Comment les expressions LOD fonctionnent dans Tableau
Cet article explique comment les expressions LOD sont calculées et fonctionnent dans Tableau. Pour plus d’informations sur les expressions LOD et la manière dont elles fonctionnent, consultez le livre blanc Comprendre les expressions LOD (Level of Detail)(Le lien s’ouvre dans une nouvelle fenêtre) sur le site Web de Tableau.
Expressions au niveau de la ligne et expressions au niveau de la vue
Dans Tableau, les expressions faisant référence à des colonnes de sources de données non agrégées sont calculées pour chaque ligne de la table sous-jacente. Dans ce cas, la dimensionnalité de l’expression est de niveau ligne. Voici un exemple d’expression au niveau de la ligne :
[Sales] / [Profit]
Ce calcul sera évalué dans chaque ligne de la base de données. Pour chaque ligne, la valeur Ventes de cette ligne sera divisée par la valeur Profit de cette ligne, produisant une nouvelle colonne avec le résultat de la multiplication (un rapport de profit).
Si vous créez un calcul avec cette définition, l’enregistrez sous le nom [ProfitRatio], puis le faites glisser du volet Données vers une étagère, Tableau agrège généralement les champs calculés de la vue :
SUM([ProfitRatio])
En revanche, les expressions faisant référence à des colonnes de sources de données agrégées sont calculées à la dimensionnalité définie par les dimensions de la vue. Dans ce cas, la dimensionnalité de l’expression est de niveau vue. Voici un exemple d’expression au niveau de la vue :
SUM(Sales) / SUM(Profit)
Si vous faites glisser ce calcul d’une étagère (ou si vous le saisissez directement sur une étagère en tant que calcul ad hoc), Tableau l’encapsule dans une fonction AGG :
AGG(SUM(Sales) / SUM(Profit))
C’est ce que l’on appelle un calcul d’agrégation. Pour plus de détails, consultez Fonctions d’agrégation dans Tableau(Le lien s’ouvre dans une nouvelle fenêtre).
Les champs de dimension et d’ensemble placés sur l’un des emplacements en surbrillance dans l’image suivante contribuent au niveau de détail de la vue :

Avant la prise en charge des expressions de niveau de détail par Tableau, il n’était pas possible de créer des calculs à un niveau de détail différent du niveau de la vue. Par exemple, si vous tentez d’enregistrer l’expression suivante, Tableau affiche le message d’erreur : « Impossible de combiner les arguments d’agrégation et de non-agrégation à cette fonction » :
[Sales] – AVG([Sales])
Dans ce cas, l’intention de l’utilisateur était de comparer les ventes en magasin de chaque magasin à la moyenne des ventes de tous les magasins. Ceci peut désormais se faire avec une expression de niveau de détail :
[Sales] - {AVG([Sales])}
C’est ce que l’on appelle une expression de niveau de détail à l’échelle de la table. Consultez À l’échelle de la table.
Limitations des expressions LOD
Les limitations et contraintes suivantes s’appliquent aux expressions de niveau de détail. Voir également Contraintes de la source de données pour les expressions LOD.
Les expressions de niveau de détail qui font référence à des mesures en virgule flottante peuvent se comporter de façon peu fiable lorsqu’elles sont utilisées dans une vue qui nécessite la comparaison des valeurs de l’expression. Pour plus de détails, consultez Comprendre les types de données dans les calculs Tableau(Le lien s’ouvre dans une nouvelle fenêtre).
Les expressions de niveau de détail ne sont pas affichées sur la page Source de données. Voir Volet Source de données.
Lors du référencement d’un paramètre dans une déclaration de dimensionnalité, utilisez toujours le nom du paramètre, et non pas sa valeur.
Dans le cadre de la fusion de données, le champ de liaison provenant de la source de données principale doit se trouver dans la vue pour que vous puissiez utiliser une expression de niveau de détail provenant de la source de données secondaire. Consultez Résoudre les problèmes liés à la fusion des données.
