データのブレンド
データ ブレンドは、複数のソースからのデータを組み合わせる方法のひとつです。セカンダリ データ ソースからの追加情報が取り込まれ、プライマリ データ ソースからのデータと共にビューに直接表示されます。
データ ブレンドは、ブレンドの関係 (リンク フィールド) をシート単位で変更する必要がある場合や、パブリッシュされたデータ ソースを結合する場合に特に便利です。
データ結合のオプション
データの組み合わせ方法は数多くありますが、それぞれに長所や短所があります。
リレーションシップは既定の方法であり、詳細レベルが異なるテーブルを含め、ほとんどのインスタンスで使用できます。関係には柔軟性があり、シート単位での分析構造に適応できます。ただし、パブリッシュされたデータ ソース間の関係を作成することはできません。
結合は、類似する行構造にデータの列を追加することによりテーブルを組み合わせます。ただし、テーブルが異なる詳細レベルである場合はデータが失われたり、重複することがあるため、分析を開始する前に結合を確立させる必要があります。パブリッシュされたデータ ソースを結合で使用することはできません。
ブレンドは、関係や結合とは異なり、データを直接組み合わせることはしません。ブレンドは各データ ソースに対して個別にクエリを実行し、その結果を適切なレベルに集計して、すべての結果をビューに視覚的に表示します。これにより、ブレンドはさまざまなレベルの詳細に対応し、パブリッシュされたデータ ソースを処理することができます。ブレンドは、ブレンドされたデータ ソースを新たに作成するわけではありません (したがって、「ブレンドされたデータ ソース」としてパブリッシュすることはできません)。これらは単に、シートごとにブレンドした結果を視覚化したものです。
データ ブレンドの手順
データ ブレンドはシート単位で実行され、2 番目のデータ ソースのフィールドがビューで使用されるときに確立されます。
ワークブックでブレンドを作成するには、少なくとも 2 つのデータ ソースに接続する必要があります。次に、フィールドを 1 つのデータ ソースからシートに移動します。これがプライマリ データ ソースになります。別のデータ ソースに切り替え、1 つのフィールドを同じシートで使用します。これがセカンダリ データ ソースになります。リンク アイコンがデータ ペインに表示され、データ ソースのブレンドに使用されているフィールドを示します。
- ワークブックに複数のデータ ソースがあることを確認してください。2 番目のデータ ソースは、[データ] > [新しいデータ ソース] から追加する必要があります。
Tip: ブレンドには、データ ペインに個別に表示される複数の異なるデータ ソースが必要です。最初のデータ ソースに別の接続を追加すると、[データ ソース] ページで関係と結合が有効になります。
- フィールドをビューにドラッグします。このデータ ソースがプライマリ データ ソースになります。
- 別のデータ ソースに切り替え、プライマリ データ ソースに対するブレンドの関係があることを確認します。
- リンク フィールド アイコン (
 ) がある場合、そのデータ ソースは自動的に関連付けられています。少なくとも 1 つのアクティブなリンクがある限り、データをブレンドできます。
) がある場合、そのデータ ソースは自動的に関連付けられています。少なくとも 1 つのアクティブなリンクがある限り、データをブレンドできます。 - 破損リンク アイコン (
