichiers pour une source de données Tableau :
- L’extension de fichier
.tdsdésigne une source de données Tableau contenant les métadonnées (connexion et sémantique uniquement). - L’extension de fichier
.tdsxdésigne une source de données Tableau complète contenant des métadonnées elles-mêmes (connexion et sémantique uniquement). - L’extension de fichier
.hyperdésigne un extrait (précédemment.tde), contenant une copie des données (les données elles-mêmes).
- L’extension de fichier
Remarque : Une source de données publiée est l’équivalent le plus proche d’une couche sémantique ou d’un modèle sémantique dans Tableau.
Note sur les données Tableau pour le public Salesforce
Tableau exploite des données provenant d’une grande variété de bases de données et de technologies, locales ou dans le nuage. Comme les données ne proviennent pas d’un nuage Salesforce avec tous les objets de données spécifiques que cela implique, la modélisation et la mise en forme des données sont très flexibles et il n’existe pas de véritables formats de données modélisés.
Les modèles standard et sémantiques sont principalement gérés via des sources de données publiées (PDS).
Fondamentaux de la sémantique des données
- Les données sont des faits bruts (nombres, observations et mesures).
- L’information est l’interprétation de ces données, ou la connaissance qui découle de leur traitement et de leur compréhension.
- La sémantique est le pont entre les données sous-jacentes et les informations qui en découlent.
Le terme provient du concept linguistique opposant sémantique et syntaxe. La syntaxe, c’est la manière de le dire; la sémantique, c’est le sens. Ce concept de la sémantique, c’est le sens s’applique à la sémantique dans le contexte des données. La sémantique englobe notamment la manière dont les tables sont combinées dans le modèle de données, les informations sur les champs ou les colonnes de données et leurs interactions, les informations supplémentaires telles que l’agrégation par défaut, et les calculs effectués sur les données brutes.
Un ensemble de données peut contenir toutes les informations qu’il vous faut, mais sans la capacité d’en extraire du sens, il ne sert à rien(Le lien s’ouvre dans une nouvelle fenêtre). Sans sémantique, il ne peut pas être utile.
Le cas d’utilisation métier est indissociable des détails de la sémantique. La sémantique est la description des données ou de leur contexte métier. La sémantique peut être divisée en différentes catégories, comme la modélisation des données; les métadonnées et descriptions des champs; les agrégations par défaut; les hiérarchies, groupes et ensembles; ainsi que les calculs.
Quelques exemples :
- Modélisation des données
- Comment les tables de données peuvent être reliées entre elles. Doit-on réunir les quatre tables de ventes trimestrielles? La table des médecins doit-elle être directement liée à celle des patients, ou les deux tables doivent-elles être liées à la table des rendez-vous?
- Métadonnées des champs (nom de champ, type de données, alias de membre)
- Nom est-il le nom d’un compte ou d’un contact?
- Remise est-il un champ booléen indiquant si une remise est appliquée ou non, un champ de type chaîne pour le type de remise, ou une mesure discrète du montant de la remise?
- Descriptions des champs
- Par exemple, précisez que dans cet ensemble de données, APR désigne Adjusted Pitching Runs (Points de lancer ajustés), et non Annual Percent Return (Taux annuel en pourcentage). Le calcul s’effectue comme suit
APR = L * IP - R / pf(P)où L : nombre moyen de points par manche lancée dans la ligue, IP : manches lancées, R : points accordés, pf(P) : facteur de parc pour le stade d’attache du joueur P.
- Par exemple, précisez que dans cet ensemble de données, APR désigne Adjusted Pitching Runs (Points de lancer ajustés), et non Annual Percent Return (Taux annuel en pourcentage). Le calcul s’effectue comme suit
- Agrégations par défaut
- Doit-on agréger les Inscriptions en utilisant COUNT (comptage de chaque occurrence) ou COUNTD (comptage des valeurs uniques seulement)?
- L’agrégation par défaut d’une mesure doit-elle être SUM ou AVG?
- Hiérarchies, ensembles, groupes
- Dans un ensemble de départements universitaires, le département d’ingénierie peut constituer une faculté autonome, alors que les départements d’histoire, de littérature, de philosophie et de sciences politiques peuvent être regroupés en faculté des arts et sciences.
- Calculs
- Les champs dérivés sont créés à partir de champs natifs dans les données, mais requièrent une manipulation ou une combinaison. Par exemple, on pourrait définir une demande d’assistance obsolète comme étant ouverte depuis 10 jours pour un compte standard, mais seulement depuis 2 jours pour un compte premium.
Sémantique dans Tableau et Tableau Semantics
Sans une couche sémantique réutilisable, les modèles de données, les définitions sémantiques et les champs calculés peuvent être créés ponctuellement et répétés, ce qui entraîne des inefficacités et des risques d’erreur ou d’incohérence.
Sémantique dans Tableau
La sémantique n’est pas nouvelle pour les utilisateurs de Tableau. Elle est historiquement intégrée aux sources de données, particulièrement les sources de données publiées (PDS). La source de données publiée est l’endroit où vous contrôlez les définitions sémantiques de vos données.
Dans l’approche Tableau, où l’analytique visuelle est cyclique(Le lien s’ouvre dans une nouvelle fenêtre), la sémantique n’a traditionnellement pas été construite dans une couche dédiée. C’est dans l’environnement de création qu’on construit conjointement le modèle de données (onglet Source de données) et la sémantique (volet Données).
Sémantique Tableau
Tableau Semantics(Le lien s’ouvre dans une nouvelle fenêtre) adopte une approche qui consiste à séparer la sémantique en une couche distincte de l’analyse, afin de pouvoir créer des modèles sémantiques et les utiliser dans une variété d’analyses ou de produits. Tableau Semantics s’intègre dans les environnements Data 360 et Tableau Next en tant que couche sémantique autonome, distincte des données et de l’analyse. L’unité de la couche sémantique est un modèle sémantique. Le modèle sémantique contient à la fois le modèle de données et les définitions sémantiques des données. Dans Tableau Semantics, Semantic Model Builder est l’interface utilisateur permettant de créer un modèle sémantique. Ces modèles sémantiques peuvent être créés dans Data 360 ou dans Tableau Next.
Interopérabilité
Le connecteur Sémantique Tableau pour Tableau vous permet d’effectuer des analyses dans Tableau en utilisant un modèle sémantique de Tableau Next. Autrement, en créant un modèle sémantique à partir d’une source de données publiée (PDS)(Le lien s’ouvre dans une nouvelle fenêtre), vous pouvez effectuer des analyses dans Tableau Next en utilisant une source de données de Tableau.