De plus, certaines sources de données ont des limites de complexité. Tableau ne désactive pas les calculs de ces bases de données, mais des erreurs de requête peuvent survenir si les calculs deviennent trop complexes.
Les expressions de niveau de détail peuvent être des dimensions ou des mesures
Lorsque vous enregistrez une expression de niveau de détail, Tableau l’ajoute à la zone Dimensions ou Mesures dans le volet Données.
Les expressions de niveau de détail FIXED peuvent se traduire par des mesures ou des dimensions, selon le champ sous-jacent dans l’expression d’agrégation. Ainsi MIN([Date])} sera une dimension car [Date] est une dimension, et {fixed Store : SUM([Sales])} sera une mesure car [Sales] est une mesure. Lorsqu’une expression de niveau de détail FIXED est enregistrée en tant que mesure, vous avez la possibilité de la déplacer vers les dimensions.
Les expressions de niveau de détail INCLUDE et EXCLUDE sont toujours des mesures.
Filtres et expressions LOD
Il existe plusieurs types de filtres différents dans Tableau qui sont exécutés dans l’ordre suivant de haut en bas.

Le texte de droite montre où les expressions de niveau de détail sont évaluées dans cette séquence.
Les filtres d’extrait (en orange) ne sont pertinents que si vous créez un extrait Tableau à partir d’une source de données. Les filtres de calculs de tables (bleu foncé) sont appliqués après l’exécution des calculs et masquent les repères sans filtrer les données sous-jacentes utilisées dans les calculs.
Si vous connaissez SQL, vous pouvez considérer les filtres de mesure comme équivalant à la clause HAVING dans une requête, et les filtres de dimension comme équivalant à la clause WHERE.
Les calculs FIXED sont appliqués avant les filtres de dimension, de sorte que si vous ne promouvez pas les champs de votre étagère Filtre au rang de Utiliser les filtres contextuels, ils sont ignorés. Par exemple, supposons que vous ayez le calcul suivant sur une étagère dans une vue, et [État] sur une autre étagère :
SUM([Sales]) / ATTR({FIXED : SUM([Sales])})
Ce calcul vous donnera le ratio des ventes d’un État par rapport aux ventes totales.
Si vous placez ensuite [État] sur l’étagère Filtres pour masquer certains des États, le filtre n’affectera que le numérateur du calcul. Dans la mesure où le dénominateur est une expression de niveau de détail FIXED, il continuera de diviser les ventes pour les États qui se trouvent toujours dans la vue par les ventes totales de tous les États, y compris ceux qui ont été éliminés de de la vue.
Les expressions de niveau de détail INCLUDE et EXCLUDE sont prises en compte après les filtres de dimension. Ainsi, si vous voulez des filtres à appliquer à votre expression de niveau de détail FIXED et ne voulez pas utiliser de Filtres contextuels, envisagez de les récrire comme des expressions INCLUDE ou EXCLUDE.
Agrégation et expressions LOD
Le niveau de détail de la vue détermine le nombre de repères de votre vue. Lorsque vous ajoutez une expression de niveau de détail à la vue, Tableau doit rapprocher les deux niveaux de détail, c’est-à-dire celui de la vue et celui de votre expression.
Le comportement d’une expression de niveau de détail dans la vue diffère selon que le niveau de détail de l’expression est plus grossier, plus fin que le niveau de détail de la vue ou identique à celui-ci. Que voulons-nous dire par "plus grossier" ou "plus fin" dans ce cas ?
L’expression de niveau de détail est plus grossière que le niveau de détail de la vue
Une expression a un niveau de détail plus grossier que la vue quand elle fait référence à un sous-ensemble des dimensions de la vue. Par exemple, pour une vue qui contient les dimensions [Catégorie] et [Segment], vous pouvez créer une expression de niveau de détail qui n’utilise qu’une de ces dimensions :
{FIXED [Segment] : SUM([Sales])}
Dans ce cas, l’expression a un niveau de détail plus grossier que la vue. Sa valeur est basée sur une dimension ([Segment]), tandis que la vue est basée sur deux dimensions ([Segment] et [Catégorie]).