 ) がある場合は、2 つのデータ ソースをリンクするフィールドの横にあるアイコンをクリックします。スラッシュが消え、アクティブなリンクになります。
) がある場合は、2 つのデータ ソースをリンクするフィールドの横にあるアイコンをクリックします。スラッシュが消え、アクティブなリンクになります。 - 目的のフィールドの横にリンク アイコンが表示されない場合は、ブレンドするリレーションシップを定義するを参照してください。
- リンク フィールド アイコン (
- セカンダリ データ ソースからフィールドをビューにドラッグします。
この 2 番目のデータ ソースが同じビューで使用されると、ブレンドがすぐに確立されます。以下の例では、プライマリ データ ソースは [Movie Adaptations (映画版)] で、セカンダリ データ ソースは [Bookshop (本屋)] です。
- プライマリ データ ソースはデータ ソース上の青色のチェック マークで示されます。ビューで使用されているプライマリ データ ソースのフィールドにはマークがありません。
- セカンダリ データ ソースは、データ ソース上のオレンジ色のチェック マークとデータ ペインの横のオレンジ色のバーで示されます。ビューで使用されているセカンダリ データ ソースのフィールドにはオレンジ色のチェック マークがあります。
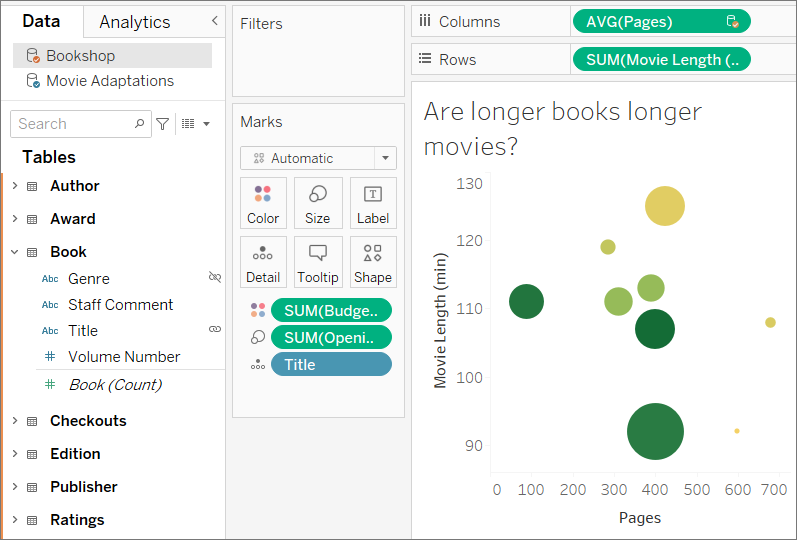
プライマリ データ ソースとセカンダリ データ ソースを理解する
データ ブレンドには、1 つのプライマリ データ ソースと 1 つまたは複数のセカンダリ データ ソースが必要です。ビューで使用される最初のデータ ソースはプライマリ データ ソースになり、ビューを定義します。これにより、セカンダリ データ ソースからの値を制限して、プライマリ データ ソースに対応する一致があるセカンダリ データ ソースの値のみをビューに表示できます。これは左結合に相当します。
たとえば、プライマリ データ ソースの [Month (月)] フィールドに [April (4 月)]、[May (5 月)]、[June (6 月)] だけが含まれている場合、セカンダリ データ ソースに 12 か月分の値があるとしても、月に基づいて作成されたビューには [April (4 月)]、[May (5 月)]、[June (6 月)] だけが表示されます。必要な分析に 12 の月のすべてが関係する場合は、他方のデータ ソースを最初に使用してシートを再構築することにより、プライマリ データ ソースを切り替えてみてください。
以下の例では、同じフィールドでリンクされている同じデータ ソースを使用しており、Viz も同じように作成されています。結果の違いは、プライマリとして指定されているデータ ソースが原因です。
- ここでは、[Rainfall (雨量)] データ ソースの [Month (月)] フィールドが最初にビューに取り込まれています。[Rainfall (雨量)] には 3 つの月しか含まれていないため、[Pollen (花粉)] データ セットがセカンダリとして追加されるとき、3 つの月だけがビューに取り込まれます。
- 別のシートでは、[Pollen (花粉)] データ セットの [Month (月)] フィールドが最初にビューに取り込まれています。12 の月すべてが表示されています。[Rainfall (雨量)] データ セットがセカンダリとして追加されると、そのデータセットの 3 つの月の雨量だけが表示されます。
