Tableau における予測モデリング関数の仕組み
ビジュアライゼーションに 傾向線や予測を追加できるようになりましたが、さらにできることがあります。統計エンジンの機能を使用してモデルを構築すると、データが傾向線や最適なラインの周りにどのように分布しているかを理解することができます。 以前は、Tableau を R および Python と統合して高度な統計計算を実行し、Tableau で視覚化する必要がありました。今は、予測モデリング関数を使用して、データから予測を行って表計算に含めることができます。表計算の使用の詳細については、「表計算を使用して値を変換する」を参照してください。
これらの予測モデリング関数を使用すると、変数を更新し、さまざまな予測変数の組み合わせで複数のモデルを視覚化することで、ターゲットと予測変数を選択できます。任意の詳細レベルでデータをフィルター処理、集計、および変換することができ、モデル (つまり予測) はデータに合わせて自動的に再計算されます。
これらの関数を使用して予測計算を作成する方法の詳細な例については、「例 - 予測モデリング関数を使用した女性の平均寿命の調査」を参照してください。
Tableau で使用できる予測モデリング関数
MODEL_PERCENTILE
| 構文 | MODEL_PERCENTILE(
|
| 定義 | 予測値が観測されたマーク以下である確率 (0 から 1 の間) を返します。マークは、ターゲット式と他の予測変数で定義されます。これは、累積分布関数 (CDF) とも呼ばれる事後予測分布関数です。 |
| 例 | MODEL_PERCENTILE( SUM([Sales]),COUNT([Orders])) |
MODEL_QUANTILE
| 構文 | MODEL_QUANTILE(
|
| 定義 | 指定した分位数で、ターゲット式と他の予測変数によって定義された推定範囲内のターゲット数値を返します。これは事後予測分位です。 |
| 例 | MODEL_QUANTILE(0.5, SUM([Sales]), COUNT([Orders])) |