Le résultat est que l’utilisation de l’expression de niveau de détail dans la vue provoque la réplication de certaines valeurs, c’est-à-dire qu’elles apparaissent plusieurs fois.
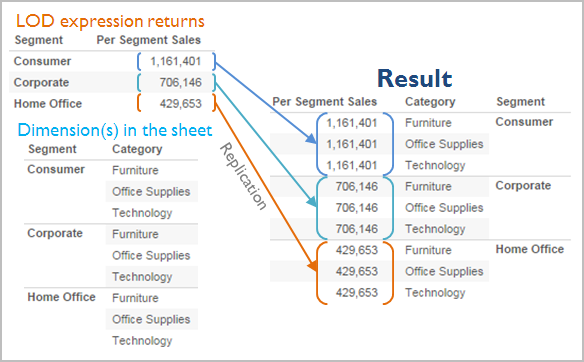
Les valeurs répliquées sont utiles pour comparer des valeurs spécifiques à des valeurs moyennes dans une catégorie. Par exemple, le calcul suivant soustrait les ventes moyennes pour un client des ventes moyennes générales :
[Sales] - {FIXED [Customer Name] : AVG([Sales])}
Lorsque les valeurs sont en cours de réplication, la modification de l’agrégation pour le champ pertinent de la vue (par exemple de AVG en SUM) ne modifiera pas le résultat de l’agrégation.
L’expression de niveau de détail est plus fine que le niveau de détail de la vue
Une expression a un niveau de détail plus fin que la vue quand elle fait référence à un surensemble des dimensions de la vue. Lorsque vous utilisez une telle expression dans la vue, Tableau agrège les résultats jusqu’au niveau de la vue. Par exemple, l’expression de niveau de détail suivante fait référence à deux dimensions :
{FIXED [Segment], [Category] : SUM([Sales])}
Lorsque cette expression est utilisée dans une vue qui ne comporte que [Segment] comme niveau de détail, les valeurs doivent être agrégées. Voici ce que vous voyez si vous faites glisser cette expression sur une étagère :
AVG([{FIXED [Segment]], [Category]] : SUM([Sales]])}])
Une agrégation—dans le cas présent, moyenne—est affectée automatiquement par Tableau. Vous pouvez modifier l’agrégation selon les besoins.
Ajout d’une expression de niveau de détail à la vue
Le type d’expression (FIXED, INCLUDE ou EXCLUDE) détermine si l’expression de niveau de détail est agrégée ou répliquée dans la vue et si la précision de l’expression est plus grossière ou plus fine que celle de la vue.
Les expressions de niveau de détail INCLUDE auront le même niveau de détail que la vue ou un niveau plus fin. Les valeurs ne seront donc jamais répliquées.
Les expressions à niveau de détail FIXED peuvent avoir un niveau de détail plus fin, plus grossier que la vue, ou identique à celle-ci. Le besoin d’agréger les résultats d’un niveau de détail FIXED dépend des dimensions qui figurent dans la vue.
Les expression EXCLUDE niveau de détail entraînent toujours l’affichage de valeurs répliquées dans la vue. Lorsque des calculs incluant des expressions EXCLUDE niveau de détail sont placées sur une étagère, Tableau utilise par défaut l’agrégation ATTR (et non SUM ou AVG) pour indiquer que l’expression ne fait pas réellement l’objet d’une agrégation et que la modification de l’agrégation n’aura pas d’effet sur la vue.
Les expressions de niveau de détail sont toujours automatiquement encapsulées dans une agrégation lorsqu’elles sont ajoutées à une étagère de la vue, sauf si elles sont utilisées comme dimensions. Ainsi, si vous double-cliquez sur une étagère et saisissez
{FIXED[Segment], [Category] : SUM([Sales])}
puis appuyez sur Entrée pour valider l’expression ; ce que vous voyez à présent sur l’étagère est
SUM({FIXED[Segment], [Category] : SUM([Sales])})
Cependant, si vous double-cliquez dans l’étagère pour modifier l’expression, ce que vous voyez en mode d’édition est l’expression d’origine.