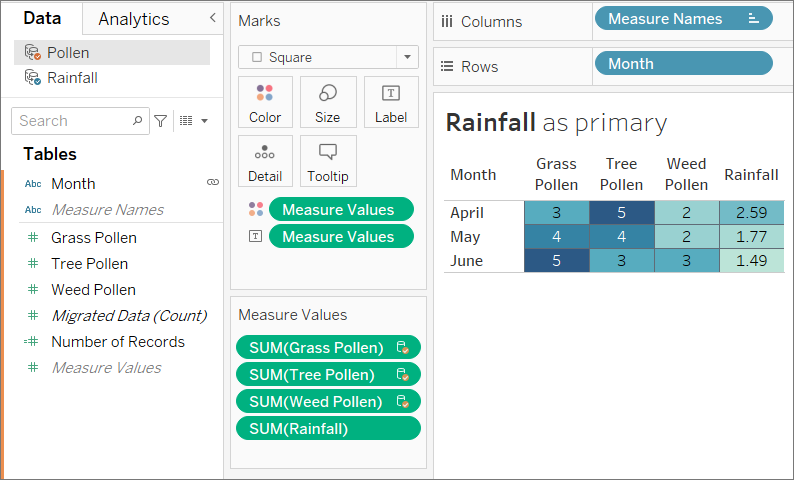
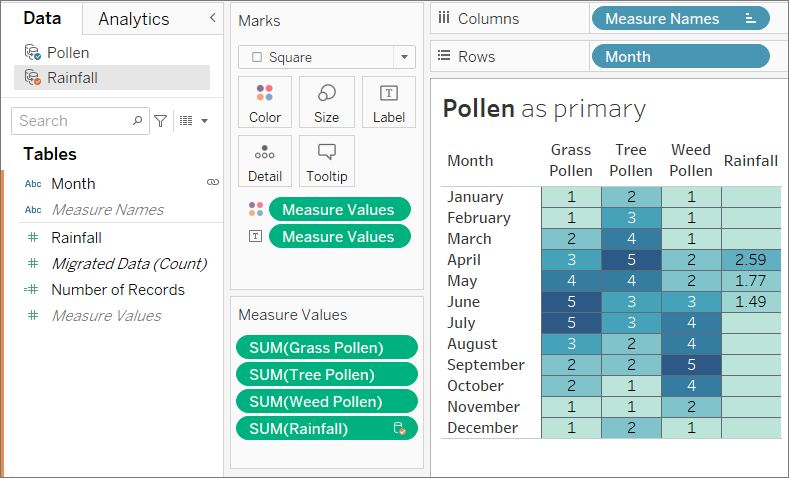
ブレンドされたデータ ソース全体の処理
データ ブレンドの性質により、ブレンドされたデータ ソースで作業する場合に考慮する必要のある点がいくつかあります。
複数のデータ ソースのフィールドを使用した計算の実行は、通常の計算とは若干異なる可能性があります。計算は単一のデータ ソースで作成する必要があります。計算エディターの上部には、計算の対象となるデータ ソースが示されます。
- 集計。別のデータ ソースから使用されるフィールドには集計 (既定では SUM) が付いていますが、これは変更できます。計算では集計引数と非集計引数を組み合わせることができないため、計算のホスト データ ソースのフィールドも集約する必要があります。(以下の画像で、SUM 集計は自動的に追加され、sum 集計は手動で追加されました)。
- ドット表記。計算で参照されるフィールドのうち、他のデータ ソースに属するものは、ドット表記を使用してそのデータ ソースを参照します。(以下の画像で、[サンプル - スーパーストア] 用に作成された計算では、[Sales Target (売上目標)] フィールドは [Sales.Targets].[Sales Target] になります。計算が [Sales Targets (売上目標)] で作成される場合、[Sales (売上)] フィールドは [サンプル - スーパーストア].[Sales] になります)。
- これらは、各データ ソースで作成される同じ計算の等価バージョンです。どちらの場合も、これは SUM(Sales) / SUM(Sales Target) です。
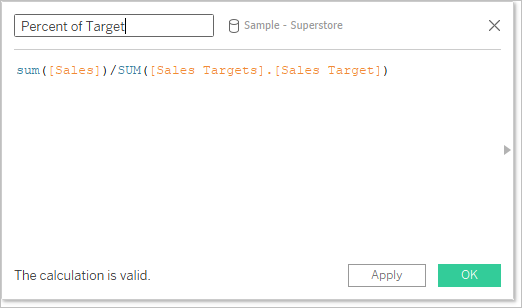
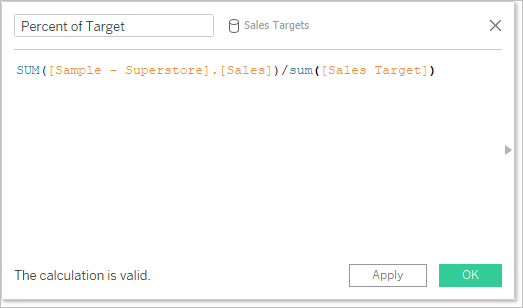
計算が少し異なる方法で処理されることに加えて、セカンダリ データ ソースにはいくつかの制限があります。セカンダリ データ ソースのフィールドによって並べ替えができなかったり、アクション フィルターがブレンドされたデータで予期したとおりに動作しなかったりする場合があります。詳細については、その他のデータ ブレンドの問題を参照してください。
ブレンドするリレーションシップを定義する
Tableau で複数のソースからのデータの組み合わせ方法が認識されるようにするには、データ ソース間に共通のディメンションが必要です。この共通のディメンションはリンク フィールドと呼ばれます。セカンダリ データ ソースのデータ ペインでは、アクティブなリンク フィールドにはアクティブなリンク アイコン (![]() ) が表示され、リンクしている可能性のあるフィールドには破損リンク アイコン (
) が表示され、リンクしている可能性のあるフィールドには破損リンク アイコン (![]() ) が表示されます。リンク フィールドは、プライマリ データ ソースに表示されません。
) が表示されます。リンク フィールドは、プライマリ データ ソースに表示されません。
たとえば、トランザクション データと割り当てデータのブレンドでは、地理的フィールドをリンク フィールドとして使用すると、同じ地域の割り当てとそのパフォーマンスの両方を分析することができます。