予測モデリング関数の能力
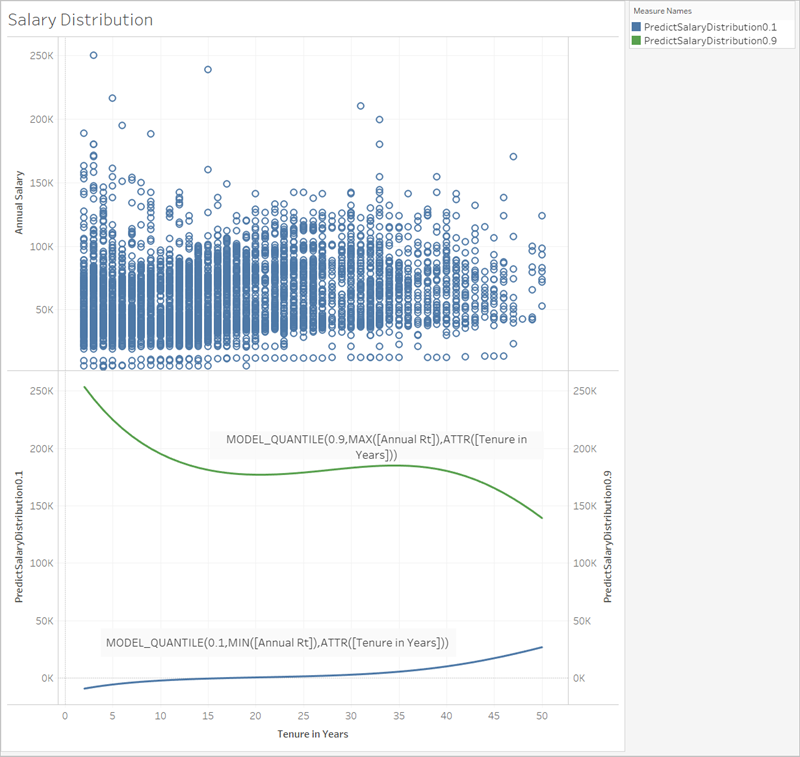
給与データを使用した例を、まずは MODEL_QUANTILE で見てみましょう。
次の例では、MODEL_QUANTILE を使用して、同じデータセットに対する予測分布の 10 パーセンタイルと 90 パーセンタイルを表示しています。統計エンジンは、既存のデータに基づいて線形回帰モデルを使用し、各在職期間の最高給与が緑の線を下回る確率が 90% であり、各在職期間の最低給与が青い線を下回る確率が 10% であると判断しました。
つまり、分位数を 0.9 に設定すると、モデルはこの時点のすべての給与が 90% の緑の線以下になると予測しています。青い線は 0.1 つまり 10% に設定されているので、10% の給与だけが青い線以下になり、その逆 (90%) は青い線より上に表示されます。
事実上これにより 1 つの帯が作られ、将来発生する可能性のあるポイントや観測されていないデータの 80% がその帯の内部に入ると予測できます。
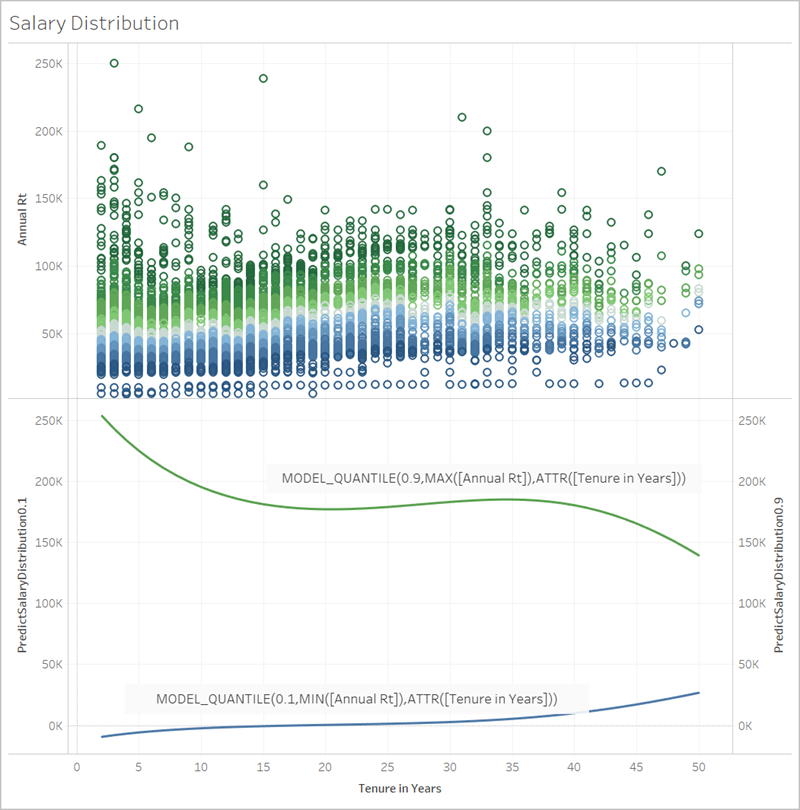
次に、データをさらに理解するために、MODEL_QUANTILE の逆関数である MODEL_PERCENTILE を見てみましょう。
MODEL_PERCENTILE 関数を使用すると、データ セットの外れ値を識別できます。MODEL_PERCENTILE は、観測されたマークが各マークの予測値のどの範囲内にあるかをパーセンタイルで示します。パーセンタイルが 0.5 に非常に近ければ、その観測値は予測される中央値に非常に近い値です。パーセンタイルが 0 または 1 に近ければ、その観測値はモデルの予測範囲の下限または上限の境界にあり、比較的予想外の値です。
以下では、MODEL_PERCENTILE を画像の上半分の給与のビジュアライゼーションに色として適用し、どの値が最も期待されるかを理解できるようにしています。
予測モデリング関数の構文の詳細
MODEL_QUANTILE とは?