Si vous encapsulez une expression de niveau de détail dans une agrégation lorsque vous la créez, Tableau utilise l’agrégation que vous spécifiez au lieu d’en affecter une lorsque tout calcul incluant cette expression est placé sur une étagère. Lorsqu’aucune agrégation n’est nécessaire (parce que le niveau de détail de l’expression est plus grossier que celui de la vue), l’agrégation que vous avez spécifiée apparaît toujours lorsque l’expression est sur une étagère, mais elle est ignorée.
Contraintes de la source de données pour les expressions LOD
Pour certaines sources de données, seules les versions plus récentes prennent en charge les expressions de niveau de détail. Certaines sources de données ne prennent pas du tout en charge les expressions de niveau de détail.
De plus, certaines sources de données ont des limites de complexité. Tableau ne désactive pas les calculs de ces bases de données, mais des erreurs de requête peuvent survenir si les calculs deviennent trop complexes.
| Source de données | Assistance |
| Actian Vectorwise | Non pris en charge. |
| Amazon EMR Hadoop Hive | Pris en charge pour la version 0.13 de Hive et les versions ultérieures. |
| Amazon Redshift | Pris en charge. |
| Aster Database | Pris en charge pour la version 4.5 et versions ultérieures. |
| Cloudera Hadoop | Pris en charge pour la version 0.13 de Hive et les versions ultérieures. |
| Cloudera Impala | Pris en charge pour la version 1.2.2 d’Impala et les versions ultérieures. |
| Cubes (sources de données multidimensionnelles) | Non pris en charge. |
| DataStax Enterprise | Non pris en charge. |
| EXASOL | Pris en charge. |
| Firebird | Pris en charge pour la version 2.0 et versions ultérieures. |
| Generic ODBC | Limité. Dépend de la source de données spécifique. |
| Google Big Query | Pris en charge pour SQL standard, non pris en charge pour SQL hérité. |
| Hortonworks Hadoop Hive | Pris en charge pour la version 0.13 de Hive et les versions ultérieures. Sur la version 1.1 de HIVE les expressions de niveau de détail qui produisent des liaisons croisées ne sont pas fiables. Une liaison croisée se produit en l’absence de champ explicite pour la liaison. Par exemple, pour une expression de niveau de détail |
| IBM BigInsights | Pris en charge. |
| IBM DB2 | Pris en charge pour la version 8.1 et versions ultérieures. |
| MarkLogic | Pris en charge pour la version 7.0 et versions ultérieures. |
| Microsoft Access | Non pris en charge. |
| Connexions basées sur Microsoft Jet (connecteurs hérités pour Microsoft Excel, Microsoft Access, et texte) | Non pris en charge. |
| Microsoft SQL Server | SQL Server 2005 et versions ultérieures. |
| MySQL | Pris en charge. |
| IBM PDA (Netezza) | Version 7.0 et versions ultérieures prises en charge. |
| Oracle | Version 9i et versions ultérieures prises en charge. |
| Actian Matrix (ParAccel) | Version 3.1 et versions ultérieures prises en charge. |
| Pivotal Greenplum | Pris en charge pour la version 3.1 et versions ultérieures. |
| PostgreSQL | Version 7 et versions ultérieures prises en charge. |
| Progress OpenEdge | Pris en charge. |
| SAP HANA | Pris en charge. |
| SAP Sybase ASE | Pris en charge. |
| SAP Sybase IQ | Version 15.1 et versions ultérieures prises en charge. |
| Spark SQL | Pris en charge. |
| Splunk | Non pris en charge. |
| Extrait de données Tableau | Pris en charge. |
| Teradata | Pris en charge. |
| Vertica | Pris en charge pour la version 6.1 et versions ultérieures. |
Consultez également
Créer des expressions LOD dans Tableau
Comprendre les expressions LOD (Level of Detail)(Le lien s’ouvre dans une nouvelle fenêtre)