注: ブレンドが機能するには、リンク フィールドで値またはメンバーを共有する必要があります。Tableau では、共有値に基づいてブレンド データのビューが作成されます。たとえば、[Color (色)] が両方のデータ ソースのリンク フィールドの場合、プライマリの [Purple (紫色)] とセカンダリの [Purple (紫)] のデータがマッチングされます。しかし、[Lt. Blue (ライトブルー)] は正しく [Light Blue (ライトブルー)] にマッチングされないため、これらのいずれかの別名を変更する必要があります。Tableau がリンク フィールドを識別できるようにフィールドの名前を変更するのと同様に、これらのフィールド内のメンバーの別名を編集できます。詳細については、ビュー内でメンバー名を変更する別名を作成するを参照してください。
リンクの確立
プライマリ データ ソースとセカンダリ データ ソースでリンク フィールドの名前が同じ場合は、自動的にリレーションシップが作成されます。プライマリ データ ソースが確立されている (つまり、フィールドがビューで使用されている) 場合、データ ペインでセカンダリ データ ソースを選択すると、2 つのデータ ソース間で同じ名前を持つフィールドのセカンダリ データ ソースに、リンク アイコン (![]() または
または ![]() ) が表示されるようになります。プライマリ データ ソースの関連フィールドがビューで使用されている場合、リンクは自動的にアクティブになります。
) が表示されるようになります。プライマリ データ ソースの関連フィールドがビューで使用されている場合、リンクは自動的にアクティブになります。
セカンダリ データ ソースにリンク アイコンがない場合は、次の 2 つの方法のいずれかでリンクを確立しなければならない場合があります。
共通のディメンションが同じ名前ではない (たとえば、[Title (タイトル)] と [Book Title (本のタイトル)] である) 場合は、一方の名前を変更すると共通のディメンションとして識別され、リンクが確立されます。
または、プライマリ データ ソースとセカンダリ データ ソースのフィールド間のリレーションシップを手動で定義することができます。手動のリンクのリレーションシップを作成する方法について詳しくは、以下を参照してください。
アクティブなリンク フィールドやリンクしている可能性のあるフィールドは、必要なだけ作成できます。データ ペインで破損リンク アイコン (![]() ) をクリックすると、関係がアクティブになります。
) をクリックすると、関係がアクティブになります。
共通のディメンションが同じ名前を共有していない場合、それらの間でリレーションシップを手動でマッピングできます。
[データ] > [Edit Blend Relationships... (ブレンドのリレーションシップの編集)] を選択します。
[Blend Relationships (ブレンドのリレーションシップ)] のダイアログ ボックスで、[プライマリ データ ソース] のドロップ ダウン メニューからプライマリ データ ソースが選択されていることを確認します。
[セカンダリ データ ソース] ペインでセカンダリ データ ソースを選択します。既存の自動ブレンド関係が表示されます (行にカーソルを合わせて [x] をクリックすると削除できます)。リレーションシップのリストで [カスタム] を選択し、[追加] をクリックします。