MODEL_QUANTILE は、事後予測分位、つまり指定した分位数での期待値を計算します。
- 分位数: 最初の引数は 0 から 1 の間の数値であり、どの分位を予測するかを示します。たとえば、0.5 は中央値を予測することを指定します。
- ターゲット式: 2 番目の引数は、予測するメジャーとなる「ターゲット」です。
- 予測変数の式: 3 番目の引数は、予測に使用する予測変数です。予測変数は、ディメンション、メジャー、またはその両方です。
結果は、可能性のある範囲内の数値です。
MODEL_QUANTILE を使用すると、信頼区間や、将来の日付などの欠損値を生成したり、基になるデータセットに存在しないカテゴリを生成したりできます。
MODEL_PERCENTILE とは?
MODEL_PERCENTILE は、累積分布関数 (CDF) として知られる、事後予測分布関数を計算します。これにより、MODEL_QUANTILE の逆数である 0 と 1 の間の特定の値の分位数が計算されます。
- ターゲット式: 最初の引数は、評価する値を識別する対象となるメジャーです。
- 予測変数の式: 2 番目の引数は、予測に使用する予測変数です。
- 追加の引数はオプションであり、予測を制御する場合に含めます。
計算の構文は似ていますが、MODEL_QUANTILE では定義した分位数が引数として追加されます。
結果は、期待値がマークで表される観測値以下である確率です。
MODEL_PERCENTILE を使用すると、データベース内の相関とリレーションシップを表示できます。MODEL_PERCENTILE が 0.5 に近い値を返す場合、観測されたマークは、選択した他の予測変数を指定すると、予測値の範囲の中央値に近くなります。MODEL_PERCENTILE が 0 または 1 に近い値を返す場合、観測されたマークは、選択した他の予測変数を指定すると、モデルが期待する範囲の下限または上限に近くなります。
上級ユーザーの場合、予測を制御するために含めることができるオプションの引数が他に 2 つあります。詳細については、予測モデリングの正則化と増強を参照してください。
何が計算されているか?
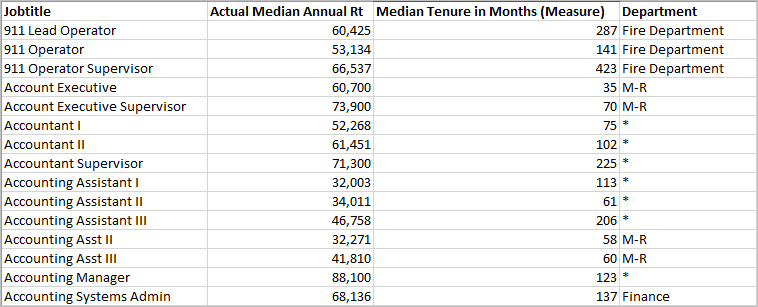
モデルの作成に使用する入力はマトリックスであり、各マークが行で、各マークに対して評価したターゲット式と予測変数の式が列となります。viz で指定された行は、統計エンジンによって計算されるデータ セットの行を定義するものです。
以下では、行 (つまりマーク) が役職で定義され、列がターゲット式 MEDIAN([Annual Rt]) である例を見てみましょう。これらに続いて、オプションで追加の予測変数 MEDIAN([Tenure in Months (Measure)] (在職月数 (メジャー)) と ATTR([Department Generic (group)] (部門汎用(グループ)) を見てみましょう。
モデルの構築と予測の生成に使用するデータの詳細については、「予測モデリングにおける計算とデータ分割」を参照してください。
どのモデルがサポートされるか?