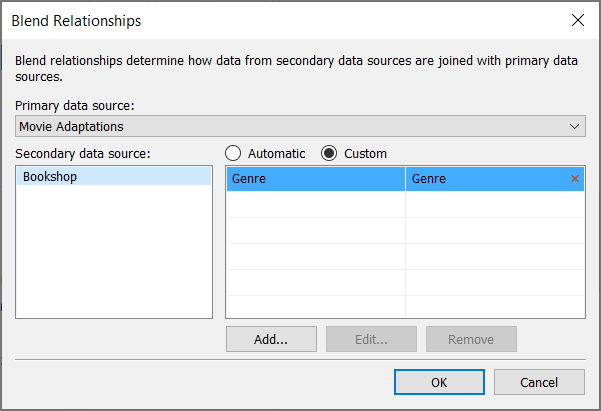
[フィールド マッピングの追加/編集] ダイアログ ボックスで、次の操作を実行します。
プライマリ データ ソースからフィールドを選択します。
セカンダリ データ ソースから比較可能なフィールドを選択します。
[OK] をクリックします。
この例では、[Segment (区分)] が [Cust Segment (顧客区分)] にマッピングされます。
![[add/edit relationships (関係の追加/編集)] ダイアログ ボックスの製品 UI](Img/datablending_addedit.png)
ヒント: 日付の場合は、リレーションシップを正確に指定できます。日付フィールドを展開し、正確な日、月、年など、日付の適切な側面を選択します。
フィールド マッピングを必要に応じて作成した後、[OK] をクリックします。
複数のリンク
リレーションシップや結合と同様に、データ ソース間のリンクが複数のフィールドによって定義されている場合があります。たとえば、地域の売上ノルマが月単位である場合、正しいデータがビューに取り込まれるように、地域と月の両方に基づいてトランザクション売上データと売上ノルマ データの間のブレンドを確立する必要があります。複数のリンクを同時にアクティブにできます。
データを複数のフィールドに基づいてブレンドする際、それらのフィールドのデータの組み合わせが両方のデータ セット間で一致する場合にのみ、値はビューに含められます。これを理解するための例を見てみましょう。
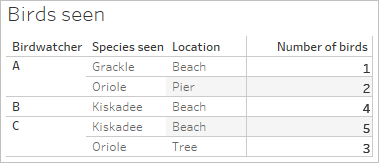
ここに 2 つのテーブルがあります。1 つはバードウォッチャーが実際に観察した鳥について、もう 1 つは観察が報告された鳥についてです。
 および
および 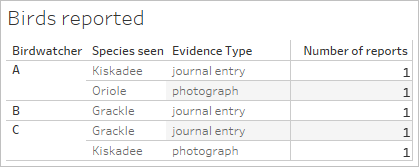
プライマリ データ ソース ([Birds seen (観察された鳥)]) のフィールド [Birdwatchers (バードウォッチャー)] および [Number of birds (鳥の数)] を含むブレンド ビューを設定し、セカンダリ データ ソース ([Birds reported (報告された鳥)]) のフィールド [Number of reports (報告数)] を取り込むと、自動的に [Birdwatcher (バードウォッチャー)] に基づいてブレンドが実行されます。
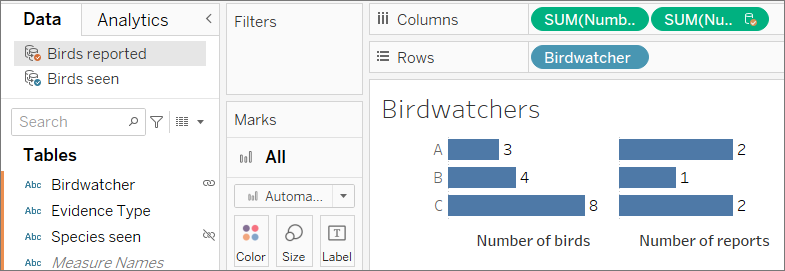
バードウォッチャー A が 3 羽の鳥を観察して 2 件の報告を行い、B が 4 羽の鳥を観察して 1 件の報告を行い、C が 8 羽の鳥を観察して 2 件の報告を行ったことがわかります。
しかし、[Species seen (観察された種類)] もリンク フィールドとして使用できます。このフィールドでもブレンドを実行してみましょう。違いは生じるでしょうか。
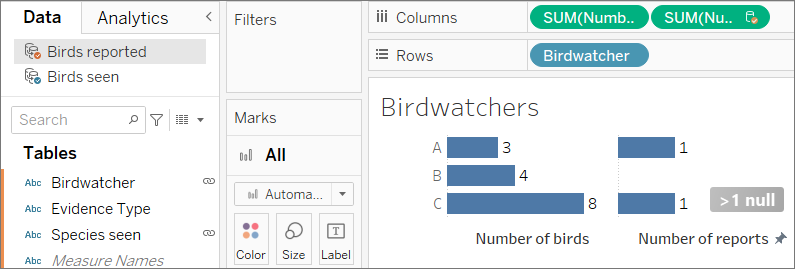
かなり大きな違いが生じます。バードウォッチャー A と C による報告がそれぞれ 1 件だけになり、B は 0 件になりました。どういうことでしょうか。
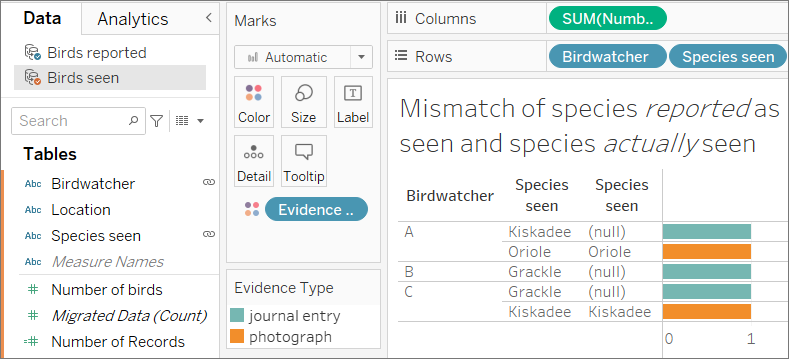
これらのバードウォッチャーがそれほど正直でないことが判明しました。日記の項目に基づいて観察内容を報告しただけのとき (上の画像にある青色のバー)、報告された種類は実際に観察された種類と一致しませんでした ([Birds seen (観察された鳥)] セカンダリ データ ソースの 2 番目の列が NULL になっていることに注目してください)。報告を写真で裏付けたとき (オレンジ色のバー)、その報告は正直でした ([Species seen (観察された種類)] の両方の列が一致します)。
3 つのレポートで種類が一致しなかったため、[Species seen (観察された種類)] がリンク フィールドとして使用されたときに、該当するデータ行が削除されました。ビューには、両方のリンク フィールドで値が一致するデータだけが表示されます。
Takeaway
複数のフィールドでリンクする場合は注意してください。アイコンをクリックしてアクティブなリンクを確立することは非常に簡単かもしれませんが、リンク フィールドが多すぎたり不適切だったりすると、分析に重大な影響が及ぶ可能性があります。
結合とデータ ブレンドの違い
データ ブレンドは、従来の左結合のシミュレーションを行います。2 つの主な違いは、集計が実行されるタイミングです。結合では、データが組み合わされてから集計されます。ブレンドでは、データが集計されてから組み合わされます。
左結合
左結合を使用してデータを組み合わせると、結合が実行されたデータベースにクエリが送信されます。左結合では、左のテーブルのすべての行と、右のテーブルでそれに対応する行が返されます。結合の結果は Tableau に返され、ビジュアライゼーションでの表示用に集計されます。
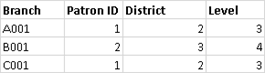
左結合では、左の表のすべての行が取得されます。共通の列は [User ID (ユーザー ID)] と [Patron ID (パトロン ID)] です。右の表に対応する情報がある場合は、そのデータが返されます。それ以外の場合は、NULL が入ります。
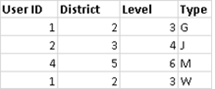


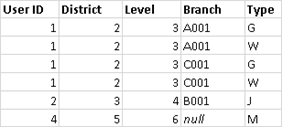
同じ表を使用しますが、順序を反転したとします。この新しい左結合の結果は異なります。今回も新しい左の表からはすべてのデータが取得されますが、右の表の行は基本的に無視されます。[User ID (ユーザー ID)] が 4 であるデータ行は、左の表に [Patron ID (パトロン ID)] が 4 である行がないため、含められません。
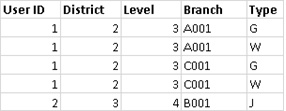
データ ブレンド
データ ブレンドを使用してデータを組み合わせる場合、シートで使用される各データ ソースのデータベースにクエリが送信されます。クエリの結果は集計されたデータとして Tableau に返され、ビジュアライゼーションでまとめて表示されます。
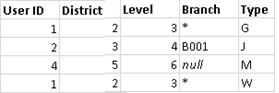
注: メジャーを集計することは簡単です。数値の合計、平均、最大値その他の集計を簡単に実行できます。メジャーの値は、ビューにおけるフィールドの集計方法に基づいて集計されます。ただし、セカンダリ データ ソースのすべてのフィールドが集計される必要があります。ディメンションの場合はどうでしょうか。ディメンション値は ATTR 集計関数を使用して集計され、セカンダリ データ ソースのすべての行に対して 1 つの値が返されます。これらの行に複数の値がある場合は、アスタリスク (*) が表示されます。これは、「ビューのこのマークについてセカンダリ データ ソースに複数の値がある」と解釈できます。