予測モデリング関数は、線形回帰、正規化線形回帰、およびガウス プロセス回帰をサポートします。これらのモデルは、さまざまなユース ケースと予測タイプをサポートするほか、制限も異なります。詳細については、予測モデルの選択を参照してください。
予測変数の選択
予測変数は、計算フィールドを含む、データ ソース内の任意のフィールド (メジャーまたはディメンション) です。
たとえば、[市区町村]、[州]、および[地域] フィールドを含むデータセットがあり、[州] 内に複数の [市区町村] レコードが存在し、[地域] 内に複数の [州] レコードが存在するとします。
[州] をマークとして使用するビジュアライゼーションでは、予測変数 ATTR([State]) または ATTR([Region]) の両方が予測変数として機能します。ただし、視覚化された州の中に複数の市区町村が存在しても予測変数として使用できないため、予測変数 ATTR([City]) は * に変換されます。つまり、viz よりも詳細レベルが低い予測変数を含めると、予測に値は追加されません。ほとんどの場合、viz よりも詳細レベルが低い予測変数は * と評価されるため、すべて同じように扱われます。
ただし、マークとして [市区町村] を使用する viz を同じデータセットを使用して生成する場合、ATTR([City])、ATTR([State])、および ATTR([Region]) はすべて予測変数として正常に使用できます。ATTR 関数の詳細については、「属性 (ATTR) 関数を使用する場合」を参照してください。
ディメンションとメジャーは、予測変数として含めるために (ビューまたは viz 内で) 視覚化する必要はありません。詳細なガイダンスについては、「予測変数の選択」を参照してください。
推奨事項
予測計算の最適な使用方法は、次の通りです。
Viz 内の各マークが、集計されたデータではなく、製品、売上、個人などの個別のエンティティを表す、個々のレコードの値を予測すること。これは、1 つのマークが 100 レコードで構成され、もう 1 つのマークがそれぞれ 1 つのレコードで構成されている場合でも、Tableau は各マークを同等に見なすためです。統計エンジンは、マークを構成するレコードの数に基づいてマークの重み付けを行いません。
- 集計されたターゲット式には SUM と COUNT を使用して値を予測すること。
制限事項
時系列を将来に拡張するには、計算フィールドを使用する必要があります。詳細については、「将来を予測する」を参照してください。
予測変数は、ビューと同じか高いレベルの詳細にする必要があります。つまり、ビューが州別に集計される場合は、州または地域を予測変数として使用する必要があり、市区町村は使用できません。詳細については、「予測変数の選択」を参照してください。
予測計算はいつ中断されるか?
使用しているモデルに関係なく、モデルが応答を返すためには、各パーティション内に少なくとも 3 つのデータ ポイントが必要です。
ガウス プロセス回帰をモデルとして指定した場合、このモデルは、1 つの順序付きディメンション予測変数と任意の数の非順序付きディメンション予測変数を使った予測計算に使用できます。メジャーは、ガウス プロセス回帰計算では予測変数としてサポートされませんが、線形回帰計算および正規化線形回帰計算で使用できます。モデルの選択の詳細については、予測モデルの選択を参照してください。
計算で ATTR[State] を予測変数として使用し、Viz にマークとして州が含まれているものの、市区町村などのより低い詳細レベルの他のフィールドが含まれていない場合は、エラーが返されます。これを防ぐには、マークと予測カテゴリの間に 1 対 1 の関係がないことを確認します。
これらの問題およびその他の予測問題の詳細については、「予測モデリング関数のエラーの解決」を参照してください。
FAQ
複数の予測変数グループのマークはどうなりますか?
複数の予測変数グループ内に存在するデータから行を集計した場合、ATTR 関数の値は複数の値を持つ特殊な値になります。たとえば、複数の州に存在するすべての都市は、同じ予測値を持ちます (別の予測変数がない場合)。予測変数を選択する場合は、viz と同じかそれ以上の詳細レベルの予測変数を使用することをお勧めします。ATTR 関数の詳細については、「属性 (ATTR) 関数を使用する場合」を参照してください。
ATTR 集約が * 値を返す場合はどうなりますか?
* は、他のもとは異なる値として扱われます。ATTR がすべてのマークに対して * を返す場合、本質的には定数値の予測変数と同じであり、無視されます。これは、その予測変数をまったく含まないのと同じです。
ATTR が一部のマークに対して * を返す場合、すべての * 値が同じとみなされる 1 つのカテゴリとして扱われます。このシナリオは、複数の予測グループにマークが存在する上記のシナリオと同じです。
[次を使用して計算] の表計算メニュー オプションについてはどうですか?
これは、他の表計算における [次を使用して計算] と同じように機能します。詳細については、「予測モデリングにおける計算とデータ分割」を参照してください。
エラーが発生する理由は?
予測モデリング関数を使用するときにエラーが発生する理由はいくつかあります。詳細なトラブルシューティングの手順については、「予測モデリング関数のエラーの解決」を参照してください。