ビューはリンク フィールドに基づいて、プライマリ データ ソース (左の表として機能する) のすべての値と、セカンダリ データ ソース (右の表) の対応する行を使用します。
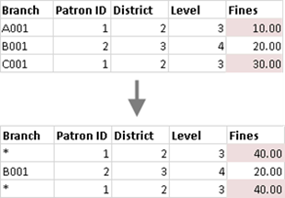
次の表があるとします。リンク フィールドが [User ID (ユーザー ID)] と [Patron ID (パトロン ID)] である場合は、次の理由により、一部の値が結果の表の一部にならない可能性があります。
左の表の行に対応する行が右の表にありません。これは結果で NULL 値によって示されます。
右の表の行に対応する値が複数あります。これは結果でアスタリスク (*) によって示されます。

メジャーが関係する場合は、メジャーも次のように集計されます。
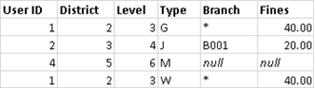
重要: ブレンドされたデータを含むビュー内のアスタリスク (*) は複数の値を示します。これは、プライマリ データ ソースの各マークについて、セカンダリ データ ソースで一致する値を 1 つだけにする (プライマリ データ ソースとセカンダリ データ ソースを入れ替えることもできます) ことによって解決できます。詳細については、データ ブレンドのトラブルシューティングを参照してください。
データ ブレンドの概要
- データ ブレンドはシート単位で行われます。
- フィールドが使用される順序によって、どのデータ ソースがセカンダリ データ ソースに対するプライマリになるかが決まります。
- プライマリ データ ソースは青色のチェック マークで示され、セカンダリ データ ソースとそのフィールドにはオレンジ色のチェック マークが付けられます。
- リンク フィールドを共有フィールド名に基づいて自動的に決定するか、ブレンドのリレーションシップを手動で作成することができます。
- データ ブレンドは左結合のように動作するため、セカンダリ データ ソースのデータが除外されることもあります。
- アスタリスク (*) が表示される場合もあります。これは、1 つのマークで複数のディメンション値が存在することを示します。これが生じるのは、データ ブレンドでは集計された結果がビューで組み合わされるためです。
- セカンダリ データ ソースを使用して、プライマリ データ ソース内のフィールド値に別名を付け直すこともできます。詳細については、データ ブレンドを使用してフィールドの値に別名を付けるを参照してください。
データ ブレンドの制限事項
- COUNTD、MEDIAN、RAWSQLAGG などの非加算的な集計に関しては、一部のデータ ブレンドの制限があります。詳細については、データ ブレンドのトラブルシューティングを参照してください。
- ブレンドされたデータ ソースを 1 つの単位としてパブリッシュすることはできません。代わりに、各データ ソースを個別に (同じサーバーに) パブリッシュした後、パブリッシュ済みデータ ソースをブレンドします。
- セカンダリ データ ソースのデータは、常に計算で集計される必要があります。
- キューブ データ ソースをブレンドする場合は、それがプライマリ データ ソースである必要があります。